
 cabelo
cabeloLingBot-World: Geração de mundo “jogável” opensource.
Imagine assistir a um vídeo gerado por IA. Agora, imagine que você pode colocar as mãos no teclado e controlar para onde a câmera vai, em tempo real, enquanto o mundo é criado à sua frente. Isso não é mais ficção científica distante: conheça o LingBot-World.
Recém-lançado, o framework apresenta o primeiro modelo de mundo de alta capacidade totalmente open source, estabelecendo um contraste direto com soluções proprietárias como o Genie 3.
Embora ambos ofereçam interatividade em tempo real, o LingBot-World se destaca no chamado grau dinâmico, ou seja, demonstra maior fidelidade ao lidar com física complexa e transições de cena. O sistema atinge 16 quadros por segundo e conta com memória espacial emergente, mantendo a consistência dos objetos mesmo após ficarem até 60 segundos fora do campo de visão.
Na prática, esse lançamento rompe o monopólio na simulação de mundos interativos, ao disponibilizar para a comunidade não apenas o código-fonte, mas também os pesos completos do modelo.
O “Teste que executei” demonstra isso perfeitamente. no video deste post.
Ele chega a simular dinâmicas que não estão visíveis na cena. Se um veículo sai do enquadramento, o modelo continua calculando sua trajetória fora da tela. Quando a câmera retorna, o carro reaparece na posição matematicamente coerente, em vez de simplesmente sumir ou ficar congelado. Isso indica uma mudança profunda: deixamos de ter modelos que apenas “imaginam” imagens e passamos a ter sistemas que efetivamente simulam leis físicas.
Publicado em 28 de janeiro de 2026, o artigo “Advancing Open Source World Models” introduziu este novo simulador que promete abalar as estruturas da IA generativa e do desenvolvimento de jogos. Diferente de tudo o que vimos até agora, o LingBot-World não apenas cria vídeos; ele simula ambientes interativos com física consistente e latência abaixo de um segundo
O Que Faz o LingBot-World Ser Diferente?
A maioria dos modelos de vídeo atuais (como o Gen3 ou Matrix GAN 2.0) funciona de forma passiva: você digita um texto e espera o vídeo ficar pronto. O LingBot-World muda esse paradigma ao permitir que o usuário dirija a câmera através das cenas usando as teclas W, A, S e D.
Seja explorando castelos góticos com dragões, interiores realistas ou mundos com estética de anime e pintura a óleo, o modelo responde aos seus comandos instantaneamente.
Por Baixo do Capô: Como a Mágica Acontece
Para os entusiastas técnicos e desenvolvedores, a arquitetura do LingBot-World é fascinante. O modelo de 14 bilhões de parâmetros (cujos pesos estão disponíveis no Hugging Face) utiliza um pipeline de treinamento em três estágios,
- Pré-treinamento: Estabelece uma base sólida de vídeo para entender texturas.
- Treinamento Intermediário (Física): Aqui o modelo aprende “conhecimento de mundo”. A equipe usou a Unreal Engine para gerar dados sintéticos onde as ações do usuário e os estados da câmera foram gravados em sincronia com o vídeo
- .Pós-treinamento (Baixa Latência): O segredo da interatividade. Usando técnicas como “destilação latente”, eles reduziram os passos computacionais para garantir que a simulação rode suavemente em tempo real.
O sistema usa um componente chamado codificador “Plucker”, que transforma seus comandos de teclado (WASD) em embeddings geométricos. Esses dados ajustam as características do vídeo através de uma camada de ação, direcionando a geração quadro a quadro
Open Source vs. O Resto
Enquanto concorrentes de peso como o Mirage 2 e o Genie 3 mantêm seus códigos fechados, o LingBot-World é totalmente Open Source
E ele não sacrifica qualidade por ser aberto. Nos benchmarks (Versus Bench), ele alcançou uma pontuação de quase 0,89 em grau dinâmico (movimento complexo), superando significativamente concorrentes como o Ume 1.5 e o HY World 1.5, que ficam em torno de 0,76. Ele consegue manter essa física complexa de forma consistente por longas durações (mais de um minuto)
Conclusão
O LingBot-World representa um passo gigante na transformação da geração de vídeo passiva em simulação interativa
Com o código disponível no GitHub, ele abre portas para acelerar o progresso no desenvolvimento de jogos e na IA corporificada, colocando o poder de criar mundos infinitos e controláveis nas mãos de qualquer desenvolvedor.
Se você quer testar, o código e os exemplos de inferência já estão disponíveis para quem quiser mergulhar na próxima geração de simuladores de mundo.
Código Fonte:
https://github.com/Robbyant/lingbot-world
Software Livre pode mudar o mundo da IA Musical da Noite para o dia.
Estamos vivendo em uma era onde a inovação tecnológica não obedece a limites de velocidade. Da noite para o dia, fomos apresentados a plataformas fantásticas e revolucionárias de geração de música com Inteligência Artificial, como o Suno. No entanto, vivemos em um mundo onde essas soluções comerciais gigantescas podem ser rapidamente ameaçadas por tecnologias livres e de código aberto.
O foco aqui não é comparar a qualidade de plataformas comerciais com as gratuitas, mas sim observar a velocidade absurda das mudanças. O que antes exigia datacenters na nuvem e assinaturas mensais pagas, agora pode rodar no conforto do seu próprio computador, de forma totalmente gratuita e sem restrições.
Para colocar essa realidade à prova, fiz um teste prático: gerei uma música completa sobre a “ABRIA” em apenas 10 segundos, utilizando uma placa de vídeo (GPU) de 16GB. Isso é possível porque as novas tecnologias de código aberto trazem a geração de áudio de nível comercial diretamente para o hardware de consumo.
Para entender como isso funciona, precisamos dividir a mágica em duas partes principais: o motor (backend) e a interface (frontend).
A Arquitetura: Separando o Cérebro da Interface
A geração local de músicas em alta velocidade só é possível graças à união de dois projetos de código aberto distintos, mas que trabalham em perfeita harmonia:
1. O Motor (Backend) – ACE-Step-1.5: Este é o verdadeiro “cérebro” da operação. O ACE-Step 1.5 é um modelo fundacional de música altamente eficiente que processa as descrições e estilos fornecidos para gerar as faixas de áudio. Ele foi desenhado para rodar localmente e entrega uma performance impressionante, conseguindo compor faixas inteiras em uma questão de segundos em GPUs modernas.
2. A Interface (Frontend) – ACE-Step UI: Interagir com inteligência artificial apenas por linhas de código pode ser frustrante. É aqui que entra o ACE-Step UI. Ele funciona como o “rosto” do projeto, entregando uma interface profissional, limpa e inspirada no Spotify. O frontend foi construído para que você possa controlar os parâmetros da música, gerenciar sua biblioteca e ver o progresso da geração de forma visual e intuitiva.
Guia Prático: Como Rodar Essa Tecnologia Localmente
A instalação pode parecer assustadora para quem não está acostumado com terminais, mas o processo foi incrivelmente simplificado. Veja como você pode configurar o seu próprio estúdio de IA musical local passo a passo.
Download da Interface Primeiro, vamos clonar o repositório do frontend e tentar iniciá-lo:
git clone https://github.com/fspecii/ace-step-ui
cd ace-step-ui
Instalando o Motor (ACE-Step-1.5) e Configurando a Interface Seguindo as instruções que o próprio sistema nos deu, baixamos o motor de IA e depois executamos a configuração (setup.sh) dentro da pasta da interface:
./setup.sh
==================================
ACE-Step UI Setup
==================================
Found ACE-Step at: ../ACE-Step-1.5
Creating .env file...
