Mon, May 29, 2023

 cabelo
cabeloMinecraft com GPT-4 incrível!
Apresentamos o Voyager, um inovador agente de aprendizado contínuo incorporado (LLM) no universo virtual de Minecraft. Ele é o primeiro de sua categoria, capaz de explorar o mundo continuamente, adquirir uma ampla gama de habilidades e fazer descobertas inéditas, tudo isso sem qualquer intervenção humana. Este post mostrará as características únicas do Voyager, sua estrutura, funcionalidades e sua capacidade de aprendizado, além de destacar seu desempenho superior em relação a outros projeto.
Em maneira empirica, o Voyager demonstra forte capacidade de aprendizado contínuo no contexto e exibe excepcional proficiência em jogar Minecraft. Voyager é capaz de utilizar a biblioteca de habilidades aprendida em um novo mundo do Minecraft para resolver tarefas inéditas do zero, enquanto outras técnicas lutam para generalizar.

O Voyager é formado por três componentes principais, essenciais para a sua operação e performance.
- O Voyager emprega um currículo automático cuja principal função é maximizar a exploração. Este currículo determina as diretrizes básicas para as atividades de aprendizado do agente, buscando garantir que ele explore o ambiente de maneira eficiente e eficaz. Ele é projetado para incentivar o agente a buscar ativamente novas experiências, ampliando assim a variedade de habilidades que pode adquirir.
- Proporciona uma biblioteca de habilidades em constante expansão, que armazena códigos executáveis capazes de representar e recuperar comportamentos complexos. Este recurso é vital para a habilidade do Voyager de adquirir, manter e aplicar uma ampla gama de habilidades. As habilidades que o Voyager aprende não são apenas armazenadas para uso futuro, mas são também organizadas de tal maneira que podem ser recuperadas e aplicadas de forma eficiente conforme a necessidade.
- Finalmente, o Voyager emprega um novo mecanismo de prompt iterativo que incorpora feedback do ambiente, erros de execução e auto-verificação para aprimorar o desempenho do programa. Esse mecanismo é essencial para ajudar o Voyager a aprender com suas ações, avaliar o sucesso de suas tarefas e corrigir erros, contribuindo para o seu crescimento e desenvolvimento contínuos.
Interação com GPT-4
Um aspecto interessante do Voyager é a forma como ele interage com o GPT-4, uma arquitetura de modelo de linguagem poderosa da OpenAI. O Voyager consulta o GPT-4 usando consultas de caixa preta, uma abordagem que evita a necessidade de ajuste fino dos parâmetros do modelo. Isso facilita a interação entre o Voyager e o GPT-4, permitindo que o agente aprenda e opere de forma mais eficiente.
As Habilidades do Voyager
As habilidades que o Voyager adquire e desenvolve são extensas, interpretáveis e composicionais. Elas são extensas no sentido de que o agente é capaz de aplicá-las em uma série de contextos ao longo do tempo. Elas são interpretáveis, o que significa que podem ser entendidas e analisadas tanto pelo Voyager quanto por observadores humanos. E são composicionais, de forma que o agente pode combinar diferentes habilidades para formar comportamentos mais complexos. Esta combinação de características permite ao Voyager aumentar rapidamente suas habilidades e mitigar o problema do esquecimento catastrófico, um desafio comum em sistemas de aprendizado de máquina.
Mais detalhes sobre o projeto aqui: https://github.com/MineDojo/Voyager
Thu, May 25, 2023
Feliz dia da toalha e do Orgulho NERD!

