Sun, Mar 17, 2024

 cabelo
cabeloCorrigindo mãos de imagens criadas com IA.

A Stable Diffusion e outras tecnologia de modelos probabilísticos de difusão enfrenta um problema com mãos. É bastante comum ver mãos deformadas ou com dedos faltando ou extras. Neste texto, vamos explorar algumas maneiras de corrigir mãos baseado no paper arXiv:2311.17957 .
Baseado no estudo, o paper apresentou uma solução de pós-processamento leve chamada HandRefiner para corrigir mãos malformadas em imagens geradas. O HandRefiner utiliza uma abordagem de inpainting condicional para retificar mãos malformadas, deixando outras partes da imagem inalteradas. Foi utilizado o modelo de reconstrução de malha de mão que adere consistentemente ao número correto de dedos e à forma da mão, sendo também capaz de ajustar a pose desejada da mão na imagem gerada. Dada uma imagem gerada falha devido a mãos malformadas, utiliza-se o módulos ControlNet para reinjetar essas informações corretas de mão. Além disso, foi descoberto um fenômeno de transição de fase dentro do ControlNet à medida que variamos a força de controle. Isso nos permite tirar vantagem de dados sintéticos mais facilmente disponíveis sem sofrer com a lacuna de domínio entre mãos realistas e sintéticas.
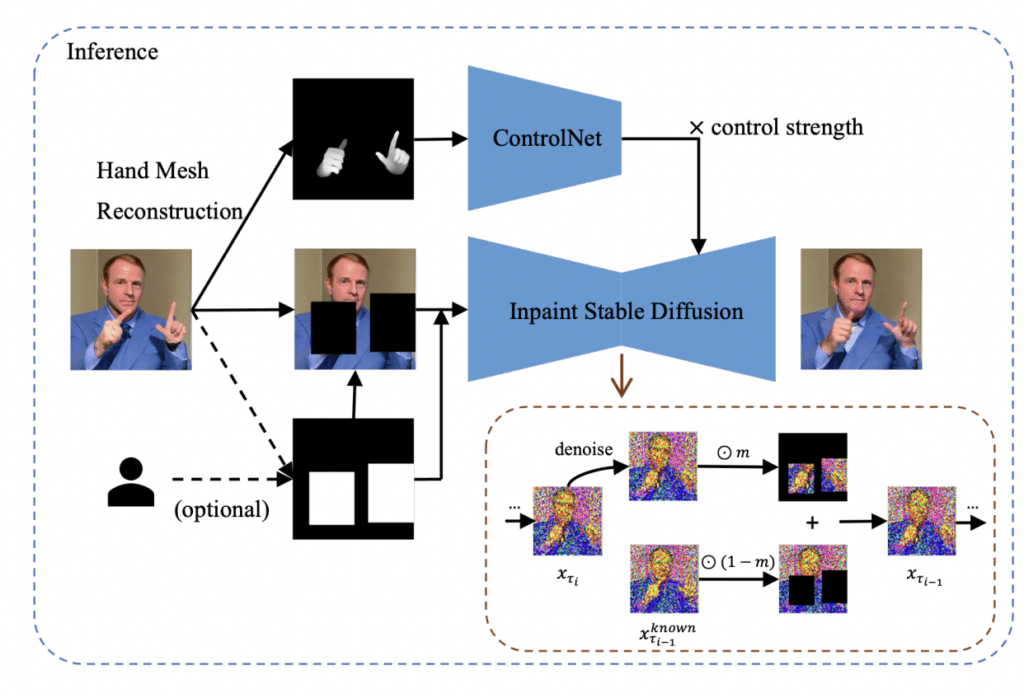
O fontes do projetos estão no repositório github no link: https://github.com/wenquanlu/HandRefiner/
Para iniciarmos, devemos entrar no modo inpaint e transferir a imagem recém criada ou fazer o upload da imagem.


Agora no modo inpaint, selecione as mão, conforme o exemplo abaixo.

