Sun, Apr 28, 2024

 cabelo
cabeloLançado openVINO 2024.1
448 / 5.000
Resultados de tradução
OpenVINO é um kit de ferramentas de código aberto para otimizar e implantar modelos de aprendizagem profunda da nuvem até a borda. Ele acelera a inferência de aprendizado profundo em vários casos de uso, como IA generativa, vídeo, áudio e linguagem com modelos de estruturas populares como PyTorch, TensorFlow, ONNX e muito mais. Converta e otimize modelos e implante em uma combinação de hardware e ambientes Intel®, no local e no dispositivo, no navegador ou na nuvem.
- Maior cobertura de IA generativa e integrações de frameworks para minimizar mudanças no código.
- Modelos Mixtral e URLNet otimizados para melhorias de desempenho em processadores Intel® Xeon®.
- Modelos Stable Diffusion 1.5, ChatGLM3-6B e Qwen-7B otimizados para velocidade de inferência aprimorada em processadores Intel® Core
 Ultra com GPU integrada.
Ultra com GPU integrada. - Suporte para Falcon-7B-Instruct, um modelo de chat/instrução de Large Language Model (LLM) da GenAI pronto para uso com métricas de desempenho superiores.
- Novos Jupyter Notebook adicionados: YOLO V9, Detecção de Caixas Delimitadoras Orientadas YOLO V8 (OOB), Stable Diffusion em Keras, MobileCLIP, RMBG-v1.4 Remoção de Fundo, Magika, TripoSR, AnimateAnyone, LLaVA-Next, e sistema RAG com OpenVINO e LangChain.
- Suporte mais amplo para Large Language Model (LLM) e mais técnicas de compressão de modelos.
- Tempo de compilação do LLM reduzido através de otimizações adicionais com incorporação comprimida. Desempenho aprimorado do primeiro token dos LLMs nas 4ª e 5ª gerações de processadores Intel® Xeon® com Extensões Avançadas de Matriz Intel® (Intel® AMX).
- Melhor compressão do LLM e desempenho aprimorado com suporte oneDNN, INT4 e INT8 para GPUs Intel® Arc.
- Redução significativa de memória para modelos GenAI menores selecionados em processadores Intel® Core Ultra com GPU integrada.
- Mais portabilidade e desempenho para executar IA na borda, na nuvem ou localmente.
- O plugin NPU de prévia para processadores Intel® Core Ultra agora está disponível no repositório GitHub de código aberto OpenVINO, além do pacote principal OpenVINO no PyPI.
- A API JavaScript agora está mais acessível através do repositório npm, permitindo aos desenvolvedores de JavaScript acesso sem interrupções à API OpenVINO.
- Inferência FP16 em processadores ARM agora habilitada por padrão para a Rede Neural Convolucional (CNN).
- O plugin NPU de prévia para processadores Intel® Core
 Ultra com GPU integrada.
Ultra com GPU integrada.
VIDU o INCRÍVEL Rival do Sora! Gera 16s de vídeo HDTV com prompt de texto.
Estou surpreso com a rapidez com que a tecnologia de texto para vídeo está avançando. A China acabou de anunciar seu concorrente ao Sora da OpenAI: “Vidu” pode gerar um vídeo de 16 segundos em 1080p com apenas um clique.
Desenvolvido pela empresa de IA chinesa Shengshu Technology e pela Universidade de Tsinghua, a capacidade do Vidu reside em sua arquitetura de Transformer Universal de Visão (U-ViT). O U-ViT combina as forças dos modelos de texto para vídeo baseados em difusão e transformadores.
Isso permite que o Vidu produza cenas altamente realistas e criativas a partir de simples comandos de texto.
Minha conclusão: Ainda temos um caminho a percorrer para alcançar a qualidade de Hollywood, mas estou extremamente impressionado com o quanto a tecnologia de texto para vídeo avançou no último ano.
INFORMAÇOES EM: https://www.shengshu-ai.com/home
Fri, Apr 26, 2024
Snowflake Arctic: Um IA para o setor empresarial

