
 Member
Member Ana06
Ana06GSoC Half Way Throug
As you may already know, openSUSE participates again in GSoC, an international program that awards stipends to university students who contribute to real-world open source projects during three months in summer. Our students started working already two months ago. Ankush, Liana and Matheus have passed the two evaluations successfully and they are busy hacking to finish their projects. Go on reading to find out what they have to say about their experience, their projects and the missing work for the few more weeks. :grinning:
Ankush Malik
Ankush is improving people collaboration in the Hackweek tool and he has already made many great contributions like the emoticons, similar project section and notifications features. In fact, the Hackweek 17 was just last week, so in the last days a lot of people have already been using these great new features. There were a lot of good comments about his work! :cupid: and we also received a lot of feedback, as you can for example see in the issues list.
But even more important than all the functionality, is all Ankush is learning while coding and working with his mentors and the openSUSE community, such as working with AJAX in Ruby on Rails, good coding practices and better coding style.
The last part of his project will include some more new features. If you want to find out more about his project and the challenges that Ankush expects to have, read his interesting blog post: https://medium.com/@ankushmalik631/how-my-gsoc-project-is-going-4942614132a2

Xu Liana
Liana is working on integrating Cloud Pinyin (the most popular input method in China) on ibus-libpinyin. For her, GSoC is being an enjoyable learning process full of challenges. With the help of her mentors she has learnt about autotools and she builds now her code without graphical build tools :muscle: For the few more weeks, she plans to learn about algorithmics that are useful for the project and, after finish the coding part, she would like to go deeper in the fundamentals of compiling. Read it from her owns word in her blog post: https://liana.hillwoodhome.net/2018/07/14/the-first-half-of-the-project-during-gsoc-libpinyin
Matheus de Sousa Bernardo
Matheus is working in Trollolo, a cli-tool which helps teams using Trello to organize their work. He has been mainly focused on the restructuring of commands and the incomplete backup feature. The discussion with his mentors made him take different implementation paths than the ones he had in mind at the beginning, learning the importance of keeping things simple. It has been complicated for Matheus to find time for both the GSoC project and his university duties. But he still has some more weeks to implement the more challenging feature, the automation of Trollolo! :boom:
Check his blog post with more details about the project: https://matheussbernardo.me/gsoc/2018/07/08/midterm
I hope you enjoyed reading about the work and experiences of the openSUSE students and mentors. Keep tuned as there are still some more hacking weeks and the students will write a last blog post summarizing their GSoC experience. :wink:

Deploying Samba smb.conf via Group Policy
I’ve been working on Group Policy deployment in Samba. Samba master (not released) currently now installs a samba-gpupdate script, which works similar to gpupdate on Windows (currently in master it defaults to –force, but that changes soon).
Group Policy can also apply automatically by setting the smb.conf option ‘apply group policies’ to yes.
Recently, I’ve written a client side extension (CSE) which applies samba smb.conf settings to client machines. I’ve also written a script which generates admx files for deploying those settings via the Group Policy Management Console.
You can view the source, and follow my progress here: https://gitlab.com/samba-team/samba/merge_requests/32


Hackweek Project Docker Registry Mirror
As part of SUSE Hackweek 17 I decided to work on a fully fledged docker registry mirror.
You might wonder why this is needed, after all it’s already possible to run a docker distribution (aka registry) instance as a pull-through cache. While that’s true, this solution doesn’t address the needs of more “sophisticated” users.
The problem
Based on the feedback we got from a lot of SUSE customers it’s clear that a simple registry configured to act as a pull-through cache isn’t enough.
Let’s go step by step to understand the requirements we have.
On-premise cache of container images
First of all it should be possible to have a mirror of certain container images locally. This is useful to save time and bandwidth. For example there’s no reason to download the same image over an over on each node of a Kubernetes cluster.
A docker registry configured to act as a pull-through cache can help with that. There’s still need to warm the cache, this can be left to the organic pull of images done by the cluster or could be done artificially by some script run by an operator.
Unfortunately a pull-through cache is not going to solve this problem for nodes running inside of an air-gapped environment. Nodes operated in such an environment are located into a completely segregated network, that would make it impossible for the pull-through registry to reach the external registry.
Retain control over the contents of the mirror
Cluster operators want to have control of the images available inside of the local mirror.
For example, assuming we are mirroring the Docker Hub, an operator might be
fine with having the library/mariadb image but not the library/redis one.
When operating a registry configured as pull-through cache, all the images of
the upstream registry are at the reach of all the users of the cluster. It’s
just a matter of doing a simple docker pull to get the image cached into
the local pull-through cache and sneak it into all the nodes.