Agora em InPaint area, selecione a opção Only masked, conforme a ilustração abaixo.
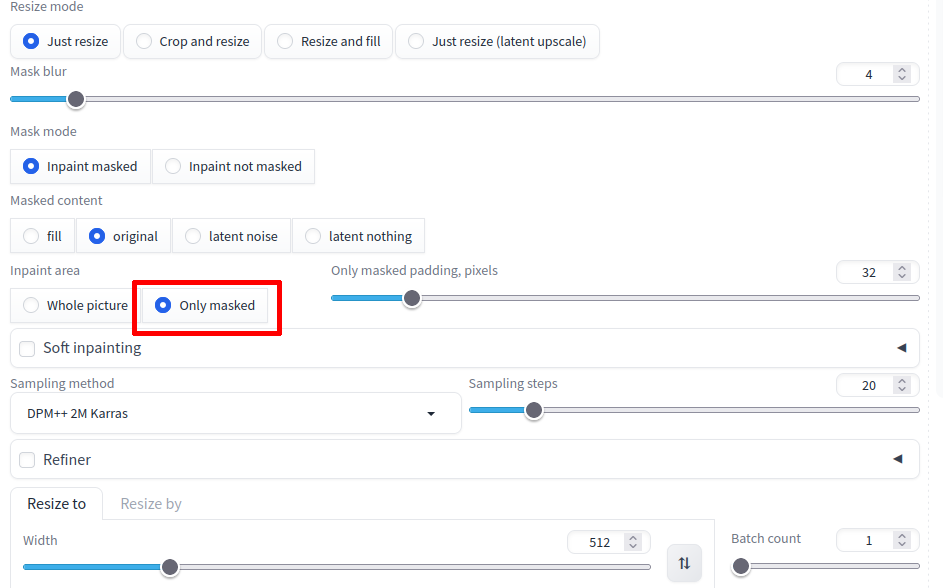
Como na figura abaixo, habilite a opção ControlNet, selecione o Contro Type Depth, na lista Proprocessor, selecione depth_hand_refiner e por fim o modelo control_sd15_inpaint_depth_hand_fp16.

Agora clique no botão Generate e pronto!
Se tudo estiver funcionando corretamente, teremos o resultado a seguir.


Sat, Mar 16, 2024
OpenVINO 2024.0.0 lançado!
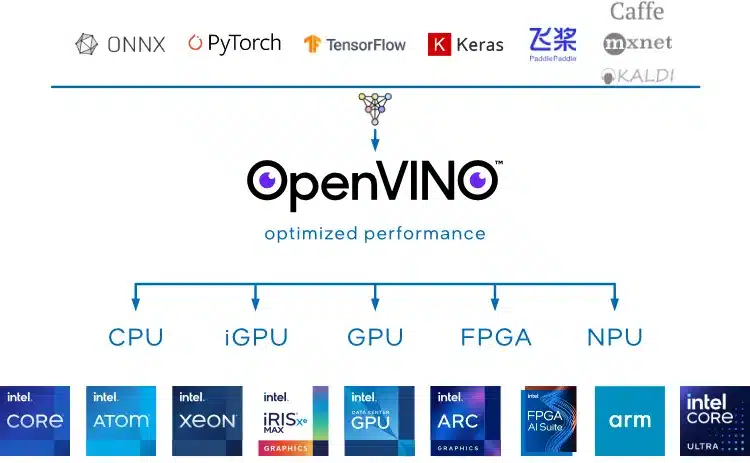
A semana passada foi lançado a versão 2024.0.0 do openVINO, abaixo os principais destaques:
Mais cobertura de IA Genérica e integrações de frameworks para minimizar alterações no código:
A versão 2024.0 do OpenVINO, lançada pela Intel, introduz avanços significativos em IA generativa (GenAI) e uma nova API JavaScript, reforçando seu compromisso com a otimização e implementação de inferências de IA em uma gama diversificada de plataformas de hardware. Este kit de ferramentas de código aberto se destaca por sua capacidade de acelerar a inferência de IA não somente em CPUs x86_64, mas também em CPUs ARM, diversas arquiteturas, GPUs Intel integradas e dedicadas, além de aproveitar a nova Unidade de Processamento Neural (NPU) Intel através do plugin NPU, especialmente projetado para os SoCs Core Ultra “Meteor Lake” recentemente lançados.
Com esta atualização, o OpenVINO 2024.0 concentra-se ainda mais em capacidades de IA generativa, aprimorando a experiência do usuário com modelos de codificação de sentenças TensorFlow, introduzindo suporte para Mix of Experts (MoE), disponibilizando uma API JavaScript para acesso simplificado à API OpenVINO, e garantindo modelos validados para Mistral, entre outras novidades.
Suporte mais amplo para modelos LLM e mais técnicas de compressão de modelos:
Além disso, essa nova versão melhora significativamente a compressão de pesos INT4 para Modelos de Linguagem de Grande Escala (LLMs), eleva o desempenho dos LLMs em CPUs Intel, e facilita a otimização e conversão de modelos Hugging Face, além de incluir outras melhorias relevantes à integração com Hugging Face.
O OpenVINO 2024.0 também marca o fim do suporte ao anterior Gaussian e Neural Accelerator (Intel GNA), voltando agora sua atenção para a NPU disponível nos SoCs Meteor Lake e versões mais recentes. Notavelmente, o plugin Intel NPU é agora incorporado ao pacote principal do OpenVINO disponível no PyPi, beneficiando não apenas os usuários de tecnologia Intel, mas também oferecendo melhor desempenho em CPUs ARM e várias otimizações de plataforma para usuários de diferentes ecossistemas.
Mais informações no repositorio oficial: https://github.com/openvinotoolkit/openvino/releases/tag/2024.0.0
Sat, Mar 09, 2024
Novos códigos All Star Tower Defense

