
 Member
Member Futureboy
FutureboyDistrobox with BoxBuddy on openSUSE

Guía para portar los temas globales a Plasma 6
Hace unos días lo comentaba, los grandes cambios de versiones tienen una cara extremadamente positiva ( ya que de lo contrario no se realizarían) y algunos aspectos negativos como puede ser un número de bugs más alto de lo habitual o la pérdida de funcionalidades o plasmoides temporal… o la imposibilidad de usar temas globales si no se hacen algunos cambios. Como ocurrió con los plasmoides, el equipo de desarrollo de KDE ha elaborado una guía para portar los temas globales a Plasma 6 y que pretende facilitar la migración de estos elementos tan característicoas de nuestro escritorio. En mi opinión, como dije con los plasmoides, una extraordinaria iniciativa.
Guía para portar los temas globales a Plasma 6
Como ya se podía intuir, no solo el API de Plasma utilizada para crear widgets de escritorio (también conocidos como «applets» o «plasmoides«) ha cambiando para la versión Plasma 6.0 sino que también se van a ver afectados los temas globales, con lo que todos estos paquetes de software que cambian de con un simple click todo el aspecto de tu escritorio deberán ser adaptados ya que se pierde la compatibilidad.
Esto es tanto así que ya se ha creado la sección propia para temas de Plasma 6 en la KDE Store, aunque en el momento de escribir este artículo, no hay ninguno creado, lo cual es significativo y, evidentemente, deber ser solucionado con rapidez.
Con la intención de que esto ocurra en el menor tiempo posible y que en breve tengamos un buen número de estas delicas visuales ideales para personalizar nuestro entorno de trabajo los diseñadores de KDE han creado una breve guía para portar los temas globales a Plasma 6.

En esta guía se especifica las novedades (como que ahora los temas son tratados como un kpackage lo que significa que necesitan de un archivo manifest.json para ser utilizados de forma correcta) o los grandes cambios (como que ya no se pueden utilizar enlaces simbólicos para cargar un tema Plasma).
Por supuesto, hay muchos cambios más como el cambio de nombre de las importaciones QML, en los scripts de diseño de escritorio, en las pantallas de bloqueo personalizadas o en los temas de inicio de sesión SDDM
En resumen, una excelente iniciativa que seguro que los desarrolladores de estas pequeñas (o no tanto) maravillas para nuestro
Más información: KDE Develop
La entrada Guía para portar los temas globales a Plasma 6 se publicó primero en KDE Blog.
#openSUSE Tumbleweed revisión de la semana 9 de 2024
Tumbleweed es una distribución de GNU/Linux «Rolling Release» o de actualización contínua. Aquí puedes estar al tanto de las últimas novedades.

openSUSE Tumbleweed es la versión «rolling release» o de actualización continua de la distribución de GNU/Linux openSUSE.
Hagamos un repaso a las novedades que han llegado hasta los repositorios esta semana.
Y recuerda que puedes estar al tanto de las nuevas publicaciones de snapshots en esta web:
El anuncio original lo puedes leer en el blog de Dominique Leuenberger, publicado bajo licencia CC-by-sa, en este este enlace:
Esta semana se han publicado 6 nuevas snapshots (0223, 0225, 0226, 0227, 0228, y 0229) con cambios tan importantes como estos:
- libjxl 0.10.0 & 0.10.1
- Samba 4.19.5
- Linux kernel 6.7.6
- mdadm 4.3
- Mozilla Firefox 123.0
- chrony 4.5
- openSSH 9.6p1
- fwupd 1.9.14
- exiv2 0.28.2
- Ruby 3.2 ha sido eliminado: esto incluye todas las gemas de ruby y el interpretador de ruby 3.2
Y para próximas actualizaciones, se está trabajando en:
- ImageMagick 7.1.1.29
- openblas 0.3.26
- openjpeg 2.5.1
- KDE Frameworks and Plasma 6
- KDE Gear 24.02.0 – Requiere KDE Frameworks 6
- Systemd 255.3
- dbus-broker
- libxml 2.12.x
- GCC 14
Si quieres estar a la última con software actualizado y probado utiliza openSUSE Tumbleweed la opción rolling release de la distribución de GNU/Linux openSUSE.
Mantente actualizado y ya sabes: Have a lot of fun!!
Enlaces de interés
- ¿Por qué deberías utilizar openSUSE Tumbleweed?
- zypper dup en Tumbleweed hace todo el trabajo al actualizar
- ¿Cual es el mejor comando para actualizar Tumbleweed?
- ¿Qué es el test openQA?
- http://download.opensuse.org/tumbleweed/iso/
- https://es.opensuse.org/Portal:Tumbleweed

