
 Member
Member DimStar
DimStarTumbleweed – Review of the weeks 2024/28 & 29 & 30
Dear Tumbleweed users and hackers,
As I informed you in my last ‘weekly review’ (end of week 27 – so three weeks ago), I enjoyed some vacation time of my own and used it to recharge by entirely stepping away from computers. Of course, you did not notice anything, as Ana was there to steer the big Tumbleweed ship around and snapshots have been delivered constantly. for completeness, I will also include things that happened during my absence to give more continuity to the reports.
During the weeks 28 – 30, 11 snapshots could be published (0705, 0708, 0709, 0710, 0711, 0712, 0714, 0715, 0716, 0722, 0724, and 0725). There was a larger gap between 0716 and 0722, as openQA detected some issues on Mesa and sdbootutil,. As we did not want you to suffer through those problems, snapshots were held back and the issues addressed.
The most relevant changes included in those snapshots were:
- Mesa 24.1.3
- Mozilla Firefox 127.0.2 & 128.0
- KDE Gear 24.05.2
- PHP 8.3.9
- Apache 2.4.61
- cmake 3.30.0 & 3.30.1
- NetworkManager 1.48.4
- Ruby 3.3.4
- SELinux 3.7
- Linux kernel 6.9.9
- KDE Frameworks 6.4.0
- KDE Plasma 6.1.3
- LibreOffice 24.2.5.2
- trasnactional-update 4.7.0: soft-reboot feature not yet enabled, as it takes a bit more time to get QA adjusted for this during the summer break
- Agama installer medium is generated as part of the snapshot. This is not yet the default installer, but you are invited to check out progress. ISOs are published in https://download.opensuse.org/tumbleweed/appliances/iso/
The staging projects are currently nicely filled; some things are passing tests already, and others will take a bit more time. But you deserve to know what’s brewing, namely:
- gnutls 3.8.6
- Qemu 9.0.2
- Lua 5.4.7
- Systemd 256.4
- AppArmor 4.0.2
- Linux kernel 6.10.1
- cURL 8.9.0: breaks test suite of cmake
- ffmpeg-7 as system default (currently ffmpeg-6). A big bunch of packages is still stuck on ffmpeg-4.
- transactional-update: enable soft reboot; see https://microos.opensuse.org/blog/2024-06-13-soft-reboot/
- dbus-broker: some networking issue after upgrades left to work out
- GCC 14: phase 2: use gcc14 as the default compiler – lots of help needed: https://build.opensuse.org/project/show/openSUSE:Factory:Staging:Gcc7

