
 cabelo
cabeloVideo interativo em tempo real com uma GPU.

Imagine entrar em um ambiente virtual que não foi completamente desenhado por uma equipe de artistas, programadores e desenvolvedores. Em vez de carregar um mapa pronto, armazenado previamente no computador, o cenário é criado continuamente por uma inteligência artificial enquanto o usuário caminha, dirige um veículo, movimenta um personagem ou altera a direção da câmera. Essa é a proposta do ABot-World-0, um modelo desenvolvido pelo AMAP CV Lab para gerar vídeos interativos condicionados às ações do usuário.
O paper do projeto, intitulado “ABot-World-0: Infinite Interactive World Rollout on a Single Desktop GPU”, foi publicado no arXiv em julho de 2026. O trabalho representa uma mudança importante na evolução dos sistemas de geração de vídeo, pois não se limita à criação de pequenos clipes previamente determinados. O objetivo é produzir um mundo visual que continue sendo gerado conforme o usuário interage com ele, criando uma experiência que se aproxima de um videogame, mas sem depender exclusivamente de cenários, movimentos e animações programados antecipadamente.
Muito além de um gerador tradicional de vídeos
Nos geradores de vídeo convencionais, o usuário escreve uma descrição e aguarda a inteligência artificial produzir uma sequência com alguns segundos de duração. Depois que o vídeo é concluído, não existe uma maneira real de entrar naquela cena, mudar sua direção ou decidir o que acontecerá em seguida. O ABot-World-0 funciona de forma diferente: o usuário envia comandos pelo teclado e o modelo utiliza essas ações para determinar como os próximos quadros devem ser produzidos.
Ao pressionar uma tecla para avançar, virar, recuar ou movimentar a câmera, a inteligência artificial precisa prever como o cenário deve se transformar em resposta àquela ação. Os novos quadros gerados passam a fazer parte do contexto utilizado na próxima etapa da simulação. Dessa forma, o sistema opera em um ciclo contínuo no qual o usuário envia um comando, a IA interpreta a ação, o ambiente responde visualmente e o resultado passa a ser usado como ponto de partida para os próximos movimentos.
O modelo trabalha com oito comandos principais. As teclas W, A, S e D controlam a movimentação, enquanto I, J, K e L controlam a rotação da câmera ou do personagem. Esses comandos são sincronizados com os quadros do vídeo e inseridos diretamente na rede neural. Com isso, o modelo aprende que determinadas ações devem provocar mudanças específicas no ambiente virtual. Nas demonstrações, é possível caminhar por cenários abertos, explorar construções, controlar personagens, dirigir veículos, atravessar terrenos variados e reagir visualmente a obstáculos.
A experiência lembra um jogo eletrônico, mas existe uma diferença fundamental. Em um jogo tradicional, o mapa, os objetos, as animações, a iluminação e as regras de interação foram previamente criados e programados. No ABot-World-0, uma parte considerável do que aparece na tela é prevista e sintetizada pela inteligência artificial durante a própria execução. Em outras palavras, o ambiente não está sendo apenas exibido: ele está sendo continuamente imaginado pelo modelo.
Um mundo virtual executado em uma única GPU
Um dos aspectos mais impressionantes do ABot-World-0 é sua capacidade de funcionar em uma única NVIDIA GeForce RTX 5090, sem depender de um cluster composto por várias GPUs. O sistema consegue gerar vídeos com resolução de 1280 × 704 pixels, alcançando uma taxa de até aproximadamente 16 quadros por segundo. A latência entre o comando do usuário e a geração do primeiro quadro correspondente fica em torno de 1,2 segundo, enquanto o consumo máximo de memória gráfica permanece abaixo de aproximadamente 19,3 GiB de VRAM nas configurações otimizadas apresentadas pelos pesquisadores.
Esses números não significam que o projeto pode ser executado em qualquer computador doméstico. A RTX 5090 é uma placa de vídeo de alto desempenho e representa o segmento mais avançado das GPUs de consumo. Mesmo assim, executar uma simulação generativa desse nível em uma única placa instalada em um computador de mesa é muito diferente de depender de dezenas ou centenas de aceleradores operando em um data center.
O desempenho também varia conforme a precisão numérica utilizada durante a inferência. Na configuração FP8, que procura preservar maior qualidade visual, o sistema alcançou aproximadamente 12,4 FPS. Já na configuração MXFP4, mais comprimida e voltada para maior velocidade, o desempenho chegou a cerca de 15,8 FPS, valor divulgado de forma arredondada como até 16 FPS.
Ainda não estamos falando de uma experiência comparável aos 60, 120 ou 144 quadros por segundo encontrados em jogos modernos. A latência de 1,2 segundo também é perceptível e impede que o sistema seja considerado totalmente instantâneo. Entretanto, o resultado demonstra que a geração interativa de mundos virtuais começa a entrar em uma faixa de desempenho utilizável, especialmente para pesquisa, prototipagem, simulação e experiências visuais experimentais.
Como a inteligência artificial aprende a controlar um mundo
Para ensinar uma inteligência artificial a criar um ambiente interativo, não basta fornecer vídeos visualmente atraentes. O modelo precisa compreender qual ação provocou cada movimento mostrado na gravação. Ele precisa aprender, por exemplo, que pressionar uma tecla para a esquerda deve alterar a trajetória do personagem e modificar a perspectiva do cenário de maneira coerente.
Por isso, o treinamento do ABot-World-0 combina dados provenientes de jogos eletrônicos, ambientes simulados e vídeos reais encontrados na internet. Os jogos fornecem imagens detalhadas acompanhadas de comandos precisos. Nesse contexto, é possível registrar exatamente qual tecla foi pressionada, para onde o personagem se movimentou, como a câmera reagiu e quais mudanças ocorreram no ambiente.
Os simuladores oferecem ainda mais controle sobre elementos como posição da câmera, geometria, horário, clima, iluminação, trânsito, trajetória e movimentação de objetos. Já os vídeos reais da internet acrescentam diversidade de paisagens, condições de iluminação, perspectivas e situações encontradas no mundo físico. Como esses vídeos normalmente não possuem os comandos que deram origem ao movimento da câmera, o sistema precisa estimar o deslocamento e criar rótulos aproximados para as ações observadas.
O projeto também apresenta um agente autônomo chamado WorldExplorer, responsável por percorrer jogos e ambientes simulados automaticamente. Durante esse processo, ele coleta vídeos, posições de câmera, ações, trajetórias, estados do ambiente e outros metadados necessários para o treinamento. Quando os pesquisadores identificam que o modelo apresenta dificuldades em determinado cenário, movimento ou perspectiva, o sistema pode direcionar uma quantidade maior de coleta para aquela situação específica.
Isso cria um ciclo de melhoria contínua. O agente coleta os dados, o modelo é treinado, os erros são analisados e novas amostras são produzidas para corrigir as deficiências encontradas. Em vez de criar um conjunto de treinamento estático, os pesquisadores utilizam o próprio desempenho da inteligência artificial para orientar quais dados precisam ser coletados posteriormente.
Controle de qualidade e preservação dos personagens
Como dados ruins produzem modelos ruins, o material coletado passa por uma sequência de 14 verificações determinísticas, distribuídas em diferentes categorias de qualidade. O pipeline procura quadros ausentes, vídeos corrompidos, resoluções incorretas, falhas de sincronização, telas de carregamento, menus, elementos de interface, problemas de geometria, personagens atravessando objetos, comandos incompatíveis com o movimento, metadados incompletos e cenas visualmente inadequadas.
Além das verificações automáticas, um modelo de visão e linguagem analisa semanticamente os vídeos. Os trechos aprovados recebem informações sobre o tipo de cenário, clima, horário, veículo, perspectiva da câmera, personagem e ações executadas. Essa etapa torna os dados mais organizados e ajuda o modelo a compreender não apenas o movimento, mas também o contexto visual em que ele acontece.
Outro desafio importante é preservar a aparência dos personagens durante sequências prolongadas. Em vídeos longos gerados por inteligência artificial, um personagem pode mudar gradualmente de roupa, rosto, cabelo, proporção ou cor. Para reduzir esse problema, o pipeline extrai imagens de referência dos personagens em diferentes ângulos. Essas imagens ajudam o modelo a manter roupas, rosto, cores e identidade visual de maneira mais consistente, principalmente em cenas na terceira pessoa, nas quais o personagem permanece visível durante grande parte da experiência.
O modelo professor, o modelo aluno e o LongForcing
O treinamento utiliza uma estratégia semelhante à relação entre um professor e um aluno. Inicialmente, os pesquisadores treinam um modelo professor bidirecional, capaz de observar diferentes momentos de uma sequência completa. Como possui acesso a mais informações, esse modelo consegue aprender com maior qualidade a aparência das cenas, os movimentos, a dinâmica dos objetos e as consequências de cada ação.
Entretanto, o modelo professor não é adequado para uma aplicação em tempo real, pois depende de várias etapas de processamento e de uma visão mais ampla da sequência. Seu conhecimento é então transferido para um modelo aluno causal, que precisa trabalhar como o sistema funcionará durante o uso real: observando apenas o que já aconteceu e prevendo o próximo trecho do vídeo.
A transferência de conhecimento ocorre em três etapas. Na primeira, chamada Teacher Forcing, o aluno aprende a produzir os próximos quadros utilizando sequências corretas fornecidas durante o treinamento. Na segunda, conhecida como destilação ODE, o sistema reduz a quantidade de etapas necessárias para transformar o ruído inicial nos próximos quadros, acelerando significativamente a geração. Na terceira etapa entra o LongForcing, uma das principais contribuições apresentadas pelo projeto.
O LongForcing treina o modelo utilizando suas próprias gerações prolongadas. Em vez de trabalhar apenas com sequências perfeitas, o aluno precisa continuar produzindo novos quadros a partir das imagens que ele mesmo criou. O modelo professor analisa essas sequências e ajuda a corrigir os desvios que surgem ao longo do tempo. Essa técnica é essencial porque, em uma simulação contínua, qualquer pequeno erro pode ser reutilizado como contexto e acabar provocando falhas cada vez maiores.
O ABot-World-0 possui aproximadamente 5 bilhões de parâmetros, número relativamente compacto quando comparado a modelos com dezenas ou centenas de bilhões. Isso é particularmente relevante porque o sistema não trabalha apenas com texto. Ele precisa processar simultaneamente vídeo, movimento, ações, contexto temporal, aparência e dinâmica do ambiente. A pesquisa demonstra que modelos extremamente grandes nem sempre são indispensáveis quando a arquitetura, os dados, o treinamento e a inferência são cuidadosamente otimizados.
O desafio de gerar um mundo sem perder qualidade
Em um vídeo convencional de poucos segundos, pequenos erros podem passar despercebidos porque a sequência termina rapidamente. Em um mundo interativo, o problema é muito mais grave. Cada quadro criado pela inteligência artificial é utilizado como contexto para produzir os quadros seguintes. Um pequeno erro pode gerar outro erro maior, que passa a influenciar novas previsões e se acumula progressivamente.
Esse fenômeno é conhecido como drift, ou desvio acumulado. Com o passar do tempo, o personagem pode mudar de aparência, os objetos podem se deformar, os detalhes do cenário podem desaparecer e os movimentos podem se tornar repetitivos. Também podem surgir imagens borradas, cores excessivamente saturadas, texturas artificiais ou quadros praticamente congelados.
O LongForcing foi desenvolvido justamente para reduzir esse problema. Em vez de treinar o modelo apenas com trechos curtos e visualmente perfeitos, os pesquisadores também o expõem às previsões acumuladas que ele produz durante gerações prolongadas. O modelo professor observa essas sequências e ajuda o aluno a retornar para uma distribuição visual mais coerente.
Nos testes de 60 segundos, a técnica apresentou menos borrões, repetição de padrões, saturação excessiva e degradação visual do que outras configurações avaliadas. O artigo também apresenta exemplos retirados de gerações com duração de horas e testes realizados em escala de dias.
A expressão “geração infinita”, entretanto, precisa ser interpretada com cuidado. Ela não significa que o ambiente permanecerá perfeito para sempre nem que a inteligência artificial possuirá memória ilimitada sobre todos os lugares, objetos e acontecimentos. O termo indica que o sistema não possui uma duração fixa obrigatória, como ocorre com vídeos limitados a cinco ou dez segundos. Enquanto houver recursos computacionais e comandos do usuário, o modelo pode continuar produzindo novos quadros, embora inconsistências ainda possam surgir ao longo da experiência.
Otimização completa para caber em uma GPU
O desempenho alcançado pelo ABot-World-0 não depende apenas do modelo de inteligência artificial. Os pesquisadores precisaram otimizar toda a cadeia de execução, incluindo arquitetura, precisão numérica, memória, decodificação e kernels utilizados pela GPU.
Entre as principais tecnologias estão um decodificador de vídeo VAE mais leve, o processamento do Diffusion Transformer em baixa precisão, SageAttention2, uma implementação otimizada de RoPE, gerenciamento avançado de memória, cache KV com tamanho limitado, geração em blocos de quadros, FlashAttention, LightX2V e quantizações em FP8 e MXFP4.
