
 Member
Member Victorhck
Victorhck#openSUSE Tumbleweed revisión de la semana 7 de 2020
Tumbleweed es una distribución “Rolling Release” de actualización contínua. Aquí puedes estar al tanto de las últimas novedades.

openSUSE Tumbleweed es la versión “rolling release” o de actualización continua de la distribución de GNU/Linux openSUSE.
Hagamos un repaso a las novedades que han llegado hasta los repositorios esta semana
El anuncio original lo puedes leer en el blog de Dominique Leuenberger, publicado bajo licencia CC-by-sa, en este enlace:
Esta semana se ha publicado 4 nuevos snapshots: 0207, 0209, 0211 and 0213, que parece ser la norma. EL último sanpshot se subirá el viernes por la tarde.
Quizás no puede parecer mucho, pero estas 4 snapshots han traido interesantes y esperadas actualizaciones a los repositorios de openSUSE Tumbleweed:
Por ejemplo:
- KDE Applications 19.12.2
- KDE Plasma 5.18
- Linux Kernel 5.5.1 ( que como en ocasiones pasadas, ha dado problemas a quienes utilizan controladores privativos de tarjetas NVIDIA ya que los controladores han llegado más tarde de lo que Tumbleweed actualiza el kernel)
Y muchas cosas están por venir en próximas actualizaciones:
- Python 3.8
- Eliminación def python 2
- glibc 2.31
- GNU make 4.3
- libcap 2.30
- RPM
- MicroOS Desktop
Si quieres estar a la última con software actualizado y probado utiliza openSUSE Tumbleweed la opción rolling release de la distribución de GNU/Linux openSUSE.
Mantente actualizado y ya sabes: Have a lot of fun!!
Enlaces de interés
-
-
- ¿Por qué deberías utilizar openSUSE Tumbleweed?
- zypper dup en Tumbleweed hace todo el trabajo al actualizar
- ¿Cual es el mejor comando para actualizar Tumbleweed?
- Comprueba la valoración de las “snapshots” de Tumbleweed
- ¿Qué es el test openQA?
- http://download.opensuse.org/tumbleweed/iso/
- https://es.opensuse.org/Portal:Tumbleweed
-

——————————–
Resumen 2019 y expectativas 2020 en GNU/Linux y FLOSS en Compilando Podcast #48
Afortunadamente me estoy poniendo al día con los podcast, y uno de los que más me gusta es el de Compilando Podcast. Así que, con conocimiento de causa hoy os quiero recomendar el episodio #48 Resumen 2019 y expectativas 2020 en GNU/Linux y FLOSS de Compilando Podcast, un audio que llega un poco tarde pero como todo lo bueno, llega cuando tiene que llegar.
Resumen 2019 y expectativas 2020 en GNU/Linux y FLOSS en Compilando Podcast #48
En palabras del gran Paco Estrada que sirven de introducción del episodio 48 de Compilando Podcast:
 «Primera entrega del 2020 de Compilando Podcast que , con algo de retraso, explora las novedades que nos traerá 2020 y hace balance de lo que ha sido el 2019 en GNU/Linux y el software libre y de código abierto; todo ello en las voces de :
«Primera entrega del 2020 de Compilando Podcast que , con algo de retraso, explora las novedades que nos traerá 2020 y hace balance de lo que ha sido el 2019 en GNU/Linux y el software libre y de código abierto; todo ello en las voces de :
Antonio Larrosa, Lorenzo Carbonell (Atareao), Philippe Lardy, Maribel García Arenas, Juan Febles, Eduardo Collado, Arantxa Serantes, Baltasar Ortega (un servidor), Samuel Iglesias y Jorge Lama.
Todas ellos y ellas, voces autorizadas en diferentes aspectos del FLOSS a los que agradecemos su visión para la audiencia de Compilando Podcast.
Este episodio está dedicado a la memoria de SERGI QUILES PÉREZ , gran linuxero, divulgador y mejor persona y compañero que nos dejó, muy temprano, el pasado mes de Enero. D.E.P.»
En resumen, un podcast interesante por que es una forma de ver un crisol de proyectos libres que vuelven a demostrar lo viva que está la Comunidad y que nadie puede conocer al 100% todo lo que se crea a su alrededor.
Como siempre os invito a escuchar el podcast completo y compartirlo con vuestro entorno cercano y en vuestras redes sociales.
¿Qué es Compilando Podcast?
Dentro del mundo de los audios de Software Libre, que los hay muchos y de calidad, destaca uno por la profesionalidad de la voz que lo lleva, el gran Paco Estrada, y por el mimo con el que está hecho. No es por nada que ganó el Open Awards’18 al mejor medio, un reconocimiento al trabajo realizado por la promoción .
A modo de resumen, Compilando Podcast es un proyecto personal de su locutor Paco Estrada que aúna sus pasiones y que además, nos ofrece una voz prodigiosa y una dicción perfecta.
Más información: Compilando Podcast
Novedades de las Preferencias del Sistema de Plasma 5.18 LTS #ilovefs
Con las novedades de las Preferencias del Sistema de Plasma 5.18 LTS doy finalizada la trilogía de estas en el blog. Eso no significa que vayan apareciendo noticias sobre esta buena versión que nos ha ofrecido el equipo de desarrollo de la Comunidad KDE y que pronto empezará sus versiones actualizadas.
Novedades de las Preferencias del Sistema de Plasma 5.18 LTS
Recodemos que Plasma 5.18 LTS fue lanzado el martes, y que tanto el miércoles como el jueves le he dedicado artículos a sus novedades.
