
 Member
Member manugupt1
manugupt1How my savings are affected on Jet when I buy more things from it?
Jet is an e-commerce competitor to Amazon. I have been using Jet as a service for some time now and really love it. As a user, I use Jet to buy my groceries and some small ingredients daily.
What attracted me to the Jet was its free delivery for 35$ without any need for the requirement for Amazon Prime. I figured that if I can avoid the subscription cost and I can still buy my stuff, hey why not?
What really kept me hooked on to Jet was these factors
- No subscription and free shipping for a base amount of purchase
- Discounts and savings
- An above average customer service.
As I use Jet more and more, I wanted to find out how my savings were affected over time. What I really wanted to know was if I as a user was saving more over time or less given its dynamic pricing.
I will make a few assumptions here:
- I will not include any discount coupons applied as not all orders had discounts (in fact, I had applied only 1 discount coupon).
- I will not include any shipping discounts applied as well.
- I will not include taxes applied as part of my purchase as well.
- To normalize, all my savings will be displayed as the % of the amount I bought.
This is what I found from my own purchase behavior.

Observations
- As I buy more things on Jet, my savings on Jet.com go lower.
- There are peaks in the savings which help keep the users hooked into making purchases.
Takeaways from this for a customer acquisition and retention strategy
- First time users can be discounted heavily to make sure that they try the products for the first time.
- To build retention loops, the next few subsequent products can be discounted more than the first time so that users return to use their products in the hopes of gaining more values.
- As the users get used to the product, discounts can be reduced to recover the costs that were initially spent to acquire users.
Danbooru Client 0.6.1 released
A new version of Danbooru Client is now available!
What is Danbooru Client?
Danbooru Client is an application to access Danbooru-based image boards (Wikipedia definition).
It offers a convenient, KF5 and Qt5-based GUI coupled with a QML image view to browse, view, and download images hosted in two of the most famous Danbooru boards (konachan.com and yande.re).
Highlights of the new version
- Unbreak konachan.com support (change in URL format)
Coming up next
HTTPS support! This is something that I didn’t think up in the first release but that it is sorely needed nowadays. Ah? You wanted to know about multiple API support? Well… so far the code has been a bit bitrotting, as I kind of lack the motivation to work on it. If I pick it up again, I hope to finish it.
Release details
Currently, there is only a source tarball. For security, I have signed it with my public GPG key (A29D259B) and I have also provided a SHA-512 hash of the release.

Getting Started in Android Development: Part 3: Reducing Bloat
So far we have seen Part 1: Building the First App, and Part 2: Publishing the first App.
That Feeling When you build a brilliant piece of software and the users are ripping it from your fingers to the sound of raving reviews:
- dad: I'm home! Have you seen my first app I've e-mailed you about?
- kid: Hi. Yup.
- dad: So?? Do you like it? Have you given it any stars?
- kid: Just one. It can do almost nothing and it takes up too much space.
And the kid is right. App description: Press a button and get a random number between 1 and 6. App size: 6MB. Six. Megabytes.
In this post we will reduce that over a hundred times to 44KB.
Thanks to SUSE, my employer, for sponsoring a company-wide Hack Week which this project was a part of!
Debug or Release Build?
I did not manage to make a release build in the Android Studio IDE. So I tried from the command line. (J. Reidinger has pointed out that I should read Configure Build Variants.)
$ sudo zypper install java-1_8_0-openjdk-devel # to provide javac
$ ./gradlew assemble
[downloads some deps at first... 280MB]
[lots of output for normal build too]
$ (cd app/build/outputs/apk; stat -c "%'9s %n" *.apk)
1,443,734 app-debug.apk
1,337,890 app-release-unsigned.apkApparently my hopes that a release build would be significantly smaller were unfounded. The APK has 1.5MB and takes up 6MB when installed.
Shrink Your Code and Resources
First I searched the web for "minify android app" and eventually arrived at Shrink Your Code and Resources in the IDE manual.
Using minifyEnabled true in build.gradle shrunk the signed release build from 1,347,038 bytes to 786,674, which results in 2.39MB installed size. (Did not find a way to install this build from the IDE, used adb install -r ./app/app-release.apk.)
Changing proguardFiles from proguard-android.txt to proguard-android-optimize.txt slightly shrinks the APK to 771,406 bytes.
Adding shrinkResources true: 745,490 bytes, 2.21MB installed.
Code Bloat: Activity Base Class
It seems that now the main reason for bloat is the sheer amount of included code: 5 methods of mine vs 4823(!) methods from the android.* classes.
Changed the base class of the main activity from android.support.v7.app.AppCompatActivity to android.app.Activity but then adb install says "Failure [INSTALL_FAILED_UPDATE_INCOMPATIBLE]". adb uninstall net.vidner.justrollonedie solved it. But I wonder what would happen if my users on the app store wanted to update. Fortunately I have none :D
The base class change improved the sizes to 661,870 APK, 1.62MB installed.

Code Bloat: API Version
I thought a 4x reduction in installed size was good enough, even if still bloated. I decided to fix one more thing before pushing an update to the store: the minimal required Android platform. (In the process of tinkering with a demo OpenGL app I discovered that android-8, supporting my old 2.2 Froyo phone, gets automatically downloaded if I declare it in the app manifest.)
So I did, and the side effect was perfect: all boilerplate code was gone and I ended up with a 17,282 byte APK, 44KB (kilobytes!) installed. Still too much for a microcontroller ;-) but good enough for Android.
Figuring out how to downgrade my code and layout and styles to still run on the older API seemed tricky at first, but then I simply generated a scratch project for android-9 and copied the differences. Then I changed one style name with the help of the API version filter (see screenshot).