Moreover some operators want to grant the privilege of adding images to the local mirror only to trusted users.
There’s life outside of the Docker Hub
The Docker Hub is certainly the most known container registry. However there are
also other registries being used: SUSE operates its own registry, there’s Quay.io,
Google Container Registry (aka gcr) and there are even user operated ones.
A docker registry configured to act as a pull-through cache can mirror only one registry. Which means that, if you are interested in mirroring both the Docker Hub and Quay.io, you will have to run two instances of docker registry pull-through caches: one for the Docker Hub, the other for Quay.io.
This is just overhead for the final operator.
A better solution
During the last week I worked to build a PoC to demonstrate we can create a docker registry mirror solution that can satisfy all the requirements above.
I wanted to have a single box running the entire solution and I wanted all the different pieces of it to be containerized. I hence resorted to use a node powered by openSUSE Kubic.
I didn’t need all the different pieces of Kubernetes, I just needed kubelet so
that I could run it in disconnected mode. Disconnected means the kubelet
process is not connected to a Kubernetes API server, instead it reads PODs
manifest files straight from a local directory.
The all-in-one box
I created an openSUSE Kubic node and then I started by deploying a standard docker registry. This instance is not configured to act as a pull-through cache. However it is configured to use an external authorization service. This is needed to allow the operator to have full control of who can push/pull/delete images.
I configured the registry POD to store the registry data to a directory on the machine by using a Kubernetes hostPath volume.
On the very same node I deployed the authorization service needed by the docker registry. I choose Portus, an open source solution created at SUSE a long time ago.
Portus needs a database, hence I deployed a containerized instance of MariaDB
on the same node. Again I used a Kubernetes hostPath to ensure the persistence
of the database contents. I placed both Portus and its MariaDB instance into the
same POD. I configured MariaDB to listen only to localhost, making it reachable
only by the Portus instance (that’s because they are in the same
Kubernetes POD).
I configured both the registry and Portus to bind to a local unix socket, then I deployed a container running HAProxy to expose both of them to the world.
The HAProxy is the only container that uses the host network. Meaning it’s actually listening on port 80 and port 443 of the openSUSE Kubic node.
I went ahead and created two new DNS entries inside of my local network:
-
registry.kube.lan: this is the FQDN of the registry -
portus.kube.lan: this is the FQDN of portus
I configured both the names to be resolved with the IP address of my container host.
I then used cfssl to generate a CA and
then a pair of certificates and keys for registry.kube.lan and portus.kube.lan.
Finally I configured HAProxy to:
- Listen on port 80 and 443.
- Automatically redirect traffic from port 80 to port 443.
- Perform TLS termination for registry and Portus.
- Load balance requests against the right unix socket using the Server Name Indication (SNI).
By having dedicated FQDN for the registry and Portus and by using HAProxy’s SNI
based load balancing, we can leave the registry listening on a standard port
(443) instead of using a different one (eg: 5000). In my opinion that’s a big
win, based on my personal experience having the registry listen on a non standard
port makes things more confusing both for the operators and the end users.
Once I was over with these steps I was able to log into https://portus.kube.lan
and perform the usual setup wizard of Portus.
Mirroring images
We now have to mirror images from multiple registries into the local one, but how can we do that?
Sometimes ago I stumbled over this tool, which can be used to copy images from multiple registries into a single one. While doing that it can change the namespace of the image to put it all the images coming from a certain registry into a specific namespace.
I wanted to use this tool, but I realized it relies on the docker open-source engine to perform the pull and push operations. That’s a blocking issue for me because I wanted to run the mirroring tool into a container without doing nasty tricks like mounting the docker socket of the host into a container.
Basically I wanted the mirroring tool to not rely on the docker open source engine.
At SUSE we are already using and contributing to skopeo, an amazing tool that allows interactions with container images and container registries without requiring any docker daemon.
The solution was clear: extend skopeo to provide mirroring capabilities.
I drafted a design proposal with my colleague Marco Vedovati, started coding and then ended up with this pull request.
While working on that I also uncovered a small glitch
inside of the containers/image library used by skopeo.
Using a patched skopeo binary (which include both the patches above) I then mirrored a bunch of images into my local registry:
$ skopeo sync --source docker://docker.io/busybox:musl --dest-creds="flavio:password" docker://registry.kube.lan
$ skopeo sync --source docker://quay.io/coreos/etcd --dest-creds="flavio:password" docker://registry.kube.lan
The first command mirrored only the busybox:musl container image from the
Docker Hub to my local registry, while the second command mirrored all the
coreos/etcd images from the quay.io registry to my local registry.