Cierro hoy esta serie con las novedades de las Preferencias del Sistema, que nos llega con muchos cambios y con una nueva funcionalidad que merece la pena destacar, la telemetría.

No obstante, antes de empezar con los detalles os sigo recomendando el vídeo de presentación de Plasma 5.18 LTS y, ya que estamos a 14 de febrero, no olvides agradecer a las personas que hacen posible el Software Libre posible su trabajo.
Las Preferencias del Sistema
La novedad principal de estas Preferencias del Sistema de Plasma 5.18 radica en la introducción de la famosa y temida telemetría, de la que algún medio como Muy Linux nos hizo un adelanto y que tanta expectación levantó en el mundillo del Software Libre.
La Comunidad KDE ha decidido implementar la posibilidad de que el usuario envíe información sobre su sistema de forma automática y esta nueva funcionalidad ha recibido el nombre de «User Feedback» o «Comentarios de los usuarios».
En este punto haz que resaltar que aunque parezca una intromisión a nuestra intimidad es conveniente resaltar que no es ese el objetivo de los desarrolladores de KDE. Las intenciones de la Comunidad KDE es poder recopilar las características técnicas de los equipos en los que los usuarios ejecutan sus entornos de escritorio.
Tanto es así que:
- Son los usuarios los que deciden compartir su información sobre su instalación. Por defecto no está seleccionado.
- No se envía información personal ni de navegación. Se puede ver y auditar que ninguno de los parámetros de la telemetría lo solicita.
- Los usuarios tienen el control del deslizador de las Preferencias de los comentarios del usuario que les permite decidir cuánto le gustaría compartir con los desarrolladores de KDE.

Los desarrolladores insisten en que está información será utilizada para mejorar Plasma aún más y hacer que se adapte mejor a sus necesidades de la gran mayoría de usuarios.
Otros aspectos que han cambiado es la sección de las preferencias del Estilo de las aplicaciones y los Temas Globales (antiguo Look & Feel) con una vista en cuadrícula, con lo que ahora es más sencillo previsualizar cómo se mostrarán las aplicaciones o el escritorio Plasma tras escoger un nuevo estilo.

También se ha añadido una deslizador a la sección de Comportamiento General que controla la velocidad de aparición de las ventanas, desde desesperadamente lento a movimiento instantáneo.
Por último, se ha mejorado la función de búsqueda de las Preferencias del sistema , con lo que encontrar el ajuste del parámetro deseado es más fácil que nunca.
Y hasta aquí las novedades principales de este Plasma 5.18 LTS, una versión que nos ha ofrecido muchas novedades, que en breve (si todo va bien el martes) recibirá su primera actualización y que promete dar muchas alegrías a sus usuarios.
Más información: KDE
#ilovefs mi gratitud a estos proyectos de #softwarelibre
De nuevo un 14 de febrero. La fecha para demostrar tu amor… por el software libre

No quería dejar pasar la fecha de este 14 de febrero, y un año más unirme a la campaña #ilovefs creada por la Free Software Foundation Europe (fsfe)
En este día de los enamorados la fsfe propone demostrar públicamente nuestro afecto, simpatía, gratitud o amor por algún proyecto de software libre y sobre todo por las personas que están detrás.
Es un buen momento (como cualquier otro) para enviar un correo, o un mensaje a alguien implicado en un proyecto de software libre agradeciéndole el que dedique su tiempo y esfuerzo en crear algo así. También estaría bien apoyarlo con algo de dinero… 
Este año quiero mandar mi afecto a tooooooodas las personas (de la primera a la última) que de alguna forma colaboran en estos proyectos de software libre, que son los que más utilizo en mi día a día.
- Mi distribución de GNU/Linux: openSUSE
- Mi entorno de escritorio y mucho más: kde
- Mi navegador web: firefox
- Mi cliente de correo: thunderbird
- Mi gestor de ventanas alternativo a Plasma: i3wm
- Mi red social: Mastodon
- Mi reciente red social: Pixelfed
- Mi nube privada: NextCloudPi gracias a NextCloud
- La tienda de aplicaciones para móviles: f-droid
- La aplicación que uso para comunicarme en Mastodon: tusky
- La comunidad de software libre de la que soy socio: KDE España
- El reproductor de música que utilizo (principalmente: moc
Y muchos otros que me dejo en el tintero. Pero este año quería dedicarlo a las personas que desarrollan, testean, reportan, traducen, parchean, difunden, promocionan, hablan o escriben sobre estos proyectos que son los que más utilizo diariamente.
Si te encuentras dentro de este grupo, un abrazo es para ti, y muuuchas gracias.
Y no quería dejar pasar la ocasión sin dedicarle también un recuerdo y un abrazo al amigo Replicante, creador y editor durante muchos años de la grandérrima web: lamiradadelreplicante.com
El 22 de mayo hará 1 año que escribió su último artículo. Para mí era un sitio de consulta, y el Replicante un tipo con buenas dotes de escritura y comunicación. Me gustaba su web y los artículos y el toque personal que les daba.
Se le echa de menos… espero que si vuelve a tener ganas y tiempo retome su proyecto y nos siga deleitando con sus historias geeks. Compa, si te llega esto, un abrazo y se te echa de menos. Gracias por tanto!!
No dejes pasar la ocasión. Entre abrazo y abrazo a tu pareja si la tienes, manda un abrazo virtual a la persona relacionada con el software libre que prefieras!!