O Dia do Orgulho Nerd, ou Dia do Orgulho Geek é uma iniciativa que advoga o direito de toda pessoa ser um nerd ou um geek. Teve origem na Espanha (“dia del orgullo friki”, em espanhol).[1]
O dia do orgulho nerd é celebrado em 25 de maio desde 2006, comemorando a première do primeiro filme da série Star Wars, em 1977. O dia 25 de maio também é o Dia da Toalha, em homenagem ao escritor Douglas Adams.
Origens
Em 2006, este dia foi celebrado pela primeira vez em toda a Espanha e na internet, graças à publicidade dada por alguns meios, como:
- Salas, Javier. “Comecocos y mangas toman la calle: la revancha de los frikis“, Telecinco, 2006-5-26. Página visitada em 2006-05-26.
- Perez, Javier. “Orgullo friki“, El Mundo, 2006-5-26. Página visitada em 2005-05-26.
- Ramos, David. “25 de mayo: Día del Orgullo Friki“, 20minutos, 2006-5-25. Página visitada em 2005-05-25.
A maior concentração aconteceu em Madri, onde 300 Nerds demonstraram seu orgulho com um pacman humano.
Comemorações de 2007
Em 2007 a celebração contou com mais ajuda de instituições oficiais (como o Circo Price, de Madri) e teve comemoração mais ampla por toda a Espanha. Atividades oficiais foram anunciadas no Pilar de la Horadada, Cádiz, Huesca, Calaf, Huelva, e Valência. Houve uma campanha Doação de Sangue Nerd. Entre outros atos, foi exibido o filme Gritos no corredor.
2008: O dia do Orgulho Nerd chega à América
Em 2008, o Dia do Orgulho Nerd atravessou o Atlântico e foi comemorado oficialmente na América, onde foi divulgado por numerosos bloggers, unidos pelo lançamento do site GeekPrideDay. O matemático e autor John Derbyshire, vencedor do Prêmio Livro de Euler e blogger geek, anunciou[2] que apareceria na parada da Quinta Avenida, vestido de número 57, na ala dos números primos – o que fez alguns bloggers dizerem que iriam procurá-lo.
Direitos e deveres dos nerds
Foi criado um manifesto para celebrar o primeiro Dia do Orgulho Nerd, que incluía a seguinte lista de direitos e deveres dos nerds:[3]Direitos
- O direito de ser nerd.[3]
- O direito de não ter que sair de casa.[3]
- O direito a não ter um par e ser virgem.[3]
- O direito de não gostar de futebol ou de qualquer outro esporte.[3]
- O direito de se associar com outros nerds.[3]
- O direito de ter poucos (ou nenhum) amigo.[3]
- O direito de ter o tanto de amigos nerds que quiser.[3]
- O direito de não ter que estar “na moda”.[3]
- O direito ao sobrepeso (ou subpeso) e de ter problemas de visão.[3]
- O direito de expressar sua nerdice.[3]
- O direito de dominar o mundo.[3]
Deveres
- Ser nerd, não importa o quê.[3]
- Tentar ser mais nerd do que qualquer um.[3]
- Se há uma discussão sobre um assunto nerd, poder dar sua opinião.[3]
- Guardar todo e qualquer objeto nerd que tiver.[3]
- Fazer todo o possível para exibir seus objetos nerds como se fosse um “museu da nerdice”.[3]
- Não ser um nerd generalizado. Você deve se especializar em algo.[3]
- Assistir a qualquer filme nerd na noite de estréia e comprar qualquer livro nerd antes de todo mundo.[3]
- Esperar na fila em toda noite de estreia. Se puder ir fantasiado, ou pelo menos com uma camisa relacionada ao tema, melhor ainda.[3]
- Não perder seu tempo em nada que não seja relacionado à nerdice.[3]
- Tentar dominar o mundo.[3]