Since the local registry is protected by Portus I had to specify my credentials while performing the sync operation.
Running multiple sync commands is not really practical, that’s why we added
a source-file flag. That allows an operator to write a configuration file
indicating the images to mirror. More on that on a dedicated blog post.
At this point my local registry had the following images:
docker.io/busybox:muslquay.io/coreos/etcd:v3.1quay.io/coreos/etcd:latestquay.io/coreos/etcd:v3.3quay.io/coreos/etcd:v3.3- … more
quay.io/coreos/etcdimages …
As you can see the namespace of the mirrored images is changed to include the FQDN of the registry from which they have been downloaded. This avoids clashes between the images and makes easier to track their origin.
Mirroring on air-gapped environments
As I mentioned above I wanted to provide a solution that could be used also to run mirrors inside of air-gapped environments.
The only tricky part for such a scenario is how to get the images from the upstream registries into the local one.
This can be done in two steps by using the skopeo sync command.
We start by downloading the images on a machine that is connected to the internet. But instead of storing the images into a local registry we put them on a local directory:
$ skopeo sync --source docker://quay.io/coreos/etcd dir:/media/usb-disk/mirrored-images
This is going to copy all the versions of the quay.io/coreos/etcd image into
a local directory /media/usb-disk/mirrored-images.
Let’s assume /media/usb-disk is the mount point of an external USB drive.
We can then unmount the USB drive, scan its contents with some tool, and
plug it into computer of the air-gapped network. From this computer we
can populate the local registry mirror by using the following command:
$ skopeo sync --source dir:/media/usb-disk/mirrored-images --dest-creds="username:password" docker://registry.secure.lan
This will automatically import all the images that have been previously downloaded to the external USB drive.
Pulling the images
Now that we have all our images mirrored it’s time to start consuming them.
It might be tempting to just update all our Dockerfile(s), Kubernetes
manifests, Helm charts, automation scripts, …
to reference the images from registry.kube.lan/<upstream registry FQDN>/<image>:<tag>.
This however would be tedious and unpractical.
As you might know the docker open source engine has a --registry-mirror.
Unfortunately the docker open source engine can only be configured to mirror the
Docker Hub, other external registries are not handled.
This annoying limitation lead me and Valentin Rothberg to create this pull request against the Moby project.
Valentin is also porting the patch against libpod,
that will allow to have the same feature also inside of
CRI-O and podman.
During my experiments I figured some little bits were missing from the original PR.
I built a docker engine with the full patch
applied and I created this /etc/docker/daemon.json configuration file:
{
"registries": [
{
"Prefix": "quay.io",
"Mirrors": [
{
"URL": "https://registry.kube.lan/quay.io"
}
]
},
{
"Prefix": "docker.io",
"Mirrors": [
{
"URL": "https://registry.kube.lan/docker.io"
}
]
}
]
}Then, on this node, I was able to issue commands like:
$ docker pull quay.io/coreos/etcd:v3.1
That resulted in the image being downloaded from registry.kube.lan/quay.io/coreos/etcd:v3.1,
no communication was done against quay.io. Success!
What about unpatched docker engines/other container engines?
Everything is working fine on nodes that are running this not-yet merged patch, but what about vanilla versions of docker or other container engines?
I think I have a solution for them as well, I’m going to experiment a bit with that during the next week and then provide an update.
Show me the code!
This is a really long blog post. I’ll create a new one with all the configuration files and instructions of the steps I performed. Stay tuned!
In the meantime I would like to thank Marco Vedovati, Valentin Rothberg for their help with skopeo and the docker mirroring patch, plus Miquel Sabaté Solà for his help with Portus.
Detail Considered Harmful
Ever since the dawn of times, we've been crafting pixel perfect icons, specifically adhering to the target resolution. As we moved on, we've kept with the times and added these highly detailed high resolution and 3D modelled app icons that WebOS and MacOS X introduced.


As many moons have passed since GNOME 3, it's fair to stop and reconsider the aesthetic choices we made. We don't actually present app icons at small resolutions anymore. Pixel perfection sounds like a great slogan, but maybe this is another area that dillutes our focus. Asking app authors to craft pixel precise variants that nobody actually sees? Complex size lookup infrastructure that prominent applications like Blender fail to utilize properly?

For the platform to become viable, we need to cater to app developers. Just like Flatpak aims to make it easy to distribute apps, and does it in a completely decetralized manner, we should emphasize with the app developers to design and maintain their own identity.
