
 Member
Member baltolkien
baltolkienAgradecimientos públicos Akademy-es 2020
Ya han pasado casi dos semanas desde la finalización del evento que ha llenado mi mente este último mes, y es el momento de realizar los agradecimientos públicos por el éxito de la Akademy-es 202º0. Espero no olvidarme de nadie.
Un evento como que KDE España ha realizado el fin de semana del 20 al 22 de noviembre no es posible sin la voluntad y el esfuerzo de mucha gente, la cual ha trabajo de forma altruista simplemente buscando la divulgación de un proyecto como KDE.
Es evidente que yo mismo he dedicado tiempo de mi vida para Akademy-es, preparando incluso la última charla del evento, pero como he dicho no he sido el único y creo que es de recibo dedicar una entrada agradeciendo a todo el mundo que ha participado en él.
Agradecimientos públicos Akademy-es 2020
El orden no es más que el que me viene a la cabeza a la hora de redactar la entrada, ya que creo que todas las personas de esta lista son igual de importantes.
Y empezaré dando las gracias a los asistentes porque sin ellos Akademy-es 2020 no hubiera tenido sentido y ver a tantas personas en el chat, interactuando entre ellas y jugando con la pizarra me ha llenado de alegría y ha justificado el esfuerzo realizado. La presencia de los asistentes garantiza que otra Akademy-es en línea está garantizada si las circunstancias así lo reclaman.

Voy a continuar con la parte técnica y dar las gracias a Kenny Coyle y al equipo de los SysAdmin de la Comunidad KDE que nos han ofrecido no solo una plataforma estable sino que también una formación express para que todo haya salido a las mil maravilla. La seguridad adquirida al utilizar Big Blue Button, una gran software para webconferencias libre, ha subido miles de enteros.
No puedo olvidar agradecer todos el trabajo a los organizadores del evento José Millán, Rubén Gómez, Antonio Larrosa, Adrián Chaves y a Albert Astals por su dedicación en forma de reuniones, de charlas en Matrix y Telegram, de correos electrónicos y, al final, en presentadores del evento. Como decía un conocido «Todo a escote sale barato» y el trabajo conjunto de todos ellos han facilitado mucho que todas las charlas han salido rodadas.
Evidentemente, no hay evento sin ponentes y estos han sido de altura. No puedo estar más agradecido de haber podido contar con Dani Gutierrez, Adrián Chaves, Víctor Suárez, Marelisa Blanco, Andrea Brandariz, Jorge Lama, Juan Febles, Aleix Pol, Ángel Obregón, María del Carmen Fernández, Ramón Villaverde, Antonio Larrosa, Albert Astals Cid, Voro Mataix, Ritxi, Julián Moyano, Iyán Méndez Veiga, Ancor, González, Rubén Gómez, Camilo Higuita, José Millán, Alejandro López, Álex Fiestas y Baltasar Ortega (un servidor).

También, como no dar las gracias a Juan Febles y a Yoyo Fernández por ayudarnos en la promoción realizando un vídeo audio con ffmpeg que después ha sido utilizado por otros promotores y así dar un poco de vida al evento. De esta forma, además de a Juan y a Yoyo cabe agradecer el esfuerzo de Dani Gutiérrez, Paco Estrada, Lorenzo el atareao, José Picón de Somos Tecnológicos por su cuñas sobre Akademy-es 2020.
Y, para finalizar, quiero agradecer a Rosanna García, amiga y compañera de mi Centro Educativo la realización del póster del evento (que he reutilizado para hacer un buen número de modificaciones) y que haya puesto su hermosa voz en 4 vídeos promocionales.