Installing frontend dependencies...
added 199 packages, and audited 200 packages in 2s
28 packages are looking for funding
run `npm fund` for details
4 high severity vulnerabilities
To address all issues, run:
npm audit fix
Run `npm audit` for details.
Installing server dependencies...
added 186 packages, and audited 187 packages in 2s
28 packages are looking for funding
run `npm fund` for details
1 low severity vulnerability
To address all issues, run:
npm audit fix
Run `npm audit` for details.
Initializing database...
Migration script not found, skipping...
==================================
Setup Complete!
==================================
To start the application:
# Terminal 1 - Start backend
cd server && npm run dev
# Terminal 2 - Start frontend
npm run dev
Then open http://localhost:3000
Iniciando Todos os Serviços Agora que tanto o frontend quanto o backend estão instalados, basta indicar onde o motor (ACE-Step-1.5) está localizado e iniciar os serviços de uma só vez:
export ACESTEP_PATH=/path/to/ACE-Step-1.5
./start-all.sh
O sistema subirá os três componentes necessários (a API do modelo de IA, o servidor backend local e a interface frontend) simultaneamente:
==================================
ACE-Step Complete Startup
==================================
==================================
Starting All Services...
==================================
[1/3] Starting ACE-Step API server...
Waiting for API to initialize...
[2/3] Starting backend server...
Waiting for backend to start...
[3/3] Starting frontend...
==================================
All Services Running!
==================================
ACE-Step API: http://localhost:8001
Backend: http://localhost:3001
Frontend: http://localhost:3000
LAN Access: http://192.168.0.106:3000
Logs: ./logs/
PIDs:
API: 17328
Backend: 17382
Frontend: 17419
==================================
Opening browser...
Services are running in background.
To stop all services, run: ./stop-all.sh
Or press Ctrl+C and they will continue running.
E pronto! O seu navegador abrirá automaticamente em http://localhost:3000, revelando uma plataforma completa e totalmente sua.
É fascinante observar o quão rápido a comunidade de código aberto se move. Há pouco tempo, criar músicas a partir de texto com qualidade excepcional parecia exclusividade de grandes corporações. Hoje, com alguns comandos no terminal, qualquer pessoa com hardware compatível pode ter seu próprio gerador musical ilimitado. O futuro da criatividade não pertence apenas às grandes plataformas; ele está sendo construído, modificado e compartilhado livremente todos os dias.
Abaixo um vídeo do projeto em funcionamento.
Seedance 2.0: Viralizou no mundo, impressionou Musk e acendeu o alerta em Hollywood

A nova inteligência artificial de geração de vídeos da ByteDance, o Seedance 2.0, tornou-se um fenômeno na China e começou a repercutir globalmente após impressionar nomes como Elon Musk. Especializado na criação de vídeos cinematográficos a partir de poucos comandos, o modelo vem sendo comparado à ascensão meteórica da DeepSeek especialmente após o impacto global do modelo R1 no início de 2025.
Mas afinal, o que torna o Seedance 2.0 tão diferente e por que Hollywood está em alerta?
A próxima fronteira da IA: do texto ao cinema
Nos últimos anos, modelos focados em texto como o ChatGPT consolidaram a IA generativa no mainstream. O próprio R1 da DeepSeek reforçou o protagonismo chinês na corrida tecnológica.
Agora, o foco se desloca para modelos multimodais capazes de integrar texto, imagem, áudio e vídeo simultaneamente. É exatamente esse o posicionamento do Seedance 2.0.
Apresentado oficialmente em 12 de fevereiro, o modelo foi descrito pela ByteDance como uma solução voltada para:
- Produções cinematográficas profissionais
- Conteúdo para e-commerce
- Campanhas publicitárias
- Criação rápida de mídia social
A promessa é reduzir drasticamente os custos de produção audiovisual, permitindo que vídeos hiper-realistas de até 15 segundos sejam criados a partir de poucas linhas de instrução.
Comparações com a DeepSeek e o “momento Sputnik”
O sucesso do Seedance 2.0 acontece em um momento simbólico. Após o impacto global da DeepSeek, investidores e especialistas buscavam o “próximo salto” da IA chinesa.
O jornal estatal chinês Global Times comparou o impacto inicial do DeepSeek-R1 a um “momento Sputnik” referência histórica ao choque geopolítico causado pelo avanço soviético na corrida espacial.
Segundo editorial publicado na China, o sucesso contínuo do Seedance 2.0 estaria gerando uma nova onda de admiração tecnológica pela China no Vale do Silício.
O próprio Elon Musk reagiu a uma postagem elogiando o modelo em sua rede social X com a frase:
“Está acontecendo rápido.”
Uma declaração curta mas simbólica considerando o ritmo acelerado da corrida global por IA multimodal.
Viralização nas redes chinesas
Na plataforma Weibo, vídeos criados com o Seedance 2.0 acumulam milhões de visualizações.
Entre os exemplos que viralizaram:
- Ye (Kanye West) e Kim Kardashian como personagens de um drama palaciano na China Imperial, cantando em mandarim
- Cenas de luta entre Tom Cruise e Brad Pitt
- Confrontos fictícios entre John Wick e Neo (personagens de Keanu Reeves)
- Finais alternativos para séries como Stranger Things
Hashtags relacionadas ao Seedance 2.0 somaram dezenas de milhões de cliques, incluindo uma promovida pelo Beijing Daily com a frase:
“Da DeepSeek ao Seedance, a IA da China triunfou.”
O outro lado: Hollywood reage

Se por um lado a tecnologia empolga usuários e investidores, por outro ela acendeu um sinal vermelho na indústria cinematográfica americana.
A associação Motion Picture Association criticou duramente o lançamento, afirmando que o modelo teria feito uso não autorizado de obras protegidas por direitos autorais.
A Disney enviou notificação extrajudicial acusando a ByteDance de “apropriação virtual desenfreada” de propriedades como personagens da Marvel e de outras franquias do estúdio.
A Paramount Global também notificou a empresa por uso indevido de marcas como “South Park”, “Star Trek” e “O Poderoso Chefão”.
O sindicato dos atores de Hollywood classificou o uso de vozes e imagens sintéticas como “violação flagrante”, enquanto a Human Artistry Campaign chamou a plataforma de “um ataque a todos os criadores do mundo”.
A resposta da ByteDance
Em comunicado à BBC, a ByteDance afirmou:
- Que respeita os direitos de propriedade intelectual
- Que ouviu as preocupações da indústria
- Que está reforçando medidas de segurança
- Que busca impedir o uso não autorizado de IP por parte dos usuários
A empresa sinaliza que o Seedance 2.0 está em fase de testes apenas na China, mas a pressão internacional pode acelerar mudanças regulatórias ou mesmo disputas judiciais de grande escala.
O que está realmente em jogo?
O caso Seedance 2.0 expõe três grandes tensões globais:
Disrupção tecnológica
A capacidade de gerar cenas cinematográficas realistas com poucos comandos reduz barreiras de entrada na produção audiovisual.
Propriedade intelectual
Quem é responsável quando um modelo gera conteúdo baseado em IP protegido?
Geopolítica da IA
China e EUA disputam liderança não apenas em modelos de texto, mas agora em vídeo, multimodalidade e mídia sintética.
