
 Member
Member DimStar
DimStaropenSUSE Tumbleweed – Review of the week 2020/48
Dear Tumbleweed users and hackers,
After last week being filled with problems, this week felt like a ‘relaxing one’ – not that there would be fewer changes incoming, but we could focus on those changes instead of cuddling the infrastructure. And so it comes that we managed to publish 5 snapshots during this week (1119, 1121, 1123, 1124, and 1125).
The most interesting changes included:
- GNOME 3.38.1 – it took a while, but at last, it’s there
- KDE Frameworks 5.76.0
- Pango 1.48.0
- Mozilla Thunderbird 78.5.0
- binutils 2.35.1
- pam 1.5.0
- Mesa 20.2.3
- Linux kernel 5.9.10
- Qt 5.15.2
And as usual, Tumbleweed does not stop rolling, and staging areas are currently filled with these changes:
- GNOME 3.38.2
- Linux kernel 5.9.11
- brp-check-suse: a bug fix in how it detected dangling symlinks (it detected them, but did not fail as it was supposed to)
- permissions package: prepares for easier listing, while supporting a full /usr merge
- RPM 4.16: still a few packages build failures
- Ruby 3.0: mainly YaST not ready for that switch
- First experiments with rpmlint 2.0 started in Staging:M
- openssl 3.0: currently alpha 9 in Staging:O

Using HP Printers & Scanners with openSUSE
Several HP Printers and Scanners require a non-free software plugin driver to run on Linux distributions. openSUSE does not come bundled with the non-free plugin.
HP provides an automatic installer for HPLIP (HP Linux Imaging and Printing). The installer is known to work on several Linux distributions including SUSE (13.2, 42.1, 42.2, 42.3, 15.0, 15.1, 15.2). Therefore, it should work on openSUSE.
Download the HPLIP installer and run it as follows:
sh hplip-3.20.9.run
Follow the on-screen instructions to complete the setup. Once done, connect your HP Printer/Scanner. It will be automatically detected and installer.
The files downloaded for the setup will be available in a folder with the same name as the HPLIP installation script, i.e in this case hplip-3.20.9.


Outside The Cubicle | DeWalt 20v Max Cordless Router

GNOME, KDE Frameworks, Mutt update in Tumbleweed
Four openSUSE Tumbleweed snapshots have been released since last Thursday.
Only two packages came in the most recent 20201124 snapshot. Email client mutt had a version bump from 1.14.7 to 2.0.2; the new major release was not because of the magnitude of features but because a few changes are backward incompatible. There were some important changes highlighted like when using attach-file to browse and add multiple attachments to an email; quit can be used to exit after tagging the files. For the full list, read the release notes. The release also fixed a Common Vulnerabilities and Exposures that ensures the IMAP connection is closed after a connection error to avoid sending credentials over an unencrypted connection. The other package in the snapshot was the Ruby static code analyzer rubygem-rubocop. The updated 1.3.1 version offers multiple new features and fixes like reading the required_ruby_version from gemspec file if it exists.

The 20201123 snapshot had several GNU package updates like an update to GNU Compiler Collection 10, which Included a fix for a memcpy miscompilation on aarch64. GNU binary tool binutils cleaned up the specfile in the 2.35.1 version and general-purpose parser generator bison 3.7.4 now defines YYBISON macro as an integer. The ipset 7.9 update enabled memory accounting for ipset allocations and the Passlib password hashing library for Python, python-passlib 1.7.4, added optional dependencies for web framework Django and apache2-utils. Bar code reader package zbar 0.23.1 changed defaults to autodetect Python and GTK versions. Several YaST packages were updated like yast2-network 4.3.28, which provided a fix for the detecting of connection configuration changes, and yast2-firstboot 4.3.8, which removed a duplicated lan client from the firstboot control file and modified the firstboot_dhcp_setup client using the installation dhcp setup client directly.
Snapshot 20201121 highlights the CVE hunting the Mozilla Thunderbird project did in version 78.5.0. The email client closed out more than a dozen CVEs like single-word search queries that were broadcast to local networks (CVE-2020-26966) and the software keyboards that may have remembered typed passwords (CVE-2020-26965). Privacy guard gpg2 2.2.24 fixed the encrypt+sign hash algo preference selection for Elliptic Curve Digital Signature Algorithm, which is needed for keys created from existing smartcard based keys. Support exporting secret keys was made to the cryptography support program gpgme 1.15.0. Sudo now logs when a user-specified command-line option is rejected by a sudoers rule in sudo 1.9.3p1 and ucode-intel 20201118 removed TGL/06-8c-01/80 due to functional issues with some original equipment manufacturer platforms.
The snapshot released a week ago on Thursday was a release many were waiting for with GNOME 3.38. Snapshot 20201119 updated GNOME users to the new Orbis release that highlights the main functionality of the desktop and provides first time users a nice welcome to GNOME with the GNOME tour welcome app. The release provides better screen recording infrastructure in GNOME Shell, made improvements to take advantage of multimedia processing package PipeWire and kernel APIs to reduce resource consumption and improve responsiveness. KDE Frameworks 5.76.0 arrived in the snapshot as well made improvements to Plasma’s Breeze Icons; Plasma Frameworks locked the header colors of Breeze Dark and Breeze Light themes and remove unnecessary anchors in the ComboBox.contentItem. Kirigami package improved the look of the FormLayout on mobile and fixed the menus in contextualActions. The 2.66.3 glib2 package fixed sending large D-Bus messages. Tools for accessing the process power of the Linux Kernel gained Alder Lake, Rocket Lake and Sapphire Rapid support in the update to cpupower 5.10. Other notable packages to that updated in the snapshot were gtksourceview4 4.8.0, pango 1.48.0, libsoup 2.72.0 and vala 0.50.1.

