
 cabelo
cabeloOrigin Pilot: Um OS da Era Quântica

O lançamento do Origin Pilot representa um marco importante na evolução da computação quântica, não apenas pelo avanço tecnológico em si, mas pela mudança estratégica que propõe na forma como sistemas quânticos são desenvolvidos, integrados e disponibilizados ao mundo. Trata-se de uma iniciativa que vai além das tradicionais bibliotecas ou frameworks de programação quântica, posicionando-se como uma camada fundamental da infraestrutura, o sistema operacional responsável por orquestrar toda a interação entre hardware quântico e sistemas clássicos.
O Origin Pilot, desenvolvido pela empresa chinesa Origin Quantum, foi disponibilizado publicamente como software open source, algo inédito no contexto de sistemas operacionais quânticos. Essa abertura marca uma ruptura com o modelo tradicional, onde o controle do stack tecnológico quântico desde o hardware até o software permanece fechado e altamente proprietário. Ao permitir o download e uso livre do sistema, a iniciativa busca reduzir barreiras de entrada e acelerar a adoção global da computação quântica, especialmente por universidades, startups e centros de pesquisa que não possuem infraestrutura completa própria.
Diferentemente de ferramentas como Qiskit ou Cirq, que operam em níveis mais altos da pilha tecnológica, o Origin Pilot atua em uma camada mais profunda: a de integração e gerenciamento do sistema. Ele funciona como um intermediário entre diferentes tipos de hardware quântico como qubits supercondutores, íons aprisionados e átomos neutros e os aplicativos desenvolvidos pelos usuários. Essa abordagem permite a criação de um ambiente unificado capaz de lidar com a heterogeneidade dos dispositivos quânticos, um dos maiores desafios atuais da área.
Do ponto de vista técnico, o sistema incorpora funcionalidades essenciais para o funcionamento eficiente de computadores quânticos. Entre elas estão o agendamento de tarefas quânticas, a alocação de qubits, a calibração automática dos sistemas e a execução paralela de múltiplos programas quânticos. Essas capacidades são críticas em ambientes NISQ (Noisy Intermediate-Scale Quantum), onde os recursos são limitados e altamente sensíveis a erros. O Origin Pilot também promove a integração entre computação clássica e quântica, permitindo pipelines híbridos que combinam CPUs, GPUs e QPUs em um mesmo fluxo de processamento.
Outro aspecto relevante é a capacidade do sistema de lidar com problemas específicos da computação quântica que não existem no mundo clássico. Questões como decoerência, ruído quântico e necessidade constante de recalibração exigem mecanismos sofisticados de controle em tempo real. O Origin Pilot incorpora algoritmos e estratégias voltadas para esses desafios, como o mapeamento eficiente de qubits e a otimização da fidelidade dos circuitos quânticos, garantindo melhor aproveitamento dos recursos disponíveis.
A proposta do Origin Pilot também carrega implicações estratégicas e geopolíticas. Ao disponibilizar gratuitamente uma camada de integração que ainda não possui equivalente aberto no Ocidente, a China pode influenciar diretamente o padrão de desenvolvimento global da computação quântica. Instituições ao redor do mundo podem optar por adotar esse sistema como base para seus projetos, o que, ao longo do tempo, cria um ecossistema dependente das abstrações, interfaces e arquiteturas definidas pela plataforma. Essa dinâmica lembra movimentos recentes no campo da inteligência artificial, onde a abertura de modelos e ferramentas levou à rápida expansão de determinados ecossistemas tecnológicos.
Além disso, o Origin Pilot faz parte de um esforço mais amplo de construção de uma infraestrutura quântica completa, que inclui hardware próprio, plataformas de nuvem quântica e ferramentas de desenvolvimento. Essa abordagem verticalizada busca reduzir a dependência de tecnologias estrangeiras e consolidar uma cadeia de valor autossuficiente. A disponibilização do sistema operacional como open source não apenas fortalece essa estratégia, mas também posiciona o país como um potencial definidor de padrões tecnológicos na próxima geração da computação.
Do ponto de vista do desenvolvedor, o impacto pode ser significativo. A existência de um sistema operacional quântico acessível permite experimentar com arquiteturas completas, sem a necessidade de construir toda a camada de integração do zero. Isso pode acelerar o desenvolvimento de aplicações práticas em áreas como criptografia, otimização, simulação de materiais e inteligência artificial quântica. Ao mesmo tempo, cria-se um novo paradigma de desenvolvimento, onde entender o comportamento do hardware e sua interação com o software passa a ser tão importante quanto escrever algoritmos quânticos.
Em síntese, o Origin Pilot não deve ser visto apenas como mais uma ferramenta no ecossistema quântico, mas como um passo em direção à maturidade da computação quântica como plataforma.
Assim como os sistemas operacionais clássicos foram fundamentais para a popularização dos computadores pessoais, iniciativas como essa podem desempenhar papel semelhante no futuro da computação quântica, definindo como os sistemas serão construídos, utilizados e evoluídos nas próximas décadas.
Referências:
https://www.globaltimes.cn/page/202602/1355718.shtml
https://postquantum.com/quantum-computing/china-quantum-os-origin-pilot/
https://medium.com/%40noahbean3396/quantum-computers-need-a-new-kind-of-operating-system-the-first-generation-just-arrived-aeeaa0c9bb60
https://en.chinadiplomacy.org.cn/2026-03/19/content_118390706.shtml
Download: https://qcloud.originqc.com.cn/en/programming/pilotos
OpenVINO 2026.1: Mais Modelos, Performance e um Salto Real na IA Multimodal
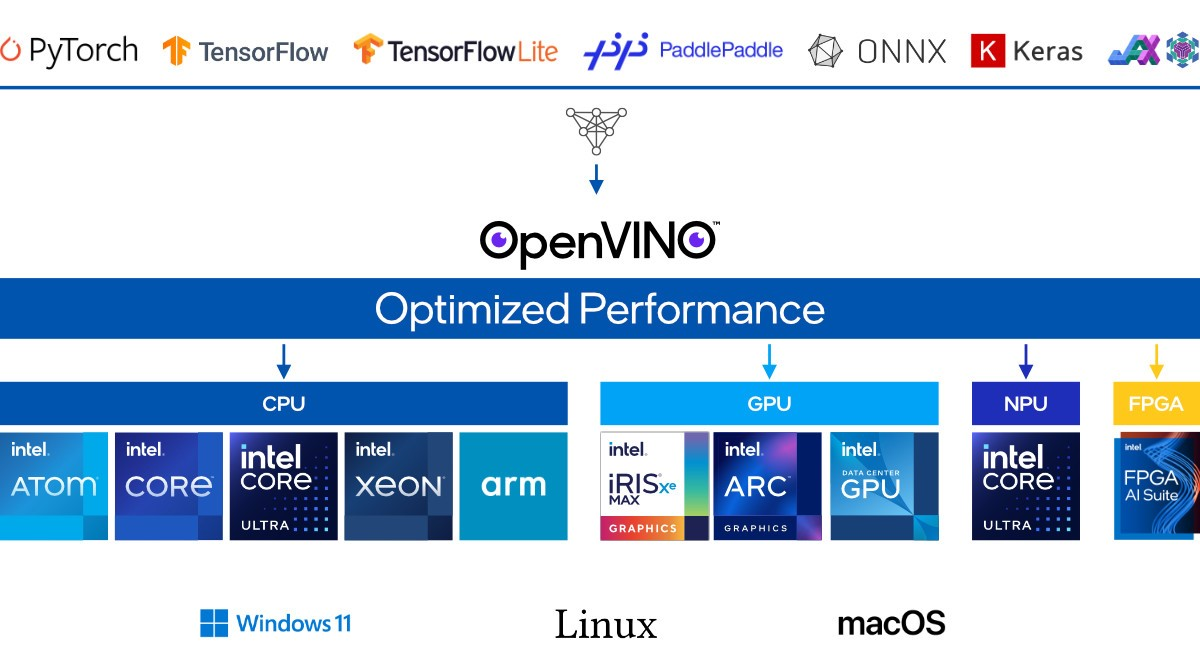
A evolução da inferência de IA em hardware Intel continua em ritmo acelerado, e o lançamento do OpenVINO 2026.1 consolida mais um avanço importante nessa jornada. Se a versão 2026.0 já havia estabelecido um novo patamar com suporte a Mixture of Experts (MoE), pipelines de Text-to-Video e técnicas mais inteligentes de compressão, a nova versão vai além: amplia significativamente o suporte a modelos, melhora a eficiência operacional e reforça o posicionamento do OpenVINO como uma das principais plataformas para inferência de IA em ambientes reais.
Mais do que uma atualização incremental, o OpenVINO 2026.1 representa uma resposta direta às demandas atuais do mercado: modelos maiores, workloads multimodais e a necessidade constante de reduzir latência sem comprometer qualidade.
Expansão de Modelos: Escalando a IA com Flexibilidade
Um dos pontos mais relevantes desta versão é a ampliação do suporte a modelos de grande porte e multimodais. O destaque vai para o suporte em CPU ao GPT-OSS 120B, um salto expressivo em relação à versão anterior (20B). Isso muda o jogo para organizações que precisam rodar modelos massivos sem depender exclusivamente de GPUs de alto custo.
Além disso, o suporte ao Qwen3 VL em CPU e GPU abre novas possibilidades para aplicações avançadas de visão computacional combinada com linguagem natural. Estamos falando de casos de uso como:
- Análise inteligente de imagens e vídeos
- Geração automática de descrições visuais
- Processamento documental com entendimento semântico
- Raciocínio multimodal em tempo real
Outro avanço importante está no OpenVINO Model Server, que agora suporta melhor modelos como Qwen3-MoE e GPT-OSS-20B. Com isso, há ganhos diretos em:
- Throughput via continuous batching
- Melhor uso de recursos em ambientes concorrentes
- Maior estabilidade em cenários de produção
E não para por aí: a introdução de endpoints de imagem com suporte a inpainting e outpainting leva o Model Server para além da inferência textual, entrando definitivamente no território da IA generativa visual.