Wed, May 24, 2023
IA treinada na dark web chamada DarkBERT

https://arxiv.org/abs/2305.08596
Desenvolvido por uma equipe sul-coreana, este modelo de inteligência artificial é treinado com dados extraídos da Dark Web. É incontestável que entramos a era das inteligências artificiais, especialmente após o surgimento de modelos equipados com LLM, ou “Large Language Model”, como o ChatGPT, desenvolvido pela OpenAI.
Isso é possível porque essas IA’s têm acesso a vastos repositórios de dados interconectados por redes neurais artificiais e são treinadas para se comunicarem da forma mais eficiente possível. Contudo, o progresso das inteligências artificiais tem gerado apreensões por parte de empresários e autoridades globais, que temem que as habilidades desses robôs possam ser exploradas para fins maliciosos.
Nesse contexto, foi recentemente lançado o DarkBERT, um chatbot similar ao ChatGPT, mas treinado com dados obtidos das partes mais profundas da internet, a dark web. Segundo seus criadores sul-coreanos, o DarkBERT é fundamentado em uma estrutura de dados conhecida como RoBERTa, que realiza um trabalho bastante similar às suas contrapartes mais famosas.
Para conceber o novo chatbot, os pesquisadores acessaram as redes de dados da dark web para coletar informações que poderiam ser ensinadas ao DarkBERT. Assim, agora o DarkBERT possui seu próprio acervo de dados sobre informações circuladas na Dark Web.
É importante ressaltar que a dark web é um ambiente frequentado por criminosos para, predominantemente, comercializarem itens ilegais, como relíquias furtadas, mercadorias de contrabando e até órgãos humanos. Além disso, na dark web também é possível monitorar a atividade de grupos extremistas e a propagação de discursos de ódio e ideias prejudiciais à manutenção da sociedade como a conhecemos.
Como foi desenvolvido? Os pesquisadores treinaram o modelo RoBERTa ao vasculhar a Dark Web através da rede conhecida como Tor. A partir daí, aplicaram técnicas de filtragem de dados, como pré-processamento de dados, e construíram um banco de dados com informações da Dark Web.
Em outras palavras, o DarkBERT nasceu da utilização do Large Language Model (LLM) RoBERTa, alimentado com as informações obtidas por esse banco de dados. Desta forma, o software é capaz de analisar dados de sites e conteúdos da internet profunda, mesmo escritos em linguagens específicas, para depois utilizá-los de maneira útil.
Como pode ser utilizado? O modelo criado pode ser empregado por forças policiais de cibersegurança, pois pode penetrar nas camadas profundas da web, onde transações ilegais ocorrem em grande escala. O DarkBERT pode continuar se aperfeiçoando e sendo aplicado em áreas ainda inexploradas.
Conforme seus desenvolvedores, o DarkBERT ainda pode ser aprimorado e atualizado, assim como outros chatbots altamente inteligentes. Para isso, a equipe continuará atualizando o seu banco de dados.
Thu, May 11, 2023
MOJO: A linguagem para IA que promete ser 35.000x mais veloz que Python

Mojo é uma linguagem de programação PROMETIDA SER projetada especificamente para aplicações de Inteligência Artificial (IA). Ela é uma inovação recente, mas não se preocupe, você não precisa começar do zero! Mojo é, de certa forma, um subconjunto do Python, aproveitando-se da facilidade de uso desta linguagem. Portanto, para aqueles familiarizados com Python, a transição para Mojo é bastante simples. Além disso, Mojo possui desempenho comparável ao do C.
Isso significa que Mojo diz combinar o melhor de dois mundos: a simplicidade do Python com a rapidez do C. Então, Python tornou-se obsoleto para Data Science e IA? Não exatamente. Embora Python possua um vasto arsenal de pacotes para lidar com dados, ele recorre a rotinas de baixo nível escritas em C, C++ ou outras linguagens de alta performance quando a demanda por desempenho é alta. É assim que bibliotecas como TensorFlow e numpy operam em Python.
A linguagem Mojo foi desenvolvida pela empresa Modular, sendo Chris Lattner, co-fundador da empresa e criador do Swift e da infraestrutura de compilação LLVM escrita em C++, um dos responsáveis pela sua criação.
Aqui estão algumas características distintivas do Mojo:
- Mojo é uma subset de Python, com o objetivo de ser totalmente compatível com esta linguagem.
- Ele apresenta uma forte verificação de tipos para melhorar o desempenho e a detecção de erros.
- Inclui um verificador de propriedade e empréstimo de memória, por meio de uma convenção de argumento de propriedade (“owner”), utilizada por funções que buscam adquirir propriedade exclusiva sobre um valor, aumentando a segurança da memória.
- Possui ajuste automático integrado, que auxilia na determinação dos melhores valores para os parâmetros de acordo com o hardware utilizado.
- Utiliza todo o potencial da MLIR (“Multi-Level Intermediate Representation”), facilitando o uso de vetores, threads e unidades de hardware específicas para IA.
- Suporta paralelismo, otimizando o uso de hardware avançado, como as modernas GPUs.
Para ilustrar o desempenho de Mojo comparado ao Python, observe a tabela abaixo (não consegui determinar qual aplicação gerou estes dados):