Presenting Cockpit Wicked
What is Cockpit?
If you are into systems management, you most likely have heard about
Cockpit at some point. In a nutshell, it offers a good looking
web-based interface to perform system tasks like inspecting the logs, applying system updates,
configuring the network, managing services, and so on. If you want to give it a try, you can install
Cockpit in openSUSE Tumbleweed just by typing zypper in cockpit.
And Cockpit Wicked?
Recently, the YaST team got informed that MicroOS developers wanted to offer Cockpit as an option for system management tasks. Unfortunately, Cockpit does not have support for Wicked, a network configuration framework included in SUSE-based distributions.
As we are experts in systems management, we were given the task of building a Cockpit module to handle network configuration using Wicked instead of NetworkManager. And today we are presenting the first version of such a module. It is still a work in progress, but it already supports some basic use cases:
- Inspect interfaces configuration.
- Configure common IPv4/IPv6 settings.
- Set up wireless devices, although only WEP and WPA-PSK authentication mechanisms are supported.
- Set up bridges, bonding and VLAN devices.
- Manage routes (work in progress).
- Set basic DNS settings, like the policy, the search list or the list of static name servers.
Why a new module?
Cockpit already features a nice module to configure the network so you might be wondering why not extending the original instead of creating a new one. The module shipped with Cockpit is specific to NetworkManager and adapting it to a different backend can be hard.
In our case, we are trying to build something that could be adapted in the future to support more backends, but we are not sure how realistic this idea is.
See It In Action
Before giving it a try, we guess you would like to see some screenshots, right? So here you are. Below you can see the list of interfaces and some details about their configurations. It features a switch to activate/deactivate each device and a button to wipe the configuration. You can change the configuration by clicking on the links.

While applying the changes, Cockpit Wicked tries to keep you informed by updating the user interface as soon as possible. And, if something goes wrong, you will get an error message. Sure, we need to improve those messages, but you have something to look into it.

At this point, WEP and WPA-PSK authentication is supported by wireless devices, and we plan to expand the support for the same mechanisms that are already supported by YaST.

Another interesting feature is the support for some virtual devices like bridges, bonding and VLAN.

And last but not least, support for routes management or DNS configuration is rather simple but already functional.