Pre-RC3 Image Released for Aeon Desktop
An experimental “Pre-RC3” image for the Aeon Desktop has been published and testers are encouraged to try out the final prototype before it becomes the official Release Candidate 3 (RC3). The new image can be downloaded from the openSUSE development repository.
This prototype, which has been submitted to openSUSE Factory, introduces some significant changes and improvements. Notably, the dd backend in the tik installer has been replaced with a new systemd-repart backend. This change allows for the installation of Aeon with Full Disk Encryption that enhances the security features of the operating system.
Existing users of Aeon RC2 and earlier versions will need to perform a reinstall to take advantage of the new features destined for RC3. Due to the fundamental changes in partition layout necessary for the new encryption features, an in-place upgrade from RC2 is not feasible without risking data integrity, according to a post on the new Aeon Desktop subreddit. Users can utilize Aeon’s reinstall feature, which facilitates the backup and restoration of user data as long as a sufficiently large USB stick is used.
Users installing the prototype image may encounter some packages from the OBS devel project. These can be removed by running transactional-update --interactive dup and selecting solutions that replace devel:microos packages with official ones.
Testers are encouraged to provide feedback and report any issues encountered during the testing phase on the Aeon Desktop bug report page.
Next Steps
If the prototype is accepted into Factory and becomes RC3, the development of Aeon will be in its final stages before an official release. RC3 will serve as the basis for writing openQA tests for Aeon, which are crucial for ensuring the desktop’s stability and functionality.
There is a possibility of an RC4, which aims to streamline the installer process by embedding the full Aeon install within the installer image, potentially reducing the download size by 50 percent. If this approach is not feasible in the short term, it may be revisited post-release.
Full Disk Encryption is set up in one of two modes: Default or Fallback. Get more info about that in the Aeon Desktop Introduces Comprehensive Full Disk Encryption article.
Los iconos Breeze de KDE
He hablado a lo largo de muchas entradas de múltiples iconos para Plasma pero poco de los oficiales, los iconos Breeze de KDE. Es hora de enmendar este error ya que hace poco que he descubierto donde se encuentran alojados en la web, con lo que podemos ver las mejoras de este conjunto de avatares al tiempo que podemos utilizar un buscador para tenerlos localizados.
Los iconos Breeze de KDE
Cuando se dio el salto de KDE 4 a Plasma 5, que es cuando de verdad se empezó a hacer hincapié en que el escritorio se llamaba Plasma, se creó el llamado Visual Design Group (VDG): un grupo de diseñadores encargados de darle un mejor aspecto visual al entorno de trabajo.
Ellos no solo se encargaron de crear iconos o fondos de pantalla sino que además crearon la guía de estilo que debería seguir las aplicaciones, plasmoides y resto de elementos gráficos para que todo fuera armonioso en lo que se llamó el KIG: KDE Interface Guide.
Es evidente que uno de los pilares fundamentales fuero los iconos, que sus diseñadores, que pidieron colaboración en su tiempo para crearlos, definen como:
Breeze-icons es un tema de iconos compatible con freedesktop.org. Está desarrollado por la Comunidad KDE como parte de KDE Frameworks 5 y se utiliza por defecto en KDE Plasma 5 y Aplicaciones KDE.
Como no podía ser de otra forma, estos iconos los tienes disponible en tu ordenador con Plasma, pero nunca está de más tenerlos en otra vía por si te interesa utilizar alguno y no te encuentras en tu dispositivo.
Es por ello que hoy os presento la web https://develop.kde.org/frameworks/breeze-icons, una sencilla web donde te explican los iconos breeze y, además, te ofrece un buscador integrado para poder buscar el icono, mymetype u otro elemento gráfico relacionado con el aspeto icónico de Plasma.
Además, esto puede ser útil si eres un diseñador y quieres crear un conjunto de iconos comparable a Breeze o simplemente buscar inspiración para una aplicación particular.

Personalmente, me encantan los iconos Breeze. Aunque en muchas ocasiones los sustituyo para ir probando cosas nuevas siempre vuelvo a ellos, y lo más importante, no siento nunca la necesidad de reemplazarlos.
Y a vosotros, ¿os gustan los iconos por defecto de KDE o tenéis un tema que rápidamente los reemplaza? Decidme en comentarios.
La entrada Los iconos Breeze de KDE se publicó primero en KDE Blog.
Disponible la Beta del reproductor de música Amarok de KDE
Se ha publicado la versión beta de Amarok 3.1 el mítico reproductor de música de la comunidad KDE

