
 Member
Member wstephenson
wstephensonI'm going to Akademy (and taking Klyde with me)
Everything's booked: the weekend after next I'll be in Bilbao at KDE's tenth Akademy meeting. Catch my talk about the latest happenings in Klyde, the lightweight presentation of KDE at 14:30 on Saturday in the New Ideas track.

3.10 Kernel Development Rate
While working on the latest statistics for the yearly Linux Foundation “Who Writes Linux” paper, I noticed the rate-of-change for the 3.10 kernel release that just happened this weekend:

Every year I think we can’t go faster, and every year I’m wrong.
Note, the “number of employers” row is not correct, I haven’t updated those numbers yet, that takes a lot more work, which I will be doing this week.

Plasmoide para consultar la RAE
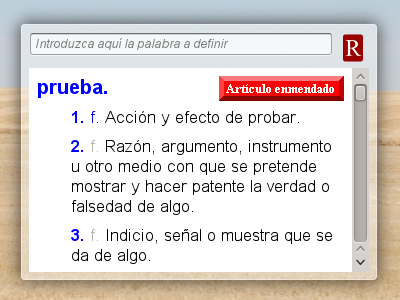
 Acabo de sacar la primera versión de raecas, un plasmoide para consultar la RAE. Es muy sencillo su uso; escribes el término a consultar y le das al intro.
Acabo de sacar la primera versión de raecas, un plasmoide para consultar la RAE. Es muy sencillo su uso; escribes el término a consultar y le das al intro.
Está basado en qRAE.
Organizing oSC13 - 22 days before

Niccolò di Bernardo dei Machiavelli
I am so happy that I read some books when I was younger since now I can understand things better in order to accept various sittuations that happen. You see I have that thing that I cannot accept situations that I cannot understand.
We are 22 days before and although we have made a great progress there are things that need to be done. One thing I see clearly the last few weeks is that no matter how important or minor are the tasks left, they get bigger and bigger every day. This happens because when you plan a conference and add tasks you see in your mind the whole picture when ALL those tasks will be done. Of course you reject some in the course of making the conference but now, just 22 days before you want everything to be done. The alternatives we talked before all worked so far but problems keep comming every single day and you just stand in the front line and face them, lossing a task is not an option, not 22 days before. It is a do or die situation.
Of course we seem to be in good shape since so far we are doing great but honnestly I have the fear of the failing. On the other hand failing is not an option so...
The thing is that the situation kind of looks like Lernean Hydra where when you cut one head two other pop up.
Non-YaST Applications Can Benefit from YaST Framework
- y2r - translates YCP code into Ruby
- ycp-killer - manages tasks related to translation of YCP code in YaST modules into Ruby
Y2R Editor
I've been asked by the team to write a simple application allowing writing YCP code that would be automatically translated to Ruby and shown aside. Creating this application using YaST framework was the very next logical step. Development was fast and easy and it has proven that we can use that framework for system applications as well.
The whole source code is written in Ruby and it's connected to the YaST framework via yast2-ruby-bindings (version >= 1.0.0).
How to Run the Editor
If you want to try running the editor yourself, follow the README.md file in y2r-tools project. You will need to have y2r project cloned to your system and it's also helpful to have to latest yast2-core from YaST:Head project, because part of it is used for the translation.Note: Just in case it will stuck in the middle of the translation, search for ruby process and kill it (kill -9 $PROCESS_ID). Then write the second quote, please :) Yes, there was a bug in yast2-core that it was searching for closing quote in strings like string message = "Unfinished.
YaST Framework
- UI support for ncurses, Qt, and GTK (as plug-ins) just by writing one single UI definition
- Possibility to use YaST libraries (even those still written in YCP)
- Possibility to use any Ruby library or Gem, such as Cheetah in this case
- SCR - Layer for accessing the system configuration (read, write, execute)
How to Create a sysfs File Correctly
One common Linux kernel driver issue that I see all the time is a driver author attempting to create a sysfs file in their code by doing something like:
int my_driver_probe(...)