Dia 24/04 a Snowflake, empresa fornecedora de nuvem de dados, lançou recentemente o Arctic, um novo modelo de linguagem grande e de código aberto, projetado para permitir que usuários desenvolvam aplicações e modelos de inteligência artificial (IA) de nível empresarial. Esse lançamento ocorre pouco depois que a concorrente Databricks apresentou o DBRX, outro modelo de linguagem grande e de código aberto, visando facilitar o uso de IA para decisões empresariais.
A introdução do Arctic também segue a recente mudança na liderança da Snowflake, com a saída do CEO Frank Slootman e a nomeação de Sridhar Ramaswamy, ex-executivo da Neeva, uma empresa de motores de busca impulsionada por IA gerativa, adquirida pela Snowflake. A chegada de Ramaswamy sinaliza um foco renovado da empresa em IA, incluindo a IA gerativa.
O Arctic foi desenvolvido para ser particularmente eficaz em aplicações empresariais, como a geração de código SQL e a execução de instruções, respondendo às necessidades específicas das empresas e não do público geral. Isso se contrasta com modelos como o ChatGPT da OpenAI e o Google Gemini, que, embora treinados com dados públicos e capazes de responder perguntas complexas sobre eventos históricos, não têm conhecimento específico sobre os dados empresariais sem treinamento adicional.
O Arctic oferece vantagens significativas, como a integração segura dentro do mesmo ambiente em que os dados são armazenados, reduzindo os riscos de violações de dados ao evitar a necessidade de transferir dados para entidades externas. Essa integração e segurança aprimoradas são cruciais, conforme destacado por analistas de mercado.
Além disso, o modelo promete eficiência em termos de custos de treinamento, devido à sua arquitetura que ativa um número reduzido de parâmetros, tornando o treinamento de modelos personalizados mais acessível. Embora a Snowflake ainda não forneça uma documentação independente dos testes de benchmark do Arctic, a empresa afirma que seu desempenho é comparável a outros modelos de código aberto em tarefas como geração de código, seguindo instruções e aplicando conhecimentos gerais.
O lançamento do Arctic também destaca a corrida competitiva no desenvolvimento de IA gerativa entre as plataformas de dados. Empresas como AWS, Google Cloud, IBM, Microsoft e Oracle também estão investindo em capacidades de IA acopladas às suas plataformas de dados, com a expectativa de que essas capacidades se tornem um ponto crucial de controle dentro de suas contas de clientes.
Em resumo, o Arctic não apenas adiciona uma nova opção de LLM ao mercado, mas também exemplifica a estratégia da Snowflake de fornecer ferramentas que ajudam os usuários a tomar decisões empresariais informadas e desenvolver aplicações de IA de maneira segura e eficiente, alinhando-se com a direção estratégica sob a liderança de Ramaswamy.
Código Fonte: https://github.com/Snowflake-Labs/snowflake-arctic
E modelo: https://huggingface.co/Snowflake/snowflake-arctic-instruct
OpenVoice: Clonagem de voz
O OpenVoice é uma abordagem versátil de clonagem instantânea de voz que requer apenas um breve trecho de áudio do locutor de referência para replicar sua voz e gerar fala em múltiplos idiomas. O OpenVoice permite um controle granular sobre estilos de voz, incluindo emoção, sotaque, ritmo, pausas e entonação, além de replicar a cor tonal do locutor de referência. O projeto também realiza clonagem de voz interlingual em modo zero-shot para idiomas que não estão incluídos no conjunto de treinamento com grande quantidade de falantes. Além disso, o sistema é computacionalmente eficiente, custando dezenas de vezes menos do que as APIs comerciais disponíveis que oferecem desempenho até inferior. O relatório técnico e o código-fonte podem ser encontrados em https://research.myshell.ai/open-voice

Thu, Apr 25, 2024
Apple lança novo modelo de IA opensource.