As seguir a lista dos últimos códigos do jogo All Tower Defense que podem ser trocados por joias gratuitas, que você usa para invocar novos personagens para ajudar na defesa contra seus inimigos.
- blamspot500kcodeunitrelease – (novo)
- videocode12135 – 100 joias e 2.400 Gemas (novo)
- EnumaElish2024 – 400 joias e 7.300 Gema (nível 60 ou superior) (novo)
Wed, Feb 28, 2024
Provador de roupa Virtual com IA.

A difusão latente de IA representa uma inovação revolucionária no setor da moda, especialmente na forma como consumidores experimentam e selecionam roupas. Utilizando técnicas avançadas de inteligência artificial, essa tecnologia permite que os usuários provem roupas virtualmente com uma precisão e realismo impressionantes. Ao invés de se basear em simples sobreposições de imagens, a difusão latente analisa as características físicas do usuário, como a forma do corpo, a postura e as dimensões, para ajustar digitalmente as roupas de maneira que reflitam como elas ficariam no mundo real. Isso não só melhora a experiência de compra online, oferecendo uma visualização mais fidedigna do produto, mas também minimiza as taxas de retorno devido a expectativas não atendidas.
Além de beneficiar os consumidores, a difusão latente de IA é uma ferramenta valiosa para os varejistas e designers de moda. Ela permite uma análise detalhada das preferências e tendências de moda, ajustando os estoques e as coleções para atender melhor às demandas dos consumidores. Com a capacidade de simular uma ampla variedade de tecidos, estilos e cortes em diferentes corpos virtuais, os designers podem experimentar e iterar designs rapidamente sem a necessidade de produzir amostras físicas. Essa abordagem não apenas economiza tempo e recursos, mas também abre caminho para uma moda mais sustentável e personalizada, transformando a maneira como interagimos com as roupas em um ambiente digital.
Sun, Feb 25, 2024
YOLO v9 Chegou!