Para concluir, o Mojo foi concebido com o objetivo de prover um modelo de programação distinto para aceleradores de aprendizado de máquina.
A Modular decidiu que o Mojo deveria suportar programação de uso geral, visto que as CPUs atuais possuem tensores e outros aceleradores de IA incorporados. Além disso, devido à ampla utilização do Python em aprendizado de máquina e em diversas outras áreas, a Modular decidiu integrar-se ao ecossistema Python.
A escolha do Python simplificou ainda mais o processo de design da linguagem. Com grande parte da sintaxe já estabelecida, a empresa pôde focar na construção do compilador e na implementação de capacidades de programação especializadas.
Como iniciar?
Você pode dar os primeiros passos AQUI com a linguagem Mojo agora mesmo, utilizando o Playground disponibilizado. Este ambiente, baseado no JupyterHub, oferece tutoriais e a chance de elaborar seu próprio código Mojo, mesmo que a linguagem ainda esteja em desenvolvimento. Para acessar o Playground, basta se cadastrar no site da plataforma.
Referencias:
[1] The PyCoach, Mojo: The Programming Language for AI That Is Up To 35000x Faster Than Python. Disponível em: https://artificialcorner.com/mojo-the-programming-language-for-ai-that-is-up-to-35000x-faster-than-python-e68d1fba37db.
[2] Modular, Modular: Mojo. Disponível em: https://docs.modular.com/mojo/.
Wed, May 10, 2023
Disponível o material da palestra: IA Generativa – Um futuro inevitável!
Deixo neste post o material da minha palestra IA Generativa – Um futuro inevitável!

Inteligência Artificial da China interpreta momentos em fotos.
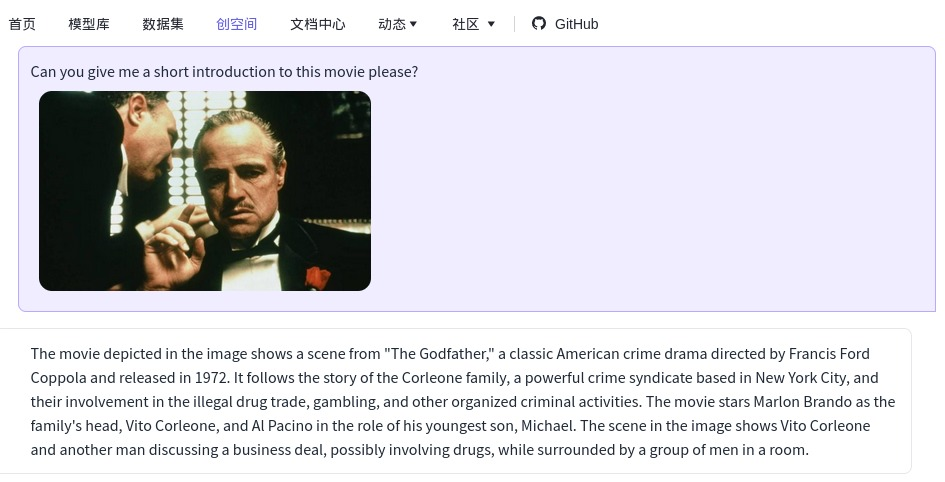
Fui surpreendido pelo desempenho de uma inteligência artificial de um projeto chinês. Ao enviar uma foto minha com minha mãe, uma cena de filme e outra foto minha na praia, os resultados foram impressionantes. Confira as respostas obtidas ao questionar sobre o aspecto emocionante da imagem, o objeto que eu segurava e a cor da minha camisa:

“A parte mais emocionante desta foto é o abraço amoroso entre você e sua mãe. Vocês dois estão se abraçando com força, mostrando a forte conexão e vínculo que compartilham. Além disso, o fato de você estar segurando um copo plástico com cerveja na mão torna esse momento mais pessoal, pois mostra que vocês estão desfrutando de uma atividade compartilhada ou de um momento de descontração juntos. Esta foto captura um momento caloroso e terno entre você e sua mãe, e provavelmente é uma lembrança que você aprecia.”
projeto: mPLUG-Owl
O paper “mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality” [1] disponibilizado dia 27 de Abril de 2023 às 13:27:01 UTC menciona que Large languade models (LLMs) demonstraram habilidades impressionantes em uma variedade de tarefas, enquanto pesquisas recentes também exploraram o uso de LLMs para geração multimodal.
Neste estudo é apresentado o mPLUG-Owl, um novo paradigma de treinamento que insere aos LLMs habilidades multimodais com aprendizagem modularizada do LLM base, um módulo de conhecimento visual e um módulo abstrator visual. O paradigma de treinamento do mPLUG-Owl envolve um método de duas etapas para alinhar imagem e texto, aprendendo os dados visuais com a assistência do LLM enquanto mantém e até melhora as habilidades de geração do LLM.
Na primeira fase, o módulo de conhecimento visual e o módulo abstrator são treinados com um módulo LLM para alinhar a imagem e o texto. Já na segunda etapa, conjuntos de dados supervisionados apenas de linguagem e multimodais são usados para ajustar conjuntamente um módulo de low-rank adaption (LoRA) no LLM e no módulo abstrator, congelando o módulo de conhecimento visual.
Os resultados experimentais mostram que o modelo supera os modelos multimodais existentes, demonstrando a impressionante habilidade de instrução e compreensão visual do mPLUG-Owl, habilidade de conversação em várias etapas e habilidade de raciocínio de conhecimento.
Mas o que mais me surpreendeu foi algumas habilidades inesperadas e interessantes, como correlação entre várias imagens e compreensão de texto em cena, o que torna possível aproveitá-lo para cenários reais mais difíceis, como compreensão de documentos apenas com visão. Nosso código, modelo pré-treinado, modelos ajustados por instrução e conjunto de avaliação estão disponíveis neste URL https://github.com/X-PLUG/mPLUG-Owl
Abaixo, mais alguns testes:


https://arxiv.org/pdf/2304.14178.pdf
Referencias científicas:
[1] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, Chenliang Li, Yuanhong Xu, Hehong Chen, Junfeng Tian, Qian Qi, Ji Zhang, Fei Huang (2023). “mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality”. arXiv:2304.14178 [cs]. arXiv.org, https://arxiv.org/abs/2304.14178
Fri, May 05, 2023
Próxima Fronteira da IA Generativa
A NVIDIA revelou uma gama de pesquisas de ponta em inteligência artificial (IA) que possibilitará a desenvolvedores e artistas concretizarem suas ideias, sejam elas fixas ou em movimento, em 2D ou 3D, hiper-realistas ou imaginativas.
Em torno de 20 trabalhos de pesquisa da NVIDIA, impulsionando a IA generativa e gráficos neurais, incluindo parcerias com mais de 12 universidades dos Estados Unidos, Europa e Israel, serão apresentados na SIGGRAPH 2023, a conferência líder em gráficos computacionais, ocorrendo de 6 a 10 de agosto em Los Angeles.
Os estudos englobam modelos de IA generativa que convertem texto em imagens personalizadas; ferramentas de renderização inversa que modificam imagens fixas em objetos 3D; modelos de física neural que empregam IA para simular elementos 3D complexos com realismo surpreendente; e modelos de renderização neural que proporcionam novas habilidades para gerar detalhes visuais em tempo real, impulsionados por IA.
As inovações desenvolvidas pelos pesquisadores da NVIDIA são frequentemente compartilhadas com os desenvolvedores no GitHub e integradas a produtos como a plataforma NVIDIA Omniverse, voltada para a criação e gerenciamento de aplicativos de metaverso, e o NVIDIA Picasso, uma fundição recentemente revelada para modelos de inteligência artificial generativos e personalizados em design gráfico. A extensa pesquisa em gráficos realizada pela NVIDIA ao longo dos anos possibilitou a incorporação de renderizações cinematográficas em jogos, como é o caso do recentemente lançado Cyberpunk 2077 Ray Tracing: Overdrive Mode, o título path-traced AAA.
Os progressos na pesquisa exibidos este ano na SIGGRAPH permitirão que desenvolvedores e empresas gerem rapidamente dados sintéticos para popular mundos virtuais destinados ao treinamento de robôs e veículos autônomos. Além disso, possibilitarão que profissionais de arte, arquitetura, design gráfico, desenvolvimento de jogos e cinema produzam mais eficientemente imagens de alta qualidade para a elaboração de storyboards, pré-visualizações e até mesmo produções.
Wed, Apr 26, 2023
Um gigante livro de receitas sobre Aprendizagem Auto-supervisionada.
Tudo o que você sempre quis saber sobre Aprendizagem Auto-Supervisionada, mas tinha medo de perguntar. Agora disponível neste super PDF desenvolvido uma grande multidão da Meta AI (FAIR) com vários colaboradores acadêmicos liderados por Randall Balestriero e Mark Ibrahim.

Download aqui: https://arxiv.org/abs/2304.12210
TactGlove – Tocando objetos no Metaverso.

A TactGlove é uma luva táctil de realidade virtual que permite que os jogadores sintam e interajam com seu ambiente virtual com mais realismo. Esta luva vem equipada com sensores táteis e motores de vibração que podem replicar a sensação de tocar objetos virtuais ou outros jogadores. O equipamento ficou disponível para uso doméstico no segundo semestre de 2022.
Este equipamento é um dispositivo háptico. Ou seja, uma tecnologia que permite aplicar as sensações cutâneas e cinestésicas na interação com o mundo virtual. Ou seja, agora podemos tocar objetos virtuais no Metaverso e uma variedade de outras funcionalidades que possibilitam uma incrível experiência de realidade virtual. Então podemos dizer que a tecnologia permite ao usuário ter uma experiência muito mais realista em ambientes virtuais ou de realidade aumentada.
Os sensores presentes na luva também são usados para detectar e interpretar os sinais elétricos transmitidos pelos músculos, proporcionando assim um melhor controle dos movimentos das mãos.
A tecnologia conta com 10 pequenos vibradores sendo colocados na ponta dos dedos da TactGlove. Pensando na higiene, há duas luvas (uma interna e outra externa) para que você possa compartilhar o produto com outras pessoas. A interna pode ser lavada em máquinas convencionais, permitindo que o suor absorvido durante o uso seja eliminado e a luva higienizada. Não precisa se preocupar caso sua mão seja grande ou pequena demais: a bHaptics desenvolveu a luva háptica nos tamanhos pequeno, médio e grande.
Cada dedo da luva TactGlove tem um atuador ressonante linear que o gadget combina com a tecnologia de rastreamento manual para proporcionar a sensação de toque ao tocar em VR.

Junto com um algoritmo neuromórfico, a empresa bHaptics utiliza pequenos motores que passam a mesma sensação. Assim proporcionando a sensação capaz de “pegar” os objetos e senti-los em sua mão. As luvas são sem fio e proporcionam até 4 horas de tempo de jogo entre as cargas.
As luvas serão compatíveis com sistemas de rastreamento de mão baseados em câmera, que estão atualmente disponíveis em dispositivos como o Oculus Quest 2/Pro e Pico Neo 3 com Ultraleap e custarão US$299 por par.
Onde comprar: https://www.bhaptics.com/tactsuit/tactglove

Abaixo um vídeo demonstrativo da tecnologia com o aplicativo demo:
Mon, Apr 17, 2023
ViT: Talvez o próximo destaque sobre IA na mídia.