A configuração original não cabia na memória da RTX 5090. O sistema tornou-se viável somente depois da combinação entre quantização, decodificador mais leve, kernels especializados e um gerenciamento mais eficiente da memória. Esse resultado traz uma lição importante para o desenvolvimento de soluções de IA: não basta possuir um bom modelo. Para transformar uma pesquisa em uma aplicação utilizável, é necessário otimizar conjuntamente software, arquitetura, memória e hardware.
Resultados apresentados no WorldRoamBench
O ABot-World-0 foi avaliado no WorldRoamBench, benchmark voltado para modelos de mundos interativos. A avaliação considera a capacidade de responder aos comandos, acompanhar trajetórias, preservar a qualidade visual, reproduzir comportamentos físicos e manter informações ao longo do tempo.
O modelo alcançou 0,5266 de precisão estrita no controle das ações, ficando muito próximo da melhor pontuação apresentada na comparação, que foi de 0,5317. Também obteve 0,7290 em precisão parcial, 0,6752 no acompanhamento de trajetória, 0,5039 em estética, 0,4651 em qualidade de imagem, 0,5223 em mecânica e 0,5041 em memória.
| Métrica | Resultado |
|---|---|
| Precisão estrita das ações | 0,5266 |
| Precisão parcial | 0,7290 |
| Acompanhamento de trajetória | 0,6752 |
| Estética | 0,5039 |
| Qualidade da imagem | 0,4651 |
| Mecânica | 0,5223 |
| Memória | 0,5041 |
Os resultados demonstram um desempenho competitivo, mas não uma vitória em todas as categorias. Outros modelos apresentaram pontuações superiores em determinados critérios, principalmente na retenção de memória. Ainda assim, o ABot-World-0 consegue oferecer resultados relevantes utilizando um modelo relativamente compacto e uma única GPU de desktop.
Os exemplos divulgados pelos pesquisadores incluem veículos colidindo com objetos, personagens deixando marcas na neve, movimentos criando rastros na água e obstáculos impedindo a passagem. Isso não significa, entretanto, que o modelo possua um mecanismo tradicional de física.
O ABot-World-0 não foi programado com regras matemáticas explícitas de colisão, gravidade ou dinâmica. Ele aprendeu esses comportamentos observando grandes quantidades de vídeos e ambientes interativos. As respostas físicas podem parecer plausíveis, mas não devem ser tratadas como uma simulação científica exata. O modelo apenas prevê visualmente o que provavelmente deveria acontecer com base nos exemplos vistos durante o treinamento.
Código aberto e possíveis aplicações
O código de inferência, a demonstração local com Gradio e o modelo causal ABot-World-0-5B-LF foram disponibilizados publicamente. O projeto utiliza a licença Apache 2.0, e os pesos podem ser encontrados em plataformas como Hugging Face e ModelScope.
O ambiente oficialmente testado utiliza Ubuntu 22.04, Python 3.12, CUDA 12.8, PyTorch 2.8, NVIDIA RTX 5090, FlashAttention, SageAttention e LightX2V. A instalação ainda exige a compilação de componentes especializados e não é tão simples quanto instalar um programa convencional. O modelo professor bidirecional e o conjunto completo de aproximadamente 500 horas de vídeos acompanhados de ações anotadas aparecem no planejamento do projeto, mas ainda não estavam totalmente disponibilizados na publicação inicial.
Tecnologias como o ABot-World-0 podem transformar diferentes setores. Na indústria de jogos, desenvolvedores poderão criar protótipos de ambientes que se expandem durante a exploração, reduzindo o tempo necessário para testar conceitos visuais, cenários e mecânicas. Na robótica, agentes autônomos poderão ser treinados em ambientes virtuais antes de serem testados no mundo real. Na realidade virtual, cada usuário poderá explorar espaços personalizados e potencialmente diferentes a cada sessão.
Na educação, estudantes poderão visitar reconstruções interativas de cidades antigas, ecossistemas, laboratórios e acontecimentos históricos. Na produção audiovisual, diretores e artistas poderão navegar por conceitos visuais antes de transformar uma ideia em uma cena tradicional. Também existem possíveis aplicações em direção autônoma, treinamento industrial, planejamento urbano e criação de grandes volumes de dados sintéticos para o treinamento de outros sistemas de inteligência artificial.
Ainda é uma tecnologia experimental
Apesar dos resultados impressionantes, o ABot-World-0 ainda deve ser entendido como um projeto de pesquisa. A experiência depende de uma RTX 5090, apresenta uma latência perceptível e não alcança a taxa de quadros típica dos jogos modernos. O sistema também pode produzir inconsistências, esquecer detalhes antigos, interpretar ações incorretamente, deformar objetos, alterar a aparência dos personagens ou gerar comportamentos fisicamente impossíveis.
O documento publicado no arXiv é um preprint, ou seja, um artigo disponibilizado antes de uma revisão científica mais ampla. Os resultados foram apresentados pelos próprios pesquisadores e ainda precisam ser reproduzidos de maneira independente pela comunidade.
O projeto demonstra uma direção tecnológica promissora, mas ainda não elimina a necessidade de motores gráficos, geometria 3D, física programada, lógica criada por desenvolvedores e validação humana. No futuro, é provável que modelos generativos sejam combinados com essas tecnologias tradicionais, e não simplesmente utilizados para substituí-las.
O futuro dos mundos gerados por inteligência artificial
O ABot-World-0 mostra que a geração de vídeo está deixando de ser apenas uma ferramenta para produzir pequenos clipes. A próxima etapa pode ser a criação de ambientes que respondem, mudam e continuam existindo enquanto são explorados.
Seu principal avanço não está apenas na qualidade visual, mas na combinação entre controle por ações, geração prolongada, preservação de personagens, redução do desvio acumulado, otimização de memória e execução em uma única GPU.
Ainda estamos longe de substituir completamente os motores gráficos convencionais. Porém, o projeto oferece uma demonstração concreta de como poderão funcionar os jogos, simuladores e ambientes virtuais do futuro. Em vez de mundos totalmente armazenados em arquivos e previamente construídos, poderemos explorar ambientes que são imaginados e renderizados pela inteligência artificial em tempo real.
Vídeo e links do projeto
Abaixo um vídeos demonstrativo e links com fontes, paper e informatização técnicas.
Código-fonte no GitHub:
https://github.com/amap-cvlab/ABot-World
Página oficial do projeto:
https://amap-cvlab.github.io/ABot-World/
Artigo científico no arXiv:
https://arxiv.org/abs/2607.19191
A ilusão dos benchmarks: KPIs tradicionais não fazem sentido para medir LLMs
Vivemos uma corrida pela superioridade em Inteligência Artificial. A cada novo lançamento, modelos como GPT, Claude, Gemini, Llama e tantos outros são apresentados com gráficos impressionantes, rankings, percentuais e benchmarks que prometem provar qual sistema é “melhor”. Mas existe um problema central nessa lógica: LLMs não são softwares tradicionais.

Um sistema tradicional pode ser medido por métricas relativamente objetivas: tempo de resposta, disponibilidade, consumo de CPU, número de requisições por segundo, taxa de erro, custo por operação. Esses indicadores fazem sentido porque o comportamento esperado do software é mais estável, previsível e repetível.
Com LLMs, a realidade é diferente.
Uma IA generativa reconhece padrões, interpreta contexto, produz linguagem, raciocina de forma probabilística e pode errar mesmo quando parece confiante. O mesmo modelo pode responder muito bem a uma pergunta e falhar em outra aparentemente simples. Pode acertar um benchmark acadêmico e se perder em uma tarefa real de negócio. Pode gerar uma resposta tecnicamente correta, mas inútil para o usuário. Pode obedecer ao formato esperado, mas tomar uma decisão ruim.
Por isso, aplicar KPIs tradicionais e benchmarks como medida absoluta de qualidade em LLMs é perigoso.
Benchmarks são úteis como ponto de partida. Eles criam uma linguagem comum para comparar modelos em tarefas específicas. O problema começa quando passamos a tratar essas pontuações como sinônimo de inteligência, confiabilidade ou utilidade no mundo real.
Um modelo que alcança 82% em um benchmark não necessariamente terá 82% de qualidade na operação da sua empresa. Um modelo que vence em matemática pode não ser o melhor para atendimento ao cliente. Um modelo excelente em programação pode não ser o mais seguro para lidar com dados sensíveis. Um modelo rápido pode ser superficial. Um modelo barato pode sair caro quando erra.
Além disso, muitos benchmarks carregam um risco invisível: parte dos dados usados nos testes pode ter aparecido durante o treinamento dos modelos. Nesse caso, o resultado deixa de medir compreensão real e passa a medir memorização. O modelo não está necessariamente resolvendo um problema novo; ele pode estar apenas reproduzindo padrões que já viu antes.
Outro ponto ignorado em muitos comparativos é que nem todo benchmark com o mesmo nome mede a mesma coisa. Uma empresa pode divulgar que seu modelo fez uma pontuação alta em uma variante mais controlada de um teste, enquanto outra divulga resultado em uma versão mais difícil, com problemas reais, múltiplos arquivos e maior complexidade. Os números parecem comparáveis, mas não são.
É aí que o benchmark deixa de ser instrumento técnico e passa a ser ferramenta de marketing.
Cada fabricante tende a divulgar a métrica em que vence. Você dificilmente verá uma página oficial destacando onde o concorrente é superior. A consequência é previsível: o mercado passa a comparar números sem entender o contexto, a dificuldade, a metodologia ou a aplicação real daquele teste.
Esse é exatamente o ponto explicado pelo Teorema do Cabelo:
Teorema do Cabelo para LLMs:
Quando a realidade é comparada com uma medida, essa realidade é involuntariamente distorcida, manipulada e otimizada.
LLMs são estocásticos e não determinísticos. Nunca veremos na página de um fabricante de IAs que seu concorrente é melhor em algo.
No caso dos LLMs, quando uma métrica passa a definir o que é “melhor”, os modelos, os produtos e as empresas começam a ser otimizados para vencer essa métrica. Não necessariamente para resolver melhor problemas reais.
Quando uma métrica observa a realidade, ela pode ajudar.
Quando uma métrica governa a realidade, ela distorce.
Se uma empresa mede um agente de IA apenas por velocidade, pode acabar criando um agente rápido, barato e inútil.
Se mede apenas taxa de conclusão, o agente pode concluir tarefas erradas apenas para marcar o processo como finalizado.
Se mede apenas custo por chamada, pode escolher um modelo barato que exige retrabalho humano, aumenta risco operacional e reduz a qualidade final.
Se mede apenas conformidade de formato, pode receber um JSON perfeito contendo uma decisão ruim, uma análise fraca ou até um vazamento de dados.
O problema, portanto, não está em medir. O problema está em confundir a medida com a realidade.
Benchmarks e KPIs podem ser úteis como sinais muitos pequenos e parciais. Eles ajudam a observar aspectos específicos de um modelo: raciocínio matemático, geração de código, compreensão textual, aderência a instruções, velocidade, custo ou taxa de erro. Mas nenhum deles, isoladamente, representa a qualidade real de uma LLM em produção.
A pergunta correta não é: “Qual modelo tem o maior benchmark?”
A pergunta correta é: “Qual modelo resolve melhor o meu problema, no meu contexto, com os meus dados, meus riscos, meus usuários e meus critérios de qualidade?”
LLMs devem ser avaliadas por contexto, não por vaidade numérica.
Devem ser testadas em cenários reais, com dados reais, usuários reais, exceções reais e consequências reais. A avaliação precisa considerar qualidade da resposta, segurança, robustez, custo total, governança, privacidade, explicabilidade, consistência, aderência ao negócio e capacidade de lidar com erro.
Porque no mundo real, o objetivo não é vencer um ranking.
O objetivo é gerar valor.
O Teorema do Cabelo nos lembra que toda métrica é apenas uma sombra da realidade. Quando usamos a sombra para entender o objeto, ela pode ser útil. Mas quando passamos a perseguir a sombra como se ela fosse o objeto, perdemos a realidade.
É exatamente isso que acontece quando tratamos benchmarks de LLMs como verdade absoluta.
A IA não deve ser otimizada apenas para parecer inteligente em testes padronizados. Ela precisa ser útil, segura, confiável e alinhada ao propósito humano.
Benchmarks medem desempenho em provas.
O mundo real mede consequência.
E entre uma prova bem respondida e uma decisão correta em produção existe uma distância enorme.
Por isso, KPIs e benchmarks tradicionais não bastam para avaliar LLMs. Eles podem indicar caminhos, mas não podem governar decisões. Quando governam, distorcem. Quando viram objetivo, manipulam. Quando viram marketing, escondem a realidade.
Essa é a síntese do Teorema do Cabelo aplicado à Inteligência Artificial:
Toda métrica que tenta representar a realidade corre o risco de alterar a própria realidade que pretende medir.
E, em LLMs, esse risco não é detalhe técnico. É o centro do problema.
Para finalizar, não estou sozinho na linha de raciocínio, o SUPER Diego Nogare Consultor Executivo de IA & ML escreveu este texto complementar ao meu pensamento.