openSUSE Tumbleweed – Review of the week 2020/07
Dear Tumbleweed users and hackers,
At SUSE we had so-called hackweek. Meaning everybody could do something out of their regular tasks and work for a week on something else they wish to invest time on. I used the time to finally get the ‘osc collab’ server back in shape (Migrated from SLE11SP4 to Leap 15.1) – And in turn handed ‘The Tumbleweed Release Manager hat’ over to Oliver Kurz, who expressed an interest in learning about the release Process for Tumbleweed. I think it was an interesting experiment for both of us: for him, to get something different done and for me to get some interesting questions as to why things are the way they are. Obviously, a fresh look from the outside gives some interesting questions and a few things translated in code changes on the tools in use (nothing major, but I’m sure discussions will go on)
As I stepped mostly back this week and handed RM tasks over to Oliver, that also means he will be posting the ‘Review of the week’ to the opensusefactory mailing list. For my fellow blog users, I will include it here directly for your reference.
What was happening this week and included in the published snapshots:
* KDE Applications 19.12.2
* KDE Plasma 5.18
* Linux Kernel 5.5.1 (which as some times in before posed a problem for owners
of NVIDIA cards running proprietary drivers when Tumbleweed is too fast and
drivers are not yet provided by NVIDIA in time for the new kernel version)²
What is still ongoing or in the process in stagings:
* Python 3.8 (salt, still brewing but progressing)
* Removal of python 2 (in multiple packages)
* glibc 2.31 (good progress but not done)
* GNU make 4.3
* libcap 2.30: breaks fakeroot and drpm
* RPM: change of the database format to ndb
* MicroOS Desktop³
Have fun,
Oliver

Call for Papers, Registration Opens for openSUSE + LibreOffice Conference
Planning for the openSUSE + LibreOffice Conference has begun and members of the open-source communities can now register for the conference. The Call for Papers is open and people can submit their talks until July 21.
The following tracks can be selected when submitting talks related to openSUSE:
-
a) openSUSE
-
b) Open Source
-
c) Cloud and Containers
-
d) Embedded.
The following tracks can be selected when submitting talks related to LibreOffice:
-
a) Development, APIs, Extensions, Future Technology
-
b) Quality Assurance
-
c) Localization, Documentation and Native Language Projects
-
d) Appealing Libreoffice: Ease of Use, Design and Accessibility
-
e) Open Document Format, Document Liberation and Interoperability
-
f) Advocating, Promoting, Marketing LibreOffice
Talks can range from easy to difficult and there are 15 minute, 30 minute and 45 minute slots available. Workshops and workgroup sessions are also available and are planned to take place on the first day of the conference.
Both openSUSE and LibreOffice are combining their conferences (openSUSE Conference and LibOcon) in 2020 to celebrate LibreOffice’s 10-year anniversary and openSUSE’s 15-year anniversary. The conference will take place in Nuremberg, Germany, at the Z-Bau from Oct. 13 to 16.
How to submit a proposal
Please submit your proposal to the following website: https://events.opensuse.org/conferences/oSLO
-
Create an account if you don’t already have one.
-
Your proposal must be written in English and be no longer than 500 words.
-
Please run spell and grammar checkers for your proposal before submission.
-
Your biography on your profile page is also a reviewed document. Please do not forget to write your background.
-
You must obey openSUSE Conference code of conduct: https://en.opensuse.org/openSUSE:Conference_code_of_conduct
-
It is recommended that you use the slide deck of what ever organization you choose to represent. The openSUSE slide decks are located at https://github.com/openSUSE/artwork/tree/master/slides and the LibreOffice slide deck is located at https://extensions.libreoffice.org/templates/libreoffice-presentation-templates
Guide to write your proposal
Please write your proposal so that it is related to one or more topics. For example, if your talk is on security or desktop, it is better that it contains how to install that applications or demo on openSUSE. Please clarify what the participants will learn from your talk.
-
The introduction of main technology or software in your talk
-
The main topic of your talk
Only workshop: please write how to use your time and what you need.
-
We recommend writing a simple timetable on your proposal
-
Please write the necessary equipment (laptops, internet access) to the Requirement field
Travel Support
The speakers are eligible to receive sponsorship from either the openSUSE Travel Support Program (TSP) or the LibreOffice’s Travel Policy process. Those who wish to use travel support should request the support well in advance. The last possible date to submit a request from openSUSE’s TSP is Sept. 1.
- Please refer to the following URL for how to apply for travel support: https://en.opensuse.org/openSUSE:Travel_Support_Program
Visa
For citizens who are not a citizen of a Schengen country in Europe, you may need a formal invitation letter that fully explains the nature of your visit. An overview of visa requirements/exemptions for entry into the Federal Republic of Germany can be found at the Federal Foreign Office website. If you fall into one of the categories requiring an invitation letter, please email ddemaio (@) opensuse.org with the email subject “openSUSE + LibreOffice Conference Visa”.
Other requirements for a visa state you must:
-
Have a valid passport
-
Have enough money for each day of their stay)
-
Be able to demonstrate the purpose of your stay to border officials
-
Pose no threat to public order, national security or international relations
Más novedades de Plasma 5.18
El martes fue lanzado, ayer comente las su novedades generales y hoy toca hablar de más novedades de Plasma 5.18 LTS, otro repaso a todo lo que nos han preparado los desarrolladores de la Comunidad y que será afinado a lo largo de los 2 años de soporte para este nuevo entorno de trabajo.
