
 Member
Member Futureboy
FutureboyBashtop on openSUSE | Terminal

Mi escritorio Plasma de noviembre 2020 #viernesdeescritorio
Esta semana he estado con Lina castro (@lirrums) y me ha vuelta a picar las ganas de compartir mi pantalla siguiendo la iniciativa #viernesdeescritorio, y de esta forma añadir otra entrada a la serie «Mi escritorio», en la que comparto en el blog el aspecto de mi ordenador, una forma de mostrar como queda un entorno de trabajo de uso diario utilizando el software creado por la Comunidad KDE. Espero que im escritorio Plasma de Noviembre 2020 os guste.
Mi escritorio Plasma de noviembre 2020 #viernesdeescritorio
Esta va a ser la sexta vez que muestro mi escritorio Plasma 5 en público. En esta ocasión he vuelto ha utilizar Latte Dock y cambiado al entorno oscuro, el cual me está costando acostumbrarme, pero que poco a poco me va gustando más.
Como es habitual, la captura está realizada sobre mi portátil Slimbook Pro de 13 pulgadas, el cual tiene instalado un KDE Neon con Plasma 5.20.3.
Utilizo el motor de ventana Kvantum, lo cual le confiere un aspecto muy particular, con unas transparencias muy elegantes. Me queda cambiar los iconos ¿cuáles me recomendáis?
El resultado de mi escritorio de noviembre de 2020 es un escritorio minimalista muy agradable a los ojos y muy bonito. Además, he estrenado el screenfetch para ver la configuración de mi equipo en Konsole. ¿Qué os parece?
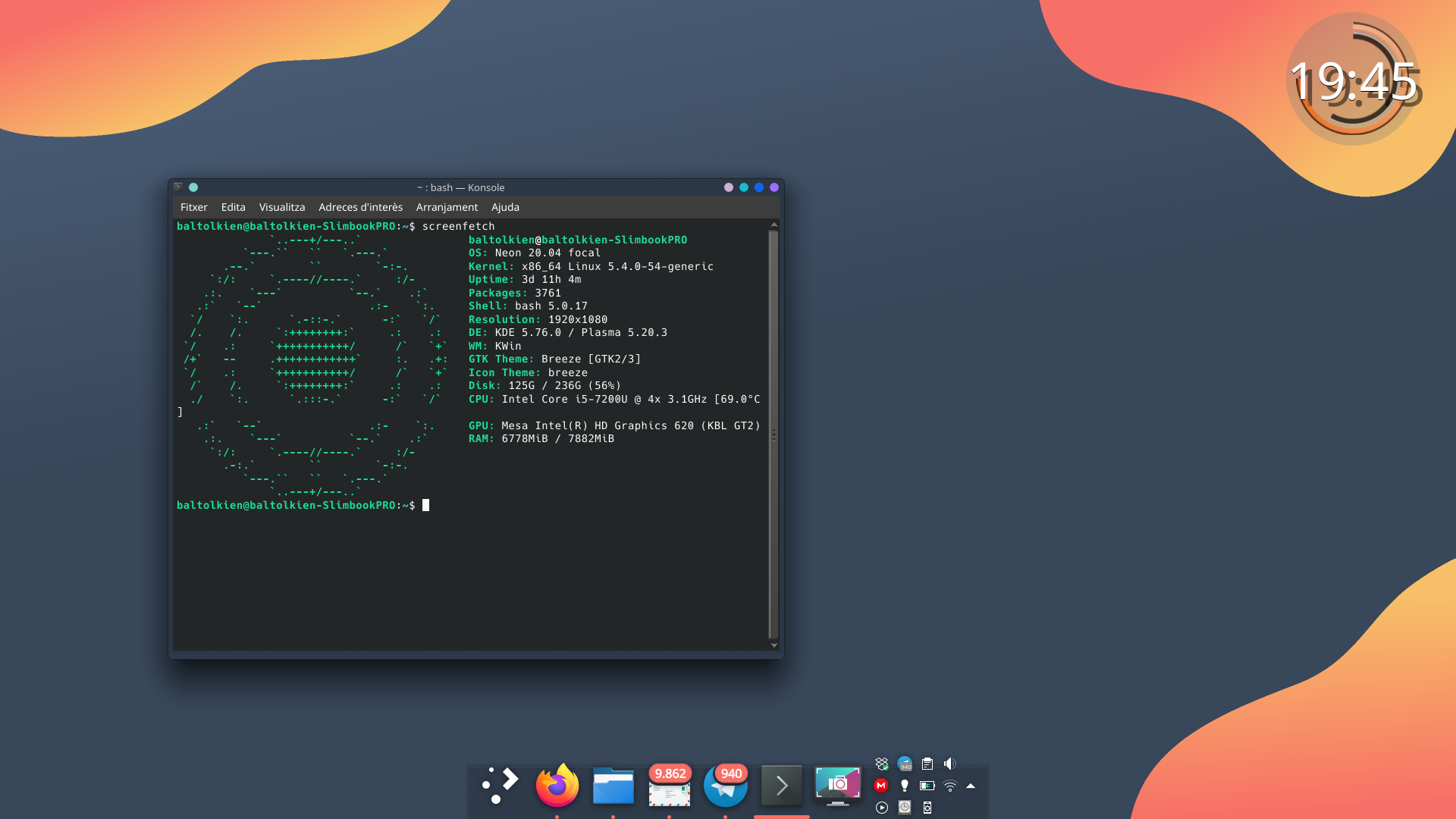
Las características del escritorio son las siguientes:
Gestor de Ventanas: Kwin (he probado con Wayland, se ve incluso mejor pero tiene un bug en Kontact me imposibilita utilizarlo)
Look and Feel: Otto de Jomada (uno de los grandes diseñadores de temas para Plasma)
Estilo de Plasma: Otto-not-rounded
Fondo: Otto
Estilo de aplicación: Kvantum
Iconos: Brisa
Plasmoides:
- Barra de tareas: Latte dock centrada y que se ocultamiento automático y que contiene, de izquierda a derecha, lanzador de aplicaciones Kickoff, gestor de tareas solo iconos (que ahora es el por defecto en Plasma) y bandeja de sistema.
- Reloj digital: Digital Clock BeClock Style

Do not use librsvg 2.40.x
Please do not use librsvg 2.40.x; it cannot render recent Adwaita icon themes correctly.
The librsvg 2.40.x series is the last "C only" version of the library; it was deprecated in 2017.
During the port to Rust, I rewrote the path parser to be spec-compliant, and fixed a few cases that the C version did not handle. One of this cases is for compact Arc data.
The SVG path grammar allows
one to remove whitespace between numbers if the next number starts
with a sign. For example, 23-45 gets parsed as two numbers 23
-45.
In addition, the arguments of the Arc commands have two flags in the
middle of a bunch of numbers. The flags can be 0 or 1, and there
may be no whitespace between the flags and the next number. For
example, A1.98 1.98 0 0015 13.96 gets parsed as A1.98 1.98 0 0 0 15
13.96 — note the two 0 0 flags before the 15.
Librsvg 2.40.x does not parse this correctly. Adwaita-icon-theme-3.36, and possibly earlier versions, uses minimized SVG files with compressed whitespace, and will not render correctly with the C-only version of librsvg.
This is help-contents-symbolic.svg rendered with librsvg 2.40.21:

And this is help-contents-symbolic.svg rendered with librsvg 2.50.2:

This is not the only icon with compact Arc commands; there are many others that will also be mis-rendered in 2.40.x.
I don't know when Adwaita started using SVGs with compressed whitespace; probably it didn't when librsvg 2.40.x was the latest version, or everyone would have noticed mis-rendered icons.
Background: Someone recently filed a bug about memory unsafety in librsvg 2.40.x's path parser, which mysteriously enough only manifests itself in big-endian platforms. I wouldn't be surprised if this had latent bugs on little-endian as well.
Please use at least librsvg 2.48.x; any earlier versions are not supported. Generally I keep an eye on the last two stable release sets (2.48.x and 2.50.x as of this writing), but only commit fixes to the latest stable series (2.50.x currently).
#openSUSE Tumbleweed revisión de la semana 48 de 2020
Tumbleweed es una distribución “Rolling Release” de actualización contínua. Aquí puedes estar al tanto de las últimas novedades.

