
 Member
Member Futureboy
FutureboyWindscribe VPN on openSUSE


Comparing uptime performance monitoring tools: StatusCake vs Freshping vs UptimeRobot
When you host your own website on a Virtual Private Server or on a DigitalOcean droplet, you want to know if your website is down (and receive a warning when that happens). Plus it’s fun to see the uptime graphs and the performance metrics. Did you know these services are available for free?
I will compare 3 SaaS vendors who offer uptime performance monitoring tools. Of course, you don’t get the full functionality for free. There are always limitations as these vendors like you to upgrade to a premium (paid) account. But for an enthousiast website, having access to these free basic options is already a big win!
I also need to address the elephant in the room: Pingdom. This is the golden standard of uptime performance monitoring tools. However, you will pay at least €440 per year for the privilege. That is a viable option for a small business. Not for an enthousiast like myself.
The chosen free alternatives are StatusCake, Freshping and UptimeRobot. There are many other options, but these ones are mentioned in multiple lists of ‘the best monitoring tools’. They also have user friendly dashboards. So let’s run with it.
StatusCake
The first option that I have tried is StatusCake. This tool not only offers the uptime monitoring, but also offers a free SpeedTest. Of course you can use the free speedtests of Google and Pingdom. But this won’t allow you to see the day-to-day differences.
The images below show the default dashboard for uptime monitoring, the detailed uptime graph for one URL and the webform for creating a new uptime test.



The next images show the default dashboard for speed tests, the detailed speed graph results and the webform for creating a new speed test.



The basic plan is free and this gets you 10 uptime tests and 1 page speed test. A paid superior plan will set you back €200 per year, which is way to much for an enthousiast like myself.

Freshping
Freshping is the second alternative that I tried. This is a Freshworks tool, so that means that it works together with other Freshworks tools such as Freshdesk, Freshsales, Freshmarketeer, Freshchat and Freshstatus. And all of these tools have a free tier. Wow, that is a lot of value for a start-up business. Of course they will like you to upgrade later on and stay with their company.

However, we are now focussing on Freshping. The below images show the default dashboard, the detailed uptime graph for one URL and the webform for creating a new uptime test.



It looks nice, but it gives you much less information than StatusCake. However they do provide value. The sprout plan is free and this gets you 50 uptime tests. A paid blossom account will set you back €119 per year. That looks cheap, but it won’t get you SSL monitoring (which is included in the paid StatusCake plan). So you will need to pay €389 per year to get this functionality. And that is too close to Pingdom, if you are only interested in uptime performance monitoring.

UptimeRobot
The last alternative that I tried is UptimeRobot. The big advantage of this tool is that the paid plan is very cheap. So let’s get to that first. The basic plan is free and this gets you 50 uptime tests. So it does offer value. A paid pro plan costs €49 per year, which is a surmountable ammount for an enthousiast like myself. This will include SSL monitoring.

So what do you get? The images below show the default dashboard for uptime monitoring, the detailed uptime graph for one URL and the webform for creating a new uptime test.



The user interface of UptimeRobot is fairly minimalistic. And you need to like the gray/green color combination (I am looking at you openSUSE and Linux Mint users). But the interface is easy enough to use. I find the graphs lacking in detail.
Conclusion
When comparing the free plans of StatusCake, Freshping and UptimeRobot the winner is StatusCake by a sizable margin. It not only offers uptime monitoring, but also 1 speed test. It provides detailed information on the graphs and you also see the information in tables that can be easily sorted.
When comparing the paid plans from the viewpoint of an enthousiast website owner, the winner is UptimeRobot. They offer both uptime testing and SSL monitoring for €49 per year. Which is a surmountable price.
Looking at these altenatives from the perspective of a startup business, Freshping starts to look more interesting. But a startup business would be better off by using the other Freshworks products and either pay less for UptimeRobot or pay a little bit more for a Pingdom standard plan.
Published on: 17 January 2020