LoRA Dinâmico e IA Multimodal: Eficiência em Escala
A adoção de LoRA dinâmico para modelos de visão e linguagem é um divisor de águas. Com suporte ao Qwen3-VL, o OpenVINO permite trocar adaptadores em tempo de execução sem recarregar o modelo base.
Na prática, isso resolve um problema crítico em produção: como servir múltiplas variações de um modelo sem multiplicar o consumo de memória e tempo de inicialização. O resultado é:
- Menor latência operacional
- Redução de custo de infraestrutura
- Maior flexibilidade para personalização de modelos
Outro ponto extremamente relevante é o novo notebook de referência que integra múltiplos VLMs, incluindo:
- Qwen2.5-VL
- LLaVA-Next-Video
Esse ambiente unificado permite explorar chatbots multimodais com suporte a vídeo e alternância dinâmica de modelos algo essencial para experimentação e benchmarking em cenários reais.
Performance: Onde o OpenVINO Realmente Brilha
Se há um ponto onde o OpenVINO tradicionalmente se destaca, é na otimização de performance e a versão 2026.1 reforça isso com avanços consistentes.
1. TaylorSeer Lite Caching
A introdução do caching TaylorSeer Lite para pipelines de difusão (como Flux, SD3 e LTX-Video) reduz computações redundantes durante o processo de denoising. Isso resulta em:
- Geração mais rápida de imagens e vídeos
- Menor consumo computacional
- Manutenção da qualidade do output
2. Otimizações em Vídeo (LTX-Video)
A fusão de operadores como RMSNorm e RoPE em um único kernel elimina overhead de execução sequencial. Esse tipo de otimização de baixo nível traz ganhos significativos:
- Redução de latência de kernel
- Menor uso de memória
- Aumento expressivo no throughput
3. Prompt Lookup Decoding
A extensão dessa técnica para pipelines multimodais é um dos avanços mais interessantes. Ao reutilizar padrões de tokens já processados, o sistema reduz a carga no modelo principal, acelerando a geração de tokens.
Isso é particularmente relevante para:
- Chatbots multimodais
- Assistentes com contexto longo
- Sistemas de análise documental
Um Novo Patamar para Inferência em Hardware Intel
O OpenVINO 2026.1 deixa claro que a estratégia da Intel não é apenas competir é redefinir o espaço de inferência eficiente. Ao permitir que modelos massivos rodem em CPU, otimizar pipelines multimodais e introduzir mecanismos inteligentes de caching e decoding, a plataforma se posiciona como uma solução altamente pragmática para empresas.
Em um cenário onde custo, performance e escalabilidade precisam coexistir, o OpenVINO oferece uma proposta extremamente equilibrada.
Para quem trabalha com IA aplicada seja em edge, cloud ou ambientes híbridos essa versão não é apenas uma atualização. É um convite para repensar arquitetura, otimizar pipelines e explorar novas possibilidades com modelos cada vez mais complexos.
Conclusão
O OpenVINO 2026.1 representa um avanço sólido na democratização da IA de alto desempenho. Com mais modelos, melhor suporte multimodal e otimizações profundas de performance, a plataforma continua evoluindo para atender às demandas reais do mercado.
Se você está construindo soluções com LLMs, VLMs ou pipelines generativos, este é o momento ideal para explorar o que há de novo e, principalmente, para extrair o máximo desempenho do hardware Intel com inteligência.
A próxima geração da IA não será apenas mais poderosa , será mais eficiente. E o OpenVINO está claramente liderando esse movimento.
Zupt: Backup open source com criptografia pós-quântica híbrida.

O Zupt é uma ferramenta open source de backup que combina compressao de dados com criptografia autenticada e, no modo --pq, proteção pós-quântica baseada em ML-KEM-768 + X25519. No repositório oficial, o projeto é descrito como uma solução em C11 puro, sem dependências externas, voltada para criar arquivos de backup comprimidos e, quando necessário, protegidos com criptografia clássica por senha ou com encapsulamento híbrido resistente ao cenário de computação quântica.
O projeto teve início com a implementação em C desenvolvida por Cristian Cezar Moises.
Como Membro e Embaixador openSUSE e Chapter Lider OWASP SP, entrei na iniciativa para viabilizar sua compilação em conformidade com os requisitos de compliance das distribuições Linux.
Além de atuar no port para as arquiteturas x86, ppc64le, armv7l, aarch64 e s390x. Esta primeira etapa está sendo realizada no openSUSE, permitindo que o DiraQ (um Linux de bolso para Computação Quântica que desenvolvi com Wilson Fonseca ) já incorpore esse recurso, cuja demonstração acontecerá no UNISO Quantum Day dia 7 de Abril.
A ideia central do Zupt é simples: transformar backup em um único fluxo operacional. Em vez de usar uma ferramenta para compactar, outra para cifrar e outra para validar integridade, o Zupt concentra tudo em um só utilitário. O projeto destaca compressão, autenticação por bloco, execução multithread, ocultação de nomes/estrutura dos arquivos dentro do archive e um modo pós-quântico para arquivos que precisam continuar confidenciais por muitos anos.
OK, mas o que significa “pós-quântico” no Zupt
Para entender o diferencial do Zupt, é importante entender o papel do ML-KEM. O NIST define ML-KEM em seu padrão FIPS 203 como um KEM (Key-Encapsulation Mechanism), isto é, um mecanismo de encapsulamento de chave que permite a duas partes estabelecerem um segredo compartilhado por um canal público, para depois usar esse segredo em algoritmos simétricos de criptografia e autenticação. O padrão prevê três conjuntos de parâmetros: ML-KEM-512, ML-KEM-768 e ML-KEM-1024. (Fonte NIST)
No Zupt, o modo --pq usa especificamente o ML-KEM-768, que o próprio SECURITY.md classifica como um esquema de nível de segurança NIST 3, combinado com X25519 em um desenho híbrido. Em outras palavras, o archive não depende só de um algoritmo “novo” pós-quântico, nem só de um algoritmo clássico consagrado: ele deriva a chave de proteção a partir da combinação dos dois. Isso torna o modelo particularmente interessante para migração gradual, porque ele mantém a robustez clássica e adiciona uma camada pensada para a ameaça quântica.
O repositório resume esse benefício com a expressão “harvest now, decrypt later”. Esse risco descreve o cenário em que um adversário intercepta dados cifrados hoje, armazena tudo e espera o futuro, quando a computação quântica ou novos ataques possam quebrar mecanismos clássicos.
O README do Zupt diz explicitamente que o modo --pq existe para enfrentar esse problema; o SECURITY.md reforça que o modo com senha (-p) não é quântico-seguro e recomenda --pq para proteção de longo prazo.
Quando o projeto afirma que essa ideia segue a mesma linha de produtos como Signal e iMessage, a comparação faz sentido no nível conceitual: o Signal documenta seu protocolo PQXDH como uma combinação de X25519 com Kyber/ML-KEM, e a Apple também descreve sua transição para criptografia híbrida pós-quântica no iMessage/PQ3 como resposta ao risco de ataques futuros contra material coletado hoje. O ponto principal não é que Zupt replique literalmente esses protocolos de mensageria, mas que ele adota a mesma filosofia de hibridização entre o mundo clássico e o pós-quântico. (Fonte Signal)
Como o modo --pq funciona na prática
O fluxo híbrido do Zupt funciona assim: a chave pública do destinatário é usada em uma encapsulação ML-KEM-768; ao mesmo tempo, o programa faz uma troca baseada em X25519; depois, os segredos resultantes são combinados e passam por SHA3-512 para derivar duas chaves: uma de cifragem e outra de autenticação. Essas chaves então alimentam o mecanismo simétrico já usado pelo programa, baseado em AES-256-CTR para confidencialidade e HMAC-SHA256 para integridade.
A consequência prática desse desenho é importante: o projeto afirma que o archive continua protegido se pelo menos um dos dois componentes permanecer seguro. Ou seja, mesmo que no futuro surja uma quebra relevante contra X25519, o componente ML-KEM-768 ainda sustentaria a segurança; e, no cenário inverso, o componente clássico ainda adicionaria proteção enquanto permanecesse confiável. Esse é exatamente o valor de um desenho híbrido em uma fase de transição criptográfica.
O que mais o Zupt oferece além do modo pós-quântico
Embora o modo --pq seja o grande diferencial, o Zupt não é “só” um experimento de criptografia. O README destaca compressão, autenticação por bloco, paralelismo e um codec chamado VaptVupt, descrito como o codec padrão da linha 2.0, combinando LZ77 + tANS com aceleração AVX2 para descompressão (Uau).
O projeto também apresenta comparação funcional com gzip, zstd e 7-Zip, ressaltando que o ganho do Zupt não é apenas taxa de compressão, mas a soma de compressão, integridade, criptografia e independência de bibliotecas externas. Também vale uma observação editorial importante para o seu artigo: no momento da consulta, a página do repositório mostrava v1.5.5 como release mais recente publicada, mas o README do branch master já descrevia a linha 2.0-RC e seus recursos, incluindo o VaptVupt como padrão. Para um texto técnico honesto, vale explicitar que parte da documentação do projeto reflete uma transição de versões.
Instalação do Zupt a partir dos fontes no openSUSE
No fluxo de compilação a partir do GitHub, o README oficial documenta um processo direto: clonar o repositório, entrar no diretório, executar make e depois sudo make install. O Makefile confirma que o compilador padrão é gcc, que o binário gerado chama-se zupt e que a instalação, por padrão, vai para /usr/local/bin. Como o procedimento usa git clone, make e gcc, no openSUSE o caminho mais lógico é preparar o ambiente com esses pacotes antes da compilação.