Having clear and simple guidelines for other major platforms and then seeing our super complicated ones, with destructive mechanisms of theming in place, makes me really question why we have anyone actually targeting GNOME.
The irony of the previous blog post is not lost on me, as I've been seduced by the shading and detail of these highres artworks. But every day it's more obvious that we need to do a dramatic redesign of the app icon style. Perhaps allowing to programatically generate the unstable/nightlies style. Allow a faster turnaround for keeping the style contemporary and in sync what other platforms are doing. Right now, the dated nature of our current guidelines shows.

Time to murder our darlings…
HackWeek 17 - Continuing with the REST API
The Libyui REST API Project
I spent the 17th HackWeek working on the previous project - libyui REST API for testing the applications.
You can read some rationale in the blog post for the previous Hackweek.
In short it allows inspecting the current user interface of a programm via a REST API. The API can be used from many testing frameworks, there is a simple experimental wrapper for the Cucumber framework.
Examples
The REST API can be also used directly from the command line, this is a short example how it works:
First start an YaST module, specify the port which will be used by the REST API:
YUI_HTTP_PORT=14155 /usr/sbin/yast timezone
Inspecting with cURL
Then you can inspect the current dialog directly from the command line
# curl http://localhost:14155/dialog
{
"class" : "YDialog",
"hstretch" : true,
"type" : "main",
"vstretch" : true,
"widgets" :
[
{
"class" : "YVBox",
"help_text" : "...",
"hstretch" : true,
"id" : "WizardDialog",
"vstretch" : true,
"widgets" :
[
{
"class" : "YReplacePoint",
"id" : "topmenu",
...
You can also send some action, like pressing the Cancel button:
curl -i -X POST "http://localhost:14155/widgets?action=press_button&label=Cancel"
Using the Cucumber Wrapper
The experimental Cucumber wrapper allows writing the tests in a native English language. The advantage is that people not familiar with YaST internals can write the tests easily. And even non-developers could use it.
Feature: To install the 3rd party packages I must be able to add a new package
repository to the package management.
Scenario: Adding a new repository
Given I start the "/usr/sbin/yast2 repositories" application
Then the dialog heading should be "Configured Software Repositories"
When I click button "Add"
Then the dialog heading should be "Add On Product"
When I click button "Next"
Then the dialog heading should be "Repository URL"
Then continue...
What Has Been Improved
Here is a short summary what has been improved since the last HackWeek.
More Details and More Actions
The HTTP server now returns more details about the UI like the table content, the combo box values, etc… Maybe something is still missing but adding more details for specific widgets should be rather easy.
Also some more actions have been added, now it is possible to set a combo box value or select the active radio button via the REST API.
Processing the Server Requests
Originally the HTTP server was processing the data only when the UI.UserInput
call was waiting for the input. That was quite limiting as the HTTP requests
might have timed out before before reaching that point.
Now the server is responsive also during the other UI calls and even when there is no UI call processed at all. So the API is not blocked when YaST is doing some time consuming action like installing packages. The response now contains the current progress state as displayed in the UI.
Moreover it even works when there is no UI dialog open yet!
# cat ./test.rb
sleep(30)
# YUI_HTTP_PORT=14155 /usr/sbin/yast2 ./test.rb &
[1] 23578
# curl -i "http://localhost:14155/dialog"
HTTP/1.1 404 Not Found
Connection: Keep-Alive
Content-Length: 34
Content-Encoding: application/json
Date: Fri, 13 Jul 2018 05:37:42 GMT
{ "error" : "No dialog is open" }
Text Mode (Ncurses UI) Support
This is the most significant change, now the ncurses texmode UI also supports the embedded REST Server!
So you can see the updated Cucumber test used for testing in the Qt UI from the last HackWeek running in the text mode!

The only problematic part is that the Cucumber and YaST fight for the terminal
output. That means we cannot run the YaST module directly but use some wrapper.
In this case we run it in a new xterm session. But for the real automated
tests it would be better to run it in a screen or tmux session in background
so it works also without any X server.