Get the App, Get the Source
The source code for Just Roll One Die is on GitHub under a MIT license. You can try out Just Roll One Die on Google Play.
Hackweek 15 - the YaST Integration Tests
Hackweek 15
I decided to spend the last SUSE Hackweek with YaST and find a way which would allow us to write and run YaST integration tests easily. See the details in the project Hackweek page.
Some time ago I found the cucumber-cpp project. It is a cucumber support for the C++ programming language.
The reason is that the YaST UI uses the libyui library which is written in C++. If we want to control and check the YaST UI we need to implement it on the libyui level.
The Hackweek Result
Here are some Cucumber test examples which I was able to run in a real system. The source code for the tests and the details how to run them can be found at the lslezak/cucumber-yast GitHub repository.
Currently only the graphical (Qt) UI is adapted, the textmode (ncurses) will not work and crash (because of the ABI incompatibility).
The code is available in my GitHub forks of libyui, libyui-qt and small improvement was done for the cucumber-cpp library. The experimental RPM packes are available in the home:lslezak:cucumber OBS repository.
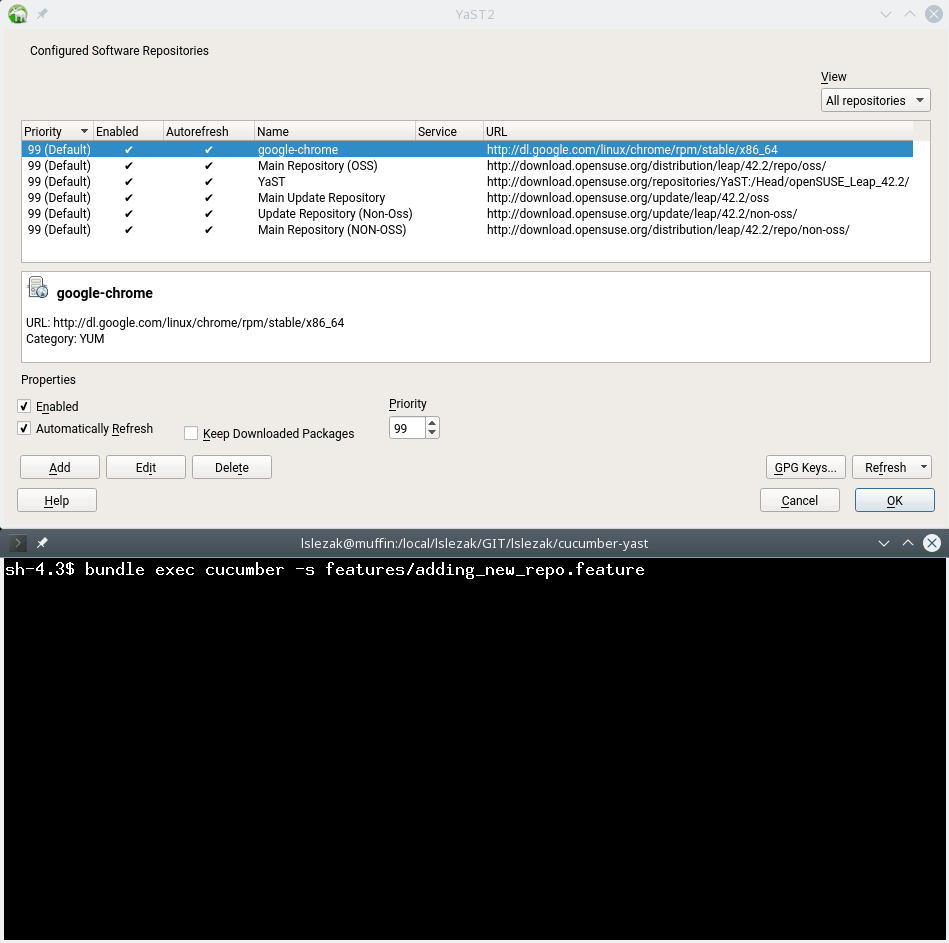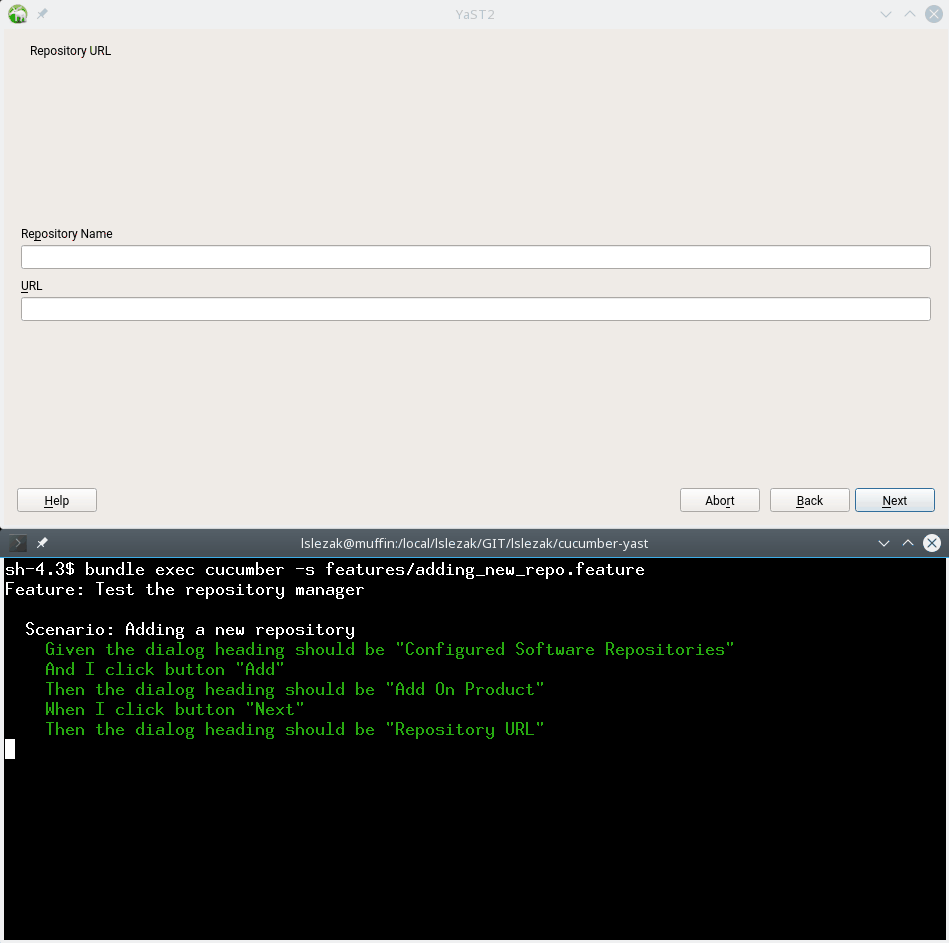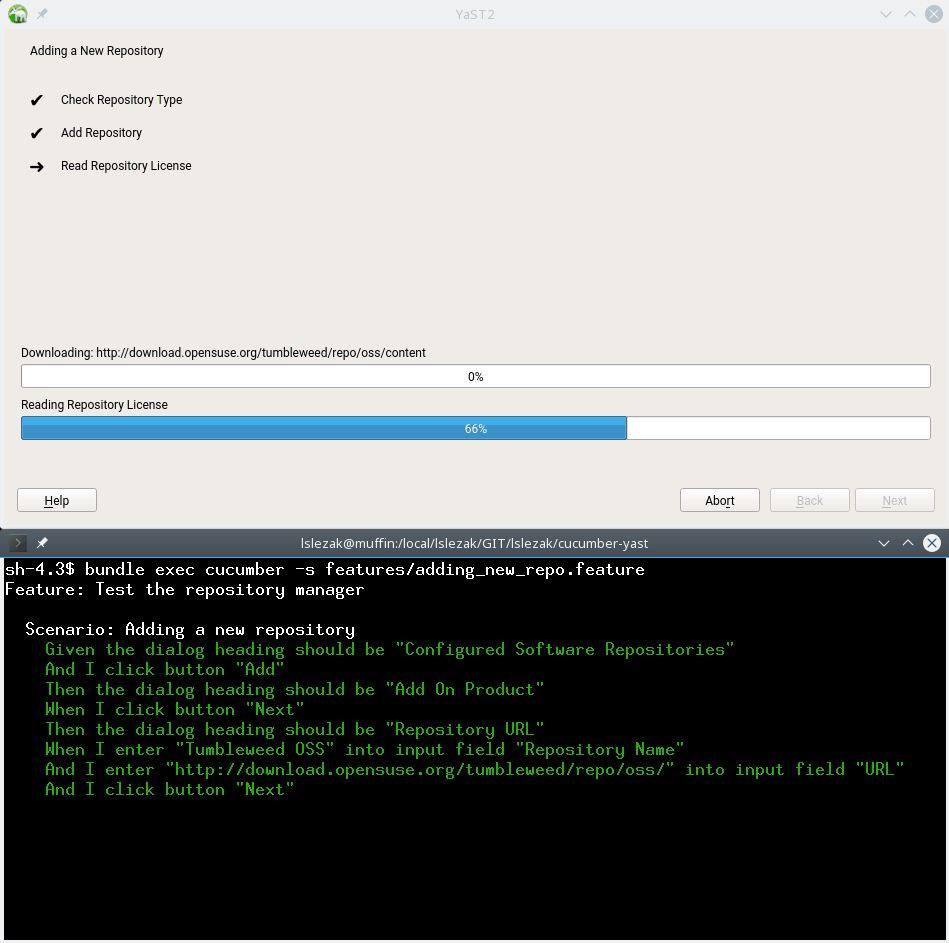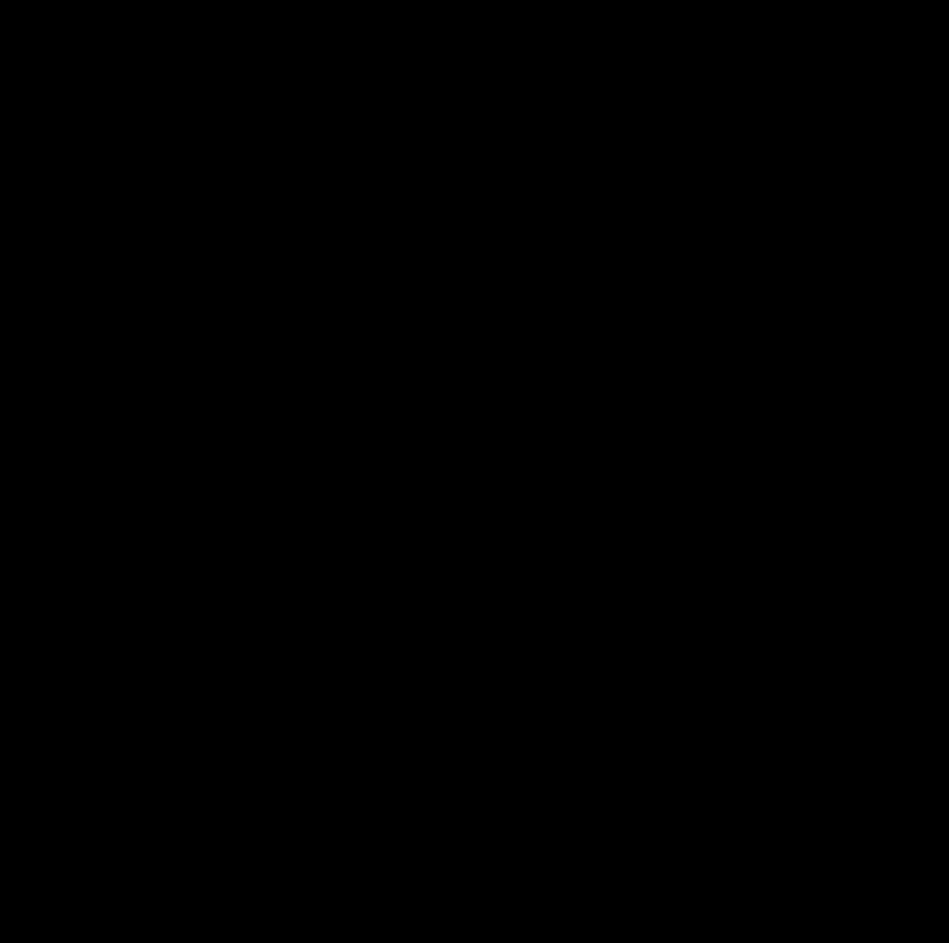
Running a Cucumber Test in Installed system
Here is the output of the adding_new_repo.feature Cucumber test.