{
...
retval = device_create_file(my_device, &my_first_attribute);
if (retval)
goto error1;
retval = device_create_file(my_device, &my_second_attribute);
if (retval)
goto error2;
...
return 0;
error2:
device_remove_file(my_device, &my_first_attribute);
error1:
/* Clean up other things and return an error */
...
return -ENODEV;
}
That’s a good first start, until they get tired of adding more and more sysfs files, and they discover attribute groups, which allows multiple sysfs files to be created and destroyed all at once, without having to handle the unwinding of things if problems occur:
YaST Runlevel is dead, long live YaST Services Manager!
Long Story Short
It's a public secret that YaST Runlevel in openSUSE 12.3 is far to be useful. It's caused by switching from SysV to systemd whereas all the UI and internal functionality has been designed for SysV. I was thinking about the possibility to rewrite the current module to use systemd directly, but then I realized that I should rather start a pilot project from scratch: The very first YaST module written completely in Ruby!New YaST Module
This new YaST module has been called Services Manager (yast2-services-manager) to better reflect what it actually does. You can find its source code here. And you can download the package here. It will additionally need yast2-ruby-bindings package in version 1.0.0 or higher which is available in the same repository. To start the module, just type yast2 services-manager as root or start it from YaST Control Center.Screenshots



Why in Ruby
All old YaST modules were written in YCP - special language invented just for YaST, but there are other programming languages that can be used now and Ruby is THE programming language used for automatic translation from YCP.Ruby gives us much more than YCP
- Developers don't need to learn another language just for YaST
- There are already many libraries out there
- We can use several great testing frameworks that already exist
- And last but not least: It's a very nice and powerful language

Droning Parrots and Javascript
LibreOffice import filter for legacy Mac file-formats - smile and say "mwaw"!
Attentive reader of this blog remembers that, besides improvements in the most frequently used file-formats, each major release of LibreOffice adds to the list of document file-formats that are freed from the dungeon of vendor lock. In a collaboration with re-lab's Valek Filippov and (then GSoC student and now Lanedo's LibreOffice developer) Eilidh McAdam, LibreOffice 3.5 brought the possibility to open and see the most commonly used Visio files to the FLOSS world. LibreOffice 3.6 was able to claim the most comprehensive coverage of CorelDraw file-format with the ability to open even the oldest CorelDraw 1 and 2 files that modern versions of CorelDraw are not able to open any more.
The latest major release of LibreOffice was also full of goodies. First, the fruitful collaboration of re-lab's Valek Filippov with (then GSoC student and now amazon.com employee) Brennan T. Vincent produced the first ever possibility of reading Microsoft Publisher files in the FLOSS world. Second, with the advent of Microsoft Office 2013 and change in the Visio 2013 file-format, LibreOffice extended the coverage of Visio file-format to all files any version of Visio ever produced.
LibreOffice 4.1 release is approaching quickly. And that is an excellent news for bad teenage poetry and other literary production from the late 80s and early 90s. With the up-coming new release, LibreOffice extends support for a host of pre-OSX MAC text formats. This is a result of a continuous effort to open as many legacy file-formats as possible to our users, and help them to settle for ODF.
This particular improvement was possible thank to the integration of libmwaw written by Laurent Alonso, LibreOffice contributor and already co-maintainer of libwps and of the Microsoft Works import filter inside LibreOffice. The horsepower doing the conversions, libmwaw is one of the libraries from the libwpd family. In the same way as libwps, libmwaw reuses libwpd's interfaces and the ODF generator classes in libodfgen in order to convert its callbacks into an xml stream in flat ODF file-format. The import filter lives in the module writerperfect.
The supported file-format include Microsoft Word for Mac from versions 1 to 5.1, Mac versions of Microsoft Works, different versions of ClarisWorks and AppleWorks, to name but a few. The list of supported file-format and of imported features is increasing literally every day. This promises further good news with every minor release of LibreOffice 4.1. More teenage poetry and bad litterature will be freed from the pit of discontinued software products.