Más novedades de Plasma 5.18
Como dije ayer, muchas son las novedades que nos ofrece el nuevo entorno de trabajo de la Comunidad KDE. Tantas que he realizado un conteo de todas las que aparecen en el changelog y me han aparecido 1276, lo cual es un número más que considerable.
Ayer hablé de las generales y este jueves quiero comentar las de las Notificaciones y Discover, pero antes os sigo recomendando el vídeo de presentación de Plasma 5.18 LTS.
Notificaciones
Este elemento cada vez más importante de los sistemas operativos ha recibido un ligero lavado de cara. Ahora están en consonancia con el estilo de Plasma (más redondeado y suave) y el indicador de cuenta atrás de las notificaciones, que también es circular y rodea al botón de cierre, proporcionando un aspecto más compacto y moderno.
Además, las notificaciones han recibido algunas nuevas funcionalidades como:
- Notificaciones cuando los dispositivos Bluetooth conectados se estén quedando sin batería.
- Más interacciones con las notificaciones ya que, por ejemplo, ahora podremos arrastrar desde la notificación el archivo descargado hasta donde queramos guardarlo.

Discover
Una aplicación básica para el ecosistema KDE es Discover. Es evidente que muchos usuarios no son muy amigos de un instalador gráfico, pero para los nuevos usuarios es algo básico disponer de un gestor de software visual que les ayude a instalar, eliminar y actualizar aplicaciones y bibliotecas con solo unos clics.
En esta nueva versión, al abrir Discover en Plasma 5.18, el cursor estará situado en el campo de búsqueda con lo que buscar los programas que quiera instalar se hace más sencillo.

Además, esta versión de Discover ha pulido más de 90 detalles bajo el capó como la limpieza de información superflua y se ha introducido la telemetría, la cual se debe activar ya que por defecto no lo está.
Más información: KDE
Juega al mítico juego de “snake” en la consola de #Linux
Puedes jugar en la consola de tu distribución de GNU/Linux al juego de la serpiente o “snake” escrito en lenguaje Rust

A veces también hay que disfrutar y dar a conocer la parte lúdica que puede tener la línea de comandos de GNU/Linux. Si hace unas semanas podíamos pasar el rato jugando al juego del ahorcado programado en Bash, hoy podemos disfrutar del juego de “snake” programado en Rust y disponible para GNU/Linux publicado bajo una licencia MIT.
Además de pasar un buen rato jugando, también podemos disfrutar (como buenos geeks que somos) echando un vistazo al código fuente del programilla y viendo cómo está escrito y lo mejor de todo, atreviéndonos a mejorarlo incorporando cosas que nos parezcan interesantes.
Para poder jugar a este juego, podemos descargarlo desde su repositorio en GitHub:
Podemos descargar la aplicación ya precompilada para GNU/Linux, darle permisos de ejecución (ya sabes: chmod +x <nombre_de_archivo> y disponernos a jugar. Y si queremos podemos descargar el código fuente y compilarlo el código en Rust en nuestro equipo (información en su README).
Tenemos algunas opciones de juego que podemos seleccionar al arrancar la aplicación. Podemos jugar solos o con otro jugador. Podemos seleccionar el modo de juego fácil o difícil, este último hace que la serpiente se mueva más deprisa.
La de horas que pasaría jugando yo a este juego en un antiquísimo Nokia, allá en los comienzos de la telefonía móvil… Ahora puedo matar el ratillo volviendo a jugar en la consola con esta pequeña aplicación.
Como dice el “lema” de openSUSE: Have a lot of fun!

People of openSUSE: An Interview with Ish Sookun
Can you tell us a bit about yourself?
I live on an island in the middle of the Indian Ocean (20°2’ S, 57°6’ E), called Mauritius. I work for a company that supports me in contributing to the openSUSE Project. That being said, we also heavily use openSUSE at the workplace.
Tell us about your early interaction with computers ? How your journey with Linux got started?
My early interaction with computers only started in the late years of college and I picked up Linux after a few students who were attending the computer classes back then whispered the term “Linux” as a super complicated thing. It caught my attention and I got hooked ever since. I had a few years of distro hopping until in 2009 I settled down with openSUSE.
Can you tell us more about your participation in openSUSE and why it started?
I joined the “Ambassador” program in 2009, which later was renamed to openSUSE Advocate, and finally the program was dropped. In 2013, I joined the openSUSE Local Coordinators to help coordinating activities in the region. It was my way of contributing back. During those years, I would also test openSUSE RCs and report bugs, organize local meetups about Linux in general (some times openSUSE in particular) and blog about those activities. Then, in 2018 after an inspiring conversation with Richard Brown, while he was the openSUSE Chairman, I stepped up and joined the openSUSE Elections Committee, to volunteer in election tasks. It was a nice and enriching learning experience along with my fellow election officials back then, Gerry Makaro and Edwin Zakaria. I attended my first openSUSE Conference in May 2019 in Nuremberg. I did a presentation on how we’re using Podman in production in my workplace. I was extremely nervous to give this first talk in front of the openSUSE community but I met folks who cheered me up. I can’t forget the encouragement from Richard, Gertjan, Harris, Doug, Marina and the countless friends I made at the conference. Later during the conference, I was back on the stage, during the Lightning Talks, and I spoke while holding the openSUSE beer in one hand and the microphone in the other. Nervousness was all gone thanks to the magic of the community.
