
Anton Cherkasov
posted at
Очередной открытый Bugs-Day

В связи с этим в Воскресенье, 20 февраля, объявляется открытый Bugs-Day, где каждый желающий получит возможность принять участие в тестировании openSUSE 11.4 на наличие ошибок.
Что нужно для того, чтобы принять участие:
- Регистрация в bugzilla.novell.com
- Установленный дистрибутив openSUSE 11.4 RC1 или openSUSE Factory
- IRC клиент для взаимодействия с другими участниками на канале #opensuse-testing
- Хорошее настроение :)
Порядок работы:
- Поиск в Bugzilla ошибок, открытых в устаревших версиях (11.4 MS 1-5 или 11.4 Factory)
- Попробуйте воспроизвести проблему на 11.4 RC1
- Если неполадка все еще остается, обновите статус ошибки для текущей версии
- Если вы уверены, что проблема была устранена, установите статус ошибки в RESOLVED+FIXED
- Если вы чувствуете, что проблема была устранена, установите статус в RESOLVED+NORESPONSE
Такой порядок действий для каждой найденной ошибки, для координации пользуйтесь IRC-каналом #opensuse-testing сети FreeNode.
Мотивация:
Куда же без неё :) Десять самых активных участников получат благодарность от сообщества в виде фирменных футболок и других хороших вещей. Ну и не забываем главного - Have a lot of Fun!
Anton Cherkasov
posted at
Реализация простейшего socks-proxy на openSUSE 11.3
Как-то раз, ещё до покупки роутера, мне понадобилось расшарить свое интернет подключение соседу по общежитию. В наличии имелся компьютер с 1 сетевым интерфейсом, подключенный к локальной сети с доступом в Интернет через шлюз, и компьютер в той же локальной сети, но без доступа к Интернету.
Самым простым решением на мой взгляд было настроить squid через Yast2, что и было сделано буквально в пять клтков. Всё бы ничего, веб-страницы заработали, но вот p2p программы, типо ICQ, Skype, Torrent-клиентов работать не пожелали. Было решено также поднять socks proxy.
В репозиториях я быстро нашел прокси сервер Dante и начал разбираться с настройками.
Все настройки хранятся в файле /etc/sockd.conf, который по доброй Unix традиции содержит подробные инструкции в виде комментариев. Ниже приведу откомментированный рабочий файл настройки, реализующий простейший прокси сервер, раздающий интернет одному клиенту без каких-либо ограничений и не требующий авторизации:
logoutput: /var/log/socks/socks.log # указываем файл для хранения логов
Самым простым решением на мой взгляд было настроить squid через Yast2, что и было сделано буквально в пять клтков. Всё бы ничего, веб-страницы заработали, но вот p2p программы, типо ICQ, Skype, Torrent-клиентов работать не пожелали. Было решено также поднять socks proxy.
В репозиториях я быстро нашел прокси сервер Dante и начал разбираться с настройками.
Все настройки хранятся в файле /etc/sockd.conf, который по доброй Unix традиции содержит подробные инструкции в виде комментариев. Ниже приведу откомментированный рабочий файл настройки, реализующий простейший прокси сервер, раздающий интернет одному клиенту без каких-либо ограничений и не требующий авторизации:
logoutput: /var/log/socks/socks.log # указываем файл для хранения логов
internal: eth0 port = 1080 # внутренний интерфейс и порт, на котором будем слушать клиентов, допустимо также указывать IP адрес.
external: eth0 # внешний интерфейс, с которого выходим в Интернет, допустимо что-то вроде external: 192.168.1.1
method: username none # метод авторизации (rfc931) в данном случае - без авторизации
# далее идет набор правил, правила со словом pass разрешают действия, со словом block - запрещают
client pass {
from: 192.168.1.2/32 to: 0.0.0.0/0
log: connect disconnect iooperation
} # разрешаем пользователю 192.168.1.2 подключаться к серверу и логируем события подключения/отключения и ввод/вывод.
pass {
from: 0.0.0.0/0 to: 0.0.0.0/0
command: connect udpassociate
log: connect disconnect iooperation
} # разрешаем серверу соединяться с любыми серверами, выполняя команды connect, udpassociate и также пишем логи
Это самый простой пример, возможности по ограничению прав, авторизации, выдаче сообщений и т. п. намного шире и подробно описаны в самом файле конфигурации.
Надеюсь этот пример поможет кому-то освоиться и послужит отправной точкой .
Anton Chernyshov
posted at
С наступающим!
Поздравляю всех читателей этого дневника с наступающим Новым Годом! Желаю в наступающем году безглючного железа, безпроблемных пользователей! Также хочется пожелать успехов и в остальных сторонах жизни - материальной, личной, карьерной.
Надеюсь, что будущий год будет не хуже прошедшего по насыщенности событиями Linux-тематики. У нашего учебного центра тоже есть много интересных задумок, которые планируется реализовать. Но об этом я пока писать не могу :).
Еще раз успехов! И помните, пингвин птица полярная :)

Надеюсь, что будущий год будет не хуже прошедшего по насыщенности событиями Linux-тематики. У нашего учебного центра тоже есть много интересных задумок, которые планируется реализовать. Но об этом я пока писать не могу :).
Еще раз успехов! И помните, пингвин птица полярная :)

Anton Chernyshov
posted at
С наступающим!
Поздравляю всех читателей этого дневника с наступающим Новым Годом! Желаю в наступающем году безглючного железа, безпроблемных пользователей! Также хочется пожелать успехов и в остальных сторонах жизни - материальной, личной, карьерной.
Надеюсь, что будущий год будет не хуже прошедшего по насыщенности событиями Linux-тематики. У нашего учебного центра тоже есть много интересных задумок, которые планируется реализовать. Но об этом я пока писать не могу :).
Еще раз успехов! И помните, пингвин птица полярная :)

Надеюсь, что будущий год будет не хуже прошедшего по насыщенности событиями Linux-тематики. У нашего учебного центра тоже есть много интересных задумок, которые планируется реализовать. Но об этом я пока писать не могу :).
Еще раз успехов! И помните, пингвин птица полярная :)

Anton Chernyshov
posted at
С наступающим!
Поздравляю всех читателей этого дневника с наступающим Новым Годом! Желаю в наступающем году безглючного железа, безпроблемных пользователей! Также хочется пожелать успехов и в остальных сторонах жизни - материальной, личной, карьерной.
Надеюсь, что будущий год будет не хуже прошедшего по насыщенности событиями Linux-тематики. У нашего учебного центра тоже есть много интересных задумок, которые планируется реализовать. Но об этом я пока писать не могу :).
Еще раз успехов! И помните, пингвин птица полярная :)
Надеюсь, что будущий год будет не хуже прошедшего по насыщенности событиями Linux-тематики. У нашего учебного центра тоже есть много интересных задумок, которые планируется реализовать. Но об этом я пока писать не могу :).
Еще раз успехов! И помните, пингвин птица полярная :)
Anton Cherkasov
posted at
Окна в... Интернет
Сегодня все одержимы новыми технологиями, облачными вычислениями и прочими Hi-Tech забавами. И вот я решил проверить, насколько установленные в моей системе браузеры поддерживают новейшие стандарты. Итак, представляю героев этого мини-обзора:
- Chromium 10.0.610.0
- Firefox 3.6.12
- Konqueror 4.5.86 (из KDE:Unstable)
- Rekonq 0.6.55
Сразу оговорюсь, почему в этом списке нет Opera. Я очень положительно отношусь к этому норвежскому браузеру и во времена активного использования Windows он был моим основным "окном в интернет", правда потом я перешёл на Firefox, когда последний дорос до 3-й версии, затем вообще на Linux, в котором у тогдашней Opera не все было гладко, а позднее на Chromium.
Также в последнее время стараюсь по возможности избегать использования закрытых программ (RMS торжествует :)) именно в силу этих обстоятельств Opera в моей системе не установлена.
Итак, преступим к тестам! Поддержка HTML5 (максимально возможная оценка - 300):
 С левого верхнего угла по часовой стрелке: Firefox, Rekonq, Konqueror (KHTML), Chromium.
С левого верхнего угла по часовой стрелке: Firefox, Rekonq, Konqueror (KHTML), Chromium.
И ещё одна картинка, на этот раз с Konqueror-ом в режиме использования WebKit:

Как видно, результаты Rekonq и Konqueror идентичны, что лишний раз показыает, что ни тот ни другой проект не вносят никаких изменений в qt-webkit, результаты работы которого мы и наблюдаем.
Кроме того я протестировал каждый браузер бенчмарком от Futuremark, результаты ниже:

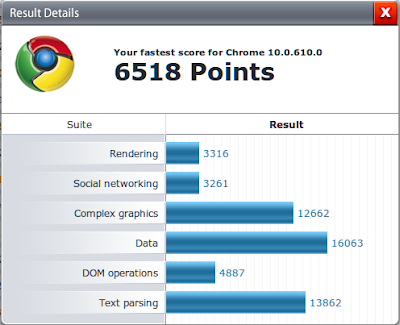
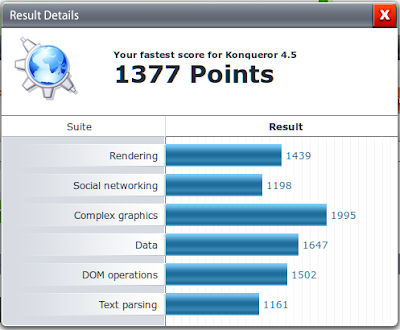

Единственное, что бросается в глаза - то что бенчмарк определил Rekonq как неизвестную версию Safari.
Каие из этого можно сделать выводы? Пусть каждый решит для себя сам, я же останусь на Chromium-е и буду пристально следить и ждать, когда допилят Rekonq, на мой взгляд очень перспективный проект, достойный стать "окном в интернет" по умолчанию, как в KDE, так и на моём десктопе.
В конце приведу ссылки на браузеры и тесты:
P.S. Ну и небольшая новость, не относящаяся к теме: После долгих раздумий я таки решил посмотреть, что это за птица и завел себе аккаунт в Twitter. Как буду его использовать пока ещё не решил, может быть это будет просто хранилище ссылок на интересные статьи, может быть буду постить туда мысли, которые слишком малы для статьи в этом блоге, а может быть оба варианта сразу или что-то другое. Вообщем всем интересующимся - мой ник в Twitter @Cerkasov.

И ещё одна картинка, на этот раз с Konqueror-ом в режиме использования WebKit:

Как видно, результаты Rekonq и Konqueror идентичны, что лишний раз показыает, что ни тот ни другой проект не вносят никаких изменений в qt-webkit, результаты работы которого мы и наблюдаем.
Кроме того я протестировал каждый браузер бенчмарком от Futuremark, результаты ниже:




Единственное, что бросается в глаза - то что бенчмарк определил Rekonq как неизвестную версию Safari.
Каие из этого можно сделать выводы? Пусть каждый решит для себя сам, я же останусь на Chromium-е и буду пристально следить и ждать, когда допилят Rekonq, на мой взгляд очень перспективный проект, достойный стать "окном в интернет" по умолчанию, как в KDE, так и на моём десктопе.
В конце приведу ссылки на браузеры и тесты:
P.S. Ну и небольшая новость, не относящаяся к теме: После долгих раздумий я таки решил посмотреть, что это за птица и завел себе аккаунт в Twitter. Как буду его использовать пока ещё не решил, может быть это будет просто хранилище ссылок на интересные статьи, может быть буду постить туда мысли, которые слишком малы для статьи в этом блоге, а может быть оба варианта сразу или что-то другое. Вообщем всем интересующимся - мой ник в Twitter @Cerkasov.
Anton Cherkasov
posted at
Окна в... Интернет
Сегодня все одержимы новыми технологиями, облачными вычислениями и прочими Hi-Tech забавами. И вот я решил проверить, насколько установленные в моей системе браузеры поддерживают новейшие стандарты. Итак, представляю героев этого мини-обзора:
- Chromium 10.0.610.0
- Firefox 3.6.12
- Konqueror 4.5.86 (из KDE:Unstable)
- Rekonq 0.6.55
Сразу оговорюсь, почему в этом списке нет Opera. Я очень положительно отношусь к этому норвежскому браузеру и во времена активного использования Windows он был моим основным "окном в интернет", правда потом я перешёл на Firefox, когда последний дорос до 3-й версии, затем вообще на Linux, в котором у тогдашней Opera не все было гладко, а позднее на Chromium.
Также в последнее время стараюсь по возможности избегать использования закрытых программ (RMS торжествует :)) именно в силу этих обстоятельств Opera в моей системе не установлена.
Итак, преступим к тестам! Поддержка HTML5 (максимально возможная оценка - 300):
 С левого верхнего угла по часовой стрелке: Firefox, Rekonq, Konqueror (KHTML), Chromium.
С левого верхнего угла по часовой стрелке: Firefox, Rekonq, Konqueror (KHTML), Chromium.
И ещё одна картинка, на этот раз с Konqueror-ом в режиме использования WebKit:

Как видно, результаты Rekonq и Konqueror идентичны, что лишний раз показыает, что ни тот ни другой проект не вносят никаких изменений в qt-webkit, результаты работы которого мы и наблюдаем.
Кроме того я протестировал каждый браузер бенчмарком от Futuremark, результаты ниже:




Единственное, что бросается в глаза - то что бенчмарк определил Rekonq как неизвестную версию Safari.
Каие из этого можно сделать выводы? Пусть каждый решит для себя сам, я же останусь на Chromium-е и буду пристально следить и ждать, когда допилят Rekonq, на мой взгляд очень перспективный проект, достойный стать "окном в интернет" по умолчанию, как в KDE, так и на моём десктопе.
В конце приведу ссылки на браузеры и тесты:
P.S. Ну и небольшая новость, не относящаяся к теме: После долгих раздумий я таки решил посмотреть, что это за птица и завел себе аккаунт в Twitter. Как буду его использовать пока ещё не решил, может быть это будет просто хранилище ссылок на интересные статьи, может быть буду постить туда мысли, которые слишком малы для статьи в этом блоге, а может быть оба варианта сразу или что-то другое. Вообщем всем интересующимся - мой ник в Twitter @Cerkasov.

И ещё одна картинка, на этот раз с Konqueror-ом в режиме использования WebKit:

Как видно, результаты Rekonq и Konqueror идентичны, что лишний раз показыает, что ни тот ни другой проект не вносят никаких изменений в qt-webkit, результаты работы которого мы и наблюдаем.
Кроме того я протестировал каждый браузер бенчмарком от Futuremark, результаты ниже:




Единственное, что бросается в глаза - то что бенчмарк определил Rekonq как неизвестную версию Safari.
Каие из этого можно сделать выводы? Пусть каждый решит для себя сам, я же останусь на Chromium-е и буду пристально следить и ждать, когда допилят Rekonq, на мой взгляд очень перспективный проект, достойный стать "окном в интернет" по умолчанию, как в KDE, так и на моём десктопе.
В конце приведу ссылки на браузеры и тесты:
P.S. Ну и небольшая новость, не относящаяся к теме: После долгих раздумий я таки решил посмотреть, что это за птица и завел себе аккаунт в Twitter. Как буду его использовать пока ещё не решил, может быть это будет просто хранилище ссылок на интересные статьи, может быть буду постить туда мысли, которые слишком малы для статьи в этом блоге, а может быть оба варианта сразу или что-то другое. Вообщем всем интересующимся - мой ник в Twitter @Cerkasov.
Anton Cherkasov
posted at
Окна в... Интернет
Сегодня все одержимы новыми технологиями, облачными вычислениями и прочими Hi-Tech забавами. И вот я решил проверить, насколько установленные в моей системе браузеры поддерживают новейшие стандарты. Итак, представляю героев этого мини-обзора:
- Chromium 10.0.610.0
- Firefox 3.6.12
- Konqueror 4.5.86 (из KDE:Unstable)
- Rekonq 0.6.55
Сразу оговорюсь, почему в этом списке нет Opera. Я очень положительно отношусь к этому норвежскому браузеру и во времена активного использования Windows он был моим основным "окном в интернет", правда потом я перешёл на Firefox, когда последний дорос до 3-й версии, затем вообще на Linux, в котором у тогдашней Opera не все было гладко, а позднее на Chromium.
Также в последнее время стараюсь по возможности избегать использования закрытых программ (RMS торжествует :)) именно в силу этих обстоятельств Opera в моей системе не установлена.
Итак, преступим к тестам! Поддержка HTML5 (максимально возможная оценка - 300):
С левого верхнего угла по часовой стрелке: Firefox, Rekonq, Konqueror (KHTML), Chromium.
И ещё одна картинка, на этот раз с Konqueror-ом в режиме использования WebKit:
Как видно, результаты Rekonq и Konqueror идентичны, что лишний раз показыает, что ни тот ни другой проект не вносят никаких изменений в qt-webkit, результаты работы которого мы и наблюдаем.
Кроме того я протестировал каждый браузер бенчмарком от Futuremark, результаты ниже:
Единственное, что бросается в глаза - то что бенчмарк определил Rekonq как неизвестную версию Safari.
Каие из этого можно сделать выводы? Пусть каждый решит для себя сам, я же останусь на Chromium-е и буду пристально следить и ждать, когда допилят Rekonq, на мой взгляд очень перспективный проект, достойный стать "окном в интернет" по умолчанию, как в KDE, так и на моём десктопе.
В конце приведу ссылки на браузеры и тесты:
P.S. Ну и небольшая новость, не относящаяся к теме: После долгих раздумий я таки решил посмотреть, что это за птица и завел себе аккаунт в Twitter. Как буду его использовать пока ещё не решил, может быть это будет просто хранилище ссылок на интересные статьи, может быть буду постить туда мысли, которые слишком малы для статьи в этом блоге, а может быть оба варианта сразу или что-то другое. Вообщем всем интересующимся - мой ник в Twitter @Cerkasov.
И ещё одна картинка, на этот раз с Konqueror-ом в режиме использования WebKit:
Как видно, результаты Rekonq и Konqueror идентичны, что лишний раз показыает, что ни тот ни другой проект не вносят никаких изменений в qt-webkit, результаты работы которого мы и наблюдаем.
Кроме того я протестировал каждый браузер бенчмарком от Futuremark, результаты ниже:
Единственное, что бросается в глаза - то что бенчмарк определил Rekonq как неизвестную версию Safari.
Каие из этого можно сделать выводы? Пусть каждый решит для себя сам, я же останусь на Chromium-е и буду пристально следить и ждать, когда допилят Rekonq, на мой взгляд очень перспективный проект, достойный стать "окном в интернет" по умолчанию, как в KDE, так и на моём десктопе.
В конце приведу ссылки на браузеры и тесты:
P.S. Ну и небольшая новость, не относящаяся к теме: После долгих раздумий я таки решил посмотреть, что это за птица и завел себе аккаунт в Twitter. Как буду его использовать пока ещё не решил, может быть это будет просто хранилище ссылок на интересные статьи, может быть буду постить туда мысли, которые слишком малы для статьи в этом блоге, а может быть оба варианта сразу или что-то другое. Вообщем всем интересующимся - мой ник в Twitter @Cerkasov.
Anton Chernyshov
posted at
Введение в использование LVM
LVM - (Logical Volume Manager - менеджер логических дисков) средство гибкого управления дисковым пространством. Позволяет динамически менять размер логических разделов на лету, создавать снимки (снапшоты) и т.д.
Дисклеймер/отмазка
LVM это очень(!!!) мощный инструмент, который требует аккуратного с собой обращения. Любая самодеятельность с ним может обернуться потерей всей(!!!) информации на диске. Поэтому прежде, чем использовать LVM на рабочих машинах (и уж тем более на «боевых» серверах), следует потренироваться на кошках. Лучше всего это делать на виртуальных машинах. Начинать использовать LVM следует только (и только!!!) тогда, как почувствуете уверенность и понимание принципов его работы.
Зачем нужен LVM
Установка системы прямо на разделы диска зачастую приводит к следующей проблеме.
Нужно каким-то образом «правильно» разбить жесткий диск. Слово «правильно» стоит в кавычках, потому что «правильного» разбиения диска для всех возможных ситуаций и применений не существует. В сети есть много советов по данному поводу, но они не учитывают потребностей конкретного пользователя (в случае настольной системы) или конкретного администратора (в случае сервера). Обычно рекомендуют разделы /home, /var, /usr, какие-то еще выносить на отдельные разделы диска. Но если разбивающий ошибется в размерах этих разделов, возникает очень не хорошая ситуация - на одних разделах место подходит к концу, в то время как на остальных места еще много. Приехали! Дисковое пространство нужно переразмечать. Для этого есть много способов:
1. Тотальный backup, затем переустановка системы с переразбиением диска.
2. Переразметка с помощью parted с риском потерять данные.
3. Изначальная установка системы на LVM, который позволяет изменять размеры своих разделов прямо на работающей системе.
Терминология
LVM предусматривает три логических уровня работы с дисковым пространством:
1. Самый нижний - физические тома (physical volumes). Это собственно физические диски. Это могут быть диски целиком (/dev/sda, /dev/sdb и т.д.) или отдельные разделы (/dev/sda1, /dev/sdb5 и т.п.).
2. Группы томов - volume groups. В группы томов объединяются физические тома. Таким образом группы томов представляют собой пул дискового пространства, необходимый для следующего уровня. Группы томов могут иметь человеческие названия, говорящие администратору системы об их предназначении: system, sales, database и т.д.
3. Логические тома (logical volumes) - это аналог разделов физического диска и то, ради чего вообще существуют диски - именно на них хранятся данные. Пользователи (и процессы) системы работают только с логическими томами. Таким образом LVM создает для них всех слой абстракции, скрывая, с какими именно физическими дисками они в данный момент работают. Администратор системы может добавлять физические тома в LVM и удалять их из него (см. ниже), но процессы (и пользователи) об этом знать не будут.
Примечание по названиям утилит LVM
Следует запомнить сразу - названия утилит для работы с разными уровнями LVM совпадают. Различие только в первых двух буквах этого названия. Это:
- pv* - для работы с физическими томами;
- vg* - для работы с группами томов;
- lv* - для работы с логическими томами.
Не стоит также пытаться зазубрить названия этих утилит и их ключи. Действовать стоит так:
1. Думаете, с каким уровнем LVM надо работать - физические тома, группы томов или логические тома.
2. Выбираете в зависимости от этого первые буквы названия: pv, vg или lv, соответственно.
3. Набираете их в консоли и нажимаете два раза TAB. Срабатывает автодополнение, которое показывает команды, начинающиеся с указанных букв.
4. Выбираете команду по ее названию, например, pvcreate для создания физических томов. Если вы ее запустите с ключом --help , она вам покажет все возможные ключи. За более подробной информацией стоит залезть в man конкретной команды.