Conclusão
O Seedance 2.0 não é apenas mais um modelo de IA. Ele representa:
- Um avanço significativo na geração multimodal
- Um símbolo da aceleração tecnológica chinesa
- Um desafio direto às estruturas tradicionais da indústria criativa
- Um novo capítulo na corrida global por inteligência artificial
Se a DeepSeek provocou um “momento Sputnik” na IA textual, o Seedance 2.0 pode estar inaugurando o momento Hollywood da IA multimodal.
E como resumiu Elon Musk: “Está acontecendo rápido.”
A pergunta agora não é se a IA vai transformar o audiovisual —
mas quem controlará essa transformação.
Veja o teste do portal Assunto Nerd.

Fontes
https://sapo.pt/artigo/programa-de-video-seedance-2-0-tera-protocolos-de-seguranca-apos-ameacas-de-hollywood-6992dd046480661f46bab874
https://www.cnnbrasil.com.br/tecnologia/nova-ia-da-bytedance-viraliza-na-china-e-impressiona-musk-saiba-por-que/
Intel Innovator brasileiro impulsiona IA local em PCs com Intel viabilizando suporte à NPU no openSUSE Linux

São Paulo, janeiro de 2026 A comunidade openSUSE deu um passo decisivo para consolidar o conceito de AI PC no ecossistema Linux com o lançamento oficial de um driver em formato RPM que habilita o uso da Unidade de Processamento Neural (NPU) presente nos processadores Intel Core Ultra. A novidade permite que notebooks e desktops executem cargas de trabalho de inteligência artificial de forma local, eficiente e energeticamente otimizada, diretamente no sistema operacional.
O pacote, batizado de linux-npu-driver, foi desenvolvido e empacotado no âmbito da iniciativa openSUSE for Innovators, passando a integrar oficialmente as distribuições openSUSE Tumbleweed, Slowroll e Leap. Com isso, o Linux passa a oferecer suporte prático a um dos pilares centrais da nova geração de PCs com IA: a aceleração dedicada por hardware.
A NPU é um acelerador especializado integrado aos processadores Intel Core Ultra, projetado para executar inferência de redes neurais com altíssima eficiência energética. Atuando de forma complementar à CPU e à GPU integrada, ela possibilita o offloading inteligente de tarefas de IA, reduzindo consumo de energia, impacto térmico e latência características especialmente relevantes em notebooks e cenários de uso contínuo.
“Os PCs com Intel Core Ultra foram concebidos desde o início para executar cargas de trabalho de inteligência artificial de forma local, eficiente e persistente”, explica Yuri Daglian, engenheiro de aplicações da Intel. “A disponibilização oficial do driver da NPU no openSUSE conecta definitivamente o hardware ao software e fortalece o ecossistema de AI PC no Linux, abrindo espaço para aplicações de IA generativa, visão computacional e modelos de linguagem rodando diretamente no dispositivo do usuário.”
Na prática, o suporte à NPU permite acelerar inferência de modelos ONNX, pipelines de visão computacional, modelos quantizados e fluxos híbridos que combinam CPU, GPU e NPU. Para o usuário final, isso significa que o sistema operacional passa a reconhecer e explorar plenamente os recursos de IA já presentes no hardware — algo que até então permanecia inacessível no Linux.
Entretanto, o uso efetivo da NPU depende também de software compatível. Atualmente, o principal caminho é o OpenVINO, toolkit de código aberto da Intel voltado à otimização e implantação de modelos de IA, que precisa ser compilado com o backend específico da NPU habilitado.
“O driver é a base de tudo. Sem ele, a NPU simplesmente não existe para o sistema operacional”, afirma Alessandro Faria, cofundador da Multicortex, embaixador do openSUSE Linux e parceiro do programa Intel Innovator, responsável pelo empacotamento do linux-npu-driver. “Como comunidade de código aberto, temos a responsabilidade de democratizar tecnologias emergentes e reduzir barreiras de acesso. Garantir que o openSUSE acompanhe a revolução da IA executada localmente faz parte desse compromisso.”
Além do driver da NPU, o próprio OpenVINO passou a estar disponível nativamente no openSUSE, resultado de um trabalho pioneiro de compatibilização entre as políticas técnicas da Intel e os padrões da distribuição. Segundo Alessandro, o processo envolveu ajustes profundos no fluxo de compilação, dependências e no modelo de instalação, viabilizando uma integração limpa e suportada oficialmente.
“O OpenVINO simplesmente não rodava no openSUSE. Primeiro foi preciso torná-lo compatível; depois, adaptar o processo de instalação para que ele funcionasse de forma nativa”, explica. “Esse é um esforço colaborativo, construído com código aberto, que não beneficia apenas o openSUSE, mas serve de referência para todo o ecossistema Linux.”
Lançado em 2018, o OpenVINO já é utilizado por centenas de milhares de desenvolvedores ao redor do mundo para acelerar inferência de IA da borda ao data center. O toolkit oferece otimização automática de hardware, recursos avançados de quantização e compressão de modelos, suporte a modelos generativos e LLMs, além de integração com tecnologias como oneAPI, oneDNN e oneTBB.
Com a infraestrutura básica agora disponível no openSUSE, a expectativa da comunidade é que cada vez mais aplicações passem a oferecer suporte nativo à NPU da Intel, consolidando a execução de inteligência artificial local, eficiente e segura diretamente no PC do usuário um dos fundamentos centrais da nova geração de AI PCs com Intel Core Ultra.
Publicação original: https://newsroom.intel.com/pt/client-computing/opensuse-passa-suportar-npu-intel-viabiliza-ia-em-pcs-com-core-ultra
Compute Capability: O “detalhe” de build CUDA que pode render 33× de performance (≈ +3300%)

Em projetos de IA, é comum a equipe de TI usar uma GPU “padrão de homologação” na nuvem (por exemplo, NVIDIA T4 no ambiente de teste) para compilar, testar e validar o pipeline. O problema aparece quando esse mesmo binário é executado em GPUs mais novas no ambiente produtivo e o desempenho fica absurdamente abaixo do que o hardware poderia entregar (e ninguém percebe por diversos fatores).
O motivo costuma ser simples: o binário foi compilado mirando a Compute Capability errada.
A Compute Capability (CC) é o identificador (X.Y) que representa o conjunto de recursos e instruções suportados por uma geração de GPUs NVIDIA. Na tabela oficial da NVIDIA, por exemplo, a T4 é CC 7.5 e a RTX 4060 Ti é CC 8.9. A seguir, vamos entender o porquê isso importa tanto e usar o seu exemplo real para mostrar o impacto: 4,30 ms vs 0,13 ms um ganho de ~33× (≈ +3208%, frequentemente arredondado como “3300%”). https://developer.nvidia.com/cuda/gpus
O que é Compute Capability e por que ela manda no desempenho
Compute Capability não é “marketing” é um contrato técnico entre o seu código e a microarquitetura da GPU. Ela define:
- Quais instruções existem (ISA/SASS disponível naquele SM)
- Quais otimizações o compilador pode aplicar
- Quais recursos de hardware podem ser usados (ex.: instruções especializadas, caminhos de memória, operações assíncronas, etc.)
- Qual PTX (código intermediário) pode ser gerado sem “assumir” features que não existem na GPU-alvo
A NVIDIA lista CC por GPU e deixa explícito que diferentes modelos mapeiam para CC diferentes (T4=7.5; RTX 4060 Ti=8.9). Em termos práticos: compilar para CC antiga em uma GPU nova pode “capar” o compilador, porque ele precisa gerar um código que só usa features garantidas naquela CC antiga.