Running a Cucumber Test During Installation
This needs a patched openSUSE Leap 42.2 installer so it is not trivial to reproduce…
In this case the installation is running in a VirtualBox virtual machine and the test is running outside on my workstation. The test source is here.
Running a Cucumber Test for a Plain Libyui Application
The Cucumber tests can be written actually for any application which uses the libyui framework, not only for YaST. This might be interesting for the other users of the libyui framework, for example the Mageia tools.
Here is a test for the libyui SelectionBox2.cc example.
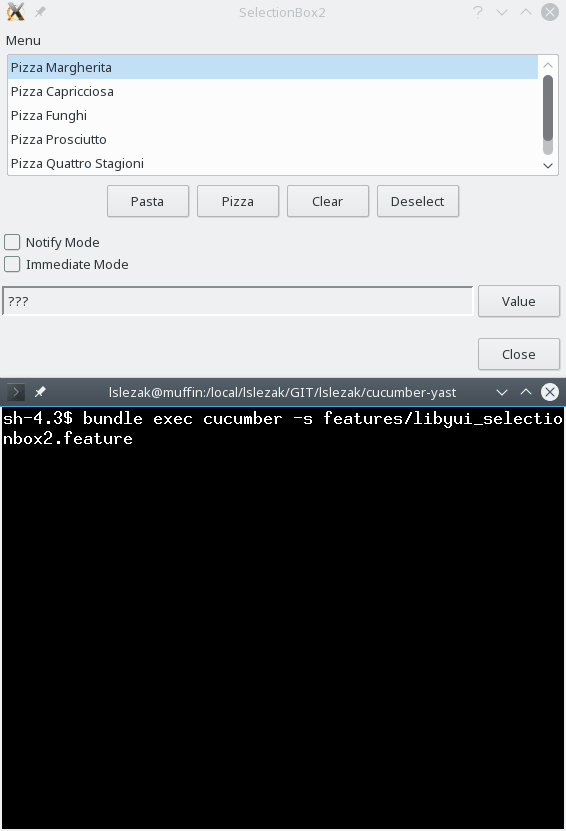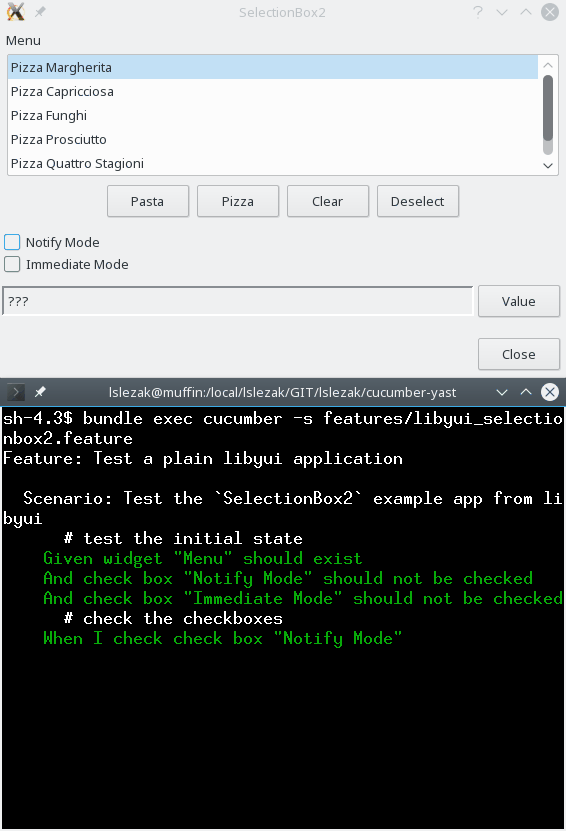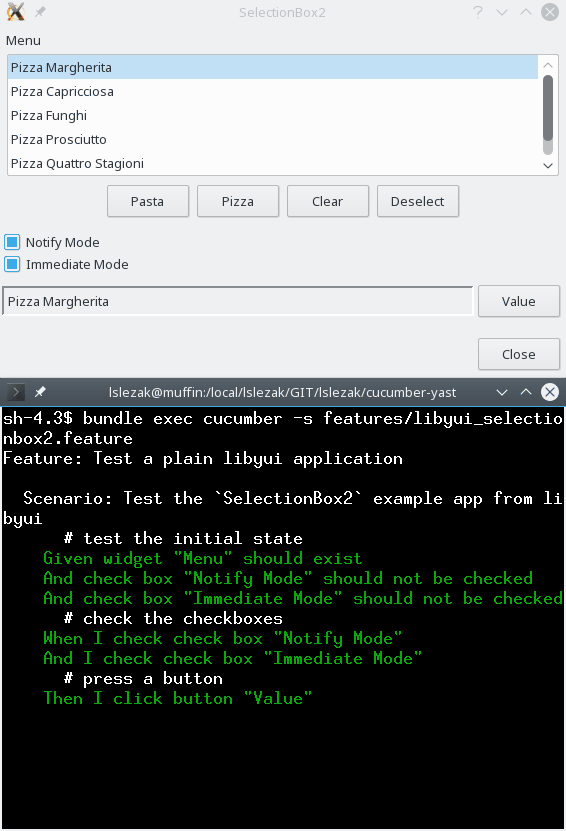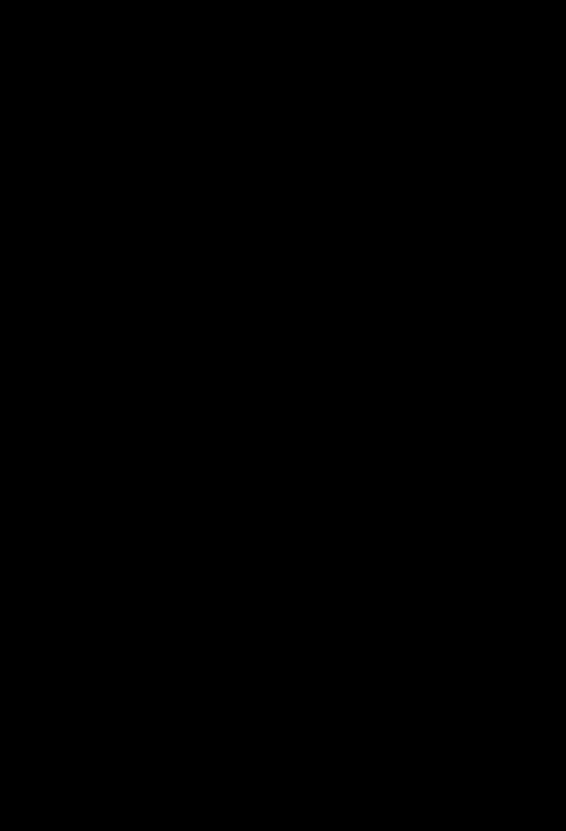
What I Learnt
- Using boost for implementing a simple TCP server is probably an overkill,
after seeing this boost::asio example
:flushed: I decided to use plain and simple
socket()/bind()/listen()C functions. - Synchronizing with the application is crucial, you cannot verify the UI
state until it is fully built by the application. In case of YaST it
is when
UI.UserInput(or similar) function is called. - I refreshed my C++ knowledge, I even used a C++ template in the code :wink:
Technical details
- The cucumber-cpp library uses the Cucumber wire protocol which basically sends JSON messages over a TCP port. The advantage is that it is possible to test the application running at another machine. This is useful for testing the YaST installation.
- I had to reimplement the server part as the cucumber-cpp library can only test an application represented by a single C++ object. Because YaST uses a plugin architecture where the parts are loaded dynamically and they cannot be easily accessed from outside so the server part must have been implemented directly on the libyui level.
- The advantage of this solution is that the integration tests are available to any libyui based application, not only YaST.
TODO
- Add more matchers
- Support for more UI calls (e.g.
UI.PollInput) - Support the other UIs (ncurses, GTK)
- Support for the packager widget (in the
libyui-*-pkgsubpackages) - Increase the Cucumber timeout - when a step takes too much time (e.g. installing packages) then the test runner times out
- Closing the application crashes the test (the TCP port is closed and cucumber reports broken pipe)
- The application needs to be already running, it is difficult to ensure clean initial state or restart the application for another test scenario
The last two issues are quite tricky, it seems we will need to run some wrapper and communicate with YaST in the tests indirectly. In that case we probably should use some simpler communication protocol like the Test Anything Protocol (TAP). I was told that this protocol is already supported by openQA so it should be easy to use it also there…
Install and configure a full software stack for a Flask app: Apache, Gunicorn, MongoDB, Redis
A few days ago, I had to deploy a new Flask application for a customer and here are some notes which could be useful for somebody, as well. I will show how everything is configured, even if here, in this tutorial, I have just a minimal Flask app, in one file: app.py
The software stack used: Python 3.x, Flask, Ubuntu 14.04, Apache, Gunicorn, MongoDB (via mongoengine), Redis(used for Flask-Cache)
Python/Flask environment setup
First we will create a user to run our application
# adduser deploy
- login as that user
# su - deploy
Let's prepare the environment to run our Flask app
$ pwd
/home/deploy/
$ mkdir apps
$ mkdir apps/domain
$ cd apps/domain
- create a python virtual environment
$ pyvenv-3.4 venv
$ source venv/bin/activate
$ pip install -r requirements.txt
$ deactivate
Apache setup
The customer has a VPS with Plesk installed, so, the place for Apache config file for a specific domain is different from a standard Apache installation. For a standard installation and configuration please check my previous post: Deploy your Flask Web Application on Ubuntu 16.04 with Apache, Gunicorn and systemd
- configure Apache to serve our Flask app:
# a2enmod proxy proxy_ajp proxy_http rewrite deflate headers proxy_balancer proxy_connect proxy_html
# service apache2 restart
- create our Apache config file specific to our domain:
# cd /var/www/vhosts/system/domain.com/conf
# cat /var/www/vhosts/system/domain.com/conf/vhost.conf
<Proxy *>
Order deny,allow
Allow from all
</Proxy>
ProxyPreserveHost On
<Location "/">
ProxyPass "http://127.0.0.1:5000/"
ProxyPassReverse "http://127.0.0.1:5000/"
</Location>
Restart Apache
# service apache2 restart
Testing Flask application
- go to the folder which contains the Flask app
$ cd /home/user/apps/domain
- start the Flask app (just for testing, using
pythoninterpreter)
$ python app.py
Let's check to see it running on: http://www.domain.com
Works, so, now let's create also a Gunicorn config file and run our aplication in production using Gunicorn.