Se ha anunciado la versión Beta de Amarok 3.1, que traerá nuevas funcionalidades y mejoras en el código. Veamos más detalles.
Si echamos un vistazo en el registro de cambios de la versión 3.0.81 de Amarok, que es la versión Beta de la próxima 3.1, además de varias correcciones de errores, habrá algunas características nuevas incluidas en la próxima versión, aunque no muchas.
Sin embargo, ha habido una gran cantidad de trabajo de preparación de la compatibilidad de Qt6. Es probable que la versión 3.1.0 se lance a principios de agosto, y toda la ayuda para detectar cualquier regresión durante este período es muy apreciada (todavía no se podrá compilar un Qt6 Amarok con la versión 3.1, pero tal vez con la eventual 3.2).
Nuevas funcionalidades
- Complemento de Last.fm actualizado para usar el método de autenticación basado en token y para notificar usuario de errores de clave de sesión
- Se vuelve a incluir el applet de Last.fm de contexto de artistas similares: una nueva versión de Amarok 3
- Recordar el proveedor de destino anterior al guardar la lista de reproducción
Cambios
- Amarok ahora depende de KDE Frameworks 5.89.
- Limpieza de código no utilizado y varios cambios que mejoran la compatibilidad con Qt6 pero no debería afectar a la funcionalidad.
- Eliminar las integraciones de openDesktop.org antiguas abandonadas de diálogo Acerca de. Esto también quita la dependencia del framework Attica.
- Deshabilitada la reproducción sin interrupciones si ReplayGain está activo y la siguiente pista está no del mismo álbum, para evitar picos de volumen debido a la demora en la aplicación de ReplayGain
Corrección de errores
- Corregido guardar y restaurar la cola de la lista de reproducción al salir / reiniciar
- Arreglar el reordenamiento del icono de la bandeja del sistema
- Arreglar el botón ‘guardar lista de reproducción’ en los controles de la lista de reproducción
- Correcciones varias para guardar y cargar varios formatos de archivos de listas de reproducción, lo que también resulta en una mejor compatibilidad con otros programas informáticos
- No mostrar sugerencias visuales falsas de reordenación en una lista de reproducción ordenada
- Arreglar múltiples instancias de servicios web que aparecen en el menú de Internet después de guardar configuración del complemento.
- Mostrar también las acciones del proveedor de podcasts para categorías de podcasts no vacías
- Se corrigieron los bloqueos relacionados con los subprocesos en CoverManager
Redescubre tu música con Amarok, redescubre Amarok.


Mistral Large 2: Outra super nova IA!

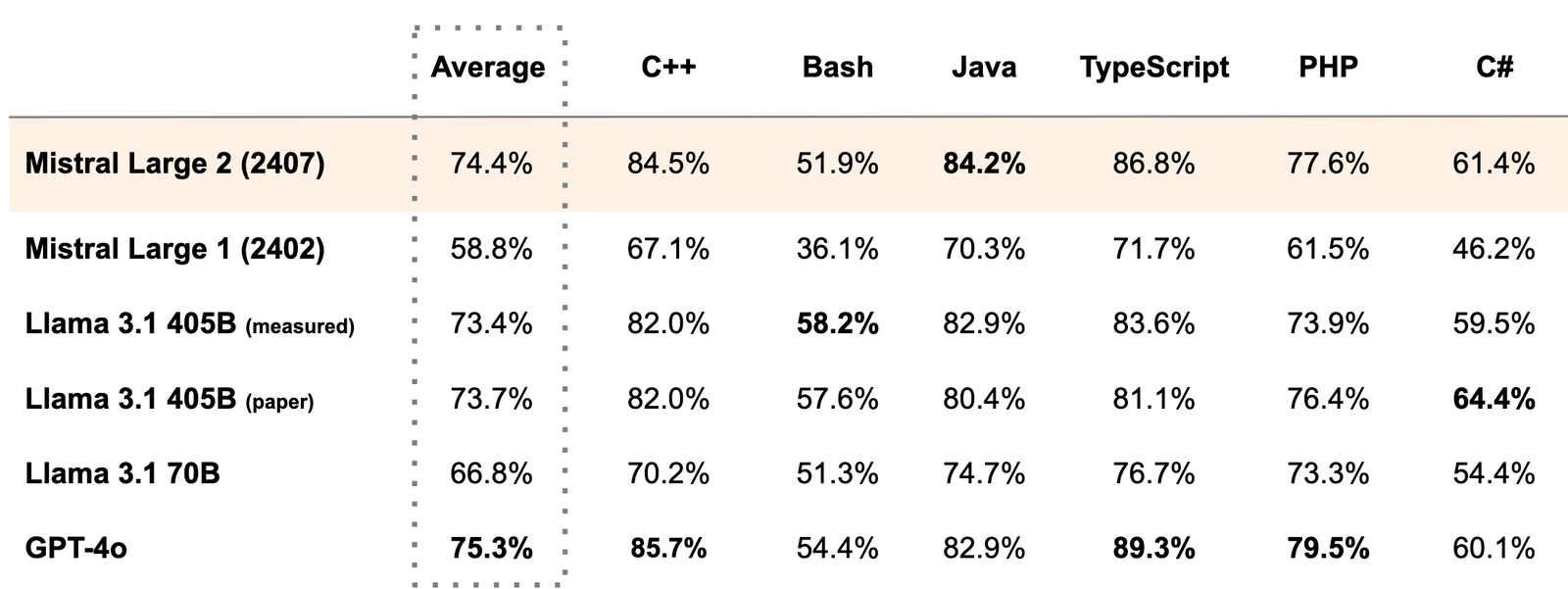
Mistral AI lançou o Mistral Large 2, a versão mais recente do seu principal modelo de linguagem, que apresenta melhorias significativas na geração de código, matemática e capacidades multilíngues. O novo modelo, com 123 bilhões de parâmetros, possui uma janela de contexto de 128.000 tokens e visa desafiar os líderes do setor em desempenho e eficiência.
O Mistral Large 2 mostra desempenho impressionante em vários benchmarks. Em tarefas de geração de código, como HumanEval e MultiPL-E, ele supera o Llama 3.1 405B (lançado ontem pela Meta) e fica apenas abaixo do GPT-4. Em matemática, particularmente no benchmark MATH (resolução de problemas sem raciocínio em cadeia), o Mistral Large 2 é segundo apenas para o GPT-4o.

As capacidades multilíngues do modelo também receberam um impulso substancial. No benchmark multilíngue MMLU, Mistral Large 2 supera o Llama 3.1 70B base em média por 6,3% em nove idiomas e tem desempenho equiparável ao Llama 3 405B.
Apesar do seu grande tamanho, a Mistral AI projetou o modelo para inferência em um único nó, enfatizando a capacidade de processamento para aplicações de longo contexto. A empresa disponibilizou o Mistral Large 2 em sua plataforma, la Plateforme, e lançou os pesos para o modelo instrutivo no HuggingFace para fins de pesquisa.

Arthur Mensch, CEO da Mistral AI, afirmou: “O Mistral Large 2 estabelece uma nova fronteira em termos de relação desempenho-custo em métricas de avaliação.” Ele destacou que a versão pré-treinada alcança uma precisão de 84,0% no MMLU, estabelecendo um novo ponto na frente de Pareto desempenho/custo para modelos abertos.
O modelo passou por um treinamento extensivo em código-fonte, aproveitando a experiência da Mistral AI com modelos anteriores focados em código. Esse enfoque resultou em um desempenho comparável ao de modelos líderes como GPT-4, Claude 3 Opus e Llama 3 405B em tarefas de codificação.
A Mistral AI também se concentrou em aprimorar as capacidades de raciocínio do modelo e reduzir as alucinações. A empresa relata um desempenho aprimorado em benchmarks matemáticos, refletindo esses esforços.
Além disso, o Mistral Large 2 foi treinado para se destacar em tarefas de seguimento de instruções e conversação, com melhorias particulares no manejo de instruções precisas e conversas longas e multi-turnos.
O lançamento do Mistral Large 2 logo após o Llama 3.1 sinaliza uma competição intensificada no espaço dos modelos de linguagem de IA. Seu desempenho em áreas especializadas como geração de código e matemática, juntamente com um forte suporte multilíngue, posiciona-o como uma opção formidável tanto para pesquisa quanto para aplicações comerciais potenciais.
À medida que os modelos de IA continuam a crescer em tamanho e capacidade, o foco da Mistral AI em eficiência e inferência em um único nó destaca uma tendência importante no equilíbrio entre desempenho e considerações práticas de implantação.
¿Es Plasma Mobile utilizable en 2024?
Me sigue salvando esta semana complicada el nuevo fichaje de KDE España: Ivan Gregori, En esta ocasión con el artículo que en realidad complementa la entrada de ayer: «¿Es Plasma Mobile utilizable en 2024?». Bienvenidos pues a la versión redactada del vídeo donde Ivan comentaba su experiencia con este software.
¿Es Plasma Mobile utilizable en 2024?
Tras ya varios años de experiencia con GNU/Linux, tenía muchas ganas de comprobar con mis propios sentidos el estado del arte en el mundo de los teléfonos inteligentes.
Enseguida me acordé que mi hermano fue usuario de un Pocophone F1 de Xiaomi, y no me lo pensé dos veces: esta era mi oportunidad de enfrentarme por primera vez a la liberación de un teléfono inteligente con software libre, y ya de paso, evitar un deshecho (al menos durante un tiempo).
Como usuario acérrimo de KDE Plasma en el escritorio, tenía un gran interés en ver hasta dónde había llegado KDE en la experiencia móvil, ya que llevaba tiempo conociendo proyectos muy interesantes de convergencia, como Merkuro. Así que, había que instalarle Plasma Mobile sí o sí.

Por cierto, Xiaomi no pone nada fácil el instalar cualquier cosa en sus teléfonos, pero eso es materia para otro debate…
Cuando por fin conseguí desbloquear el dispositivo, instalar un sistema operativo fue bastante sencillo gracias a la titánica labor de la gente de postmarketOS, un proyecto comunitario magnífico que pretende rescatar móviles de la muerte privativa, por desgracia siempre prematura.
Realicé un vídeo contando mi experiencia con Plasma Mobile, que os lo dejo aquí:
(también disponible en YouTube para aquellos que aún no se hayan pasado al fediverso)
En muy resumidas cuentas, los puntos claves de mi experiencia son:
Convergencia
Si eres usuario de KDE Plasma, Plasma Mobile te va a gustar bastante de entrada: utiliza el mismo código base que KDE Plasma para escritorio, lo que permite una experiencia unificada entre dispositivos: la llamada «convergencia». Sin embargo, esta convergencia aún no está completa, por desgracia. Algunas configuraciones básicas no están adaptadas al móvil, y ciertos menús se vuelven confusos o incluso inutilizables…
Estoy seguro que esto será mejorado en los próximos meses, pero obviamente me obliga a advertir de que… probablemente Plasma Mobile no debería ser tu escritorio en el teléfono a día de hoy.
Funcionalidades básicas
Las llamadas funcionaron, y las aplicaciones de teléfono y SMS están bastante bien, aunque definitivamente hay que mejorar la gestión de la salida de audio por el auricular superior para las llamadas.
La barra de notificaciones y controles funciona bastante bien, de hecho… me han gustado más incluso que las alternativas ofrecidas por Android y, por supuesto iOS, que (en mi humilde opinión) aún tiene recorrido para alcanzar a Android, y aparentemente ahora a Plasma Mobile.

Aplicaciones
Las aplicaciones preinstaladas con Plasma Mobile, como Angelfish (navegador web) y la terminal basada en Konsole funcionan sorprendentemente bien. Hacer un navegador web funcional y rápido no es tarea sencilla, y sin embargo Angelfish no tiene casi nada que envidiarle a Firefox en Android, por ejemplo.

Sin embargo, otras aplicaciones clave, como el calendario de Merkuro, no funcionan correctamente, mostrando problemas críticos en la interfaz de usuario. De nuevo, cositas a mejorar, que estoy seguro que serán enmendadas. Hay que tener en cuenta que Merkuro es una suite aún en su infancia, pero me gusta mucho su proyección a futuro.
También he percibido una falta a la hora de poder desinstalar/cerrar aplicaciones desde el menú o el escritorio; así como poder borrar su cache, y demás «meta-gestiones». Es posible que aquí haya que estandarizar un poco mejor cómo Linux gestiona estas cosas… es algo bastante más complicado de lo que parece, al menos es la sensación que tengo como usuario, que alguna vez me toca ir a la carpeta de ~/.cache a borrar cosas manualmente… ser capaz de seleccionar una aplicación y explícitamente borrar su cache o desinstalarla vendría muy bien tanto para móviles como escritorio, en mi opinión personal.
Conclusiones
Como ya he dicho, aunque hay cosas que me gustaron muchísimo de la experiencia con Plasma Mobile… otras claramente me echaron para atrás, al menos por ahora. Si estáis interesados, es bastante probable que próximamente estudiemos algunas alternativas a Plasma Mobile, como puede ser Phosh, a ver qué tal avanzan otros proyectos similares.
Enlaces de interés
- Kirigami, librería de desarrollo de aplicaciones convergentes, perfecta para Plasma Mobile.
- PeerTube de Ivan GJ
- YouTube de Ivan GJ
La entrada ¿Es Plasma Mobile utilizable en 2024? se publicó primero en KDE Blog.
Why it is useful to set the version number in the syslog-ng configuration
The syslog-ng configuration starts with a version number declaration. Up until recently, if it was missing, syslog-ng did not start. With syslog-ng 4.8, this is changing.
From this blog, you can learn why version information is useful, what workaround you can use if you do not want to edit your syslog-ng configuration on each update, and what changed in version 4.8.
You can read the rest of my blog at https://www.syslog-ng.com/community/b/blog/posts/why-it-is-useful-to-set-the-version-number-in-the-syslog-ng-configuration
syslog-ng logo
¿Plasma Mobile utilizable en 2024? #postmarketOS #KDE #PlasmaMobile #review
Repito entradilla: Los meses de junio y principios de julio son bastante estresantes, así que tengo varios artículos pendientes de Akademy-es 2024 de València Eslibre Edition, pero tengo poco tiempo así que me aprovecho del trabajo de de Ivan Gregori, reciente miembro de KDE España, titulado «¿Plasma Mobile utilizable en 2024? #postmarketOS #KDE #PlasmaMobile #review» donde analiza el estado del proyecto.
¿Plasma Mobile utilizable en 2024? #postmarketOS #KDE #PlasmaMobile #review
Quizás os suene el nombre de Ivan Gregori ya que hace poco realizó un excelente artículo invitado en el blog titulado «¿En qué debería KDE trabajar en los próximos 2 años? ¡Participa!» en el que explicaba el proceso democrático con el que se elijen los objetivos de KDE
En esta ocasión aparece como creador de contenido de Youtube, algo de lo que parece que tiene experiencia ya que lo hace bastante bien, así que me dejo de rollos y os invito a ver ya su vídeo.

En palabras de su Ivan GJ,:
Vamos a investigar si Plasma Mobile es una opción viable en 2024, utilizando un Pocophone F1. Después de cuatro años de experiencia con GNU/Linux en mis ordenadores personales y de trabajo, he decidido dar el salto e intentar instalar este sistema operativo en un móvil. Acompáñame mientras revisamos las características, fortalezas y debilidades de Plasma Mobile (por ahora), así como su convergencia con KDE Plasma en el escritorio.
Por cierto, aunque el vídeo está en Youtube, yo os dejo el que está alojado en su canal del Fediverso.
Mastodon: https://mastodon.social/@ivangj
Peertube: https://fediverse.tv/a/ivangj/
Web: https://ivangj.xyz/
La entrada ¿Plasma Mobile utilizable en 2024? #postmarketOS #KDE #PlasmaMobile #review se publicó primero en KDE Blog.
Mistral NeMo: Mais uma IA!
Hoje, vamos dar uma olhada em um novo competidor que está causando impacto: o Nemo da Mistral AI. Este poderoso modelo de 12 bilhões de parâmetros está chamando a atenção com suas capacidades impressionantes e seu potencial para revolucionar a interação com a IA.

O Nemo não é apenas um rosto bonito no mundo dos LLMs. Ele é construído com uma combinação única de características que o destacam:
- Arquitetura de ponta: O Nemo possui habilidades impressionantes de raciocínio, conhecimento mundial e habilidades de codificação, especialmente considerando seu tamanho.
- Colaboração com a Nvidia: Esta parceria resultou em um modelo que se destaca na inferência eficiente, mesmo com quantização, permitindo uma operação mais rápida e suave.
- Versatilidade linguística: O Nemo fala fluentemente várias línguas, suportando diversos idiomas com facilidade.
- Tokenizador avançado: Conheça o Tekken, o tokenizador eficiente que ajuda o Nemo a comprimir textos de forma mais eficaz, especialmente para codificação.
- Ajuste fino de instruções: Este modelo é especialista em seguir instruções precisas, lidando com conversas complexas e gerando códigos de alta qualidade.
Benchmarks: O desempenho do Nemo em vários benchmarks mostra um quadro promissor:

• HellaSwag: O Nemo marca 83,5, superando o Llama 3 e o Gemma 2.
• Winograd Schema Challenge: O Nemo alcança uma pontuação de 76,8.
• NaturalQuestions: O Nemo marca 31,2.
• TriviaQA: O Nemo obtém respeitáveis 73,8.
• MMLU: O Nemo marca 68.
• OpenBookQA: O Nemo marca 60,6.
• CommonSenseQA: O Nemo marca 70,4.
• TruthfulQA: O Nemo marca 50,3.
Embora esses benchmarks sejam impressionantes, é importante notar que faltam comparações com modelos líderes como Quen 2 e DeepSeek V2.
Vamos direto ao ponto: Como o Nemo realmente se sai? Os benchmarks mostram resultados seriamente impressionantes:
• Superando a concorrência: O Nemo supera seus rivais como Llama 3 e Gemma 2 em vários métricos, demonstrando suas capacidades impressionantes.
• Potência de raciocínio: Ele constantemente se sai bem em tarefas de raciocínio, provando sua habilidade de pensar criticamente e resolver problemas.
• Campeão na geração de código: O Nemo se destaca na geração de código, até mesmo gerando código funcional para tarefas complexas como um jogo da cobrinha em Python.
O futuro do Nemo é brilhante. Ele ainda está em seus estágios iniciais, mas com o desenvolvimento contínuo e as contribuições da comunidade, tem o potencial de se tornar um dos modelos de linguagem de IA mais influentes do mundo.
Low Code Platform, Revolucionando el Desarrollo Empresarial
En ocasiones empezar a programar es algo complicado. En ocasiones explicar programación puede ser laborioso. En ocasiones crear un proyecto desde cero requiere mucho tiempo. Para estos casos, y muchos más, aparecen proyectos como App Inventor o Scratch Online, pero nunca viene mal tener más alternativas como la que os presento hoy: Low Code Plaform, una plataforma privada pero que permite a los desarrolladores crear Software Libre ya que la lincencia la eligen ellos.
¿Qué es una Low Code Platform?
En el mundo empresarial actual, la rapidez y la eficiencia son esenciales para mantener una ventaja competitiva. Las empresas buscan constantemente formas de optimizar sus procesos y reducir el tiempo de desarrollo de aplicaciones. Es aquí donde entra en juego el concepto de low code platform. En este artículo, exploraremos qué es una low code platform, sus beneficios y cómo está transformando el panorama del desarrollo de software.
Una low code platform es un entorno de desarrollo que permite la creación de aplicaciones de software con una mínima cantidad de codificación manual. En lugar de escribir líneas y líneas de código, los desarrolladores pueden utilizar interfaces gráficas y configuraciones predefinidas para diseñar y construir aplicaciones. Este enfoque democratiza el desarrollo, permitiendo que personas con poca o ninguna experiencia en programación puedan crear aplicaciones funcionales.

Beneficios de Utilizar una Low Code Platform
Uno de los principales beneficios de una low code platform es la velocidad. Al reducir significativamente la cantidad de codificación manual, los desarrolladores pueden crear aplicaciones mucho más rápido. Esto es especialmente útil para empresas que necesitan adaptarse rápidamente a las cambiantes demandas del mercado.
Además, las plataformas low code mejoran la colaboración entre equipos. Al ser más accesibles, permiten que los equipos de negocio y TI trabajen juntos de manera más eficiente. Los usuarios de negocio pueden participar en el proceso de desarrollo, asegurando que las aplicaciones cumplen con los requisitos específicos y reduciendo el riesgo de malentendidos.
Otro beneficio clave es la reducción de costos. La disminución del tiempo de desarrollo se traduce en menos horas de trabajo, lo que puede reducir considerablemente los costos asociados con la creación de software. Además, al no requerir conocimientos avanzados de programación, las empresas pueden ahorrar en formación y contratar personal con diferentes niveles de habilidad.
Impacto en el Desarrollo Empresarial
Las low code platforms están cambiando la forma en que las empresas abordan el desarrollo de software. Al permitir un desarrollo más rápido y accesible, estas plataformas están impulsando la innovación y la eficiencia operativa. Por ejemplo, las empresas pueden lanzar nuevas aplicaciones o actualizar las existentes con mayor rapidez, lo que les permite responder más ágilmente a las necesidades del mercado.
Además, estas plataformas facilitan la integración con otras tecnologías y sistemas empresariales. Esto es crucial en un entorno donde las empresas dependen cada vez más de diversas herramientas digitales para gestionar sus operaciones. Con una plataforma low code, las empresas pueden crear soluciones personalizadas que se integren perfectamente con sus sistemas existentes, mejorando la coherencia y la eficiencia.
Implementación de una Low Code Platform
Implementar una low code platform en una empresa puede parecer un desafío, pero con una planificación adecuada, los beneficios superan con creces los esfuerzos iniciales. El primer paso es identificar las necesidades y objetivos específicos de la empresa. ¿Qué tipos de aplicaciones se necesitan? ¿Qué procesos se pueden optimizar?
Una vez identificadas las necesidades, es crucial seleccionar la plataforma low code adecuada. Existen varias opciones en el mercado, cada una con sus propias características y beneficios. Es importante elegir una plataforma que se alinee con los objetivos y las capacidades técnicas de la empresa.
La implementación también requiere la formación adecuada del personal. Aunque las low code platforms son más accesibles que los entornos de desarrollo tradicionales, sigue siendo esencial que los empleados comprendan cómo utilizar la plataforma de manera efectiva. Proporcionar formación y recursos de apoyo puede facilitar una transición suave y maximizar los beneficios de la plataforma.
Casos de Uso de Low Code Platforms
Las aplicaciones de las low code platforms son variadas y abarcan múltiples sectores. Por ejemplo, en el sector financiero, estas plataformas pueden utilizarse para desarrollar aplicaciones de gestión de riesgos o herramientas de análisis de datos. En el ámbito de la salud, se pueden crear aplicaciones para gestionar los historiales médicos de los pacientes y optimizar los procesos administrativos.

En el sector de retail, las plataformas low code permiten la creación rápida de aplicaciones de gestión de inventarios o sistemas de punto de venta personalizados. Además, las empresas de servicios pueden utilizar estas plataformas para desarrollar aplicaciones de atención al cliente y gestión de proyectos, mejorando la eficiencia y la satisfacción del cliente.
El Futuro de las Low Code Platforms
El futuro de las low code platforms es prometedor. Con la creciente demanda de soluciones rápidas y eficientes, estas plataformas están bien posicionadas para jugar un papel crucial en el desarrollo de software. A medida que la tecnología avanza, es probable que las low code platforms se vuelvan aún más potentes y versátiles, integrando tecnologías emergentes como la inteligencia artificial y el aprendizaje automático.
Además, la tendencia hacia la digitalización y la transformación digital en las empresas impulsará aún más la adopción de estas plataformas. Las organizaciones buscarán cada vez más formas de optimizar sus operaciones y mejorar su capacidad de respuesta, y las low code platforms ofrecerán una solución efectiva para lograr estos objetivos.

Conclusión
En conclusión, una low code platform es una herramienta poderosa que está revolucionando el desarrollo de software empresarial. Sus beneficios, que incluyen mayor velocidad, reducción de costos y mejora de la colaboración, la convierten en una opción atractiva para las empresas que buscan mantenerse competitivas en un mercado en constante cambio. Con la capacidad de crear aplicaciones rápidamente y adaptarse a las necesidades específicas de la empresa, una plataforma low code es una inversión que puede ofrecer un retorno significativo. ¡Es hora de considerar cómo una low code platform puede transformar tu negocio y llevarlo al siguiente nivel!
La entrada Low Code Platform, Revolucionando el Desarrollo Empresarial se publicó primero en KDE Blog.