Como o nvcc decide o que vai rodar: PTX, SASS e “fatbinary”
O nvcc normalmente gera:
- PTX (intermediário, “assembly virtual”)
-
CUBIN/SASS (binário nativo para um SM específico, ex.:
sm_75,sm_89) - Tudo isso pode ser empacotado num fatbinary dentro do executável
Na documentação do nvcc, a NVIDIA explica que o executável carrega imagens de código e, em tempo de execução, o runtime/driver escolhe a imagem mais apropriada para a GPU presente.
E aqui mora o ponto-chave:
- Se você inclui SASS nativo para a GPU (
sm_89na 4060 Ti), ela roda direto com o melhor código possível. - Se você não inclui SASS para aquela GPU, mas inclui PTX, o driver pode fazer JIT (compilar na hora) porém limitado ao PTX e às features assumidas naquele PTX.
- Se você inclui apenas código para uma GPU mais antiga e/ou PTX “antigo”, você pode até rodar, mas deixa performance na mesa.
O artigo técnico da NASA sobre compilação CUDA resume bem o modelo em 2 estágios (PTX → CUBIN) e descreve o papel de compute_XY vs sm_XY, além do JIT e do fatbinary como estratégia de portabilidade. Este texto da NASA foi inspiração deste post: https://www.nas.nasa.gov/hecc/support/kb/compiling-cuda-applications-for-different-generations-of-nvidia-gpus-at-nas_700.html
O caso real: time compila no ambiente de homologação T4 (CC 7.5) e executa na RTX 4060 Ti (CC 8.9)
Compilação “errada” (mirando T4 / compute_75)
Um equipe compila na instância com T4 (muito usada em homologação e testes) com:
$ nvcc matmul.cu -o matmul_wrong -arch=compute_75 -gencode arch=compute_75,code=sm_75
Executando esse binário numa RTX 4060 Ti (CC 8.9), o resultado medido foi:
$ ./matmul_wrong
Tempo de execução: 4.30 ms
Compilação “certa” (mirando a GPU real do alvo / compute_89)
Agora compilando especificamente para a RTX 4060 Ti:
$ nvcc matmul.cu -o matmul_right -arch=compute_89 -gencode arch=compute_89,code=sm_89
Resultado:
$ ./matmul_right
Tempo de execução: 0.13 ms
O “ganho de 3300%” (matemática do impacto)
- Speedup (vezes mais rápido): 4,30 / 0,13 ≈ 33,08×
- “% mais rápido” (comparando contra o tempo menor): (4,30 − 0,13) / 0,13 × 100 ≈ 3207,7%
- Redução do tempo: (4,30 − 0,13) / 4,30 × 100 ≈ 97,0%
Ou seja: chamar isso de “~3300%” é um arredondamento comum o número exato pelo seu benchmark dá ~3208%.
Por que a Compute Capability errada pode causar um abismo desses?
Mesmo que o código-fonte CUDA seja igual, o código gerado pode mudar drasticamente quando você troca o alvo (sm_75 → sm_89), porque:
-
Instruções e agendamentos diferentes
- O backend (ptxas) gera SASS específico por arquitetura. Mirar
sm_89permite escolher instruções, latências e scheduling adequados ao hardware.
- O backend (ptxas) gera SASS específico por arquitetura. Mirar
-
Limitação por “conjunto mínimo de features”
- Quando você gera PTX assumindo
compute_75, você está dizendo ao compilador: “use apenas o que é garantido em CC 7.5”. - Mesmo rodando numa GPU CC 8.9, o caminho pode ficar preso a decisões conservadoras (ou depender mais de JIT).
- Quando você gera PTX assumindo
-
JIT não é “milagre”: ele compila o que você deu
- Se você entrega PTX antigo, o driver compila, mas não inventa features que o PTX/arquitetura-alvo não permitiram assumir. A própria doc do
nvccdescreve que PTX pode ser embutido e compilado dinamicamente quando não há binário nativo adequado.
- Se você entrega PTX antigo, o driver compila, mas não inventa features que o PTX/arquitetura-alvo não permitiram assumir. A própria doc do
Homologação na nuvem ≠ alvo final
- No exemplo, a T4 (CC 7.5) é ótima para CI e testes, mas não pode ditar o “target único” se você entrega para desktops Ada (CC 8.9) e isso vale muito em pipelines de IA (inferencia, kernels custom, extensões CUDA, etc.).
A melhor prática para times: compile uma vez e rode bem em T4 e em 4060 Ti
Em vez de escolher “T4 ou 4060 Ti”, faça o executável carregar ambos:
-
SASS nativo para T4 (
sm_75) → sem JIT, ótimo no ambiente de teste/homologação -
SASS nativo para 4060 Ti (
sm_89) → máximo desempenho no desktop - PTX para forward-compat (opcional, mas recomendado quando você não controla todos os alvos)
A própria documentação do nvcc mostra como --generate-code/-gencode permite repetir arquiteturas e também como incluir PTX (usando code=compute_XX) para JIT quando não existir SASS correspondente.
Exemplo de “fat binary” bem pragmático para seu cenário:
$ nvcc matmul.cu -o matmul_fat \
--generate-code arch=compute_75,code=sm_75 \
--generate-code arch=compute_89,code=sm_89 \
--generate-code arch=compute_89,code=compute_89
Assim:
- Na T4, ele usa
sm_75. - Na RTX 4060 Ti, ele usa
sm_89. - Em GPUs futuras (acima de 8.9), se não houver SASS exato, ainda há PTX 8.9 para o driver compilar via JIT.
Benchmark honesto: duas dicas rápidas para não “se enganar”
Seu micro benchmark já é excelente para ilustrar o ponto, mas em artigo eu sempre recomendo mencionar:
- Warm-up: rode o kernel algumas vezes antes de medir (evita pegar JIT/cache/boost “frio”).
- Várias iterações: meça média/mediana de N execuções (evita ruído de clock/boost).
Isso não muda a mensagem principal (CC correta importa), mas dá credibilidade técnica.
O código do exemplo (para referência no artigo)
Abaixo está o kernel e a medição por cudaEvent exatamente como você forneceu (um microbenchmark simples para evidenciar diferenças de codegen/arquitetura):
#include <stdio.h>
#include <cuda.h>
__global__ void matmul_kernel(float *A, float *B, float *C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
float sum = 0.0f;
for (int i = 0; i < N; i++) {
sum += A[idx * N + i] * B[i * N + idx];
}
C[idx] = sum;
}
}
int main() {
const int N = 1024;
const int size = N * N * sizeof(float);
float *hA = (float*)malloc(size);
float *hB = (float*)malloc(size);
float *hC = (float*)malloc(N * sizeof(float));
for(int i = 0; i < N*N; i++){
hA[i] = 1.0f;
hB[i] = 1.0f;
}
float *dA, *dB, *dC;
cudaMalloc(&dA, size);
cudaMalloc(&dB, size);
cudaMalloc(&dC, N * sizeof(float));
cudaMemcpy(dA, hA, size, cudaMemcpyHostToDevice);
cudaMemcpy(dB, hB, size, cudaMemcpyHostToDevice);
dim3 block(256);
dim3 grid((N + block.x - 1) / block.x);
// Medição
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
matmul_kernel<<<grid, block>>>(dA, dB, dC, N);
cudaEventRecord(stop);
cudaDeviceSynchronize();
float ms = 0.0f;
cudaEventElapsedTime(&ms, start, stop);
printf("Tempo de execução: %.2f ms\n", ms);
cudaMemcpy(hC, dC, N * sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(dA); cudaFree(dB); cudaFree(dC);
free(hA); free(hB); free(hC);
return 0;
}
Fechando: a regra de ouro
Se o seu time como no exemplo aqui, compila em T4 (CC 7.5) para homologação, mas o alvo também inclui Ada (CC 8.9), não escolha um único target.