Also some more complex scenarios work in the text mode, like a complete openSUSE Leap 15.0 installation running inside a VirtualBox VM:
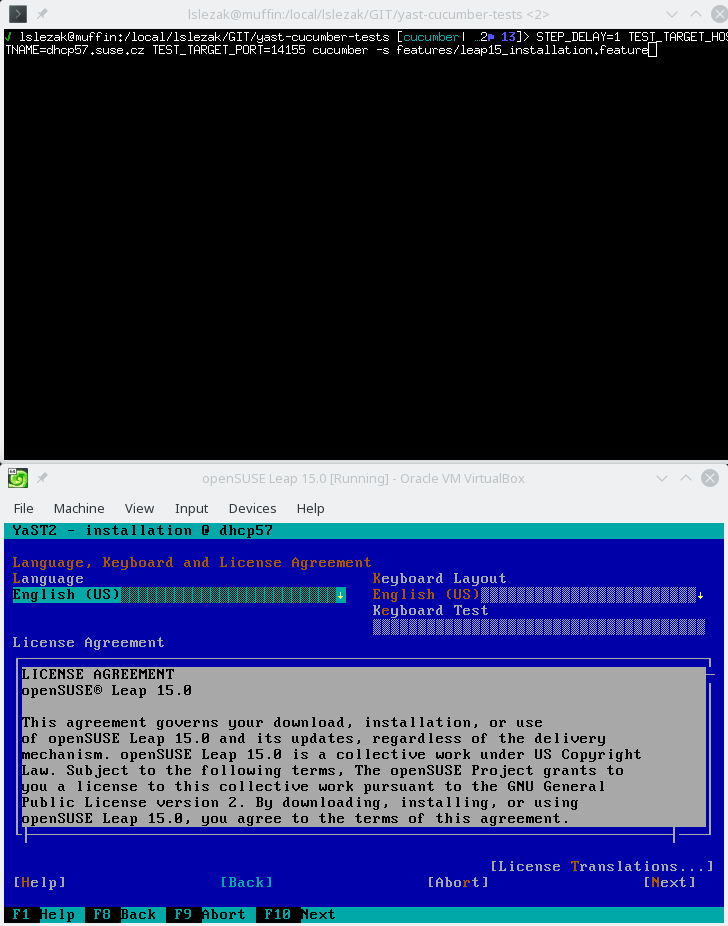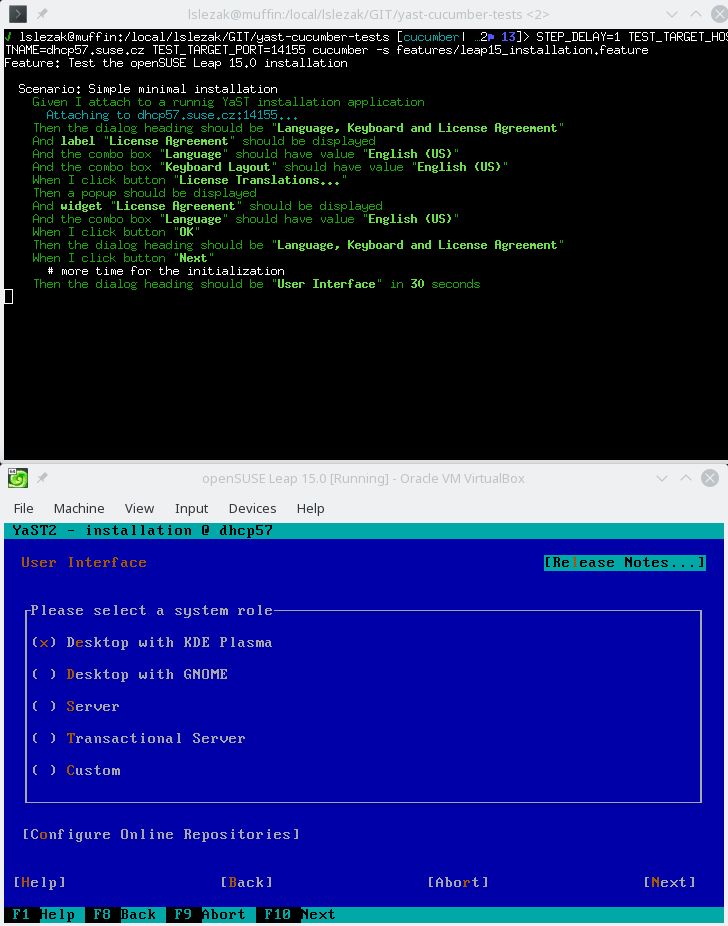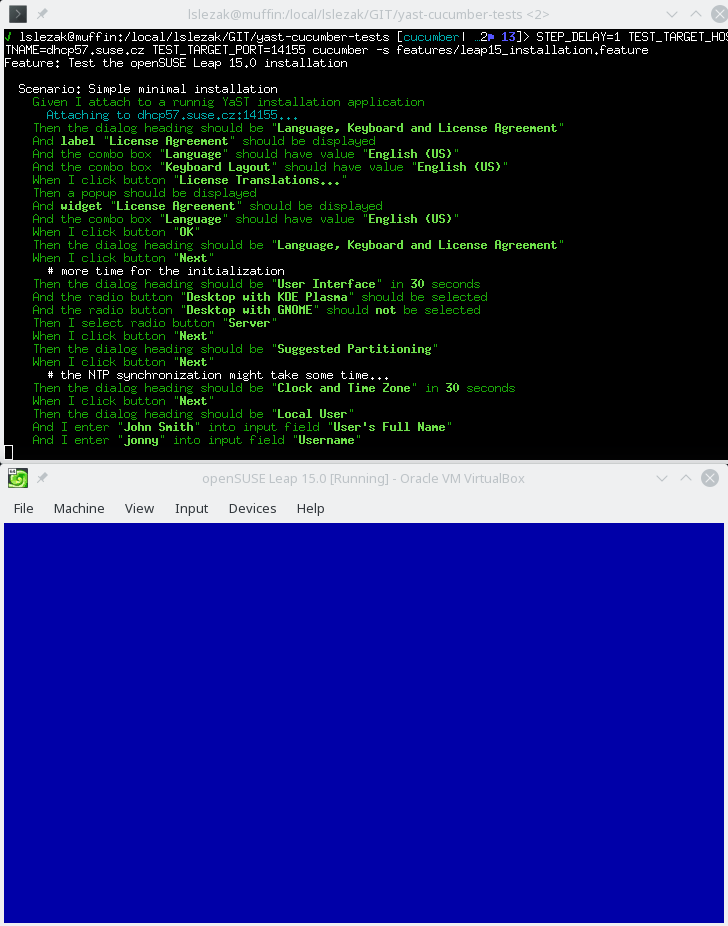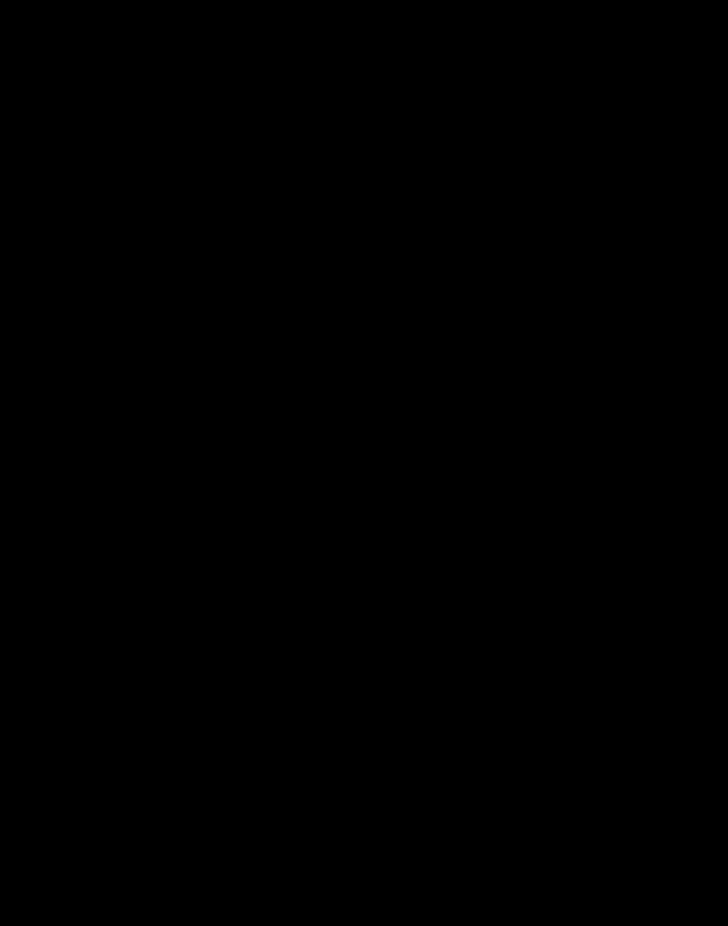
In theory the REST API should work the same way in both graphical and text mode, from the outside you should not see a difference. Unfortunately in reality there are some differences you need to be aware…
The Text Mode Differences
Some differences are caused by the different UI implementation - like the
Ncurses UI does not implement the Wizard widget and the main window has different
properties. For example the main navigation buttons like Back or Next
have YPushButton class in the text mode but in the graphical mode
they have YQWizardButton class and the dialog content is wrapped in an
additional YWizard object.
