Mon, May 13, 2024

 cabelo
cabeloUnidos pelo Sul disponível nas principais lojas de música.
A música “Unidos pelo Sul” já está disponível em todas as principais plataformas de streaming de música. Com apenas um simples clique, você não apenas terá a oportunidade ouvir a canção criada 100% por Inteligência Artificial, mas também contribuirá para uma causa nobre, ajudando as vítimas afetadas pelas recentes enchentes. É uma excelente maneira de fazer a diferença na vida de quem precisa.


Spotify:
https://tinyurl.com/rs-spotify-music

YouTube Music:
https://tinyurl.com/rs-youtube-music

Amazon Music:
https://tinyurl.com/rs-amazon-music

Apple Music:
https://tinyurl.com/rs-apple-music

iTunes:
https://tinyurl.com/rs-apple-music

Deezer:
https://tinyurl.com/rs-deezer

TikTok Music:
https://tinyurl.com/rs-tiktok
Desmobilização com Inteligência Artificial
Neste post apresento a proposta do paper arXiv:2405.03682 , que propõe um fluxo de trabalho que utiliza a Stable Diffusion para aprimorar os resultados de inpainting no contexto de “defurnishing” — a remoção de móveis em imagens panorâmicas internas.
Especificamente, mostra como o aumento do contexto, o ajuste fino do modelo específico para o domínio e a melhoria na mesclagem de imagens podem produzir inpaints de alta fidelidade que são geometricamente plausíveis sem a necessidade de estimar o layout do ambiente. É demonstrado melhorias qualitativas e quantitativas em comparação com outras técnicas de remoção de móveis.

O fluxo de trabalho consiste nos seguintes componentes:
- Pré-processamento: Estimativa de máscaras de móveis por meio de segmentação semântica, rolagem e preenchimento da imagem para garantir um contexto ótimo e redução de resolução para adequação ao pipeline da Stable Diffusion.
- Inpainting: Nosso inpainting personalizado, ajustado para panoramas equiretangulares e resistente a máscaras inexatas e sombras remanescentes, reduzindo assim a tendência da Stable Diffusion em inpainting para criar objetos ilusórios.
- Pós-processamento: Super-resolução e mesclagem das imagens original e inpainted, de modo que os detalhes de alta frequência sejam preservados.
Resultado:

Informações detalhadas do paper: https://arxiv.org/abs/2405.03682
Fri, May 10, 2024
IA da IBM supera o llama3
A IBM introduziu ao mercado a Granite, uma nova série de modelos de inteligência artificial (IA) de código aberto, destinados a facilitar o processo de codificação para desenvolvedores em diversos setores. Os modelos, disponíveis em plataformas como Hugging Face, GitHub, watsonx.ai, e RHEL AI, são liberados sob a licença Apache 2.0. Eles foram projetados para auxiliar desenvolvedores na escrita, teste, depuração e distribuição de software confiável.
Granite apresenta quatro variantes, que variam de acordo com o tamanho do banco de dados, de 3 a 34 bilhões de parâmetros, de acordo com o Analytics India Magazine. Os modelos foram submetidos a testes rigorosos em diversos benchmarks e se mostraram superiores a outros modelos de código aberto semelhantes, como Code Llama e Llama 3, em várias tarefas de programação. Essa superioridade é atribuída ao seu treinamento em um vasto conjunto de dados composto por 500 milhões de linhas de código abrangendo mais de 50 linguagens de programação, permitindo-lhes identificar padrões e solucionar bugs complexos em linguagens como Python, JavaScript, Java, entre outras.
Além de suas aplicações em geração de código e testes, os modelos Granite são também adequados para automatizar tarefas rotineiras, tais como a criação de testes unitários e a elaboração de documentação técnica. “Acreditamos no poder da inovação aberta e queremos alcançar o maior número possível de desenvolvedores”, disse Ruchir Puri, cientista-chefe da IBM Research, expressando entusiasmo quanto ao potencial de desenvolvimento de novas ferramentas e software com o uso de Granite.

Informações: https://github.com/ibm-granite/granite-code-models
Wed, May 08, 2024
Música Unidos pelo Sul: Ouça e Ajude as Vítimas das Enchentes.