Q&A for openSUSE Board elections
Our openSUSE Chairman has some questions for the candidates for the openSUSE Board. My answers are here:
1. What do you see as three, four strengths of openSUSE that we should cultivate and build upon?
1) Fantastic coherence in the community
2) Great products with collaboration all over the world
3) Quality
2. What are the top three risks you see for openSUSE? (And maybe ideas how to tackle them?)
1) Dependency on SUSE (humans and financials)
Background: I was asked really often at open source events how another company can sponsor openSUSE. We had to say that it would not possible because all of our money is going via a SUSE credit card and the money would be lost (same with the GSoC money, which has to be transferred to other organizations because of this issue). No company wants to pay Open Source Developers with such a background of an open-source project. Therefore, most openSUSE Contributors are working for SUSE or SUSE Business Partners. This topic popped up more than 3 times during my last Board Membership (really created by SUSE employees each time!).
Solution: Creation of the foundation! I had to suggest this solution more than 3 times before that was accepted by SUSE employees in the Board. I told about all the benefits how we can manage our own money then, receive new sponsors, SUSE can use more money for their own, SUSE can sponsor us continuously and we would be able to receive more Contributors.
2) openSUSE infrastructure in Provo
Background: I am one of the Founders of the openSUSE Heroes Team and was allowed to coordinate our first wiki project between Germany and Provo. The openSUSE infrastructure is in Microfocus hands and they need very long to respond on issues and we are not allowed to receive access as a community. Additionally, SUSE is not part of Microfocus any more which makes it more difficult to receive good support in the future.
Solution 1: Migration of all openSUSE systems from Provo to Nuremberg / Prague (perhaps missing space?)
Solution 2: Migration of all openSUSE systems from Provo to any German hosting data centre with access for openSUSE Heroes
3) Bad reputation of openSUSE Leap & openSUSE Tumbleweed
Background: We are the openSUSE project with many different sub-projects. We don’t offer only Linux distributions, but we are well known for that and most people are associating us with that. I had given many presentations about openSUSE during my last Board Membership and represented us at different open source events. The existing openSUSE Board does not do that very much. They have another focus at the moment.
Solution: We need more openSUSE Contributors representing openSUSE and I can do that as an openSUSE Board Member again. After that, we can be one of the top Linux distributions again. 
3. What should the board do differently / more of?
The existing openSUSE Board is working mostly on the topic with the foundation. That is good. Thank you! But the role of a Board Member contains the representation of the community, too. We would have one less risk with that.
4. If you had a blank voucher from the SUSE CEO for one wish, what would that be?
I wish the start financing of the foundation for openSUSE. Both sides will profit from that. 
5. What is your take on the Foundation? What do you consider a realistic outcome of that endeavour? (And if different, what outcome would you like to see?)
The Foundation is a benefit for SUSE and openSUSE (see risk 1). SUSE can support and contribute to us continuously. The difference is that we are open for other sponsoring companies then. Google Summer of Code money can be used for Travel Support. We can say how much money can be used for every openSUSE event/ Summit (without any eye on the situation of SUSE). We can manage that all for our own. If we can accept more companies as sponsors, SUSE can invest the saved money into the own company or in other open-source projects. We become more open and that is a reason for companies to invest money into jobs as Open Source Developers for us. So the community can grow with more companies as sponsoring partners.
The post Q&A for openSUSE Board elections first appeared on Sarah Julia Kriesch.
Comparing perf.data files with perf-diff
Being a performance engineer (or an engineer who’s mainly concerned with software performance) is a lot like being any other kind of software engineer, both in terms of skill set and the methods you use to do your work.
However, there’s one area that I think is sufficiently different to trip up a lot of good engineers that haven’t spent much time investigating performance problems: analysing performance data.
The way most people get this wrong is by analysing numbers manually instead of using statistical methods to compare them. I’ve written before about how humans are bad at objectively comparing numbers because they see patterns in data where none exist.
I watched two talks recently (thanks for the recommendation Franklin!) that riffed on this theme of “don’t compare results by hand”. Emery Berger spends a good chunk of his talk, “Performance matters” explaining why it’s bad idea to use “eyeball statistics” (note eyeball statistics is not actually a thing) to analyse numbers, and Alex Kehlenbeck’s talk “Performance is a shape, not a number” really goes into detail on how you should be using statistical methods to compare latencies in your app. Here’s my favourite quote from his talk (around the 19:21 mark):
The ops person that’s responding to a page at two in the morning really has no idea how to compare these things. You’ve gotta let a machine do it.
And here’s the accompanying slide that shows some methods you can use.