Installation
The module has started its way to Tumbleweed. But, if you are interested in giving it a try, you can grab the RPM from the GitHub release page.
If you are already using Wicked, we recommend you to take a backup of your network configuration
just in case something goes wrong. Just copying the /etc/sysconfig/network directory is enough. In
case you are using NetworkManager but you are curious enough to give this module a try, you can
easily switch to Wicked using the YaST2 network module.YaST2 Network
Bear in mind that this module will replace the one included by default in Cockpit. If you want the
original module back, you need to uninstall the cockpit-wicked package.
What’s Next?
Apart from polishing what we already have and fixing bugs, there are many things to do. In the short term, we are focused on:
- Submitting the strings for translation so you can enjoy the module in your preferred language.
- Improving the UX according to our usability experts.
- Filtering out interfaces that are not managed by Wicked (like
virbr0).
But before deciding our next steps, we would love to hear from you. So please, if you have some time and you are interested, give the module a try and tell us what you think.
Additional Links
- GitHub repository: https://github.com/openSUSE/cockpit-wicked
- Development tips: https://github.com/openSUSE/cockpit-wicked/blob/master/DEVELOPMENT.md
Gaming Rack Design and Construction
Web interfaces for your syslog server – an overview
This is the 2020 edition of my most read blog entry about syslog-ng web-based graphical user interfaces (web GUIs). Many things have changed in the past few years. In 2011, only a single logging as a service solution was available, while nowadays, I regularly run into others. Also, while some software disappeared, the number of logging-related GUIs is growing. This is why in this post, I will mostly focus on generic log management and open source instead of highly specialized software, like SIEMs.
Why grep is not enough?
Centralized event logging has been an important part of IT for many years for many reasons. Firstly, it is more convenient to browse logs in a central location rather than viewing them on individual machines. Secondly, central storage is also more secure. Even if logs stored locally are altered or removed, you can still check the logs on the central log server. Finally, compliance with different regulations also makes central logging necessary.
System administrators often prefer to use the command line. Utilities such as grep and AWK are powerful tools, but complex queries can be completed much faster with logs indexed in a database and a web interface. In the case of large amounts of messages, a web-based database solution is not just convenient, it is a necessity. With tens of thousands of incoming messages per second, the indexes of log databases still give Google-like response times even for the most complex queries, while traditional text-based tools are not able to scale as efficiently.
Why still syslog-ng?
Many software used for log analysis come with their own log aggregation agents. So why should you still use syslog-ng then? As organizations grow, so does the IT staff starts to diversify. Separate teams are created for operations, development and security, each with its own specialized needs in log analysis. And even the business side often needs log analysis as an input for business decisions. You can quickly end up with 4-5 different log analysis and aggregation systems running in parallel and working from the very same log messages.
This is where syslog-ng can come handy: creating a dedicated log management layer, where syslog-ng collects all of the log messages centrally, does initial basic log analysis, and feeds all the different log analysis software with relevant log messages. This can save you time and resources in multiple ways:
-
You only have to learn one tool instead of many.
-
Only a single tool to push through security and operations teams.
-
There are less computing resources on clients.
-
Logs travel only once over the network.
-
Long term archival in a single location with syslog-ng instead of using multiple log analysis software.
-
Filtering on the syslog-ng side can save significantly on the hardware costs of the log analysis software, and also on licensing in case of a commercial solution.
The syslog-ng application can collect both system and application logs, and can be installed both as a client and a server. Thus, you have a single application to install for log management everywhere on your network. It can reliably collect and transport huge amounts of log messages, parse (“look into”) your log messages, enrich them with geographical location and other extra data, making filters and thus, log routing, much more accurate.
Logging as a Service (LaaS)
A couple years ago, Loggly was the pioneer of logging as a service (LaaS). Today, there are many other LaaS providers (Papertrail, Logentries, Sumo Logic, and so on) and syslog-ng works perfectly with all of them.
Structured fields and name-value pairs in logs are increasingly important, as they are easier to search, and it is easier to create meaningful reports from them. The more recent IETF RFC 5424 syslog standard supports structured data, but it is still not in widespread use.
People started to use JSON embedded into legacy (RFC 3164) syslog messages. The syslog-ng application can send JSON-formatted messages – for example, you can convert the following messages into structured JSON messages:
-
RFC5424-formatted log messages.
-
Windows EventLog messages received from the syslog-ng Agent for Windows application.
-
Name-value pairs extracted from a log message with PatternDB or the CSV parser.
Loggly and other services can receive JSON-formatted messages, and make them conveniently available from the web interface.
A number of LaaS providers are already supported by syslog-ng out of the box. If your service of choice is not yet directly supported, the following blog can help you create a new LaaS destination: https://www.syslog-ng.com/community/b/blog/posts/how-to-use-syslog-ng-with-laas-and-why
Some non-syslog-ng-based solutions
Before focusing on the solutions with syslog-ng at their heart, I would like to say a few words about the others, some which were included in the previous edition of the blog.