Edwin and Ary told me about their activities in Indonesia, particularly about the openSUSE Asia Summit. When the CfP for oSAS 2019 was opened, I did not hesitate to submit a talk, which was accepted, and months later I stood among some awesome openSUSE contributors in Bali, Indonesia. It was a great Summit where I discovered more of the openSUSE community. I met Gerald Pfeifer, the new chairman of openSUSE, and we talked about yoga, surrounded by all of the geeko fun, talks and workshops happening.
Back to your question, to answer the second part about “why openSUSE”, I can safely, gladly and proudly say that openSUSE was (and still is) the most welcoming community and easiest project to start contributing to.
Tea or coffee?
Black coffee w/o sugar please.
Can you describe us the work of the Election Committee ? What challenges is it facing when elections time comes?
An election official should be familiar with the election rules. These help us plan an election and set the duration for every phase. The planning phase is crucial and it requires the officials to consult each other often. Some times being in time zones that are hours apart it is not obvious to hold long hours chats. We then rely on threaded emails that then takes more time to reach consensus on a matter. The election process becomes challenging if members do not step up for board candidacy as the deadline approaches. When the election begins, the next challenge is to not miss out any member. We make sure that we obtain an up-to-date list of openSUSE members and that they receive their voter link/credentials. We attend to requests from members having issues finding the email containing their voter link. Very often it ends up being something trivial as members using two different email addresses; one on the mailing list and a different one in their openSUSE Connect account.
I call these challenges to address the question but in reality it’s fun to be part of all this and ensure everything runs smoothly. Gerry has set a good example in the 2018-2019 Board election, which we still follow. Edwin has been extremely supportive in the three elections where we worked together. Recently joined, Ariez Vachha has proven to be a great addition to the team.
What do you like the most about being involved in the community?
The people.
What is one feature, project, that you think needs more attention in openSUSE?
Documentation.
What side projects/hobbies you work on outside of openSUSE?
I experiment with containers using Podman. It’s a fairly recent love but it keeps me busy. Community-wise, I like to attend local meetups, events and blog about those activities. I often help with the planning or any other task within my capacity for the Developers Conference of Mauritius. It’s a yearly event that brings the local geeks together for three days of fun. Luckily I have a supportive wife who bears with the geek tantrums and she volunteers in some of the community activities too. Oh, I might get kicked if I do not mention and give her credit for the openSUSE Goodies packs she prepares for my local talks.
What is your desktop environment of choice / preferred desktop setup?
GNOME until recently. I switched to KDE after my developer colleagues would not stop bragging about how good their KDE environment is and my GNOME/Wayland environment started acting weird.
What is your favorite food?
Paneer Makhani (Indian cottage cheese in spicy curry gravy).
What do you think the future holds for the openSUSE project?
With the example set by the openSUSE Asia community, I think the future of the project is having a strong openSUSE presence on every habitable continent.
Any final thoughts or message to our readers?
Let’s paint the world green!
Do you CI?
When I ask ask people about their approach to continuous integration, I often hear a response like
“yes of course, we have CI, we use…”.
When I ask people about doing continuous integration I often hear “that wouldn’t work for us…”
It seems the practice of continuous integration is still quite extreme. It’s hard, takes time, requires skill, discipline and humility.
What is CI?
Continuous integration is often confused with build tooling & automation. CI is not something you have, it’s something you do.
Continuous integration is about continually integrating. Regularly (several times a day) integrating your changes (in small & safe chunks) with the changes being made by everyone else working on the same system.
Teams often think they are doing continuous integration, but are using feature branches that live for hours or even days to weeks.
Code branches that live for much more than an hour are an indication you’re not continually integrating. You’re using branches to maintain some degree of isolation from the work done by the rest of the team.
I like the current Wikipedia definition: “continuous integration (CI) is the practice of merging all developer working copies to a shared mainline several times a day.”
I like this description. It’s worth calling out a few bits.
CI is a practice. Something you do, not something you have. You might have “CI Tooling”. Automated build/test running tooling that helps check all changes.
Such tooling is good and helpful, but having it doesn’t mean you’re continually integrating.
Often the same tooling is even used to make it easier to develop code in isolation from others. The opposite of continuous integration.
I don’t mean to imply that developing in isolation and using the tooling this way is bad. It may be the best option in context. Long lived branches and asynchronous tooling has enabled collaboration amongst large groups of people across distributed geographies and timezones.
CI is a different way of working. Automated build and test tooling may be a near universal good. (even a hygiene factor). The practice of Continuous Integration is very helpful in some contexts, even if less universally beneficial.
…all developer working copies…
All developers on the team integrating their code. Not just small changes. If bigger features are worked on in isolation for days or until they’re complete you’re not integrating continuously.
…to a shared mainline…
Code is integrated into the same branch. Often “master” in git parlance. It’s not just about everyone pushing their code to be checked by a central service. It’s about knowing it works when combined with everyone else’s work in progress, and visible to the rest of the team.
…several times a day
This is perhaps the most extreme part. The part that highlights just how unusual a practice continuous integration really is. Despite everyone talking about it.
Imagine you’re in a team of five developers, working independently, practising CI. Aiming to integrate your changes roughly once an hour. You might see 40 commits to master in a single day. Each commit representing a functional, working, potentially releasable state of the system.
(Teams I’ve worked on haven’t seen quite such a high commit rate. It’s reduced by pairing and non-coding work; nonetheless CI means high rate of commits to the mainline branch)
Working in this way is hard, requires a lot of discipline and skill. It might seem impossible to make large scale changes this way at first glance. It’s not surprising it’s uncommon.
To visualise the difference
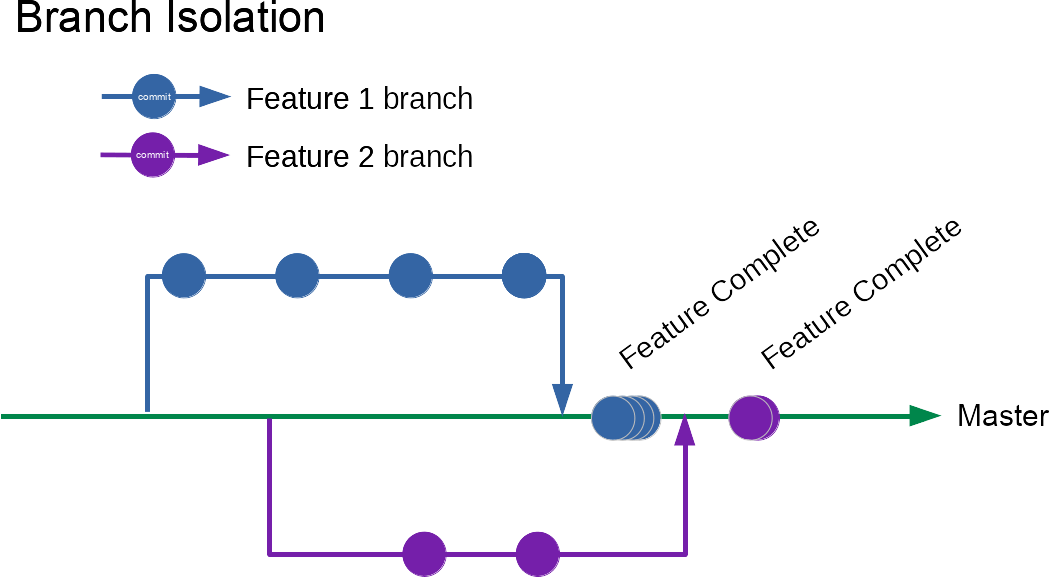
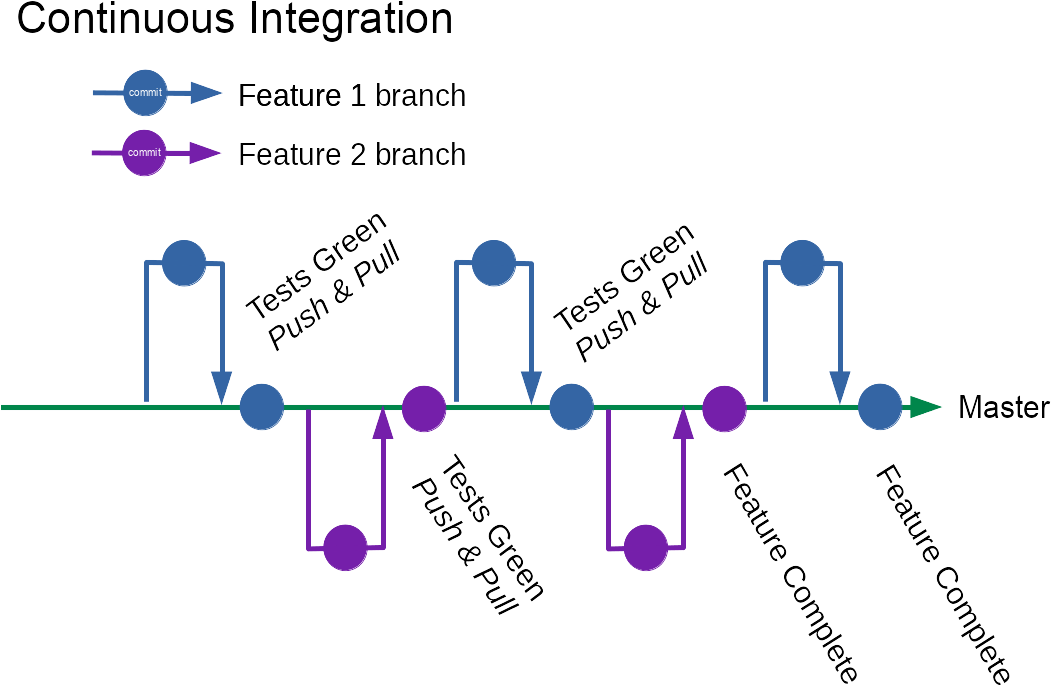
Why CI?
Get Feedback
Why would work work in such a way? Integrating our changes will incur some overhead. It likely means taking time out every single hour to review changes so far, tidy, merge, and deal with any conflicts arising.
Continuously integrating helps us get feedback as fast as possible. Like most Extreme Programming practices. It’s worth practising CI if that feedback is more valuable to you than the overhead.
Team mates
We may get feedback from other team members—who will see our code early when they pull it. Maybe they have ideas for doing things better. Maybe they’ll spot a conflict or an opportunity from their knowledge and perspective. Maybe you’ve both thought to refactor something in subtly different ways and the difference helps you gain a deeper insight into your domain.
Code
CI amplifies feedback from the code itself. Listening to this feedback can help us write more modular, supple code that’s easier to change.
If our very-small change conflicts with another working on a different feature it’s worth considering whether the code being changed has too many responsibilities. Why did it need to change to support both features? Modularity is promoted by CI creating micro-pain from multiple people changing the same thing at the same time.