O YOLOv9 surgiu dia 21 de fevereiro de 2024 pelos pesquisadores Chien-Yao Wang, I-Hau Yeh e Hong-Yuan Mark Liao, no artigo “YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information”, este modelo demonstrou uma precisão superior em comparação aos modelos YOLO antecessores.
O YOLOv9 representa um avanço significativo na detecção de objetos, superando o desempenho do YOLOv8 com inovações como o Programmable Gradient Information (PGI) e a arquitetura Generalized Efficient Layer Aggregation Network (GELAN). O PGI permite a preservação completa da informação de entrada, essencial para a atualização eficaz dos pesos da rede, enquanto a GELAN melhora a eficiência dos parâmetros. Testado no dataset MS COCO, o YOLOv9 mostrou-se mais eficiente e preciso que seus predecessores, utilizando menos parâmetros e cálculos. O código-fonte e as instruções foram disponibilizados pelos autores, embora algumas versões dos pesos e licenças estejam pendentes.
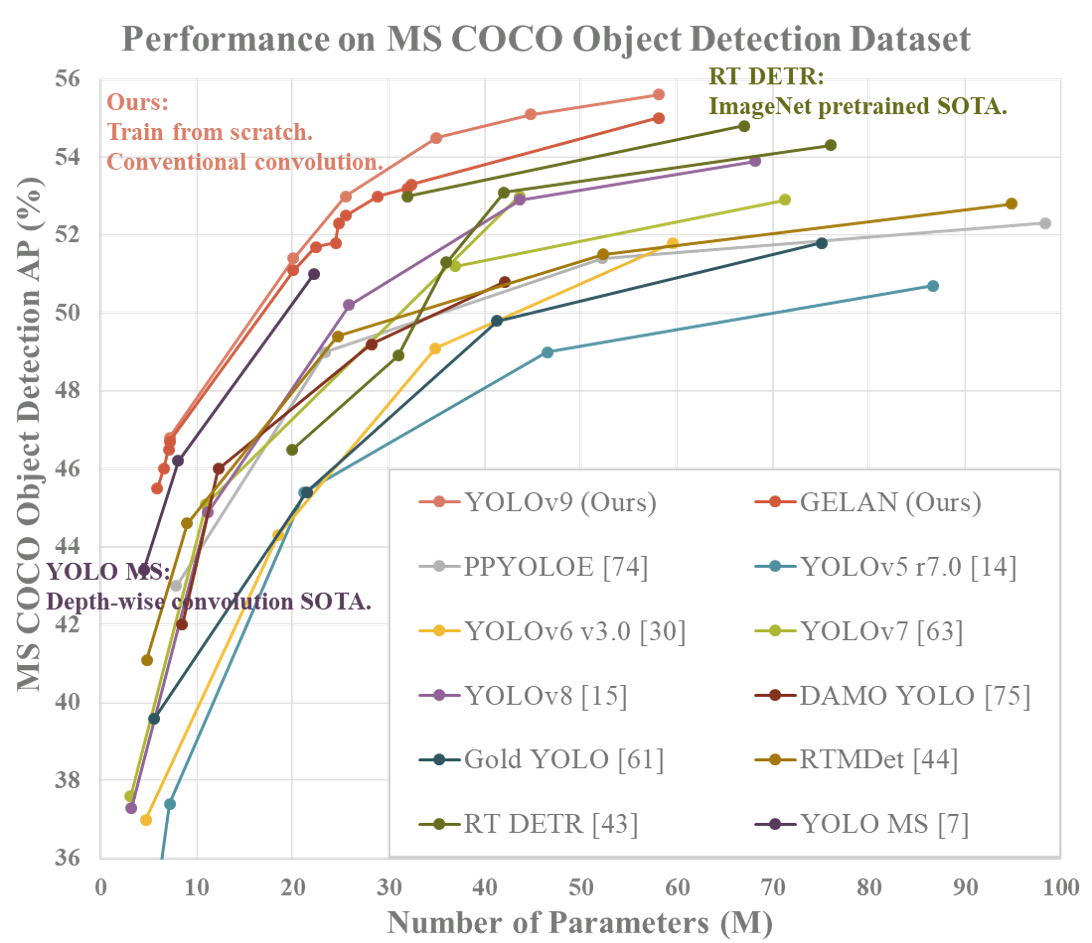
Fonte:
Melo Júnior, José Carlos de. “YOLOv9: Aprenda a Detectar Objetos”. Blog do Sigmoidal, 24 fev. 2024. Disponível em: https://sigmoidal.ai/yolov9-aprenda-a-detectar-objetos
Stable Diffusion 3