$ vim /home/user/apps/domain/gunicorn.conf
accesslog = "/home/deploy/apps/domain/logs/gunicorn_access.log"
errorlog = "/home/deploy/apps/domain/logs/gunicorn_error.log"
- and we need to create also the directory for
Gunicorn's log files
$ mkdir logs
So, the directory looks like:
$ ls -ltr
total 16
-rw-rw-r-- 1 deploy deploy 206 Feb 28 10:19 app.py
drwxrwxr-x 5 deploy deploy 4096 Feb 28 21:47 venv
-rw-rw-r-- 1 deploy deploy 142 Feb 28 21:48 gunicorn.conf
drwxrwxr-x 2 deploy deploy 4096 Feb 28 21:48 logs
Now, is time to run our Flask application in production using Gunicorn
(venv) deploy@myhost:~/apps/domain$ gunicorn -c gunicorn.conf -b 0.0.0.0:5000 app:app
Let's check again to see it running on: http://www.domain.com ==> Works
Good - it seems that up to now everything is configured and running.
One additional thing: you perhaps want to have your Flask application surviving at reboot, and also to start/stop it using service command. Ubuntu 14.04 is using Upstart, so we have to create one more file, let's call it /etc/init/myapp.conf with the following content (all errors will go to /var/log/upstart/myapp.log):
description "myapp"
start on (filesystem)
stop on runlevel [016]
respawn
setuid deploy
setgid deploy
chdir /home/deploy/apps/domain/
exec /home/deploy/apps/domain/venv/bin/gunicorn -c /home/deploy/apps/domain/gunicorn.conf -b 0.0.0.0:5000 app:app
And now we should be able to use service myapp start to start the application or service myapp stop to stop the application. For a similar start-up script for Systemd you can check my previous tutorial: Deploy your Flask Web Application on Ubuntu 16.04 with Apache, Gunicorn and systemd.
Install and configure Redis
Redis is an open source (BSD licensed), in-memory data structure store which can be used as a database, cache and message broker. We are using it in our Flask application for caching.
- update our repos/packages
# apt-get update
- install Redis
# apt-get install redis-server
- check if Redis is running
# netstat -ant | grep 6379
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN
# service redis-server status
redis-server is running
- is it working?
# redis-cli
127.0.0.1:6379> ping
PONG
- do a quick performance check
# redis-benchmark -q -n 1000 -c 10 -P 5
PING_INLINE: 200000.00 requests per second
PING_BULK: 249999.98 requests per second
SET: 333333.34 requests per second
GET: 200000.00 requests per second
INCR: 200000.00 requests per second
LPUSH: 333333.34 requests per second
LPOP: 333333.34 requests per second
SADD: 499999.97 requests per second
SPOP: 499999.97 requests per second
LPUSH (needed to benchmark LRANGE): 249999.98 requests per second
LRANGE_100 (first 100 elements): 71428.57 requests per second
LRANGE_300 (first 300 elements): 26315.79 requests per second
LRANGE_500 (first 450 elements): 15384.62 requests per second
LRANGE_600 (first 600 elements): 9708.74 requests per second
MSET (10 keys): 142857.14 requests per second
In default installation (on Ubuntu 14.04) Redis is running only on localhost but it doesn't have any authorization mechanism turned on. So, we need to take care of that first. We have to edit the config file
/etc/redis/redis.conf
- make sure is listening on localhost:
bind 127.0.0.1
- make sure you add AUTH (
foobaredis the password here, be sure you have a good one)
requirepass foobared
# service redis-server restart
Stopping redis-server: redis-server.
Starting redis-server: redis-server.
# service redis-server status
redis-server is running
- AUTH was added so, let's check to see if is working without password
# redis-cli
127.0.0.1:6379> ping
(error) NOAUTH Authentication required.
127.0.0.1:6379>
===> is not working without AUTH, GOOD
Let’s try using AUTH command
# redis-cli
127.0.0.1:6379> ping
(error) NOAUTH Authentication required.
127.0.0.1:6379> AUTH foobared
OK
127.0.0.1:6379> ping
PONG
127.0.0.1:6379>
===> now works. So, any Redis client should first authenticate using AUTH command, in order to proceed.
Install and configure MongoDB
MongoDB is a NoSQL database that offers a high performance, high availability, and automatic scaling enterprise database. Data is stored in a "document" structure in JSON format (in MongoDB called BSON).
- update our repos/packages
# apt-get update
- let’s install MongoDB
# apt-get install mongodb
- check if it is running
# service mongodb status
mongodb start/running, process 6405
- check if is listening only on localhost
# netstat -ant | grep 27017
tcp 0 0 127.0.0.1:27017 0.0.0.0:* LISTEN
- show some statistics (press
CTRL+Cto stop it)
# mongostat
- show some statistics (10 rows, every 2 Seconds)
# mongostat --rowcount 10 2
- let’s use MongoDB command iine
# mongo
MongoDB shell version: 2.4.9
connecting to: test
Welcome to the MongoDB shell.
For interactive help, type "help".
For more comprehensive documentation, see
http://docs.mongodb.org/
Questions? Try the support group
http://groups.google.com/group/mongodb-user
> show dbs
local 0.078125GB
>
- get out of mongo client: type
exit
To create an admin user we have to login to Mongo server and use admin database:
# mongo
MongoDB shell version: 2.4.9
connecting to: test
> use admin
switched to db admin
NOTE: the installed MongoDB version is 2.4.9, and the syntax for user management changed for 2.6.0. Please check MongoDB's documentation.