Another difference might be that YaST (or the libyui application in general) might display a different content in the graphical mode and in the text mode. For example the YaST time zone selection displays a nice clickable map in the graphics mode:
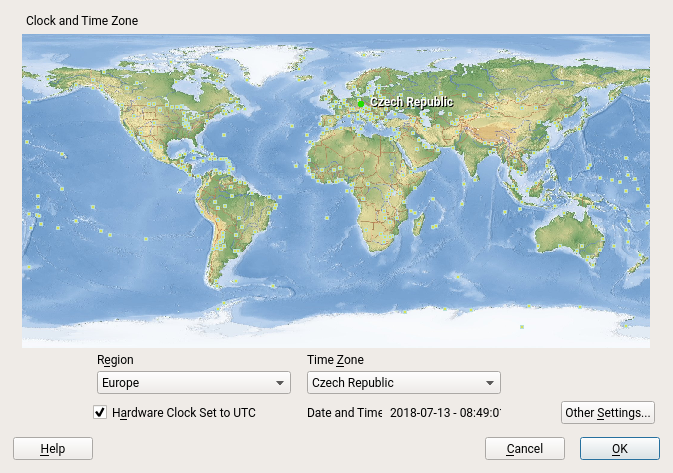
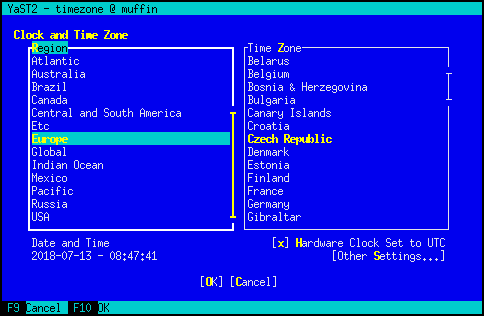
Obviously the world map cannot be displayed in the text mode:
But the bigger difference is that in the graphical mode the time zone is selected
using the ComboBox widgets while in the text mode there are SelectionBox
widgets!
What is Still Working :smiley:
The original support for generic libyui applications is still present. That means the REST API is not bound to YaST but can be used by any libyui application.
Here is a test for the libyui ManyWidgets example which is a standalone C++ application not using YaST at all:

Prepared Testing Packages
If you want to test this libyui feature in openSUSE Leap 15.0 then you can install the packages from the home:lslezak:libyui-rest-api OBS project. See more details here.
Sources
The source code is available in the http_server branches in the libyui/libyui, libyui/ncurses and libyui/qt Git repositories.
TODO
There are lots of missing things, but the project is becoming more usable for the basic application testing.
The most important missing features:
- Trigger
notifyorimmediateevents - if a widget with these properties is changed via the API these UI events are not created. Which usually means after changing a widget via the API the dialog is not updated as when the change is done by user. - Authentication support
- Move the web server to a separate plugin so it is an optional feature which can be added only when needed
- SSL (HTTPS) support
- IPv6 support
- and many more…
I will continue with the project at the next HackWeek if possible…
Freedom and Fairness on the Web
But how does this look like with software we don't run ourselves, with software which is provided as a service? How does this apply to Facebook, to Google, to Salesforce, to all the others which run web services? The question of freedom becomes much more complicated there because software is not distributed so the means how free and open source software became successful don't apply anymore.
The scandal around data from Facebook being abused shows that there are new moral questions. The European General Data Protection Regulation has brought wide attention to the question of privacy in the context of web services. The sale of GitHub to Microsoft has stirred discussions in the open source community which relies a lot on GitHub as kind of a home for open source software. What does that mean to the freedoms of users, the freedoms of people?
I have talked about the topic of freedom and web services a lot and one result is the Fair Web Services project which is supposed to give some definitions how freedom and fairness can be preserved in a world of software services. It's an ongoing project and I hope we can create a specification for what a fair web service is as a result.
I would like to invite you to follow this project and the discussions around this topic by subscribing to the weekly Fair Web Services Newsletter I maintain for about a year now. Look at the archive to get some history and sign up to get the latest posts fresh to your inbox.
The opportunities we have with the web are mind-boggling. We can do a lot of great things there. Let's make sure we make use of these opportunities in a responsible way.

Merge two git repositories
I just followed this medium post, but long story short:
Check out the origin/master branch and make sure my local master, is equal to origin, then push it to my fork (I seldomly do git pull on master).
git fetch origin
git checkout master
git reset --hard origin/master
git push foursixnine
I needed to add the remote that belongs to a complete different repository:
git remote add acarvajal gitlab@myhost:acarvajal/openqa-monitoring.git
git fetch acarvajal
git checkout -b merge-monitoring
git merge acarvajal/master --allow-unrelated-histories
Tadam! my changes are there!