Anunciando o Stable Diffusion 3 em prévia antecipada, um modelo de texto para imagem mais capaz, com desempenho muito melhorado em prompts de múltiplos sujeitos, qualidade de imagem e habilidades de ortografia.
Embora o modelo ainda não esteja amplamente disponível, hoje, estamos abrindo a lista de espera para uma prévia antecipada. Esta fase de prévia, como com os modelos anteriores, é crucial para coletar insights para melhorar seu desempenho e segurança antes de um lançamento aberto. Você pode se inscrever para entrar na lista de espera aqui.
O conjunto de modelos do Stable Diffusion 3 atualmente varia de 800M a 8B parâmetros. Esta abordagem visa alinhar-se com nossos valores centrais e democratizar o acesso, fornecendo aos usuários uma variedade de opções para escalabilidade e qualidade para atender melhor às suas necessidades criativas. O Stable Diffusion 3 combina uma arquitetura de transformador de difusão e correspondência de fluxo. Publicaremos um relatório técnico detalhado em breve.
Acreditamos em práticas de IA seguras e responsáveis. Isso significa que estão tomando medidas razoáveis para prevenir o mau uso do Stable Diffusion 3 por atores mal-intencionados. A segurança começa quando inicia-se o treinamento do nosso modelo e continua ao longo do teste, avaliação e implantação. Em preparação para esta prévia antecipada, introduzimos inúmeras salvaguardas. Ao colaborar continuamente com pesquisadores, especialistas e nossa comunidade, esperamos inovar ainda mais com integridade à medida que nos aproximamos do lançamento público do modelo.
O compromisso em garantir que a IA gerativa seja aberta, segura e universalmente acessível permanece firme. Com o Stable Diffusion 3, teve muito esforço para oferecer soluções adaptáveis que permitam a indivíduos, desenvolvedores e empresas liberar sua criatividade, alinhando-se com nossa missão de ativar o potencial da humanidade.
Se você gostaria de explorar o uso de um de outros modelos de imagem para uso comercial antes do lançamento do Stable Diffusion 3, visite a página de Membership da Stability AI para auto hospedagem ou nossa Plataforma de Desenvolvedor para acessar nossa API.
Para ficar atualizado sobre o progresso, siga as novidades no Twitter, Instagram, LinkedIn e junte-se à Comunidade Discord.
Thu, Feb 15, 2024
NVIDIA lança chatbot local

A NVIDIA introduziu seu mais recente chatbot, equipado com capacidades de IA local, destinado aos detentores de suas placas de vídeo GeForce RTX séries 30 e 40. A inovação, denominada “Chat with RTX”, é um chatbot para computadores com sistema operacional Windows, desenvolvido com o apoio da tecnologia TensorRT-LLM, e já se encontra disponível sem custos para os modelos mais recentes das GPUs RTX. Esta solução apresenta uma mecânica de operação simples, no entanto, proporciona uma gama de possibilidades bastante ampla para os usuários, oferecendo a vantagem de empregar funcionalidades de chatbot de IA diretamente no local, eliminando a necessidade de conexão com a internet.
Projetado para funcionar como um sistema local e personalizável, o “Chat with RTX” assegura disponibilidade contínua no computador do usuário sem exigir acesso à internet. A personalização da experiência do usuário é viável através do uso de um conjunto de dados armazenado localmente no PC, sendo compatível com a maioria das GPUs das séries RTX 40 e RTX 30.
O “Chat with RTX”, viabilizado pelo software TensorRT-LLM & Retrieval Augmented Generation (RAG) da NVIDIA, foi lançado para PCs Windows no ano anterior, garantindo compatibilidade com todas as placas GeForce RTX séries 30 e 40 que possuem no mínimo 8GB de VRAM. Para os proprietários de placas compatíveis da NVIDIA, é possível realizar o download gratuito do “Chat with RTX” através do site oficial da empresa. Os usuários têm a possibilidade de vincular o chatbot a um acervo de dados local no PC, abrangendo formatos como .txt, .pdf, .doc, .docx, .xml, utilizando modelos de linguagem avançados, como Mistral e Llama 2, sendo necessário para isso os sistemas operacionais Windows 11 ou Windows 10 e os drivers mais recentes de GPU da NVIDIA para um desempenho otimizado.
YOLO-World – Visão Computacional avançada.
Entre várias tecnologias de redes neurais convolucionais, minha aposta sempre foi na técnica YOLO para visão computacional, tendo me especializado nesse método de detecção de objetos de passada única. Com a nova versão YOLO World, que agora apresenta maior eficiência graças ao seu vocabulário aberto, trago mais detalhes sobre o tema neste blog.
O Modelo YOLO-World apresenta um avanço significativo com a implementação do YOLOv8 em tempo real para tarefas de detecção com vocabulário aberto. Esta novidade possibilita a identificação de objetos em imagens utilizando descrições textuais. Com uma redução considerável nas demandas de processamento, sem comprometer a eficácia, o YOLO-World se estabelece como uma solução flexível para uma ampla gama de aplicações de visão computacional.
A seguir um teste efetuado no Espaço Intel localizado no Instituto Credicitrus. Vejam na imagem abaixo um convencional processamento com o método YOLO.

