Mon, Jan 08, 2024

 cabelo
cabeloMúsica para Carnaval criada com IA

Estou lançando o que pode ser o primeiro hit de carnaval em português do Brasil criado por inteligência artificial. Esta música reflete um aspecto contemporâneo do comportamento humano: a tendência de capturar e compartilhar momentos através de selfies, e a expectativa de receber curtidas em troca. Esta prática se tornou uma característica marcante da nossa sociedade digital.
Vivemos em uma era de mudanças sem precedentes, descrita como o momento mais disruptivo para a humanidade. As inovações tecnológicas estão abrindo portas para novas oportunidades e um significativo aumento na produtividade. Estas transformações estão redefinindo como vivemos e trabalhamos.
Um dos maiores benefícios desta era tecnológica é a contribuição da inteligência artificial para melhorar nossa qualidade de vida. A IA está cada vez mais capacitada para assumir tarefas repetitivas, liberando os seres humanos para se dedicarem a atividades mais criativas e significativas. Este avanço promete não apenas mais eficiência, mas também uma nova forma de experienciar o mundo.
Clique na imagem abaixo para ouvir a música
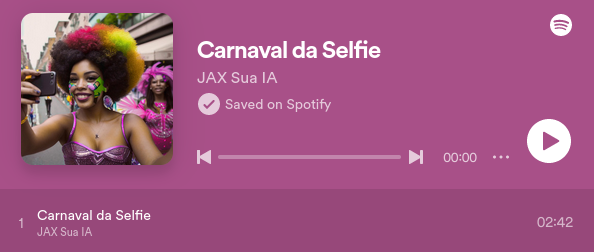
Em breve estará disponível JAX: A nossa IA!
Música para Carnaval criada 100% com IA

Estou lançando o que pode ser o primeiro hit de carnaval em português do Brasil criado por inteligência artificial. Esta música ( Carnaval da Selfie ) reflete um aspecto contemporâneo do comportamento humano: a tendência de capturar e compartilhar momentos através de selfies, e a expectativa de receber curtidas em troca. Esta prática se tornou uma característica marcante da nossa sociedade digital.
Vivemos em uma era de mudanças sem precedentes, descrita como o momento mais disruptivo para a humanidade. As inovações tecnológicas estão abrindo portas para novas oportunidades e um significativo aumento na produtividade. Estas transformações estão redefinindo como vivemos e trabalhamos.
Um dos maiores benefícios desta era tecnológica é a contribuição da inteligência artificial para melhorar nossa qualidade de vida. A IA está cada vez mais capacitada para assumir tarefas repetitivas, liberando os seres humanos para se dedicarem a atividades mais criativas e significativas. Este avanço promete não apenas mais eficiência, mas também uma nova forma de experienciar o mundo.
Clique na imagem abaixo para ouvir a música
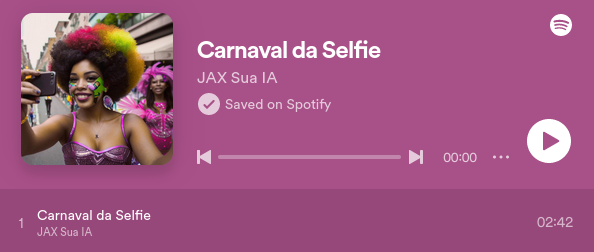
Em breve estará disponível JAX: A nossa IA!
Thu, Jan 04, 2024
OpenCV 4.9.0 Lançada!