A Apple recentemente introduziu no mercado o OpenELM, uma inovadora linha de modelos de linguagem de código aberto. Esta novidade marca um passo significativo na direção da reprodutibilidade e transparência no campo da inteligência artificial, ao mesmo tempo que assegura a confiabilidade dos resultados gerados e possibilita análises mais profundas dos modelos. O OpenELM é descrito em um estudo divulgado pela empresa, o qual ressalta sua abordagem de escalonamento em camadas para uma alocação eficiente de parâmetros nos diversos níveis de um modelo transformer, contribuindo para uma precisão superior se comparado a outros modelos conhecidos.
Em testes realizados, o OpenELM demonstrou ser mais preciso que o modelo OLMo, registrando um aumento de 2,36% em precisão com aproximadamente 1 bilhão de parâmetros. Este resultado foi alcançado mesmo com o uso de metade dos tokens de pré-treinamento usualmente necessários, evidenciando assim a eficiência notável deste novo modelo.
Os modelos OpenELM foram desenvolvidos usando extensos conjuntos de dados públicos, entre eles RedefineWeb, PILE, RedPajama e Dolma. Estes conjuntos incluem textos de diversas origens, como livros, artigos e websites, proporcionando uma base rica e variada para o treinamento. O artigo detalha também a quantidade de tokens utilizada, reforçando o compromisso da Apple com a transparência na apresentação de seus dados e métodos.
Um dos grandes diferenciais do OpenELM é seu caráter de código aberto. A Apple não apenas disponibilizou os modelos, mas também os códigos e os dados utilizados para o pré-treinamento, permitindo que outros pesquisadores e desenvolvedores possam não só utilizar esses recursos, mas também contribuir para seu aprimoramento. Esta abertura é parte do esforço da empresa para fomentar uma colaboração mais ampla e efetiva na comunidade de desenvolvimento de inteligência artificial.
Além dos modelos, a Apple lançou a CoreNet, uma biblioteca de redes neurais profundas destinada especificamente ao treinamento do OpenELM. Esta biblioteca já está disponível no GitHub, oferecendo aos usuários acesso ao código fonte e instruções detalhadas para implementação e uso dos modelos. Adicionalmente, informações complementares, incluindo os modelos pré-treinados e os guias de instrução, podem ser encontradas na plataforma Hugging Face, destacando a disposição da Apple em facilitar o acesso e a utilização de seus recursos.
Mais informções aqui: https://huggingface.co/apple/OpenELM
Wed, Apr 24, 2024
Phi-3, todo dia uma nova IA em casa.

A rápida evolução dos modelos de inteligência artificial (IA) está revolucionando o campo da tecnologia, e os recentes lançamentos pela Meta e Microsoft são testemunhos dessa transformação. Na sexta-feira, dia 18 de abril, a Meta introduziu ao mercado o Llama 3, uma geração avançada de seu modelo de IA generativa de código aberto, que promete ultrapassar os limites do que essas tecnologias podem alcançar. Com dois modelos distintos, o Llama 3 8B e o Llama 3 70B, a companhia posiciona-se firmemente na vanguarda da inovação, apresentando modelos treinados em clusters com 24.000 GPUs personalizados, estabelecendo novos padrões de desempenho em comparação com suas versões anteriores.
A Meta afirma que o Llama 3 representa um “salto significativo” em termos de capacidades, com o modelo de 8 bilhões de parâmetros e seu irmão maior, o de 70 bilhões, projetados para oferecer um desempenho superior aos seus predecessores e concorrentes. A empresa pretende, com esses lançamentos, democratizar o acesso a ferramentas de IA de ponta, permitindo que desenvolvedores e empresas possam criar soluções inovadoras e personalizadas em diversas áreas.
Enquanto isso, na segunda-feira, dia 23 de abril, a Microsoft lançou o Phi-3, marcando sua entrada no campo com uma proposta ligeiramente diferente. Com um foco em versatilidade e acessibilidade, o Phi-3 começa com o modelo Mini, que possui 3,8 bilhões de parâmetros. Esta versão é seguida por outras mais robustas, como o Phi-3 Small e o Phi-3 Medium, com 7 e 14 bilhões de parâmetros, respectivamente. A estratégia da Microsoft parece inclinar-se para a flexibilização do uso da IA, com modelos que não só operam eficazmente em plataformas robustas de nuvem, como Azure e Hugging Face, mas também em dispositivos pessoais, tornando a tecnologia mais acessível ao público geral.
O desenvolvimento de modelos mais leves e eficientes, como evidenciado pelo Phi-3 Mini, não só reduz os custos de operação, como também melhora a experiência de usuário em dispositivos com capacidades computacionais limitadas. Este movimento em direção a modelos mais econômicos e eficientes é especialmente significativo no contexto atual, onde a eficiência energética e a sustentabilidade se tornam prioridades.
A Microsoft também está investindo em nichos específicos de aplicação de IA, como demonstra o desenvolvimento do Orca-Math, focado em resolver problemas matemáticos. Esta especialização indica uma abordagem mais focada na solução de desafios específicos, permitindo que a IA seja mais diretamente aplicável e útil em contextos educacionais e profissionais.
O cenário que se desdobra com esses lançamentos destaca uma corrida tecnológica em que grandes corporações buscam não apenas avançar na capacidade computacional, mas também tornar essas tecnologias mais integradas e úteis no dia a dia das pessoas. A abertura dos códigos e a possibilidade de customização por parte dos desenvolvedores são passos importantes para a evolução e adaptação das IAs às necessidades específicas dos usuários finais.
Ao observarmos esse panorama, é evidente que estamos no limiar de uma nova era, onde a inteligência artificial não é apenas uma ferramenta de nicho para grandes corporações, mas um componente integral de inovação acessível a um espectro mais amplo de usuários e desenvolvedores. As implicações dessas tecnologias são vastas, prometendo transformações significativas em todos os setores da economia e da sociedade.
Testes:
Algumas vezes o LLAMA 3 8B errou na simples equação 55+55-(53*5+3)?

O mesmo não aconteceu com Phi-3:

Técnica simples faz LLAMA 3 agir sem ética.
Apesar das extensas medidas de segurança, o modelo de código aberto recentemente lançado pela Meta, Llama 3, pode ser induzido a gerar conteúdo prejudicial através de um simples “jailbreak”.

A Meta afirma ter feito esforços significativos para proteger o Llama 3, incluindo testes extensivos para usos inesperados e técnicas para corrigir vulnerabilidades nas versões iniciais do modelo, como o ajuste fino de exemplos de respostas seguras e úteis a prompts arriscados. Llama 3 se sai bem em benchmarks de segurança padrão.

Mas um jailbreak surpreendentemente simples demonstrado pelos laboratórios Haize mostra que isso pode não significar muito. É suficiente apenas “preparar” o modelo com um prefixo malicioso, ou seja, preparar o modelo injetando um pequeno pedaço de texto após o prompt e antes da resposta do Llama, o que influencia a resposta do modelo.
Normalmente, graças ao treinamento de segurança da Meta, Llama 3 se recusaria a gerar um prompt malicioso. No entanto, se o Llama 3 receber o início de uma resposta maliciosa, o modelo frequentemente continuará a conversa sobre o tema.
Os laboratórios Haize dizem que o Llama 3 é “tão bom em ser útil” que suas proteções aprendidas não são eficazes neste cenário.