Quero começar este post, mencionando que não usei o Chat-GPT e sim minha esposa Gisele que corrige 90% dos meus textos. Logo os 10% publicados na internet com erros, foram os que ela não corrigiu! Mas voltando ao ponto focal, eu acreditava que a Visão Neuromórfica seria o futuro da Visão Computacional. E aparentemente eu estava enganado, pois a arquitetura Transformers está derivando em tecnologia que será capaz de ler nossos lábios durante conversar nas ruas das imagens em câmeras públicas de monitoramento.
Esta minha afirmação, deve-se que em 2017, foi publicado um paper chamado “Attention Is All You Need” [1], que apresentava um novo modelo de rede neural focado no processamento de Linguagem Natural. Hoje conhecido como Transformers que deu origem ao ChatGPT da openAI(seq2seq).

Hoje estamos com uma avalanche informacional no setor de redes neurais. O assunto da moda chamada Transformers é a primeira revolução de mais dois assuntos que merecem atenção e ficarão para os próximos posts. Este novo modelo foi focado em NLP (Processamento de Linguagem Natural). Em 2020 terminei os testes com o GPT-3 e postei aqui no assunto nerd.O que mais chamou a minha atenção nesta tecnologia foi o Mecanismo de Atenção. Esta técnica mudou tudo, até minha maneira de ver os meus trabalhos técnicos. O conceito foca na informação de dados ruidosos, assim resolvendo o gargalo representativo baseado no score de atenção.
Não vou perder tempo com o Chat GPT, pois a mídia já fez isto muito bem. Então, podemos dizer que o esforço cognitivo do GPT-3 ou 4 é a maneira diferenciada de processar / interpretar o contexto.
Em 2021 outro paper [2] surgiu com uma nova proposta de rede neural. Focada em melhorar como as máquinas enxergam. A Vision Transformer ou ViT, é uma arquitetura muito semelhante ao modelo Transformers proposto em 2017. Com pequenas alterações para processar imagens em vez de textos.
Até aqui, as redes neurais convolucionais foi o estado da arte em visão computacional. O seu processamento é baseado nos kernels convolucionais para reconhecer as características dos objetos. É uma saga treinar um CNN. O ViT tem a proposta de não imitar o conceito do Transformes, pois o conceito de Mecanismo de Atenção para cada pixel seria inviável em termos de custo computacional. Ai veio a genialidade do paper, o modelo divide a imagem em unidades quadradas (denominada tokens). O padrão é 16×16. Assim aplicando o Self-Attention em cada parte da imagem. Com isto a velocidade é impressionante, pois o ViT varre a imagem com 90% de precisão.