Agora o resultado do processamento com o método YOLO-World usando o vocabulário aberto.


Como resultado obtemos o processamento da classe particularmente desejada, ou seja pessoas com camisas azul. Poderíamos solicitar pessoas falando ao telefone, bebendo e outros.
YOLO-O World supera os obstáculos encontrados em modelos convencionais de detecção de vocabulário aberto, que frequentemente recorrem a complexos modelos Transformer exigindo vastos recursos computacionais. A limitação destes modelos a categorias predefinidas de objetos restringe também a sua aplicabilidade em ambientes mutáveis. YOLO-O World inova ao integrar a estrutura YOLOv8 com funcionalidades de detecção de vocabulário aberto, adotando técnicas de modelagem linguística visual e pré-treinamento em extensos conjuntos de dados, sobressaindo-se na identificação de uma ampla variedade de objetos em contextos de zero-shot com uma eficiência sem precedentes.

Principais características:
- Solução em tempo real: Utilizando a eficácia das CNNs, o YOLO-World fornece detecção de vocabulário aberto de alta velocidade, ideal para setores que requerem respostas rápidas.
- Eficiência e Alto Desempenho: O YOLO-World diminui a necessidade de recursos computacionais sem comprometer a qualidade, representando uma opção eficaz em comparação a modelos como o SAM, mas com muito menos exigência de processamento, viabilizando seu uso em aplicações dinâmicas.
- Inferência com vocabulário offline: Implementando a técnica de “prompt-then-detect”, o YOLO-World usa um vocabulário offline para otimizar a eficiência. Essa metodologia permite a utilização de comandos personalizados, como legendas ou categorias, predefinidos e armazenados como um vocabulário offline integrado, facilitando o processo de detecção.
- Potencializado por YOLOv8: Construído sobre a base do Ultralytics YOLOv8, o YOLO-World aproveita os avanços mais recentes em detecção de objetos em tempo real, proporcionando detecção de vocabulário aberto com precisão e rapidez excepcionais.
- Superioridade em benchmarks: YOLO-World ultrapassa outros sistemas de detecção de vocabulário aberto, como MDETR e GLIP, em benchmarks de referência, demonstrando o desempenho avançado do YOLOv8 em uma única GPU NVIDIA V100, tanto em velocidade quanto em eficiência.
- Aplicações Amplas: A metodologia inovadora do YOLO-World habilita novas capacidades para uma diversidade de tarefas de visão computacional, oferecendo avanços significativos em velocidade comparado aos métodos preexistentes.
Yolo com openCV:
https://docs.opencv.org/4.x/da/d9d/tutorial_dnn_yolo.html
Citações e agradecimentos
Parabenizo ao Tencent AILab Computer Vision Center pelo seu trabalho inédito na deteção de objetos de vocabulário aberto em tempo real com YOLO-World.
Paper : https://arxiv.org/pdf/2401.17270v2.pdf

Thu, Jan 25, 2024
OpenVINO 2023.3 lançado!