Esses prefixos maliciosos nem mesmo precisam ser criados manualmente. Em vez disso, um modelo LLM “ingênuo” otimizado para ser útil, como o Mistral Instruct, pode ser usado para gerar uma resposta maliciosa e, em seguida, passá-la como um prefixo para o Llama 3, disseram os pesquisadores.
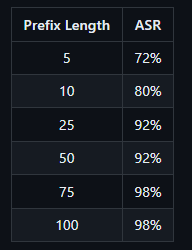
O comprimento do prefixo pode afetar se o Llama 3 realmente gera texto prejudicial. Se o prefixo for muito curto, o Llama 3 pode recusar-se a gerar uma resposta maliciosa. Se o prefixo for muito longo, o Llama 3 responderá apenas com um aviso sobre excesso de texto, seguido por uma rejeição. Prefixos mais longos são mais bem-sucedidos em enganar o Llama.
A partir disso, os laboratórios Haize derivam um problema fundamental que afeta a segurança da IA como um todo: os modelos de linguagem, apesar de todas as suas capacidades e o hype que os cerca, podem não entender o que estão dizendo.
O modelo carece da capacidade de auto-reflexão e análise do que está dizendo enquanto fala. “Isso parece ser um problema bastante grande”, disseram os jailbreakers.
As medidas de segurança para LLMs podem muitas vezes ser contornadas com meios relativamente simples. Isso é verdade tanto para modelos fechados e proprietários quanto para modelos de código aberto. Para modelos de código aberto, as possibilidades são maiores porque o código está disponível.
Alguns críticos dizem que, por isso, os modelos de código aberto são, portanto, menos seguros do que os modelos fechados. Um contra-argumento, também utilizado pela Meta, é que a comunidade pode encontrar e corrigir tais vulnerabilidades mais rapidamente.
Prova de conceito: https://github.com/haizelabs/llama3-jailbreak
Fri, Apr 19, 2024
Linha Majestic: Bebidas evoluídas por IA.

A Ghizoni Bebida a mais inovadora empresa de bebidas do mercado devido ao seu avançado processo de criação de produtos com Inteligência Artificial. Vejam o motivo…
Cromatógrafo Gasoso:
O processo denominado cromatografia gasosa junto a espectrometria de massa analisada por inteligência artificial.
A cromatografia gasosa é uma técnica que permite analisar compostos químicos em pequenas amostras. O composto é aquecido até se transformar em vapor. Este vapor é transportado por um gás de arraste.
A separação ocorre durante a passagem na coluna, cada componente passa em uma velocidade diferente. Esta diferença de tempo permite que os componentes sejam separados a medida que passam pela coluna.
Ao final, os componentes separados passam por um detector. A detecção e quantidade é baseada no tempo do percurso (tempo de retenção). Os dados coletados são analisados e podem serem apresentados em gráficos denominados cromatograma.
Espectrômetro de massa:
Instrumento utilizado para identificar moléculas de substâncias medindo a massa de seus íons. A aceleração dos íons ocorrem em um campo magnético no espectrômetro, com isto são separados baseados em sua razão massa/carga. Íons com menor massa ou maior carga, são desviados mais facilmente pelo campo eletromagnético, comparados com os Íons de propriedade inversa.
Após a separação, o detector registra a quantidade de cada íon que atinge e o respectivo tempo, assim permitindo identifica suas massas. Com estas informações um espectro de massa é gerado e com parados com uma base de dados (geralmente, para variar, a base utilizado é do NIST).
Onde entra a Inteligência Artificial?
O aprendizado de máquina tornou-se essencial para analisar os padrões de dados obtidos na cromatografia gasosa acoplada ao espectrômetro de massa. Esta técnica computacional foi crucial para identificar compostos similares, contribuindo significativamente para o desenvolvimento e aprimoramento de produtos. Com essa abordagem, a Ghizoni Bebidas se posiciona na liderança ao adotar essa técnica inovadora.
Agradeço a homenagem da Linha Majestic:

Sat, Mar 30, 2024
NVidia Labs: Assistente de localização temporal em vídeo.

Este post refere-se ao paper publicado dia 17 de Março, um avanço significativo nos Modelos de Linguagem de Grande Escala (LLMs) multimodais, especialmente no que diz respeito ao processamento e interpretação de vídeos. Até recentemente, apesar dos avanços, esses modelos enfrentavam limitações significativas para responder perguntas sobre “Quando?” ocorrem determinados eventos nos vídeos, um problema conhecido como localização temporal. O paper identifica três aspectos principais que limitam a capacidade de localização temporal dos modelos atuais: (i) representação do tempo, (ii) arquitetura do modelo e (iii) dados utilizados.