——————————–
openSUSE Tumbleweed – Review of the week 2024/09
Dear Tumbleweed users and hackers,
This week was truly crazy for the staging masters — apologies to Ana for flooding you with requests. Many contributors have been busy preparing our packages for RPM 4.20 (which is still at least half a year out – but we preferred to fix things now rather than being under pressure then). When the effort started on Feb 20, we had 2066 spec files that would have failed to build with RPM 4.20. Today, just 10 days later, we have less than 700 – and many requests in the queue to address those.
Of course, that’s not everything that happened this week. We have again delivered six snapshots (0223, 0225, 0226, 0227, 0228, and 0229) with the following changes:
- libjxl 0.10.0 & 0.10.1 (this time the update went without fallout)
- Samba 4.19.5
- Linux kernel 6.7.6
- mdadm 4.3: stricter on naming devices posix compliant
- Mozilla Firefox 123.0
- chrony 4.5
- openSSH 9.6p1
- fwupd 1.9.14
- exiv2 0.28.2
- Ruby 3.2 has been removed: this includes all the ruby gems AND the ruby 3.2 interpreter
The staging lists and backlog are largely filled with the same old topics:
- ImageMagick 7.1.1.29
- Python 3.x fixes for CVE-2023-6597 (TmpDir cleaning)
- openblas 0.3.26: breaks python-networkx, and python-scikit-learn
- openjpeg 2.5.1: breaks ghostscript
- KDE Frameworks and Plasma 6: Staging turns out to be messy
- KDE Gear 24.02.0 – Requires KDE Frameworks 6
- Systemd 255.3
- python 3.9 deprecation: we decided to postpone this a little but, due to the still large fallout from Python 3.12 addition. Removing a Python flavor will require us to rebuild all the Python packages for the new builds to drop the python39 flavor. Too many packages fail to build at this moment.
- dbus-broker: a big step forward; upgrades seem to be an issue that needs to be addressed
- libxml 2.12.x: slow/no progress
- GCC 14: phase 2: use gcc14 as the default compiler
Fiesta de lanzamiento de Plasma 6 de València en Linux Center
Ayer fue el maravilloso y esperado 28 de febrero, dia seleccionado para lanzar la mayor actualización de Software KDE en años. Algunas fiestas de lanzamiento de Plasma 6 se han realizado, como la de Málaga. Otras están pendientes, como la de Barcelona (a la cual todavías estás a tiempo de asistir), y otras se han cristalizado justo esta semana. Me complace anunciar en el blog la fiesta de lanzamiento de Plasma 6 de València, un pequeño evento que vamos a realizar en las instalaciones de Linux Center de la empresa valenciana Slimbook y que servirá para reunir usuarios y desarrolladores, compartir una mañana agradable y ¡comer una paella!
Fiesta de lanzamiento de Plasma 6 de València en Linux Center
La ciudad del Turia, sede de esLibre y Akademy-es 2024 no ha querido dejar pasar esta ocasión y finalmente ha decidido organizar una fiesta de lanzamiento de Plasma 6 para el próximo 9 de marzo. Y es tan tarde porque se ha querido organizar a lo grande, con dos charlas y con una paella para celebrarlo. Si te interesa, date prisa ya que tiene plazas limitadas.
El anuncio es el siguiente:
PLASMA & BASH & PAELLA
Con motivo del lanzamiento de la gran versión de Plasma 6, el escritorio de KDE, te proponemos pasar una jornada diferente.
Pasa la mañana del sábado con linuxeros, aprendiendo sobre la terminal, y conociendo las novedades del escritorio de KDE Plasma versión 6.
Y si lo deseas, quédate a comer GRATIS con nosotros.