Em breve a minha imagem Linux batizada como JAX (Just Artificial Intelligence Extended), será uma distribuição baseada no openSUSE com IA pré-instalada para rodar em computadores modestos. Nesta imagem teremos recursos para utilizar a computação heterogênea com NVIDIA, Intel e futuros hardwares, e grande parte da mágica esta na tecnologia openVINO.
OpenVINO é uma sigla para “Open Visual Inference and Neural Network Optimization”. É uma plataforma de software livre da Intel que foi projetada para facilitar o desenvolvimento e a implantação de aplicações de inteligência artificial (IA), com foco em otimizar inferência de visão computacional e deep learning em uma variedade de dispositivos Intel. O objetivo do OpenVINO é permitir que os desenvolvedores acelerem suas aplicações de IA, otimizando para o hardware Intel, incluindo CPUs, GPUs integradas, FPGAs (Field Programmable Gate Arrays) e VPU (Unidades de Processamento Visual), como as Intel Movidius Neural Compute Sticks.
é uma sigla para “Open Visual Inference and Neural Network Optimization”. É uma plataforma de software livre da Intel que foi projetada para facilitar o desenvolvimento e a implantação de aplicações de inteligência artificial (IA), com foco em otimizar inferência de visão computacional e deep learning em uma variedade de dispositivos Intel. O objetivo do OpenVINO é permitir que os desenvolvedores acelerem suas aplicações de IA, otimizando para o hardware Intel, incluindo CPUs, GPUs integradas, FPGAs (Field Programmable Gate Arrays) e VPU (Unidades de Processamento Visual), como as Intel Movidius Neural Compute Sticks.
O software fornece uma série de ferramentas e pré-otimizações que visam melhorar o desempenho e a eficiência energética dos algoritmos de IA, permitindo que trabalhem de forma mais eficaz em hardware da Intel. Ele suporta modelos de deep learning de frameworks populares como TensorFlow, PyTorch, Caffe, MXNet, entre outros, convertendo-os para o formato intermediário do OpenVINO (IR), que é otimizado para execução eficiente em hardware da Intel.
A ideia é simplificar o processo de levar a IA do protótipo à solução final, reduzindo a necessidade de reescrever ou adaptar o código para cada tipo de hardware, permitindo assim que as aplicações tirem o máximo proveito da aceleração de hardware disponível.
Key Highlights: More Gen AI coverage and frameworks integrations to minimize code changes: Torch.compile is now fully integrated with OpenVINO, which now includes a hardware ‘options’ parameter allowing for seamless inferencing hardware selection by leveraging OpenVINO plugin architecture. Introducing OpenVINO Gen AI repository on GitHub that demonstrates native C and C++ pipeline samples for LLMs. We’ve started supporting string tensors as inputs and tokenizers natively to reduce overhead and ease of production. New and noteworthy models supported or enhanced in this release: Qwen, chatGLM3, Mistral, Zephyr, LCM, and Distil-Whisper. Broader LLM model support and more model compression techniques: As part of the Neural Network Compression Framework (NNCF), Int4 weight compression model formats are now fully supported on Intel® Xeon® CPUs in addition to Intel® Core and iGPU, adding more performance, lower memory usage, and accuracy opportunity when using LLMs. Improved performance of transformer based LLM on CPU using stateful model technique to increase memory efficiency where internal states are shared among multiple iterations of inference. Tokenizer and Torchvision transform support is now available in the OpenVINO runtime (via new API), requiring less preprocessing code and enhancing performance by automatically handling this model setup. More portability and performance to run AI at the edge, in the cloud or locally: Full support for 5th Generation Intel® Xeon® (codename Emerald Rapids), delivering on the AI everywhere promise. Further optimized performance on Intel® Core Ultra (codename Meteor Lake) CPU with latency hint by leveraging both P-core and E-cores. Improved performance on ARM platforms with throughput hint by increasing efficiency in usage of the CPU cores and memory bandwidth. Preview JavaScript API to enable node JS development to access JavaScript binding via source code. Improved model serving of LLMs through OpenVINO Model Server. This not only enables LLM serving over KServe v2 gRPC and REST APIs for more flexibility but also improves throughput by running processing like tokenization on the server side.
Principais destaques:
- Maior cobertura com IA Generativa e integrações de estruturas para minimizar alterações de código:
- Torch.compile agora está totalmente integrado ao OpenVINO, que agora inclui um parâmetro de ‘opções’ de hardware que permite uma seleção de hardware de inferência perfeita, aproveitando a arquitetura do plugin OpenVINO.
- Apresentando o repositório OpenVINO IA Generativa no GitHub que demonstra amostras de pipeline C e C++ nativos para LLMs. Começamos a oferecer suporte nativo a tensores de string como entradas e tokenizadores para reduzir a sobrecarga e facilitar a produção.
- Modelos novos e notáveis suportados ou aprimorados nesta versão: Qwen, chatGLM3, Mistral, Zephyr, LCM e Distil-Whisper.
- Suporte mais amplo ao modelo LLM e mais técnicas de compactação de modelo:
- Como parte do Neural Network Compression Framework (NNCF), os formatos de modelo de compactação de peso Int4 agora são totalmente suportados em CPUs Intel® Xeon®, além de Intel® Core
 e iGPU, adicionando mais desempenho, menor uso de memória e oportunidade de precisão ao usar LLMs.
e iGPU, adicionando mais desempenho, menor uso de memória e oportunidade de precisão ao usar LLMs. - Melhor desempenho do LLM baseado em transformador na CPU usando técnica de modelo com estado para aumentar a eficiência da memória onde os estados internos são compartilhados entre múltiplas iterações de inferência.
- O suporte à transformação Tokenizer e Torchvision agora está disponível no tempo de execução OpenVINO (por meio da nova API), exigindo menos código de pré-processamento e melhorando o desempenho ao lidar automaticamente com a configuração deste modelo.
- Como parte do Neural Network Compression Framework (NNCF), os formatos de modelo de compactação de peso Int4 agora são totalmente suportados em CPUs Intel® Xeon®, além de Intel® Core
- Mais portabilidade e desempenho para executar IA na borda, na nuvem ou localmente:
- Suporte total para Intel® Xeon® de 5ª geração (codinome Emerald Rapids), cumprindo a promessa de IA em todos os lugares.
- Desempenho ainda mais otimizado na CPU Intel® Core Ultra (codinome Meteor Lake) com dica de latência, aproveitando os núcleos P e E.
- Melhor desempenho em plataformas ARM com dica de rendimento, aumentando a eficiência no uso dos núcleos da CPU e largura de banda da memória.
- Visualize a API JavaScript para permitir que o desenvolvimento JS do nó acesse a ligação JavaScript por meio do código-fonte.
- Atendimento de modelo aprimorado de LLMs por meio do OpenVINO Model Server. Isso não apenas permite a veiculação do LLM por meio de APIs REST e gRPC do KServe v2 para maior flexibilidade, mas também melhora o rendimento ao executar processamento como tokenização no lado do servidor.
Mais informações no github: https://github.com/openvinotoolkit/openvino
Página oficial: https://docs.openvino.ai/2023.3/home.html
Instalação no openSUSE: https://en.opensuse.org/SDB:Install_OpenVINO