- Compute Capability certa = performance “de graça”
- Compute Capability errada = gargalo invisível que pode custar ordens de grandeza (como seus 33×)
E o melhor: corrigir isso geralmente é só ajustar flags de build e de quebra você padroniza uma entrega que roda bem em cloud e local.
Checklist final para o time de TI (cloud + desktop)
- Não compile “só para a GPU da de testes” se o binário roda fora dela
- Gere fat binary com
-gencodepara todos os alvos relevantes - Inclua PTX (ex.:
code=compute_XX) quando você não controla 100% dos alvos - Padronize isso no CMake/CI (não deixe o dev “lembrar” na mão)
- Documente o CC alvo por ambiente (homologação, dev, produção)
Conclusão
Compute Capability não é detalhe: é uma decisão de engenharia de build que pode te entregar performance “de graça” ou te fazer carregar um gargalo invisível por meses.

Compute Capability: O “detalhe” de build CUDA que pode evitar até ≈ +3300% de prejuízo em performance.
Em projetos de IA, é comum a equipe de TI usar uma GPU “padrão de homologação” na nuvem (por exemplo, NVIDIA T4 no ambiente de teste) para compilar, testar e validar o pipeline. O problema aparece quando esse mesmo binário é executado em GPUs mais novas no ambiente produtivo e o desempenho fica absurdamente abaixo do que o hardware poderia entregar (e ninguém percebe por diversos fatores).
O motivo costuma ser simples: o binário foi compilado mirando a Compute Capability errada.
A Compute Capability (CC) é o identificador (X.Y) que representa o conjunto de recursos e instruções suportados por uma geração de GPUs NVIDIA. Na tabela oficial da NVIDIA, por exemplo, a T4 é CC 7.5 e a RTX 4060 Ti é CC 8.9. A seguir, vamos entender o porquê isso importa tanto e usar o seu exemplo real para mostrar o impacto: 4,30 ms vs 0,13 ms um ganho de ~33× (≈ +3208%, frequentemente arredondado como “3300%”). https://developer.nvidia.com/cuda/gpus
O que é Compute Capability e por que ela manda no desempenho
Compute Capability não é “marketing” é um contrato técnico entre o seu código e a microarquitetura da GPU. Ela define:
- Quais instruções existem (ISA/SASS disponível naquele SM)
- Quais otimizações o compilador pode aplicar
- Quais recursos de hardware podem ser usados (ex.: instruções especializadas, caminhos de memória, operações assíncronas, etc.)
- Qual PTX (código intermediário) pode ser gerado sem “assumir” features que não existem na GPU-alvo
A NVIDIA lista CC por GPU e deixa explícito que diferentes modelos mapeiam para CC diferentes (T4=7.5; RTX 4060 Ti=8.9). Em termos práticos: compilar para CC antiga em uma GPU nova pode “capar” o compilador, porque ele precisa gerar um código que só usa features garantidas naquela CC antiga.
Como o nvcc decide o que vai rodar: PTX, SASS e “fatbinary”
O nvcc normalmente gera:
- PTX (intermediário, “assembly virtual”)
-
CUBIN/SASS (binário nativo para um SM específico, ex.:
sm_75,sm_89) - Tudo isso pode ser empacotado num fatbinary dentro do executável
Na documentação do nvcc, a NVIDIA explica que o executável carrega imagens de código e, em tempo de execução, o runtime/driver escolhe a imagem mais apropriada para a GPU presente.
E aqui mora o ponto-chave:
- Se você inclui SASS nativo para a GPU (
sm_89na 4060 Ti), ela roda direto com o melhor código possível. - Se você não inclui SASS para aquela GPU, mas inclui PTX, o driver pode fazer JIT (compilar na hora) porém limitado ao PTX e às features assumidas naquele PTX.
- Se você inclui apenas código para uma GPU mais antiga e/ou PTX “antigo”, você pode até rodar, mas deixa performance na mesa.
O artigo técnico da NASA sobre compilação CUDA resume bem o modelo em 2 estágios (PTX → CUBIN) e descreve o papel de compute_XY vs sm_XY, além do JIT e do fatbinary como estratégia de portabilidade. Este texto da NASA foi inspiração deste post: https://www.nas.nasa.gov/hecc/support/kb/compiling-cuda-applications-for-different-generations-of-nvidia-gpus-at-nas_700.html
O caso real: time compila no ambiente de homologação T4 (CC 7.5) e executa na RTX 4060 Ti (CC 8.9)
Compilação “errada” (mirando T4 / compute_75)
Um equipe compila na instância com T4 (muito usada em homologação e testes) com:
$ nvcc matmul.cu -o matmul_wrong -arch=compute_75 -gencode arch=compute_75,code=sm_75
Executando esse binário numa RTX 4060 Ti (CC 8.9), o resultado medido foi:
$ ./matmul_wrong
Tempo de execução: 4.30 ms
Compilação “certa” (mirando a GPU real do alvo / compute_89)
Agora compilando especificamente para a RTX 4060 Ti:
$ nvcc matmul.cu -o matmul_right -arch=compute_89 -gencode arch=compute_89,code=sm_89
Resultado:
$ ./matmul_right
Tempo de execução: 0.13 ms
O “ganho de 3300%” (matemática do impacto)
- Speedup (vezes mais rápido): 4,30 / 0,13 ≈ 33,08×
- “% mais rápido” (comparando contra o tempo menor): (4,30 − 0,13) / 0,13 × 100 ≈ 3207,7%
- Redução do tempo: (4,30 − 0,13) / 4,30 × 100 ≈ 97,0%
Ou seja: chamar isso de “~3300%” é um arredondamento comum o número exato pelo seu benchmark dá ~3208%.
Por que a Compute Capability errada pode causar um abismo desses?
Mesmo que o código-fonte CUDA seja igual, o código gerado pode mudar drasticamente quando você troca o alvo (sm_75 → sm_89), porque:
-
Instruções e agendamentos diferentes
- O backend (ptxas) gera SASS específico por arquitetura. Mirar
sm_89permite escolher instruções, latências e scheduling adequados ao hardware.
- O backend (ptxas) gera SASS específico por arquitetura. Mirar
-
Limitação por “conjunto mínimo de features”
- Quando você gera PTX assumindo
compute_75, você está dizendo ao compilador: “use apenas o que é garantido em CC 7.5”. - Mesmo rodando numa GPU CC 8.9, o caminho pode ficar preso a decisões conservadoras (ou depender mais de JIT).
- Quando você gera PTX assumindo
-
JIT não é “milagre”: ele compila o que você deu
- Se você entrega PTX antigo, o driver compila, mas não inventa features que o PTX/arquitetura-alvo não permitiram assumir. A própria doc do
nvccdescreve que PTX pode ser embutido e compilado dinamicamente quando não há binário nativo adequado.
- Se você entrega PTX antigo, o driver compila, mas não inventa features que o PTX/arquitetura-alvo não permitiram assumir. A própria doc do
Homologação na nuvem ≠ alvo final
- No exemplo, a T4 (CC 7.5) é ótima para CI e testes, mas não pode ditar o “target único” se você entrega para desktops Ada (CC 8.9) e isso vale muito em pipelines de IA (inferencia, kernels custom, extensões CUDA, etc.).