De esta forma esta fiesta viene vitaminada ya que tendremos el siguiente programa:
- Taller 1: Bash para surfear Linux «like a PRO» – Por Borja López
- Taller 2: Novedades del mejor escritorio que puedes tener en tu ordenadores: Plasma 6 de KDE – Por Baltasar Ortega (un servidor)
- Comida comunitaria: Paella, cortesía de SLIMBOOK.
¿Qué os parece? Yo voy, por razones evidentes, pero si no fuera como ponente intentaría asistir porque conocer Plasma 6, Bash y Slimbook de una tacada y que además te inviten a comer, no tiene precio. Pero no olvides registrate, porque como hemos dicho, es necesario apuntarse para controlar las plazas.
La información básica es la siguiente:
- Fecha: 9 de marzo
- Hora: 10:00
- Lugar: Linux Center (Grupo Odín) Ronda de la Química s/n Edificio ABM L’Andana, 7ª planta Frente a Parque Técnológico 46980 Paterna, Valencia
- ¿Qué vamos a hacer? Taller, charla, compartir, comer y ver el mundo con un poco más de esperanza.
Enlace para apuntarse y más información: Promo/Events/Parties/KDE 6th Megarelease#Valencia
Fiestas de lanzamiento de Plasma 6
Las fiestas de lanzamiento de Plasma 6, la última versión del entorno de escritorio de KDE, han generado gran expectativa entre la comunidad de usuarios y desarrolladores. Durante estos eventos o fiestas de lanzamiento, se realizan presentaciones y demostraciones de las nuevas funcionalidades de Plasma 6, lo que brinda a los asistentes la oportunidad de explorar de primera mano las innovaciones que ofrece esta actualización.
Tambien es común que se organicen actividades como hackatones, en las que los desarrolladores trabajan en conjunto en la resolución de problemas o en el desarrollo de nuevas ideas para futuras versiones del software.
En otros tiempos se realizaban cada lanzamiento semestral pero el ritmo de la Comunidad KDE es ta elevado que al final se han reservado para ocasiones especiales como es este del próximo 28 de febrero.
Para organizarse un poco, el equipo de Promo de la Comunidad KDE ha dispuesto una página para poder centralizar estos eventos. En sus palabras:
Esta página es para los listados de la fiesta de lanzamiento del 6º Megarelease de KDE. Por favor, siga la siguiente plantilla para facilitar la lectura y mantenerlo ordenado.
El 6º Megarelease de KDE está planeado para el 28 de febrero de 2024, por supuesto no hay necesidad de celebrarlo el mismo día.
Usamos el término «fiesta» pero puede ser lo que quieras, una cena, una reunión en una cafetería, una charla en tu grupo local de Software Libre, ¡sé creativo!
Si tienes preguntas, envía un correo electrónico a aacid@kde.org o kde-promo@kde.org.
En un principio se están organizando varias en Europa y una en el América del Norte, pero seguro que se irán añadiendo más y más cuando se acerque el evento.
Para España, de momento, tenemos dos ciudades donde se están moviendo las cosas, Barcelona y Málaga, y me consta que hay otra que lo está intentando.
Por otro lado, no seas pasivo y anímate a organizarla en tu ciudad si no está en la lista. Son eventos que dejan un gran sabor de boca.
Más información: Promo/Events/Parties/KDE 6th Megarelease
La entrada Fiesta de lanzamiento de Plasma 6 de València en Linux Center se publicó primero en KDE Blog.
Fiesta de lanzamiento de Plasma 6 de València en Linux Center
Ayer fue el maravilloso y esperado 28 de febrero, dia seleccionado para lanzar la mayor actualización de Software KDE en años. Algunas fiestas de lanzamiento de Plasma 6 se han realizado, como la de Málaga. Otras están pendientes, como la de Barcelona (a la cual todavías estás a tiempo de asistir), y otras se han cristalizado justo esta semana. Me complace anunciar en el blog la fiesta de lanzamiento de Plasma 6 de València, un pequeño evento que vamos a realizar en las instalaciones de Linux Center de la empresa valenciana Slimbook y que servirá para reunir usuarios y desarrolladores, compartir una mañana agradable y ¡comer una paella!
Fiesta de lanzamiento de Plasma 6 de València en Linux Center
La ciudad del Turia, sede de esLibre y Akademy-es 2024 no ha querido dejar pasar esta ocasión y finalmente ha decidido organizar una fiesta de lanzamiento de Plasma 6 para el próximo 9 de marzo. Y es tan tarde porque se ha querido organizar a lo grande, con dos charlas y con una paella para celebrarlo. Si te interesa, date prisa ya que tiene plazas limitadas.
El anuncio es el siguiente:
PLASMA & BASH & PAELLA
Con motivo del lanzamiento de la gran versión de Plasma 6, el escritorio de KDE, te proponemos pasar una jornada diferente.