По мере набора опыта работы с LVM нужда в такой последовательности отпадет. Необходимые команды и их опции запомнятся сами собой.
Создание
Я буду рассматривать создание LVM на уже установленной системе. Знание терминологии и принципов работы с ним в дальнейшем позволит найти в инсталляторе нужные пункты для создания логических томов на этапе установки системы.
Первый этап - это создание правильных разделов. Это такие разделы, которые LVM признает за свои и сможет при загрузке их корректно инициализировать. «Родной» тип разделов для LVM - 8E Linux LVM. Все, что будет дальше, не будет работать, если при создании разделов не указать приведенный корректный тип. Итак, создаем несколько разделов типа 8E с помощью любимого средства разбиения диска:
[root@localhost ~]# fdisk -l /dev/sdb
Disk /dev/sdb: 2147 MB, 2147483648 bytes
255 heads, 63 sectors/track, 261 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
Device Boot Start End Blocks Id System
/dev/sdb1 1 61 489951 8e Linux LVM
/dev/sdb2 62 261 1606500 5 Extended
/dev/sdb5 62 122 489951 8e Linux LVM
/dev/sdb6 123 261 1116486 8e Linux LVM
Еще раз. Пример я привожу с виртуальной машины, чего и вам советую на этапе обучения.
Я создал три раздела для работы с LVM. Сколько их создавать и какого размера решает сам администратор. Например, никто не мешает отдать целиком весь диск (/dev/sdb в данном случае) под власть LVM. В том, как это сейчас сделал я, смысла искать не стоит :). Мой пример преследует только цели демонстрации работы с LVM.
ВНИМАНИЕ! Форматировать созданные разделы НЕ надо!
Следующее, что мы должны сделать - это инициализировать созданные разделы как физические тома:
[root@localhost ~]# pvcreate /dev/sdb1
Physical volume "/dev/sdb1" successfully created
[root@localhost ~]# pvcreate /dev/sdb5
Physical volume "/dev/sdb5" successfully created
[root@localhost ~]# pvcreate /dev/sdb6
Physical volume "/dev/sdb6" successfully created
Если нет сообщений об ошибках, можно смело шагать вперед.
Следующий шаг - это создание группы томов. Делается это командой vgcreate (еще раз подчеркиваю похожесть названия утилит для работы с LVM). Самое трудное тут - это придумать имя группы томов, которое будет отражать ее назначение:
[root@localhost ~]# vgcreate fileserver /dev/sdb1 /dev/sdb5
Volume group "fileserver" successfully created
Аргументы vgcreate это название группы томов (fileserver) и те физические тома, которые мы включаем в эту группу. В данном случае я включил в нее только /dev/sdb1 /dev/sdb5, что нам и покажет утилита pvscan:
[root@localhost ~]# pvscan
PV /dev/sdb1 VG fileserver lvm2 [476.00 MiB / 476.00 MiB free]
PV /dev/sdb5 VG fileserver lvm2 [476.00 MiB / 476.00 MiB free]
...
PV /dev/sdb6 lvm2 [1.06 GiB]
...
Здесь мы видим созданные нами физические тома, их размер и к какой группе томов они относятся. Последний физический том (/dev/sdb6) у нас пока сам по себе. Для обнаружения наличия групп томов LVM (это нужно, например, если вы загрузились с Live CD, который не активирует LVM по умолчанию) есть аналогичная команда - vgscan:
[root@localhost ~]# vgscan
Reading all physical volumes. This may take a while...
Found volume group "fileserver" using metadata type lvm2
Активировать неработающий LVM можно командой vgchange -ay:
[root@localhost ~]# vgchange -ay
0 logical volume(s) in volume group "fileserver" now active
Это все для того же примера с LiveCD. Сейчас это делать было не обязательно. Вывод приведенной команды показывает наличие отсутствия логических томов, значит сейчас самое время создать их :). Для создания логических томов испольузется команда lvcreate:
[root@localhost ~]# lvcreate -L 300M -n samba fileserver
Logical volume "samba" created
Вуаля! Вы только что создали свой первый логический том. Синтаксис команды прост до безобразия:
- ключ -L указывает размер создаваемого тома. Поддерживаются суффиксы K (килобайты), M (мегабайты), G (гигабайты).
- ключ -n указывает название для тома (samba в данном случае)
- последний аргумент fileserver указывает группу томов, в которой мы создаем логический том (теоретически, групп может быть несколько).
Что важно - логические тома именуются системой следующим образом:
/dev/имя_группы_томов/имя_тома
В нашем примере это:
[root@localhost ~]# lvscan
ACTIVE '/dev/fileserver/samba' [300.00 MiB] inherit
Одно только это - хороший аргумент для использования LVM. Ведь не надо помнить что находится на /dev/sda3, /dev/sdb5 и т. п. Имена логических томов имеют вполне человеческое название (если их правильно назвать).
Еще несколько замечаний.
В группе томов можно создать столько томов, сколько будет нужно. Но не больше, чем есть дискового пространства в этой группе томов. Посмотреть, сколько его у нас есть (и самое главное сколько его еще осталось) можно командой vgdisplay:
[root@localhost ~]# vgdisplay fileserver
--- Volume group ---
VG Name fileserver
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 2
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 0
Max PV 0
Cur PV 2
Act PV 2
VG Size 952.00 MB
PE Size 4.00 MB
Total PE 238
Alloc PE / Size 75 / 300.00 MB
Free PE / Size 163 / 652.00 MB
VG UUID SZLgLK-b9V8-RiZV-gH5i-N0pA-2ppf-axLqfO
Сейчас для нас тут самое ценное - это VG Size 952.00 MB (общий размер дискового пространства группы томов), Alloc PE / Size 75 / 300.00 MB (уже выделенное для создания логических томов дисковое пространство), Free PE / Size 163 / 652.00 MB (свободное и еще не распределенное дисковое пространство - наш резерв).
PE тут - это физические экстенты. Они представляют собой нечто вроде кусков дискового пространства, на которые LVM «нарезает» физические тома. Все размеры логических томов всегда содержат целое число этих физических экстентов и всегда кратны их размеру (как видно из приведенных цифр размер экстента - 4Мб).
Теперь созданный том можно отформатировать и примонтировать:
[root@localhost ~]# mkdir /mnt/data
[root@localhost ~]# mkfs.ext4 /dev/fileserver/samba
...
[root@localhost ~]# mount /dev/fileserver/samba /mnt/data/
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/mapper/fileserver-samba
291M 11M 266M 4% /mnt/data
Как мы видим, наш логический том готов к использованию!
Увеличение логических томов
Самая мощная возможность LVM - это то, что размеры логических томов можно менять на лету. Правда, чтобы их уменьшить, «полет» придется прервать (об этом ниже), а вот увеличение размеров томов - это практически безопасная операция.
Предположим, что нам перестало хватать места на нашем логическом томе /dev/fileserver/samba.
Последовательность действий такая:
1. Сначала нужно убедиться в наличии необходимого нам дискового пространства в группе томов. Делается это командой vgdisplay. Допустим, мы хотим добавить к нашему логическому тому еще 300 Мб. Как мы видим (см. вывод команды vgdisplay выше), у нас еще достаточно свободного места в группе.
2. Увеличиваем логический том командой lvextend:
[root@localhost ~]# lvextend -L +200M /dev/fileserver/samba
Extending logical volume samba to 500.00 MB
Logical volume samba successfully resized
Новый размер тома (ключ -L) можно указывать и в относительных единицах (как в примере), и в абсолютных.
3. Если мы теперь посмотрим на вывод команды df -h мы увидим, что пока ничего не изменилось:
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/mapper/fileserver-samba
291M 11M 266M 4% /mnt/data
несмотря на то, что lvscan показывает верный размер:
[root@localhost ~]# lvscan
ACTIVE '/dev/fileserver/samba' [500.00 MB] inherit
Это произошло потому, что мы увеличили размер логического тома, но пока «забыли» сказать об этом файловой системе, расположенной «этажом выше». Давайте же изменим размер файловой системы. Делается это командной resize2fs (для ext2/ext3/ext4) или resize_reiserfs для одноименной системы:
[root@localhost ~]# resize2fs /dev/fileserver/samba
resize2fs 1.41.5 (23-Apr-2009)
Filesystem at /dev/fileserver/samba is mounted on /mnt/data; on-line resizing required
old desc_blocks = 2, new_desc_blocks = 2
Performing an on-line resize of /dev/fileserver/samba to 512000 (1k) blocks.
The filesystem on /dev/fileserver/samba is now 512000 blocks long.
Теперь все правильно:
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/mapper/fileserver-samba