A melhor prática para times: compile uma vez e rode bem em T4 e em 4060 Ti
Em vez de escolher “T4 ou 4060 Ti”, faça o executável carregar ambos:
-
SASS nativo para T4 (
sm_75) → sem JIT, ótimo no ambiente de teste/homologação -
SASS nativo para 4060 Ti (
sm_89) → máximo desempenho no desktop - PTX para forward-compat (opcional, mas recomendado quando você não controla todos os alvos)
A própria documentação do nvcc mostra como --generate-code/-gencode permite repetir arquiteturas e também como incluir PTX (usando code=compute_XX) para JIT quando não existir SASS correspondente.
Exemplo de “fat binary” bem pragmático para seu cenário:
$ nvcc matmul.cu -o matmul_fat \
--generate-code arch=compute_75,code=sm_75 \
--generate-code arch=compute_89,code=sm_89 \
--generate-code arch=compute_89,code=compute_89
Assim:
- Na T4, ele usa
sm_75. - Na RTX 4060 Ti, ele usa
sm_89. - Em GPUs futuras (acima de 8.9), se não houver SASS exato, ainda há PTX 8.9 para o driver compilar via JIT.
Benchmark honesto: duas dicas rápidas para não “se enganar”
Seu micro benchmark já é excelente para ilustrar o ponto, mas em artigo eu sempre recomendo mencionar:
- Warm-up: rode o kernel algumas vezes antes de medir (evita pegar JIT/cache/boost “frio”).
- Várias iterações: meça média/mediana de N execuções (evita ruído de clock/boost).
Isso não muda a mensagem principal (CC correta importa), mas dá credibilidade técnica.
O código do exemplo (para referência no artigo)
Abaixo está o kernel e a medição por cudaEvent exatamente como você forneceu (um microbenchmark simples para evidenciar diferenças de codegen/arquitetura):
#include <stdio.h>
#include <cuda.h>
__global__ void matmul_kernel(float *A, float *B, float *C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
float sum = 0.0f;
for (int i = 0; i < N; i++) {
sum += A[idx * N + i] * B[i * N + idx];
}
C[idx] = sum;
}
}
int main() {
const int N = 1024;
const int size = N * N * sizeof(float);
float *hA = (float*)malloc(size);
float *hB = (float*)malloc(size);
float *hC = (float*)malloc(N * sizeof(float));
for(int i = 0; i < N*N; i++){
hA[i] = 1.0f;
hB[i] = 1.0f;
}
float *dA, *dB, *dC;
cudaMalloc(&dA, size);
cudaMalloc(&dB, size);
cudaMalloc(&dC, N * sizeof(float));
cudaMemcpy(dA, hA, size, cudaMemcpyHostToDevice);
cudaMemcpy(dB, hB, size, cudaMemcpyHostToDevice);
dim3 block(256);
dim3 grid((N + block.x - 1) / block.x);
// Medição
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
matmul_kernel<<<grid, block>>>(dA, dB, dC, N);
cudaEventRecord(stop);
cudaDeviceSynchronize();
float ms = 0.0f;
cudaEventElapsedTime(&ms, start, stop);
printf("Tempo de execução: %.2f ms\n", ms);
cudaMemcpy(hC, dC, N * sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(dA); cudaFree(dB); cudaFree(dC);
free(hA); free(hB); free(hC);
return 0;
}
Fechando: a regra de ouro
Se o seu time como no exemplo aqui, compila em T4 (CC 7.5) para homologação, mas o alvo também inclui Ada (CC 8.9), não escolha um único target.
- Compute Capability certa = performance “de graça”
- Compute Capability errada = gargalo invisível que pode custar ordens de grandeza (como seus 33×)
E o melhor: corrigir isso geralmente é só ajustar flags de build e de quebra você padroniza uma entrega que roda bem em cloud e local.
Checklist final para o time de TI (cloud + desktop)
- Não compile “só para a GPU da de testes” se o binário roda fora dela
- Gere fat binary com
-gencodepara todos os alvos relevantes - Inclua PTX (ex.:
code=compute_XX) quando você não controla 100% dos alvos - Padronize isso no CMake/CI (não deixe o dev “lembrar” na mão)
- Documente o CC alvo por ambiente (homologação, dev, produção)
Conclusão
Compute Capability não é detalhe: é uma decisão de engenharia de build que pode te entregar performance “de graça” ou te fazer carregar um gargalo invisível por meses.
Qwen3-TTS: TTS open source com streaming de baixa latência e controle de voz.

A equipe Qwen (Alibaba Cloud) liberou o Qwen3-TTS, uma suíte multilíngue e open source de text-to-speech focada em três frentes que, na prática, costumam exigir pipelines separados: TTS de alta qualidade, clonagem de voz (com poucos segundos de referência) e “design” de voz guiado por descrição em linguagem natural. A proposta aqui é clara: oferecer uma pilha única, pronta para produção de voice agents, dublagem, narração e interfaces conversacionais com streaming em tempo real e controle detalhado de estilo
O que muda na prática: “primeiro pacote” rápido e voz controlável
O destaque do Qwen3-TTS é o foco explícito em latência percebida. No relatório técnico, o time descreve o objetivo de emitir áudio rapidamente (o famoso first-packet latency), citando valores na casa de ~97 ms para a variante menor e ~101 ms para a maior, em configuração de referência. Isso é o tipo de número que muda a experiência de um assistente de voz: em vez de “pensar em silêncio”, o sistema começa a falar quase imediatamente e vai completando o restante conforme gera. https://arxiv.org/pdf/2601.15621v1
Ao mesmo tempo, o Qwen3-TTS foi desenhado para ser controlável por instruções (estilo “ChatML/Chat-like”), permitindo guiar emoção, ritmo, entonação e timbre com prompts. Isso vale tanto para vozes predefinidas quanto para vozes clonadas — e também para o modo “VoiceDesign”, em que você descreve a voz (“nervoso, adolescente, entonação ascendente…”) e o modelo tenta materializar essa identidade sonora.
Família de modelos: Base, CustomVoice e VoiceDesign
A suíte é organizada em variantes com objetivos bem definidos:
- Base (0.6B e 1.7B): o “coringa” para TTS e clonagem de voz, onde você fornece um áudio de referência (e opcionalmente a transcrição) para imitar o falante.
CustomVoice (0.6B e 1.7B): modelos com vozes/timbres curados e “prontos” para usar via prompt, ideais para prototipar produtos com consistência de personagem sem precisar gravar dataset próprio.
VoiceDesign (1.7B): criação de voz “do zero” a partir de descrições em linguagem natural, útil para gerar personas novas (e, em seguida, reutilizá-las). Um ponto importante para quem publica conteúdo ou atende público global: o Qwen3-TTS cobre 10 idiomas, incluindo Português (além de chinês, inglês, japonês, coreano, alemão, francês, russo, espanhol e italiano).
O “segredo” do streaming: tokenizer de fala e arquitetura dual-track
Grande parte da mágica vem do tokenizer de fala (codec) e do desenho do modelo. O artigo e o relatório descrevem um tokenizer em 12,5 frames/s (chamado “12Hz”), com múltiplos codebooks para separar conteúdo semântico de detalhes acústicos viabilizando compressão agressiva sem “matar” naturalidade. A arquitetura do modelo é descrita como dual-track, permitindo que, a cada avanço do texto, já haja previsão de tokens acústicos e decodificação incremental do áudio.