A biblioteca OpenCV lançou sua versão 4.9.0. Esta ferramenta, globalmente reconhecida e aplicada em diversos setores, foi originalmente apresentada ao mundo pela Intel no ano 2000. Hoje, conta com uma comunidade de mais de 47 mil contribuidores. E fiquei muito feliz de encontrar meu nome na lista de contribuidores deste release.
- Core Module:
DNN module patches:
- Experimental transformers support
- #24476 ONNX Attention layer support
- #24037 ONNX Einsum layer support
- #23987 OpenVINO backend for INT8 models
- #24092 ONNX Gather Elements layer
- #24378 ONNX InstanceNorm layer
-
#24295 better support of ONNX Expand layer with
cv::broadcast - #24463 #24577 #24483 Improved DNN graph fusion with shared nodes and commutative operations
- #23897 #24694 #24509 New fastGEMM implementation and several layers on top of it
- #23654 Winograd fp16 optimizations on ARM
- Tests and multiple fixes for Yolo family models support
- New layers support and bug fixes in CUDA backend: GEMM, Gelu, Add
- #24462 CANN backend: bug fix, support HardSwish, LayerNormalization and InstanceNormalization
- #24552 LayerNormalization: support OpenVINO, OpenCL and CUDA backend.
Objdetect module:
- #24299 Implemented own QR code decoder as replacement for QUIRC library
- #24364 Bug fixes in QR code encoder version estimation
- #24355 More accurate Aruco marker corner refinement with dynamic window
- #24479 Fixed contour filtering in ArUco
- #24598 QR code detection sample for Android
- Multiple local bug fixes and documentation update for Aruco makers, Charuco boards and QR codes.
Mais detalhes aqui : https://github.com/opencv/opencv/releases/tag/4.9.0
Sun, Dec 31, 2023
Feliz 2024

Imagem gerada 100% com IA, inclusive EU.
Sun, Dec 24, 2023

Sun, Dec 17, 2023
Stable Diffusion WebUI 1.70 disponível.

No dia 15 de dezembro, foi lançada a versão 1.70 do Stable Diffusion, um marco significativo para mim, pois tive a honra de contribuir, ainda que modestamente. Minha participação focou-se na compatibilização com as plataformas Linux openSUSE e Fedora, especificamente no uso da biblioteca TCMALLOC, no pull request #13936. A TCMalloc, desenvolvida com uma implementação alternativa das funções malloc() em C/ C++, utilizadas para alocação de memória nessas linguagens de programação. Essa biblioteca se destaca por ser uma solução malloc rápida e projetada para operações multithread, ou seja, otimizada para programação em sistema multi-nuclear. Os binários e os códigos-fonte da versão utilizada, estão disponíveis no repositório openSUSE for Innovators, oferecendo aos desenvolvedores acesso aprimorado e otimizado para essas plataformas neste link: https://build.opensuse.org/projects/home:cabelo:innovators/packages/gperftools/repositories/15.5/binaries .

Mais informações : https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.7.0
Wed, Dec 13, 2023
OWASP SP : Terceiro Virtual de 2023
Desafios e Empoderamento: Mulheres na Linha de Frente da Cibersegurança

O OWASP São Paulo Chapter está entusiasmado em anunciar mais um encontro virtual, focado em um tema crucial e inspirador: “Desafios e Empoderamento: Mulheres na Linha de Frente da Cibersegurança“. Este evento especial será marcado pela presença de três mulheres excepcionais que se destacam no cenário da cibersegurança: Eva Pereira, Paula Papis e Carolina Bozza.
O bate-papo será moderado pela Professora Ines Brosso e Patricia Sanches, e trará à tona temas relevantes de cibersegurança, será debatido também sobre os desafios extras que mulheres precisam enfrentar para entrar e crescer dentro da área de Segurança da Informação.
Acesse nossa pagina no LinkdIn para ver mais sobre os nossos convidados.
Este evento será um espaço inclusivo e esclarecedor, destacando não apenas a importância das mulheres na cibersegurança, mas também abordando desafios enfrentados por elas no campo profissional.
Este evento oferecerá uma oportunidade única para discutir, aprender e se inspirar com a experiência e a sabedoria dessas mulheres excepcionais na cibersegurança.
Marque em sua agenda e não perca esta oportunidade única de mergulhar no mundo da cibersegurança e do papel crucial que cada indivíduo desempenha na proteção dos dados e informações.
A transmissão será realizada ao vivo no canal do YouTube da OWASP São Paulo Chapter e pela nossa pagina do LinkedIn. Inscreva-se agora para receber atualizações e lembretes sobre este evento imperdível!
Fique ligado para mais detalhes e não deixe de participar deste diálogo fascinante sobre o fator humano na segurança digital. Nos vemos lá!