Como veis, no son pocas las personas que han participado en el éxito de este evento, que nos ha cargado de pilas y que nos ha dado confianza para que esto no sea más que un suma y sigue en la realización de este tipo de eventos.
¡Nos vemos en Akademy-es 2021!
Proxmox VE のCTでXは動くのか
結論から先に書きます。Proxmox VEのLXC コンテナでX をぅこかすことは出来ませんでした。
コンソールとしてSPICEクライアントやxterm.js も指定できるので、出来るかなと思ったのですが、そうは問屋が卸しませんでした。
Xはインストール出来ます。しかし、xinit で起動してみると、 /dev/tty0 がないと言ってきて起動しません。確かに、/dev/ 配下を見ると、
ls -l
total 0
crw–w—- 1 root tty 136, 0 Nov 20 10:10 console
lrwxrwxrwx 1 root root 11 Nov 20 10:03 core -> /proc/kcore
lrwxrwxrwx 1 root root 13 Nov 20 10:03 fd -> /proc/self/fd
crw-rw-rw- 1 nobody nobody 1, 7 Nov 11 08:28 full
lrwxrwxrwx 1 root root 25 Nov 20 10:03 initctl -> /run/systemd/initctl/fifo
lrwxrwxrwx 1 root root 28 Nov 20 10:03 log -> /run/systemd/journal/dev-log
drwxrwxrwt 2 nobody nobody 40 Nov 20 10:03 mqueue
crw-rw-rw- 1 nobody nobody 1, 3 Nov 11 08:28 null
crw-rw-rw- 1 root root 5, 2 Nov 20 2020 ptmx
drwxr-xr-x 2 root root 0 Nov 20 10:03 pts
crw-rw-rw- 1 nobody nobody 1, 8 Nov 11 08:28 random
drwxrwxrwt 2 root root 40 Nov 20 10:03 shm
lrwxrwxrwx 1 root root 15 Nov 20 10:03 stderr -> /proc/self/fd/2
lrwxrwxrwx 1 root root 15 Nov 20 10:03 stdin -> /proc/self/fd/0
lrwxrwxrwx 1 root root 15 Nov 20 10:03 stdout -> /proc/self/fd/1
crw-rw-rw- 1 nobody nobody 5, 0 Nov 15 23:26 tty
crw–w—- 1 root tty 136, 0 Nov 20 10:03 tty1
crw–w—- 1 root tty 136, 1 Nov 20 10:03 tty2
crw-rw-rw- 1 nobody nobody 1, 9 Nov 11 08:28 urandom
crw-rw-rw- 1 nobody nobody 1, 5 Nov 11 08:28 zero
となっていて、/dev/tty0 がありません。そこで以下を試してみました。
- /dev/console を /dev/tty0 に ln しようとしたのですが、
Invalid cross-device link エラーで駄目 - ln -s でやってみたのですが、xinit を動かしたときに
parse_vt_settings: Cannot find a free VT: Inappropriate ioctl for device
エラーで駄目 - mknod tty0 c 136 0 でデバイスファイルを作ろうとしたのですが、
operation not permitted
エラーで駄目
でした。これで行き止まり。
ちなみに、他のディストリビューションも見てみましたが、結果は同じ。そもそも tty0 がないところから同じでした。
というわけで、残念ながらコンテナ内でXを動かすのには失敗しました。

Logitech K400+ Keyboard Water Spill Repair
Bpytop on openSUSE | Terminal
Plasma Bigscreen sigue su desarrollo
Me complace compartir con vosotros que Plasma Bigscreen sigue su desarrollo a buen ritmo lanzando la segunda beta para Raspberry Pi 4. La Comunidad KDE es realmente asombrosa.
Plasma Bigscreen sigue su desarrollo
El proyecto Plasma Bigscreen sigue su desarrollo y se complace en anunciar el lanzamiento de una nueva imagen beta para el Raspberry Pi 4. Los aspectos destacados de la versión
- Kernel y firmware actualizados: La imagen ahora incluye el Kernel y Firmware de la rama del kernel de la Raspberry Pi versión 5.4.y, Esta actualización trae varias correcciones para los dispositivos USB que no funcionan en la imagen anterior y también añade soporte completo para las nuevas placas.
- Soporte de Armhf: aunque arm64 parece ser la tendencia, aun tenemos soporte para un sistema base armhf. Desde la próxima versión también habrá una versión armhf disponible para descargar.
- Base actualizada a Neon Focal: La imagen ha sido re-basada a KDE Neon Focal 20.04 trayendo todas las últimas mejoras, actualizaciones de aplicaciones y actualizaciones de seguridad de KDE Neon.
- Mycroft Core Release 20.08: ¡Mycroft ha sido actualizado! Mycroft-Core enviado en la imagen está ahora basado en la última versión 20.08 de la rama de desarrollo de mycroft, mejorando no sólo el tiempo de inicio de los servicios de mycroft, sino también varias otras mejoras menores notables.