"Did behavior change?" slide from Alex Kehlenbeck's talk
Yet despite knowing these things I stil have a bad habit of eyeballing
perf.data files when comparing profiles from multiple runs. And as we’ve
established now, that’s extremely dumb and error prone. What I really should be
doing is using perf-diff.
Here’s a gist for random-syscall.c,
a small program that runs for some duration in seconds and randomly calls
nanosleep(2) or spins in userspace for 3 milliseconds. To generate some
profile data, I ran it 5 times and recorded a profile with perf-record like
this:
$ gcc -Wall random-syscall.c -o random-syscall
$ for i in $(seq 1 5); do sudo perf record -o perf.data.$i -g ./random-syscall 10; done
Executing for 10 secs
Loop count: 253404
[ perf record: Woken up 14 times to write data ]
[ perf record: Captured and wrote 3.577 MB perf.data.1 (31446 samples) ]
Executing for 10 secs
Loop count: 248593
[ perf record: Woken up 12 times to write data ]
[ perf record: Captured and wrote 3.185 MB perf.data.2 (28252 samples) ]
Executing for 10 secs
Loop count: 271920
[ perf record: Woken up 12 times to write data ]
[ perf record: Captured and wrote 3.573 MB perf.data.3 (31587 samples) ]
Executing for 10 secs
Loop count: 263291
[ perf record: Woken up 13 times to write data ]
[ perf record: Captured and wrote 3.641 MB perf.data.4 (32152 samples) ]
Executing for 10 secs
Loop count: 259927
[ perf record: Woken up 13 times to write data ]
[ perf record: Captured and wrote 3.507 MB perf.data.5 (30898 samples) ]
$ perf diff perf.data.[1-5]The output of $ perf-diff perf.data.[1-5] looks like this:
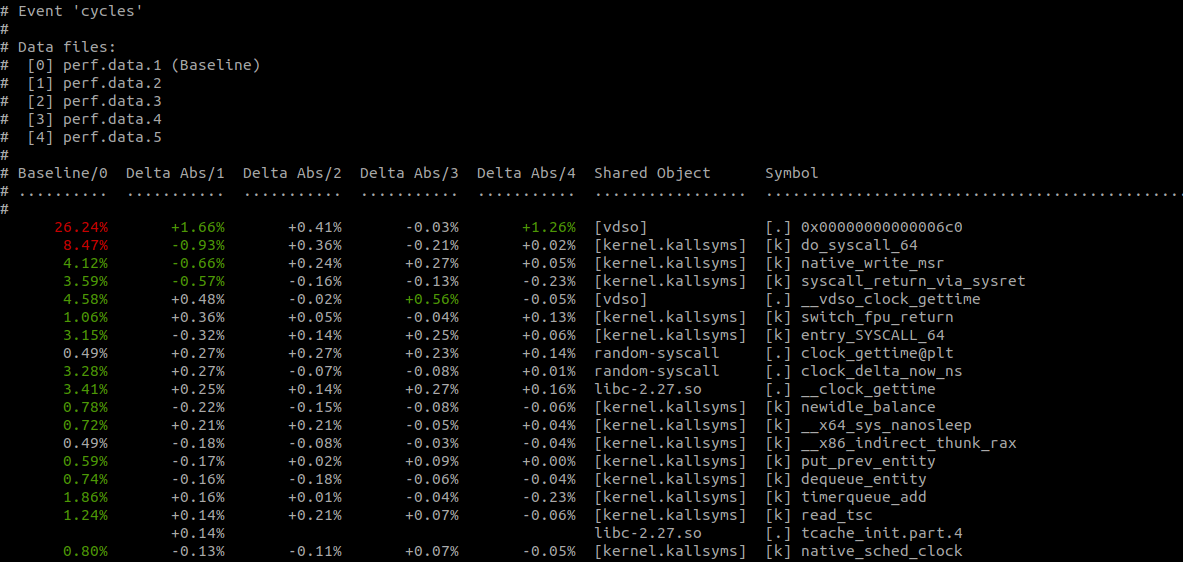
$ perf diff perf.data.[1-5]
Much better! No more eyeball statistics. As you’d expect, perf-diff
comes with the usual assortment of command-line options including
--comms (narrow the displayed results to specific programs), --sort
(order the displayed results by a given key), and --symbols (only
display provided symbols).
Dell Inspiron 20 3048 All-In-One Desktop SSD Upgrade
Kandidatur für das openSUSE Board #2: Fragen und Antworten
Bereits Anfang 2019 habe ich für das Board von openSUSE kandidiert. Nachdem inzwischen wieder zwei Plätze offen sind, stehe ich auch diesmal wieder für die Aufgabe zur Verfügung und stelle mich zur Wahl.
Einen allgemeinen Überblick über meine Vorstellungen und Ziele gibt es hier.
Im Vorfeld zur Wahl stehen alle Kandidaten der Community natürlich für Fragen offen. Einen Katalog aus 5 Fragen von Gerald Pfeifer, derzeit Chairman des Boards, habe ich beantwortet und möchte diesen auch hier bereitstellen.
Ein Hinweis: Fragen und Antworten sind ursprünglich auf Englisch. Dies ist nur eine Übersetzung.
1. Was sind deiner Meinung nach die drei, vier Stärken von openSUSE, die wir kultivieren und auf denen wir aufbauen sollten?
1) Vielfalt der Features
OpenSUSE ist vor allem für die Distributionen Leap und Tumbleweed bekannt. Die große Bandbreite der verschiedenen Teilprojekte und wie sie zusammenpassen, ist eine große Stärke. Wir sollten einen Weg finden, oS mit den ganzen Projektteilen wie YaST, OBS, openQA etc. in Verbindung zu bringen.
2) „Erbe“
Linux-Distributionen kommen und gehen, manche bleiben jahrelang, andere verschwinden in den Tiefen des Internets. OpenSUSE gibt es nun schon seit Jahrzehnten und es muss diese Tatsache in Richtung einer Anerkennung als zuverlässiger Freund für den Betrieb von Computern verändern.
3) Genehmigungsfreie Gemeinschaft
Die openSUSE-Community lebt von Menschen, die einfach Dinge tun und versuchen, andere durch Ergebnisse zu überzeugen. Das ist nicht überall bei FOSS üblich. Einige andere Gemeinschaften versuchen, die Dinge über Komitees und Oberbosse zu vereinheitlichen.
2. Was sind die drei größten Risiken, die du für openSUSE siehst? (Und vielleicht Ideen, wie man sie angehen kann?)
1) Vergessen werden
2) Teilweise unbekannt bleiben
3) Im eigenen Saft schmoren
Es könnte auch andere Risiken geben, aber diese drei passen alle zu einem großen Thema: Kommunikation – oder eher dem Fehlen einer solchen.
Meine Idee, dies anzugehen, ist es, das Marketingteam (irgendwie) wiederzubeleben und als treibende Kraft für alles, was von openSUSE in Richtung des Restes der Welt geht, zu pushen. Es gibt bereits Initiativen, Artikel zu schreiben, mit Community-Leuten in Interviews zu sprechen und neues Marketingmaterial zu erstellen. Dies erfordert natürlich Koordination und Manpower, aber es läuft bereits recht gut.
Das Marketing-Team, das ich im Sinn habe, ist eine Initiative, die in zwei Richtungen arbeitet: Neben der Arbeit in Eigenregie möchte ich es offen haben für Menschen, die Ideen, Wünsche und Projekte einbringen. Mitglieder können Tickets öffnen, Nichtmitglieder können E-Mails senden oder in Chatrooms erklären, was sie wollen oder brauchen. Die Marketingleute erledigen dann entweder die Anfrage selbst oder versuchen, jemanden zu finden, der bereit ist, dies zu tun, z.B. in Artwork, l10n oder einem anderen geeigneten Team.
Das Hauptziel ist es, einen konstanten Fluss interessanter Inhalte für den Rest der Gemeinschaft und für jeden außerhalb von openSUSE aufrechtzuerhalten.
Die Antwort auf die folgende Frage erweitert diesen Punkt noch ein wenig.
3. Was sollte der Vorstand anders / mehr tun?
Kommunizieren. Obwohl die meisten Leute hier (einschließlich mir) die Sache mit der Hierarchie nicht mögen, ist es etwas, das nicht ungenutzt bleiben sollte. Kurz gesagt: Wenn das Board etwas sagt, wird es weithin als etwas Wichtiges und Offizielles angesehen.