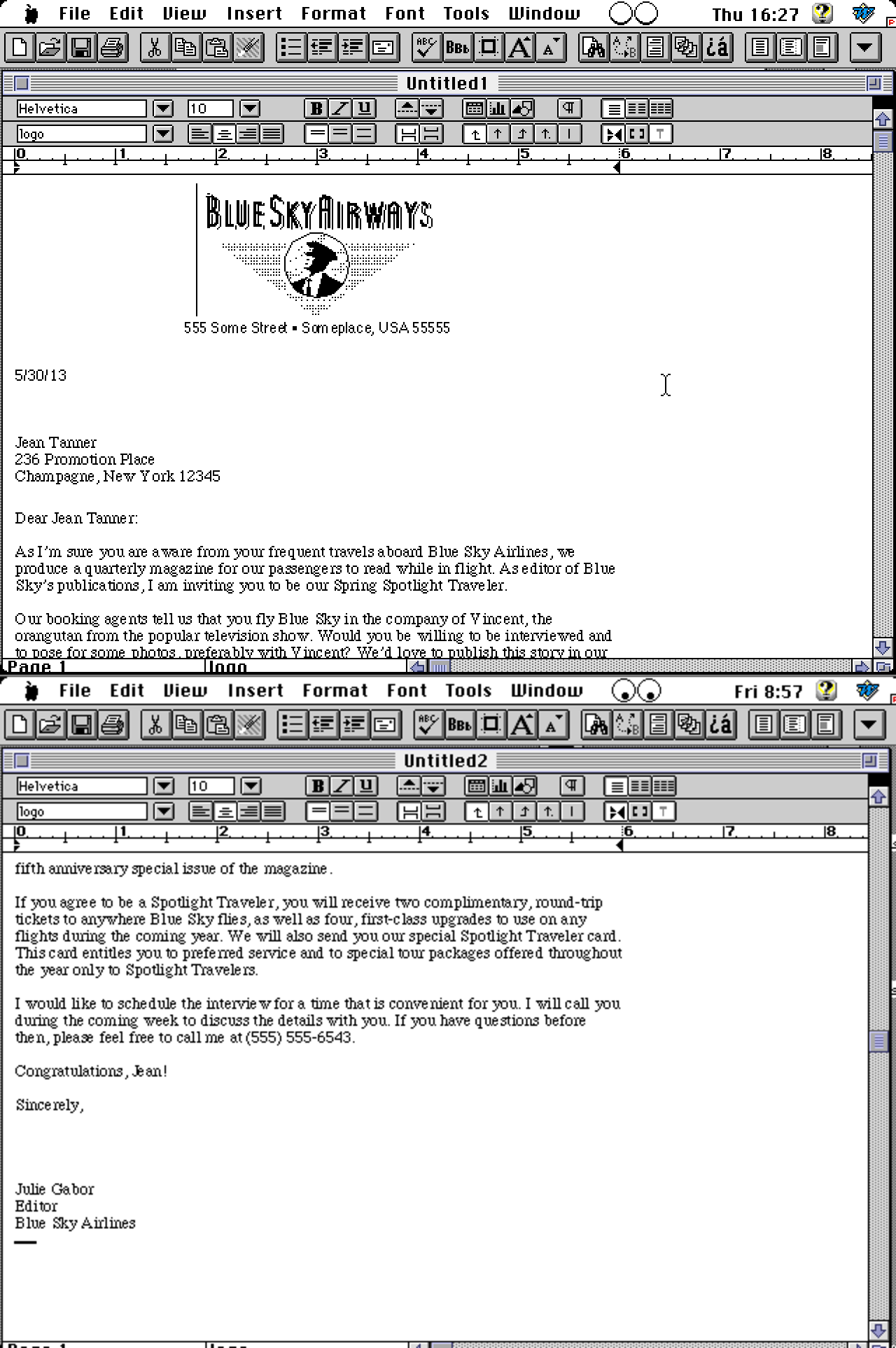
After having found a way to get screenshots of some sample documents in their respective generating application, we are able to satisfy those readers that are hungry for pictures. First is a sample document in Mac Word 5.1 (1992) file-format opened in the originating application and in the up-coming LibreOffice 4.1:
 |
 |
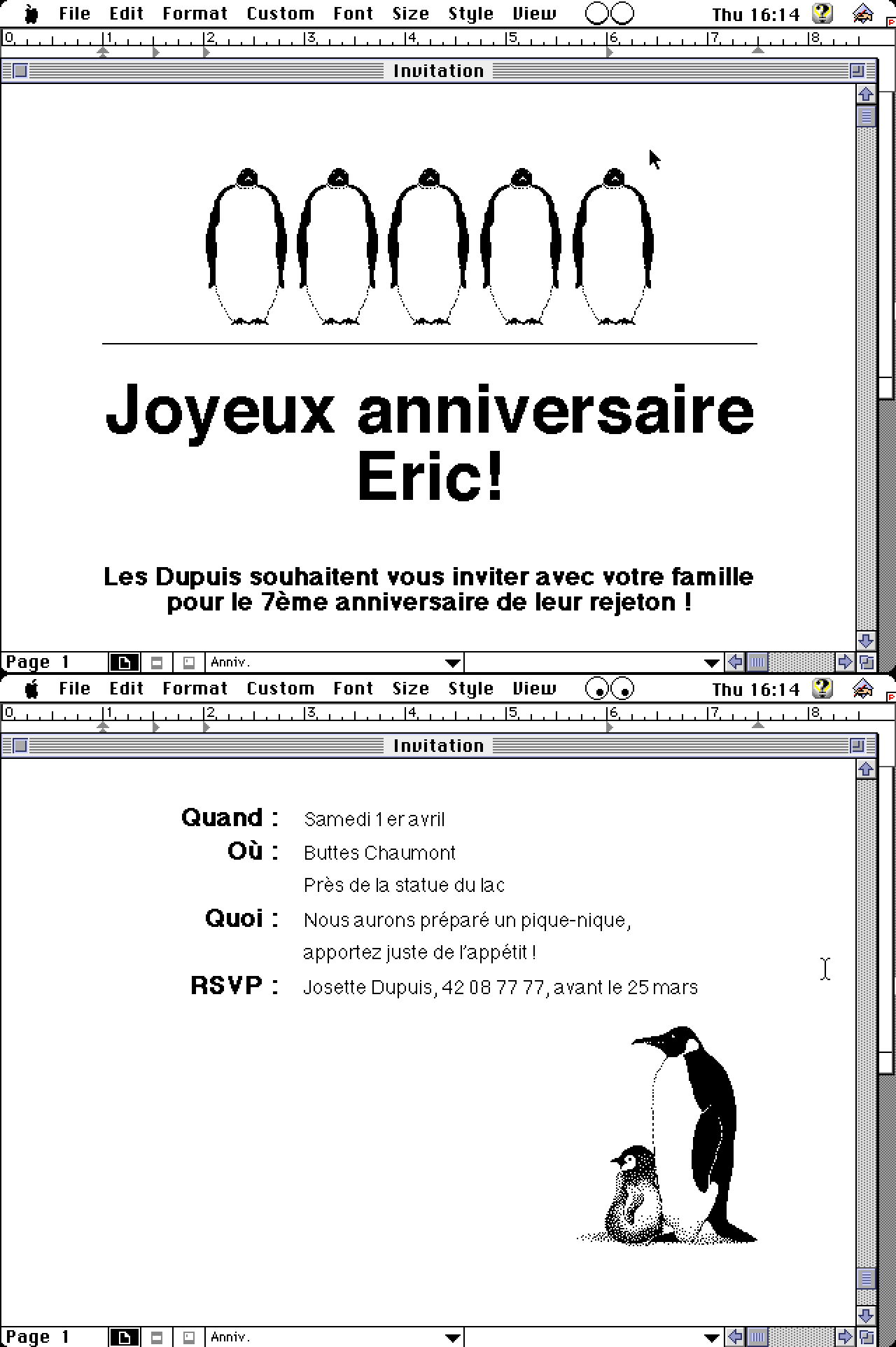
Following is a simple document with picture produced by Write Now 4.1 from about 1993. It demonstrates the reason why LibreOffice is frequently called the "Swiss Army knife" of file-formats:
 |
 |
Following is an example of conversion of a document in MacWrite Pro 1.5 file-format from 1994:
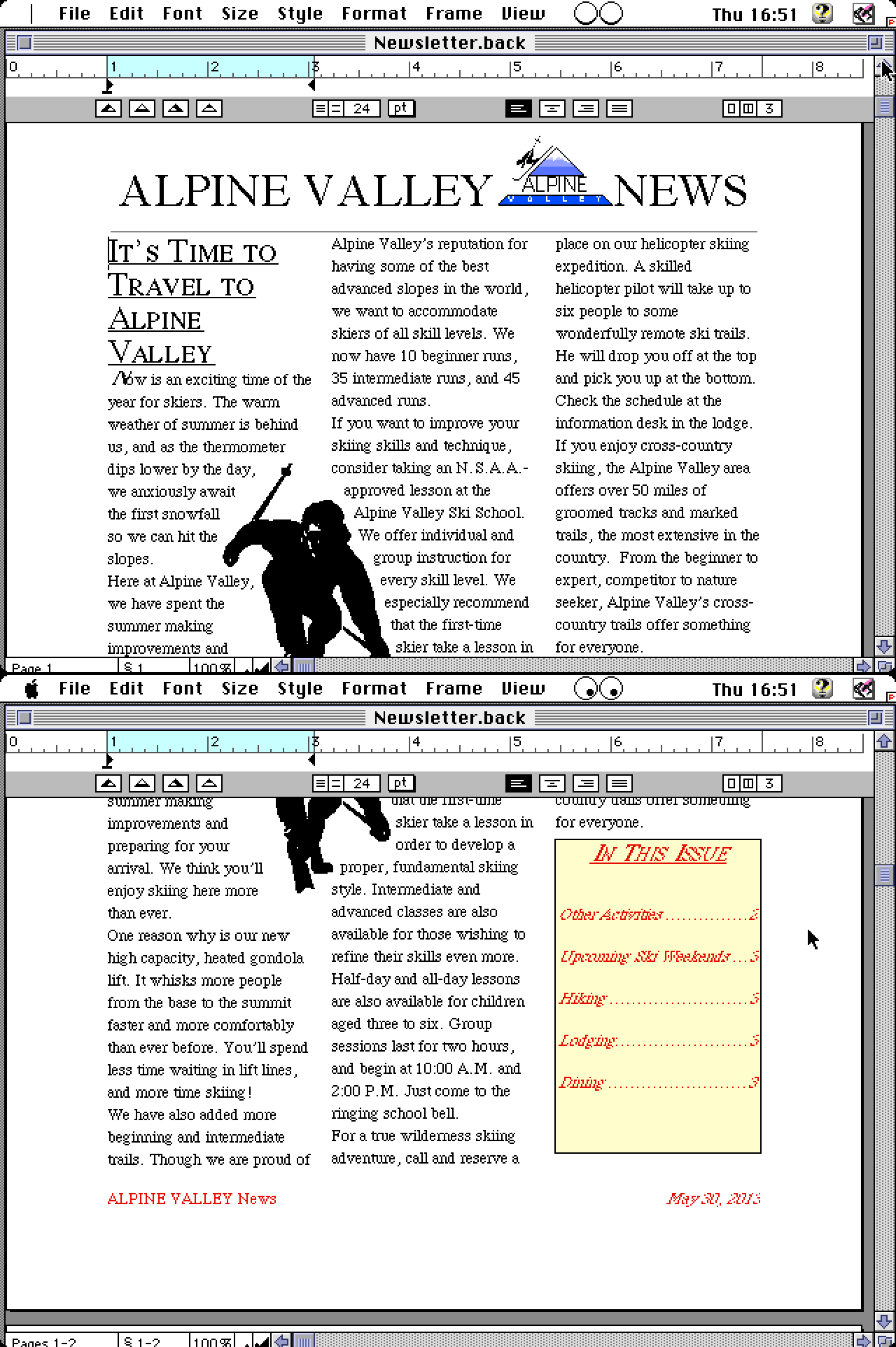 |
 |
And, last but not least is an example of conversion of a wordprocessing documents in AppleWorks 6.0 from the late 90s. The software was discontinued by Apple with the end-of-life of their PowerPC series. But LibreOffice can resurrect your documents:
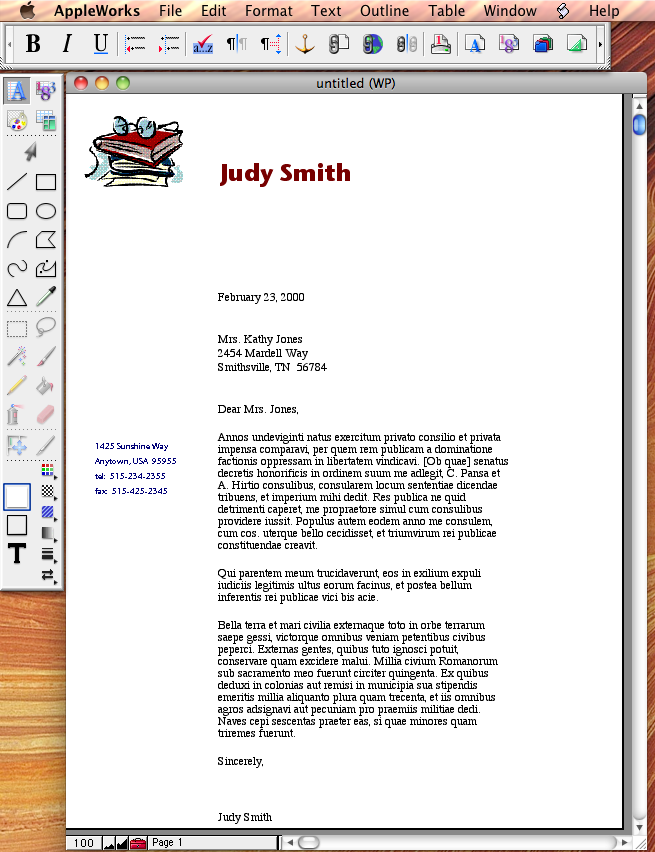 |
 |