Wed, Nov 29, 2023
OWASP SP : Segundo Meetup Virtual de 2023

O Fator Humano na Segurança da Informação: Um Diálogo Inovador com Especialistas de Destaque
A OWASP São Paulo Chapter tem o prazer de anunciar seu próximo encontro virtual, um bate-papo imperdível sobre o papel crucial do fator humano na Segurança da Informação. Este evento promete uma discussão profunda e esclarecedora, trazendo à mesa três renomados especialistas no campo da cibersegurança: Céu Balzano, Rafael Silva e Rodrigo Jorge.
Acesse nossa pagina no LinkdIn para ver mais sobre os nossos convidados.
Este encontro virtual promete explorar não apenas os aspectos técnicos, mas também os desafios e oportunidades que o fator humano apresenta no universo da Segurança da Informação. Junte-se a nós para uma conversa enriquecedora com especialistas de ponta, onde insights valiosos e perspectivas inovadoras serão compartilhados.
Marque em sua agenda e não perca esta oportunidade única de mergulhar no mundo da cibersegurança e do papel crucial que cada indivíduo desempenha na proteção dos dados e informações.
A transmissão será realizada ao vivo no canal do YouTube da OWASP São Paulo Chapter. Inscreva-se agora para receber atualizações e lembretes sobre este evento imperdível!
Fique ligado para mais detalhes e não deixe de participar deste diálogo fascinante sobre o fator humano na segurança digital. Nos vemos lá!
SOBRE A OWASP SÃO PAULO
A OWASP São Paulo é um dos 9 capítulos brasileiros entre os mais de 270 ativos em todo o mundo. O objetivo é disseminar a missão da fundação, tornando a segurança das aplicações visível para que as pessoas e as organizações possam tomar decisões conscientes sobre os verdadeiros riscos que correm.
São realizados encontros periódicos para compartilhamento de conhecimentos, discussão de temas e aprendizado sobre segurança de software.
Participe!

Mon, Nov 06, 2023
IA permite criar vídeos com sensação de Toque

Com a integração de tecnologias hápticas avançadas, os ambientes imersivos do metaverso e a aplicação de inteligência artificial (IA), estamos agora na vanguarda de uma era em que vídeos e hologramas ultrapassam a barreira da tela. Essa sinergia tecnológica permite que usuários interajam com objetos nas cenas digitais de maneira tátil, efetivamente podendo “tocar” e sentir o conteúdo virtual. Isso é possível graças à capacidade da IA de gerar mapas de profundidade detalhados em imagens e vídeos, criando uma simulação realística de espaços tridimensionais. Adicionalmente, com as inovações contínuas no metaverso, essas experiências interativas e táteis estão se tornando mais acessíveis e ricas, marcando uma nova fase na interação humano-computador.
Primeiramente, o processo inicia com a divisão do vídeo em frames individuais, que são posteriormente processados por um algoritmo de deeo learning. Este algoritmo é responsável por avaliar meticulosamente cada pixel dos frames para estimar sua profundidade, levando em consideração fatores como dimensão e formato dos objetos, nuances de iluminação e padrões de movimento. Através da síntese dessas estimativas, um mapa de profundidade coerente é gerado para o vídeo completo. Esse mapa é a chave para renderizar o vídeo de forma a emular a percepção tridimensional, conferindo-lhe um efeito 3D convincente. Para garantir precisão e realismo, o algoritmo é treinado utilizando um vasto conjunto de dados que abrange vídeos detalhados de pessoas, objetos diversos e ambientes naturais, permitindo-lhe aprender e reconhecer uma ampla gama de profundidades espaciais. Abaixo um exemplo do vídeo processado e renderizado.
Esta técnica é denominada “Video Depthify”, refere-se à criação de uma sensação tridimensional ao atribuir valores de profundidade a cada pixel ou região de um vídeo. O objetivo é fazer com que os objetos pareçam ter profundidade real e relações espaciais uns com os outros, ao invés de parecerem planos.
Para que um modelo de machine learning possa “depthify” vídeos, ele primeiro precisa ser treinado em um grande conjunto de dados, assim posteriormente permitindo que o modelo aprenda a relação entre os pixels do vídeo e os valores de profundidade correspondentes.
Redes Neurais Convolucionais (CNNs): As CNNs são usadas nesse tipo de tarefa, pois são particularmente boas em tarefas relacionadas à imagem e vídeo. Elas podem identificar características e padrões em imagens que correspondem a diferentes níveis de profundidade.
Estimação de profundidade monocular é uma técnica que tenta derivar mapas de profundidade de imagens ou vídeos de uma única lente. Isso é particularmente desafiador, mas com conjuntos de dados suficientes e modelos complexos, tornou-se viável “depthify” vídeos que foram gravados sem qualquer equipamento especializado de profundidade.
Hardware 3D
Atualmente, a geração de vídeos com profundidade alcançou um patamar notavelmente avançado graças à utilização de câmeras 3D inovadoras, como a Intel RealSense e a OAK-D, que capturam dados espaciais com grande precisão. Estas câmeras são equipadas com sensores de profundidade sofisticados, que mapeiam o ambiente em três dimensões em tempo real, fornecendo uma nuvem de pontos densa e informações detalhadas sobre a forma e o posicionamento dos objetos no espaço. Combinando esses dados ricos com algoritmos inteligentes, é possível criar vídeos que não apenas exibem imagens com aparência tridimensional, mas que também permitem interações profundamente imersivas e aplicativos avançados em realidade aumentada, robótica e além, revolucionando como interagimos e percebemos conteúdo digital em três dimensões. Um exemplo, é o projeto que desenvolvi para projetar hologramas com câmeras realsense https://github.com/cabelo/rscreatelg .