Making a large-scale change to our system via small sub-hour changes forces us to take a tidy-first approach. Often the next change we want to make is hard, not possible in less than an hour. Instead of taking our preconceived path towards our preconceived design, we are pressured to first make the change we want to make easier. Improve the design of the existing code so that the change we want to make becomes simple.
Even with this approach we’re unlikely to be able to make large scale changes in a single step. CI encourages mechanisms for integrating the code for incomplete changes. Such as branch by abstraction which further encourages modularity.
CI also exerts pressure to do more and better
If our tests are brittle—coupled to the current structure of the code rather than the important behaviour then they will fail frequently when the code is changed. If our tests are slow then we’d waste lots of time running regularly, hopefully incentivising us to invest in speeding them up.
Continuous integration of small changes exposes us to this feedback regularly.
If we’re integrating hourly then this feedback is also timely. We can get feedback on our code structure and designs before it becomes expensive to change direction.
Production
CI is a useful foundation for continuous delivery, and continuous deployment. Having the code always in an integrated state that’s safe to release.
Continuously deploying (not the same as releasing) our changes to production enables feedback from customers, users, its impact on production health.
Combat Risk
Arguably the most significant benefit of CI is that it forces us to make our changes in small, safe, low-risk steps. Constant practice ensures it’s possible when it really matters.
It’s easy to approach a radical change to our system from the comforting isolation of a feature branch. We can start pulling things apart across the codebase and shaping them into our desired structure. Freed from the constraints of keeping tests passing or even our code compiling. Coming back to getting it working, the code compiling, and the tests compiling afterwards.
The problem with this approach is that it’s high risk. There’s a high risk that our change takes a lot longer than expected and we’ll have nothing to integrate for quite some time. There’s a high risk that we get to the end and discover unforeseen problems only at integration time. There’s a high risk that we introduce bugs that we don’t detect until after our entire change is complete. There’s a high risk that our product increment and commercial goals are missed because they are blocked by our big radical change. There’s a risk we feel pressured into rushing and sacrificing code quality when problems are only discovered late during an integration phase.
CI liberates us from these risks. Rather than embarking on a grand plan all at once, we break it down into small steps that we can complete and integrate swiftly. Steps that only take a few mins to complete.
Eventually the accumulation of these small changes unlock product capabilities and enable releasing value. Working in small steps becomes predictable. No longer is there a big delay from “we’ve got this working” to “this is ready for release”
This does not require us to be certain of our eventual goal and design. Quite the opposite. We start with a small step towards our expected goal. When we find something hard, hard to change then we stop and change tack. First making a small refactoring to try and make our originally intended change easy to make. Once we’ve made it easy we can go back and make the actual change.
What if we realise we’re going in the wrong direction? Well we’ve refactored our code to make it easier to change. What if we’ve made our codebase better for no reason? We’ve still won.
Collaborate Effectively
Meetings are not always popular. Especially ceremonies such as standups. Nevertheless it’s important for a team of people working towards a common goal to understand where each other have got to. To be able to react to new information, change direction if necessary, help each other out.
The more we work separately in isolation, the more costly and painful synchronisation points like standups can become. Catching each other up on big changes in order to know whether to adjust the plan.
Contrast this with everyone working in small, easy to digest steps. Making their progress visible to everyone else on the team frequently. It’s more likely that everyone already has a good idea of where the rest of the team is at and less time must be spent catching up. When everyone on the team is aware of where everyone else has got to the team can actually work as team. Helping each other out to speed a goal.
No-one likes endless discussions that get in the way of making progress. No-one likes costly re-work when they discover their approach conflicts with other work in the team. No-one likes wasting time duplicating work. CI enables constant progress of the whole team, at a rate the whole team can keep up with.
Arguably the most extreme continuous integration is mob programming. The whole team working on the same thing, at the same time, all the time.
Obstacles
“but we’re making a large scale change”
We touched on this above. It’s usually possible to make a large scale change via small, safe, steps. First making the change easier, then making the change. Developing new functionality side by side in the same codebase until we’re satisfied it can replace older functionality.
Indeed the discipline required to make changes this way can be a positive influence on code quality.
“but code review”
Many teams have a process of blocking code review prior to integrating changes into a mainline branch. If this code review requires interrupting someone else every few minutes this may be impractical.
Continuous integration like requires being comfortable with changes being integrated without such a blocking pull-request review style gate.
It’s worth asking yourself why you do such review and whether a blocking approach is the only way. There are alternatives that may even achieve better results.
Pair programming means all code is reviewed at the point in time it was written. It also gives the most timely feedback from someone else who fully understands the context. Pairing tends to generate feedback that improves the code quality. Asynchronous reviews all too often focus on whether the code meets some arbitrary bar—focusing on minutiae such as coding style and the contents of the diff, rather than the implications of the change on our understanding of the whole system.
Pair programming doesn’t necessarily give all the benefits of a code review. It may be beneficial for more people to be aware of each change, and to gain the perspective of people who are fresher or more detached. This can be achieved to a large extent by rotating people through pairs, but review may still be useful.
Another mechanism is non-blocking code review. Treating code review more like a retrospective. Rather than “is this code good enough to be merged” ask “what can we learn from this change, and what can we do better?”.
Consider starting each day reviewing as a team the changes made the previous day and what you can learn from them. Or stopping and reviewing recent changes when rotating who you are pair-programming with. Or having a team retrospective session where you read code together and share ideas for different approaches.
“but master will be imperfect”
Continuous integration implies master is always in an imperfect state. There will be incomplete features. There may be code that would have been blocked by a code review. This may seem uncomfortable if you strive to maintain a clean mainline that the whole team is happy with and is “complete”.
Imperfection in master is scary if you’re used to master representing the final state of code. Once it’s there being unlikely to change any time soon. In such a context being protective of it is a sensible response. We want to avoid mistakes we might need to live with for a long time.
However, an imperfect master is less of a problem in a CI context. What is the cost of a coding style violation that only lives for a few hours? What is the cost of temporary scaffolding (such as a branch by abstraction) living in the codebase for a few days?
CI suggests instead a habitable master branch. A workspace that’s being actively worked in. It’s not clinically clean, it’s a safe and useful environment to get work done in. An environment you’re comfortable spending lots of time in. How clean a workspace needs to be depends on the context. Compare a gardeners or plumbers’ work environment to a medical work environment.
“but how will we test it?”
Some teams separate the activities of software development from software testing. One pattern is testing features when each feature is complete, during an integration and stabilisation phase.
This allows teams to maintain a master branch that they think works, with uncertain work in progress in isolation.
However thorough our automated, manual, and exploratory testing we’re never going to have perfect software quality. Integration-testing might be a pattern to ensure integrated code meets some arbitrary quality bar but it won’t be perfect.
CI implies a different approach. Continuous exploratory testing of the master version. Continually improving our understanding of the current state of the system. Continuously improving it as our understanding improves. Combine this with TDD and high levels of automated checks and we can have some confidence that each micro change we integrate works as intended.
Again, this sort of approach requires being comfortable with master being imperfect. Or perhaps a recognition that it is always going to be imperfect, whatever we do.
“but we need to be able to do bugfixes”
Many teams work in batches. Deploying and releasing one set of features, working on more features in feature branches, then integrating, deploying, and releasing the next batch.
Under this model they can keep a branch that represents the current deployed version of the software. When an urgent bug is discovered in production they can fix it on this branch and deploy just that change.
From such a position the prospect of making a bugfix on top of a bunch of other already integrated changes might seem alarming. What if one of our other changes causes a regression.
CI is a fundamentally different way of working. Where our current state of master always captures the team’s current understanding of the most progressed, safest, least buggy system. Always deployable. Zero-bugs (bugs fixed when they’re discovered). Constantly evolving through small, safe steps.
A good way to make it safe to deploy bugfixes in a CI context is to also practise continuous deployment. Every micro-change deployed to production (not necessarily released). Doing this we’ll always have confidence we can deploy fixes rapidly. We’re forced to ensure that master is always safe for bugfixes.
“but…”
There’s also plenty of circumstances in which CI is not feasible or not the right approach for you. Maybe you’re the only developer! Occasional integration works well for sporadic collaboration between people with spare time open source contributions. For teams distributed across wide timezones there’s less benefits to CI. You’re not going to get fast feedback while your colleague is asleep! You can still work in and benefit from small steps regardless of whether anyone is watching.
Sometimes feedback is less important than hammering out code. If you’re working on something that you could do in your sleep and all that holds you back is how fast you can hammer out lines of code. The value of CI is much less.
Perhaps your team is very used to working with long lived branches. Used to having the code/tests broken for extended periods while working on a problem. It’s not feasible to “just” switch to a continuous integration style. You need to get used to working in small, safe, steps.
How…
Try it
Make “could we integrate what we’ve done” a question you ask yourself habitually. It fits naturally into the TDD cycle. When the tests are green consider integration. It should be safe.
Listen to the feedback
Listen to the feedback. Ok, you tried integrating more frequently and something broke, or things were slower. Why was that really? How could you avoid similar problems occurring while still being able to integrate regularly?
Tips when it’s hard
Combine with other Extreme Programming practices.
CI is easier with other Extreme Programming practices, not just TDD—which makes it safer and lends a useful cadence to development .
It’s easier when pair programming. Someone else helping remember the wider context. Someone to suggest stepping back and integrating a smaller set before going down a rabbit hole. Pairing also helps our chances of each change being safe to make. It’s more likely that others on the team will be happy with our change if our pair is on board.


CI is a lot easier with collective ownership. Where you are free to change any part of the codebase to make your desired change easy.
When your change is hard to do in small steps, first tackle one thing that makes it hard. “First make the change easy”
Separate expanding and contracting. Start building your new functionality in several steps alongside the old, then migrate existing usages, then finally remove the old. This can be done in several steps.
Separate integrating and releasing. Integrating your code should not mean that the code necessarily affects your users. Make releasing a product/business decision with feature toggles.
Invest in fast tooling. If your build and test suite takes more than 5 minutes you’re going to struggle to do continuous integration. A 5 min build and test run is feasible even with tens of thousands of tests. However, it does require constant investment in keeping the tooling fast. This is a cost of CI, but it’s also a benefit. CI requires you to keep the tooling you need to safely integrate and release a change fast and reliable. Something you’ll be thankful for when you need to make a change fast.
That’s a lot of work…
Unlike having CI [tooling], doing CI is not for all teams. It seems uncommonly practised. In some contexts it’s impractical. In others it’s not worth the overhead. Maybe worth considering whether the feedback and risk reduction would help your team.
If you’re not doing CI and you try it out, things will likely be hard. You may break things. Try to reflect deeper than “we tried it and it didn’t work”. What made it hard to work in and integrate small changes? Should you address those things regardless?
The post Do you CI? appeared first on Benji's Blog.