485M 11M 450M 3% /mnt/data
Обратите внимание, что все показанное производилось на смонтированной файловой системе. То есть, все операции не требуют остановки серверов, приостановки работы пользователей и т. п.
Уменьшение логических томов
Уменьшение размера логического тома уже не такая тривиальная операция. Она требует специального подхода, четкой последовательности действий и размонтирования файловой системы (по крайней мере на момент написания).
ВНИМАНИЕ!
Шаги 2 и 3 очень часто путают местами, что приводит к потере данных, хранящихся на логическом томе.
Делается это все так:
1. Размонтируем файловую систему: umount /dev/fileserver/samba
2. Уменьшаем размер файловой системы. Для этого сначала сделаем проверку самой файловой системы. Утилита resize2fs не даст изменить размер до выполнения проверки. Конечно, у нее есть ключ -f, который заставит ее это сделать, но лучше перестраховаться и все-таки выполнить проверку:
[root@localhost ~]# fsck.ext4 -f /dev/fileserver/samba
e2fsck 1.41.5 (23-Apr-2009)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/fileserver/samba: 11/127512 files (0.0% non-contiguous), 26603/512000 blocks
[root@localhost ~]# resize2fs /dev/fileserver/samba 300M
resize2fs 1.41.5 (23-Apr-2009)
Resizing the filesystem on /dev/fileserver/samba to 307200 (1k) blocks.
The filesystem on /dev/fileserver/samba is now 307200 blocks long
3. Только после корректного выполнения двух предыдущих шагов уменьшаем размер логического тома:
[root@localhost ~]# lvreduce -L 300M /dev/fileserver/samba
WARNING: Reducing active logical volume to 300.00 MB
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce samba? [y/n]: y
Reducing logical volume samba to 300.00 MB
Logical volume samba successfully resized
В качестве размера тома (ключ -L), как и в случае с lvextend можно указывать и абсолютные и относительные единицы. Здесь мы также видим страшное предупреждение о потере данных. Несмотря на это (если вы не используете тестовые версии программ), ваши данные будут в целости и сохранности (скорее всего :) , 100% гарантии вам все равно никто не даст).
После этого монтируем файловую систему и смотрим что поменялось:
[root@localhost ~]# mount /dev/fileserver/samba /mnt/data/
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/mapper/fileserver-samba
291M 11M 266M 4% /mnt/data
Итак, если вы все делаете в указанной последовательности, вашим данным скорее всего ничего не грозит. Но лучше перед уменьшением тома все-таки сделать его резервную копию. Я сам многократно уменьшал физические тома без каких-либо потерь данных, но наличие резервной копии - это наличие резервной копии :).
Увеличение и уменьшение группы томов
Следующая возможность LVM - это возможность дополнять группу томов новыми физическими томами (например, если уже не хватает имеющихся) и выводить из группы не нужные больше физические тома (например, скорая поломка диска или замена оборудования). Лично я видел на форумах, что некоторые таким образом даже переносят работающую систему с одного диска на другой.
Давайте вернемся к нашему примеру. Допустим нам перестало хватать места в нашей группе томов и мы ее хотим дополнить новыми физическими томами. Делается это командой vgextend:
[root@localhost ~]# vgextend fileserver /dev/sdb6
Volume group "fileserver" successfully extended
[root@localhost ~]# vgdisplay fileserver
--- Volume group ---
VG Name fileserver
System ID
Format lvm2
Metadata Areas 3
Metadata Sequence No 5
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 1
Max PV 0
Cur PV 3
Act PV 3
VG Size 1.99 GB
PE Size 4.00 MB
Total PE 510
Alloc PE / Size 75 / 300.00 MB
Free PE / Size 435 / 1.70 GB
VG UUID SZLgLK-b9V8-RiZV-gH5i-N0pA-2ppf-axLqfO
Как мы видим (выделено), пул дискового пространства, которым мы располагаем, увеличился. Теперь его тоже можно использовать для увеличения существующих логических томов данной группы и для создания новых.
Следующая операция, которую тоже можно делать с LVM - это уменьшение группы томов. Прежде чем вывести физический том из группы - его необходимо освободить от данных. Первое, что тут следует сделать в данном случае - это убедиться, что дискового пространства, которое останется в группе, хватит для размещения этих данных. Разработчики LVM пока не владеют методами размещения данных в астральном пространстве, но работа над этим ведется :). Итак, посмотреть это можно командой pvscan:
[root@localhost ~]# pvscan
PV /dev/sdb1 VG fileserver lvm2 [476.00 MB / 176.00 MB free]
PV /dev/sdb5 VG fileserver lvm2 [476.00 MB / 476.00 MB free]
PV /dev/sdb6 VG fileserver lvm2 [1.06 GB / 1.06 GB free]
Здесь мы видим, что реально сейчас используется только первый физический том - /dev/sdb1. И еще мы тут видим один интересный аспект работы LVM: если какой-то логический том можно разместить на отдельном физическом целиком - LVM выберет именно этот путь.
Кстати, под словом free команда pvscan подразумевает не свободное от данных пространство, а пространство не выделенное в логические тома.
Итак, для освобождения физических томов от данных и размещения их на других физических томах той же группы есть команда pvmove:
[root@localhost ~]# pvmove /dev/sdb1
/dev/sdb1: Moved: 100.0%
По умолчанию данная программа требует только одного аргумента - имени освобождаемого тома. Также ей можно указать (вторым аргументом) и имя тома, на который нужно поместить данные.
Вывод команды pvscan теперь выглядит вот так:
[root@localhost ~]# pvscan
PV /dev/sdb1 VG fileserver lvm2 [476.00 MB / 476.00 MB free]
PV /dev/sdb5 VG fileserver lvm2 [476.00 MB / 476.00 MB free]
PV /dev/sdb6 VG fileserver lvm2 [1.06 GB / 788.00 MB free]
Как мы видим, теперь наш логический том «уехал» на другой раздел диска. Причем этот том смонтирован и с ним в этот момент могут работать пользователи.
Убрать освобожденный том из группы можно командой vgreduce:
[root@localhost ~]# vgreduce fileserver /dev/sdb1
Removed "/dev/sdb1" from volume group "fileserver"
[root@localhost ~]# pvscan
PV /dev/sdb5 VG fileserver lvm2 [476.00 MB / 476.00 MB free]
PV /dev/sdb6 VG fileserver lvm2 [1.06 GB / 788.00 MB free]
PV /dev/sdb1 lvm2 [478.47 MB]
Теперь мы видим, что наш физический том /dev/sdb1 «осиротел» и больше не принадлежит ни одной группе.
Снапшоты/Снимки
Следующая полезная возможность LVM - это снапшоты или снимки. Снимок - это как бы фотография дискового пространства оригинального тома. После выполнения снимка все изменения, происходящие на томе-оригинале, никак не видны на снимке. Все программы будут продолжать работать с оригинальным томом как ни в чем не бывало.
Сферы применения снапшотов могут быть самыми разнообразными. Например, резервное копирование базы данных. Если не использовать LVM - базу данных необходимо останавливать, копировать ее файлы куда-нибудь для последующего резервного копирования, а затем запускать ее заново. То есть делать это придется в нерабочее время. С LVM все проще - следует сделать снимок раздела с файлами базы данных и уже можно начинать делать резервную копию. Остановка базы данных не нужна.
Самая интересная особенность LVM при работе со снимками - это то, что снимок может занимать меньше дискового пространства, чем оригинал. Для этого используется режим Copy-on-Write, при котором реальное использование дискового пространства начинается только при изменении данных на томе-оригинале. То есть при попытке модификации файла на томе-оригинале неизмененный файл сначала сохраняется на томе-снимке, а уж затем модифицируется.
ВНИМАНИЕ! При заполнении тома-снимка до конца, происходит его уничтожение. То есть том продолжает существовать, но ни смонтировать его, ни просмотреть его содержимое (если он был смонтирован до этого) уже не получится. Эту особенность следует обязательно учитывать при задании размера тома-снимка в момент его создания.
Создание снимка делается хорошо известной командой lvcreate:
[root@localhost ~]# lvcreate -s -L 100M -n backup /dev/fileserver/samba
Logical volume "backup" created
Ключ -s указывает, что создаем мы именно снапшот, -n указывает имя создаваемого тома, а /dev/fileserver/samba показывает с какого именно тома мы делаем снимок.
Команда lvscan покажет нам, что мы создали снапшот:
[root@localhost ~]# lvscan
ACTIVE Original '/dev/fileserver/samba' [300.00 MB] inherit
ACTIVE Snapshot '/dev/fileserver/backup' [100.00 MB] inherit