O texto fala sobre vivemos um dilúvio de relatórios sobre Inteligência Artificial. E muitos deles parecem dizer verdades diferentes. Enquanto alguns apontam adoção massiva e avanço acelerado rumo à AGI, outros mostram que a maturidade real das empresas ainda é baixa, com poucas organizações capazes de transformar IA em valor estratégico. A confusão nasce de metodologias, métricas e objetivos distintos: uso não é maturidade, hype não é estratégia e benchmark não é realidade. No fim, o desafio dos líderes não é descobrir qual relatório está certo, mas construir uma bússola própria para navegar nessa tempestade de informações e decidir qual verdade faz sentido para a sua organização.
Leia o texto na íntegra: https://diegonogare.net/2025/11/com-tantos-relatorios-de-ia-qual-verdade-voce-quer/
OpenCV 5.0.0: a maior evolução do OpenCV em anos

O OpenCV 5.0.0 foi lançado oficialmente em junho de 2026 e representa uma das mudanças mais importantes da biblioteca desde a consolidação do OpenCV 2.x e 4.x. Não se trata apenas de uma atualização incremental: a versão 5 reorganiza módulos, remove APIs antigas, moderniza a base de código, melhora o suporte a IA, amplia o suporte a ONNX, introduz novos tipos de dados e prepara a biblioteca para uma computação visual mais heterogênea, envolvendo CPU, GPU, aceleradores e novos backends de hardware. O release oficial do GitHub marca o OpenCV 5.0.0 como a versão mais recente e aponta para o resumo oficial e o guia de migração 4.x → 5.x
O que muda na visão geral
O OpenCV passa a manter duas linhas ativas: a ramificação 4.x, ainda estável, e a nova 5.x, também estável, onde a maior parte das funcionalidades mais recentes será concentrada. A versão 5.0 aproveita partes consolidadas do OpenCV 4.x, adiciona novos recursos, remove componentes obsoletos e introduz algumas mudanças de API, principalmente para limpar dívida técnica acumulada ao longo dos anos.
Na prática, o OpenCV 5.0.0 mira três frentes: modernização da base de código, melhor suporte a IA e melhor preparação para aceleração em diferentes arquiteturas. Isso é especialmente importante para aplicações atuais de visão computacional, robótica, edge AI, sistemas embarcados, inspeção industrial, biometria, vídeo analytics, veículos autônomos e pipelines que combinam visão clássica com deep learning.
Novos requisitos: C++17 e fim do Python 2
Uma das primeiras mudanças é o requisito mínimo de C++17. O OpenCV 5.0 é compilado por padrão com C++17 e deve ser compatível com padrões mais novos. Para quem mantém projetos C++, isso significa revisar toolchains, CMake, compiladores e pipelines de build. O guia oficial de migração recomenda configurar o projeto para C++17 e informa versões mínimas como GCC 8, Clang 9 e MSVC 2017 19.14 ou superior.
O suporte ao Python 2 foi removido. A partir do OpenCV 5.0, é necessário usar Python 3.6 ou superior, e apenas bindings para Python 3 são construídos e distribuídos. Para projetos modernos isso dificilmente será um problema, mas ambientes legados precisarão ser atualizados.
Limpeza pesada: adeus API C legada
O OpenCV 5 removeu a antiga API C do OpenCV 1.x. Funções como cvCreateMat() e cvFindContours(), além de estruturas como CvMat e IplImage, foram retiradas. Alguns macros como CV_8U e CV_32F continuam existindo, mas o caminho oficial agora é a API C++.
Essa decisão é simbólica e técnica. Simbólica porque fecha definitivamente a era do OpenCV 1.x. Técnica porque reduz complexidade, facilita manutenção e permite que a biblioteca avance com modelos de dados e APIs mais modernas. O guia de migração observa que a maior parte do código de produção da última década já não usa diretamente a API C, mas projetos legados precisarão migrar para C++.
OpenVX removido e caminho para uma HAL não CPU
O suporte a OpenVX foi removido da árvore principal. A justificativa é que o OpenCV está caminhando para uma nova camada de abstração de hardware, uma HAL não CPU, que poderá permitir a integração de acelerações específicas de fornecedores sem amarrar a biblioteca a uma única API externa.
Essa mudança é importante para o futuro do OpenCV em ambientes heterogêneos. Em vez de tentar manter integrações antigas e específicas, a biblioteca passa a caminhar para um modelo em que diferentes fornecedores podem plugar acelerações por baixo, mantendo uma interface mais consistente para o desenvolvedor.
G-API e ML clássico foram para o opencv_contrib
O módulo Graph API, conhecido como G-API, foi movido para opencv_contrib. O mesmo aconteceu com o módulo clássico de machine learning, ml. Quem ainda depende de cv::ml::SVM, cv::ml::RTrees ou da G-API precisará compilar o OpenCV com os módulos extras do opencv_contrib.
Para usuários Python, a recomendação oficial é considerar alternativas como scikit-learn para algoritmos clássicos de machine learning. O guia de migração também reforça que cv2.ml.* só estará disponível se o OpenCV for construído com opencv_contrib.
Features2D virou Features
O antigo módulo features2d foi renomeado para features. A mudança reflete uma ampliação de escopo: o módulo deixa de tratar apenas detectores e descritores clássicos 2D e passa a lidar também com vetores de características produzidos por redes neurais modernas.
Detectores clássicos importantes como SIFT, ORB, FAST, GoodFeaturesToTrack e MSER continuam no repositório principal. Já alguns descritores e detectores obsoletos foram movidos para opencv_contrib. O OpenCV 5 também adiciona recursos de características locais baseados em deep learning, incluindo ALIKED e DISK, além do matcher LightGlue.
Outra mudança relevante é a substituição prática do FLANN por busca aproximada de vizinhos mais próxima baseada em Annoy dentro do módulo features. Isso moderniza a forma como o OpenCV lida com busca ANN, especialmente em cenários envolvendo embeddings e vetores de características.
Objdetect foi limpo: Haar e HOG foram para contrib
O módulo objdetect também passou por limpeza. Detectores baseados em Haar e HOG foram movidos para opencv_contrib, no módulo xobjdetect. A explicação é direta: detectores modernos baseados em deep learning tendem a ser mais rápidos e mais precisos.
Para novos projetos, isso sinaliza uma mudança de paradigma. O OpenCV continua preservando compatibilidade via contrib para quem precisa de Haar Cascade ou HOG, mas incentiva o uso de detectores modernos, como modelos DNN para detecção facial e objetos. O guia de migração cita, por exemplo, o uso do FaceDetectorYN baseado em DNN.
Calib3d foi dividido em módulos especializados
O antigo e grande módulo calib3d foi dividido em quatro módulos: geometry, calib, stereo e ptcloud. O módulo geometry concentra algoritmos clássicos de geometria 2D, 3D e nD; calib fica com calibração de câmera; stereo cuida de estimativa de profundidade por correspondência estéreo; e ptcloud reúne algoritmos de alto nível para dados 3D, como odometria visual e TSDF.
Para C++, o cabeçalho legado opencv2/calib3d.hpp continua funcionando como uma camada de compatibilidade, incluindo os novos cabeçalhos por baixo. Para novos projetos, porém, a recomendação é incluir apenas o módulo necessário, como opencv2/geometry.hpp, opencv2/calib.hpp ou opencv2/stereo.hpp. Em Python, a mudança é transparente: as funções continuam acessíveis por cv2.
Novos tipos de dados no Core
O módulo Core recebeu novos tipos de dados. Além dos tipos já conhecidos, como CV_8U, CV_16U, CV_32F, CV_64F e CV_16F, o OpenCV 5 introduz CV_16BF para bfloat16, CV_32U para uint32_t, CV_64U para uint64_t, CV_64S para int64_t e CV_Bool para booleanos armazenados em 1 byte.
Essa mudança aproxima o OpenCV das necessidades modernas de IA. Tipos como FP16 e BF16 são fundamentais em deep learning, inferência otimizada, aceleradores e pipelines que buscam reduzir consumo de memória. O OpenCV também informa que operações básicas com hfloat e bfloat estão disponíveis mesmo em hardware sem suporte nativo, usando conversões internas eficientes.
O tipo CV_Bool também é importante porque matrizes booleanas agora podem ser usadas como máscaras onde antes se usavam máscaras uchar ou schar. Isso melhora a semântica do código e deixa mais clara a intenção do desenvolvedor.
Matrizes 1D e 0D de verdade
O OpenCV 5 passa a suportar arrays com menos de duas dimensões. Um std::vector<T> encapsulado em Mat, InputArray ou OutputArray agora é tratado como um array 1D real, e não mais como uma matriz 2D Nx1 ou 1xN, como acontecia no OpenCV 4.x.
Essa mudança pode afetar códigos que verificam diretamente .rows ou .cols. O guia de migração recomenda usar .total() para obter o número de elementos quando o código precisar funcionar de forma compatível. Para distinguir uma matriz vazia de um escalar 0D, a recomendação é usar mat.empty().
MatShape substitui MatSize
O OpenCV 5 introduz MatShape como substituto de MatSize. A nova estrutura carrega informações de forma e layout dos dados, é embutida diretamente em Mat, UMat e GpuMat e evita alocações dinâmicas extras. Ela também é usada extensivamente pelo módulo DNN para inferência de formas.
Para compatibilidade, MatSize continua disponível como alias, mas novos códigos devem preferir MatShape. Essa mudança é especialmente relevante para modelos de IA, tensores e operações multidimensionais.
LAPACK sempre disponível
O OpenCV 5 passa a ter LAPACK sempre disponível internamente. Isso melhora operações como SVD, decomposição de autovalores/autovetores e componentes do framework USAC. Quando não houver uma biblioteca LAPACK externa instalada, o OpenCV constrói e usa um subconjunto interno mínimo.
Imgproc: mais desempenho, mais precisão e melhor texto
O módulo imgproc recebeu mudanças importantes. Algoritmos de geometria computacional, como convex hull, triangulação de Delaunay e funções relacionadas, foram movidos para o módulo geometry. Em C++, pode ser necessário adicionar opencv2/geometry.hpp; em Python, as funções continuam disponíveis por cv2.
As funções warpAffine, warpPerspective e remap foram substancialmente revisadas. A interpolação bilinear e bicúbica deixou de usar aproximações baseadas em tabelas, resultando em maior precisão e melhor desempenho. Segundo o resumo oficial, os ganhos de velocidade variam de 10% a mais de 300%, dependendo da plataforma, tamanho da imagem, tipo de dado e flags de operação.
O redimensionamento por vizinho mais próximo agora segue o algoritmo do Pillow, tornando os resultados compatíveis com ele. Isso é útil para pipelines que misturam OpenCV e Pillow, mas pode exigir atualização de testes pixel-a-pixel baseados em saídas antigas do OpenCV 4.x.
A renderização de texto foi modernizada. O OpenCV 5 substitui o mecanismo antigo por um renderizador TrueType baseado em STB, com a fonte variável Rubik embutida. Usuários também podem carregar fontes customizadas. Isso amplia o suporte a Unicode, embora ainda existam limitações para scripts que exigem shaping complexo, como árabe e devanágari, e para emojis coloridos.
Também foi adicionado o algoritmo TRUCO, sigla para “Threaded Raster Unrestricted Contour Ownership”, usado para acelerar a extração de contornos. O cv::findContours() passa a usar TRUCO automaticamente quando possível, e o novo algoritmo é descrito como várias vezes mais rápido que a implementação anterior.
DNN: o módulo mais transformado do OpenCV 5
A maior mudança do OpenCV 5 está no módulo DNN. Ele recebeu um novo motor de inferência, que passa a coexistir com o motor clássico. Esse novo motor oferece suporte muito melhor a shapes dinâmicos, subgrafos e recursos modernos do ONNX. A cobertura da especificação ONNX passa de menos de 23% no OpenCV 4.x para mais de 80% no OpenCV 5.

A função cv::dnn::readNet() e variantes como readNetFromONNX() passam a aceitar o parâmetro engine = ENGINE_AUTO. Por padrão, o OpenCV tenta usar o novo motor e, se não conseguir carregar o modelo, faz fallback automático para o motor clássico. Também é possível controlar o motor por variável de ambiente: 1 para clássico, 2 para novo motor, 3 para automático e 4 para ONNX Runtime.
O OpenCV 5 também pode ser construído com ONNX Runtime integrado. Nesse modo, o OpenCV usa seu próprio parser ONNX para construir o grafo ORT internamente, evitando depender do pacote ONNX completo e reduzindo o tamanho binário. Para GPU NVIDIA via ORT, a build deve ser feita com as opções correspondentes de ONNX Runtime GPU.
Um ponto de atenção: o novo motor DNN roda atualmente apenas em CPU. O suporte a GPU para esse novo motor será adicionado em versões futuras. Enquanto isso, quem precisa de GPU deve forçar o motor clássico ou compilar com ONNX Runtime e execution providers da NVIDIA.
Fim dos parsers Darknet e Caffe
Os parsers Darknet e Caffe foram removidos. Isso afeta funções como readNetFromDarknet() e readNetFromCaffe(). A recomendação oficial é converter modelos para ONNX e carregá-los com readNetFromONNX(). Modelos TFLite continuam funcionando via motor clássico, com migração para o novo motor planejada.
Essa mudança acompanha o mercado. ONNX se consolidou como formato comum para interoperabilidade entre frameworks, enquanto Darknet e Caffe ficaram mais associados a modelos e pipelines legados.
Suporte a VLMs: visão e linguagem dentro do OpenCV
O novo motor DNN inclui suporte para modelos visão-linguagem, ou VLMs. O OpenCV 5 passa a incluir componentes necessários como tokenizers, camadas de atenção, blocos de decodificação, pós-processamento e KV-cache para executar VLMs de ponta a ponta.
Isso é uma mudança conceitual forte. Historicamente, o OpenCV era visto como uma biblioteca de visão computacional clássica, com suporte crescente a deep learning. Agora ele começa a entrar no território de modelos multimodais, capazes de combinar imagem e texto.
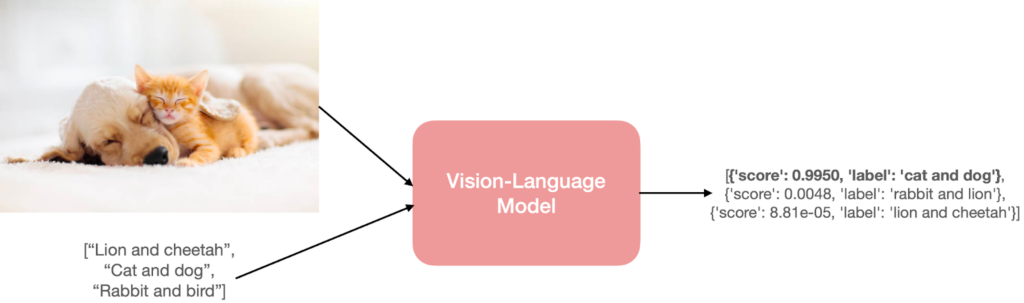
Desempenho do novo DNN
O resumo oficial informa que o novo motor entrega desempenho competitivo em CPU, igualando ou superando o ONNX Runtime em vários modelos. Os benchmarks apresentados comparam tempos de inferência em milissegundos em diferentes plataformas, incluindo Intel i9, Intel i7, Apple M1, Apple M5 e AMD, com modelos como MobileNetv2, ResNet-50, YOLOv8, ViT e SAM2 Encoder.
Os números variam conforme modelo e hardware. Em alguns casos, o ONNX Runtime ainda é mais rápido; em outros, o OpenCV 5 aparece à frente. O ponto central é que o OpenCV deixa de ser apenas uma alternativa simples de inferência e passa a competir mais diretamente com runtimes especializados em workloads de IA.
Modelos migrados para o Hugging Face
A coleção de modelos pequenos e eficientes do OpenCV foi migrada para o Hugging Face. Todos os modelos usam ONNX e devem ser compatíveis com outros frameworks de inferência.
Isso facilita download, reuso, versionamento e integração com ecossistemas modernos de IA. Para quem trabalha com demonstrações, protótipos, pipelines educacionais ou validação rápida de modelos, essa mudança é bastante prática.
Novo módulo Geometry e calibração multicâmera
A reorganização de geometria e calibração é uma das grandes melhorias estruturais do OpenCV 5. O framework USAC passa a ser o backend padrão para algoritmos de estimação robusta, incluindo homografia, matriz essencial, matriz fundamental, solvePnP e outros. Em comparação com o RANSAC clássico, o USAC combina estratégias modernas como PROSAC, NAPSAC, Progressive-NAPSAC, MSAC, MAGSAC++, LMeds, LO-RANSAC, GC-RANSAC e verificação SPRT.
Também foi adicionado um pipeline de calibração multicâmera ao módulo calib. Ele calibra N câmeras simultaneamente em três estágios: intrínsecos por câmera, extrínsecos par-a-par e otimização global final. O pipeline suporta modelos pinhole e fisheye, inclusive rigs mistos.
O pipeline aceita padrões checkerboard, ChArUco e circle grid. Ele também lida com observações parciais, quando nem todas as câmeras enxergam o padrão completo em todos os frames. Isso é essencial para rigs reais, nos quais o campo de visão entre câmeras pode não se sobrepor perfeitamente.
Processamento 3D: malhas, nuvens de pontos, TSDF e ICP
O OpenCV 5 adiciona suporte inicial a algoritmos de malha e nuvem de pontos, incluindo TSDF e ICP. Também foram adicionados importadores e exportadores para formatos populares como .ply e .obj.
Isso aproxima o OpenCV de aplicações de robótica, reconstrução 3D, sensores de profundidade, visão estéreo, SLAM, inspeção volumétrica e percepção espacial. Ainda é um suporte inicial, mas indica uma direção clara para o ciclo 5.x.
Samples revisados e exemplos de IA generativa
Muitos samples foram revisados, exemplos obsoletos foram removidos e novos exemplos foram adicionados. Os samples de deep learning agora usam uma coleção compartilhada de modelos, que pode ser baixada pelo script download_models.py dentro de samples/dnn.
Também foram adicionados samples experimentais para VLMs e modelos de difusão latente, LDM. Isso mostra que o OpenCV está se posicionando não apenas para visão clássica e deep learning discriminativo, mas também para fluxos mais modernos de IA multimodal e generativa.
Documentação modernizada
A documentação do OpenCV 5 foi modernizada com tema responsivo, navegação lateral persistente, índice “on this page”, busca instantânea com Ctrl+K, modo claro/escuro e melhor renderização matemática.
Essa melhoria parece secundária, mas é importante para adoção. OpenCV é usado por estudantes, pesquisadores, empresas e engenheiros de produto. Uma documentação mais navegável reduz barreiras de entrada e acelera migrações.
Mudanças importantes para migração
A migração do OpenCV 4.x para 5.x tende a exigir ajustes pequenos na maioria dos projetos, mas alguns pontos merecem atenção. O guia oficial lista como áreas afetadas: requisitos de build, remoção da API C, reestruturação de módulos, mudanças no Core, novo motor DNN, alterações de comportamento no imgproc, mudanças em Video I/O e detalhes dos bindings Python.
Projetos C++ devem revisar includes, especialmente em calib3d, features2d, imgproc, ml, gapi, Haar/HOG e geometria computacional. Projetos Java precisarão atualizar imports em alguns casos. Em Python, boa parte da reestruturação é transparente, pois as funções continuam acessíveis em cv2, mas cv2.ml.*, Haar e HOG dependem de build com opencv_contrib.
No DNN, modelos ONNX continuam sendo carregados de forma parecida, mas Caffe e Darknet devem ser convertidos para ONNX. Quem depende de GPU deve observar que o novo motor é CPU-only por enquanto, sendo necessário usar o motor clássico ou ONNX Runtime com provider NVIDIA.
No imgproc, pipelines com testes pixel-a-pixel podem precisar atualizar baselines. O resize por vizinho mais próximo agora segue o comportamento do Pillow, e warpAffine, warpPerspective e remap podem gerar pequenas diferenças numéricas por usarem interpolação mais precisa.
No módulo Video I/O, VideoCapture::get() passa a retornar -1 para propriedades não suportadas. No OpenCV 4.x, retornava 0, o que era ambíguo porque 0 também pode ser um valor válido para algumas propriedades. A recomendação é testar valores menores que zero para detectar propriedades não suportadas.
Atenção para Android e páginas de 16 KB
O release oficial traz uma observação específica para Android: o SDK Android original do OpenCV 5.0.0 foi construído com NDK antigo e inclui biblioteca C++ padrão sem alinhamento adequado para dispositivos com páginas de 16 KB. Para publicações no Google Play, a recomendação é usar o pacote com sufixo 16kb-page-fix.
Essa observação é importante para desenvolvedores Android, especialmente considerando exigências recentes de compatibilidade em dispositivos e versões novas do sistema.
O impacto prático do OpenCV 5.0.0
Para quem usa OpenCV apenas para carregar imagem, redimensionar, converter cor e salvar vídeo, a migração provavelmente será simples. Mas mesmo nesses casos há ganhos potenciais de desempenho e mudanças de comportamento em resize, warp e renderização de texto.
Para quem usa OpenCV com IA, a mudança é muito maior. O novo DNN, a maior cobertura ONNX, o suporte a VLMs, os novos tipos BF16/FP16 e a integração com ONNX Runtime colocam o OpenCV em uma posição mais competitiva como runtime de inferência em CPU e como ferramenta de prototipação multimodal.
Para robótica, visão 3D e calibração, a divisão de calib3d, o novo pipeline multicâmera, o USAC como backend padrão e o suporte inicial a nuvens de pontos e malhas tornam o OpenCV 5 mais organizado e mais alinhado com aplicações modernas de percepção.
Para sistemas embarcados e edge AI, a direção é clara: o OpenCV quer ser uma camada de visão computacional portátil, capaz de aproveitar acelerações específicas sem obrigar o desenvolvedor a reescrever a aplicação para cada hardware.
Conclusão
O OpenCV 5.0.0 não é apenas uma nova versão; é uma mudança de geração. Ele remove o passado legado da API C, reorganiza módulos, moderniza tipos de dados, melhora processamento de imagem, amplia fortemente o DNN, melhora suporte a ONNX, abre caminho para VLMs, fortalece visão 3D e prepara a biblioteca para um futuro heterogêneo.
A versão também exige cuidado na migração. Projetos que usam Caffe, Darknet, API C antiga, Haar/HOG, cv2.ml.*, G-API, comparações pixel-a-pixel ou GPU via DNN precisam testar com atenção. Mas o ganho é claro: uma biblioteca mais limpa, moderna, pronta para IA e mais adequada ao cenário atual de visão computacional.
O OpenCV 5.0.0 marca a transição do OpenCV de uma biblioteca clássica de visão computacional para uma plataforma moderna de visão, IA, geometria, inferência e percepção multimodal.
Brain2Qwerty: digitando com o cérebro
A interface entre cérebro e máquina sempre pareceu pertencer ao futuro distante. Durante décadas, a ideia de uma pessoa conseguir se comunicar apenas por meio da atividade cerebral foi tratada como ficção científica ou como uma tecnologia limitada a laboratórios altamente especializados. O projeto Brain2Qwerty, da Meta AI Research, mostra que esse futuro está ficando mais concreto.

O Brain2Qwerty é uma pesquisa de interface cérebro-computador não invasiva capaz de decodificar sentenças digitadas a partir de sinais cerebrais. Em vez de exigir implantes cirúrgicos no cérebro, o projeto utiliza registros de atividade cerebral capturados por tecnologias como MEG, magnetoencefalografia, e EEG, eletroencefalografia. A proposta é ambiciosa: aproximar a IA de um cenário em que pessoas que perderam a capacidade de falar ou se mover possam voltar a se comunicar sem precisar passar por cirurgia cerebral.
A versão mais recente, chamada Brain2Qwerty v2, representa um avanço importante em relação à primeira versão. O Brain2Qwerty v1 já conseguia prever teclas a partir de padrões de atividade cerebral registrados por MEG, mas dependia do tempo exato de cada tecla pressionada, o que limitava seu uso em tempo real. A versão v2 supera essa limitação ao gerar sentenças diretamente a partir de gravações contínuas da atividade cerebral.
Na prática, o sistema combina módulos hierárquicos para interpretar diferentes níveis da linguagem: letras, palavras e sentenças. O pipeline usa redes neurais profundas para transformar sinais cerebrais ruidosos em texto coerente, explorando também o contexto linguístico com modelos de linguagem. Esse ponto é essencial, porque o cérebro não gera um sinal “limpo” como um teclado tradicional; a IA precisa inferir padrões, corrigir ambiguidades e reconstruir o significado provável da frase.
Os resultados chamam atenção. Segundo a Meta, o Brain2Qwerty v2 foi treinado com aproximadamente 22 mil sentenças de nove voluntários, cada um gravado por cerca de 10 horas usando um equipamento de MEG enquanto digitava. O modelo alcançou 61% de acurácia média por palavra e chegou a 78% no melhor participante. Mais de metade das sentenças do melhor caso foram decodificadas com no máximo um erro de palavra.
Esse avanço precisa ser entendido com equilíbrio. Não estamos falando ainda de uma tecnologia pronta para uso doméstico ou clínico amplo. O próprio projeto reconhece dois grandes desafios: a precisão ainda não é suficiente para comunicação cotidiana confiável, e o equipamento de MEG usado nos testes é grande, caro e inacessível para a maioria dos pacientes. Ainda assim, a pesquisa mostra uma tendência promissora: quanto mais dados são usados no treinamento, melhor fica o desempenho do decodificador, sem que tenha sido observado um platô claro de evolução até o momento.
O artigo publicado na Nature Neuroscience sobre o Brain2Qwerty v1 já indicava o potencial da abordagem. Naquele estudo, os pesquisadores demonstraram a decodificação de sentenças digitadas a partir de EEG e MEG em voluntários saudáveis. O desempenho com MEG foi muito superior ao EEG, com taxa média de erro de caracteres de 29% contra 65% no EEG, chegando a 18% de erro nos melhores participantes usando MEG.