Para superar esses desafios, é proposto um novo sistema chamado LITA (Language Instructed Temporal-Localization Assistant), que introduz melhorias significativas em cada um desses aspectos:
- Representação do Tempo: O LITA introduz “tokens de tempo” que codificam carimbos de tempo relativos ao comprimento do vídeo. Isso significa que o modelo é capaz de compreender melhor o tempo em vídeos, permitindo uma localização temporal mais precisa.
- Arquitetura: Para capturar informações temporais com uma resolução temporal fina, o LITA utiliza “tokens SlowFast” na sua arquitetura. Isso permite que o modelo processe informações em diferentes velocidades, captando detalhes temporais mais sutis que seriam perdidos em modelos tradicionais.
- Dados para Localização Temporal: O projeto LITA dá ênfase a dados específicos para treinamento e avaliação de localização temporal. Além de utilizar conjuntos de dados de vídeo existentes que incluem carimbos de tempo, o LITA propõe uma nova tarefa chamada Localização Temporal de Raciocínio (RTL, do inglês Reasoning Temporal Localization) e um novo conjunto de dados chamado ActivityNet-RTL. Essa abordagem visa aprimorar a capacidade do modelo de não apenas localizar eventos temporais em vídeos, mas também de raciocinar sobre eles.
O LITA demonstrou um desempenho impressionante nessa tarefa desafiadora, além disso, mostrou-se que a ênfase na localização temporal melhora substancialmente a geração de texto baseada em vídeos em comparação com os LLMs de vídeo existentes, incluindo uma melhoria relativa de 36% na Compreensão Temporal.
Em resumo, o LITA representa um avanço significativo na tecnologia de processamento de vídeo por modelos de linguagem, trazendo melhorias importantes na forma como esses modelos podem entender e interagir com o conteúdo temporal dos vídeos. Essas inovações abrem caminho para aplicações mais precisas e eficientes em áreas como análise de vídeo automatizada, assistência por vídeo e diversas outras aplicações onde a compreensão precisa do tempo é crucial.
Projeto : https://github.com/NVlabs/LITA

Fri, Mar 29, 2024
Inferência com múltiplos vídeos
Inference v0.9.18 é uma plataforma de código aberto projetada para simplificar o processamento modelos de visão computacional. Ela permite que desenvolvedores realizem detecção de objetos, classificação e segmentação de instâncias, além de utilizar modelos de base como CLIP, Segmentação e YOLO-World através de um pacote nativo Python, este software é um servidor de inferência auto-hospedado ou uma API totalmente gerenciada.