openSUSE Tumbleweed es la versión “rolling release” o de actualización continua de la distribución de GNU/Linux openSUSE.
Hagamos un repaso a las novedades que han llegado hasta los repositorios estas semanas.
El anuncio original lo puedes leer en el blog de Dominique Leuenberger, publicado bajo licencia CC-by-sa, en este enlace:
Después de unas semanas con diferentes problemas que se han ido solucionando, esta semana ha sido más tranquila. Los desarrolladores se han podido centra más en los paquetes de software sin tener que preocuparse de la propia infraestructura.
Lo que ha hecho que se hayan publicado 5 snapshots (1119, 1121, 1123, 1124 y 1125).
Los cambios más interesantes que han traido son:
- GNOME 3.38.1. Ha tardado tiempo, pero por fin está aquí
- KDE Frameworks 5.76.0
- Pango 1.48.0
- Mozilla Thunderbird 78.5.0
- binutils 2.35.1
- pam 1.5.0
- Mesa 20.2.3
- Linux kernel 5.9.10
- Qt 5.15.2
Y como es normal, openSUSE Tumbleweed no deja de girar, y ya se están “cocinando” actualizaciones como:
- GNOME 3.38.2
- Linux kernel 5.9.11
- brp-check-suse
- RPM 4.16
- Ruby 3.0
- openssl 3.0: actualmente testeando la verisón alpha 9
Si quieres estar a la última con software actualizado y probado utiliza openSUSE Tumbleweed la opción rolling release de la distribución de GNU/Linux openSUSE.
Mantente actualizado y ya sabes: Have a lot of fun!!
Enlaces de interés
-
-
- ¿Por qué deberías utilizar openSUSE Tumbleweed?
- zypper dup en Tumbleweed hace todo el trabajo al actualizar
- ¿Cual es el mejor comando para actualizar Tumbleweed?
- Comprueba la valoración de las “snapshots” de Tumbleweed
- ¿Qué es el test openQA?
- http://download.opensuse.org/tumbleweed/iso/
- https://es.opensuse.org/Portal:Tumbleweed
-

——————————–
openSUSE Tumbleweed – Review of the week 2020/48
Dear Tumbleweed users and hackers,
After last week being filled with problems, this week felt like a ‘relaxing one’ – not that there would be fewer changes incoming, but we could focus on those changes instead of cuddling the infrastructure. And so it comes that we managed to publish 5 snapshots during this week (1119, 1121, 1123, 1124, and 1125).
The most interesting changes included:
- GNOME 3.38.1 – it took a while, but at last, it’s there
- KDE Frameworks 5.76.0
- Pango 1.48.0
- Mozilla Thunderbird 78.5.0
- binutils 2.35.1
- pam 1.5.0
- Mesa 20.2.3
- Linux kernel 5.9.10
- Qt 5.15.2
And as usual, Tumbleweed does not stop rolling, and staging areas are currently filled with these changes:
- GNOME 3.38.2
- Linux kernel 5.9.11
- brp-check-suse: a bug fix in how it detected dangling symlinks (it detected them, but did not fail as it was supposed to)
- permissions package: prepares for easier listing, while supporting a full /usr merge
- RPM 4.16: still a few packages build failures
- Ruby 3.0: mainly YaST not ready for that switch
- First experiments with rpmlint 2.0 started in Staging:M
- openssl 3.0: currently alpha 9 in Staging:O
Publicado el cartel de emisión de 24H24L
Se acerca el día de emisión y ya se ha publicado el cartel de emisión de 24H24L, un evento de podcasting ambicioso que empieza el próximo sábado 12 de diciembre y que amenaza con llenar todo mi podcaster de programas GNU/Linux.
Publicado el cartel de emisión de 24H24L
Para quienes no lo sepan, 24H24L es un evento en forma de podcasting orientado hacia aquellos curiosos de GNU/Linux que no se han atrevido a probarlo e incluso para los que están empezando en el apasionante mundo del software libre.
Para ello se ha organizado una especie de maratón organizado por temáticas que pretenden llegar a todos los perfiles de usuarios. Ya nos hicimos eco de su comunicado de prensa hace un tiempo.
A medida que se acerca la fecha de emisión, se van conociendo más y más detalles, siendo uno de los principales el cartel de emisión de 24H24L que tiene la hora, temática y participantes de cada uno de los diferentes podcast.
Es mi deber compartirlo con vosotros y animaros a que no solo lo sigáis sino a que también lo divulguéis.

Como no podía ser de otra forma la Comunidad KDE está presente en varios podcast, concretamente:
- Administraciones Públicas moderado por David Marzal y con la presencia de Baltasar Ortega, Salvador Aznar, Táfol Nebot y Julián Moyano el domingo 21 a las 10:00
- Escritorios Linux moderado por Rubén Gómez y con la presencia de Aleix Pol, Alejandro, Diego Muñoz y Juanjo Salvador el domingo 21 a las 14:00.
- Software Libre y software propietario moderado por Rubén Gómez y con la presencia de integrantes de Ubuntu y otras hierbas el domingo 21 a las 14:00.
Puedes encontrar más información en redes sociales:
- Mail: [24h24L@mailo.com](mailto:24h24L@mailo.com?subject=Nota de prensa)
- Twitter: @24H24L1
- Canal de Telegram: Evento 24H24L
- Mastodon: @24h24l@mastodon.online
- Youtube 24H24L
José Jiménez (Organización)
#24H24L