Obwohl das nur teilweise wahr ist und diametral zu dem steht, was der Vorstand wirklich ist (ein „Diener“ der Gemeinschaft), ist es sicherlich ein Weg, um Aufmerksamkeit für das gesamte Projekt zu gewinnen.
Ein Beispiel: Wählt relevante Dinge aus den Meetingnotizen aus, macht einen monatlichen Beitrag auf news-o-o, fügt ein nettes „Board News“ Emblem hinzu.
4. Wenn du einen Blanko-Gutschein vom SUSE-CEO für einen Wunsch hättest, welcher wäre das?
Ich würde ihn dafür verwenden, die Prozesse mit Heroes und der technischen Infrastruktur zu vereinfachen. Obwohl ich nicht so sehr Details kenne, höre ich oft, dass die Dinge langsam laufen und viel nachgebohrt werden muss. Und ich gehe davon aus, dass das, was dort öffentlich sichtbar ist, nur die Spitze des Eisbergs ist.
5. Was hältst du von der Stiftung? Was hältst du für ein realistisches Ergebnis dieses Unterfangens? (Und falls anders, welches Ergebnis würdest du gerne sehen?)
SUSE ist in rechtliche und finanzielle Angelegenheiten der Community involviert und wird sich höchstwahrscheinlich niemals zurückziehen. Und es würde sich falsch anfühlen, wenn man versuchen würde, alle Verbindungen dort zu kappen. Aber meine Vermutung und Hoffnung für die Stiftung ist, dass sie die Dinge klarer und getrennter gestalten wird.
Du hast weitere Fragen? Schreib mir!
(Quelle der Fragen ist hier.)
Running for openSUSE Board #2: Questions and Answers
Already in the beginning of 2019 I have been a candidate for the board of openSUSE. Since there are now two places open again, I am again available for the task and run for election.
A general overview of my ideas and goals can be found here.
In the run-up to the election all candidates of the community are of course open for questions. I have answered a catalogue of 5 questions from Gerald Pfeifer, currently chairman of the board, and would like to make it available here.
1. What do you see as three, four strenghts of openSUSE that we should cultivate and build upon?
1) Variety of features
OpenSUSE is mostly recognized for the distributions Leap and Tumbleweed. The broad scale of different sub-projects and them fitting together is a big strength. We should find a way to get oS associated with the whole project bits like YaST, OBS, openQA etc.
2) “Heritage”
Linux distributions come and go, some stay for years, others vanish in the depths of the internet. OpenSUSE has been around for decades now and needs to plot twist that fact towards a recognition as reliable friend for running computers.
3) Permission-free community
The openSUSE community lives from people that just do things and try to convince others by results. That is not usual everywhere in FOSS. Some other communities try to streamline things into committees and head honchos.
2. What are the top three risks you see for openSUSE? (And maybe ideas how to tackle them?)
1) Getting forgotten
2) Staying unknown in some parts
3) Stewing in our own juice
There might be other risks as well but these three all fit into one major topic: communication – or more the lack of it.
My idea to tackle this is to revive (somehow) and to push the marketing team as a driving spot for everything going from openSUSE towards the rest of the world. There are already initiatives to write articles, talk to community people in interviews and to create new marketing material. This of course needs coordination and manpower, but is already taking off quite good.
The marketing team I have in mind is an initiative working in two directions: Besides doing things on our own I want to have it open for people dropping ideas, wishes and projects. Members can open tickets, non-Members can send emails or join chat rooms to explain what they want or need. Marketing people then either fulfill the request by themselves or try to find someone willing to do that, e.g. in artwork, l10n or any other appropriate team.
The main goal is to keep a constant stream of interesting content towards the rest of the community and to anyone outside openSUSE.
The answer to the following question extends this point a bit more.
3. What should the board do differently / more of?
Communicate. Though most people here (including me) don’t like the hierarchy thing it’s something that should not be left unused. In short: if the board says something, it is widely recognized as something important and official.
Being that only partly true and diametrically positioned against of what the board really is (a “servant” to the community), it sure is a way to gain attention for the whole project.
As a quick shot example: pick relevant stuff from the board meeting notes, make a monthly posting on news-o-o, add a nice “board news” badge.
4. If you had a blank voucher from the SUSE CEO for one wish, what would that be?
I’d go for easing up processes with Heroes and tech infrastructure. Though being not into the details anyhow I often hear about things going slowly and needing lots of poking. And I assume what’s visible public there is only the tip of the iceberg.
5. What is your take on the Foundation? What do you consider a realistic outcome of that endeavour? (And if different, what outcome would you like to see?)
Having SUSE involved with community stuff like legal and budget issues will most likely never been gone. And it would feel wrong to try to cut all connections there. But my guess and hope for the foundation is that it will make things more clear and separated.
Do you have further questions? Drop me a line!
(Source of these questions is here.)