Pasa la mañana del sábado con linuxeros, aprendiendo sobre la terminal, y conociendo las novedades del escritorio de KDE Plasma versión 6.
Y si lo deseas, quédate a comer GRATIS con nosotros.
De esta forma esta fiesta viene vitaminada ya que tendremos el siguiente programa:
- Taller 1: Bash para surfear Linux «like a PRO» – Por Borja López
- Taller 2: Novedades del mejor escritorio que puedes tener en tu ordenadores: Plasma 6 de KDE – Por Baltasar Ortega (un servidor)
- Comida comunitaria: Paella, cortesía de SLIMBOOK.
¿Qué os parece? Yo voy, por razones evidentes, pero si no fuera como ponente intentaría asistir porque conocer Plasma 6, Bash y Slimbook de una tacada y que además te inviten a comer, no tiene precio. Pero no olvides registrate, porque como hemos dicho, es necesario apuntarse para controlar las plazas.
La información básica es la siguiente:
- Fecha: 9 de marzo
- Hora: 10:00
- Lugar: Linux Center (Grupo Odín) Ronda de la Química s/n Edificio ABM L’Andana, 7ª planta Frente a Parque Técnológico 46980 Paterna, Valencia
- ¿Qué vamos a hacer? Taller, charla, compartir, comer y ver el mundo con un poco más de esperanza.
Enlace para apuntarse y más información: Promo/Events/Parties/KDE 6th Megarelease#Valencia
Fiestas de lanzamiento de Plasma 6
Las fiestas de lanzamiento de Plasma 6, la última versión del entorno de escritorio de KDE, han generado gran expectativa entre la comunidad de usuarios y desarrolladores. Durante estos eventos o fiestas de lanzamiento, se realizan presentaciones y demostraciones de las nuevas funcionalidades de Plasma 6, lo que brinda a los asistentes la oportunidad de explorar de primera mano las innovaciones que ofrece esta actualización.
Tambien es común que se organicen actividades como hackatones, en las que los desarrolladores trabajan en conjunto en la resolución de problemas o en el desarrollo de nuevas ideas para futuras versiones del software.
En otros tiempos se realizaban cada lanzamiento semestral pero el ritmo de la Comunidad KDE es ta elevado que al final se han reservado para ocasiones especiales como es este del próximo 28 de febrero.
Para organizarse un poco, el equipo de Promo de la Comunidad KDE ha dispuesto una página para poder centralizar estos eventos. En sus palabras:
Esta página es para los listados de la fiesta de lanzamiento del 6º Megarelease de KDE. Por favor, siga la siguiente plantilla para facilitar la lectura y mantenerlo ordenado.
El 6º Megarelease de KDE está planeado para el 28 de febrero de 2024, por supuesto no hay necesidad de celebrarlo el mismo día.
Usamos el término «fiesta» pero puede ser lo que quieras, una cena, una reunión en una cafetería, una charla en tu grupo local de Software Libre, ¡sé creativo!
Si tienes preguntas, envía un correo electrónico a aacid@kde.org o kde-promo@kde.org.
En un principio se están organizando varias en Europa y una en el América del Norte, pero seguro que se irán añadiendo más y más cuando se acerque el evento.
Para España, de momento, tenemos dos ciudades donde se están moviendo las cosas, Barcelona y Málaga, y me consta que hay otra que lo está intentando.
Por otro lado, no seas pasivo y anímate a organizarla en tu ciudad si no está en la lista. Son eventos que dejan un gran sabor de boca.
Más información: Promo/Events/Parties/KDE 6th Megarelease
La entrada Fiesta de lanzamiento de Plasma 6 de València en Linux Center se publicó primero en KDE Blog.
Guía para portar los plasmoides a Plasma 6
Los grandes cambios de versiones tienen una cara extremadamente positiva ( ya que de lo contrario no se realizarían) y algunos aspecto negativos como puede ser un número de bugs más alto de lo habitual o la pérdida de funcionalidades o plasmoides temporal. Para minimizar esto último el equipo de desarrollo de KDE ha elaborado una guía para portar los plasmoides a Plasma 6 y que pretende facilitar la migración de la gran mayoría de los widgets. En mi opinión, una extraordinaria iniciativa.
Guía para portar los plasmoides a Plasma 6
Como ya sabíamos, la API de Plasma utilizada para crear widgets de escritorio (también conocidos como «applets» o «plasmoides«) ha cambiando para la versión Plasma 6.0. Esto significa que la gran mayoría de los plamoides han dejado de funcionar en nuestros entornos de trabajo.
De hecho, hace unos días que ya están empezando a aparecer en la Store de KDE los primeros plasmoides específicos para el nuevo escritorio Plasma 6 que evidentemente deberá ir creciendo a medida que avance el tiempo hasta alcanzar números de escándolo como lo son los más de 400 que ya tenía Plama 5.