Create a User Administrator
>db.addUser( { user: "root",
pwd: "root_password",
roles: [ "userAdminAnyDatabase" ] } )
Let’s add a user with read/write permissions, which has dbAdmin role as well
> use admin
switched to db admin
> db.addUser( {user:"admin", pwd:"admin_pass", roles:[ "readWrite", "dbAdmin"] } )
{
"user" : "admin",
"pwd" : "bfe79169688f26a49508d70ce4c0b01c",
"roles" : [
"readWrite",
"dbAdmin"
],
"_id" : ObjectId("58b5ce37c339fdf8b9638d30")
}
- show all available users to be sure it was created
> show users
{
"_id" : ObjectId("58b5ce37c339fdf8b9638d30"),
"user" : "admin",
"pwd" : "bfe79169688f26a49508d70ce4c0b01c",
"roles" : [
"readWrite",
"dbAdmin"
]
}
>
If you want/need to add a user with only read access:
> db.addUser( {user:"readuser", pwd:"readuserpass", roles:[ "read"] } )
I will add only one more user for our Flask app (with read/write access):
> db.addUser( {user:"flask_user", pwd:"flask_user_pass", roles:[ "readWrite"] } )
> db.addUser( {user:"flask_user", pwd:"flask_user_pass", roles:[ "readWrite"] } )
{
"user" : "flask_user",
"pwd" : "7e80bce849898d7c85fe007147dc5c94",
"roles" : [
"readWrite"
],
"_id" : ObjectId("58b5d011c339fdf8b9638d31")
}
- and now we should have two users in our database, let's check if we are right
> show users
{
"_id" : ObjectId("58b5ce37c339fdf8b9638d30"),
"user" : "admin",
"pwd" : "bfe79169688f26a49508d70ce4c0b01c",
"roles" : [
"readWrite",
"dbAdmin"
]
}
{
"_id" : ObjectId("58b5d011c339fdf8b9638d31"),
"user" : "flask_user",
"pwd" : "7e80bce849898d7c85fe007147dc5c94",
"roles" : [
"readWrite"
]
}
>
Now, the only thing left is to restart mongo with auth flag. In order to do that we have to change a line in Mongo's config file.
# vim /etc/mongodb.conf
and change the line #auth = true to
auth = true
- restart mongodb
# service mongodb restart
mongodb stop/waiting
mongodb start/running, process 7354
Let’s test to see if everything works:
# mongo
MongoDB shell version: 2.4.9
connecting to: test
> use admin
switched to db admin
> show dbs
Tue Feb 28 20:36:39.328 listDatabases failed:{ "ok" : 0, "errmsg" : "unauthorized" } at src/mongo/shell/mongo.js:46
>
==> right, we are not authorised!!!
Everything should be installed and configured by now.
Getting Started in Android Development: Part 2: Publishing the First App
Here I simply describe what it takes to publish an Android application that I described in the previous part, Building the First App.
Thanks to SUSE, my employer, for sponsoring a company-wide Hack Week which this project was a part of!
I will only deal with free apps: no cost for the user and no advertisements. I guess it would be easy to slap an advertisement module on it or put a minimal price tag on the app. But then it would be morally wrong for me to keep the profits without giving SUSE a cut, and the organizational and accounting process would quickly turn this into a lawyer's Hack Week. Scratch that.
Registering a Publisher Account: $25
I started with the instructions at Get Started with Publishing.
I could have reused my existing Google account but decided to create a new one. The next step may put you off: a 25 USD registration fee is needed.
Then a fair amount of legalese, which I did skim through, and I was rewarded by the knowledge that Google apparently does not like developers to publish web browsers or search engines.
Publishing the App
When I thought my application was good enough to be published I went to the Developer Console to make a Store Listing.
Entered the app name, summary, long description; no surprise there, I had expected that from openSUSE RPM packaging. Then came the innovation: screenshots are required! In fact,
- Two screenshots
- a high-resolution icon (512x512 pixels)
- a feature graphic (1024x500 px) which appears as the heading of the app listing page
Reportedly the new standard way to take a screenshot is Power + Volume Down. But that did not work for my Xperia phone. I had to enable the following setting, after which a Screenshot option appeared in the menu that appears after holding Power.
- Settings, then
- Device / Buttons, then
- Power button / Power menu, there
- enable Screenshot ☑.
For a moment I feared I would need to hire a designer for the icon, but then I told LibreOffice to write a 6 in a 360pt big font and used that. whew!
More form items to fill: App type: Applications (not Games); Category: Entertainment (I guess); Pricing and distribution: Free, All countries, No ads.
We do not process any user data so we check a box that we're Not submitting a privacy policy.
Now we are at a point in the form where it says that we need to submit a content rating, but it won't let us do it. I think it only allows to rate after the app has been uploaded.
Are we ready to upload the app code? Upload APK... bzzzt, wrong! must not upload a debug build. Did not find a way to make a production build in the GUI so used the CLI for a change: ./gradlew assemble... bzzzt, wrong! must not upload an unsigned build.
Signing software makes sense. Except the signing mechanism is unfamiliar to me, something involving a Java KeyStore. So I followed the manual: Sign Your App. Ended up with a file in my home directory and needing to enter two passwords each time I build a signed APK. At least no certification authority needed to be involved.
Content Rating: Category: Utility, No violence, No sexuality, No offensive language, No controlled substances (illegal drugs), No communication with other users, No sharing of personal information, No sharing of location, No digital goods purchasing, No Nazi symbolism, Not a browser or search engine.
Finally all information was there, I hit Publish, and I wondered how long the review process would take. It took about 3 hours on a European Tuesday noon.
You can try out Just Roll One Die on Google Play. The source code for Just Roll One Die is on GitHub under a MIT license.
Next
In the next part we will deal with software bloat. Because an app that can roll a 6 is justified in taking up 6MB on your kid's tablet, right? Right??

Hackweek projet: Let's Encrypt DNS-01 validation for acme.sh with Gandi LiveDNS
Let's Encrypt is a project aimed at providing SSL certificates for free, in an automated way.
I wanted to get a SSL certificate for my Synology NAS. Synology now supports natively Let's Encrypt but only if the NAS accepts incoming HTTP / HTTPS connections (which is not always what you want).
Fortunately, the protocol used by Let's Encrypt to validate a hostname (and generate a certificate), Automatic Certificate Management Environment (ACME) has a alternative validation path, DNS-01, based on DNS.
DNS-01 requires access to your DNS server, so you can add a validation token used by Let's Encrypt server, to ensure you own the domain name you are requesting a certificate for.
There is a lot of ACME implementations, but very few supports DNS-01 validation with my DNS provider (gandi.net).
I ended-up using acme.sh, fully written in shell script and tried to plug Gandi DNS support in it.
After some tests, I discovered Gandi current DNS service is not allowing fast changing DNS zone informations (which is somehow a requirement for DNS-01 validation). Fortunately, Gandi is now providing a new LiveDNS server, available in beta, with a RESTful HTTP API.
I was able to get it working quite rapidly with curl, and once the prototype was working, I've cleaned everything and created a pull request for integrating the support in acme.sh.
Now, my NAS has its own Let's Encrypt certificate and will update it every 90 days automatically. Getting and installing a certificate for another server (running openSUSE Leap) only took me 5 minutes.
This was a pretty productive hackweek !
Getting Started in Android Development: Part 1: Building the First App
Getting Started in Android Development: Part 1: Building the First App
Do you know programming and want to start with the Android platform? Just like me! Read on.
Thanks to SUSE, my employer, for sponsoring a company-wide Hack Week which this project was a part of!
In case you wonder why Android: it is a good balance of work and play. Android is not the coolest toy to play with at the moment, but it is the most versatile device that people are likely to have at hand, especially when traveling. And Android already outnumbers openSUSE and all other OSs in my household.
This is a three part series: 1) building an app, 2) publishing it on Google Play, 3) trimming it down. In this part, we'll set up the development environment, follow the official tutorial to build a trivial app, then build a trivial yet useful app of our own.

a screenshot of my first app
Installing the SDK
I am using openSUSE Leap 42.1 (x86_64). You will notice that I keep tallying the disk space taken. This is because I am a bit short of space on one of my machines, and need to have an idea how much cleanup is needed.
Went to https://developer.android.com/.
Downloaded Android Studio (2.2.3 for Linux, 438 MiB, unpacks to 785 MiB), followed the instructions, unpacking to /opt (getting /opt/android-studio).
Ran /opt/android-studio/bin/studio.sh. Was greeted by an "Android Studio Setup Wizard": chose a Standard setup. Additional download of 890MB (1412MB unpacked) to ~/Android/Sdk.
Got a slightly confusing notice about KVM emulator acceleration. It seems that if you have used KVM before on your machine, the SDK will use it out of the box. But even with acceleration, don't expect the emulator to be fast. If you have a real device, use that.
"Building Your First App"
For the most part I simply followed the tutorial for building, installing, and running a trivial app that asks for a message and then displays it. The documentation feels excellent!
The one non-obvious part was choosing which Android version, in other words, which API level, to target. in the Target Android Devices dialog, the preselected option is API 15: Android 4.0.3 (IceCreamSandwich). That is presumably based on the current active device statistics which result in the app being compatible with 97% of devices. The oldest one is API 9: Android 2.3 (Gingerbread), which was a bit disappointing since my older phone from 2010 runs API 8, 2.2 (Froyo). (Don't worry, I eventually solved that in part 3.) Fortunately my newer phone has API 22: Android 5.1.1. Installed the API 22 platform too, to match the phone, about 100MB.
Connected my phone with a USB cable, pressed Run, and there it was! Don't worry, a buggy app will just crash and not affect the rest of your phone.
Just Roll One Die
Now it looked like I knew enough to make a useful app, so I did: Once my family was on a train with a board game table but we had no dice. So my first actual app is Just Roll One Die. A totally simple application that can just roll one ordinary six-faced die. Six faces ought to be enough for anybody. No pictures, just digits.
The source code for Just Roll One Die is on GitHub under a MIT license. You can try out Just Roll One Die on Google Play. (The details of how to get an app there are described in Part 2: Publishing the First App.)
How about you?
I was amazed how easy it was and I can't believe that it took me so long to try this. Wy don't you too give it a try and let me know how you are doing.
Using Linux notebook as an alarm clock
New and improved Inqlude web site

All libraries have additional meta data now to group them by a number of curated topics. You can see the topics in the navigation bar on the left and use them to navigate Inqlude by categories. The listing shows more information on first view, such as the supported platforms, to make it easier to find libraries according to your criteria without having to navigate between different pages. The presentation in general is cleaner now, and some usability testing has shown that the page works better now than before. In addition to the visible changes, Nanduni has also done quite a bit of improvements under the hood, including better automated testing. I'm proud of what we have achieved there.
It always has been a privilege for me to act as mentor as part of Google's Summer of Code or other programs. This is one of the most rewarding parts of working in free software communities, to see how new people learn and grow, especially if they decide to stay involved after the program has ended and become valuable members of the community for the long term. Being able to help with that I feel is one of the most satisfying investments of your time in the community.