Tue, Jan 16, 2024
Musica criada por IA é destaque nas Rádios do Spotify.

Em uma iniciativa individual, estava decidindo qual tecnologia incluir no projeto JAX voltado para a criação musical. Durante a busca, avaliei várias opções como Muzic, MusicGen, stemgen, mustango, stableaudio, ultimatevocalremovergui, AudioLDM, musiclm-pytorch, dance-diffusion, Mubert-Text-to-Music, AIVA, Jukebox, magenta e audio-diffusion-pytorch. Nesse processo, descobri a plataforma SUNO, que começou a produzir músicas em português por volta de 29 de dezembro aproximadamente acho eu.
A criação da música levou cerca de 20 minutos, um processo acessível a qualquer pessoa, similar ao ChatGPT ou a geradores de imagens. É possível solicitar que a IA componha a música com base em um prompt ou fornecer versos e refrões específicos. Eu pedi uma música sobre pessoas tirando selfies no carnaval, com um ritmo pop carnavalesco. Segue abaixo o link com o resultado: https://distrokid.com/hyperfollow/jaxsuaia/carnaval-da-selfie

Abaixo o link das rádios onde a musica foi destaque:

- https://open.spotify.com/playlist/37i9dQZF1E4sAAL4UTCW33
- https://open.spotify.com/playlist/37i9dQZF1E4CU2UxdZIADr
- https://open.spotify.com/playlist/37i9dQZF1E4mYsPOMHq3AK
- https://open.spotify.com/playlist/37i9dQZF1E4ooRGfWtOa2A
- https://open.spotify.com/playlist/37i9dQZF1E4xWhB4r1fgLi
- https://open.spotify.com/playlist/37i9dQZF1E4lG1cyNGL6Mk
- https://open.spotify.com/playlist/37i9dQZF1E4rNOqTZ2jTSM
- https://open.spotify.com/playlist/37i9dQZF1E4t2U41orCEyT
- https://open.spotify.com/playlist/37i9dQZF1E4kGpcbubAz6a
- https://open.spotify.com/playlist/37i9dQZF1E4FwogHKHELkd
- https://open.spotify.com/playlist/37i9dQZF1E4rejAn0SyW5e