Os pré-requisitos mínimos no openSUSE podem ser instalados assim:
sudo zypper install git gcc make
Em seguida, faça a compilação:
git clone https://github.com/cristiancmoises/zupt.git
cd zupt
make
sudo make install
Depois da instalação, você pode confirmar que o binário entrou corretamente no sistema com:
which zupt
zupt version
zupt help
Esse fluxo está alinhado ao README e ao Makefile do projeto, que mostram build sem dependências externas além do toolchain C padrão.
Instalação do Zupt via zypper no openSUSE

O README também documenta instalação por pacote no ecossistema openSUSE. No trecho consultado, a instrução publicada era adicionar o repositório da iniciativa e instalar o pacote com zypper. Como o texto do repositório explicitava o exemplo para openSUSE 16.0, o mais correto é reproduzir exatamente esse procedimento no artigo, sem extrapolar para versões que não estejam listadas no README consultado.
sudo zypper addrepo https://download.opensuse.org/repositories/home:cabelo:innovators/16.0/home:cabelo:innovators.repo
sudo zypper refresh
sudo zypper install zupt
Após isso, os mesmos comandos de verificação continuam válidos:
zupt version
zupt help
Esse método é o mais prático para quem quer começar rapidamente, enquanto a instalação via fonte é mais interessante para auditoria de código, testes com mudanças locais ou validação de uma branch específica.
Uso básico do Zupt
A interface principal do programa gira em torno de alguns subcomandos: compress, extract, list, test, bench, keygen, version e help. O README mostra o formato geral como zupt compress [OPTIONS] <output.zupt> <files/dirs...> e zupt extract [OPTIONS] <archive.zupt>, além de opções como nível de compressão, número de threads, senha, modo pós-quântico, saída de extração e modos de codec.
1. Criando um backup simples sem criptografia
Para apenas compactar arquivos, o uso básico documentado é:
zupt compress backup.zupt ~/Documents/
Esse comando cria um archive .zupt usando o codec padrão documentado no branch atual do projeto. É o modo indicado para dados não sensíveis ou para testes rápidos de desempenho e formato.
2. Criando um backup com senha
Se a intenção é proteger o conteúdo com senha, o README mostra:
zupt compress -p "changeme" backup.zupt ~/Documents/
Nesse caso, o SECURITY.md diz que a derivação passa por PBKDF2-SHA256 e gera chaves para AES-256-CTR + HMAC-SHA256. É uma proteção útil para uso comum, mas a própria documentação alerta que esse modo não é o indicado para proteção de longo prazo contra ameaça quântica.
3. Extraindo um backup
Para restaurar o conteúdo em um diretório específico, o fluxo documentado é:
zupt extract -o ~/restored/ backup.zupt
Se o archive tiver sido protegido com senha, a senha deve ser informada no comando; se tiver sido criado com --pq, será preciso usar a chave privada correspondente. A opção -o define o diretório de destino da restauração.
4. Criando um backup pós-quântico
O modo pós-quântico documentado no README envolve primeiro gerar um par de chaves, depois exportar a chave pública e usá-la na compressão:
zupt keygen -o mykey.key
zupt keygen --pub -o pub.key -k mykey.key
zupt compress --pq pub.key backup.zupt ~/Documents/
Para extrair depois:
zupt extract --pq mykey.key -o ~/restored/ backup.zupt
A lógica é semelhante a fluxos de criptografia de chave pública: quem cria o backup usa a chave pública para proteger o archive, e só quem possui a chave privada consegue abrir o conteúdo. Para arquivos arquivísticos, backups frios, documentos estratégicos e material com exigência de sigilo prolongado, este é o modo mais interessante do Zupt.
5. Listando, testando e ajustando o comportamento
Além de comprimir e extrair, o README informa que o Zupt também oferece:
zupt list backup.zupt
zupt test backup.zupt
list serve para inspecionar o archive, e test para validar integridade. O projeto também documenta -l <1-9> para nível de compressão, -t <N> para número de threads, -s para armazenar sem compressão, -f para codec rápido legado e --solid para modo sólido. Isso permite adaptar o comportamento entre velocidade, taxa de compressão e custo de CPU.
Cuidados e limitações que merecem atenção
Um artigo técnico sobre o Zupt fica mais forte quando menciona não apenas os recursos, mas também os limites atuais. O COMPAT.md informa, por exemplo, que links simbólicos são ignorados, arquivos especiais também podem ser ignorados, e as permissões dos arquivos ainda não são restauradas na extração; o documento também cita limites para tamanho de bloco, quantidade de arquivos e algumas restrições de modo sólido.
Além disso, o README do branch atual é explícito ao dizer que a linha 2.0-RC já está adequada para uso pessoal e testes, mas ainda não é indicada para ambientes críticos ou grandes volumes de dados. Portanto, um texto responsável deve apresentar o Zupt como uma ferramenta muito promissora, tecnicamente interessante e especialmente relevante por trazer criptografia híbrida pós-quântica ao universo de backup, mas ainda em evolução.
Conclusão
O Zupt se destaca por atacar um problema real com uma abordagem moderna: backup não é só compactar arquivos, é preservar confidencialidade, integridade e recuperabilidade por muitos anos. Ao combinar compressão, autenticação por bloco, execução paralela e um modo híbrido ML-KEM-768 + X25519, a ferramenta entra em um espaço ainda pouco explorado por utilitários de backup open source. O grande valor do projeto está justamente em aproximar a discussão de criptografia pós-quântica da operação cotidiana de backup.
Vazamento do Claude Code: expõe meio milhão de linhas de IA
No dia 31 de março de 2026, um evento chamou a atenção da comunidade de engenharia de software e segurança: o suposto vazamento completo do código-fonte do Claude Code, CLI oficial da Anthropic.
Mas o mais curioso?
Não foi um ataque sofisticado.
Foi algo muito mais comum e perigoso: um source map publicado no npm.
O que aconteceu
Um pesquisador de segurança identificou que o pacote @anthropic-ai/claude-code incluía um arquivo .map de aproximadamente 57 MB, contendo o código original completo da aplicação. Esse tipo de arquivo é usado normalmente para debug, mapeando código minificado de volta ao original mas, neste caso, ele continha todo o código em texto puro dentro da propriedade sourcesContent.
O resultado:
- ~1.900 arquivos
- 512.000+ linhas de código TypeScript
- Arquitetura completa de produção exposta
Ou seja: não foi um
leak parcial.
Foi o sistema inteiro.
O que existe dentro do Claude Code
O vazamento revelou algo muito mais interessante do que apenas código revelou como uma IA moderna de desenvolvimento realmente funciona por dentro.
Arquitetura real (não marketing)
O Claude Code não é apenas um wrapper de chat. Ele é um sistema complexo com:
-
Sistema de ferramentas (tool-based)
Cada ação (ler arquivo, executar bash, buscar web) é um módulo isolado e com permissões. -
Query Engine (~46k linhas)
Responsável por orquestrar chamadas ao modelo, cache, streaming e controle de execução. -
Multi-agentes (“swarms”)
Capacidade de criar agentes paralelos para resolver tarefas complexas. -
Integração com IDEs
Comunicação com VS Code e JetBrains via canais autenticados.
Tudo isso rodando sobre Bun + React (Ink) no terminal.
O que mais chamou atenção (e preocupa)
Esse tipo de vazamento não expõe só código ele expõe modelo mental e decisões de segurança.
Entre os pontos críticos identificados:
- System prompts e lógica interna de comportamento
- Modelo de permissões de ferramentas
- Proteções contra path traversal e acesso indevido
- Features beta não lançadas
- Estratégias de orquestração de agentes
Além disso, foram encontrados codenames internos como:
- KAIROS → modo persistente “always-on”
- Capybara → outro subsistema interno
- Flags de recursos como:
- contexto de 1 milhão de tokens
- “interleaved thinking”
- controle de esforço e modo rápido
A falha real: supply chain e build pipeline
O mais importante aqui não é o Claude. É o padrão. Esse incidente reforça um problema recorrente:
Falhas em pipelines de build e publicação são hoje uma das maiores superfícies de ataque.
O erro foi simples:
- O bundler gerou
.map - O
.npmignorenão excluiu - Nenhum pre-check validou o pacote antes do publish
Resultado: qualquer pessoa com npm pack tinha acesso ao código inteiro.
Insight estratégico (o que isso nos ensina)
Esse caso revela três coisas fundamentais sobre o futuro da IA:
1. IA moderna = sistemas complexos, não modelos isolados
O diferencial não está só no LLM está na orquestração.
2. Segurança de IA não é só prompt injection
É:
- supply chain
- permissões de ferramentas
- controle de execução
3. Transparência involuntária acelera aprendizado global
Mesmo sendo um incidente, ele oferece um “raio-x” de como sistemas state-of-the-art são construídos.
Conexão com o futuro (e com o que estamos construindo)
Se você trabalha com:
- sistemas multi-agente
- execução local/offline de IA
- orquestração de ferramentas
Esse vazamento praticamente confirma uma direção:
O futuro da IA está na integração entre modelo + sistema operacional + runtime de execução.
Algo muito próximo do que já vemos emergindo em iniciativas como:
- AI-native OS
- agentes autônomos
- computação heterogênea (CPU + GPU + NPU)
Conclusão
Não foi apenas um vazamento. Foi um lembrete.Onde:
- segurança básica ainda falha
- sistemas de IA são mais complexos do que parecem
- e estamos apenas começando a entender como esses sistemas realmente funcionam
E talvez o ponto mais importante:
Quem dominar a arquitetura, não só o modelo vai dominar a próxima geração da IA.
VLM + CNN + Agentes: Como Resolver o “ECA Digital” no Linux sem Nuvem e preservando a privacidade do usuário.
Nos últimos dias, muito se discutiu muitas vezes com desinformação sobre a aplicação de conceitos do chamado “ECA Digital” (ou apelidado de “Lei Felca”) no ecossistema Linux. A narrativa dominante sugere restrições, controle excessivo ou até inviabilidade do uso de sistemas abertos.
E esse problema já tem solução.
É possível implementar mecanismos de proteção infantil diretamente no sistema operacional Linux, de forma 100% offline, sem coleta de dados e sem dependência de cloud, utilizando o estado da arte em Inteligência Artificial: VLMs (Vision-Language Models), redes neurais convolucionais (CNNs) e agentes inteligentes.
O Problema: Controle de Acesso por Idade no Linux
Ambientes Linux tradicionalmente utilizam autenticação baseada em senha, chave ou biometria simples. Porém, nenhum desses mecanismos responde a uma pergunta essencial no contexto do ECA Digital:
Quem está tentando obter privilégios administrativos é realmente um adulto autorizado?
Isso abre espaço para cenários comuns:
- Crianças tentando instalar software inadequado
- Uso indevido de credenciais dos pais
- Escalada de privilégio sem contexto de idade
A Solução: VLM + CNN com Agentes Inteligentes
A arquitetura proposta combina três componentes principais:
1. VLM (Vision-Language Model)
O VLM atua como camada semântica, interpretando a cena capturada pela câmera:
- Contexto do usuário diante do dispositivo
- Interação com prompts de validação
- Auxílio na inferência de idade com base visual
2. CNN (Redes Neurais Convolucionais)
As CNNs são responsáveis pela parte crítica:
- Detecção facial em tempo real
- Estimativa de idade (age estimation)
- Classificação etária (criança vs adulto)
Esse modelo é otimizado para execução local (edge), sem necessidade de GPU de alto custo.
3. Agentes de Decisão
Agentes inteligentes orquestram o fluxo:
- Validam se a ação requer privilégio root
- Disparam a análise visual
- Decidem permitir ou bloquear a operação
Teste de Vivacidade (Liveness Detection)
Um dos pontos mais importantes do sistema é evitar fraudes. Não basta detectar um rosto é necessário garantir que ele é real. O sistema impede ataques usando foto impressas e Vídeos doa pais.
Privacidade por Design: 100% Offline
Diferente de soluções comerciais, este modelo segue um princípio fundamental:
Nenhum dado é armazenado. Nenhuma imagem sai da máquina.
Características:
- Processamento local (edge computing)
- Sem envio para APIs externas
- Sem armazenamento de imagens ou embeddings
- Apenas decisão binária em tempo real (permitir/bloquear)
Isso elimina riscos de:
- Vazamento de dados
- Compliance com LGPD
- Dependência de serviços cloud
Integração Profunda com Linux via PAM
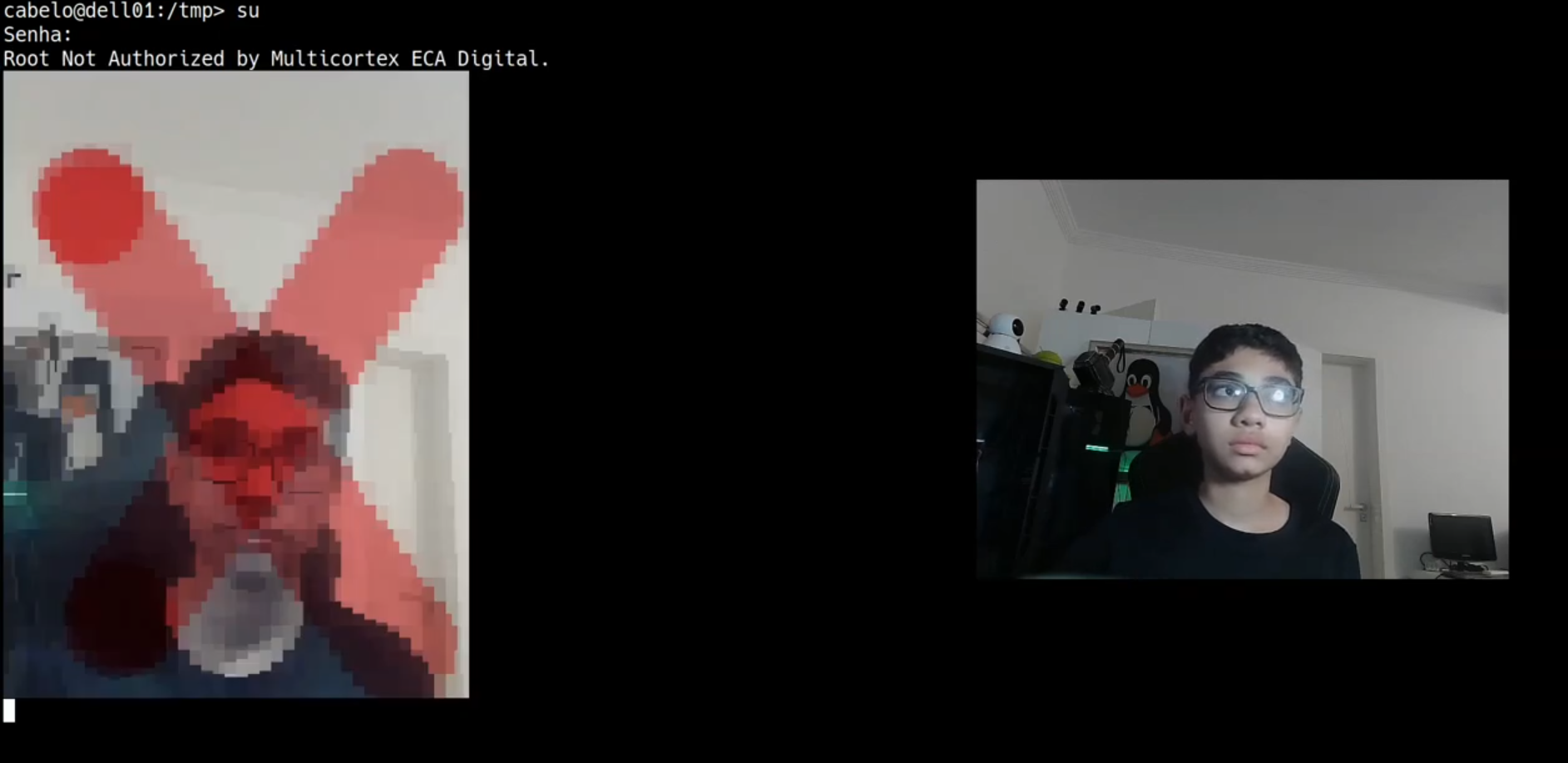
Toda essa inteligência não roda como um aplicativo isolado. Ela foi integrada diretamente ao sistema de autenticação do Linux através do PAM (Pluggable Authentication Modules).
Como funciona na prática:
- Usuário executa um comando com
sudoou tenta acesso root - O PAM intercepta a requisição
- O módulo customizado ativa o pipeline de IA
- A câmera captura o rosto do usuário
- O modelo CNN + VLM analisa idade e vivacidade
- O agente decide:
-
 Adulto → libera autenticação
Adulto → libera autenticação -
 Criança → bloqueia operação
Criança → bloqueia operação
-
 Adulto → libera autenticação
Adulto → libera autenticação Criança → bloqueia operação
Criança → bloqueia operaçãoTudo isso acontece antes da concessão de privilégios.
Vantagens dessa abordagem:
- Transparente para o usuário
- Integrado ao sistema operacional
- Funciona com qualquer aplicação que use PAM (sudo, login, ssh, etc.)
- Baixo impacto de performance
Impacto no Mercado: Linux Compatível com ECA Digital
Essa abordagem resolve diretamente o principal argumento usado contra o Linux em ambientes regulados:
“Linux não tem controle de acesso por idade”
Agora tem e de forma mais avançada que qualquer sistema tradicional.
Benefícios:
- Adequação ao conceito de ECA Digital
- Controle parental real, não apenas superficial
- Segurança sem invasão de privacidade
- Total soberania de dados (zero cloud)
Conclusão
O debate sobre restrições ao Linux baseado em desinformação ignora o avanço tecnológico disponível hoje.
Combinando:
- VLM
- CNN
- Agentes inteligentes
- Integração via PAM
é possível criar um sistema de controle de privilégios inteligente, privado e totalmente offline.
Isso não apenas resolve as preocupações do mercado como posiciona o Linux à frente, oferecendo uma solução mais segura, auditável e alinhada com princípios modernos de privacidade. Vejam o sistema funcionando abaixo:
Lei 15.211/2025, Linux e pânico digital: quando ninguém lê a lei e compartilham pânico.

A repercussão em torno da Lei 15.211/2025 mostrou, mais uma vez, como informação sem fundamento pode ser transformada em histeria coletiva quando quase ninguém se dá ao trabalho de ler o texto original da norma. No lugar da leitura, entrou o impulso por curtidas, engajamento e manchetes apocalípticas. O resultado foi previsível: uma onda de desinformação sobre uma suposta “proibição do Linux no Brasil”.
Nos últimos dias, recebi diversos e-mails e mensagens de pessoas preocupadas com a ideia de que a chamada “Lei Felca” abriria caminho para banir distribuições Linux no país. A narrativa se espalhou com velocidade impressionante, impulsionada principalmente por gente que jamais instalou, administrou ou sequer utilizou GNU/Linux de forma real no dia a dia, mas que se sentiu confortável para decretar o seu “fim” nas redes sociais.
O episódio ganhou ainda mais ruído em 17 de março, quando a distribuição Arch Linux 32 bloqueou o acesso a partir do Brasil. Para quem não conhece, trata-se de um projeto comunitário independente, um fork do Arch Linux tradicional, mantido para oferecer suporte a máquinas antigas com arquitetura de 32 bits (i686). A decisão desse projeto específico foi rapidamente tratada por muita gente como se fosse prova definitiva de que “o Linux havia sido bloqueado no Brasil”, o que evidentemente não corresponde aos fatos.