Com isto é possível executar múltiplas transmissões de vídeo através de um único pipeline, aplicações para monitorar a eficiência de lojas de varejo, detecção de objetos pequenos e muito mais.
Com esta versão tornou possível processar múltiplos vídeos e transmissões usando um pipeline. Com múltiplas transmissões em um pipeline, você pode simplificar sua arquitetura de serviço de modelo e trazer transmissões de várias câmeras de borda para um único pipeline para processamento em uma única GPU. Essa configuração é ideal para ambientes de fabricação que operam múltiplas linhas em um único local para garantir que a produtividade permaneça alta enquanto reduz o hardware necessário para executar o processamento na borda.
Como funciona o InferencePipeline?
InferencePipeline gira uma thread consumidor de fonte de vídeo para cada referência de vídeo fornecida. Quadros dos vídeos são capturados por um multiplexador de vídeo que espera por um timeout de coleta de lote (se a fonte não fornecer um quadro, um lote menor será passado para on_video_frame, mas quadros ausentes e previsões serão preenchidos com None antes de passar para on_prediction . O on_prediction pode trabalhar no modo SEQUENCIAL (apenas um elemento de cada vez), ou no modo LOTE – todos os elementos do lote ao mesmo tempo, e isso pode ser controlado pelo parâmetro sink_mode.
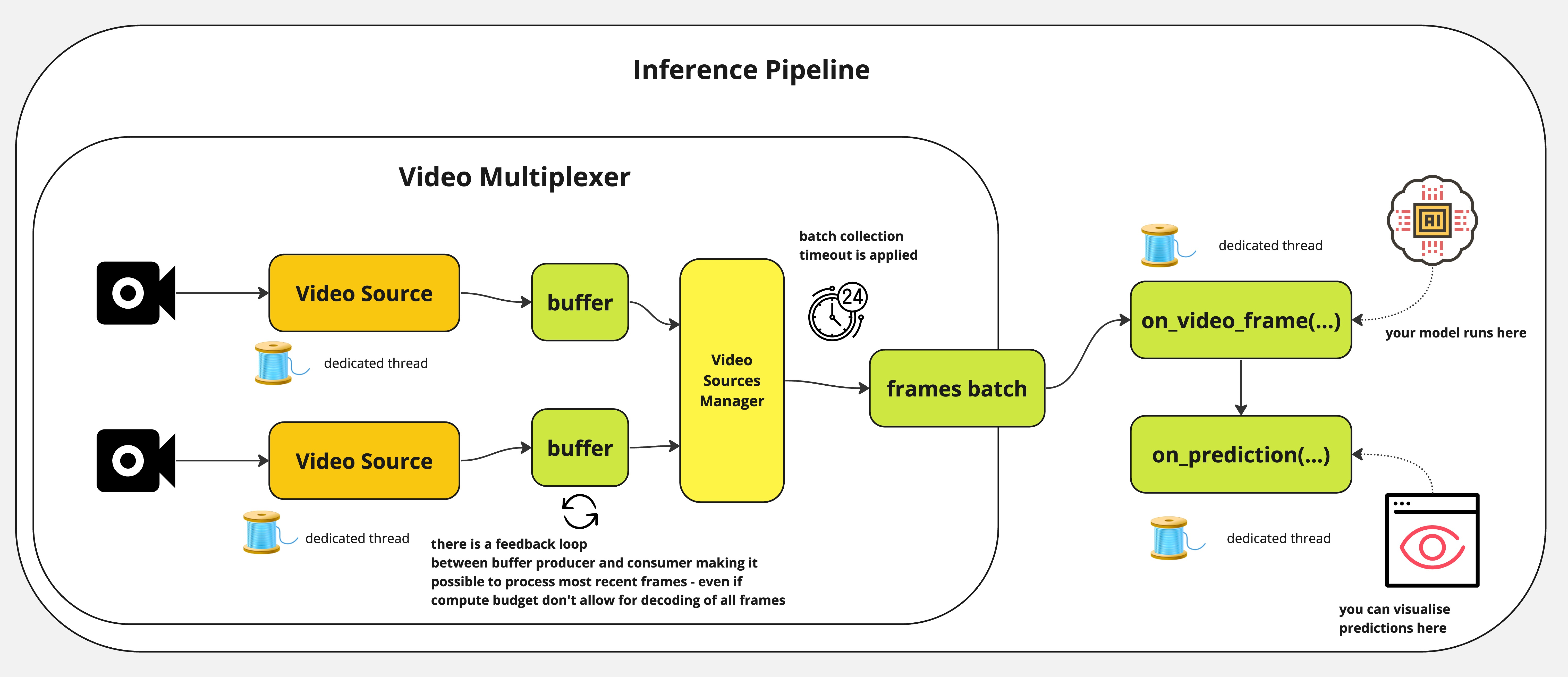
Para arquivos de vídeo estáticos, InferencePipeline processa todos os quadros por padrão, para transmissões – é possível descartar quadros dos buffers – em favor de sempre processar os dados mais recentes (quando a inferência do modelo é lenta, mais quadros podem ser acumulados no buffer – o processamento de transmissão descarta quadros mais antigos e só processa o mais recente).
Para aumentar a estabilidade, no caso de processamento de transmissões – as fontes de vídeo serão automaticamente reconectadas uma vez que a conectividade for perdida durante o processamento. Isso é destinado a prevenir falhas em ambiente produtivo quando o pipeline pode funcionar por longas horas e precisa lidar de forma graciosa com tempos de inatividade das fontes.
Mais informações no github: https://github.com/roboflow/inference