Con la intención de que en poco tiempo tengamos un número alto de plasmoides disponibles para nuestro nuevo entorno de trabajo, el equipo de desarrolladores de ha crado una guía para portar los plasmoides a Plasma 6 que, con todo lujo de detalles, explica la diferencias en la forma de trabajar de Plasma 5 y Plasma 6, así como las nuevas funcionalidades y posibilidades que a partir de ahora van a tener estas pequeñas aplicaciones.
Además, han creado una tabla de equivalencias entre elementos de los plasmoides en cada una de las versiones, lo cual simplificará mucho la migración de plasmoides.

En resumen, una excelente iniciativa que seguro que los desarrolladores de estas pequeñas (o no tanto) maravillas para nuestro
Más información: KDE Develop
La entrada Guía para portar los plasmoides a Plasma 6 se publicó primero en KDE Blog.
KDE Neon ya ha migrado a Plasma 6
Tras anunciar la Comunidad KDE el Megalanzamiento 6 de KDE esta mañana de manera oficial me alegra anunciar que KDE Neon ya ha migrado a Plasma 6… algo que intuía y que nadie se atrevía a decir. Como decía hace unas horas, hoy es un día de celebración ya que es un punto y aparte de unas tecnologías que ya han dado todo de sí y el inicio de una nueva era donde se alcanzarán cotas más altas de excelencia. ¡KDE Rocks!
KDE Neon ya ha migrado a Plasma 6
Creo que han pasado apenas 5 horas si llega desde el anuncio del lanzamiento de Plasma 6 hasta que los chicos de KDE Neon han puesto a disposición de todo el mundo su versión de Plasma 6, tanto para nuevas descargas como para las actualizaciones de los equipos que ya lo tienen en funcionamiento.

En una breve entrada en su blog, los desarrolladores de KDE Neon comentan:
Hoy KDE ha hecho el mayor lanzamiento de su historia, nunca antes en los 25 años de historia del proyecto habíamos anunciado tantas novedades al mismo tiempo, pero trae la base recién renovada para mantener fuertes nuestros cimientos de software.
KDE neon User edition se ha actualizado con KDE Frameworks 6, Plasma 6 y todas las aplicaciones de KDE Gear 24.02. Puedes actualizar a través de Discover o descargar la última versión ISO instalable.
Si sólo quieres probarlo, prueba las imágenes Docker.
Muchas gracias a Carlos, Harald y Jonathan por hacer este lanzamiento de Neon, a los cientos de desarrolladores de KDE por escribir el software y a Augustin y Paul por acoger el sprint de lanzamiento en Málaga.
De esta forma, tras una descarga de unos 500 Mb y unos 15 minutos de actualización, he arrancado mi portátil con el nuevo y flamante software: Plasma6, KDE Gear 24.02 y KDE Frameworks 6.

Y aparece una pantalla de actualización, todo un detalle.

¿Y todo funciona a la perfección?
Evidentemente no todo me funciona bien. He hecho una actualización sonbre un sistema en «vivo», en una distribución que lleva en mi equipo varios años y que, y esto es muy importante, yo suelo probar mucho software y muchos plasmoides, por lo que tengo mucho «bloatware» que he ido introduciendo yo mismo. El resultado es que la mayoría de los plasmoides no me funcionan y que me ocurren cosas raras como que al principio Krunner no se abría, problema que he solucionado simplemente ejecutándolo una vez desde el inicio, o que Gwenview se cierra al intentar recortar una imagen.
No obstante, la mayor parte de las cosas funcionan bien. He quitado el doble click para ejecutar las cosas y creo que mi pantalla se ve mejor que antes, aunque quizás eso sea un efecto de la ilusión que me ha hecho este lanzamiento, y las animaciones son más fluídas. Es más, cosas que antes no funcionaban bien ahora lo hacen, como Falkon y el backend de WordPress del blog, que ahora muestra el SEO como toca.

Y no olvidemos una cosa, todo este trabajo colaborativo es fruto de pequeñas contribuciones de muchas personas repartidas a lo largo de todo el mundo pero el colofón final ha sido realizado por apenas pocas personas, que hace un par de días celebraron el futuro lanzamiento con una cena en Málaga dentro de la serie de Fiestas de Lanzamiento que se están celebrando estos días y que me consta, se alargarán casi un mes. El Software Libre es Software hecho por personas para personas y más que hacer críticas feroces es mucho mejor agradecer y hacer críticas constructivas.

Creo que es un buen momento para recordar la palabras de los desarrolladores de KDE, lo cuales destacan el salto tecnológico que han dado en el día de hoy:
Con Plasma 6, nuestra tecnología ha experimentado dos actualizaciones importantes: una transición a la última versión de nuestra infraestructura de aplicaciones, Qt, y una migración a la moderna plataforma gráfica de Linux, Wayland. Hemos hecho todo lo posible para asegurar que estos cambios sean lo más fluidos e imperceptibles posible para el usuario, por lo que, cuando instale esta actualización, verá el mismo entorno de escritorio familiar que conoce y ama. Pero estas actualizaciones internas benefician la seguridad, la eficiencia y el rendimiento de Plasma, además de mejorar la compatibilidad con el hardware moderno. Así, Plasma proporciona una experiencia de usuario más confiable en general, al tiempo que allana el camino para más mejoras futuras.
Continuaremos proporcionando compatibilidad con la antigua sesión de X11 para los usuarios que prefieran mantenerla por ahora.
KDE Community, 28 de febrero de 2024