Luvas com tecnologia háptica
As tecnologias táteis, como o TactGlove da bHaptics, são dispositivos inovadores que buscam melhorar a imersão em ambientes virtuais e digitais através da simulação de sensações táteis.
Funcionam com atuadores e Mapeamento de Sensações: O TactGlove, e dispositivos similares, são equipados com uma série de atuadores distribuídos ao longo da superfície da luva (por exemplo, um luva). Estes atuadores são pequenos motores ou módulos que podem vibrar ou se mover de maneiras específicas. Quando ativados, eles recriam a sensação de toque, pressão ou até mesmo movimento na pele do usuário, imitando a sensação de estar tocando ou sendo tocado por objetos virtuais.

Esses dispositivos táteis são conectados a sistemas de realidade virtual (VR) ou realidade aumentada (AR). Quando um usuário interage com um objeto virtual ou experimenta um evento no ambiente digital (como ser atingido por um objeto), o sistema envia informações para o dispositivo tátil. Baseando-se nessa informação, o dispositivo ativa os atuadores apropriados para simular a sensação correspondente.
Quando se utiliza inteligência artificial para gerar um vídeo com tecnologia Depthify, o sistema consegue calcular precisamente as coordenadas relativas dos objetos virtuais dentro do vídeo em relação ao ambiente real. Essa habilidade de “entender” a posição espacial permite, então, ativar os mecanismos hápticos de uma luva especializada, como a vibração, no exato momento em que uma colisão entre pontos tridimensionais é detectada. Desta forma, o usuário pode experimentar uma resposta tátil sincronizada com a interação visual, intensificando a imersão e proporcionando uma experiência de realidade mista convincente e interativa.
Abaixo um exemplo da tecnologia em prática. Resumidamente o futuro chegou!
Sat, Nov 04, 2023
IA gera modelos 3D em minutos.
Esta totalmente dominado a capacidade de transformar textos em imagens 2D através de ferramentas de IA como Midjourney, DallE 3 da OpenAI, Leonardo AI e Stable Diffusion. Agora, a Stability AI, responsável pelo Stable Diffusion, está avançando para desenvolver modelos 3D a partir de prompts em tempo recorde com seu novo recurso, o Stable 3D AI. Este instrumento revolucionário tem como objetivo descomplicar a elaboração de conteúdo 3D, facilitando a criação de objetos 3D texturizados de alta qualidade.
Foi apresentado um vídeo demonstrativo sobre a facilidade de se criar modelos 3D a partir de instruções textuais, similar ao processo usado em artes 2D com IA. Os modelos 3D representam o próximo desafio a ser superado pela inteligência artificial. O Stable 3D é um marco na área de modelagem 3D, ao automatizar um processo que historicamente demandava habilidades especializadas e tempo considerável.
Crie modelos 3D através de instruções textuais com o auxílio da IA
O Stable 3D possibilita que mesmo aqueles sem conhecimento na área, gerar modelos 3D preliminares em questão de minutos. Basta escolher uma imagem, ilustração ou fornecer uma instrução textual. A ferramenta, a partir dessas informações, desenvolve um modelo 3D, eliminando etapas manuais de modelagem e texturização. Os modelos produzidos pelo Stable 3D são disponibilizados no formato padrão “.obj”, compatível com a maioria dos softwares 3D, permitindo edições posteriores em programas renomados como Blender e Maya, ou até sua integração em motores de jogos como Unreal Engine 5 ou Unity.
O Stable 3D não só torna o processo de criação 3D mais simples, mas também mais econômico. Ele busca democratizar o cenário para designers, artistas e desenvolvedores autônomos, habilitando a geração de inúmeros objetos 3D diariamente a um custo reduzido. Tal avanço tem o potencial de revolucionar setores como desenvolvimento de jogos, animação e realidade virtual, nos quais a produção de objetos 3D é fundamental.
Stable 3D: Uma Inovação da Stability AI
O surgimento do Stable 3D é uma evidência do progresso na criação de conteúdo 3D. Essa capacidade de transformar instruções textuais em modelos 3D em poucos minutos destaca a evolução contínua da inteligência artificial no universo da criação digital. À medida que essa tecnologia avança, antecipamos uma transição de modelos básicos para estruturas de malha detalhadas.
Neste momento, a Stability AI oferece uma prévia exclusiva do Stable 3D para quem demonstrar interesse. Os interessados podem se conectar com a Stability AI através de sua página de contato para experimentar diretamente o poder dessa ferramenta e avaliar sua capacidade de revolucionar a produção 3D.
Stable 3D, com sua abordagem inovadora, tem o potencial de redefinir a criação de conteúdo 3D. Tornando a geração de objetos 3D mais acessível e automatizada, esta ferramenta sinaliza uma nova fase na criação de conteúdo digital. Sua versatilidade, amplificada pela compatibilidade com os formatos padrão de arquivos 3D, torna-a essencial para profissionais independentes, sejam eles designers, artistas ou desenvolvedores.
A junção de IA com a habilidade de converter texto em modelos 3D pode remodelar áreas como gráficos computacionais, animação, design de games e produção cinematográfica:
Para Gráficos Computacionais e Animação:
- Fluxo Aprimorado: A necessidade de esculpir cada modelo manualmente é reduzida, permitindo aos artistas aprimorar um modelo pré-gerado.
- Prototipagem Acelerada: Ajustes nas instruções textuais permitem uma exploração de design mais ágil.
No Campo de Design de Jogos:
- Produção de Ativos Agilizada: Reduzindo o tempo tradicionalmente gasto na criação de ativos 3D.
- Foco em Qualidade: O design de jogos pode se centrar mais na mecânica e narrativa, elevando a qualidade final.
Na Indústria Cinematográfica:
- Economia: Diminui os custos associados à produção de modelos 3D de alta qualidade.
- Mais Espaço para Inovação: A geração simplificada permite aos cineastas abraçar riscos criativos.
Questões Universais:
- Acesso Ampliado: O processo descomplicado convida uma diversidade maior de participantes para a modelagem 3D.
- Colaboração Interdisciplinar: Profissionais de áreas diversas podem se beneficiar, desde arquitetos até engenheiros.
- Questões de Direitos: A facilidade de criação exige soluções robustas para questões de direitos autorais.
A habilidade de gerar modelos 3D a partir de texto representa uma evolução paralela ao que vimos com a geração de arte AI 2D nos últimos anos. À medida que novas informações emergem sobre essa inovação, continuaremos a compartilhar insights. Para mais informações, o site oficial da Stability AI é um recurso valioso.
Finalmente, enquanto a produção 3D guiada por texto promete eficiência e inovação, desafios como direitos autorais e qualidade precisarão ser abordados, sem esquecer das implicações no mercado de trabalho especializado.