A grande mudança da v2 está na aproximação com uma interface mais contínua e natural. Em vez de depender de marcações explícitas de cada tecla, o sistema tenta compreender a produção da frase diretamente a partir do fluxo da atividade cerebral. Isso coloca o Brain2Qwerty em uma categoria muito relevante para o futuro das neuropróteses: sistemas menos invasivos, mais escaláveis e potencialmente mais seguros.
Outro ponto importante é a abertura científica. O repositório oficial no GitHub disponibiliza código para as versões v1 e v2, com licença CC BY-NC 4.0, ou seja, com restrição para uso não comercial. O dataset da v1, coletado pelo BCBL, também foi disponibilizado no Hugging Face, enquanto o dataset da v2 permanece sob embargo até a aceitação do artigo correspondente.
Do ponto de vista tecnológico, o Brain2Qwerty mostra como a próxima geração de IA não estará limitada a texto, imagem, áudio ou vídeo. A fronteira agora avança para sinais biológicos. A IA passa a atuar como tradutora entre padrões neurais e linguagem humana. Isso abre portas para aplicações em acessibilidade, reabilitação, medicina, neurociência computacional e interfaces homem-máquina.
Mas esse tipo de tecnologia também exige responsabilidade. Decodificar sinais cerebrais envolve questões profundas de privacidade, consentimento, segurança e governança. Se hoje discutimos proteção de dados pessoais, amanhã discutiremos com ainda mais intensidade a proteção de dados neurais. O cérebro não pode ser tratado como mais uma fonte comum de dados. Ele representa uma camada extremamente sensível da identidade humana.
O Brain2Qwerty não é apenas um projeto de IA. Ele é um marco simbólico de uma nova fase: a convergência entre inteligência artificial, neurociência e computação de alto desempenho. Ainda há muitos obstáculos técnicos, clínicos e éticos pela frente, mas a direção é clara. A comunicação entre cérebro e máquina está deixando de ser uma promessa distante para se tornar uma área real de pesquisa aplicada.
No futuro, talvez teclados, telas e comandos de voz não sejam as únicas formas de interação com computadores. Projetos como o Brain2Qwerty indicam que poderemos construir interfaces capazes de compreender intenção, linguagem e pensamento motor de forma cada vez mais direta. O desafio será garantir que essa tecnologia seja desenvolvida com segurança, inclusão e respeito à autonomia humana.
Brain2Qwerty é um lembrete poderoso: a próxima grande revolução da inteligência artificial talvez não esteja apenas em máquinas que falam melhor, mas em sistemas capazes de devolver a voz a quem a perdeu.
Fontes:
https://github.com/facebookresearch/brain2qwerty
https://facebookresearch.github.io/brain2qwerty
O GLM 5.2 : O Novo modelo que Está Desafiando a OpenAI e a Anthropic.

Eesta semana, a comunidade de Inteligência Artificial recebeu uma surpresa fantástica: a empresa Z.A ai lançou oficialmente os pesos abertos (open weights) do seu novo modelo, o GLM 5.2. O lançamento incluiu tanto a versão completa quanto a versão FP8 do modelo. Essa é uma mudança de postura muito bem-vinda, já que, recentemente, diversos criadores de modelos chineses estavam hesitando em liberar os pesos, optando por oferecer apenas versões proprietárias por meio de APIs.
Com base em testes rigorosos e novos benchmarks, o GLM 5.2 não é apenas uma pequena atualização, mas sim uma ferramenta incrivelmente poderosa. Aqui estão os detalhes que você precisa saber sobre o porquê de este modelo estar chamando tanta atenção.
Desempenho de Ponta e Salto em Relação ao GLM 5.1 A evolução da versão 5.1 para a 5.2 é descrita como “enorme”, particularmente em tarefas complexas como programação e uso de agentes autônomos (agentic coding). O GLM 5.2 foi construído especificamente para tarefas de longo horizonte (“long horizon tasks”) e tem mostrado resultados esmagadores nos benchmarks da Artificial Analysis.
Para se ter uma ideia do seu poder, ele está superando modelos de peso como Deep Seek Pro, Quen 3.7 Max, Miniax M3 e até modelos proprietários fechados como o GPT 5.5. Nos rankings atuais de inteligência, o GLM 5.2 tem sido batido apenas pelo Opus 4.8 da Anthropic e pelo modelo Fable (que, vale ressaltar, não está mais disponível para a maioria do público e apresentava falhas sem o uso do Opus 4.8 como fallback). Além disso, o GLM 5.2 está se destacando no novo benchmark Deep Suite, que vem substituindo métricas mais antigas da indústria.
O Segredo: Longas Cadeias de Pensamento e Predição de Múltiplos Tokens O que faz o GLM 5.2 ser tão inteligente? Em grande parte, é a sua arquitetura voltada para longas cadeias de pensamento (long chains of thought). Enquanto laboratórios como OpenAI e Anthropic têm focado em obter alta inteligência com uma quantidade menor de tokens de saída, o GLM 5.2 vai na direção oposta: ele utiliza uma grande quantidade de tokens de raciocínio para refletir profundamente antes de responder. Ao lidar com quebra-cabeças de lógica, por exemplo, o modelo aumenta significativamente a quantidade de tokens de pensamento da maneira correta, demonstrando um verdadeiro raciocínio.
Apesar de gerar muitos tokens, o modelo não é lento. Graças à adoção da tecnologia de predição de múltiplos tokens (multi-token prediction), o GLM 5.2 se tornou muito mais rápido que seus antecessores. Em testes práticos utilizando a API do Open Router, a velocidade média de geração tem ficado entre 36 a 40 tokens por segundo.
Na prática, o modelo é capaz de entregar resultados onde muitos outros falham:
- Design de Interfaces (Front-End): O GLM 5.2 assumiu o primeiro lugar na “Design Arena”, superando até mesmo a família de modelos Claude
Em um teste solicitando a criação de uma página web complexa, o modelo gerou perfeitamente um site estilo Anthropic com mais de 8.000 tokens, contendo imagens embutidas e diversas animações interativas.Geração de Textos Extensos: Se você precisa de redações longas, o GLM 5.2 brilha. Enquanto modelos tradicionais frequentemente interrompem a geração ao redor de 500 palavras, o GLM 5.2 possui a capacidade de continuar escrevendo até superar a marca de 5.000 tokens gerados em uma única resposta.Capacidade Visual/Lógica (SVG): O modelo passou tranquilamente no teste de criar visualmente um “Pelicano andando de bicicleta” usando apenas código SVG.
Custo-Benefício Imbatível e Controle de Privacidade A abertura dos pesos do modelo também resolve uma preocupação crítica corporativa: privacidade de dados. Como o modelo é de código aberto (open weights), várias empresas (como a Together AI no futuro) poderão hospedá-lo. Isso significa que os desenvolvedores não são obrigados a enviar seus dados proprietários para data centers na China, podendo escolher provedores locais de sua confiança.
No quesito preço, o GLM 5.2 chega para quebrar o mercado. Ele está sendo disponibilizado por cerca de US 4,40 por milhão de tokens de saída. Esse valor é dramaticamente inferior aos planos pagos e aos custos de API dos modelos proprietários equivalentes no mercado atual.
Veredito: Vale a Pena? Com toda certeza. O GLM 5.2 surge como um substituto formidável e infinitamente mais barato para modelos comerciais que usamos rotineiramente, como o Gemini Flash.
Dica de Segurança: Se você for experimentar o modelo agora utilizando agregadores como o Open Router, certifique-se de verificar as políticas de privacidade da plataforma em relação à retenção dos seus prompts e dados para treinamento de outros modelos de terceiros. O GLM 5.2 já está provando que modelos abertos chegaram para competir de igual para igual e possivelmente ultrapassar os gigantes da indústria.
Até a próxima.
Magalu Cloud e IA MED: Saúde, privacidade e soberania com tecnológica brasileira
A Inteligência Artificial deixou de ser uma promessa distante para se tornar uma ferramenta concreta de transformação em áreas essenciais da sociedade. Na saúde, esse movimento é ainda mais relevante, porque envolve vidas, tempo de atendimento, qualidade na triagem, apoio aos profissionais e proteção de dados extremamente sensíveis. É nesse contexto que nasce a IA MED, uma solução desenvolvida pela MultiCortex para levar modelos avançados de linguagem ao setor de saúde com foco em precisão, privacidade, eficiência operacional e soberania tecnológica.
A IA MED já está em funcionamento na cidade de Bebedouro, interior de São Paulo, cidade natal de Alessandro de Oliveira Faria, também conhecido como Cabelo, fundador da MultiCortex. A implantação tem um significado especial: além de representar um avanço tecnológico para a rede municipal de saúde, simboliza o retorno de décadas de pesquisa, desenvolvimento e inovação para beneficiar diretamente a população da cidade onde nasceu o idealizador da solução.

Segundo publicação oficial da Prefeitura Municipal de Bebedouro, a tecnologia IAmed foi desenvolvida pelo bebedourense e tem como objetivo auxiliar os profissionais de saúde no dia a dia, contribuindo para mais agilidade, precisão e qualidade nos atendimentos prestados à população. A Prefeitura também informa que a ferramenta foi cedida gratuitamente ao município pela MultiCortex IA, com infraestrutura Magalu Cloud, para acelerar e fomentar o uso de IA na saúde pública local.
A proposta da IA MED parte de uma preocupação muito concreta: ferramentas genéricas de Inteligência Artificial generativa, especialmente aquelas hospedadas em nuvens internacionais, não foram concebidas originalmente para lidar com a complexidade, a responsabilidade e a sensibilidade dos dados de saúde pública brasileira. Em um ambiente clínico, dados pessoais, históricos médicos, sintomas, exames, hipóteses, encaminhamentos e informações familiares não podem ser tratados como simples entradas de texto em uma aplicação qualquer. Eles exigem governança, segurança, rastreabilidade, controle de acesso e conformidade com a legislação brasileira.
A Lei Geral de Proteção de Dados Pessoais, a LGPD, estabelece regras para o tratamento de dados pessoais, inclusive em meios digitais, com o objetivo de proteger direitos fundamentais como liberdade, privacidade e livre desenvolvimento da personalidade. A própria legislação brasileira classifica dados referentes à saúde como dados pessoais sensíveis, o que torna ainda mais importante a adoção de arquiteturas tecnológicas que reduzam exposição, transferência desnecessária e dependência de ambientes fora do controle da organização pública ou privada.
Por isso, a IA MED foi pensada como uma Inteligência Artificial privada, verticalizada e adequada ao contexto da saúde. Diferente de IAs genéricas, que tentam responder sobre qualquer assunto a partir de modelos amplos e de uso geral, a IA MED trabalha com modelos de linguagem especializados, ajustados para fluxos, protocolos, terminologias e necessidades do setor de saúde. Essa verticalização permite maior aderência ao domínio médico-assistencial e reduz a dependência de respostas genéricas, vagas ou pouco contextualizadas.
Na prática, isso significa que a IA MED não existe para substituir médicos, enfermeiros, técnicos ou gestores de saúde. Pelo contrário: ela foi criada para apoiar esses profissionais. O papel da Inteligência Artificial é atuar como uma camada de auxílio, ajudando na organização das informações, na análise de dados clínicos disponíveis, na identificação de riscos, na triagem de prioridades, na sugestão de caminhos com base em protocolos e na redução de tarefas burocráticas que consomem tempo das equipes.
Nas Unidades Básicas de Saúde, onde a demanda é constante e os profissionais precisam lidar com grande volume de atendimentos, a IA pode se tornar uma aliada estratégica. Ela pode ajudar a estruturar informações do paciente, facilitar o acesso ao histórico, apoiar a classificação de risco, sugerir perguntas relevantes durante uma triagem, organizar encaminhamentos e permitir que a equipe tenha uma visão mais clara do fluxo de atendimento. Com isso, o profissional de saúde ganha tempo, reduz carga mental e pode se concentrar mais no cuidado humano.
Essa é uma das maiores contribuições da IA MED: usar tecnologia não para afastar o paciente do profissional, mas para devolver tempo ao atendimento humanizado. A saúde pública enfrenta desafios diários de volume, urgência, documentação, filas, registros e priorização. Quando uma ferramenta de IA bem desenhada assume parte do trabalho repetitivo e auxilia na organização das informações, ela contribui para que médicos e enfermeiros possam tomar decisões com mais segurança e menos sobrecarga.
Outro diferencial importante da IA MED está no custo computacional. Muitos projetos de Inteligência Artificial são inviabilizados porque dependem de servidores extremamente caros, como máquinas baseadas em GPUs H100 ou B200, que podem representar investimentos muito altos em infraestrutura. A proposta da MultiCortex é demonstrar que, com engenharia especializada, otimização de modelos, verticalização e uso inteligente de hardware, é possível entregar uma solução de IA aplicada à saúde utilizando infraestrutura com custo muito inferior na ordem de aproximadamente 10% do valor de grandes servidores baseados nessas GPUs topo de linha (GRAÇAS A COMPUTAÇÃO HETEROGÊNEA).