Pretty exciting news! But the most exciting thing is that you can be part of this adventure. Join the fun by submitting bugs or by fixing your personal itches. So, if you want to help, patches can be sent to libreoffice-dev mailing list. And, do not forget to find a way to join the #libreoffice-dev channel at irc.freenode.net in order to meet other developers. We can promise you that you will have a lot of fun in the LibreOffice community.

17 Months Sprinting

After helping start the Narwhal and Dashboard projects during my first few months, I transitioned to lead the Analytics Technology team with Chris Wegrzyn. The Analytics department grew to 54 people, busy with managing polling, creating and updating statistical models, and analyzing any and all data to advise campaign leadership across all departments on program strategy and efficacy.
Our team of nine Analytics engineers created, curated, and maintained a 50 TB analytics database, uniting all the campaign's data into one place – letting us create, coordinate, and analyze holistic, data-driven programs.
Suddenly we could do things like notice a supporter had requested a mail-in ballot and assist them via email to ensure the ballot was cast and counted. We could analyze merchandise purchased via the mailing list, events, and the online store. We created a TV-ad purchasing optimizer that got us 15% more persuadable viewers per dollar.
We created a tool ("Stork") that connected our analytics database with a few key vendor APIs, Google Spreadsheets, mapping, and basic data processing features — and empowered analysts and state and HQ data staff to implement their own automated, data-driven ideas for helping re-elect the President. We released the tool to users when it had a single function, and let user feedback set the agenda for the next 23. We often added new features within hours of users' requests. Its functions were composable, and served as the basis for several of our own even higher-level tools.
Our process in Analytics Technology was partly agile, but mostly just keep-it-simple and get-it-done. Our team didn't have to be web-scale, we just had to be Big Data scale; instead of millions of web requests, we had 6-billion-row tables to join and keep synced, and 200 querying users (and dozens of apps) to keep happy. And mostly, we needed to move quickly to take as many creative (yet often simple, common sense) ideas and help make them happen while they could still have an impact. I think a lot of us wished we'd had just a couple more months, and oh what we could have created!

The Analytics Technology team; left to right: me, Bill Wanjohi, Christopher Manning, Chase Martyn, Erek Dyskant, Chelsea Zhang, Curtis Morales, Chris Wegrzyn, Zane Shelby, and Tim Trautman
We used SQL (oh, did we use SQL), Python, Ruby, Java, Hadoop, Postgres, Vertica, cron, git, ElasticSearch, EC2, DynamoDB, S3, SES, and much more. We were generalists, who built and maintained our tools collectively, who seamlessly multitasked on data ETL, Rails apps, database administration, GIS, data-triggered emailers, Hadoop jobs, and much more.
Some personal highlights of the 17 months included receiving extremely kind letters from state staff thanking the team for our work and our tools, giving a man the Heimlich maneuver at State and Randolph on the way into work, and shaking President Obama's hand:
