
 Member
Member Victorhck
VictorhckAtajos de teclado con la tecla «meta» de Plasma de KDE
Vamos a repasar unos cuantos atajos de teclado que utilizan la tecla «meta» en Plasma de KDE

El escritorio Plasma de la comunidad KDE para sistemas *NIX sigue siendo el escritorio más configurable que existe. Y a pesar de usarlo desde hace ya unos cuantos años, sigue deparándome sorpresas.
En este caso, vamos a hacer un repaso de algunos atajos de teclado que utilizan la tecla «meta» que quizás no conocías y que puede que incorpores a tu «arsenal» a la hora de usar tu equipo para ser más rápido y trabajar menos.
Este artículo surgió de un comentario del amigo Krovikan74 (un habitual del blog), que me pareció interesante y con la entidad propia, para no quedarse en un comentario, si no aprovechar lo que compartió para escribir esta entrada. Así que gracias por tu aporte.
Estos atajos de teclado que se comentan, funcionan si no has cambiado tu ninguna configuración que viene predeterminada. Vamos al lío:
-
Meta→ La tecla por sí sola, abre el lanzador de aplicaciones -
Meta + .→ Abre el selector de emojis de Plasma -
Meta + G→Abre un selector de los escritorios virtuales -
Meta + L→ (Lock) Bloquea la sesión y requiere la contraseña para volver a acceder -
Meta + W→ Selector de ventanas dentro del escritorio actual -
Meta + E→ (Explorer) Abre Dolphin, el explorador de archivos de Plasma -
Meta + R→ (Record) Graba la pantalla con espectacle (aunque me da un error) -
Meta + P→ Muestra opciones sobre a dónde redirigir la imagen de la pantalla -
Meta + <números>→ Remito al artículo de RGB, ya que yo no lo tengo así configurado -
Meta + Alt + <flechas>→ Cambia entre las ventanas existentes en el escritorio -
Meta + <flechas arriba/abajo>→ Mueve la ventana de la aplicación a la parte superior/inferior de la pantalla -
Meta + <flechas izquierda/derecha>→ Mueve la ventana de la aplicación a la parte izquierda/derecha de la pantalla -
Meta + RePag→ Maximiza/Restaura el tamaño de una ventana -
Meta + AvPag→ Minimiza una ventana -
Meta + Q→ Para gestionar las actividades (yo no las uso, no puedo dar más detalles) -
Meta + D→ Muestra el escritorio «apartando» todas las ventanas -
Meta + T→ Modo Tilling de Plasma
Espero que te resulte útil y que quizás alguna la empieces a utilizar por su utilidad en tu uso de Plasma.
¿Alguna más que no aparezca en este listado y que utilices asíduamente? No dudes en compartirlas en los comentarios


Looking at Next Steps for Leap 16 Branding
Many thanks to all who participated in the Leap 16 branding workshop at the openSUSE Conference 2024. The enthusiasm and creativity is moving us forward to take the next steps with Leap 16 branding. Let’s develop some of these fantastic ideas further!
Below is a list of Leap 16 branding initiatives we aim to achieve:
1) Abstract Distribution Agnostic Wallpaper
We are looking for wallpaper designs that can be shared across any distribution. This could be a gradient, fractal or any other abstract design, which ideally incorporates the new logo. The goal is to create something visually appealing and universally adaptable as chameleons do.
2) Abstract Distribution Specific Wallpaper for Leap 16 and Tumbleweed
In addition to the agnostic wallpaper, we need specific designs for Leap 16 and Tumbleweed. These wallpapers should reflect the unique identity of each distribution while maintaining a cohesive visual theme. An adjustable design for other flavors like Slowroll, Kalpa, Aeon and others can be considered and proposed to those projects.
3) Day and Night Variant with Chameleon
We’re also seeking designs for a day and night variant featuring a beloved chameleon. These wallpapers should complement each other while representing the different times of the day in a creative and engaging way. Additionally, day/night variants for abstract designs could also be an option. While not necessary, if participants have good ideas, these will be consider further.

4) Photo Submissions of Our Mascot
We invite you to submit two photos related to our mascot, the chameleon, or anything that resembles to it. The photographer of the photo must also be the submitter; the creator of a photograph with a camera. This is a great opportunity to showcase your photography skills and contribute to our branding efforts. Please note that AI-generated images are not eligible for submission; we want to see your original photographic work.
Call for Photo Competition!
We are thrilled to announce a photo competition. Please submit your pictures for a chance to be featured in branding materials. You can submit your photos through our GitHub issue tracker. We will use a thumbs up/down mechanism to select the best entries.
Submit photos here.
Submission Guidelines
You are welcome to participate on the wallpapers collection set in our branding repository.
Photos can be submitted here under issue 18.
Deadline and Requirements
The deadline for submissions is Nov. 1, 2024. Please ensure your entries meet the following requirements:
- Must be brand-related (chameleons, chameleon-like objects, etc.)
- High-resolution photographs only (4k or preferrably 5k)
- Original work - submitted by the author of the photograph or with approval from the actual author
- Landscape orientation only
Please add a copy of your photos, including a description (where it was taken and what is in the picture), as comments into the issue. Include a link to a high-resolution variant.
We can’t wait to see your creative contributions and make Leap 16 an even more visually stunning experience for everyone in the openSUSE community!
(Image made with DALL-E)
Episodio 30 de KDE Express: Plasma 6.1, Mobile, vídeos en el escritorio e integración
Me congratula presentaros el episodio 30 de KDE Express, titulado «Plasma 6.1, Mobile, vídeos en el escritorio e integración» donde David Marzal sigue llevando en solitario estas más que interesantes píldoras.
Episodio 30 de KDE Express: Plasma 6.1, Mobile, vídeos en el escritorio e integración
Comenté hace ya bastante tiempo que había nacido KDE Express, un audio con noticias y la actualidad de la Comunidad KDE y del Software Libre con un formato breve (menos de 30 minutos) que complementan los que ya generaba la Comunidad de KDE España, aunque ahora estamos tomándonos un tiempo de respiro por diversos motivos, con sus ya veteranos Vídeo-Podcast que todavía podéis encontrar en Archive.org, Youtube, Ivoox, Spotify y Apple Podcast.
De esta forma, a lo largo de estos primeros 30 episodios, promovidos principalmente por David Marzal, nos han contado un poco de todo: noticias, proyectos, eventos, etc., convirtiéndose (al menos para mi) uno de los podcast favoritos que me suelo encontrar en mi reproductor audio.
En palabras de David el nuevo episodio de KDE Express número 30 los siguientes temas:

Selección noticias de este mes de junio. A fecha de grabación estamos con Plasma 6.1.2, Frameworks 6.3.0 y Gear 24.05.1.
Artículo original con los enlaces en https://kdeexpress.gitlab.io/30/
- Fedora propone publicar una imagen con KDE Plasma Mobile, para tablets seguramente
- Y hablando de movilidad, postmarketOS 24.06 se actualiza a KDE Plasma 6, al igual que openMandriva
- Integración de Plasma Browser
- Puedes tener vídeos de fondo de pantalla en Plasma 6
- Plasma 6.1 nos trae:
- Activar el escritorio remoto desde la configuración del sistema (funciona en Wayland)
- Modo edición de escritorio mejorado (comentado en el anteior episodio)
- Recordar aplicaciones abiertas en la sesión bajo Wayland
- Sincronizar colores LED de tu teclado (si es compatible)
- Menear el ratón para que crezca activado por defecto (accesibilidad)
- Barrera para no cambiar de monitor sin querer con el ratón : Bordes de la pantalla -> Barrera de bordes.
- Mejora de rendimiento sustancial en viejos Intel gracias al Triple buffering
- Atajo recomendado:
- Meta + R = Grabar región con Spectacle
- Meta + + / Meta + – / Meta + 0 = Zoom del escritorio con seguimiento de ratón
Agradecimientos: Jorge Lama por su asistencia, consejo, apoyo y edición de audio en este episodio.
Y, como siempre, os dejo aquí el listado de los episodios. ¡Disfrutad!
Por cierto, también podéis encontrarlos en Telegram: https://t.me/KDEexpress
La entrada Episodio 30 de KDE Express: Plasma 6.1, Mobile, vídeos en el escritorio e integración se publicó primero en KDE Blog.
Mix de novedades de Plasma 6.1 ( y V)
El martes 18 de junio fue lanzada la primera gran revisión Plasma 6 y a lo largo de varias entregas he destacado sus principales características. Es hora de finalizar esta serie con el mix de novedades de Plasma 6.1.
Mix de novedades de Plasma 6.1 ( y V)
Aunque la Comunidad KDE ya ha lanzado la primera actualización de la sexta rama de su escritorio, o dicho de otra forma, Plasma 6.1, hasta hace poco no me he puesto a desgranar sus nuevas catacterísticas. Esta versión suponía un punto y seguido en la evolución positiva que sigue haciendo el entorno de trabajo más popular del proyecto KDE y la primera en ofrecer novedades realmente revolucionarias. Es hora de finalizar este repaso, pero antes os pongo la lista de artículos publicados:
- Escritorio remoto integrado en Plasma. Novedades de Plasma 6.1 (I)
- Nueva configuración visual del escritorio. Novedades de Plasma 6.1 (II)
- Aplicaciones persistentes en Plasma. Novedades de Plasma 6.1 (III)
- Sincronización de los LED de color del teclado. Novedades de Plasma 6.1 (IV)
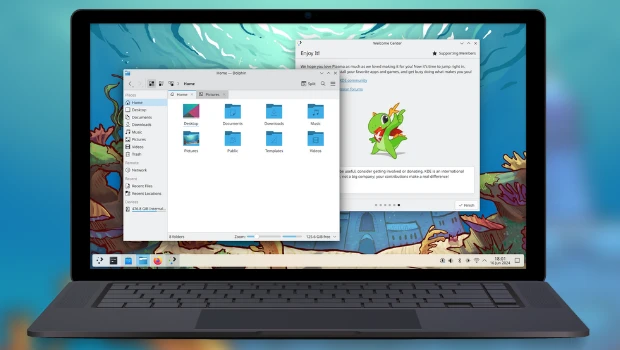
Además de las novedades especificas comentadas en los artículos de la serie, los desarrolladores han destacado las siguientes novedades.
- Se han simplificado las opciones que se muestran al salir de Plasma reduciendo el número de opciones confusas. Por ejemplo, tras pulsar Apagar, Plasma solo mostrará Apagar y Cancelar, en lugar de todas las opciones de energía.
- El bloqueo de pantalla proporciona la opción de configurarlo para que se comporte como un salvapantallas tradicional, ya que permite elegir que no se pida la contraseña para desbloquearlo.
- Dos cambios de accesibilidad visual facilitan el uso del cursor en Plasma 6.1:
- Sacudir el cursor hace que el cursor crezca cuando se «sacude». Esto ayuda a localizar esa diminuta flecha en pantallas grandes y abarrotadas cuando se pierde entre tanta ventana.
- La barrera de borde es útil cuando se tiene una configuración con varios monitores y se quiere acceder a objetos que están en el mismo borde del monitor. La «barrera» es un área adhesiva para el cursor cuando se mueve cerca del borde entre pantallas, que hace que sea más fácil hacer clic en objetos (si eso es lo que desea hacer), en lugar de que el cursor se deslice a la siguiente pantalla.
- Dos avances importantes en Wayland mejorarán enormemente su experiencia con Plasma:
- La sincronización explícita elimina el parpadeo y los defectos visuales que han experimentado tradicionalmente los usuarios de NVidia.
- El uso de triple búfer en Wayland hace que las animaciones y la representación en la pantalla sean más suaves.
Más información: KDE
Las novedades de Plasma 6.1
Aquí tenéis unas pinceladas de las novedades que nos facilitaron los desarrolladores en su fase beta fueron las siguientes:
- Triple búfer en KWin para una mejor renderización y animaciones más fluidas.
- Permitir el uso del protocolo de sincronización explícita de Wayland, lo que debería mejorar la vida de los usuarios de NVIDIA en particular.
- Permitir el uso del portal de captura de entrada.
- Integración del sistema de escritorio remoto para permitir conexiones de clientes RDP con el escritorio Plasma, además de una nueva página en las «Preferencias del sistema» para configurarla.
- Nueva experiencia de usuario para el modo de edición de Plasma, para hacer que su modalidad sea más obvia y visualmente más elegante.
- Se ha añadido una barrera de borde configurable entre pantallas, para que sea más fácil alcanzar los elementos de la interfaz de usuario que tocan los bordes entre pantallas. Esto también permite que los paneles que se ocultan automáticamente en los bordes entre las pantallas funcionen correctamente.
- Restauración de falsa sesión en Wayland que, por lo menos, vuelve a abrir las aplicaciones que estaban abiertas la última vez, incluso aunque no vuelvan a estar situadas en el mismo lugar. Todavía se sigue trabajando en la restauración real de la sesión.
- Compatibilidad con la sincronización del color de la luz RGB posterior del teclado con el color de acento de Plasma.
- Permitir el uso del perfil de color integrado en la pantalla, para las pantallas que lo incluyan.
- Permitir que Discover pueda sustituir aplicaciones Flatpak que han alcanzado el final de soporte con sus reemplazos.
- Compatibilidad con las funciones del modo de conservación de batería en muchos portátiles Lenovo IdeaPad y Legion.
- Compatibilidad con el bloqueo de pantalla sin contraseña, que permite usarlo como un salvapantallas en entornos sin problemas de seguridad.
- Ahora se puede hacer un clic central en el widget de «Energía y batería» para bloquear o desbloquear el reposo automático y el bloqueo de la pantalla. También se puede usar la rueda del ratón sobre él para cambiar el perfil de ahorro de energía activo.
- Esquinas ligeramente redondeadas y más coherencia entre los radios de las esquinas en todas partes.
- Mejor algoritmo de organización de ventanas para la «Vista general».
- El efecto «Mover el cursor para encontrarlo» se ha activado de forma predeterminada.
- Nuevo efecto desactivado de forma predeterminada para ocultar el puntero del ratón tras un período de inactividad.
- La página del teclado de las «Preferencias del sistema» se ha reescrito en QML.
La entrada Mix de novedades de Plasma 6.1 ( y V) se publicó primero en KDE Blog.
Sincronización de los LED de color del teclado. Novedades de Plasma 6.1 (IV)
El martes 18 de junio fue lanzada la primera gran revisión Plasma 6. Ya es hora de ir analizando sus novedades. Ya he hablado del escritorio remoto integrado en Plasma, la nueva forma de personalizar el escritorio y de las aplicaciones persistentes. Hoy toca hablar de la sincronización de los LED de color del teclado, otra forma de personalizar nuestro entorno de trabajo real.
Aplicaciones persistentes en Plasma. Novedades de Plasma 6.1 (III)
La Comunidad KDE publicó hace un tiempo la primera actualización de la sexta rama de su escritorio, o dicho de otra forma, Plasma 6.1, una versión que suponía un punto y seguido en la evolución positiva que sigue haciendo el entorno de trabajo más popular del proyecto KDE y la primera en ofrecer novedades realmente revolucionarias. Es hora de empezar a repasarlas.
En palabras de sus desarrolladores:
No sería una nueva versión de Plasma sin al menos una función de personalización estética elegante. Esta vez, sin embargo, le damos la facultad de ir más allá de la pantalla, hasta llegar al teclado, que ahora permite sincronizar los colores LED de las teclas para que coincidan con el color de acento del escritorio.
La mejora definitiva para el usuario preocupado por la moda.
Tenga en cuenta que esta característica no funcionará en los teclados no reconocidos (¡aunque el reconocimiento de más teclados está en camino!).
Más información: KDE
Las novedades de Plasma 6.1
Hoy es un día de descarga y actualizaciones, y mientras espero que esté disponible para mi KDE Neon, os comento algunas de sus novedades:
No obstante, aquí tenéis unas pinceladas de las novedades que nos facilitaron los desarrolladores en su fase beta fueron las siguientes:
- Triple búfer en KWin para una mejor renderización y animaciones más fluidas.
- Permitir el uso del protocolo de sincronización explícita de Wayland, lo que debería mejorar la vida de los usuarios de NVIDIA en particular.
- Permitir el uso del portal de captura de entrada.
- Integración del sistema de escritorio remoto para permitir conexiones de clientes RDP con el escritorio Plasma, además de una nueva página en las «Preferencias del sistema» para configurarla.
- Nueva experiencia de usuario para el modo de edición de Plasma, para hacer que su modalidad sea más obvia y visualmente más elegante.
- Se ha añadido una barrera de borde configurable entre pantallas, para que sea más fácil alcanzar los elementos de la interfaz de usuario que tocan los bordes entre pantallas. Esto también permite que los paneles que se ocultan automáticamente en los bordes entre las pantallas funcionen correctamente.
- Restauración de falsa sesión en Wayland que, por lo menos, vuelve a abrir las aplicaciones que estaban abiertas la última vez, incluso aunque no vuelvan a estar situadas en el mismo lugar. Todavía se sigue trabajando en la restauración real de la sesión.
- Compatibilidad con la sincronización del color de la luz RGB posterior del teclado con el color de acento de Plasma.
- Permitir el uso del perfil de color integrado en la pantalla, para las pantallas que lo incluyan.
- Permitir que Discover pueda sustituir aplicaciones Flatpak que han alcanzado el final de soporte con sus reemplazos.
- Compatibilidad con las funciones del modo de conservación de batería en muchos portátiles Lenovo IdeaPad y Legion.
- Compatibilidad con el bloqueo de pantalla sin contraseña, que permite usarlo como un salvapantallas en entornos sin problemas de seguridad.
- Ahora se puede hacer un clic central en el widget de «Energía y batería» para bloquear o desbloquear el reposo automático y el bloqueo de la pantalla. También se puede usar la rueda del ratón sobre él para cambiar el perfil de ahorro de energía activo.
- Esquinas ligeramente redondeadas y más coherencia entre los radios de las esquinas en todas partes.
- Mejor algoritmo de organización de ventanas para la «Vista general».
- El efecto «Mover el cursor para encontrarlo» se ha activado de forma predeterminada.
- Nuevo efecto desactivado de forma predeterminada para ocultar el puntero del ratón tras un período de inactividad.
- La página del teclado de las «Preferencias del sistema» se ha reescrito en QML.
En los próximas entradas más detalles.
La entrada Sincronización de los LED de color del teclado. Novedades de Plasma 6.1 (IV) se publicó primero en KDE Blog.
Aplicaciones persistentes en Plasma. Novedades de Plasma 6.1 (III)
El martes 18 de junio fue lanzada la primera gran revisión Plasma 6. Ya es hora de ir analizando sus novedades. Ya he hablado del escritorio remoto integrado en Plasma o la nueva forma de personalizar el escritorio. Hoy toca habla de las aplicaciones persistente, un claro ejemplo de cómo, con bastante celeridad, vuelven alguna de las funcionalidades perdidas en la transición de Qt5 a Qt6.
Aplicaciones persistentes en Plasma. Novedades de Plasma 6.1 (III)
La Comunidad KDE publicó hace un tiempo la primera actualización de la sexta rama de su escritorio, o dicho de otra forma, Plasma 6.1, una versión que suponía un punto y seguido en la evolución positiva que sigue haciendo el entorno de trabajo más popular del proyecto KDE y la primera en ofrecer novedades realmente revolucionarias. Es hora de empezar a repasarlas.
En palabras de sus desarrolladores:
Plasma 6.1 en Wayland dispone ahora de una función que «recuerda» lo que estaba haciendo el la última sesión, como hacía en X11, aunque todavía está en pleno desarrollo. Si cierra la sesión y apaga el equipo con muchas ventanas abiertas, Plasma las abrirá la próxima vez que acceda al escritorio, haciendo que sea más rápido y más fácil volver a lo que estaba haciendo.
Más información: KDE
Las novedades de Plasma 6.1
Hoy es un día de descarga y actualizaciones, y mientras espero que esté disponible para mi KDE Neon, os comento algunas de sus novedades:
No obstante, aquí tenéis unas pinceladas de las novedades que nos facilitaron los desarrolladores en su fase beta fueron las siguientes:
- Triple búfer en KWin para una mejor renderización y animaciones más fluidas.
- Permitir el uso del protocolo de sincronización explícita de Wayland, lo que debería mejorar la vida de los usuarios de NVIDIA en particular.
- Permitir el uso del portal de captura de entrada.
- Integración del sistema de escritorio remoto para permitir conexiones de clientes RDP con el escritorio Plasma, además de una nueva página en las «Preferencias del sistema» para configurarla.
- Nueva experiencia de usuario para el modo de edición de Plasma, para hacer que su modalidad sea más obvia y visualmente más elegante.
- Se ha añadido una barrera de borde configurable entre pantallas, para que sea más fácil alcanzar los elementos de la interfaz de usuario que tocan los bordes entre pantallas. Esto también permite que los paneles que se ocultan automáticamente en los bordes entre las pantallas funcionen correctamente.
- Restauración de falsa sesión en Wayland que, por lo menos, vuelve a abrir las aplicaciones que estaban abiertas la última vez, incluso aunque no vuelvan a estar situadas en el mismo lugar. Todavía se sigue trabajando en la restauración real de la sesión.
- Compatibilidad con la sincronización del color de la luz RGB posterior del teclado con el color de acento de Plasma.
- Permitir el uso del perfil de color integrado en la pantalla, para las pantallas que lo incluyan.
- Permitir que Discover pueda sustituir aplicaciones Flatpak que han alcanzado el final de soporte con sus reemplazos.
- Compatibilidad con las funciones del modo de conservación de batería en muchos portátiles Lenovo IdeaPad y Legion.
- Compatibilidad con el bloqueo de pantalla sin contraseña, que permite usarlo como un salvapantallas en entornos sin problemas de seguridad.
- Ahora se puede hacer un clic central en el widget de «Energía y batería» para bloquear o desbloquear el reposo automático y el bloqueo de la pantalla. También se puede usar la rueda del ratón sobre él para cambiar el perfil de ahorro de energía activo.
- Esquinas ligeramente redondeadas y más coherencia entre los radios de las esquinas en todas partes.
- Mejor algoritmo de organización de ventanas para la «Vista general».
- El efecto «Mover el cursor para encontrarlo» se ha activado de forma predeterminada.
- Nuevo efecto desactivado de forma predeterminada para ocultar el puntero del ratón tras un período de inactividad.
- La página del teclado de las «Preferencias del sistema» se ha reescrito en QML.
En los próximas entradas más detalles.
La entrada Aplicaciones persistentes en Plasma. Novedades de Plasma 6.1 (III) se publicó primero en KDE Blog.
#openSUSE Tumbleweed revisión de las semanas 26 y 27 de 2024
Tumbleweed es una distribución de GNU/Linux «Rolling Release» o de actualización contínua. Aquí puedes estar al tanto de las últimas novedades.

openSUSE Tumbleweed es la versión «rolling release» o de actualización continua de la distribución de GNU/Linux openSUSE.
Hagamos un repaso a las novedades que han llegado hasta los repositorios esta semana.
Y recuerda que puedes estar al tanto de las nuevas publicaciones de snapshots en esta web:
El anuncio original lo puedes leer en el blog de Dominique Leuenberger, publicado bajo licencia CC-by-sa, en este este enlace:
En este lapso de tiempo de dos semanas se han publicado un total de 12 snapshots (0620, 0621, 0622, 0624, 0625, 0627, 0628, 0629, 0701, 0702, 0703, y 0704)
Los cambios más relevantes que han traído estas snapshots son:
- GDB 14.2
- MariaDB 11.4.2
- Mesa: con la solución a los problemas gráficos de ATI/AMD, versión 24.1.2
- Shadow 4.16.0
- Wayland 1.23.0
- KDE Plasma 6.1.0, 6.1.1 y 6.1.2
- GCC 14.1.1
- Qt 6.7.2
- Linux kernel 6.9.6 (con solución a los problemas de conexión con iwlwifi) & 6.9.7
- NetworkManager 1.48.2
- ClamAV 1.3.1
- GNOME 46.3
- GStreamer 1.24.5
- Perl 5.40.0
- LLVM 18.1.8
- Poppler 24.07.0
- Qemu 9.0.1
- Systemd 255.8
- Cups 2.4.10
- Samba 4.20.2
- PyTest 8.2.2
- openssh que soluciona la vulnerabilidad CVE-2024-6387, aka RegreSSHion
Y esto se está preparando para próximas snapshots:
- Mesa 24.1.3
- Mozilla Firefox 127.0.2
- LibreOffice
- Agama paquetes e instalador.
- KDE Gear 24.05.2
- SELinux 3.7
- cmake 3.30.0
- transactional-update: habilitar soft reboot
- dbus-broker: algún problema de red después de que las actualizaciones se hayan resuelto
- GCC 14
Si quieres estar a la última con software actualizado y probado utiliza openSUSE Tumbleweed la opción rolling release de la distribución de GNU/Linux openSUSE.
Mantente actualizado y ya sabes: Have a lot of fun!!
Enlaces de interés
- ¿Por qué deberías utilizar openSUSE Tumbleweed?
- zypper dup en Tumbleweed hace todo el trabajo al actualizar
- ¿Cual es el mejor comando para actualizar Tumbleweed?
- ¿Qué es el test openQA?
- http://download.opensuse.org/tumbleweed/iso/
- https://es.opensuse.org/Portal:Tumbleweed

——————————–
Tumbleweed – Review of the weeks 2024/26 & 27
Dear Tumbleweed users and hackers,
My excuse to span two weeks in this report is quite simple: last week was the openSUSE Conference in Nuremberg and I spent my time talking to all the fun people from the community instead. And I am sure you are forgiving me for this. With the conference in full swing and weekends in between, it is quite amazing that the release Team (mostly Ana these days) still managed to produce and publish 12 snapshots (0620, 0621, 0622, 0624, 0625, 0627, 0628, 0629, 0701, 0702, 0703, and 0704)
The most relevant changes from these snapshots include:
- GDB 14.2
- MariaDB 11.4.2
- Mesa: work around broken graphics on ATI/AMD chipsets, Version 24.1.2
- Shadow 4.16.0
- Wayland 1.23.0
- KDE Plasma 6.1.0, 6.1.1 & 6.1.2
- GCC 14.1.1
- Qt 6.7.2
- Linux kernel 6.9.6 (fixing connection issues with iwlwifi) & 6.9.7
- NetworkManager 1.48.2
- ClamAV 1.3.1
- GNOME 46.3
- GStreamer 1.24.5
- Perl 5.40.0
- LLVM 18.1.8
- Poppler 24.07.0
- Qemu 9.0.1
- Systemd 255.8
- Cups 2.4.10
- Samba 4.20.2
- PyTest 8.2.2
- openssh fix against CVE-2024-6387, aka RegreSSHion
Quite an impressive list in just 2 weeks I’d say. At least in the northern hemisphere, the summer holiday is starting (including my own – so no reports from me for the next two weeks! Please follow the individual snapshot release announcements on the factory@lists.opensuse.org mailing list). With many people enjoying a break, we will likely see fewer requests going to Tumbleweed.
Looking at what is currently to be found in the staging area, we can predict those changes to happen in the next few days/weeks:
- Mesa 24.1.3
- Mozilla Firefox 127.0.2
- LibreOffice: fix excessive recommends on libreoffice-qt6
- Agama packages and installer to appear. Not yet QA’ed as part of the Tumbleweed release process, but feel free to test and play with it
- KDE Gear 24.05.2
- SELinux 3.7
- cmake 3.30.0
- transactional-update: enable soft reboot; see https://microos.opensuse.org/blog/2024-06-13-soft-reboot/
- dbus-broker: some networking issue after upgrades left to work out
- GCC 14: phase 2: use gcc14 as the default compiler – lots of help needed: https://build.opensuse.org/project/show/openSUSE:Factory:Staging:Gcc7
Thunderbird 128 a la vuelta de la esquina
Ya puedes probar la versión Beta de Thunderbird 128, el potente cliente de correo de software libre

El cliente de correo Thunderbird sigue preparando su versión 128, que se publicará el próximo 10 de julio de 2024. Pero ya está disponible su versión Beta para probarla en nuestros equipos y echar un vistazo a las novedades y contribuir reportando errores.
Esta será una actualización un poco más corta ya que la comunidad de Thunderbird dedicó la mayor parte de se esfuerzo en probar y pulir 128 beta, que se convertirá en ESR el 10 de julio. Pero aún así se han corregido un total de 127 errores y se están solucionando algunas cosas más. Por ejemplo…
Ahora se pueden ver los colores personalizados que elegiste para sus diferentes cuentas en las ventanas de redacción del correo electrónico. Esta fue una solicitud que se realizó hace 18 años y que finalmente se ha podido cumplir gracias al increíble trabajo que muchos desarrolladores realizaron durante los últimos 2 años. Las cosas llegan…
Ha sido necesario reestructurar el código para hacerlo más confiable y modular, con una separación más clara entre los datos y la interfaz de usuario. Esta profunda mejora hace que se puedan ofrecer estas funciones solicitadas desde hace mucho tiempo mucho más rápido.
El código del cliente está terminado, todo está en su lugar y estamos probando la sincronización de los datos del servidor con un servidor provisional temporal.
También siguen trabajando en una sincronización de cuentas, al estilo del navegador Firefox, para sincronizar Thundebird en todos tus dispositivos.
Todavía se está trabajando para generar su propio servidor de producción, pero requiere más trabajo para tenerlo disponible, por lo que potencialmente no se habilitará la sincronización de forma predeterminada para la primera versión de ESR y, en cambio, se mantendrá oculta temporalmente, con el objetivo de habilitarla en una versión futura (tal vez 128.1 o 128.2) dependiendo de cuándo este listo el servidor de producción.
Todo esto y mucho más es lo que espera a este gran software, que te ayuda a gestionar tus correos electrónicos, tus contactos, tus calendarios y mucho más…
Puedes probar la versión Beta, sin necesidad de reemplazar tu versión estable y disfrutar de las novedades antes que nadie si te puede la curiosidad…
Enlaces de interés
- https://blog.thunderbird.net/2024/07/thunderbird-monthly-development-digest-june-2024/
- https://www.thunderbird.net
- https://www.thunderbird.net/en-CA/thunderbird/115.0/beta-appeal/
Segunda actualización de KDE Gear 24.05
La Comunidad KDE es una comunidad responsable y no solo se preocupa en lanzar novedades sino que también en mejorarlas. Me complace presentar la segunda actualización de KDE Gear 24.05 que apareció hace casi dos meses. Más estabilidad, mejores traducciones y pequeñas mejoras para las aplicaciones de nuestro entornos de trabajo.
Segunda actualización de KDE Gear 24.05
A pesar de lo que puedan pensar muchas personas, las aplicaciones no son perfectas. Entre las líneas de código se pueden colar errores de tipografía o que el usuario realice alguna opción que en un principio no estaba prevista por los desarrollador, por poner solo un par de ejemplos de imperfecciones.
Este no es un problema del Software Libre ya que el Software actual funciona de esta manera ya que no se piensa en él como un producto final que se encierra en una caja y se olvida. En la actualidad se sabe que el Software está vivo y sería estúpido ir guardando las mejoras sin dejarlas a disposición del gran público.
Con esto se gana en rapidez y evolución pero puede aumentar el número de errores (por norma general) leves, los cuales son subsanables con pequeñas actualizaciones.
La Comunidad KDE lo tiene claro: grandes lanzamientos cada cuatro meses y actualizaciones mensuales para subsanar errores.

Por ello me congratula compartir con vosotros la segunda actualización de KDE Gear 24.05 que nos ofrece más de 180 errores resueltos entre aplicaciones, librerías y widgets, algo que mejora el rendimiento del sistema.
Aquí podéis encontrar la lista completa de cambios de KDE Gear 24.05.02, pero por poner unos cuantos ejemplos de los errores que sea han resuelto tenemos:
- kdepim-runtime: Corrección de una fuga de memoria en el recurso EWS
- kio-gdrive: arreglado «Este archivo no existe» después de hacer clic en una carpeta
- partitionmanager: Corregido fallo causado por hacer clic en el botón de eliminar punto de montaje
Más información: KDE Gear 24.05.02
La entrada Segunda actualización de KDE Gear 24.05 se publicó primero en KDE Blog.