Essa diferença de custo é fundamental para a realidade brasileira. A inovação não pode ficar restrita a grandes centros, grandes hospitais ou instituições com orçamentos milionários. A Inteligência Artificial precisa ser viável para municípios, unidades públicas, clínicas, secretarias e organizações que buscam modernização, mas precisam respeitar limites financeiros. A IA MED nasce justamente dessa visão: criar uma tecnologia de alto impacto, com custo mais acessível e aplicação prática no cotidiano da saúde
A parceria com a Magalu Cloud reforça outro ponto central do projeto: a soberania dos dados. A Magalu Cloud se apresenta como uma nuvem brasileira, com preços em reais, suporte em português, infraestrutura local e data centers fisicamente no Brasil, distribuídos nas regiões Sudeste e Nordeste. A empresa também destaca que os dados são armazenados localmente e em conformidade com a legislação brasileira.
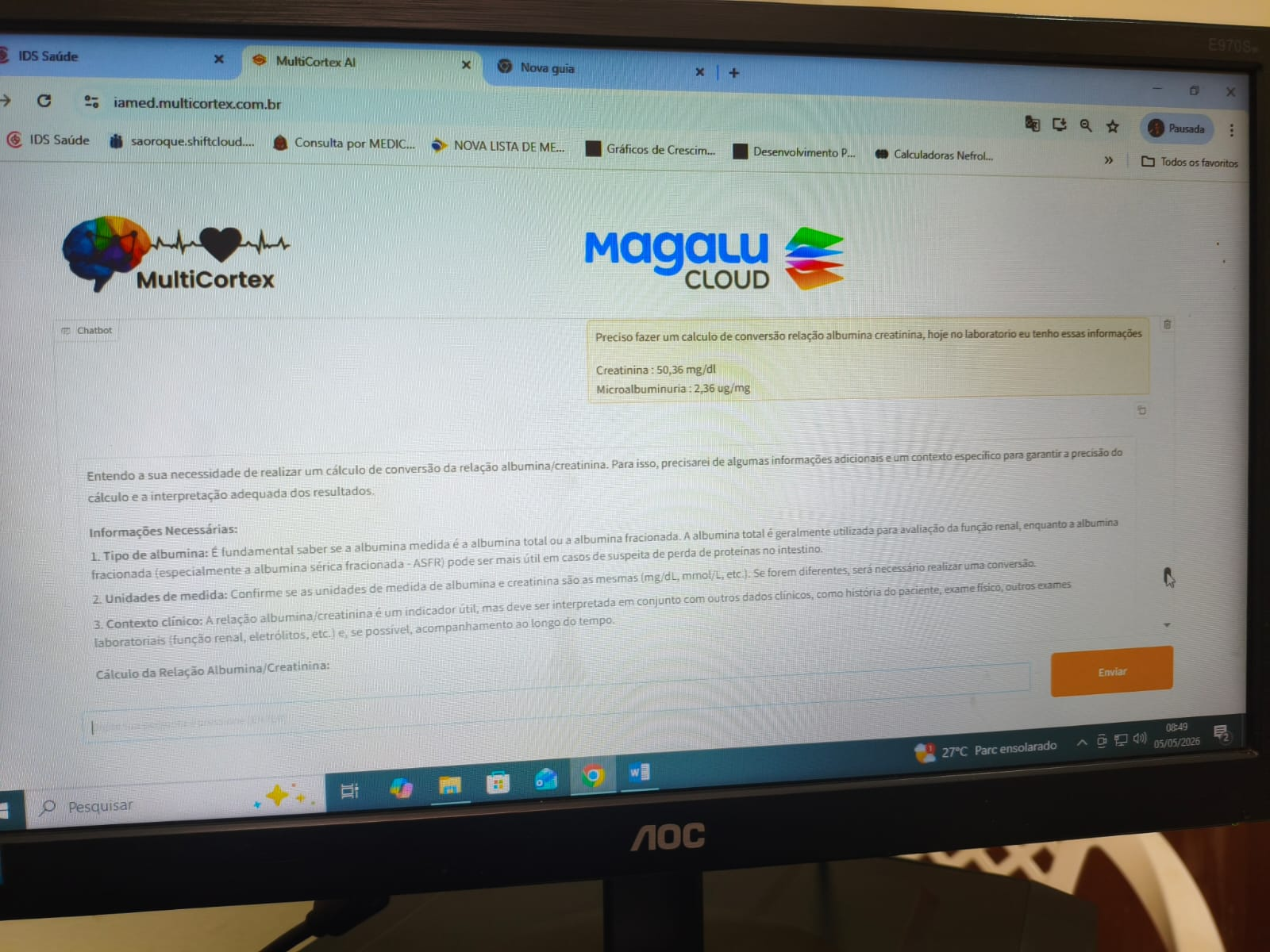
Para aplicações de saúde, esse detalhe é decisivo. Utilizar infraestrutura em território nacional reduz riscos associados à transferência internacional de dados, melhora a previsibilidade regulatória e aproxima a operação da realidade jurídica, técnica e institucional do Brasil. Em vez de depender exclusivamente de nuvens estrangeiras, cobradas em dólar e sujeitas a camadas adicionais de complexidade contratual e regulatória, a IA MED utiliza uma infraestrutura alinhada ao conceito de soberania digital.
A Magalu Cloud também destaca benefícios como preços em reais, previsibilidade sem variação cambial, suporte humano em português, infraestrutura local, baixa latência, custos reduzidos, escalabilidade e serviços como máquinas virtuais, armazenamento, VPC, Kubernetes, banco de dados e ferramentas de identidade e acesso. Para um projeto como a IA MED, esses elementos ajudam a compor uma base tecnológica mais adequada para o setor público brasileiro.
Além da privacidade, há também a questão da previsibilidade de custos. Muitas soluções de IA em nuvem funcionam com cobrança baseada em tokens, o que pode se tornar um problema quando há grande volume de atendimentos, consultas, registros e interações. Em ambientes públicos, onde orçamento precisa ser planejado e justificado, custos variáveis e imprevisíveis podem dificultar a adoção em escala. A IA MED busca reduzir esse problema ao operar em uma arquitetura mais controlada, privada e otimizada, sem depender do modelo tradicional de cobrança por token de plataformas externas.
Essa abordagem permite que a Inteligência Artificial deixe de ser uma despesa imprevisível e passe a ser uma infraestrutura estratégica. Em vez de pagar indefinidamente por cada interação processada em serviços de terceiros, a organização pode trabalhar com um ambiente mais previsível, controlado e adaptado à sua demanda. Para a saúde pública, isso significa maior capacidade de planejamento, menor dependência externa e mais sustentabilidade para expandir o uso da tecnologia.
O impacto para a população pode ser percebido de várias formas. O cidadão tende a se beneficiar de atendimentos mais organizados, triagens mais ágeis, melhor acompanhamento, redução de retrabalho e maior apoio à identificação de prioridades. Em muitos casos, a diferença não estará apenas em “usar IA”, mas em usar IA para melhorar processos invisíveis que afetam diretamente a experiência do paciente: tempo de espera, clareza das informações, encaminhamentos, continuidade do cuidado e segurança no atendimento.
Para os profissionais de saúde, a IA MED representa uma ferramenta de apoio em um cenário de alta responsabilidade. O cansaço mental, a pressão por produtividade, a repetição de tarefas administrativas e o volume de informações podem aumentar a margem de erro em qualquer setor. Na saúde, porém, erros podem ter consequências graves. A Inteligência Artificial, quando aplicada com responsabilidade, pode ajudar a mitigar riscos, organizar dados e apoiar decisões, sempre mantendo o profissional humano no centro do processo.
A iniciativa em Bebedouro também carrega um valor simbólico importante. Ver uma tecnologia criada por um bebedourense sendo aplicada diretamente em benefício da população local mostra que inovação não precisa nascer apenas em polos internacionais ou grandes capitais. A inovação também pode surgir do interior, de trajetórias individuais de pesquisa, de comunidades técnicas brasileiras e de empresas que entendem os desafios reais do país.
Para Alessandro de Oliveira Faria, a implantação da IA MED em Bebedouro representa mais do que um projeto tecnológico. É o resultado de mais de 25 anos de pesquisa em Inteligência Artificial, iniciada ainda em 1998, somada a uma trajetória dedicada à computação de alto desempenho, otimização de hardware, software livre e aplicação prática da tecnologia em benefício da sociedade. Levar essa experiência para a saúde pública da sua cidade natal é uma forma de transformar conhecimento acumulado em impacto social direto.
Durante a fase de avaliação, a MultiCortex disponibilizou o sistema gratuitamente ao município de Bebedouro por meio de um termo de cooperação com a Prefeitura. A empresa assumiu integralmente os custos computacionais em nuvem, reforçando o compromisso de manter Bebedouro na vanguarda da inovação tecnológica. A iniciativa remete ao histórico da cidade com projetos pioneiros de tecnologia, como ocorreu no início dos anos 2000 com a implantação da biometria de impressão digital.
Esse ponto é essencial: inovação pública não acontece apenas quando se compra tecnologia pronta. Ela acontece quando há colaboração entre poder público, empresas, pesquisadores, profissionais técnicos e a comunidade. Ao ceder a IA MED gratuitamente na fase de avaliação, a MultiCortex cria uma oportunidade concreta para que a cidade experimente, valide e compreenda os benefícios da Inteligência Artificial aplicada à saúde de forma segura, responsável e alinhada à realidade local.
A IA MED também reforça uma visão maior da MultiCortex: devolver às organizações o controle sobre sua própria Inteligência Artificial. No setor da saúde, esse controle é ainda mais importante. Não se trata apenas de desempenho técnico, mas de governança, soberania, privacidade e responsabilidade. Uma IA aplicada à saúde precisa respeitar dados, pessoas, profissionais e instituições. Precisa ser explicável dentro do possível, auditável, segura e construída para o contexto em que será usada.
Ao unir modelos de LLM verticalizados, infraestrutura nacional, custo computacional reduzido, privacidade e foco no apoio aos profissionais de saúde, a IA MED se posiciona como uma alternativa brasileira para um dos maiores desafios da atualidade: como usar Inteligência Artificial em áreas sensíveis sem abrir mão da segurança, da ética e da soberania dos dados.
Bebedouro, ao receber essa implantação, dá um passo importante rumo à modernização dos serviços públicos de saúde. A iniciativa mostra que a tecnologia pode ser uma aliada direta do cuidado, não apenas uma ferramenta distante de laboratório. Mostra também que a IA pode ser aplicada de forma responsável, com foco em pessoas, em eficiência pública e na valorização dos profissionais que estão na linha de frente.
A IA MED nasce com esse propósito: transformar a Inteligência Artificial em uma infraestrutura confiável para a saúde, capaz de apoiar decisões, otimizar processos, reduzir custos e proteger dados sensíveis. Mais do que uma ferramenta tecnológica, ela representa uma visão de futuro para a saúde pública brasileira, um futuro em que inovação, privacidade, soberania e cuidado humano caminham juntos.
IA MED: Saúde pública, privacidade e soberania tecnológica brasileira
A Inteligência Artificial deixou de ser uma promessa distante para se tornar uma ferramenta concreta de transformação em áreas essenciais da sociedade. Na saúde, esse movimento é ainda mais relevante, porque envolve vidas, tempo de atendimento, qualidade na triagem, apoio aos profissionais e proteção de dados extremamente sensíveis. É nesse contexto que nasce a IA MED, uma solução desenvolvida pela MultiCortex para levar modelos avançados de linguagem ao setor de saúde com foco em precisão, privacidade, eficiência operacional e soberania tecnológica.
A IA MED já está em funcionamento na cidade de Bebedouro, interior de São Paulo, cidade natal de Alessandro de Oliveira Faria, também conhecido como Cabelo, fundador da MultiCortex. A implantação tem um significado especial: além de representar um avanço tecnológico para a rede municipal de saúde, simboliza o retorno de décadas de pesquisa, desenvolvimento e inovação para beneficiar diretamente a população da cidade onde nasceu o idealizador da solução.
Segundo publicação oficial da Prefeitura Municipal de Bebedouro, a tecnologia IAmed foi desenvolvida pelo bebedourense e tem como objetivo auxiliar os profissionais de saúde no dia a dia, contribuindo para mais agilidade, precisão e qualidade nos atendimentos prestados à população. A Prefeitura também informa que a ferramenta foi cedida gratuitamente ao município pela MultiCortex IA, com infraestrutura Magalu Cloud, para acelerar e fomentar o uso de IA na saúde pública local.
A proposta da IA MED parte de uma preocupação muito concreta: ferramentas genéricas de Inteligência Artificial generativa, especialmente aquelas hospedadas em nuvens internacionais, não foram concebidas originalmente para lidar com a complexidade, a responsabilidade e a sensibilidade dos dados de saúde pública brasileira. Em um ambiente clínico, dados pessoais, históricos médicos, sintomas, exames, hipóteses, encaminhamentos e informações familiares não podem ser tratados como simples entradas de texto em uma aplicação qualquer. Eles exigem governança, segurança, rastreabilidade, controle de acesso e conformidade com a legislação brasileira.
A Lei Geral de Proteção de Dados Pessoais, a LGPD, estabelece regras para o tratamento de dados pessoais, inclusive em meios digitais, com o objetivo de proteger direitos fundamentais como liberdade, privacidade e livre desenvolvimento da personalidade. A própria legislação brasileira classifica dados referentes à saúde como dados pessoais sensíveis, o que torna ainda mais importante a adoção de arquiteturas tecnológicas que reduzam exposição, transferência desnecessária e dependência de ambientes fora do controle da organização pública ou privada.