Since I want everything inside a specific directory:
mkdir openqa/monitoring
git mv ${allmyfiles} openqa/monitoring/
Since the unrelated repository had a README.md file, I need to make sure that both of them make it into the cut, the one from my original repo, and the other from the new unrelated repo:
Following command means: checkout README.md from acarvajal/master.
git checkout acarvajal/master -- README.md
git mv README.md openqa/monitoring/
Following command means: checkout README.md from origin/master.
git checkout origin/master -- README.md
Commit changes, push to my fork and open pull request :)
git commit
git push foursixnine
Mapping Open Source Governance Models
The project is up on GitHub right now. For each project there is a YAML file collecting data such as project name, founding date, links to web sites, governance documents, statistics, or maintainer lists. It's interesting to look into the different implementations of governance there. There is a lot of good material, especially if you look at the mature and well-established foundations such as The Apache Foundation or the Eclipse Foundation. I'm also looking into syncing with some other sources which have similar data such as Choose A Foundation or Wikidata.
The web site is minimalistic now. We'll have to see for what proves to be useful and adapt it to serve these needs. Having access to the data of different projects is useful but maybe it also would be useful to have a list of code of conducts, a comparison of organisation types, or other overview pages.

If you would like to contribute some data about the governance on an open source project which is not listed there or you have more details about one which is already listed please don't hesitate to contribute. Create a pull request or an open an issue and I'll get the information added.
This is a nice small fun project. SUSE Hack Week gives me a bit of time to work on it. If you would like to join, please get in touch.
Problemas con Firefox y la swap
Durante semanas noté que el equipo se ralentizaba mucho al momento de que usaba Firefox en sitios como Facebook o TweetDeck. Aunque de entrada sé que esas páginas consumen mucho CPU, lo que más me extrañaba era el considerable lentitud por uso de SWAP (algo que no me pasa en MacOS porque: SSD  ).
).
Buscando alguna explicación en los foros, me topé con dos soluciones que me parecieron muy buenas:
1.- Mandar el caché de Firefox a la RAM. Esto hace que Firefox use la memoria principal para alojar el caché, lo que ahorra llamados al disco duro (uso un «viejito» SATA).
2.- Indicarle a Linux que use preferentemente la memoria principal y no el intercambio. Si tienes más de 8GB de RAM, pues ¡aprovéchalos completamente! Así evitamos que se use ese espacio de disco duro destinado a la SWAP.
Desde que apliqué estos cambios he notado que el rendimiento del equipo ha mejorado y no he notado periodos de cuelgue al usar el navegador… aunque lo siguiente que tengo en mente será comprar un SSD para Linux .
Port Forwarding with systemd
Using Port Forwarding with xinetd has served me well at many occasions. As time proceeds, new technologies show up that allow for similar functionality and others are deprecated. When reading about the obsoletion of xinetd in SLES15, I wondered if you could do the port forwarding also with systemd instead of xinetd.
To accomplish the same port forwarding like in Port Forwarding with xinetd you can proceed as follows.
With systemd, the procedure is twofold. First you have to create a socket that listens on a stream. The second part is to start a proxy service that connects to a remote port. Both are connected by means of their respective name
/etc/systemd/system/http-switch.socket /etc/systemd/system/http-switch.service
Just sticking with the previous example, let me use the following:
- the private has the IP address range 192.168.10.0/24
- the switch is configured with 192.168.10.254 and its management port is 80
- the jump host with access to both networks has the external address 10.10.10.1
- use port 81 to access the switch over the jump host
The first thing we need is a .socket file:
# cat /etc/systemd/system/http-switch.socket [Socket] ListenStream=10.10.10.1:81 [Install] WantedBy=sockets.target
This socket must be connected to a proxy by means of the service name:
# cat /etc/systemd/system/http-switch.service [Unit] Description=Remote Switch redirect Requires=network.target After=network.target [Service] ExecStart=/usr/lib/systemd/systemd-socket-proxyd 192.168.10.254:80 [Install] WantedBy=multi-user.target
After adding these files, the service can be enabled and started with the following commands:
systemctl enable http-switch.socket systemctl enable http-switch.service systemctl start http-switch.socket systemctl start http-switch.service
The previous example is just a very basic one. Especially with the socket file, there is lots and lots of parameters and options available. For more information, see
man 5 systemd.socket
man 5 systemd.service