LibreOffice, Firefox et Curl reçoivent des mises à jour dans Tumbleweed

Plusieurs paquets ont été mis à jour cette semaine dans openSUSE Tumbleweed comme prévu après la saison des vacances. Cinq instantanés de cette version évolutive ont été livrés cette dernière semaine après avoir passé les tests rigoureux appliqués par openQA.
Ces versions sont incroyablement stables avec des notes enregistrées au-dessus 95, selon le Tumbleweed snapshot reviewer.
L'instantané le plus récent, 20200112, a mis à jour Xfce avec une mise à jour pour xfce4-session 4.14.1 et xfce4-settings 4.14.2.
Divers changements visibles pour les développeurs ont été apportés dans l'instantané 20200101 dont re2 de Google une bibliothèque pour expressions régulières . frogr, l'application GNOME pour la gestion des images avec un compte Flickr, a été mis à jour en 1.6 et a supprimé l'usage obsolète de GTimeVal. La plate-forme open source pour le scale-out du stockage cloud public et privé, glusterfs 7.1, a corrigé le rééquilibrage du stockage provoqué par une erreur d'entrée et une fuite de mémoire dans glusterfsd.
La version 7.0.9.14 de ImageMagick a optimisé les performances des effets spéciaux de Fx et de virglrenderer 0.8.1, qui est un projet visant à étudier la possibilité de créer un GPU 3D virtuel pour une utilisation à l'intérieur des machines virtuelles qemu afin accélérer le rendu 3D.
L'instantané a continué de mettre à jour les paquets pour KDE Applications 19.12.1 qui avaient été intégré dans l'instantané 20200111 . Des améliorations ont été apportées à la vitesse de la molette de défilement pour Dolphin de KDE et le logiciel de montage vidéo Kdenlive avait plusieurs correctifs et un ajustement pour un rendu plus rapide, du code obsolète a aussi été supprimé du paquet de diagramme des applications parapluie. La plupart des paquets Applications KDE ont également mis à jour l'année du copyright à 2020.
En plus des paquets KDE Applications 19.12.1 qui ont commencés à arriver dans l'instantané 20200111, Plasma 5.17.5 de KDE est également arrivé dans l'instantané. Cette mise à jour de Plasma a corrigé une régression intervenue dans la transition l'applet de pageur hors de QtWidgets et a corrigé le glisser-déposer de fichiers depuis Dolphin vers un widget de bureau virtuel. Le Plasma NetworkManager avait également un correctif pour un crash lors du changement de configuration IPv4.
Le correctif très attendu de la vulnérabilité de sécurité dans Firefox a été effectué avec la mise à jour de Mozilla vers Firefox 72.0.1; il y avait huit Common Vulnerabilities and Exposures (CVE) traitées dans la mise à jour de la version précédente 71 incluse dans Tumbleweed, mais la version 72.0.1 a corrigé le bogue que des pirates pouvaient utiliser pour accéder à un ordinateur de toute personne utilisant le navigateur en raison d'informations d'alias incorrectes dans le compilateur JIT IonMonkey.
LibreOffice 6.4.0.1 a ajouté un correctif pour corriger un bouton qui permettait le mauvais ordre d'une interface Qt et curl 7.68.0 comportait un grand nombre de correctifs et de modifications pour inclure l'ajout d'une implémentation de BearSSL vtls pour la Transport Layer...