Por isso, a IA MED foi pensada como uma Inteligência Artificial privada, verticalizada e adequada ao contexto da saúde. Diferente de IAs genéricas, que tentam responder sobre qualquer assunto a partir de modelos amplos e de uso geral, a IA MED trabalha com modelos de linguagem especializados, ajustados para fluxos, protocolos, terminologias e necessidades do setor de saúde. Essa verticalização permite maior aderência ao domínio médico-assistencial e reduz a dependência de respostas genéricas, vagas ou pouco contextualizadas.
Na prática, isso significa que a IA MED não existe para substituir médicos, enfermeiros, técnicos ou gestores de saúde. Pelo contrário: ela foi criada para apoiar esses profissionais. O papel da Inteligência Artificial é atuar como uma camada de auxílio, ajudando na organização das informações, na análise de dados clínicos disponíveis, na identificação de riscos, na triagem de prioridades, na sugestão de caminhos com base em protocolos e na redução de tarefas burocráticas que consomem tempo das equipes.
Nas Unidades Básicas de Saúde, onde a demanda é constante e os profissionais precisam lidar com grande volume de atendimentos, a IA pode se tornar uma aliada estratégica. Ela pode ajudar a estruturar informações do paciente, facilitar o acesso ao histórico, apoiar a classificação de risco, sugerir perguntas relevantes durante uma triagem, organizar encaminhamentos e permitir que a equipe tenha uma visão mais clara do fluxo de atendimento. Com isso, o profissional de saúde ganha tempo, reduz carga mental e pode se concentrar mais no cuidado humano.
Essa é uma das maiores contribuições da IA MED: usar tecnologia não para afastar o paciente do profissional, mas para devolver tempo ao atendimento humanizado. A saúde pública enfrenta desafios diários de volume, urgência, documentação, filas, registros e priorização. Quando uma ferramenta de IA bem desenhada assume parte do trabalho repetitivo e auxilia na organização das informações, ela contribui para que médicos e enfermeiros possam tomar decisões com mais segurança e menos sobrecarga.
Outro diferencial importante da IA MED está no custo computacional. Muitos projetos de Inteligência Artificial são inviabilizados porque dependem de servidores extremamente caros, como máquinas baseadas em GPUs H100 ou B200, que podem representar investimentos muito altos em infraestrutura. A proposta da MultiCortex é demonstrar que, com engenharia especializada, otimização de modelos, verticalização e uso inteligente de hardware, é possível entregar uma solução de IA aplicada à saúde utilizando infraestrutura com custo muito inferior na ordem de aproximadamente 10% do valor de grandes servidores baseados nessas GPUs topo de linha (GRAÇAS A COMPUTAÇÃO HETEROGÊNEA).
Essa diferença de custo é fundamental para a realidade brasileira. A inovação não pode ficar restrita a grandes centros, grandes hospitais ou instituições com orçamentos milionários. A Inteligência Artificial precisa ser viável para municípios, unidades públicas, clínicas, secretarias e organizações que buscam modernização, mas precisam respeitar limites financeiros. A IA MED nasce justamente dessa visão: criar uma tecnologia de alto impacto, com custo mais acessível e aplicação prática no cotidiano da saúde
A parceria com a Magalu Cloud reforça outro ponto central do projeto: a soberania dos dados. A Magalu Cloud se apresenta como uma nuvem brasileira, com preços em reais, suporte em português, infraestrutura local e data centers fisicamente no Brasil, distribuídos nas regiões Sudeste e Nordeste. A empresa também destaca que os dados são armazenados localmente e em conformidade com a legislação brasileira.
Para aplicações de saúde, esse detalhe é decisivo. Utilizar infraestrutura em território nacional reduz riscos associados à transferência internacional de dados, melhora a previsibilidade regulatória e aproxima a operação da realidade jurídica, técnica e institucional do Brasil. Em vez de depender exclusivamente de nuvens estrangeiras, cobradas em dólar e sujeitas a camadas adicionais de complexidade contratual e regulatória, a IA MED utiliza uma infraestrutura alinhada ao conceito de soberania digital.
A Magalu Cloud também destaca benefícios como preços em reais, previsibilidade sem variação cambial, suporte humano em português, infraestrutura local, baixa latência, custos reduzidos, escalabilidade e serviços como máquinas virtuais, armazenamento, VPC, Kubernetes, banco de dados e ferramentas de identidade e acesso. Para um projeto como a IA MED, esses elementos ajudam a compor uma base tecnológica mais adequada para o setor público brasileiro.
Além da privacidade, há também a questão da previsibilidade de custos. Muitas soluções de IA em nuvem funcionam com cobrança baseada em tokens, o que pode se tornar um problema quando há grande volume de atendimentos, consultas, registros e interações. Em ambientes públicos, onde orçamento precisa ser planejado e justificado, custos variáveis e imprevisíveis podem dificultar a adoção em escala. A IA MED busca reduzir esse problema ao operar em uma arquitetura mais controlada, privada e otimizada, sem depender do modelo tradicional de cobrança por token de plataformas externas.
Essa abordagem permite que a Inteligência Artificial deixe de ser uma despesa imprevisível e passe a ser uma infraestrutura estratégica. Em vez de pagar indefinidamente por cada interação processada em serviços de terceiros, a organização pode trabalhar com um ambiente mais previsível, controlado e adaptado à sua demanda. Para a saúde pública, isso significa maior capacidade de planejamento, menor dependência externa e mais sustentabilidade para expandir o uso da tecnologia.
O impacto para a população pode ser percebido de várias formas. O cidadão tende a se beneficiar de atendimentos mais organizados, triagens mais ágeis, melhor acompanhamento, redução de retrabalho e maior apoio à identificação de prioridades. Em muitos casos, a diferença não estará apenas em “usar IA”, mas em usar IA para melhorar processos invisíveis que afetam diretamente a experiência do paciente: tempo de espera, clareza das informações, encaminhamentos, continuidade do cuidado e segurança no atendimento.
Para os profissionais de saúde, a IA MED representa uma ferramenta de apoio em um cenário de alta responsabilidade. O cansaço mental, a pressão por produtividade, a repetição de tarefas administrativas e o volume de informações podem aumentar a margem de erro em qualquer setor. Na saúde, porém, erros podem ter consequências graves. A Inteligência Artificial, quando aplicada com responsabilidade, pode ajudar a mitigar riscos, organizar dados e apoiar decisões, sempre mantendo o profissional humano no centro do processo.
A iniciativa em Bebedouro também carrega um valor simbólico importante. Ver uma tecnologia criada por um bebedourense sendo aplicada diretamente em benefício da população local mostra que inovação não precisa nascer apenas em polos internacionais ou grandes capitais. A inovação também pode surgir do interior, de trajetórias individuais de pesquisa, de comunidades técnicas brasileiras e de empresas que entendem os desafios reais do país.
Para Alessandro de Oliveira Faria, a implantação da IA MED em Bebedouro representa mais do que um projeto tecnológico. É o resultado de mais de 25 anos de pesquisa em Inteligência Artificial, iniciada ainda em 1998, somada a uma trajetória dedicada à computação de alto desempenho, otimização de hardware, software livre e aplicação prática da tecnologia em benefício da sociedade. Levar essa experiência para a saúde pública da sua cidade natal é uma forma de transformar conhecimento acumulado em impacto social direto.
Durante a fase de avaliação, a MultiCortex disponibilizou o sistema gratuitamente ao município de Bebedouro por meio de um termo de cooperação com a Prefeitura. A empresa assumiu integralmente os custos computacionais em nuvem, reforçando o compromisso de manter Bebedouro na vanguarda da inovação tecnológica. A iniciativa remete ao histórico da cidade com projetos pioneiros de tecnologia, como ocorreu no início dos anos 2000 com a implantação da biometria de impressão digital.
Esse ponto é essencial: inovação pública não acontece apenas quando se compra tecnologia pronta. Ela acontece quando há colaboração entre poder público, empresas, pesquisadores, profissionais técnicos e a comunidade. Ao ceder a IA MED gratuitamente na fase de avaliação, a MultiCortex cria uma oportunidade concreta para que a cidade experimente, valide e compreenda os benefícios da Inteligência Artificial aplicada à saúde de forma segura, responsável e alinhada à realidade local.
A IA MED também reforça uma visão maior da MultiCortex: devolver às organizações o controle sobre sua própria Inteligência Artificial. No setor da saúde, esse controle é ainda mais importante. Não se trata apenas de desempenho técnico, mas de governança, soberania, privacidade e responsabilidade. Uma IA aplicada à saúde precisa respeitar dados, pessoas, profissionais e instituições. Precisa ser explicável dentro do possível, auditável, segura e construída para o contexto em que será usada.
Ao unir modelos de LLM verticalizados, infraestrutura nacional, custo computacional reduzido, privacidade e foco no apoio aos profissionais de saúde, a IA MED se posiciona como uma alternativa brasileira para um dos maiores desafios da atualidade: como usar Inteligência Artificial em áreas sensíveis sem abrir mão da segurança, da ética e da soberania dos dados.
Bebedouro, ao receber essa implantação, dá um passo importante rumo à modernização dos serviços públicos de saúde. A iniciativa mostra que a tecnologia pode ser uma aliada direta do cuidado, não apenas uma ferramenta distante de laboratório. Mostra também que a IA pode ser aplicada de forma responsável, com foco em pessoas, em eficiência pública e na valorização dos profissionais que estão na linha de frente.
A IA MED nasce com esse propósito: transformar a Inteligência Artificial em uma infraestrutura confiável para a saúde, capaz de apoiar decisões, otimizar processos, reduzir custos e proteger dados sensíveis. Mais do que uma ferramenta tecnológica, ela representa uma visão de futuro para a saúde pública brasileira, um futuro em que inovação, privacidade, soberania e cuidado humano caminham juntos.
SOTAQUE: IA aprendendo a falar como Brasileiro

A Inteligência Artificial já consegue conversar, transcrever áudio, narrar livros, atender clientes e criar assistentes de voz. Mas existe um problema que ainda passa despercebido: muitas dessas tecnologias não entendem o Brasil como ele realmente fala. O português brasileiro não é uma voz única, neutra e padronizada. Ele é caipira, baiano, nortista, gaúcho, mineiro, carioca, paulistano, nordestino, amazônico, interiorano, urbano e profundamente diverso.
É exatamente para enfrentar esse desafio que nasce o SOTAQUE — Speech-Oriented Training Audio for Quality Understanding and Expression, uma iniciativa voltada à criação de um dataset aberto de vozes em português brasileiro, com foco na diversidade regional dos sotaques do país. A proposta é simples e poderosa: reunir vozes reais de brasileiros para que tecnologias de fala, como assistentes virtuais, audiobooks, sistemas de transcrição automática e modelos de voz, consigam representar melhor a pluralidade do nosso idioma.
Meus mais sinceros
parabéns Fabrício Carraro!
Hoje, muitos modelos de fala em português ainda são treinados com pouca diversidade de vozes, muitas vezes concentradas em sotaques urbanos do Sudeste, especialmente paulistano e carioca. Isso faz com que uma IA fale português de forma artificialmente neutra e, em alguns casos, tenha dificuldade para compreender pessoas com sotaques regionais mais marcados. O resultado é uma tecnologia que funciona melhor para alguns brasileiros do que para outros
O SOTAQUE quer mudar essa realidade por meio de uma construção coletiva. A ideia é criar uma base pública, documentada e aberta, feita com contribuições voluntárias da comunidade. Cada pessoa pode ajudar enviando um áudio com sua própria voz e respondendo algumas perguntas rápidas sobre seu perfil linguístico, como região onde cresceu, estado, sotaque declarado e faixa etária. O processo leva poucos minutos e pode ser feito com uma gravação nova ou até com um áudio antigo, desde que respeite as regras do projeto.
A importância desse projeto vai além da tecnologia. Ele toca em representatividade linguística. Quando um sotaque fica fora dos datasets, milhões de pessoas também ficam menos representadas nas ferramentas digitais que escutam, falam, transcrevem e interagem em português. Ter uma IA que entende melhor o Brasil é também garantir que a inovação não apague as nossas diferenças regionais, mas aprenda com elas.
Outro ponto relevante é que o projeto nasce com uma proposta aberta. As gravações, transcrições e metadados autorizados serão publicados com licença CDLA-Permissive-2.0, permitindo uso amplo por pesquisadores, startups, escolas, criadores de conteúdo e desenvolvedores interessados em tecnologias de fala em português brasileiro. A meta inicial do projeto é alcançar 1.000 horas de áudio coletado e curado, com uma meta final de 10.000 horas.
Naturalmente, quando falamos de voz, também falamos de privacidade. O próprio termo do projeto deixa claro que a participação é voluntária, restrita a maiores de 18 anos localizados no Brasil no momento da contribuição, e que a pessoa deve contribuir apenas com a própria voz. Também é importante evitar áudios com dados pessoais de terceiros, senhas, informações financeiras ou qualquer conteúdo sensível.