- Soporte para KDE Connect: Plasma Bigscreen ha añadido soporte para KDE Connect KCM e Indicador permitiendo el emparejamiento de sus dispositivos KDE Connect con Plasma Bigscreen y habilitando el plugin de bigscreen en KDE Connect le permitirá navegar por la interfaz de bigscreen usando sólo su teléfono.
- Varias mejoras y correcciones para las aplicaciones de voz: Esta versión cuenta con una habilidad dedicada a la plataforma Bigscreen que implementa más de la API de la GUI de Mycroft para darle una experiencia de aplicación de voz más fluida. Adicionalmente, la última imagen beta también incluye nuevas habilidades instaladas por defecto/aplicaciones de voz como PeerTube y todas las habilidades por defecto de mycroft actualizadas a su rama 20.08.
Más información: Beta 2 Image Release For Raspberry Pi 4
¿Qué es Plasma Bigscreen?
Para resumir, el proyecto tangible de Plasma Bigscreen (y digo tangible porque ya lo puedes tener en tu televisor) es la unión de varias tecnologías libres:
- Las increíbles Raspberry Pi, un proyecto que proporciona el hardware necesario para que funcione el resto del Software. Con menos de 50 € puedes tener tu pequeño PC con el que trastear y conectar donde quieras: un monitor, una pequeña pantalla, un televisor moderno e, incluso, con un televisor con entrada RCA.
- El proyecto MyCroft AI, un software que convierte tu pequeña Raspberry Pi en un asistente de personal controlado por tu voz.
- El Software de la Comunidad, que con su concepción camaleónica y sus propiedades de escalibilidad, se puede adaptar a nuevos formatos de visualización y control.

Proxmox VEのLXCでopenSUSEを使う
手軽な仮想化環境 Proxmox-VE は、LXC を使ったコンテナ環境も用意されています。コンテナ環境では、kernel は 仮想化環境のベースOSのものを使いますが、ユーザランドはopenSUSE のものが使われます。この記事を書いている時点で openSUSE 15.2 相当のコンテナ環境があったので使ってみることにしました。
openSUSE 15.2 のコンテナ環境は、Proxmox VE 標準で用意されていますので、それをWebインタフェースから選択するだけでダウンロード、インストールができます。
インストール完了後は、パッケージの総数は181個でした。見てみましたが、最低限の動作をするために必要なものだけしかない状態です。ssh,sshもないですし、yastも入っていませんでした。ほとんど何も出来ないと行っていいでしょう。/ ディレクトリも 213M しか使っていませんでした。必要最低限のユーザランドを一気に入れてしまうFreeBSDよりまさらにコンパクトです。さすがにzypper は入っていましたので、パッケージの追加は出来ます。
そこで、まずは zypper update を行ったのち、openssh を入れ、さらに yast (パッケージとしてはyast2) を入れてみました。
yast を入れた直後の画面は図1のようになります。
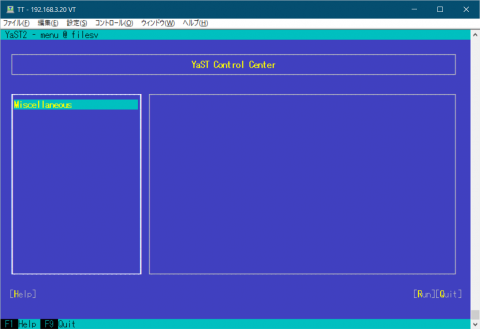
何もないですね。この時点では、yast2-ycp-ui-bindings, yast2-perl-bindings,yast2,yast2-core,yast2-xml,yast2-logs,yast2-ruby-bindings,yast2-hardware-detection,yast2-pkg-binding というものしか入っていません。 yast のサブメニューに対応するパッケージを何も入れていないため、何もないわけです。
そこで、他のサーバを参考にしつつ、yast パッケージを入れてみることにしました。取りあえずはSamba サーバにしたいため、yast2-samba-server を入れることにしました。すると、yast2-samba-client を含め、関連するパッケージが42個も入りました。
続いてSamba本体のパッケージ Samba を入れます。ここでも40パッケージが追加されました。
さて、Sambaをyast で設定するためには少し準備が必要です。useradd でユーザの追加、共有ディレクトリの準備とアクセス権の設定をします。また、pdbedit でSamba用ユーザの登録をします。その後に yast で Sambaの設定をします。しかし、起動すると、図2のように cups を無効にするかどうかを聞いてきます。
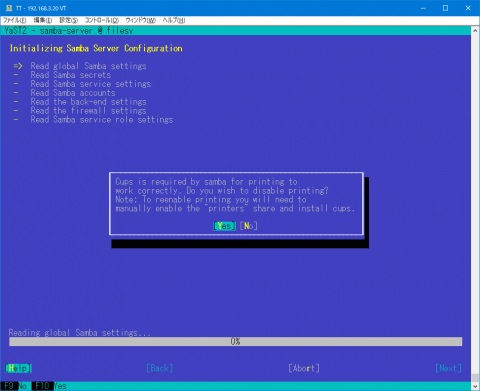
今はSamba経由で印刷することはほぼ皆無なので、最初から無効にしておいてもいいんじゃないかと思うのですけどね。
さて、一通り設定が終わり、Sambaを起動しようとしたのですが、smbdがなぜか起動しません。ログを見ると、
ERROR: failed to setup guest info.
と言うエラーが出ていました。これはSambaが使うゲストユーザの定義がないということでした。調べて見ると、普通OSをインストールしたときには、nobody というユーザが作られているのですが、このLXC環境では入っていなかったのでした。そこで、uid 65534,gid 65533 の nobody を作りました。これでsmbの起動はOKとなりました。
Mi tema de colores para el editor #Vim
Hoy os muestro el tema de colores que he escogido para el editor Vim y la barra Airline