No relatório técnico, o time também menciona a existência de dois tokenizers (12Hz e 25Hz), com trade-offs diferentes (o 12Hz mirando ultra-low latency). E, no repositório oficial, eles deixam claro que nem tudo do relatório está liberado ainda: alguns modelos citados no paper devem ser disponibilizados depois, enquanto a série pública atual gira em torno do tokenizer 12Hz e modelos 0.6B/1.7B. https://github.com/QwenLM/Qwen3-TTS
Benchmarks: clonagem zero-shot e qualidade multilíngue
Os resultados apresentados enfatizam dois eixos: inteligibilidade (ex.: WER em cenários de clonagem) e similaridade de falante (o quão parecido fica com a voz-alvo). No texto de divulgação, a equipe destaca desempenho forte em clonagem zero-shot e bons resultados multilíngues, inclusive em testes cruzados (um falante “mantendo identidade” ao falar outro idioma).
Licença e por que isso importa
Um detalhe que vale ouro para quem cria produto: a equipe afirma que está liberando modelos e tokenizers sob licença Apache 2.0, o que costuma facilitar adoção comercial (sempre com a devida revisão jurídica do seu caso).
Mão na massa: como experimentar rápido
O repositório oficial indica um caminho bem direto: instalar o pacote qwen-tts via PyPI e carregar os modelos por ID do Hugging Face, com exemplos tanto para VoiceDesign quanto para Voice Clone. Eles também mostram como reusar um “prompt de clonagem” para evitar recomputar características do falante quando você vai gerar várias falas na mesma voz (ótimo para reduzir custo/latência).
Dica prática: se a sua meta é real-time voice agent, olhe primeiro para a combinação modelo + streaming + reuso de prompt de clonagem é aí que normalmente se ganha responsividade sem sacrificar tanto a qualidade.
Cuidados e uso responsável
Sempre que falamos de clonagem e design de voz, vale reforçar: use com consentimento, sinalize quando uma voz for sintetizada (quando aplicável) e evite cenários que possam facilitar fraude/impersonação. Modelos bons tornam isso mais importante, não menos.
OpenCV 4.13.0: desempenho, robustez e maturidade em produção

No último dia de dezembro de 2025 foi lançada a versão 4.13.0 do OpenCV, a biblioteca de visão computacional mais utilizada no mundo. Diferente de versões focadas apenas em novos recursos pontuais, o OpenCV 4.13.0 se destaca por consolidar desempenho, estabilidade e suporte a arquiteturas modernas, tornando-se uma atualização especialmente relevante para ambientes de produção, IA embarcada e pipelines de alto desempenho.
Compartilho aqui minha felicidade, pois por meu nome esta presente na lista de contribuidores no projeto oficial.
Robustez e confiabilidade
Um dos pontos mais fortes do OpenCV 4.13.0 é a grande quantidade de correções críticas. A biblioteca recebeu melhorias importantes relacionadas a:
- Correções de memory leaks, heap-buffer-overflow e acessos fora dos limites.
- Tratamento mais seguro de entradas inválidas ou degeneradas.
- Maior estabilidade numérica em funções sensíveis como calibração de câmera, PnP,
solveCubic,minAreaRecte algoritmos geométricos.
Esse conjunto de ajustes reduz drasticamente riscos de falhas em sistemas que operam continuamente, como aplicações industriais, automação, robótica e visão computacional em tempo real.
Ganhos reais de desempenho multiplataforma
A versão 4.13.0 traz otimizações profundas voltadas a diferentes arquiteturas modernas:
- x86 (AVX512)
- ARM (NEON, SVE, Windows ARM64)
- RISC-V (RVV)
- IBM POWER9
Essas otimizações impactam diretamente operações fundamentais como filtros (Gaussian Blur, bilateral), gradientes (Sobel, Scharr), Canny, operações morfológicas e kernels usados em DNN.
Além disso, melhorias no HAL e no backend IPP reduzem gargalos em cenários multi-thread e de alto throughput.
Na prática, isso significa mais FPS, menor latência e melhor aproveitamento de hardware, sem mudanças no código da aplicação.
Evolução consistente em algoritmos clássicos de visão
O OpenCV 4.13.0 também avança na qualidade dos algoritmos tradicionais:
- Novo Iterative Phase Correlation, ampliando precisão em alinhamento de imagens.
- Melhorias significativas em
convexHull,minEnclosingCircle,approxPolyDPe geometria computacional. - Correções em Hough Lines, connected components e desenho de contornos.
- Optical Flow e ECC mais flexíveis, com suporte multicanal e máscaras opcionais.
Essas melhorias são especialmente importantes para aplicações que dependem de precisão geométrica, como metrologia, inspeção visual, visão estéreo e mapeamento.
DNN mais estável, rápido e compatível
O módulo DNN recebeu atenção especial:
- Suporte ampliado a ONNX e TFLite, incluindo novas camadas.
- Correções no parsing de convoluções e flags de otimização.
- Otimizações de GEMM e softmax, com intrínsecos específicos para ARM.
- Correções de falhas críticas que poderiam causar crashes em redes complexas.
Isso torna o OpenCV ainda mais confiável como engine de inferência leve, especialmente em ambientes edge e embarcados.
VideoIO e codecs mais modernos
Outro destaque é a evolução no suporte a vídeo e câmeras:
- Compatibilidade com FFmpeg 8.0. (ISTO É DEMAIS)
- Melhor integração com aceleração por hardware (incluindo HEVC em Raspberry Pi 4 e 5).
- Avanços no suporte a câmeras industriais (Orbbec, Aravis).
- Correções importantes em seek, escrita de vídeo e uso de codecs por hardware.
Essas melhorias são essenciais para quem trabalha com captura de vídeo em tempo real, visão embarcada e sistemas de aquisição contínua.
Imgcodecs mais completos e seguros
O módulo de codecs evoluiu significativamente:
- Suporte avançado a metadados (ICCP, XMP, cICP) em JPEG, PNG, WebP e AVIF.
- OpenEXR com leitura e escrita multiespectral.
- Maior tolerância a imagens muito grandes (acima de 1 GiB).
- Diversas correções encontradas por fuzzing, reforçando a segurança contra arquivos malformados.
Isso amplia o uso do OpenCV em pipelines profissionais de imagem, fotografia computacional e processamento científico.
Bindings mais maduros (Python, Java e JavaScript)
A versão 4.13.0 também melhora bastante a experiência para desenvolvedores:
- Python: suporte a DLPack, tipagem mais precisa, menos vazamentos de memória.
- JavaScript/WASM: melhor performance, deep copy correto e APIs mais consistentes.
- Java: wrappers mais modernos e opções de gerenciamento de ciclo de vida.
Essas melhorias tornam o OpenCV mais integrado a pipelines modernos de IA, web e ciência de dados.
Build, CUDA e futuro
Por fim, o OpenCV 4.13.0 olha claramente para o futuro:
- Suporte a CUDA 13.0.
- Compatibilidade com Visual Studio 2026.
- Builds reprodutíveis.
- Integração do KleidiCV 0.7 por padrão em Linux e macOS.
- Melhor compatibilidade com toolchains novos e antigos.
Conclusão
O OpenCV 4.13.0 não é apenas uma atualização incremental. Ele representa uma versão madura, estável e altamente otimizada, pronta para:
- Ambientes industriais
- IA embarcada e edge computing
- Pipelines de visão computacional em larga escala
- Aplicações críticas em tempo real
Se você utiliza OpenCV em produção, esta versão é altamente recomendada — não apenas pelos novos recursos, mas principalmente pela qualidade, performance e confiabilidade que ela entrega.