Теперь можете убедиться в том, что изменения, происходящие с оригиналом, никак не повлияют на снапшот.
Полезные советы для работы с LVM
1. В руководстве по администрированию RHEL встретился один замечательный совет. При использовании LVM не следует стараться распределить все имеющееся дисковое пространство в логические тома. Гораздо лучше другой путь. При распределении дискового пространства следует сделать это по своему опыту, ориентируясь на минимально необходимые потребности пользователей системы или работающих сервисов. Оставшееся в группе пространство будет «горячим» резервом, который администратор сможет добавить при нехватке места. Как было видно выше - добавление дискового простраства (увеличение логических томов) операция легкая и быстрая, в отличие от уменьшения.
Полезные источники (которые было бы неплохо посмотреть):
Anton Chernyshov
posted at
Краткое введение в программирование на Bash - часть II
Выкладываю перевод второй часть статьи про введение в программирование на bash, начатое здесь.
В своей второй статье Гарольд продолжает свое первоклассное введение в программирование на bash. На этот раз он объясняет, как выполнять арифметические операции в скриптах bash, как определить функции в своих программах. Завершается статья введением в такие продвинутые вещи как чтение пользовательского ввода, обработка скриптом аргументов, перехватывание сигналов и обработка кодов завершения программ.
Безусловно, результаты прочтения превзойдут все ожидания! После этой статьи вас уже нельзя будет назвать новичком. Ведь вы на пути к тому, чтоб называться мастером программирования на bash!
Арифметика и bash
bash позволяет выполнять арифметические операции. Как вы уже видели в предыдущей статье, арифметика выполняется с помощью команды expr. Однако, подобно команде true, этот вариант считается медленным. Причина кроется в том, что для использования true и expr оболочка должна предварительно запустить их. Лучше всего использовать встроенную в bash функцию, которая работает быстрее. Аналогично тому, что альтернативой true является команда ":", альтернатива expr - заключение арифметического выражения в конструкцию вида $((...)). Будьте внимательны, она отличается от $(...). Отличие тут в количестве скобок. Так давайте же испробуем это:
#!/bin/bash
x=8 # присваиваем x значение 8
y=4 # присваиваем y значение 4
x=8 # присваиваем x значение 8
y=4 # присваиваем y значение 4
# результат сложения x и y сохраняем в z:
z=$(($x + $y))
echo «Сумма $x и $y равна $z»
z=$(($x + $y))
echo «Сумма $x и $y равна $z»
Как обычно, выбор используемого метода вычислений за вами. Если использование expr для вас более комфортно и привычнее, чем $((…)), используйте его.
bash умеет выполнять сложение, вычитание, умножение, целочисленное деление и получение остатка от деления. Каждое арифметическое действие имеет соответствующий ему оператор:
Действие | Оператор |
Сложение |
+ |
Вычитание |
- |
Умножение |
* |
Целочисленное деление |
/ |
Остаток от деления |
% |
Большинство из вас должно быть знакомо с первыми четырьмя операциями. Если вы не знаете, что такое деление по модулю, то это просто число равное остатку от деления одного целого числа на другое. Ниже приведен пример выполнения арифметических операций в bash:
#!/bin/bash
x=5 # устанавливаем x равным 5
y=3 # устанавливаем y равным 3
x=5 # устанавливаем x равным 5
y=3 # устанавливаем y равным 3
# сохраняем сумму x и y в переменную add
add=$(($x + $y))
add=$(($x + $y))
# сохраняем разность x и y в переменную sub
sub=$(($x – $y))
# умножаем x на y и сохраняем результат в переменную mul
mul=$(($x * $y))
mul=$(($x * $y))
# в переменную div сохраняем результат деления x на y
div=$(($x / $y))
# получаем остаток от деления x на y и сохраняем его в переменную mod
mod=$(($x % $y))
mod=$(($x % $y))
# печатаем ответы
echo «Сумма равна: $add»
echo «Разность равна $sub»
echo «Произведение равно $mul»
echo «Результат деления $div»
echo «Остаток от деления $mod»
echo «Сумма равна: $add»
echo «Разность равна $sub»
echo «Произведение равно $mul»
echo «Результат деления $div»
echo «Остаток от деления $mod»
Код, приведенный выше, можно было бы написать с использованием expr. Например, вместо add=$(($x + $y)) мы могли бы использовать add=$(expr $x + $y) или add=`expr $x + $y`.
Чтение ввода пользователя
А теперь - самое интересное. Мы напишем свой скрипт так, что он будет взаимодействовать с пользователем, а пользователь с ним. Команда для получения данных от пользователя - read. Это встроенная в bash команда, сохраняющая ввод пользователя в указанной переменной:
#!/bin/bash
# спросить у пользователя его имя и поздороваться с ним
echo -n “Введите свое имя: ”
read user_name
echo “Привет $user_name!”
# спросить у пользователя его имя и поздороваться с ним
echo -n “Введите свое имя: ”
read user_name
echo “Привет $user_name!”
Переменная здесь - это user_name. Конечно, мы могли бы назвать ее как угодно. read прервет выполнение скрипта и будет ждать, пока пользователь введет что-нибудь и нажмет клавишу ENTER. Если клавиша ENTER была нажата без ввода чего-либо, read запустит следующую строку кода. Попробуйте это сделать. Ниже приведен тот же пример, только на этот раз мы
проверяем, вводит ли пользователь что-либо:
#!/bin/bash
# спрашиваем имя пользователя и выводим приветствие
echo -n «Введите имя: »
read user_name
# спрашиваем имя пользователя и выводим приветствие
echo -n «Введите имя: »
read user_name
# проверка ввода пользователя
if [ -z «$user_name» ]; then
echo «Вы не сказали мне свое имя!»
exit
fi
echo «Привет $user_name!»
if [ -z «$user_name» ]; then
echo «Вы не сказали мне свое имя!»
exit
fi
echo «Привет $user_name!»
В приведенном примере, если пользователь нажал ENTER и не ввел при этом ничего, наша программа напишет об этом и завершит свою работу. В противном случае она напечатает приветствие. Получение пользовательского ввода полезно для интерактивных программ, которые требуют от пользователя ввести какие-то данные.
Функции
Использование функций делает сопровождение своих скриптов проще. Проще говоря, это хороший способ разделить программу на более мелкие куски. Функция выполняет определенное действие и может возвращать то значение, какое вы пожелаете. Прежде чем продолжать, я приведу пример скрипта, написанного с использованием функции:
#!/bin/bash
# функция hello() печатает сообщение
# функция hello() печатает сообщение
hello()
{
echo «Вы находитесь в функции hello()»
}
{
echo «Вы находитесь в функции hello()»
}
echo «Вызываем функцию hello()…»
hello
hello
Попробуйте запустить код из примера выше. Функция hello() в нем имеет только одно предназначение - просто напечатать сообщение. Но, конечно же, они могут решать и более сложные задачи. Выше мы вызвали функцию hello(), используя строку:
hello
Когда запускается эта строка, bash ищет скрипт для строки hello(). Он находит его в начале файла и выполняет его содержимое. Функции всегда вызываются по своему имени, что мы и видели выше. При написании функции вы можете обьявить ее, просто указав имя_функции(), как это сделано выше, или если вы хотите сделать ее объявление более явным, можете объявить ее так: function имя_функции(). Ниже представлен альтернативный способ написания функции hello() :
function hello()
{
echo «Вы находитесь в функции hello()»
}
{
echo «Вы находитесь в функции hello()»
}
Функции имеют в имени пустые открывающую и закрывающую скобки: "()", за ними следует пара фигурных скобок: «{...}», содержащих тело функции. Другими словами, весь код функции заключен в эти фигурные скобки. Функции всегда должны быть предварительно объявлены до своего вызова. Давайте попробуем в приведенном выше примере вызвать функцию до ее объявления:
#!/bin/bash
echo «Вызов функции hello() …»
hello
# функция hello() просто выводит сообщение
hello()
{
echo «Вы находитесь в функции привет ()»
}
echo «Вызов функции hello() …»
hello
# функция hello() просто выводит сообщение
hello()
{
echo «Вы находитесь в функции привет ()»
}
Вот что мы получим, когда попытаемся запустить этот скрипт:
$ ./hello.sh
Вызов функции привет () ...
./hello.sh: hello: command not found
Вызов функции привет () ...
./hello.sh: hello: command not found
Как видите, мы получили сообщение об ошибке. Поэтому стоит всегда размещать ваши функции в начале кода или, по крайней мере, непосредственно перед вызовом функции. Еще один пример использования функции:
#!/bin/bash
# admin.sh – инструмент для администратора
# admin.sh – инструмент для администратора
# функция new_user () создает новую учетную запись пользователя
new_user()
{
echo «Подготовка к созданию новых пользователей ...»
sleep 2
# запускаем программу adduser
adduser
}
adduser
}
echo «1. Добавить пользователя»
echo «2. Выход»
echo «2. Выход»
echo «Укажите, что вы хотите сделать:"
read choice
case $choice in
1) new_user # вызов функции new_user()
;;
*) exit
;;
esac
read choice
case $choice in
1) new_user # вызов функции new_user()
;;
*) exit
;;
esac
Для того чтобы приведенный скрипт работал правильно, вам необходимо запустить его из-под пользователя root, т. к. иначе программа adduser не сможет создать новых пользователей. Надеюсь, этот пример (хоть он и краток) показывает положительный эффект от использования функций.
Перехват сигналов
Вы можете использовать встроенную в bash программу trap для перехвата сигналов в своих программах. Это хороший способ изящно завершать работу программы. Например, если пользователь, когда ваша программа работает, нажмет CTRL-C - программе будет отправлен сигнал interrupt (SIGINT, signal (7)), который завершит ее. trap позволит вам перехватить этот сигнал, что даст возможность либо продолжить выполнение программы, либо сообщить пользователю, что программа завершает работу. Синтаксис этой команды такой:
trap action signal
Здесь:
action - то, что вы хотите делать, когда сигнал получен;
signal - сигнал, на который стоит реагировать.
Список сигналов можно посмотреть с помощью команды trap -l . При указании сигналов в своих скриптах можно опустить первые три буквы названия сигнала, т. е. SIG. Например, сигнал прерывания это - SIGINT. В вашем скрипте, в качестве его имени, можно указать просто INT. Вы также можете использовать номер сигнала, указанный рядом с его именем. Например, числовое значение сигнала SIGINT - 2. Попробуйте написать и запустить приведенный ниже пример:
#!/bin/bash
# использование команды trap
# использование команды trap
# перехватываем нажатие CTRL-C и запускаем функцию sorry()
trap sorry INT
# function sorry() prints a message
sorry()
{
echo «Извини меня, Дэйв. Я не могу этого сделать»
sleep 3
}
sorry()
{
echo «Извини меня, Дэйв. Я не могу этого сделать»
sleep 3
}
# обратный отсчет от 10 до 1:
echo «Подготовка к уничтожению системы»
for i in 10 9 8 7 6 5 4 3 2 1; do
echo «Осталось $i секунд до уничтожения...»
sleep 1
done
echo «Запуск программы уничтожения!»
for i in 10 9 8 7 6 5 4 3 2 1; do
echo «Осталось $i секунд до уничтожения...»
sleep 1
done
echo «Запуск программы уничтожения!»
Наберите и запустите приведенный пример. Когда программа будет работать и вести обратный отсчет, нажмите CTRL-C. Это действие отправит программе сигнал прерывания - SIGINT. Тем не менее сигнал будет перехвачен командой trap, которая, в свою очередь, выполнит функцию sorry(). Вы можете заставить trap игнорировать сигнал, указав символ кавычек вместо указания действия. Также вы можете отключить ловушку с помощью тире: "-". Например:
# запускать функцию sorry(), если получен сигнал SIGINT
trap sorry INT
trap sorry INT
# отключение ловушки
trap – INT
# ничего не делать при получении сигнала SIGINT
trap ” INT
Если вы отключаете ловушку, программа работает как обычно - при получении сигнала прерывается ее исполнение и она завершает работу. Когда вы говорите trap ничего не делать при получении сигнала - она делает именно это. Ничего. Программа будет продолжать работать, игнорируя сигнал.
Логические И и ИЛИ
Вы уже видели, что такое управляющие структуры и как их использовать. Для решения тех же задач есть еще два способа. Это логическое И - "&&" и логическое "ИЛИ" - « || ». Логическое И используется следующим образом:
выражение_1 && выражение_2
Сначала выполняется выражение, стоящее слева, если оно истинно, выполняется выражение, стоящее справа. Если выражение_1 возвращает ЛОЖЬ, то выражение_2 не будет выполнено. Если оба выражения возвращают ИСТИНУ, выполняется следующий набор команд. Если какое-либо из выражений не истинно, приведенное выражение считает ложным в целом. Другими словами, все работает так:
если выражение_1 истинно И выражение_2 истинно, тогда выполнять...
Примечание переводчика: При работе с булевыми переменными ИСТИНА и ЛОЖЬ (True и False), bash ведет себя отлично от других языков программирования. В других языках 0 соответствует False (Ложь), а 1 - True (Истина). В bash все наоборот. Связано это с такой вещью, как коды завершения программ (см. ниже).
Об этом следует всегда помнить при написании своих скриптов!
Пример использования:
#!/bin/bash
x=5
y=10
if [ "$x" -eq 5 ] && [ "$y" -eq 10 ]; then
echo «Оба условия верны»
else
echo «Условия не верны»
fi
x=5
y=10
if [ "$x" -eq 5 ] && [ "$y" -eq 10 ]; then
echo «Оба условия верны»
else
echo «Условия не верны»
fi
Здесь мы находим, что переменные х и у содержат именно те значения, которые мы проверям, поэтому проверяемые условия верны. Если вы измените значение с х = 5 на х = 12, а затем снова запустите программу, она выдаст фразу «Условия не верны».
Логическое ИЛИ используется аналогичным образом. Разница лишь в том, что оно проверяет ошибочность выражения слева. Если это так - оно начинает выполнять следующий оператор:
выражение_1 || выражение_2
Данное выражение в псевдокоде выглядит так:
если выражение_1 истинно ИЛИ выражение_2 истинно, выполняем ...
Таким образом, любой последующий код будет выполняться, если хотя бы одно из выражений истинно:
#!/bin/bash
x=3
y=2
if [ "$x" -eq 5 ] || [ "$y" -eq 2 ]; then
echo «Одно из условий истинно»
else
echo «Ни одно из условий не является истинным»
fi
x=3
y=2
if [ "$x" -eq 5 ] || [ "$y" -eq 2 ]; then
echo «Одно из условий истинно»
else
echo «Ни одно из условий не является истинным»
fi
Здесь вы видите, что только одно из выражений истинно. Попробуйте изменить значение у и повторно запустите программу. Вы увидите сообщение, что ни одно из выражений не является истинным.
Аналогичная реализация условия с помощью оператора if будет большего размера, чем вариант с использованием логического И и ИЛИ, поскольку потребует дополнительного вложенного if. Ниже приведен код, реализующий тот же функционал, но с использованием оператора if:
#!/bin/bash
x=5
y=10
if [ "$x" -eq 5 ]; then
if [ "$y" -eq 10 ]; then
echo «Оба условия верны»
else
echo «Оба условия неверны»
fi
fi
x=5
y=10
if [ "$x" -eq 5 ]; then
if [ "$y" -eq 10 ]; then
echo «Оба условия верны»
else
echo «Оба условия неверны»
fi
fi
Приведенный код менее нагляден для чтения и требует для своего написания больших усилий. Но у вас остается возможность для избавления себя от всех этих трудностей путем использования операторов логических И и ИЛИ.
Использование аргументов
Возможно, вы уже заметили, что большинство программ в Linux не интерактивны. Вы должны указать им какие-то параметры, в противном случае вы получите сообщение со списком возможных аргументов. Возьмем, к примеру, команду more. Если вы не укажете имя файла, она выдаст краткую справку по использованию программы. Ну и конечно же возможно сделать так, чтобы ваши скрипты также могли принимать аргументы. Для этого вам нужно знать что такое переменная вида $#. В ней содержится общее количество аргументов, переданных программе. Например, если вы запустите программу следующим образом:
$ что-то параметр
то значение переменной $# будет равно единице, потому что программе передан только один аргумент. Для двух аргументов ее значение будет равно двум и так далее. Также стоит знать о том, что каждый параметр командной строки (включая даже имя скрипта!!!) может также сохраняться в соответствующие переменные. Так, имя нашей программы что-то будет сохранено в переменной $0. Аргумент программы параметр сохранится в переменной $1. Вы можете использовать до 9 переменных, начиная с $0 (обозначающего имя скрипта), а затем $1-$9, обозначающие аргументы програмы. Давайте посмотрим, как это работает:
#!/bin/bash
# скрипт, печатающий свои аргументы
# проверяем, переданы ли скрипту аргументы:
# скрипт, печатающий свои аргументы
# проверяем, переданы ли скрипту аргументы:
if [ "$#" -ne 1 ]; then
echo «корректный запуск программы: $0 <параметр>»
fi
echo «Переданный параметр - $1»