Falo disso com a tranquilidade de quem leva Linux a sério desde 1998, contribui com projetos open source e participa de palestras e iniciativas voltadas à comunidade. Para mim, usar Linux não é modismo, discurso de rede social ou bandeira ideológica de ocasião. É prática, trabalho árduo e convicção. Por isso, antes de repetir boatos, fui fazer o que quase ninguém fez: Buscar minimamente informações sobre a lei (Paulo Henrique Alkmin fez este trabalho).
A Lei nº 15.211, sancionada em setembro de 2025 e vigente a partir de 17 de março de 2026, institui o chamado Estatuto Digital da Criança e do Adolescente. O apelido “Lei Felca” surgiu em referência ao youtuber cujo vídeo sobre exploração infantil em redes sociais acelerou a tramitação do tema no Congresso. Até aí, tudo bem. O problema começou quando parte do debate público resolveu transformar uma leitura superficial em profecia técnica.
De fato, o Art. 1º estabelece que a lei se aplica a produtos e serviços de tecnologia da informação direcionados a crianças e adolescentes no país, ou com provável acesso por eles. Já o Art. 2º, inciso I, menciona exemplos como aplicações de internet, programas de computador, softwares, sistemas operacionais de terminais, lojas de aplicativos e jogos eletrônicos. Foi justamente a presença da expressão “sistemas operacionais” que bastou para disparar o pânico.
Mas o mais curioso é que a própria lei contém dispositivos que enfraquecem frontalmente a tese de que haveria espaço para uma proibição ampla de Linux ou qualquer outro sistema operacional (Obrigado novamente Paulo Henrique Alkmin ).
O primeiro ponto ignorado por quase todo mundo está no Art. 2º, § 2º, que exclui do escopo da lei as funcionalidades essenciais ao funcionamento da internet, incluindo protocolos e padrões técnicos abertos e comuns. Basta lembrar que o kernel Linux está presente em mais de 96% dos servidores web do mundo para perceber o tamanho do absurdo da narrativa criada. Estamos falando de uma base tecnológica central da infraestrutura global da internet, não de um aplicativo qualquer.
O segundo ponto relevante aparece no Art. 14, parágrafo único. Ali, a lei deixa claro que, independentemente das medidas adotadas por sistemas operacionais e lojas de aplicativos, os fornecedores das próprias aplicações devem implementar mecanismos para impedir o acesso indevido. Em outras palavras: a responsabilidade principal recai sobre a aplicação, não sobre o sistema operacional. Se uma rede social precisa adotar verificação etária, o dever primário é da plataforma. O sistema operacional pode até ter um papel complementar, mas não é o centro da obrigação.
O terceiro ponto, talvez o mais ignorado de todos, está no Art. 37, parágrafo único, que veda regulamentações que resultem em mecanismos de vigilância massiva, genérica ou indiscriminada, além de resguardar explicitamente direitos como liberdade de expressão e privacidade. Bloquear o uso de um sistema operacional inteiro como resposta regulatória seria, justamente, uma medida genérica, indiscriminada e incompatível com esse espírito.
Ou seja: bastariam três trechos da própria lei para desmontar a história do “Linux proibido”. Três dispositivos. No mesmo texto legal. Ainda assim, muita gente preferiu ignorá-los para manter viva a narrativa do caos.
A desinformação se espalhou em dois eixos ao mesmo tempo. De um lado, houve exploração política. De outro, houve um ruído técnico lamentável, inclusive entre pessoas da própria comunidade de tecnologia, que transformaram um “pode impactar discussões futuras” em “vai proibir o Linux”. É sempre mais fácil viralizar com uma frase catastrófica do que ler e interpretar os 37 artigos de uma lei.
Outro argumento que apareceu com frequência foi o de que o GNU/Linux “não teria mecanismos de controle parental” ou que seria incapaz de se adaptar a exigências legais voltadas à proteção de menores. Isso também revela desconhecimento técnico. O ecossistema Linux já dispõe de soluções concretas para esse tipo de necessidade. Há ferramentas como Malcontent, além de repositórios que exigem classificação etária de aplicativos com base no padrão OARS (Open Age Ratings Service). Também existem soluções como o Timekpr-nExT, que permite estabelecer limites diários, semanais e mensais de uso, e o CTparental, que oferece gestão de tempo e controle de conteúdo acessado ou baixado na internet.
Ou seja, além de a tese do “banimento” não se sustentar juridicamente, ela também fracassa tecnicamente. O GNU/Linux não é um ambiente sem recursos, sem governança ou sem capacidade de adaptação. Pelo contrário: justamente por ser aberto, auditável e colaborativo, ele frequentemente consegue responder com mais agilidade e transparência a desafios técnicos do que plataformas fechadas.
E digo mais: Se em algum momento surgisse uma exigência real para integração de verificação etária ou mecanismos complementares dentro do sistema operacional, a própria comunidade open source teria plena capacidade de responder.
Eu mesmo sozinho iria procurar a Serpro ou Gov.BR e implementaria integração com APIs com base de fé pública “e/ou privada” em módulos PAM, se necessário fosse. (exemplo vídeo abaixo). Agora imagine o que aconteceria se toda a comunidade resolvesse atacar o problema de forma coordenada. A chance de o resultado ser tecnicamente melhor do que o de plataformas proprietárias seria enorme.
No fim, esse episódio não fala apenas sobre Linux ou sobre a Lei 15.211/2025. Ele revela algo mais amplo e preocupante: a velocidade com que boatos se tornam “verdades” quando são emocionalmente convenientes. Em vez de leitura, contexto e análise, escolhe-se o pânico performático. Em vez de debate sério, produz-se barulho.
A lição é simples. Antes de decretar o fim do Linux, do software livre ou da internet como conhecemos, vale a pena fazer o básico: ler a lei. Porque, neste caso, o suposto escândalo nasceu muito menos do texto legal e muito mais da preguiça intelectual de quem preferiu acreditar na desinformação.

Use a FORÇA, Leia os fontes
e USE LINUX!
Lei 15.211/2025, Linux e pânico digital: quando ninguém lê a lei e compartilham notícias apocalípticas.
A repercussão em torno da Lei 15.211/2025 mostrou, mais uma vez, como informação sem fundamento pode ser transformada em histeria coletiva quando quase ninguém se dá ao trabalho de ler o texto original da norma. No lugar da leitura, entrou o impulso por curtidas, engajamento e manchetes apocalípticas. O resultado foi previsível: uma onda de desinformação sobre uma suposta “proibição do Linux no Brasil”.
Nos últimos dias, recebi diversos e-mails e mensagens de pessoas preocupadas com a ideia de que a chamada “Lei Felca” abriria caminho para banir distribuições Linux no país. A narrativa se espalhou com velocidade impressionante, impulsionada principalmente por gente que jamais instalou, administrou ou sequer utilizou GNU/Linux de forma real no dia a dia, mas que se sentiu confortável para decretar o seu “fim” nas redes sociais.
O episódio ganhou ainda mais ruído em 17 de março, quando a distribuição Arch Linux 32 bloqueou o acesso a partir do Brasil. Para quem não conhece, trata-se de um projeto comunitário independente, um fork do Arch Linux tradicional, mantido para oferecer suporte a máquinas antigas com arquitetura de 32 bits (i686). A decisão desse projeto específico foi rapidamente tratada por muita gente como se fosse prova definitiva de que “o Linux havia sido bloqueado no Brasil”, o que evidentemente não corresponde aos fatos.
Falo disso com a tranquilidade de quem leva Linux a sério desde 1998, contribui com projetos open source e participa de palestras e iniciativas voltadas à comunidade. Para mim, usar Linux não é modismo, discurso de rede social ou bandeira ideológica de ocasião. É prática, trabalho árduo e convicção. Por isso, antes de repetir boatos, fui fazer o que quase ninguém fez: Buscar minimamente informações sobre a lei (Paulo Henrique Alkmin fez este trabalho o que facilitou este post).
A Lei nº 15.211, sancionada em setembro de 2025 e vigente a partir de 17 de março de 2026, institui o chamado Estatuto Digital da Criança e do Adolescente. O apelido “Lei Felca” surgiu em referência ao youtuber cujo vídeo sobre exploração infantil em redes sociais acelerou a tramitação do tema no Congresso. Até aí, tudo bem. O problema começou quando parte do debate público resolveu transformar uma leitura superficial em profecia técnica.
De fato, o Art. 1º estabelece que a lei se aplica a produtos e serviços de tecnologia da informação direcionados a crianças e adolescentes no país, ou com provável acesso por eles. Já o Art. 2º, inciso I, menciona exemplos como aplicações de internet, programas de computador, softwares, sistemas operacionais de terminais, lojas de aplicativos e jogos eletrônicos. Foi justamente a presença da expressão “sistemas operacionais” que bastou para disparar o pânico.
Mas o mais curioso é que a própria lei contém dispositivos que enfraquecem frontalmente a tese de que haveria espaço para uma proibição ampla de Linux ou qualquer outro sistema operacional (Obrigado novamente Paulo Henrique Alkmin ).
O primeiro ponto ignorado por quase todo mundo está no Art. 2º, § 2º, que exclui do escopo da lei as funcionalidades essenciais ao funcionamento da internet, incluindo protocolos e padrões técnicos abertos e comuns. Basta lembrar que o kernel Linux está presente em mais de 96% dos servidores web do mundo para perceber o tamanho do absurdo da narrativa criada. Estamos falando de uma base tecnológica central da infraestrutura global da internet, não de um aplicativo qualquer.
O segundo ponto relevante aparece no Art. 14, parágrafo único. Ali, a lei deixa claro que, independentemente das medidas adotadas por sistemas operacionais e lojas de aplicativos, os fornecedores das próprias aplicações devem implementar mecanismos para impedir o acesso indevido. Em outras palavras: a responsabilidade principal recai sobre a aplicação, não sobre o sistema operacional. Se uma rede social precisa adotar verificação etária, o dever primário é da plataforma. O sistema operacional pode até ter um papel complementar, mas não é o centro da obrigação.