Desenvolvi uma música totalmente composta por inteligência artificial como parte de uma iniciativa para auxiliar as vítimas das recentes enchentes no Sul do Brasil. A faixa está disponível no Spotify e em outras plataformas musicais, com a totalidade dos rendimentos destinada aos afetados no Rio Grande do Sul. Este projeto não busca autopromoção nem atenção da mídia; seu propósito é puramente humanitário, empregando a tecnologia para oferecer suporte às pessoas impactadas pela tragédia.
Segundo o site da Remessa Online, o Spotify paga aproximadamente U$ 0,00397 por reprodução. Levando em conta os 44,1 milhões de usuários na América Latina, citados pela Bloomberg Linea, a reprodução da música cinco vezes por cada usuário em um dia poderia gerar mais de 4 milhões de reais. Estou comprometido com a transparência e com a garantia de que 100% do valor arrecadado será efetivamente destinado às vítimas das enchentes.
Se cada usuário ouvir a música
cinco vezes ao dia, a arrecadação
diária seria de aproximadamente
R$ 4,3 milhões.
Para ajudar as vítimas, basta ouvir a musica nas lojas a seguir:
https://distrokid.com/hyperfollow/jaxsuaia/unidos-pelo-sul

OU CLIQUE AQUI PARA OUVIR DIRETO NO SPOTIFY
Mon, May 06, 2024
PAG: Orientação de atenção perturbada
Estudos recentes comprovam que modelos de difusão podem gerar amostras de alta qualidade, mas a qualidade dessas amostras muitas vezes depende fortemente de técnicas de orientação durante a amostragem, como a orientação por classificador (CG) e orientação sem classificador (CFG), que não são aplicáveis na geração incondicional ou em diversas tarefas subsequentes, como restauração de imagens. Neste artigo, propomos uma nova técnica de orientação para amostragem em difusão, chamada Orientação por Atenção Perturbada (PAG), que melhora a qualidade das amostras tanto em configurações incondicionais quanto condicionais, sem a necessidade de treinamento adicional ou integração de módulos externos. O PAG é projetado para aprimorar progressivamente a estrutura das amostras sintetizadas durante o processo de desruído, aproveitando a capacidade dos mecanismos de autoatenção de capturar informações estruturais. Ele envolve a geração de amostras intermediárias com estrutura degradada, substituindo mapas de autoatenção selecionados na difusão U-Net por uma matriz identidade e orientando o processo de desruído para se afastar dessas amostras degradadas.
A Orientação por Atenção Perturbada melhora significativamente a qualidade das amostras em modelos de difusão sem necessitar de condições externas, como rótulos de classes ou prompts de texto, nem de treinamento adicional. Isso é particularmente valioso em configurações de geração incondicional, onde a orientação sem classificador (CFG) não é aplicável. Nossa orientação pode ser utilizada para aumentar o desempenho em várias tarefas subsequentes que utilizam modelos de difusão incondicionais, incluindo ControlNet com um prompt vazio e tarefas de restauração de imagem como super-resolução e inpainting.
Comparativos qualitativos entre amostras de difusão guiadas e não guiadas (linha de base). Sem quaisquer condições externas, como rótulos de classes ou prompts de texto, ou treinamento adicional, nosso PAG eleva dramaticamente a qualidade das amostras de difusão mesmo em geração incondicional, onde a orientação sem classificador (CFG) não é aplicável. Nossa orientação também pode melhorar o desempenho base em várias tarefas subsequentes, como ControlNet com prompt vazio e restauração de imagem, incluindo inpainting e desfocagem.
Mais informações:
https://github.com/v0xie/sd-webui-incantations
https://github.com/KU-CVLAB/Perturbed-Attention-Guidance

Sat, May 04, 2024
Experimentar roupas antes de comprar na Internet.
Em breve, graças à Inteligência Artificial, será possível experimentar de maneira virtual as roupas vendidas na internet antes de comprar. Para comprovar a teoria, busquei um projeto no github, e o coloquei em funcionamento na minha maquina. Após, entrei no site Véi Nerd ( https://www.veinerd.com/produto/camiseta-linux ). Escolhi uma camiseta que gostei e salvei na minha maquina. Ao submeter as duas imagens de referencia ao sistema, o resultado foi muito animador e tudo aconteceu de maneira automática.
No teste foi possível gerar imagens com um alto grau de consistência de vestuário em cenários reais. Mesmo com fundos complexos ou poses diversas das pessoas, é possível gerar imagens de alta qualidade.

O projeto IDM-VTON é a experimentação virtual baseada em imagens, que produz uma imagem de uma pessoa usando uma peça de vestuário selecionada, a partir de um par de imagens que retratam, respectivamente, a pessoa e a vestimenta. Tecnologia anteriores adaptaram modelos de difusão baseados em exemplos existentes para a experimentação virtual, a fim de melhorar a naturalidade das imagens geradas em comparação com outros métodos (como os baseados em GAN), mas não conseguiram preservar a identidade das vestimentas.
Para superar este obstáculo, o projeto IDM-VTON propões um modelo de difusão inovador que melhora a fidelidade da vestimenta e gera imagens autênticas de experimentação virtual. Pois utiliza dois módulos diferentes para codificar a semântica da imagem da vestimenta; com base no UNet do modelo de difusão,
1) a semântica de alto nível extraída de um codificador visual é fundida à camada de atenção cruzada, e então 2) os recursos de baixo nível extraídos do UNet paralelo são fundidos à camada de autoatenção. Além disso, é fornecido prompts textuais detalhados para as imagens tanto da vestimenta quanto da pessoa, a fim de realçar a autenticidade das visuais geradas. Então é constatado um método de personalização usando um par de imagens de pessoa-vestimenta, que melhora significativamente a fidelidade e autenticidade
Os meus testes experimentais demonstram que o método supera as abordagens anteriores (tanto baseadas em difusão quanto em GAN) na preservação dos detalhes da vestimenta e na geração de imagens autênticas de experimentação virtual, tanto qualitativa quanto quantitativamente. Além disso, o método de personalização proposto demonstra sua eficácia em um cenário real. Mais visualizações estão disponíveis na página do projeto: https://github.com/yisol/IDM-VTON


Fri, May 03, 2024
Wed, May 01, 2024
Transferência de material com IA.
Esta é a implementação oficial do ZeST: Zero-Shot Material Transfe a partir de uma Única Imagem. Com ZeST, é possível transferir o material de uma imagem exemplar para outra imagem de entrada. Por exemplo, a partir de uma foto de uma maçã e uma imagem de um exemplar de uma tigela dourada, o ZeST consegue aplicar o material de ouro da tigela na maçã. Esse processo é feito mantendo as pistas de iluminação precisas e assegurando que todos os outros aspectos permaneçam consistentes.
A tecnologia permite que características específicas de um material sejam replicadas em diferentes objetos em novas imagens de forma convincente. Isto é feito sem a necessidade de múltiplas imagens do mesmo material, utilizando apenas uma imagem exemplar. O resultado é uma integração visualmente harmoniosa do novo material, como ouro, em objetos tão comuns como uma maçã, respeitando as nuances de iluminação e textura originais do objeto.

Sun, Apr 28, 2024
Lançado openVINO 2024.1
OpenVINO é um kit de ferramentas de código aberto para otimizar e implantar modelos de aprendizagem profunda da nuvem até a borda. Ele acelera a inferência de aprendizado profundo em vários casos de uso, como IA generativa, vídeo, áudio e linguagem com modelos de estruturas populares como PyTorch, TensorFlow, ONNX e muito mais. Converta e otimize modelos e implante em uma combinação de hardware e ambientes Intel®, no local e no dispositivo, no navegador ou na nuvem.
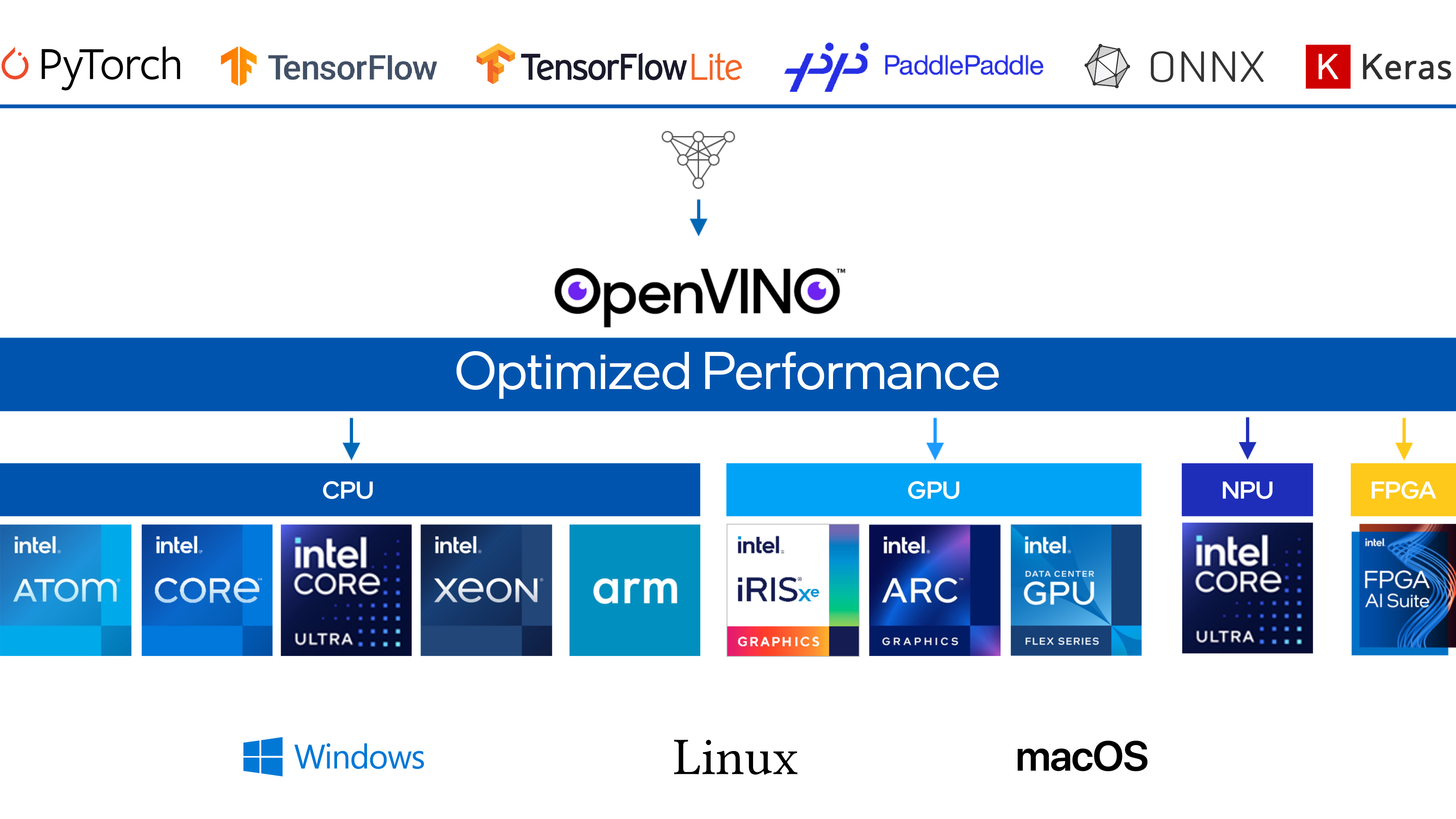
- Maior cobertura de IA generativa e integrações de frameworks para minimizar mudanças no código.
- Modelos Mixtral e URLNet otimizados para melhorias de desempenho em processadores Intel® Xeon®.
- Modelos Stable Diffusion 1.5, ChatGLM3-6B e Qwen-7B otimizados para velocidade de inferência aprimorada em processadores Intel® Core
 Ultra com GPU integrada.
Ultra com GPU integrada. - Suporte para Falcon-7B-Instruct, um modelo de chat/instrução de Large Language Model (LLM) da GenAI pronto para uso com métricas de desempenho superiores.
- Novos Jupyter Notebook adicionados: YOLO V9, Detecção de Caixas Delimitadoras Orientadas YOLO V8 (OOB), Stable Diffusion em Keras, MobileCLIP, RMBG-v1.4 Remoção de Fundo, Magika, TripoSR, AnimateAnyone, LLaVA-Next, e sistema RAG com OpenVINO e LangChain.
- Suporte mais amplo para Large Language Model (LLM) e mais técnicas de compressão de modelos.
- Tempo de compilação do LLM reduzido através de otimizações adicionais com incorporação comprimida. Desempenho aprimorado do primeiro token dos LLMs nas 4ª e 5ª gerações de processadores Intel® Xeon® com Extensões Avançadas de Matriz Intel® (Intel® AMX).
- Melhor compressão do LLM e desempenho aprimorado com suporte oneDNN, INT4 e INT8 para GPUs Intel® Arc.
- Redução significativa de memória para modelos GenAI menores selecionados em processadores Intel® Core Ultra com GPU integrada.
- Mais portabilidade e desempenho para executar IA na borda, na nuvem ou localmente.
- O plugin NPU de prévia para processadores Intel® Core Ultra agora está disponível no repositório GitHub de código aberto OpenVINO, além do pacote principal OpenVINO no PyPI.
- A API JavaScript agora está mais acessível através do repositório npm, permitindo aos desenvolvedores de JavaScript acesso sem interrupções à API OpenVINO.
- Inferência FP16 em processadores ARM agora habilitada por padrão para a Rede Neural Convolucional (CNN).
- O plugin NPU de prévia para processadores Intel® Core
 Ultra com GPU integrada.
Ultra com GPU integrada.
VIDU o INCRÍVEL Rival do Sora! Gera 16s de vídeo HDTV com prompt de texto.
Estou surpreso com a rapidez com que a tecnologia de texto para vídeo está avançando. A China acabou de anunciar seu concorrente ao Sora da OpenAI: “Vidu” pode gerar um vídeo de 16 segundos em 1080p com apenas um clique.
Desenvolvido pela empresa de IA chinesa Shengshu Technology e pela Universidade de Tsinghua, a capacidade do Vidu reside em sua arquitetura de Transformer Universal de Visão (U-ViT). O U-ViT combina as forças dos modelos de texto para vídeo baseados em difusão e transformadores.
Isso permite que o Vidu produza cenas altamente realistas e criativas a partir de simples comandos de texto.
Minha conclusão: Ainda temos um caminho a percorrer para alcançar a qualidade de Hollywood, mas estou extremamente impressionado com o quanto a tecnologia de texto para vídeo avançou no último ano.
INFORMAÇOES EM: https://www.shengshu-ai.com/home