Приведенный скрипт ожидает один и только один аргумент для своего запуска. Если вы не укажете ему аргументов - будет выводиться справочная информация. В противном случае, если при запуске указан какой-то аргумент - он передается в наш скрипт, который выведет его на экран. Напоминаю, что $0 это имя скрипта. Именно поэтому эта переменная используется в справочном сообщении. Последняя строка выводит переданный программе параметр - $1.
Работа с временными файлами
Довольно часто вам будет необходимо создавать временные файлы. Обычно это файл, в котором хранятся какие-то используемые скриптом данные либо что-то еще. Как только работа скрипта будет завершена, этот файл нужно удалить. При создании такого файла вы должны задать его имя. Проблема тут кроется в том, что файл, создаваемый вами, не должен случайно переписать уже существующий в той же директории, если их имена совпадут. Для того чтобы создать временный файл с гарантированно уникальным именем, вам нужно использовать символ «$$» символ, либо как префикс, либо как суффикс к имени создаваемого файла. Предположим, вы хотите создать временный файл с именем hello. Возможно, что у пользователя, который работает с нашим скриптом, уже есть файл с таким именем. Создавая файл с именем hello.$$ или $$hello, вы создадите файл с уникальным именем. Например:
$ touch hello
$ ls
hello
$ ls
hello
$ touch hello.$$
$ ls
hello hello.689
Примерно так и будет выглядеть имя вашего временного файла.
Примечание переводчика: В переменной $$ обычно хранится следующий свободный PID. Именно поэтому использование такой переменной гарантирует уникальные имена для вновь создаваемых файлов.
Коды завершения программ
Большинство программ возвращают в операционную систему какое-то число, показывающее, насколько удачно программа завершила свою работу. Например, man-страница grep говорит, что grep вернет 0, если заданный шаблон найден, и 1, если совпадений не найдено. Почему нас так волнуют эти коды завершения? По разным причинам. Допустим, мы хотим проверить - есть ли пользователь с данным именем в системе? Один из способов сделать - использовать команду вида: grep имя_пользователя /etc/passwd . Допустим, имя пользователя - vasya:
$ grep vasya /etc/passwd
$
$
Ничего не вывелось. Это означает, что grep не обнаружила заданного пользователя. Но для нас было бы значительно лучше получить сообщение об этом. Это как раз тот случай, когда нужно использовать код завершения программы. Он сохраняется в переменной с именем $? . Посмотрим на следующий фрагмент кода:
#!/bin/bash
# ищем пользователя vasya в /etc/passwd,
# ищем пользователя vasya в /etc/passwd,
# весь вывод перенаправляем в /dev/null
grep vasya /etc/passwd > /dev/null 2>&1
# смотрим код завершения и действуем по обстоятельствам:
if [ "$? -eq 0 ]; then
echo «Пользователь vasya найден»
exit
else
echo «Пользователь vasya не найден»
fi
Теперь, когда вы запустите скрипт, он будет перехватывать и анализировать код завершения grep. Если он равен 0, значит пользователь найден и мы выводим соответствующее сообщение об ошибке. В противном случае скрипт напечатает, что пользователя найти не получилось. Это очень простой способ использования получаемого кода завершения программы. По мере практики вы сами будете понимать, для решения какой задачи вам нужно использовать эти коды завершения.
Если вас озадачивает конструкция вида 2>&1, тут все довольно просто. В Linux этими числами обозначаются дескрипторы файлов. 0 - стандартный ввод (по умолчанию, клавиатура), 1 стандартный вывод (по умолчанию, монитор) и 2 - вывод стандартных ошибок (по умолчанию, монитор). Весь вывод команды идет в файл с дескриптором 1, любые ошибки отправляются в файл с дескриптором 2. Если вы не хотите, чтобы сообщения об ошибках появлялись на экране, просто перенаправьте его в /dev/null. Но это не прекратит вывод на экран обычной информации. Например, если у вас нет разрешения на чтение домашнего каталого другого пользователя, вы не сможете просмотреть список его содержимого:
$ ls /root
ls: /root: Permission denied
ls: /root: Permission denied
$ ls /root 2> /dev/null
$
Как видите, во второй раз информация об ошибке не была напечатана. Все то же самое относится к другим программам и дескриптору 1. Если вы не хотите видеть нормальный выход из программы, то есть хотите, чтобы она работала молча, вы можете перенаправить в /dev/null и его. Теперь, если вы не хотите видеть вообще никакого вывода программы - добавьте в нее следующее:
$ ls /root > /dev/null 2>&1
Это означает, что программа будет отправлять свой вывод и ошибки, которые возникают в /dev/null, т. е. будет работать молча, что нам и нужно.
Примечание переводчика: на самом деле все работает так:
Конструкция вида 2>&1 перенаправляет вывод ошибок (дескриптор 2) на стандартный вывод (дескриптор 1). Знак «загогулины» - & - тут нужен для того, чтобы пояснить bash, что вы имеете в виду не файл с именем 1, а именно файл с дескриптором 1, т. е. стандартный вывод. Если вы укажете что-то вроде:
$ команда 2>1
то стандартный вывод ошибок пойдет в файл с именем 1. Конструкцией 2>&1 мы «сцепляем» вывод команды и вывод ошибок вместе. А первым перенаправлением (первым символом > в коментируемой команде) мы отправляем весь вывод команды в /dev/null. Чтобы дополнительно понять, как все работает, можете поэкспериментировать, убрав 2>&1 из команды и перезапустив ее.
А что если вы хотите, чтобы ваш скрипт тоже возвращал какой-нибудь код завершения при выходе? Команда exit может принимать один аргумент - тот самый код завершения. Обычно число 0 используется для обозначения успешного завершения работы. Число, отличное от нуля означает, что произошла какая-то ошибка. Какое число возвращать - решает сам програмист. Посмотрим приведенный пример:
#!/bin/bash
if [ -f "/etc/passwd" ]; then
echo «Файл passwd существует»
exit 0
else
echo «Нет такого файла»
exit 1
fi
if [ -f "/etc/passwd" ]; then
echo «Файл passwd существует»
exit 0
else
echo «Нет такого файла»
exit 1
fi
Задавая значение кода завершения, вы делаете возможным для других скриптов, использующих ваш скрипт, анализировать результаты его работы.
Переносимость ваших скриптов на bash
При написании ваших собственных скриптов важно делать это так, чтобы они оставались переносимыми. Термин «переносимость» означает, что если ваш скрипт работает под Linux, то он должен работать в другой Unix-системе с малыми изменениями или вообще без них. Чтобы добиться этого, вы должны быть осторожны при вызове внешних программ. Разработчик должен при этом ответить на вопрос: "Будет ли эта программа доступна на другом варианте Unix?" (и что более важно - будет ли она там работать также, как на Linux - прим. перев.). Допустим, вы используете программу foo, которая на Linux работает аналогично echo, поэтому вместо echo вы используете ее. Но если ваш скрипт будет работать на других системах, где нет программы foo, он начнет выдавать сообщения об ошибках. Кроме того, имейте в виду, что разные версии bash могут иметь разные методы для одних и тех же операций. Например, конструкция VAR = $(ps) делает то же самое, что и VAR = `ps`, но на самом деле старые версии оболочек, например Bourne shell (sh), признают только последний синтаксис. Если вы собираетесь распространять свои скрипты, обязательно включайте текстовый файл README, который будет предупреждать пользователя о любых сюрпризах, в том числе и о том, что скрипт проверялся на такой-то версии bash. Желательно также указать, какие программы и библиотеки (и каких версий) будут нужны скрипту.
Примечание переводчика: Для проверки наличия в скрипте команд и функций специфичных для bash в ALT Linux есть пакет checkbashisms, который взят из пакета devscripts Debian.
Заключение
Пришла пора завершить это краткое введение в написание скриптов на bash. Однако ваше обучение этому умению еще не завершено. В тоже время, написанного вполне достаточно, чтобы вы могли модифицировать имеющиеся скрипты и писать собственные. Если вы действительно хотите стать мастером написания скриптов на bash, я рекомендую приобрести книгу «Learning the bash shell» (Изучение оболочки bash), 2-е издание издательства O'Reilly & Associates, Inc.
Скрипты на bash идеально подходят для повседневной работы по администрированию. Но если вы планируете что-то более серьезное, следует использовать гораздо более мощный язык, такой как C или Perl. Удачи!