Using HP Printers & Scanners with openSUSE
Several HP Printers and Scanners require a non-free software plugin driver to run on Linux distributions. openSUSE does not come bundled with the non-free plugin.
HP provides an automatic installer for HPLIP (HP Linux Imaging and Printing). The installer is known to work on several Linux distributions including SUSE (13.2, 42.1, 42.2, 42.3, 15.0, 15.1, 15.2). Therefore, it should work on openSUSE.
Download the HPLIP installer and run it as follows:
sh hplip-3.20.9.run
Follow the on-screen instructions to complete the setup. Once done, connect your HP Printer/Scanner. It will be automatically detected and installer.
The files downloaded for the setup will be available in a folder with the same name as the HPLIP installation script, i.e in this case hplip-3.20.9.

Outside The Cubicle | DeWalt 20v Max Cordless Router

GNOME, KDE Frameworks, Mutt update in Tumbleweed
Four openSUSE Tumbleweed snapshots have been released since last Thursday.
Only two packages came in the most recent 20201124 snapshot. Email client mutt had a version bump from 1.14.7 to 2.0.2; the new major release was not because of the magnitude of features but because a few changes are backward incompatible. There were some important changes highlighted like when using attach-file to browse and add multiple attachments to an email; quit can be used to exit after tagging the files. For the full list, read the release notes. The release also fixed a Common Vulnerabilities and Exposures that ensures the IMAP connection is closed after a connection error to avoid sending credentials over an unencrypted connection. The other package in the snapshot was the Ruby static code analyzer rubygem-rubocop. The updated 1.3.1 version offers multiple new features and fixes like reading the required_ruby_version from gemspec file if it exists.

The 20201123 snapshot had several GNU package updates like an update to GNU Compiler Collection 10, which Included a fix for a memcpy miscompilation on aarch64. GNU binary tool binutils cleaned up the specfile in the 2.35.1 version and general-purpose parser generator bison 3.7.4 now defines YYBISON macro as an integer. The ipset 7.9 update enabled memory accounting for ipset allocations and the Passlib password hashing library for Python, python-passlib 1.7.4, added optional dependencies for web framework Django and apache2-utils. Bar code reader package zbar 0.23.1 changed defaults to autodetect Python and GTK versions. Several YaST packages were updated like yast2-network 4.3.28, which provided a fix for the detecting of connection configuration changes, and yast2-firstboot 4.3.8, which removed a duplicated lan client from the firstboot control file and modified the firstboot_dhcp_setup client using the installation dhcp setup client directly.
Snapshot 20201121 highlights the CVE hunting the Mozilla Thunderbird project did in version 78.5.0. The email client closed out more than a dozen CVEs like single-word search queries that were broadcast to local networks (CVE-2020-26966) and the software keyboards that may have remembered typed passwords (CVE-2020-26965). Privacy guard gpg2 2.2.24 fixed the encrypt+sign hash algo preference selection for Elliptic Curve Digital Signature Algorithm, which is needed for keys created from existing smartcard based keys. Support exporting secret keys was made to the cryptography support program gpgme 1.15.0. Sudo now logs when a user-specified command-line option is rejected by a sudoers rule in sudo 1.9.3p1 and ucode-intel 20201118 removed TGL/06-8c-01/80 due to functional issues with some original equipment manufacturer platforms.
The snapshot released a week ago on Thursday was a release many were waiting for with GNOME 3.38. Snapshot 20201119 updated GNOME users to the new Orbis release that highlights the main functionality of the desktop and provides first time users a nice welcome to GNOME with the GNOME tour welcome app. The release provides better screen recording infrastructure in GNOME Shell, made improvements to take advantage of multimedia processing package PipeWire and kernel APIs to reduce resource consumption and improve responsiveness. KDE Frameworks 5.76.0 arrived in the snapshot as well made improvements to Plasma’s Breeze Icons; Plasma Frameworks locked the header colors of Breeze Dark and Breeze Light themes and remove unnecessary anchors in the ComboBox.contentItem. Kirigami package improved the look of the FormLayout on mobile and fixed the menus in contextualActions. The 2.66.3 glib2 package fixed sending large D-Bus messages. Tools for accessing the process power of the Linux Kernel gained Alder Lake, Rocket Lake and Sapphire Rapid support in the update to cpupower 5.10. Other notable packages to that updated in the snapshot were gtksourceview4 4.8.0, pango 1.48.0, libsoup 2.72.0 and vala 0.50.1.