O terceiro ponto, talvez o mais ignorado de todos, está no Art. 37, parágrafo único, que veda regulamentações que resultem em mecanismos de vigilância massiva, genérica ou indiscriminada, além de resguardar explicitamente direitos como liberdade de expressão e privacidade. Bloquear o uso de um sistema operacional inteiro como resposta regulatória seria, justamente, uma medida genérica, indiscriminada e incompatível com esse espírito.
Ou seja: bastariam três trechos da própria lei para desmontar a história do “Linux proibido”. Três dispositivos. No mesmo texto legal. Ainda assim, muita gente preferiu ignorá-los para manter viva a narrativa do caos.
A desinformação se espalhou em dois eixos ao mesmo tempo. De um lado, houve exploração política. De outro, houve um ruído técnico lamentável, inclusive entre pessoas da própria comunidade de tecnologia, que transformaram um “pode impactar discussões futuras” em “vai proibir o Linux”. É sempre mais fácil viralizar com uma frase catastrófica do que ler e interpretar os 37 artigos de uma lei.
Outro argumento que apareceu com frequência foi o de que o GNU/Linux “não teria mecanismos de controle parental” ou que seria incapaz de se adaptar a exigências legais voltadas à proteção de menores. Isso também revela desconhecimento técnico. O ecossistema Linux já dispõe de soluções concretas para esse tipo de necessidade. Há ferramentas como Malcontent, além de repositórios que exigem classificação etária de aplicativos com base no padrão OARS (Open Age Ratings Service). Também existem soluções como o Timekpr-nExT, que permite estabelecer limites diários, semanais e mensais de uso, e o CTparental, que oferece gestão de tempo e controle de conteúdo acessado ou baixado na internet.
Ou seja, além de a tese do “banimento” não se sustentar juridicamente, ela também fracassa tecnicamente. O GNU/Linux não é um ambiente sem recursos, sem governança ou sem capacidade de adaptação. Pelo contrário: justamente por ser aberto, auditável e colaborativo, ele frequentemente consegue responder com mais agilidade e transparência a desafios técnicos do que plataformas fechadas.
E digo mais: Se em algum momento surgisse uma exigência real para integração de verificação etária ou mecanismos complementares dentro do sistema operacional, a própria comunidade open source teria plena capacidade de responder.
Eu mesmo sozinho iria procurar a Serpro ou Gov.BR e implementaria integração com APIs com base de fé pública “e/ou privada” em módulos PAM, se necessário fosse. (exemplo vídeo abaixo). Agora imagine o que aconteceria se toda a comunidade resolvesse atacar o problema de forma coordenada. A chance do resultado ser tecnicamente melhor comparado as plataformas proprietárias seria enorme.
No fim, esse episódio não fala apenas sobre Linux ou sobre a Lei 15.211/2025. Ele revela algo mais amplo e preocupante: a velocidade com que boatos se tornam “verdades” quando são emocionalmente convenientes. Em vez de leitura, contexto e análise, escolhe-se o pânico performático. Em vez de debate sério, produz-se barulho.
A lição é simples. Antes de decretar o fim do Linux, do software livre ou da internet como conhecemos, vale a pena fazer o básico: ler a lei. Porque, neste caso, o suposto escândalo nasceu muito menos do texto legal e muito mais da preguiça intelectual de quem preferiu acreditar na desinformação.
Use a FORÇA, Leia os fontes
e USE LINUX!
Granite 4.0 1B Speech: IA de voz compacta para o edge

Visão geral
Granite 4.0 1B Speech é o novo modelo de fala aberto da família Granite, da IBM, voltado para reconhecimento automatico de fala (ASR) e tradução automática de fala (AST) em múltiplos idiomas. Com cerca de 1 bilhão de parâmetros, ele foi desenhado para rodar em dispositivos com recursos limitados, mantendo desempenho competitivo frente a modelos bem maiores, inclusive em benchmarks públicos como o OpenASR.
O modelo é distribuído com pesos abertos, sob licença Apache 2.0, e já está integrado ao ecossistema de ferramentas como Hugging Face Transformers e vLLM, facilitando a adoção por desenvolvedores e empresas.
Principais capacidades
Granite 4.0 1B Speech é um modelo de linguagem de fala (“speech-language model”) capaz de:
- Reconhecimento automático de fala (ASR) em seis idiomas: inglês, francês, alemão, espanhol, português e japonês.
- Tradução automática de fala (AST) bidirecional entre esses idiomas e o inglês, além de pares adicionais como inglês–italiano e inglês–mandarim em cenário de fala-para-texto-para-texto.
- Processamento de entradas apenas de texto, reaproveitando o backbone Granite 4.0 1B como um modelo de linguagem tradicional quando não há áudio.
Além disso, a versão 4.0 introduz dois recursos bastante pedidos pela comunidade: suporte completo a ASR em japonês e “keyword list biasing”, que permite enviesar a decodificação para reconhecer melhor nomes próprios, siglas e termos específicos de domínio.
O que muda em relação ao Granite Speech 3.3
Granite 4.0 1B Speech sucede a linha Granite Speech 3.3, que incluía variantes de 2B e 8B parâmetros focadas principalmente em ASR em inglês e AST para alguns idiomas europeus e asiáticos. Enquanto o Granite Speech 3.3 8B já superava modelos abertos e fechados em tarefas de transcrição em inglês, ele exigia mais memória e poder computacional, o que limitava usos em cenários de edge ou dispositivos embarcados.
Na nova geração, a IBM reduz o número de parâmetros pela metade em relação ao granite-speech-3.3-2b, mantendo ou melhorando a acurácia em inglês e ampliando o suporte multilíngue. Isso é viabilizado por melhorias na arquitetura, na estratégia de alinhamento entre áudio e texto e no uso de técnicas de inferência como speculative decoding, que aceleram significativamente o tempo de resposta.
Arquitetura em alto nível
Granite 4.0 1B Speech segue a linha dos modelos Granite Speech anteriores: um encoder acústico especializado é acoplado a um modelo de linguagem de propósito geral (Granite 4.0 1B Base), alinhado para operar sobre embeddings de fala.
No encoder de áudio, a IBM utiliza 16 blocos Conformer treinados com CTC (Connectionist Temporal Classification) sobre um vocabulário de caracteres ASCII para idiomas europeus e um conjunto fonético de Katakana para japonês. Esse encoder incorpora block-attention com janelas de 4 segundos e self-conditioned CTC, reduzindo o custo computacional e melhorando a robustez em áudios longos.
Entre o encoder de fala e o LLM, há um adaptador de modalidade baseado em Windowed Query Transformer (Q-Former), responsável por reduzir a sequência temporal e projetar os embeddings acústicos para o espaço de embeddings de texto do Granite 4.0. O modelo de linguagem em si herda o backbone Granite 4.0 1B, que usa uma arquitetura híbrida Mamba‑2/Transformer, com foco em eficiência de memória e latência, além de oferecer contexto longo (até 128k tokens) em algumas variantes.
Desempenho em benchmarks
Apesar do tamanho relativamente pequeno, Granite 4.0 1B Speech alcançou a primeira posição no OpenASR Leaderboard, com word error rate (WER) médio em torno de 5,5%, superando modelos como Whisper Large V3, Phi-4 Multimodal e Canary 1B Flash. Esses resultados mostram que é possível combinar compacidade com alta qualidade de transcrição, algo especialmente relevante para aplicações em produção com custos de infra estrita.
Nos benchmarks de ASR em inglês, o modelo atinge WER competitivo ou superior em relação a sistemas com muito mais parâmetros, mantendo boa performance também em cenários multilíngues. Em AST, o modelo acompanha ou se aproxima de modelos maiores nos pares de idioma suportados, com destaque para traduções inglês–europeu e inglês–japonês/chinês.
Licença, governança e segurança
Assim como os demais modelos Granite 4.0, o 1B Speech é liberado sob licença Apache 2.0, o que permite uso comercial, modificações e redistribuição, desde que mantidos os avisos de copyright e licença. A IBM destaca que os modelos compactos seguem o mesmo padrão de governança, rastreabilidade de dados e certificações (incluindo conformidade com ISO 42001) adotado na família Granite maior.
Para deployments em produção, a recomendação é integrar o modelo com o Granite Guardian, camada de segurança e detecção de riscos que ajuda a mitigar abusos, vazamento de dados sensíveis e outros comportamentos indesejados. Isso é especialmente relevante em cenários regulados, como saúde, finanças e setor público, em que logs de áudio e transcrições podem conter informações altamente sensíveis.
Casos de uso típicos
Granite 4.0 1B Speech é particularmente atrativo para cenários de edge e aplicações empresariais que precisam de processamento de fala local.
Alguns exemplos de uso incluem:
- Contact centers e voicebots corporativos, com reconhecimento de fala em tempo real em múltiplos idiomas e opção de tradução on-the-fly para agentes humanos.
- Sistemas embarcados em veículos, equipamentos industriais ou dispositivos IoT, onde a comunicação por voz precisa funcionar mesmo com conectividade limitada.
- Ferramentas de produtividade, como assistentes pessoais, sistemas de tomada de notas em reuniões e legendagem automática, com possibilidade de rodar localmente em notebooks potentes ou estações de trabalho.
- Aplicações multilíngues em ambientes regulados, que exigem maior controle sobre dados de áudio e transcrições, evitando o envio de informações para serviços externos proprietários.
No contexto de desenvolvimento de agentes e pipelines RAG, o modelo também pode atuar como front-end de voz para um LLM de texto maior, convertendo áudio em texto que depois será enriquecido com contexto externo e respondido de volta ao usuário, possivelmente com síntese de voz em outro componente.
Como experimentar o modelo
O Granite 4.0 1B Speech está disponível no Hugging Face sob o identificador ibm-granite/granite-4.0-1b-speech, com documentação detalhada, exemplos de uso e instruções de inferência via Transformers e vLLM.