Para gustos los colores y cada cual tiene su preferido que combina como quiere. Y en el editor Vim hay colores para todos los gustos.
Después de mucho escoger y probar, os muestro el tema de colores que estoy utilizando tanto en el editor Vim como en Vim Airline.
Este artículo es una nueva entrega del curso “improVIMsado” que desde hace meses vengo publicando en mi blog sobre el editor Vim y que puedes seguir en estos enlaces:
- https://victorhckinthefreeworld.com/tag/vim/
- https://victorhck.gitlab.io/comandos_vim/articulos.html
La elección de la paleta de colores del editor Vim, nos puede ayudar a la hora de distinguir y ver mejor el texto que estamos editando. Puede ser más que una simple elección estética, una herramienta que nos ayude y facilite a la hora de trabajar con Vim.
El resaltado de sintaxis, la comodidad de nuestros ojos a la hora de ver el texto y los gustos personales de fondos oscuros o claros, etc. Yo me decanto por fondos oscuros…
Seguro que encontrar un tema de colores para Vim que te guste es algo que te puede resultar difícil y puede que una vez encontrado, andes probando y cambies entre otras opciones recién descubiertas, hasta dar con el más idóneo.
En este artículo os voy a mostrar el tema de colores que estoy utilizando desde hace un tiempo, quizás en un tiempo lo cambie de nuevo, pero por el momento me resulta cómodo de utilizar.
Es un tema oscuro, con colores no estridentes, con buen soporte para muchas sintaxis. Se trata del tema oceanic-material. (aquí tenéis una captura, no es mía)

Para probar este tema de colores simplemente descarga, el archivo de configuración y pégalo en la carpeta .vim/colors. Después para probarlo, abre Vim y escribe:
:colorscheme oceanic-material
Ya sabes que Vim tiene autocompletado con la tecla Tabulador. Así que escribe :color<Tab> y ocea<Tab> para que el Tabulador te autocomplete el resto.
Al hacer eso, solo lo habrás establecido de manera temporal. Una vez que cierres la sesión volverás a tener el tema que tenías anteriormente configurado. Si te convence el tema de colores, para establecerlo por defecto deberás modificar el archivo .vimrc de configuración y añadir esa línea al archivo (sin “:” )
Para Vim Airline estoy también utilizando un tema suave, que se llama deus.

Si te animas a probarlo, ya me dirás si te convence o si el tema que utilizas ahora no lo cambias por nada. Utiliza los comentarios del blog para dejar tu opinión.

Lanzada la cuarta actualización de Plasma 5.20
Tal y como estaba previsto en el calendario de lanzamiento de los desarrolladores, hoy martes 1 de diciembre la Comunidad KDE ha comunicado que ha sido lanzada la cuarta actualización de Plasma 5.20. Una noticia que aunque es esperada y previsible es la demostración palpable del alto grado de implicación de la Comunidad en la mejora continua de este gran entorno de escritorio de Software Libre.
Lanzada la cuarta actualización de Plasma 5.20
No existe Software creado por la humanidad que no contenga errores. Es un hecho incontestable y cuya única solución son las actualizaciones. Es por ello que en el ciclo de desarrollo del software creado por la Comunidad KDE se incluye siempre las fechas de las actualizaciones.

De esta forma, el martes 1 de diciembre ha sido lanzada la tercera actualización de Plasma 5.20, la cual solo trae (que no es poco) soluciones a los bugs encontrados en esta semana de vida del escritorio y mejoras en las traducciones. Es por tanto, una actualización 100% recomendable.
Más información: KDE
Las novedades básicas de Plasma 5.20
Os dejo las novedades más destacada de esta nueva versión son:
- La barra de tareas por defecto será la de Solo Iconos, y además será un poco más ancho (una de las primeras cosas que suelo cambiar cuando configuro mi escritorio)
- Las visualizaciones en pantalla (OSD) que aparecen al cambiar el volumen o el brillo de la pantalla (por ejemplo) se han rediseñado para ser menos intrusivas.