Exposing C and Rust APIs: some thoughts from librsvg
Librsvg exports two public APIs: the C API that is in turn available to other languages through GObject Introspection, and the Rust API.
You could call this a use of the facade pattern on top of the rsvg_internals crate. That crate is the actual implementation of librsvg, and exports an interface with many knobs that are not exposed from the public APIs. The knobs are to allow for the variations in each of those APIs.
This post is about some interesting things that have come up during the creation/separation of those public APIs, and the implications of having an internals library that implements both.
Initial code organization
When librsvg was being ported to Rust, it just had an rsvg_internals
crate that compiled as a staticlib to a .a library, which was
later linked into the final librsvg.so.
Eventually the code got to the point where it was feasible to port the toplevel C API to Rust. This was relatively easy to do, since everything else underneath was already in Rust. At that point I became interested in also having a Rust API for librsvg — first to port the test suite to Rust and be able to run tests in parallel, and then to actually have a public API in Rust with more modern idioms than the historical, GObject-based API in C.
Version 2.45.5, from February 2019, is the last release that only had a C API.
Most of the C API of librsvg is in the RsvgHandle class. An
RsvgHandle gets loaded with SVG data from a file or a stream, and
then gets rendered to a Cairo context. The naming of Rust source
files more or less matched the C source files, so where there was
rsvg-handle.c initially, later we had handle.rs with the Rustified
part of that code.
So, handle.rs had the Rust internals of the RsvgHandle class, and
a bunch of extern "C" functions callable from C. For example, for
this function in the public C API:
void rsvg_handle_set_base_gfile (RsvgHandle *handle,
GFile *base_file);
The corresponding Rust implementation was this:
#[no_mangle]
pub unsafe extern "C" fn rsvg_handle_rust_set_base_gfile(
raw_handle: *mut RsvgHandle,
raw_gfile: *mut gio_sys::GFile,
) {
let rhandle = get_rust_handle(raw_handle); // 1
assert!(!raw_gfile.is_null()); // 2
let file: gio::File = from_glib_none(raw_gfile); // 3
rhandle.set_base_gfile(&file); // 4
}
- Get the Rust struct corresponding to the C GObject.
- Check the arguments.
- Convert from C GObject reference to Rust reference.
- Call the actual implementation of
set_base_gfilein the Rust struct.
You can see that this function takes in arguments with C types, and converts them to Rust types. It's basically just glue between the C code and the actual implementation.
Then, the actual implementation of set_base_gfile looked like
this:
impl Handle {
fn set_base_gfile(&self, file: &gio::File) {
if let Some(uri) = file.get_uri() {
self.set_base_url(&uri);
} else {
rsvg_g_warning("file has no URI; will not set the base URI");
}
}
}
This is an actual method for a Rust Handle struct, and takes Rust
types as arguments — no conversions are necessary here. However,
there is a pesky call to rsvg_g_warning, about which I'll talk later.
I found it cleanest, although not the shortest code, to structure things like this:
-
C code: bunch of stub functions where
rsvg_blahjust calls a correspondingrsvg_rust_blah. -
Toplevel Rust code: bunch of
#[no_mangle] unsafe extern "C" fn rust_blah()that convert from C argument types to Rust types, and call safe Rust functions — for librsvg, these happened to be methods for a struct. Before returning, the toplevel functions convert Rust return values to C return values, and do things like converting theErr(E)of aResult<>into aGErroror a boolean or whatever the traditional C API required.
In the very first versions of the code where the public API was
implemented in Rust, the extern "C" functions actually contained
their implementation. However, after some refactoring, it turned out
to be cleaner to leave those functions just with the task of
converting C to Rust types and vice-versa, and put the actual
implementation in very Rust-y code. This made it easier to keep the
unsafe conversion code (unsafe because it deals with raw pointers
coming from C) only in the toplevel functions.
Growing out a Rust API
This commit is where the new, public Rust API
started. That commit just created a Cargo workspace
with two crates; the rsvg_internals crate that we already had, and a
librsvg_crate with the public Rust API.
The commits over the subsequent couple of months are of intense refactoring:
-
This commit moves the
unsafe extern "C"functions to a separatec_api.rssource file. This leaveshandle.rswith only the safe Rust implementation of the toplevel API, andc_api.rswith the unsafe entry points that mostly just convert argument types, return values, and errors. -
The API primitives get expanded to allow for a public Rust API that is "hard to misuse" unlike the C API, which needs to be called in a certain order.
Needing to call a C macro
However, there was a little problem. The Rust code cannot call
g_warning, a C macro in glib that prints a message to
stderr or uses structured logging. Librsvg used that to signal
conditions where something went (recoverably) wrong, but there was no
way to return a proper error code to the caller — it's mainly used as
a debugging aid.
This is what the rsvg_internals used to be able to call that C macro:
First, the C code exports a function that just calls the macro:
/* This function exists just so that we can effectively call g_warning() from Rust,
* since glib-rs doesn't bind the g_log functions yet.
*/
void
rsvg_g_warning_from_c(const char *msg)
{
g_warning ("%s", msg);
}
Second, the Rust code binds that function to be callable from Rust:
pub fn rsvg_g_warning(msg: &str) {
extern "C" {
fn rsvg_g_warning_from_c(msg: *const libc::c_char);
}
unsafe {
rsvg_g_warning_from_c(msg.to_glib_none().0);
}
}
However! Since the standalone librsvg_crate does not link to the C
code from the public librsvg.so, the helper rsvg_g_warning_from_c
is not available!
A configuration feature for the internals library
And yet! Those warnings are only meaningful for the C API, which is
not able to return error codes from all situations. However, the Rust
API is able to do that, and so doesn't need the warnings printed to
stderr. My first solution was to add a build-time option for whether
the rsvg_internals library is being build for the C library, or for
the Rust one.
In case we are building for the C library, the code calls
rsvg_g_warning_from_c as usual.
But in case we are building for the Rust library, that code is a no-op.
This is the bit in rsvg_internals/Cargo.toml to declare the feature:
[features]
# Enables calling g_warning() when built as part of librsvg.so
c-library = []
And this is the corresponding code:
#[cfg(feature = "c-library")]
pub fn rsvg_g_warning(msg: &str) {
unsafe {
extern "C" {
fn rsvg_g_warning_from_c(msg: *const libc::c_char);
}
rsvg_g_warning_from_c(msg.to_glib_none().0);
}
}
#[cfg(not(feature = "c-library"))]
pub fn rsvg_g_warning(_msg: &str) {
// The only callers of this are in handle.rs. When those functions
// are called from the Rust API, they are able to return a
// meaningful error code, but the C API isn't - so they issues a
// g_warning() instead.
}
The first function is the one that is compiled when the c-library
feature is enabled; this happens when building rsvg_internals to
link into librsvg.so.
The second function does nothing; it is what is compiled when
rsvg_internals is being used just from the librsvg_crate crate
with the Rust API.
While this worked well, it meant that the internals library was
built twice on each compilation run of the whole librsvg module:
once for librsvg.so, and once for librsvg_crate.
Making programming errors a g_critical
While g_warning() means "something went wrong, but the program will
continue", g_critical() means "there is a programming error". For
historical reasons Glib does not abort when g_critical() is called,
except by setting G_DEBUG=fatal-criticals, or by
running a development version of Glib.
This commit turned warnings into critical errors when the
C API was called out of order, by using a similar
rsvg_g_critical_from_c() wrapper for a C macro.
Separating the C-callable code into yet another crate
To recapitulate, at that point we had this:
librsvg/
| Cargo.toml - declares the Cargo workspace
|
+- rsvg_internals/
| | Cargo.toml
| +- src/
| c_api.rs - convert types and return values, call into implementation
| handle.rs - actual implementation
| *.rs - all the other internals
|
+- librsvg/
| *.c - stub functions that call into Rust
| rsvg-base.c - contains rsvg_g_warning_from_c() among others
|
+- librsvg_crate/
| Cargo.toml
+- src/
| lib.rs - public Rust API
+- tests/ - tests for the public Rust API
*.rs
At this point c_api.rs with all the unsafe functions looked out of
place. That code is only relevant to librsvg.so — the public C API
—, not to the Rust API in librsvg_crate.
I started moving the C API glue to a separate librsvg_c_api crate that lives
along with the C stubs:
+- librsvg/
| *.c - stub functions that call into Rust
| rsvg-base.c - contains rsvg_g_warning_from_c() among others
| Cargo.toml
| c_api.rs - what we had before
This made the dependencies look like the following:
rsvg_internals
^ ^
| \
| \
librsvg_crate librsvg_c_api
(Rust API) ^
|
librsvg.so
(C API)
And also, this made it possible to remove the configuration feature
for rsvg_internals, since the code that calls
rsvg_g_warning_from_c now lives in librsvg_c_api.
With that, rsvg_internals is compiled only once, as it should be.
This also helped clean up some code in the internals library.
Deprecated functions that render SVGs directly to GdkPixbuf are now
in librsvg_c_api and don't clutter the rsvg_internals library.
All the GObject boilerplate is there as well now; rsvg_internals is
mostly safe code except for the glue to libxml2.
Summary
It was useful to move all the code that dealt with incoming C types, our outgoing C return values and errors, into the same place, and separate it from the "pure Rust" code.
This took gradual refactoring and was not done in a single step, but it left the resulting Rust code rather nice and clean.
When we added a new public Rust API, we had to shuffle some code around that could only be linked in the context of a C library.
Compile-time configuration features are useful (like #ifdef in the C
world), but they do cause double compilation if you need a C-internals
and a Rust-internals library from the same code.
Having proper error reporting throughout the Rust code is a lot of work, but pretty much invaluable. The glue code to C can then convert and expose those errors as needed.
If you need both C and Rust APIs into the same code base, you may end up naturally using a facade pattern for each. It helps to gradually refactor the internals to be as "pure idiomatic Rust" as possible, while letting API idiosyncrasies bubble up to each individual facade.