Um exemplo simplificado de uso com vLLM demonstra como carregar o modelo, aplicar o template de chat e enviar um áudio junto com a instrução para obter a transcrição:
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
from vllm.assets.audio import AudioAsset
model_id = "ibm-granite/granite-4.0-1b-speech"
tokenizer = AutoTokenizer.from_pretrained(model_id)
def get_prompt(question: str, has_audio: bool):
if has_audio:
question = f"<|audio|>{question}"
chat = [{"role": "user", "content": question}]
return tokenizer.apply_chat_template(chat, tokenize=False)
model = LLM(
model=model_id,
max_model_len=2048,
limit_mm_per_prompt={"audio": 1},
)
question = "can you transcribe the speech into a written format?"
prompt_with_audio = get_prompt(question=question, has_audio=True)
audio = AudioAsset("mary_had_lamb").audio_and_sample_rate
inputs = {"prompt": prompt_with_audio, "multi_modal_data": {"audio": audio}}
outputs = model.generate(
inputs,
sampling_params=SamplingParams(temperature=0.2, max_tokens=64),
)
print(outputs[0].outputs[0].text)
Além da integração com vLLM, o modelo pode ser consumido via API ou contêineres preparados por parceiros e pela própria IBM, seguindo a mesma lógica de outros modelos Granite 4.0.
Por que o Granite 4.0 1B Speech é relevante
A combinação de abertura de pesos, licença permissiva, eficiência computacional e desempenho de ponta em benchmarks públicos torna o Granite 4.0 1B Speech um candidato natural para empresas que querem construir soluções de voz sem ficarem presas a serviços proprietários. O fato de o modelo liderar rankings como o OpenASR, mesmo com apenas 1 bilhão de parâmetros, mostra que há espaço para arquiteturas mais enxutas competirem com gigantes em tarefas de ASR e AST.
Para times de engenharia, isso se traduz em custos menores de GPU/CPU, possibilidade de deployment on-premises ou no edge e mais controle sobre toda a cadeia de dados de áudio.
Para a comunidade, é mais um passo na direção de um ecossistema de IA de voz verdadeiramente aberto, no qual modelos de fala de alta qualidade podem ser auditados, adaptados e combinados com outras peças (TTS, LLMs de texto, agentes) sem barreiras artificiais.
Até o próximo post.
OWASP SP disponibiliza ModSecurity (CRS) para openSUSE.

Hoje dia 09 de Março de 2026 às 14h30, uma hora a após lançar a versão 4.21.1 do OWASP CRS, o Capítulo SP disponibilizou esta versão para todas as versões da plataforma openSUSE LINUX. Isto demonstra o nosso compromisso com a evangelização e colaboração com a comunidade de desenvolvedores de Software Livre.
OWASP CRS é um conjunto de regras genéricas de detecção de ataques para uso com o ModSecurity ou firewalls de aplicações web compatíveis. O CRS visa proteger aplicações web contra uma ampla gama de ataques, incluindo os dez principais da OWASP, com um mínimo de falsos positivos.
OWASP Core Rule Set 4.24.1: Atualização das regras de proteção para WAF
Foi disponibilizada a nova versão 4.24.1 do OWASP Core Rule Set (CRS), um dos conjuntos de regras mais utilizados no mundo para Web Application Firewalls (WAF), especialmente com ModSecurity e outros motores compatíveis. O CRS fornece um conjunto de regras genéricas para detectar e bloquear ataques comuns contra aplicações web, incluindo vulnerabilidades presentes no OWASP Top 10, como SQL Injection, XSS e File Inclusion. Essa atualização faz parte da série 4.x, que recebe melhorias contínuas focadas principalmente em novas detecções de ataques, redução de falsos positivos e ajustes internos nas regras, mantendo compatibilidade com os principais motores de WAF.
Principais melhorias desta versão
A versão 4.24.1 traz um conjunto de refinamentos importantes no ruleset:
1. Correções e estabilidade das regras
Foram aplicadas correções em regras existentes para evitar comportamentos inesperados ou falhas de detecção. Isso inclui ajustes em expressões regulares, lógica de validação e melhorias no processamento das requisições HTTP.
2. Redução de falsos positivos (false positives)
Um dos focos constantes do projeto CRS é reduzir bloqueios indevidos. Nesta atualização foram feitos refinamentos em diversas regras para evitar que tráfego legítimo seja interpretado como ataque.
3. Melhorias nas detecções de ataques web
A atualização inclui aprimoramentos em regras relacionadas a categorias de ataques comuns como:
- SQL Injection (SQLi)
- Cross-Site Scripting (XSS)
- Remote Code Execution (RCE)
- exploração de headers HTTP
- evasão de filtros em payloads
Essas melhorias aumentam a capacidade do WAF de identificar técnicas modernas de evasão utilizadas por atacantes.
4. Manutenção e limpeza do ruleset
Também foram incluídas melhorias de manutenção do projeto, como ajustes em scripts, testes e organização interna das regras, facilitando o desenvolvimento e a evolução futura do CRS.
Por que atualizar?
O OWASP CRS é a primeira linha de defesa contra ataques a aplicações web quando utilizado com um WAF. Atualizações frequentes são importantes porque:
- novos vetores de ataque surgem constantemente
- técnicas de bypass evoluem rapidamente
- correções de falsos positivos melhoram a operação em produção
A série 4.24.x está entre as versões oficialmente suportadas pelo projeto, o que significa que continuará recebendo atualizações de segurança e correções.
Conclusão
A versão 4.24.1 do OWASP Core Rule Set é uma atualização incremental focada em estabilidade, melhoria de detecção e redução de falsos positivos, mantendo o ruleset alinhado com as técnicas modernas de ataque à web.
Para ambientes que utilizam ModSecurity, Nginx, Apache ou outros WAFs compatíveis, manter o CRS atualizado é essencial para garantir proteção eficaz contra ameaças emergentes.
Mais informações, download e outros:
https://build.opensuse.org/package/show/home:cabelo:innovators/owasp-modsecurity-crs
Enxergar pessoas através das paredes com Wi-Fi – π RuView: WiFi DensePose
O projeto RuView (tambem chamado de WiFi DensePose) é daqueles projetos que parecem ficção científica e bruxaria: ele estima pose humana, presença e até sinais vitais usando apenas ondas de rádio do Wi-Fi, sem capturar um único pixel de vídeo, ou seja somente Wifi.
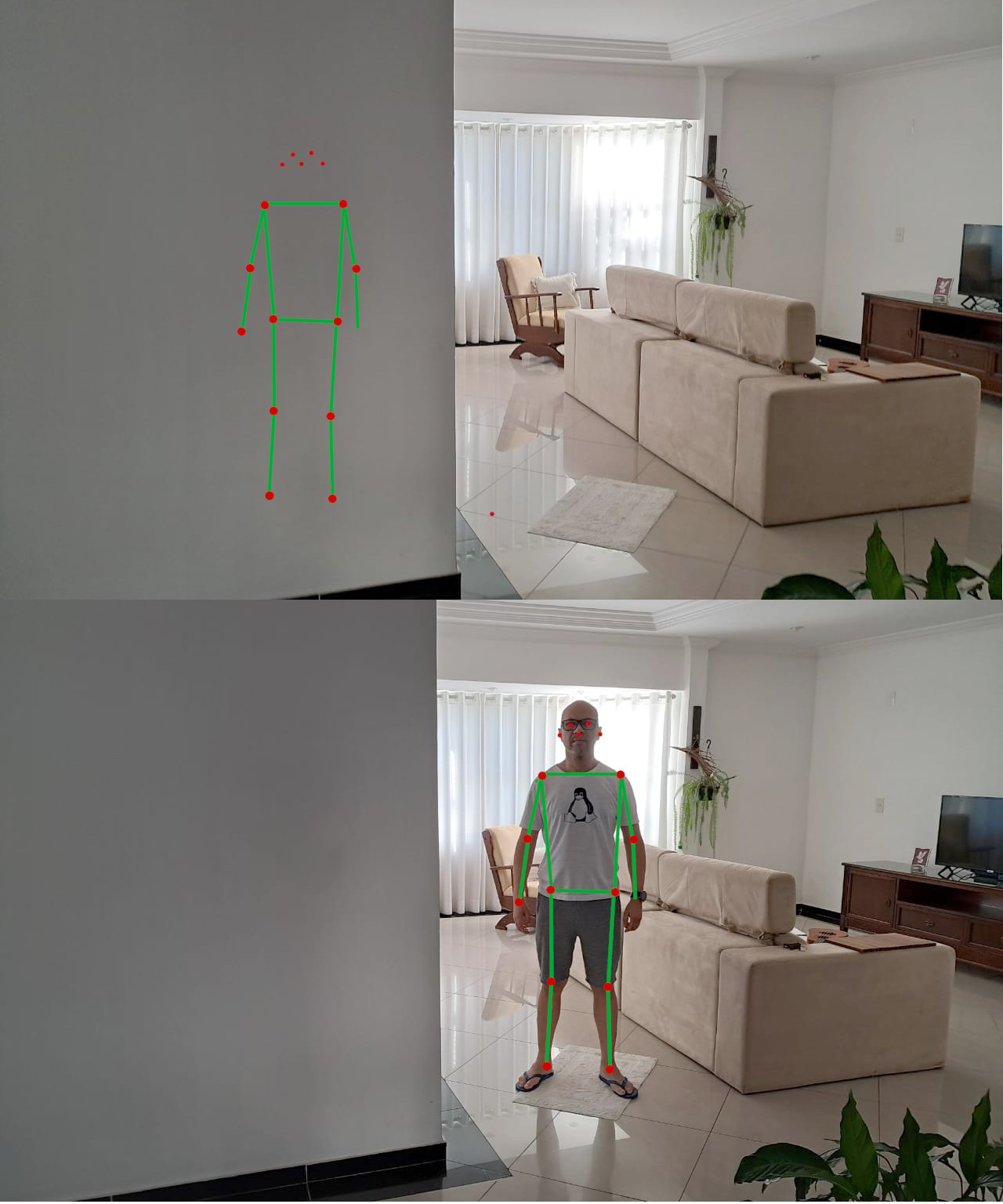
O que é o RuView, em uma frase?
O RuView é um sistema open source que analisa perturbações no CSI (Channel State Information) do Wi-Fi para reconstruir, em tempo real, pose humana (skeleton/DensePose), presença e métricas de respiração/batimentos com foco forte em privacidade, porque não usa câmeras.
Por que “CSI” importa (e por que seu notebook comum não faz tudo)
Aqui está o pulo do gato:
- RSSI (o que Wi-Fi comum costuma expor) é basicamente “um número por AP” (força do sinal). Serve para presença/movimento de forma bem mais grossa.
- CSI expõe informações ricas por subportadora (amplitude/fase), permitindo extrair padrões finos do ambiente e do movimento.
O próprio projeto deixa claro: pose/vitais/through-wall dependem de CSI; em laptops comuns você tende a ficar no máximo em presença/movimento via RSSI.
O que ele consegue detectar hoje
O “cardápio” técnico do projeto:
- Pose estimation: CSI (amplitude/fase por subportadora) → DensePose UV maps / skeleton
- Respiração: bandpass ~0,1–0,5 Hz → pico por FFT (faixa típica 6–30 BPM)
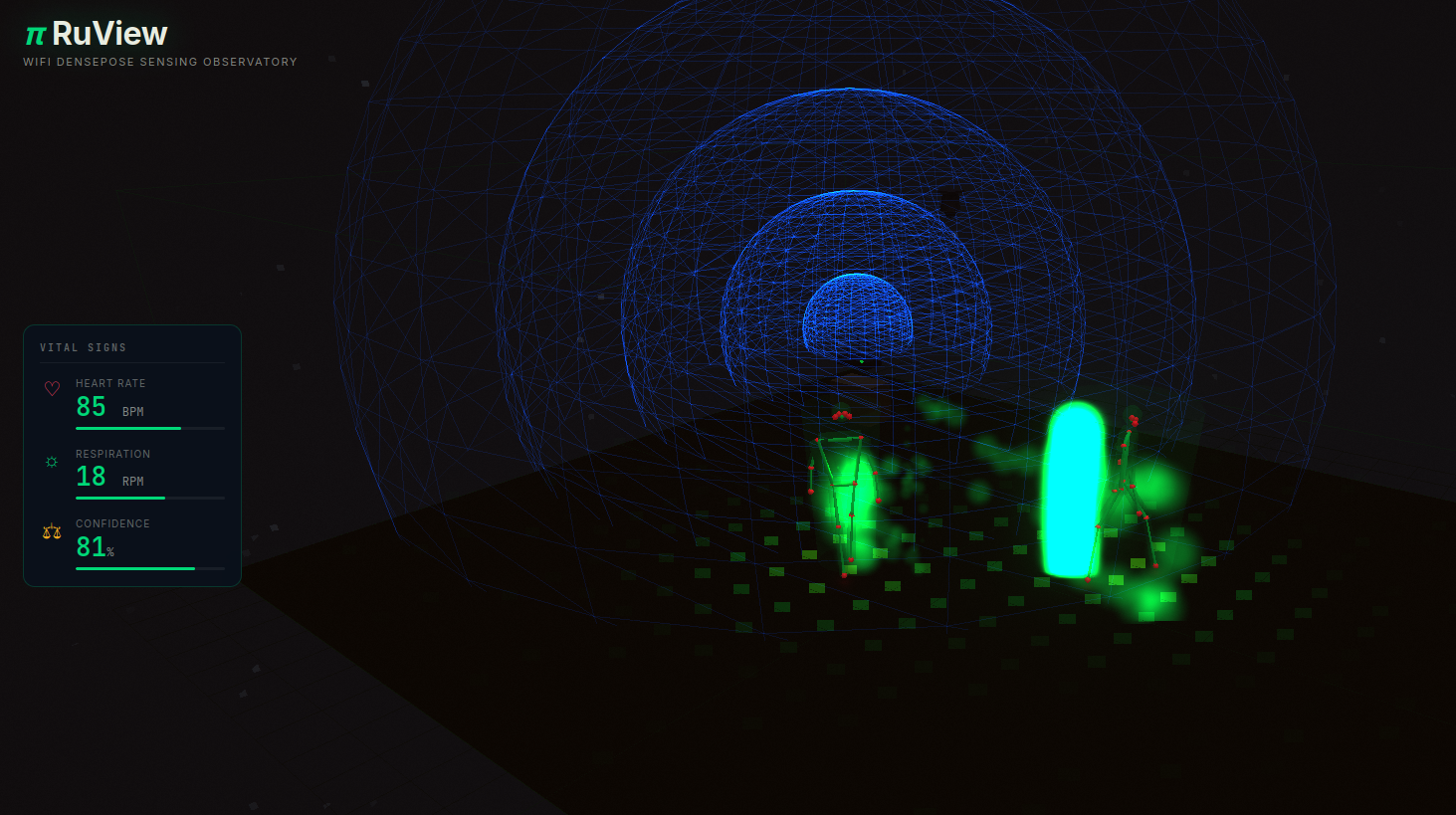
- Batimentos: bandpass ~0,8–2,0 Hz → pico por FFT (faixa típica 40–120 bpm)
- Presença: variação de RSSI + energia de banda de movimento com latência muito baixa
-
Through-wall sensing: usando geometria de zona de Fresnel + multipath (o README menciona “até ~5m” em certos cenários)
E tem um detalhe importante de responsabilidade: a estimativa de sinais vitais no firmware alpha é heurística e “não é para uso médico” melhor com pessoa parada e ambiente controlado.
O projeto esta disponível nos seguintes hardware:
- ESP32-S3 (recomendado) para capturar CSI e montar uma malha (mesh) de sensores; o README cita cenários com ESP32-S3 “~$8” como add-on por zona.
- NICs de pesquisa (ex.: Intel 5300 / Atheros AR9580) com drivers/patches para CSI no Linux.
- Sem hardware: dá para brincar o pipeline com execução determinística/“proof replay”. Além disso, o projeto mostra uma linha interessante para edge AI: um modelo/embedding de “fingerprint” do ambiente com ~55 KB total, cabendo na memória do ESP32, com backbone + head + MicroLoRA por ambiente.
Arquitetura: do rádio ao 3D
- O RuView não é só “um script”; ele é um sistema completo:
- Captura e streaming (ESP32-S3): captura CSI em frequência definida e pode enviar bruto por UDP para um servidor.
- Processamento e API (Rust): o “sensing server” expõe REST API e WebSocket para frames/vitais/pose e integra com UI.
- Visualização (Observatory/Three.js): um modo “Observatory” para ver cenários (multi-person, fall detect, intrusion, etc.) e animações em 3D.
O projeto também enfatiza performance com um rewrite em Rust, citando pipeline completo em ordem de dezenas de microssegundos por frame e um comparativo de speedup vs Python.
Primeiros passos em 30 segundos (sem instalar ferramentas compiladas localmente)
O caminho mais simples é via Docker:
docker pull ruvnet/wifi-densepose:latest
docker run -p 3000:3000 -p 3001:3001 -p 5005:5005/udp ruvnet/wifi-densepose:latest
# depois abra http://localhost:3000
Abaixo as URL da API:
curl http://localhost:3000/health
curl http://localhost:3000/api/v1/vital-signs
curl http://localhost:3000/api/v1/pose/current
Verificação “científica”: pipeline determinístico (sem Wi-Fi real)
Um pedaço que eu achei muito bem pensado: o projeto oferece um modo “verify” para confirmar que o pipeline de sinal é real e reproduzível sem hardware, sem GPU, sem Docker. Para isto basta usar o comando ./verify
Ele roda checagem de ambiente, replay de um sinal de referência por toda a cadeia (filtragem, janelamento, FFT/Doppler etc.) e compara um hash SHA-256 do resultado.
Edge Intelligence no ESP32: do “raw streaming” ao “standalone”
O RuView também descreve “tiers” de processamento no próprio ESP32-S3:
- Tier 0: só streaming bruto (raw CSI)
- Tier 1: limpeza + estatística + seleção de subportadoras + compressão
- Tier 2: Tier 1 + presença + vitais + motion scoring + fall detection
- (No README do github, também aparece um tier com módulos WASM, para extensões customizadas)
A ideia é reduzir banda e permitir detecção local sem PC/servidor, dependendo do tier configurado.
Casos de uso que fazem sentido (e por que isso chama tanta atenção)
Quando você junta “funciona no escuro”, “não precisa line-of-sight” e “sem câmera”, começa a aparecer uma lista enorme de aplicações. Por exemplo, como monitoramento de idosos (quedas/sono), segurança perimetral, ambientes industriais e robótica, entre outros. A parte legal aqui é que não é só “conceito”: o projeto também discute limitações físicas (subportadoras, multipath, atenuação por metal) e escalabilidade por múltiplos APs/nós.
Privacidade: “sem câmera” não significa “sem dado sensível”
Mesmo sendo privacy-first (sem imagem/vídeo), o próprio user guide lembra que posição, movimento e sinais vitais ainda são dados pessoais e podem cair em regulações dependendo do contexto.
RESUMO: RuView é um daqueles projetos que redefinem o que a gente entende por “sensor”: em vez de adicionar mais uma câmera ao mundo, ele tenta extrair informação do que já está no ar ondas de rádio. E mesmo que você não vá colocar isso em produção amanhã, só o fato de ter:
- pipeline verificável (hash),
- stack completa (edge → API → UI),
- e documentação extensa,
já torna o repositório um prato cheio para quem pesquisa IA aplicada, sistemas embarcados e computação “ambiental”.
Créditos: ruvnet
Fonte: https://github.com/ruvnet/RuView