Mais detalhes deste release e informações aqui: https://github.com/opencv/opencv/wiki/OpenCV-Change-Logs#version4130
Abaixo a lista de contribuidores deste release, parabéns a todos os envolvidos.
0AnshuAditya0, Aakash Preetam, Abhishek Gola, Abhishek Shinde, Aditya Jha, Adrian Kretz, AdwaithBatchu, Akash Arunkumar, Alessandro de Oliveira Faria (A.K.A.CABELO), Alex, Alexander Alekhin, Alexander Smorkalov, Anastasiya Pronina, Andrei Tamas, Ansh Swaroop, Anshu, Arsenii Rzhevskii, Atri Bhattacharya, Benjamin Buch, Brian Ferri, ClaudioMartino, cudawarped, D00E, Dave Merchant, Dheeraj Alamuri, Dimitre, Dmitry Kurtaev, Dmytro Dadyka, eplankin, Ghazi-raad, happy-capybara-man, harunresit, inventshah, kallaballa, Karnav Shah, Kumataro, Madan mohan Manokar, Maxim Smols kiy, Pierre Chatelier, pratham-mcw, raimbekovm, ramukhsuya, Samaresh Kumar Singh, satyam yadav, Stefania Hergane, Suleyman TURKMEN, utibenkei, Vadim Levin, Vincent Rabaud, and Yuantao Feng

librePods: liberte seu AirPods em 2026.

Relembrando os tempos dourados, deixo aqui no Viva O Linux, Um artigo onde veremos como libertar o seu AirPods para utilizá-lo na plataforma Linux com todos os recursos diferenciados deste hardware.
Quando você conecta um AirPods a um desktop Linux, normalmente ele funciona como “um fone Bluetooth qualquer”: áudio ok, mas boa parte dos recursos premium (ANC/Transparency, detecção de ouvido, bateria confiável, ajustes finos, etc.) fica presa ao ecossistema Apple. O LibrePods nasceu justamente para “libertar” esses recursos.
O que é o LibrePods
LibrePods é um projeto open source que desbloqueia recursos avançados dos AirPods em dispositivos não-Apple, trazendo de volta modos de ruído, transparência/adaptive, detecção de ouvido, status de bateria, modo “hearing aid”, personalizações e mais recursos que a Apple costuma expor só quando o fone “acha” que está conectado a iOS/macOS.
Para que serve (no Linux)
Na prática, no Linux ele serve como um painel/controle para o seu AirPods, com um app nativo (GUI) que expõe funções que normalmente não aparecem no stack Bluetooth padrão. O repositório mantém um app Linux dedicado e releases específicos.
Como ele funciona (visão técnica, sem magia)
O “pulo do gato” do LibrePods é que ele implementa (via engenharia reversa) partes do protocolo proprietário usado pelos AirPods para negociar recursos com dispositivos Apple. Em várias funções, a liberação depende de identificação do dispositivo host (ex.: fabricante/vendor), então o projeto também documenta mecanismos para o host “se apresentar” de forma compatível e o AirPods liberar telemetria e controles avançados. The Verge+1
Em outras palavras: não é “tweak de UI”; é protocolo + controle de estados (e, em alguns cenários, identificação do host) para acessar recursos que já existem no hardware do AirPods.
Vantagens para usuárias Linux
- Você usa o que pagou: ANC/Transparency/Adaptive e outros controles deixam de ficar “reféns” do iPhone/iPad/Mac.
- Status de bateria mais útil (incluindo case/earbuds, dependendo do modelo/estado do suporte).
- Experiência mais integrada: o projeto menciona melhorias de integração (ex.: expor bateria e atalhos de controle), e existe um app Linux com funcionalidades centrais.
- FOSS e auditável: por ser open source, dá para inspecionar/acompanhar evolução e limitar “apps caixa-preta” que só fazem polling genérico.
Observação importante de maturidade: o README do projeto sinaliza que o app Linux tem/teve uma fase “versão antiga” e que há trabalho em uma nova versão, então espere evolução rápida e possíveis arestas dependendo do seu modelo de AirPods e distro.
Requisitos no Linux
1) Hardware/stack Bluetooth
- Adaptador Bluetooth funcional no PC (interno ou dongle).
- BlueZ e serviços de Bluetooth ativos (padrão na maioria das distros desktop).
2) AirPods compatíveis
O projeto lista compatibilidades por modelo (alguns com suporte completo, outros parcial). Em geral, modelos mais recentes tendem a receber o “suporte cheio” primeiro.
| Status | Device | Features |
|---|---|---|
 |
AirPods Pro (2nd Gen) | Fully supported and tested |
|
AirPods Pro (3rd Gen) | Fully supported (except heartrate monitoring) |
|
AirPods Max | Fully supported (client shows unsupported features) |
 |
Other AirPods models | Basic features (battery status, ear detection) should work |
Dependências
Devemos garantir que o sistema de gerenciamento de audio e bluethooth esteja funcionando corretamento.
Qt6 packages
# For Arch Linux / EndeavourOS
sudo pacman -S qt6-base qt6-connectivity qt6-multimedia-ffmpeg qt6-multimedia
# For Debian
sudo apt-get install qt6-base-dev qt6-declarative-dev qt6-connectivity-dev qt6-multimedia-dev \
qml6-module-qtquick-controls qml6-module-qtqml-workerscript qml6-module-qtquick-templates \
qml6-module-qtquick-window qml6-module-qtquick-layouts
# For Fedora
sudo dnf install qt6-qtbase-devel qt6-qtconnectivity-devel \
qt6-qtmultimedia-devel qt6-qtdeclarative-devel
# For openSUSE
sudo zypper install patterns-kde-devel_qt6
openSSL
# On Arch Linux / EndevaourOS, these are included in the OpenSSL package, so you might already have them installed.
sudo pacman -S openssl
# For Debian / Ubuntu
sudo apt-get install libssl-dev
# For Fedora
sudo dnf install openssl-devel
# For openSUSE
sudo zypper install openssl-devel
Libpulse e cmake
# On Arch Linux / EndevaourOS, these are included in the libpulse package, so you might already have them installed.
sudo pacman -S libpulse
# For Debian / Ubuntu
sudo apt-get install libpulse-dev
# For Fedora
sudo dnf install pulseaudio-libs-devel
# For openSUSE
sudo zypper install pulseaudio-qt-devel cmake libpulse-devel
Download, compilação e instalação.
Agora com todos requisitos instalado e cofigurado, efetue do download dos fontes com o comando git clone.
git clone https://github.com/kavishdevar/librepods
Após o download entra na pasta linux dentro da pasta librepods recém criada.
cd librepods/linux
Ao entrar na pasta, devemos criar a pasta build e os comandos cmake e make para efetuas a compilação.
mkdir build cd build cmake .. make -j $(nproc)
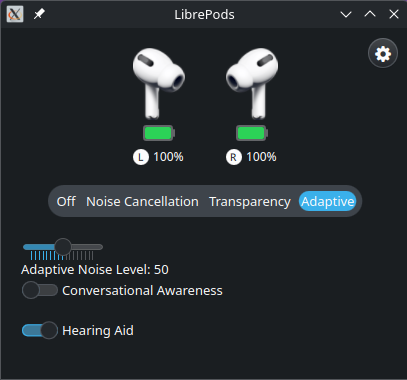
Se tudo funcionou corretamente, teremos o binario librepods na pasta pronto para ser executado. Então basta digitar ./librepods e teremos uma tela como na figura a baixo e pronto! Boa liberdade.
Mais informações na página oficial do projeto. https://github.com/kavishdevar/librepods/