Las novedades básicas del megalanzamiento
Hoy no es el día de entrar en detalle, así que simplemente voy a dar unas pinceladas de las novedades básicas del megalanzamiento.
- Nuevo efecto de vista general: se han combinado los efectos de Vista general y Cuadrícula de escritorios en uno, con grandes mejoras en los gestos del panel táctil.
- Color mejorado: Plasma en Wayland ya tiene compatibilidad parcial con alto rango dinámico (HDR).
- Nuevo fondo de escritorio: Árbol escarlata, creado por axo1otl.
- Panel flotante: en Plasma 6, el panel flota de forma predeterminada. Se puede cambiar, por supuesto.
- ¡Nuevos valores predeterminados!
- Brisa refrescada: se ha rediseñado el tema Brisa para que presente un aspecto más moderno, con menos marcos y con un espaciado más consistente.
- Preferencias reorganizadas: se ha mejorado la aplicación de Preferencias para que resulte más amigable y tenga menos páginas anidadas.
- ¡El cubo ha vuelto!
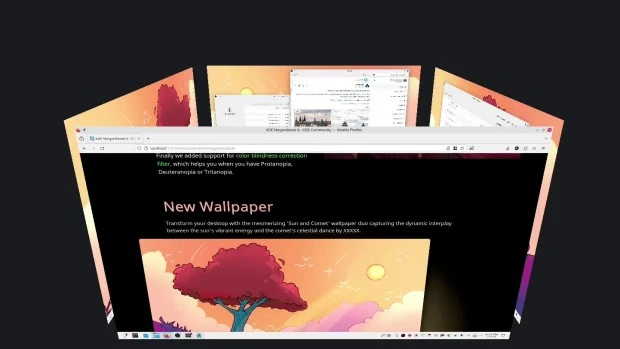
- Mejoras en la búsqueda de Plasma: ahora personalizar el orden de los resultados de la búsqueda y es mucho más rápida.
- Mejoras en Plasma Mobile.
- Cambios en todas las aplicaciones de KDE Gear: Kontact, Kleopatras. Itineray, KDE Edu, KDEnlive, Dolphin, Spectacle, etc.
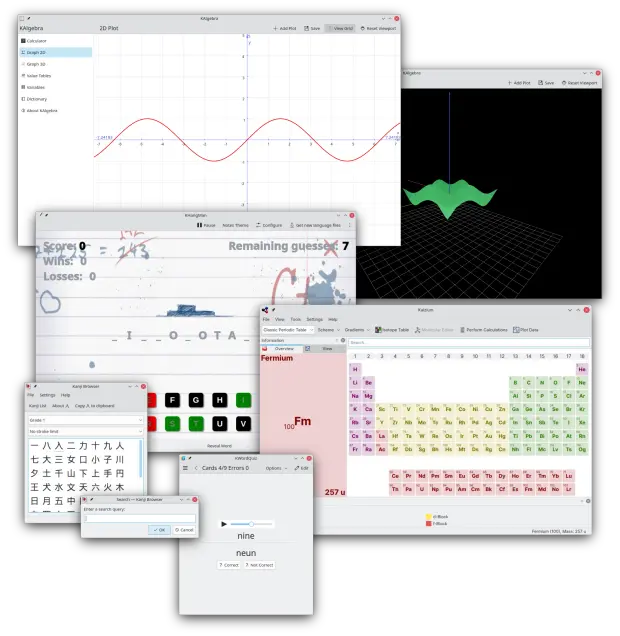
Y esto es una brevísima pincelada… Creo que ahora tengo temas de para el blog de sobra hasta 2025.
Ahora toca esperar que mi distro de cabecera haga la migración… y yo detrás. Y ya he visto que están calentando motores en KDE Neon. ¡Estad atentos!
La entrada KDE Neon ya ha migrado a Plasma 6 se publicó primero en KDE Blog.

Provador de roupa Virtual com IA.

A difusão latente de IA representa uma inovação revolucionária no setor da moda, especialmente na forma como consumidores experimentam e selecionam roupas. Utilizando técnicas avançadas de inteligência artificial, essa tecnologia permite que os usuários provem roupas virtualmente com uma precisão e realismo impressionantes. Ao invés de se basear em simples sobreposições de imagens, a difusão latente analisa as características físicas do usuário, como a forma do corpo, a postura e as dimensões, para ajustar digitalmente as roupas de maneira que reflitam como elas ficariam no mundo real. Isso não só melhora a experiência de compra online, oferecendo uma visualização mais fidedigna do produto, mas também minimiza as taxas de retorno devido a expectativas não atendidas.
Além de beneficiar os consumidores, a difusão latente de IA é uma ferramenta valiosa para os varejistas e designers de moda. Ela permite uma análise detalhada das preferências e tendências de moda, ajustando os estoques e as coleções para atender melhor às demandas dos consumidores. Com a capacidade de simular uma ampla variedade de tecidos, estilos e cortes em diferentes corpos virtuais, os designers podem experimentar e iterar designs rapidamente sem a necessidade de produzir amostras físicas. Essa abordagem não apenas economiza tempo e recursos, mas também abre caminho para uma moda mais sustentável e personalizada, transformando a maneira como interagimos com as roupas em um ambiente digital.
Megalanzamiento 6 de KDE
Puntual como un reloj la Comunidad KDE se alegran en anunciar el Megalanzamiento 6 de KDE. Una noticia que aunque estaba prevista no debe alejarnos que estos grandes avances lo son aún más si pensamos que se hacen de forma comunitaria y dentro de las Comunidad de Software Libre. Hoy es un día de celebración ya que es un punto y aparte de unas tecnologías que ya han dado todo de sí y el inicio de una nueva era donde se alcanzarçan cotas más altas de excelencia. ¡KDE Rocks!
La comunidad de KDE presenta con orgullo Plasma 6, Frameworks 6 y Gear 24.02
Creo que esta sería la entrada más apropiada para hoy. Saber que los meses de trabajo de desarrolladores de software, de traductores, de diseñadores, de promotores, de organizdores de eventos, de ideólogos, de probadores, de mentores, etc. de la Comunidad KDE han llegado a buen puerto, cumpliendo con los plazos previstos y ofreciendo un producto que no tiene nada que envidiar a cualquiera del mundo del Software Libre o Privado me llena de orgullo.
No hay más que ver el pedazo anuncio que se ha trabajado la gente de Promo y que es en realidad un reflejo de todo lo que han trabajo el resto de sus compañeros estos últimos años, justo cuando se dijo que se iba a migrar de tecnología.
Megalanzamiento 6 de KDE
A la cabeza de este megalanzamiento está Plasma 6 ya que en realidad es la parte más visible del proyecto KDE, pero no hay que olvidar que también las aplicaciones KDE (empaquetadas en KDE Gears 24.02) y el motor de todos (KDE Frameworks) han dado el salto tecnológico que se debía dar.
De esta forma, en palabras de los desarrolladores de KDE (que engloba todos los perfiles que antes he comentado) destacan dicho salto:
Con Plasma 6, nuestra tecnología ha experimentado dos actualizaciones importantes: una transición a la última versión de nuestra infraestructura de aplicaciones, Qt, y una migración a la moderna plataforma gráfica de Linux, Wayland. Hemos hecho todo lo posible para asegurar que estos cambios sean lo más fluidos e imperceptibles posible para el usuario, por lo que, cuando instale esta actualización, verá el mismo entorno de escritorio familiar que conoce y ama. Pero estas actualizaciones internas benefician la seguridad, la eficiencia y el rendimiento de Plasma, además de mejorar la compatibilidad con el hardware moderno. Así, Plasma proporciona una experiencia de usuario más confiable en general, al tiempo que allana el camino para más mejoras futuras.
Continuaremos proporcionando compatibilidad con la antigua sesión de X11 para los usuarios que prefieran mantenerla por ahora.
KDE Community, 28 de febrero de 2024
Las novedades básicas del megalanzamiento
Hoy no es el día de entrar en detalle, así que simplemente voy a dar unas pinceladas de las novedades básicas del megalanzamiento.
- Nuevo efecto de vista general: se han combinado los efectos de Vista general y Cuadrícula de escritorios en uno, con grandes mejoras en los gestos del panel táctil.
- Color mejorado: Plasma en Wayland ya tiene compatibilidad parcial con alto rango dinámico (HDR).
- Nuevo fondo de escritorio: Árbol escarlata, creado por axo1otl.
- Panel flotante: en Plasma 6, el panel flota de forma predeterminada. Se puede cambiar, por supuesto.
- ¡Nuevos valores predeterminados!
- Brisa refrescada: se ha rediseñado el tema Brisa para que presente un aspecto más moderno, con menos marcos y con un espaciado más consistente.
- Preferencias reorganizadas: se ha mejorado la aplicación de Preferencias para que resulte más amigable y tenga menos páginas anidadas.
- ¡El cubo ha vuelto!
- Mejoras en la búsqueda de Plasma: ahora personalizar el orden de los resultados de la búsqueda y es mucho más rápida.
- Mejoras en Plasma Mobile.
- Cambios en todas las aplicaciones de KDE Gear: Kontact, Kleopatras. Itineray, KDE Edu, KDEnlive, Dolphin, Spectacle, etc.
Y esto es una brevísima pincelada… Creo que ahora tengo temas de para el blog de sobra hasta 2025.
Ahora toca esperar que mi distro de cabecera haga la migración… y yo detrás. Y ya he visto que están calentando motores en KDE Neon. ¡Estad atentos!
La entrada Megalanzamiento 6 de KDE se publicó primero en KDE Blog.