- Ahora se notifica cuando el sistema está a punto de agotar el espacio incluso si el directorio personal es a una partición diferente.
- Ahora se pueden componer mosaicos con las esquinas de las ventanas combinando los atajos de mosaico izquierda/derecha/arriba/abajo. Por ejemplo, pulsando Meta+flecha arriba y después la flecha izquierda para hacer el mosaico de una ventana a la esquina superior izquierda.
- Las páginas de Configuración de Inicio automático, Bluetooth, y Gestión de usuarios se han rediseñado según los estándares modernos de interfaz de usuario y se han reescrito desde cero.
- Notificaciones de monitorización y fallo de discos S.M.A.R.T

ファイルサーバーで Spotify を再生する
openSUSE Advent Calendar 2020 が始まりました。今年も完走できるのか!?まだ空きがありますので、みなさんご協力お願いします。
みなさん、Spotify を使っていますか? Spotify は定額サブスクリプションで音楽をストリーミングで聴けるサービスです。再生クライアントはデスクトップ、モバイル各種プラットフォームに対応しており、さらに Linux 用の公式クライアントもあります。
これまで音楽を再生するときは、PC から再生するか、PCの電源が切れているときは、スマホとオーディオアンプ(AI-301DA)を Bluetooth で接続して再生していました。ただ、スマホからの再生は電池を消費するのがちょっと難点です。
ということで、常時電源が点いているファイルサーバー(もちろん OS は openSUSE)から Spotify を再生できるようにしてみました。Spotify の公式クライアントにはちょっと便利な機能があり、自身のアカウントでログインした、他のデバイスの Spotify クライアントを使ってリモートで再生することができます(Spotify Connect)。スマホの Spotify クライアントを使って、PC や Amazon Echo から再生するというのがおそらく一般的な使い方です。
ファイルサーバーにはディスプレイが接続されておらず、デスクトップ環境も動いていませんので、公式の Spotify クライアントではなく、今回は Spotifyd という OSS の非公式クライアントを使用してみました。その名の通り、デーモンとしてバックグラウンドで動作するクライアントです。
ビルド・インストール
誰かが作ったパッケージがあるにはあるのですが、今回はソースからビルドしてインストールしました。master ブランチではなく、リリース版の 0.2.24 を使います。設定ファイルのフォーマットが違う(master では TOML 形式になっている)ので、ドキュメントのバージョンには気をつけて下さい。
https://github.com/Spotifyd/spotifyd/releases/tag/v0.2.24
Rust は openSUSE Leap 15.2 で提供されているものが使えました。
$ sudo zypper in cargo alsa-devel make gcc
ドキュメントに従ってビルドします。
cargo build --release
ビルド結果は target/release/spotifyd にありますので、これをファイルサーバーの /opt/spotifyd/bin あたりに転送します。
設定
/etc/spotifyd.conf を作成します。設定例は README.md に書いてあるとおりです。 https://github.com/Spotifyd/spotifyd/blob/v0.2.24/README.md
- password: Spotify の管理画面でデバイス用のパスワードを発行しておく
- device: 書いてあるとおり
aplay -Lで使いたい出力のデバイス名を調べて下さい - cache_path: /var/cache/spotifyd あたりに設定しておきましょう
自動起動に使用する service ファイル(/etc/systemd/system/spotifyd.service)はこんな感じです。ソースコードの contrib ディレクトリ内の例からは少し変えてあります。まず、User は spotifyd ユーザーを作成して root から落としてあります。RestartSec は、spotifyd がときどき落ちていることがあったので、起動ループになると嫌だなと思い、長めに設定してみました。
[Unit] Description=A spotify playing daemon Documentation=https://github.com/Spotifyd/spotifyd<br>Wants=sound.target After=sound.target Wants=network-online.target<br>After=network-online.target [Service] ExecStart=/opt/spotifyd/bin/spotifyd --no-daemon Restart=always RestartSec=300 User=spotifyd Group=nobody Type=simple [Install] WantedBy=default.target
あとは spotifyd を起動して、クライアントからデバイスに接続できるかを試してみて下さい。
$ systemctl enable spotifyd<br>$ systemctl start spotifyd