Kubic with Kubernetes 1.17.0 released
Announcement
The Kubic Project is proud to announce that Snapshot 20200113 has just been released containing Kubernetes 1.17.0.
This is a particually exciting release with Cloud Provider Labels becoming a GA-status feature, and Volume Snapshotting now reaching Beta-status.
Release Notes are avaialble HERE.
Special Thanks
Special thanks to Sascha Grunert, Ralf Haferkamp and Michal Rostecki who all contributed to this release, either through debugging issues or by picking up other open Kubic tasks so other contributors could focus on this release.
Please look at our github projects board for an incomplete list of open tasks, everyone is free to help out so please join in!
Upgrade Steps
All newly deployed Kubic clusters will automatically be Kubernetes 1.17.0 from this point.
For existing clusters, you will need to follow the following steps after your nodes have transactionally-updated to 20200113 or later.
For a kubic-control cluster please run kubicctl upgrade.
For a kubeadm cluster you need to follow the following steps on your master node:
kubectl drain <master-node-name> --ignore-daemonsets.
Then run kubeadm upgrade plan to show the planned upgrade from your current v1.16.x cluster to v1.17.0.
kubeadm upgrade apply v1.17.0 will then upgrade the cluster.
kubectl uncordon <master-node-name> will then make the node functional in your cluster again.
For then for all other nodes please repeat the above steps but using kubeadm upgrade node instead of kubeadm upgrade apply, starting with any additional master nodes if you have a multi-master cluster.
Thanks and have a lot of fun!
The Kubic Team