Tue, Oct 24, 2023

 cabelo
cabelo“apocalipse quântico” pode ocorrer mais cedo!
A assustadora “criptopocalipse ou apocalipse quântico“, ou o fim da criptografia atual, pode chegar antes do que pensávamos devido aos ASICs de computação em memória, e não por causa dos computadores quânticos. ASICs são chips personalizados, mais demorados e caros de produzir do que chips comuns.

Imagem ilustrativa : Eu com um Asic Miner Bitcoin Butterfly Labs 30gh
Existem pesquisas no uso de ASICs de processamento em memória para potencialmente quebrar sistemas de criptografia de chave pública, mais conhecidos como RSA, de 2.048 bits em tempo real .
A teoria é que, se o processamento e os dados puderem ser combinados na memória, o chamado gargalo de von Neumann pode ser quebrado. Esse gargalo é a latência introduzida por ter armazenamento e processamento separados, e a consequente necessidade de comunicação entre os dois.
MemComputing
O principal problema atual é o “gargalo de von Neumann”, que é a demora causada por armazenar e processar informações separadamente. À medida que os cálculos se tornam mais complexos, o tempo para processá-los aumenta exponencialmente em computadores tradicionais. A criptografia RSA tem sido segura porque fatorar grandes números é muito demorado nesses sistemas.
A pesquisa da MemComputing sugere que seu método pode resolver problemas difíceis mais rápido, tornando possível decifrar o RSA antes da chegada dos computadores quânticos. Embora ainda seja teórico, se for verdadeiro, a criptografia atual pode estar em risco mais cedo devido aos ASICs de computação em memória.
Fonte do paper: https://arxiv.org/pdf/2309.08198.pdf

Sun, Oct 22, 2023
3D-GPT : Inteligência Artificial e Metaverso se aproximando.
A importância da modelagem de ativos 3D é inegável na era do metaverso. Os métodos tradicionais de modelagem 3D de cenas sintéticas realistas envolvem tarefas minuciosas de design complexo, refinamento e comunicação com o cliente.
Em minha jornada diária e persistente de vasculhar meticulosamente os artigos científicos publicados, buscando identificar aqueles que, inquestionavelmente, moldarão o panorama do futuro, quero destacar de forma especial o 3D-GPT.
Esse artigo, que foi divulgado na última quinta-feira, dia 19 de outubro de 2023, não é apenas mais um entre tantos. Ele apresenta e discorre sobre a iminente e fascinante convergência entre o metaverso e a inteligência artificial. Essa fusão, conforme evidenciado no documento, promete redefinir os paradigmas de como percebemos e interagimos com realidades virtuais, destacando-se como um marco no avanço tecnológico e conceitual. A relevância deste paper é tamanha que ele pode muito bem ser um dos pilares que sustentará as inovações nas próximas décadas.
Resumindo, o paper 3D-GPT, utiliza Large Language Mode (LLMs) para modelagem 3D orientada por instruções. Neste contexto, o 3D-GPT capacita os LLMs para proporcionar tarefas de modelagem 3D em segmentos gerenciáveis e determinando o agente apropriado para cada um.
O 3D-GPT é estruturado com a presença de três agentes fundamentais que desempenham papéis específicos: o agente de despacho de tarefa, responsável por organizar e delegar funções; o agente de conceituação, que interpreta e conceitua as diretrizes; e o agente de modelagem, encarregado do processo de construção e modelagem 3D em si. Trabalhando de forma integrada, estes agentes coletivamente perseguem dois propósitos de grande importância. O primeiro deles envolve um aprimoramento sistemático e consistente das descrições iniciais da cena, que são breves e sucinta. Estas descrições são progressivamente transformadas e evoluídas para representações mais detalhadas e complexas, ao mesmo tempo que o 3D-GPT ajusta e modifica dinamicamente o texto, levando em consideração as instruções adicionais que são fornecidas ao longo do processo. Como segundo objetivo, o 3D-GPT se empenha em incorporar de maneira fluida e contínua técnicas de geração procedural. Isto é realizado através da extração de valores específicos de parâmetros presentes no texto enriquecido, facilitando assim a interface e integração com programas especializados em 3D, otimizando a criação de ativos digitais.
No video acima, podemos notar que o 3D-GPT fornece resultados confiáveis e colabora efetivamente com designers humanos. Além disso, ele se integra perfeitamente ao Blender, desbloqueando mais possibilidades de manipulação. O trabalho destaca o imenso potencial dos LLMs na modelagem 3D, estabelecendo as bases para futuros avanços na geração de cenas e animação.

Link do Paper: https://arxiv.org/pdf/2310.12945.pdf

Sat, Sep 30, 2023
Criando roupas com Inteligência Artificial.

Na vanguarda da moda, tecnologias inovadoras estão redefinindo os limites do possível, mesclando o real e o virtual de formas antes inimagináveis. A inteligência artificial (IA) tem permitido a criação de modelos e vestuários digitais que, embora não existam no plano físico, são visualmente impactantes e autênticos.
Este fenômeno surge como uma ferramenta poderosa para designers e marcas, proporcionando um campo de experimentação sem limites onde estilos, texturas e cores são explorados sem a necessidade de produção física. Ao mergulharmos neste universo inovador, somos levados a questionar os contornos da realidade, pois a IA nos convida a interagir com o intangível de maneiras completamente novas.
A aplicação da IA na moda não se limita à criação de modelos e vestuários fictícios. Outra inovação revolucionária é o espelho digital com realidade aumentada, que permite aos usuários experimentarem vestidos virtualmente. Os consumidores podem visualizar, em tempo real, como as peças ficariam em seus corpos, podendo ajustar tamanhos, cores e modelos com um simples toque, proporcionando uma experiência de compra personalizada e interativa.
Esses espelhos digitais redefinem a experiência de compra ao permitirem que os consumidores explorem uma variedade infinita de opções sem a necessidade de trocar de roupa fisicamente, economizando tempo e esforço, e proporcionando um novo nível de conveniência e satisfação.
Este avanço tecnológico tem implicações significativas para o setor da moda. Permite a visualização de designs antes de sua produção, possibilitando ajustes e refinamentos, e viabiliza a produção de peças mais alinhadas com as preferências dos consumidores, minimizando excessos e desperdícios.
A integração da IA e da realidade aumentada na moda não apenas redefine o ato de vestir e a experiência de compra, mas também reflete uma evolução na forma como percebemos e interagimos com o mundo, desafiando nossas noções preexistentes de realidade e autenticidade.
No entanto, é crucial considerar questões éticas e de privacidade ao implementar tais tecnologias. A coleta e o uso responsável de dados são essenciais para garantir a confiança do consumidor e para o desenvolvimento sustentável deste novo paradigma fashion.
Finalmente, ao entrelaçar o tangível e o intangível, a moda impulsionada pela inteligência artificial e realidade aumentada oferece um vislumbre de futuros possíveis, onde a criatividade e a inovação continuam a expandir os horizontes da imaginação humana. O potencial é imenso, e as possibilidades, infinitas, à medida que avançamos para um futuro onde o real e o virtual coexistem e se complementam de maneiras surpreendentes e inspiradoras.
Fri, Sep 29, 2023
GPT-4V – O chatGPT agora enxerga imagens.
No dia 25 de setembro de 2023, a OpenAI revelou a introdução de dois recursos inovadores que expandem as maneiras com as quais as pessoas podem interagir com seu modelo mais avançado e recente, o GPT-4: a capacidade de questionar sobre imagens e de usar a voz como entrada para uma consulta.
Neste Post, as primeiras impressões do pessoal da Roboflow com o recurso de entrada de imagem do GPT-4V. Foi conduzido uma série de experimentos para averiguar as funcionalidades do GPT-4V, demonstrando os pontos onde o modelo se sai bem e onde enfrenta obstáculos.
O que é GPT-4V?
GPT-4V(ision) (GPT-4V) é um modelo multimodal criado pela OpenAI. Ele permite que os usuários façam o upload de uma imagem e realizem perguntas sobre ela, uma tarefa denominada como resposta a perguntas visuais (VQA).
O lançamento do GPT-4V começou em 24 de setembro e ele estára acessível tanto no aplicativo OpenAI ChatGPT para iOS quanto na plataforma web.
Foram diversos testes por parte da equipe Roboflow, mas o que mais me impressionou foram as habilidades do GPT-4V em responder perguntas ao questionarmos sobre um local específico. Foi Submetido uma foto de São Francisco juntamente com a pergunta “Onde é isso?”.
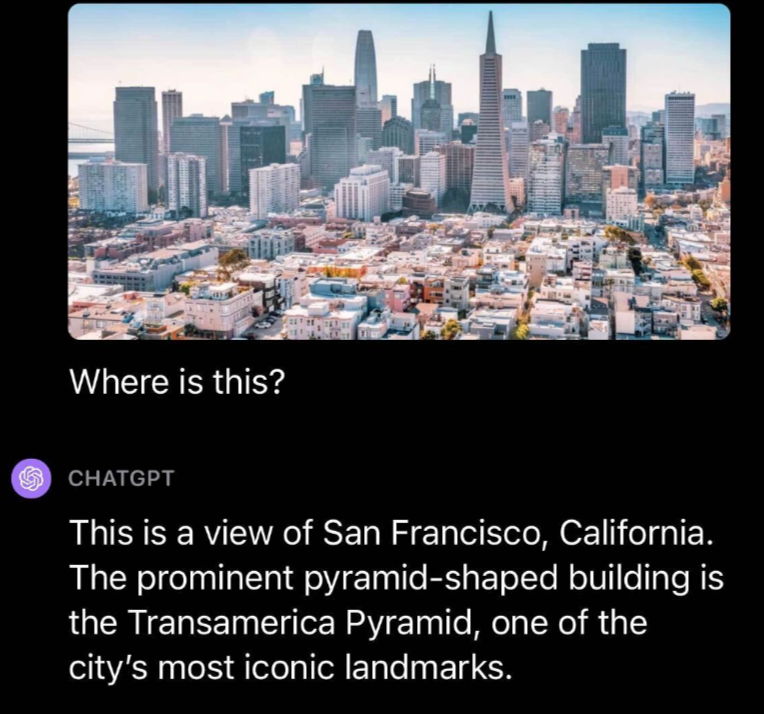
O GPT-4V reconheceu acertadamente o local como São Francisco e destacou que a Pirâmide Transamerica, presente na foto enviada, é um marco icônico da cidade.
Outro teste impressionante foi a capacidade de OCR do GPT-4V: OCR em uma imagem com texto em um pneu de carro. A intenção era construir um entendimento de como o GPT-4V se comporta em OCR em cenários reais, onde o texto pode ter menos contraste e estar em um ângulo não perpendicular.
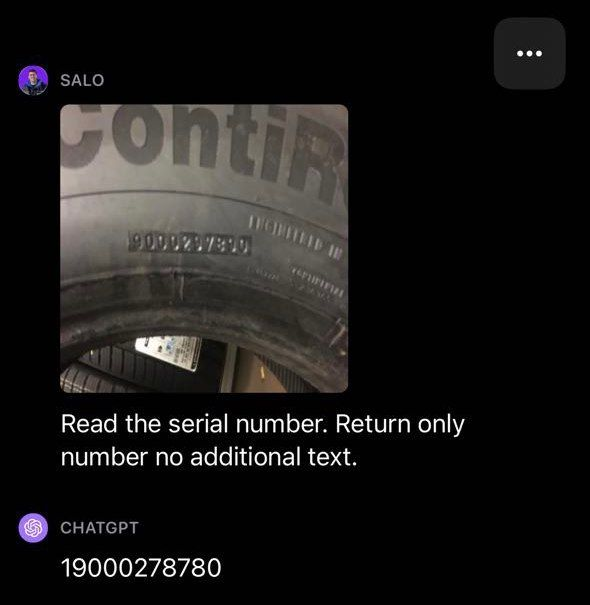
O GPT-4V não conseguiu identificar corretamente o número de série em uma imagem de um pneu. Alguns números estavam corretos, mas houve vários erros no resultado fornecido pelo modelo.
OCR Matemático é uma versão especializada de OCR destinada especificamente a equações matemáticas. Ele é muitas vezes considerado uma disciplina própria, dado que a sintaxe que o modelo de OCR necessita reconhecer abrange uma ampla variedade de símbolos.
Submetemos uma questão de matemática ao GPT-4V. Esta pergunta estava contida em uma captura de tela de um documento. A pergunta refere-se ao cálculo do comprimento de um fio de tirolesa, dados dois ângulos. Apresentamos a imagem com a instrução “Resolva isso.”
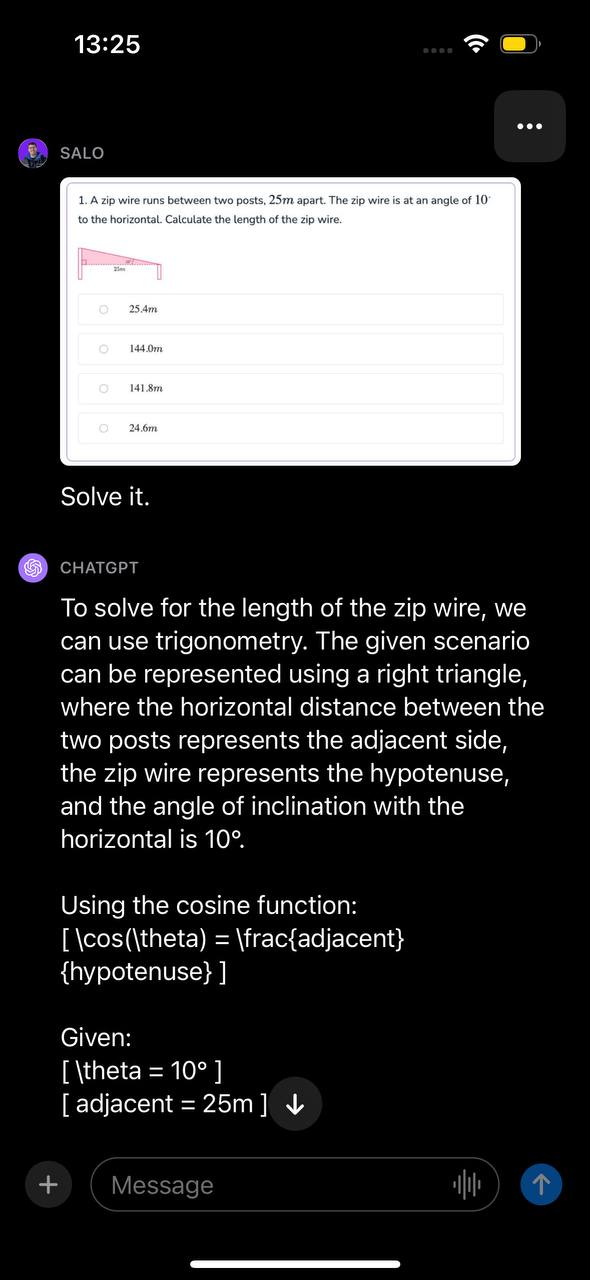

O modelo reconheceu que o problema poderia ser solucionado através de trigonometria, determinou a função apropriada a ser utilizada e demonstrou, passo a passo, como solucionar o problema. Em seguida, o GPT-4V apresentou a resposta correta para a questão.
GPT-4V em Visão Computacional e Mais
O GPT-4V representa um avanço significativo no campo da aprendizagem de máquinas e processamento de linguagem natural. Com ele, é possível fazer perguntas sobre uma imagem – e suas respectivas perguntas de seguimento – de maneira natural, e o modelo tentará fornecer uma resposta.
O GPT-4V demonstrou bom desempenho em diversas perguntas genéricas sobre imagens e mostrou ter consciência de contexto em alguns dos casos que testamos. Por exemplo, conseguiu responder corretamente a perguntas sobre um filme retratado em uma imagem sem que lhe fosse dito textualmente qual era o filme.
O GPT-4V é promissor para responder perguntas gerais. Modelos anteriores, destinados a este propósito, frequentemente apresentavam respostas menos fluentes. O GPT-4V, por outro lado, é capaz de responder a perguntas e suas respectivas de seguimento sobre uma imagem com profundidade.
Com o GPT-4V, perguntas sobre uma imagem podem ser feitas sem necessidade de um processo em duas etapas (isto é, classificação e, em seguida, usar os resultados para questionar um modelo de linguagem como o GPT). É provável que existam limitações no que o GPT-4V pode compreender, assim, testar um caso de uso para entender o desempenho do modelo é fundamental.
Com isso dito, o GPT-4V possui suas limitações. O modelo “alucinou”, fornecendo informações incorretas. Isso representa um risco ao utilizar modelos de linguagem para responder perguntas. Ademais, o modelo não conseguiu delimitar objetos com precisão para detecção, indicando que, atualmente, não é adequado para este caso de uso.
Também notamos que o GPT-4V não responde perguntas sobre pessoas. Quando apresentado com uma foto de Taylor Swift e questionado sobre quem estava na imagem, o modelo optou por não responder. A OpenAI considera isso um comportamento previsto, conforme descrito no cartão de sistema publicado.

Fri, Sep 08, 2023
O 1° comercial criado 100% com inteligência artificial.

O primeiro anúncio em vídeo com IA, que comprava o potencial da nova geração e respectiva mudança na maneira de produzir vídeo no setor de publicidade.
A Lift, uma agência de Israel, revelou que seu novo anúncio foi totalmente criado por inteligência artificial. De acordo com o portal brasileiro Update or Die, essa iniciativa não é estritamente inovadora. Experiências anteriores já haviam sido feitas, muitas vezes com um tom satírico, como o falso anúncio de uma empresa fictícia fundada pela ativista Greta Thunberg para derrubar e vender árvores da Amazônia brasileira.
O anúncio da Lift, desenvolvido por Matan Cohen Grumi para uma marca americana de pasta de amendoim, é completamente sério e sinaliza uma era emergente onde a autoria humana ou computacional em comerciais e filmes se tornará indistinguível. Com uma abordagem simples, o vídeo é embalado por música de ópera e apresenta uma sequência de cachorros ansiando pela pasta de amendoim, finalizando com a mensagem de que o produto é “feito para humanos, mas desejado por todos”.
Thu, Aug 31, 2023
A Importância da Visão Computacional para Monitorar Pessoas que Moram Sozinhas

Viver sozinho pode ser uma experiência libertadora, mas também pode trazer riscos para pessoas que necessitam de acompanhamento devido a condições médicas, idade avançada ou outras circunstâncias. Diante deste cenário, a tecnologia vem sendo cada vez mais considerada como uma aliada potencial. Um projeto piloto em andamento busca oferecer uma solução tecnológica promissora: utilizar visão computacional para monitorar essas pessoas e fornecer assistência quando necessário.
O Projeto Piloto
Este projeto inovador tem o objetivo de utilizar ferramentas de monitoramento de alta tecnologia para pessoas que podem se encontrar sozinhas por diversas razões. Utilizando processadores i5 de sexta geração ou superior, o sistema é capaz de detectar eventos como quedas e acionar ajuda de forma automática.
Entretanto, o objetivo final é ainda mais ambicioso. Os desenvolvedores estão trabalhando para tornar o sistema compatível com dispositivos móveis, Raspberry Pi e outros equipamentos de configuração mais modesta, tornando a tecnologia acessível a um público ainda mais amplo.
Visão Computacional: O Coração do Sistema
A visão computacional é um campo da inteligência artificial que ensina as máquinas a interpretar e entender o mundo visual. Neste projeto, a visão computacional pode fazer muito mais do que apenas detectar quedas. Potencialmente, o sistema poderá identificar comportamentos anormais, monitorar rotinas e até fornecer dados para análises médicas.
Segurança e Privacidade
É claro que o uso de câmeras para monitorar pessoas em suas próprias casas levanta preocupações legítimas sobre privacidade. No entanto, os desenvolvedores do projeto estão focados em garantir que todos os dados sejam seguros e utilizados apenas para o propósito de assistência e cuidado. Além disso, o uso da tecnologia seria totalmente opcional, destinado a quem vê um valor claro na utilização do sistema de monitoramento.
Por que é Importante?
- Autonomia: Este sistema permite que pessoas que normalmente necessitariam de um cuidador possam manter sua independência, sem sacrificar sua segurança.
- Resposta Rápida: No caso de emergências como quedas, o tempo é crucial. O sistema poderia reduzir significativamente o tempo entre o incidente e a chegada da ajuda.
- Acessibilidade: Ao tornar o sistema compatível com hardware mais acessível, a tecnologia poderia ser utilizada por uma parcela maior da população, não apenas por aqueles que podem pagar por sistemas de monitoramento caros.
- Paz de Espírito para Familiares: Saber que seu ente querido está sendo monitorado e que ajuda será acionada imediatamente em caso de emergência é algo inestimável.
Conclusão
Com o envelhecimento da população e o aumento do número de pessoas vivendo sozinhas, soluções como essa são cada vez mais necessárias. O projeto é um excelente exemplo de como a visão computacional pode ser usada para tornar a vida melhor e mais segura para uma grande parcela da sociedade. Estamos aguardando ansiosamente as fases futuras deste projeto inovador.
Thu, Aug 17, 2023
Brain2Music: Reconstruindo Música a partir de atividades cerebrais.

O complexo processo de reconstrução de experiências com base na atividade cerebral humana sempre fascinou cientistas e pesquisadores. Ele desvela uma compreensão singular sobre como nosso cérebro, essa maravilha biológica, decodifica, interpreta e, por fim, representa o universo ao nosso redor. Recentemente, um paper inovador foi publicado, abordando um método pioneiro que se propõe a uma tarefa audaciosa: recriar música a partir dos impulsos e atividades do nosso cérebro.
Um grupo de pesquisadores no Japão, com expertise em neurociência e inteligência artificial, desenvolveu um modelo de IA generativa. Este modelo é capaz de, surpreendentemente, transformar ondas cerebrais, as sutis e complexas sinfonias elétricas de nossos neurônios, em composições musicais. Esta iniciativa revolucionária recebeu o nome de “Brain2Music”. A companhia por trás desta pesquisa, reconhecendo o impacto potencial de suas descobertas, compartilhou entusiasticamente alguns dos resultados preliminares do estudo com a comunidade científica e o público em geral esta semana.
O que torna esta pesquisa ainda mais cativante é a notável precisão do modelo. Ao analisar as faixas de áudio geradas pela inteligência artificial, observa-se uma semelhança com a música original. Para validar e treinar o modelo, clipes musicais de 15 segundos, retirados de um total de 540 músicas e abrangendo dez gêneros diferentes, foram selecionados de forma aleatória. Estes clipes foram então tocados para um grupo de participantes. Enquanto se perdiam na melodia e harmonia desses fragmentos musicais, suas atividades cerebrais eram meticulosamente capturadas e registradas, alimentando o treinamento subsequente do modelo de IA.
A simulação de áudio, ou mais especificamente a reprodução de áudio através de inteligência artificial, está rapidamente emergindo como uma das áreas mais promissoras no vasto universo da tecnologia. Estamos à beira de uma era onde a fusão de neurociência e IA pode redefinir as fronteiras do possível. Com avanços como o “Brain2Music”, podemos nos perguntar: será que, em um futuro não muito distante, seremos capazes de criar sinfonias, melodias e harmonias simplesmente com o poder de nossos pensamentos? Apenas o tempo, a pesquisa e a paixão inabalável pelo desconhecido dirão.

Fri, Jul 28, 2023
OWASP SP : Primeiro Meetup Virtual de 2023

Nesta quarta-feira, dia 02 de Agosto (quarta feira), a OWASP SP proporcionará o primeiro Meetup com debate de extrema relevância, sendo uma vez que o mundo vive uma crise no contexto de segurança da informação e uma grande transformação tecnológica. Todo dia nos deparamos com um novos vazamentos de dados. Sendo assim, a propagação de conhecimento, proporcionará softwares e sistemas seguros minimizando esta crise.
Faremos um bate papo com o tema: “A Importância da OWASP para os Times de Ataque e Defesa”. Um encontro obrigatório para profissionais de segurança, desenvolvedores, e qualquer pessoa interessada em aprender mais sobre a segurança na web.
Estamos animados em já ter confirmado dois convidados especiais:

Paulo Baldin atualmente é CISO e DPO da STARK BANK. Possui mais de 16 anos de experiência e coordenou/participou de mais de 86 projetos (contabilizando 22 mil horas efetivas) em prevenção a fraudes, segurança da informação, auditoria interna/externa, controles internos, combate a crimes cibernéticos, data analytics e desde 2017 atuando diretamente com proteção de dados e privacidade. Graduado e com quatro Pós-Graduações, possui mais de 51 certificações nas suas áreas de atuação, entre elas CISM, CDPSE, DPO, ISO 27001 LI e CPC-PD.

Ana Paula Tessaro: Ana ou Nana, atua como Engenheira de Segurança na JUSBRASIL. Além disso, possuí doutorado em Tecnologia Nuclear, com foco em sistemas, pelo IPEN/USP. Seu campo de atuação abrange segurança defensiva e inteligência cibernética. Possuí várias publicações de artigos em revistas renomadas como Radiation Physics and Chemistry e Brazilian Journal of Radiation Sciences e segue sua jornada com curiosidade, sempre buscando excelência e inovação.

Jonathan Coradi, é Especialista de Segurança da Informação no Banco Safra atua nas frentes do time de pentest e engajamento de RedTeam diretamente alinhado com o negócio. Possui as certificações CRTO e DCPT, autor da CVE-2022-38350 e amante de busca por falhas.
Será um momento de grande aprendizado e troca de experiências. Prepare-se para ampliar seus conhecimentos e habilidades em segurança da web! A troca de ideias e experiências é um dos alicerces da nossa comunidade, por isso, reserve um espaço na sua agenda para esse encontro!

Visão Computacional ajudando a IA Generativa!

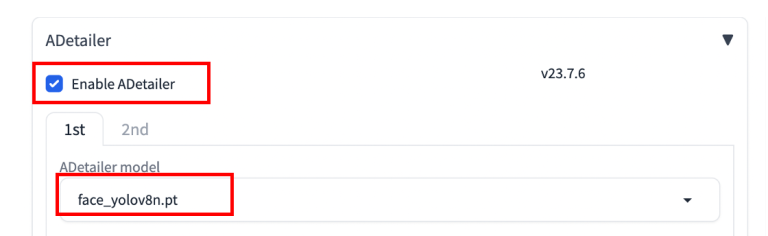
O After Detailer (adetailer) é uma extensão que automatiza o recurso inpainting e muito mais. Isso economiza seu tempo, como também é ótimo para corrigir rapidamente problemas comuns, como rostos distorcidos.
Na imagem gerada, como o rosto é pequeno e a resolução é baixa, não há muitos pixels cobrindo o rosto. O VAE não tem pixels suficientes para gerar uma boa face. Portanto, o rosto é truncado e deformações são geradas.
O After Detailer automatiza esse processo usando um modelo de inferência para o reconhecimento facial, assim detectando o rosto e criando a máscara de pintura automaticamente. A extensão então executa o inpainting apenas com a área mascarada.
https://github.com/Bing-su/adetailer

Fri, Jul 21, 2023
TokenFlow: IA para geração de vídeos.
A inteligência artificial (IA) que cria conteúdo novo, como imagens ou texto, tem se expandido para vídeos. Mas, até agora, os modelos de vídeo ainda não estão no mesmo nível que os de imagem em relação à qualidade visual e à capacidade do usuário de controlar o que é gerado. Neste estudo, foi desenvolvido um sistema que utiliza um tipo especial de IA que converte texto em imagem para editar vídeos baseados em texto.
Basicamente, o sistema pega um vídeo original e um texto guia e cria um vídeo de alta qualidade que segue as instruções do texto. Ao mesmo tempo, ele mantém o arranjo espacial e a dinâmica do vídeo original. A ideia por trás do nosso método é garantir que as características de cada quadro do vídeo sejam consistentes ao longo de toda a edição. Fazemos isso propagando essas características, disponíveis em nosso modelo, de quadro para quadro.
O melhor de tudo é que o sistema não precisa de treinamento ou ajustes específicos. Ele pode ser usado com qualquer método padrão de edição de texto para imagem. Os resultados da edição com nosso sistema em uma série de vídeos reais são impressionantes.
Abaixo o link do paper:

https://arxiv.org/abs/2307.10373