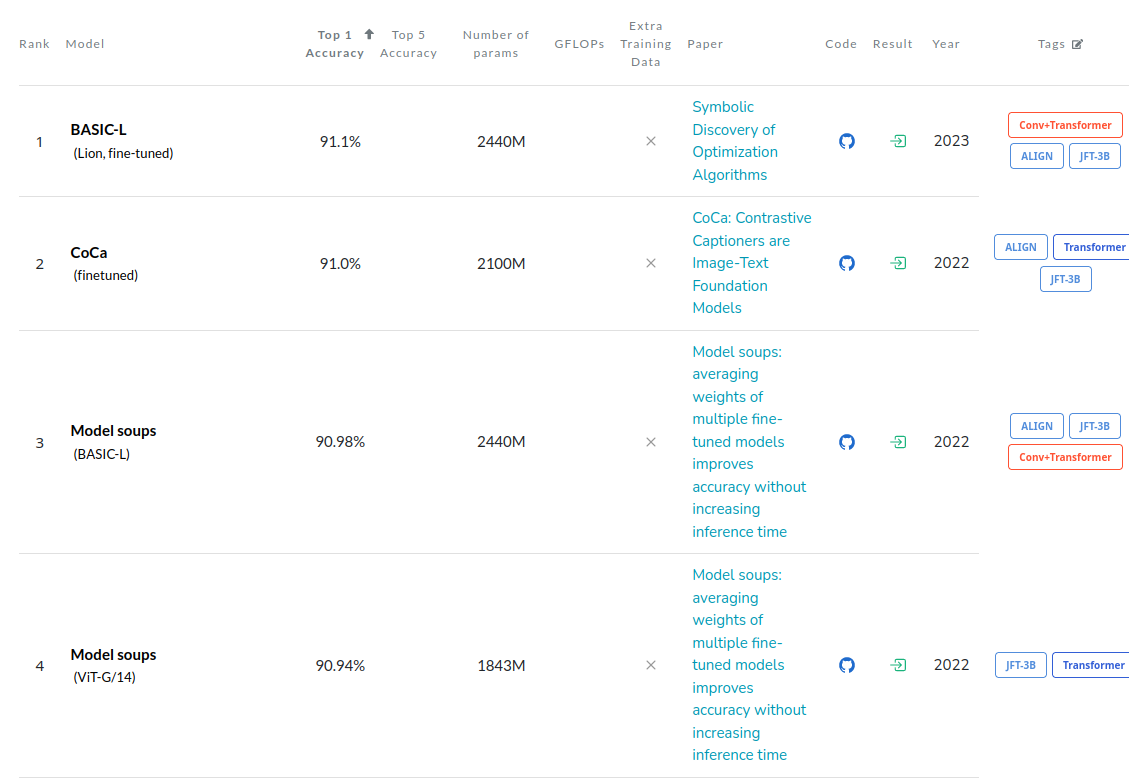
Nos testes de processamento de imagem em 14/03, uma versão do ViT assumiu o primeiro lugar, o segundo lugar foi para um modelo que combinou CNN com Transformers. Para entenderem o contexto, as melhores CNNs de longa data, não chegaram perto desta nova abordagem. Agora em 16/04/2023 modelos Transformes+CNN atingiram o primeiro lugar.
Estou empolgado, pois aplicar o mecanismo de atenção na entrada (encoders) pode ser um grande passo na arquitetura de redes neurais, assim resultando uma nova abordagem no setor de visão computacional.
Os Transformers estão sendo explorados em arquiteturas de aprendizado de máquina multimodais, que são habilitadas para processar diversos tipos de dados, como áudio, vídeo e imagens. Um paper [3] faz uma abordagem onde redes multimodais podem ser usadas para criar sistemas que compreendem a fala e leem os lábios de uma pessoa simultaneamente.
Problema: “não tem almoço grátis”, a arquitetura Transformers tem um alto custo de processamento na fase de pré-treinamento para superar a precisão dos modelos concorrentes. Treinar imagem é uma saga enorme. Mas para terminar, existem estudos sobre diminuir este custo computacional, como Transformes com filtro que podem ser implementados em CNNs. Então teremos muitas novidades disruptivas no setor de IA.
Referencias científicas:
[1] Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N; Kaiser, Lukasz; Polosukhin, Illia. (2017). “Attention Is All You Need”. arXiv:1706.03762 [cs]. arXiv.org, http://arxiv.org/abs/1706.03762.
[2] Dosovitskiy, Alexey, et al. (2021). “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”. arXiv:2010.11929 [cs]. arXiv.org, http://arxiv.org/abs/2010.11929.
[3] Akbari, Hassan; Yuan, Liangzhe; Qian, Rui; Chuang, Wei-Hong; Chang, Shih-Fu; Cui, Yin; Gong, Boqing. (2021). “VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text”. arXiv:2104.11178 [cs, eess]. arXiv.org, http://arxiv.org/abs/2104.11178.