O SOTAQUE é uma oportunidade para a comunidade brasileira participar diretamente da construção de tecnologias mais justas, abertas e representativas. Em vez de esperar que grandes empresas definam sozinhas como a IA deve falar português, podemos contribuir com a nossa própria voz para que os próximos modelos entendam melhor quem somos, de onde viemos e como falamos.
Contribuir é simples, vá até a página Contribuir e envie um áudio com sua voz (Leva uns 2 minutos: granvando um áudio, conta um pouco sobre você, marca o consentimento. Pronto), ajude a construir um dataset aberto que pode beneficiar toda a comunidade de IA, educação, acessibilidade, pesquisa e inovação no Brasil. A sua voz tem valor. O seu sotaque também.
Mais informações aqui: https://sotaque.ia.br/
auto-round: Estado da Arte em quantização para CPU/XPU/GPU NVIDIA

O AutoRound (https://github.com/intel/auto-round) é uma ferramenta de quantização para LLMs e VLMs desenvolvida pela Intel. A ideia central é reduzir o modelo para 2, 3, 4 ou 8 bits, mantendo boa precisão, principalmente em cenários de low-bit weight-only quantization (converte os pesos mas manter a inferência), como W4A16, W3A16 e W2A16. O próprio repositório descreve o AutoRound como um toolkit para LLMs/VLMs que usa signed gradient descent para obter alta acurácia em 2–4 bits com baixo custo de ajuste.
Como Intel Innovator, tenho a missão mostrar o compromisso sério da Intel neste vertical tecnológica. A tecnologia beneficia GPU NVIDIA, CPU e XPU
Em termos simples: ele não apenas “arredonda” os pesos para 4 bits como um método ingênuo faria. Ele aprende a melhor forma de arredondar os pesos e também ajusta os limites de clipping para reduzir o erro entre a saída do bloco original e a saída do bloco quantizado. O paper do SignRound (https://arxiv.org/html/2309.05516v3) explica que o método adiciona parâmetros treináveis para ajustar o rounding e dois parâmetros extras para ajustar o clipping dos pesos; depois usa reconstrução por bloco e otimização com SignSGD.
Como ele funciona
O fluxo é mais ou menos assim:
- Você passa um modelo Hugging Face, por exemplo
Qwen/Qwen3-0.6B,Llama,Mistral, etc. - Ele usa um dataset de calibração. Por padrão, usa
NeelNanda/pile-10k, mas aceita datasets customizados, JSON local, lista de strings, input ids, concatenação de datasets e aplicação de chat template. - Para cada bloco/camada, ele compara a saída do modelo original com a saída do modelo quantizado.
- Ele otimiza o rounding dos pesos e o range de clipping usando signed gradient descent.
- No final, salva o modelo em um formato escolhido:
auto_round,auto_gptq,auto_awq,gguf,llm_compressor,mlx, entre outros.
Como usar?
pip install auto-round
auto-round \
--model Qwen/Qwen3-0.6B \
--scheme "W4A16" \
--format "auto_round" \
--output_dir ./qwen_autoround_w4a16
Para exportar para GGUF:
auto-round \
--model Qwen/Qwen3-0.6B \
--format "gguf:q4_k_m" \
--output_dir ./qwen_gguf_q4_k_m
O repositório mostra instalação via pip install auto-round, suporte a CPU/GPU CUDA, Intel XPU e Gaudi/HPU, além de exemplos com Qwen/Qwen3-0.6B
O que significa W4A16, W3A16, W2A16
W4A16 significa:
| Campo | Significado |
|---|---|
W4 |
pesos em 4 bits |
A16 |
ativações em 16 bits, normalmente FP16/BF16 |
group_size=128 |
quantização por grupos de pesos |
sym=True |
quantização simétrica |
O AutoRound documenta esquemas como W4A16, W8A16, W3A16, W2A16, mixed bits, GGUF, NVFP4, MXFP4, FP8 e outros.
Na prática, W4A16 costuma ser o ponto mais seguro: boa redução de memória com perda pequena. W2A16 é muito mais agressivo: pode reduzir muito mais o tamanho dos pesos, mas exige algoritmo melhor, calibração melhor e validação forte.
Diferença para GPTQ, AWQ, SmoothQuant, bitsandbytes e GGUF
| Tecnologia | O que faz | Diferença principal em relação ao AutoRound |
|---|---|---|
| AutoRound / SignRound | PTQ weight-only com otimização de rounding e clipping por SignSGD | Mais focado em otimizar o arredondamento dos pesos, bom para 2–4 bits, com exportação para vários formatos |
| GPTQ | Quantização weight-only baseada em informação de segunda ordem/Hessian | GPTQ é “one-shot” e muito usado para 3/4 bits; AutoRound usa otimização de rounding/clipping e pode inclusive exportar em formato GPTQ |
| AWQ | Activation-aware weight quantization | AWQ identifica canais importantes pelas ativações e protege pesos salientes; não depende de backprop/reconstrução, enquanto AutoRound otimiza com calibração e SignSGD |
| SmoothQuant | Quantização W8A8, pesos e ativações em INT8 | SmoothQuant é mais voltado para INT8 completo, migrando dificuldade das ativações para os pesos; AutoRound é mais focado em weight-only low-bit, como W4A16/W2A16 |
| bitsandbytes / QLoRA | Quantização 8-bit/4-bit prática para carregar e fine-tunar modelos | bitsandbytes é ótimo para fine-tuning com LoRA/QLoRA e carregamento simples; AutoRound é mais um pipeline offline de quantização calibrada/exportável |
| GGUF / llama.cpp | Formato/ecossistema de arquivo e kernels para CPU/GPU | GGUF não é apenas algoritmo; é formato + tipos de quantização. AutoRound pode exportar para GGUF, inclusive q4_k_m, q2_k_s, etc. |
GPTQ se baseia em quantização weight-only com informação aproximada de segunda ordem e mostrou bons resultados em 3/4 bits em modelos grandes. AWQ usa estatísticas de ativação para proteger canais salientes e evitar quantização mista ineficiente, sem backpropagation ou reconstrução. SmoothQuant é uma abordagem PTQ para W8A8, suavizando outliers de ativação por uma transformação matematicamente equivalente entre ativações e pesos. bitsandbytes fornece camadas quantizadas 8-bit/4-bit, otimizadores 8-bit, LLM.int8() e QLoRA com NF4 para reduzir uso de memória.
Vantagens do AutoRound
A grande vantagem é que ele tenta entregar mais qualidade em baixa precisão, principalmente em 2, 3, 4 e 8 bits, onde métodos simples como RTN geralmente degradam bastante. No paper original, os autores comparam com GPTQ, AWQ, HQQ, OmniQuant e RTN, e relatam ganhos maiores conforme os bits diminuem, especialmente em W2G128, com melhorias absolutas de acurácia média entre 6,91% e 33,22% em 11 tarefas zero-shot.
Outra vantagem é a compatibilidade de ecossistema: o AutoRound suporta exportação para auto_round, auto_gptq, auto_awq, gguf, llm_compressor e mlx, além de integração com Transformers, vLLM e SGLang.
Dicas:
# equilíbrio entre qualidade e custo
auto-round --model Qwen/Qwen3-0.6B --scheme "W4A16"
# melhor qualidade, mais lento
auto-round-best --model Qwen/Qwen3-0.6B --scheme "W4A16"
# mais rápido, com possível perda de acurácia
auto-round-light --model Qwen/Qwen3-0.6B --scheme "W4A16"
A documentação recomenda auto-round como bom equilíbrio geral, auto-round-best para melhor acurácia — especialmente 2-bit — e auto-round-light para velocidade, mais indicado em 4-bit e modelos maiores que 3B.

O AutoRound não elimina a necessidade de benchmark real. Quantização muda o comportamento do modelo, e a perda pode aparecer em raciocínio, código, português, instruções longas ou domínios específicos. Para um modelo que você usa em produção, eu validaria pelo menos:
# exemplo conceitual
lm_eval \
--model hf \
--model_args pretrained=./qwen_autoround_w4a16 \
--tasks hellaswag,arc_challenge,mmlu,truthfulqa \
--batch_size auto
Também é importante entender que W4A16 quantiza principalmente os pesos, mantendo ativações em 16 bits. Isso reduz muito o tamanho do modelo, mas não resolve sozinho todos os gargalos, por exemplo KV-cache em contextos longos. O paper original deixa claro que o foco experimental era weight-only quantization em camadas lineares dos blocos transformer.
Outro ponto: alguns esquemas novos, como MXFP4/MXINT4/MXFP8, aparecem na documentação como recursos de pesquisa ou sem kernel real em certos casos; então o formato escolhido precisa casar com o runtime que você vai usar.
Minha leitura particular: AutoRound é uma das opções mais interessantes hoje para quantização low-bit de LLMs quando qualidade importa mais do que apenas velocidade de conversão. Para W4A16, eu testaria como alternativa séria a GPTQ/AWQ. Para W2A16, eu priorizaria AutoRound/SignRound, mas sempre com avaliação no seu conjunto de tarefas.
Código fonte: https://github.com/intel/auto-round
Copy Fail (CVE-2026-31431) como mitigar/impedir o acesso a root.

Copy Fail (CVE-2026-31431) é uma vulnerabilidade de escalonamento local de privilégio no kernel Linux QUE TOMOU CONTA DAS REDES SOCIAIS. Ela foi divulgada publicamente em 29 de abril de 2026 e está ligada ao subsistema criptográfico do kernel, especialmente à interface AF_ALG / algif_aead e ao template criptográfico authencesn. Em termos práticos: um usuário local sem privilégios pode abusar de uma falha lógica para fazer uma escrita controlada de poucos bytes no page cache de um arquivo legível e, a partir disso, alterar o comportamento de binários privilegiados para obter root.
O conceito central é que o kernel permite que programas em userspace usem algoritmos criptográficos via sockets AF_ALG. A falha apareceu em uma lógica de operação “in-place” em AEAD, isto é, quando a origem e o destino da operação criptográfica são tratados de forma inadequada como se pudessem compartilhar o mesmo espaço/mapeamento. O patch oficial basicamente remove essa complexidade e volta a operar “out-of-place”, porque não havia benefício real em operar in-place nesse caso.
O nome Copy Fail vem justamente dessa ideia: uma cópia que deveria cair em um destino seguro acaba afetando um local errado/controlável. A exploração pública descreve uma cadeia envolvendo AF_ALG, splice(), page cache e uma escrita controlada de 4 bytes em arquivo legível. Isso é perigoso porque muitos binários privilegiados do sistema, como su, sudo, pkexec, passwd, mount, chsh e chfn, normalmente são executáveis setuid-root e, em várias distribuições, também são legíveis por usuários comuns.
O impacto é alto porque não é uma exploração remota: o atacante precisa ter acesso local ao sistema, por exemplo uma conta shell, usuário em servidor compartilhado, container mal isolado ou ambiente multiusuário. Mas, uma vez dentro, a falha pode permitir virar root sem depender de race condition, offsets específicos por distribuição ou tentativas instáveis. Os pesquisadores afirmam ter testado em Ubuntu, Amazon Linux, RHEL e SUSE, incluindo SUSE 16.
Nós como membros da OWASP Capítulo São Paulo, temos a missão de ajudar a mitigar este problema…
A mitigação principal e correta é atualizar o kernel para uma versão que contenha o patch/revert de algif_aead. A mitigação com chmod é uma defesa emergencial: ela reduz a superfície de ataque removendo permissão de leitura de binários setuid sensíveis, mantendo a execução e o bit setuid. Então abaixo o comando de autoria do Raphael Bastos A.K.A. coffnix para executar o chmod removendo o direito de leitura dos comandos passwd chsh chfn mount sudo pkexec
for b in passwd chsh chfn mount sudo su pkexec;
do p=$(readlink -f "$(command -v "$b")");
[ -n "$p" ] && chmod 4711 "$p"; done
O brinquedo funciona assim: ele percorre a lista de binários sensíveis (passwd, chsh, chfn, mount, sudo, pkexec), encontra o caminho real de cada um com command -v e readlink -f, e aplica chmod 4711 no arquivo encontrado.
O modo 4711 significa:
4 = ativa o bit setuid
7 = dono/root pode ler, escrever e executar
1 = grupo só pode executar
1 = outros usuários só podem executar
Ou seja, o binário continua funcionando como setuid-root, mas deixa de ser legível por usuários comuns. Como a exploração depende de atingir arquivos legíveis no page cache, remover a permissão de leitura desses binários dificulta ou bloqueia essa cadeia específica contra esses alvos.
Em sistemas de produção, eu usaria assim:
sudo sh -c 'for b in passwd chsh chfn mount sudo pkexec; do p=$(readlink -f "$(command -v "$b")"); [ -n "$p" ] && chmod 4711 "$p"; done'
Depois valide:
ls -l /usr/bin/passwd /usr/bin/chsh /usr/bin/chfn /usr/bin/mount /usr/bin/sudo /usr/bin/pkexec
Você deve ver algo parecido com:
-rws--x--x root root ...
Resumo: patch de kernel é a correção real; chmod 4711 nos binários setuid é uma mitigação rápida para reduzir o alvo explorável enquanto o kernel corrigido não é aplicado.