LogAnalyzer from the makers of Rsyslog was a simple, easy to use PHP application a few years ago. While it has developed quite a lot, recently I could not get it to work with syslog-ng. Some of the popular monitoring software have syslog support to some extent, for example, Nagios, Cacti and several others. I have tested some of these, I have even sent patches and bug reports to enhance their syslog-ng support, but syslog is clearly not their focus, just one of the possible inputs.
The ELK stack (Elasticsearch + Logstash + Kibana) and Graylog2 have become popular recently, but they have their own log collectors instead of syslog-ng, and syslog is just one of many log sources. Syslog support is quite limited both in performance and protocol support. They recommend using file readers for collecting syslog messages, but that increases complexity, as it is an additional software on top of syslog(-ng), and filtering still needs to be done on the syslog side. Note that syslog-ng can send logs to Elasticsearch natively, which can greatly simplify your logging architecture.
Collecting and displaying metrics data
You can collect metrics data using syslog-ng. Examples include netdata or collectd. You can send the collected data to Graphite or Elasticsearch. Graphite has its own web interface, while you can use Kibana to query and visualize data collected to Elasticsearch.
Another option is to use Grafana. Originally, it was developed as an alternative web interface to the Graphite databases, but now it can also visualize data from many more data sources, including Elasticsearch. It can combine multiple data sources to a single dashboard and provides fine-grained access control.
Loki by Grafana is one of the latest applications that lets you aggregate and query log messages, and of course, to visualize logs using Grafana. It does not index the contents of log messages, only the labels associated with logs. This way, processing and storing log messages requires less resources, making Loki more cost-effective. Promtail, the log collector component of Loki, can collect log messages using the new, RFC 5424 syslog protocol. Learn here how syslog-ng can send its log messages to Loki.
Splunk
One of the most popular web-based interfaces for log messages is Splunk. A returning question is whether to use syslog-ng or Splunk. Well, the issue is a bit of apples vs. oranges: they do not replace, but rather complement each other. As I already mentioned in the introduction, syslog-ng is good at reliably collecting and processing huge amounts of data. Splunk, on the other hand, is good at analyzing log messages for various purposes. Learn more about how you can integrate syslog-ng with Splunk from our white paper!
Syslog-ng based solutions
Here I show a number of syslog-ng based solutions. While every software described below is originally based on syslog-ng Open Source Edition (except for One Identity’s own syslog-ng Store Box (SSB)), there are already some large-scale deployments available also with syslog-ng Premium Edition as their syslog server.
-
The syslog-ng application and SSB focus on generic log management tasks and compliance.
-
LogZilla focuses on logs from Cisco devices.
-
Security Onion focuses on network and host security.
-
Recent syslog-ng releases are also able to store log messages directly into Elasticsearch, a distributed, scalable database system popular in DevOps environments, which enables the use of Kibana for analyzing log messages.
Benefits of using syslog-ng PE with these solutions include the logstore, a tamper-proof log storage (even if it means that your logs are stored twice), Windows support, and enterprise grade support.
LogZilla
LogZilla is the commercial reincarnation of one of the oldest syslog-ng web GUIs: PHP-Syslog-NG. It provides the familiar user interface of its predecessor, but also includes many new features. The user interface supports Cisco Mnemonics, extended graphing capabilities, and e-mail alerts. Behind the scenes, LDAP integration, message de-duplication, and indexing for quick searching were added for large datasets.
Over the past years, it received many small improvements. It became faster, and role-based access control was added, as well as the live tailing of log messages. Of course, all these new features come with a price; the free edition, which I have often recommended for small sites with Cisco logs is completely gone now.
A few years ago, a complete rewrite became available with many performance improvements under the hood and a new dashboard on the surface. Development never stopped, and now LogZilla can parse and enrich log messages, and can also automatically respond to events.
Therefore, it is an ideal solution for a network operations center (NOC) full of Cisco devices.
Web site: http://logzilla.net/
Security Onion
One of the most interesting projects utilizing syslog-ng is Security Onion, a free and open source Linux distribution for threat hunting, enterprise security monitoring, and log management. It is utilizing syslog-ng for log collection and log transfer, and uses the Elastic stack to store and search log messages. Even if you do not use its advanced security features, you can still use it for centralized log collection and as a nice web interface for your logs. But it is also worth getting acquainted with its security monitoring features, as it can provide you some useful insights about your network. Best of all, Security Onion is completely free and open source, with commercial support available for it.
You can learn more about it at https://www.syslog-ng.com/community/b/blog/posts/syslog-ng-and-security-onion
Elastisearch and Kibana
Elasticsearch is gaining momentum as the ultimate destination for log messages. There are two major reasons for this:
-
You can store arbitrary name-value pairs coming from structured logging or message parsing.
-
You can use Kibana as a search and visualization interface.
The syslog-ng application can send logs directly into Elasticsearch. We call this an ESK stack (Elasticsearch + syslog-ng + Kibana).
Learn how you can simplify your logging to Elasticsearch by using syslog-ng: https://www.syslog-ng.com/community/b/blog/posts/logging-to-elasticsearch-made-simple-with-syslog-ng
syslog-ng Store Box (SSB)
SSB is a log management appliance built on syslog-ng Premium Edition. SSB adds a powerful indexing engine, authentication and access control, customized reporting capabilities, and an easy-to-use web-based user interface.
Recent versions introduced AWS and Azure cloud support and horizontal scalability using remote logspaces. The new content-based alerting can send an e-mail alert whenever a match between the contents of a log message and a search expression is found.
SSB is really fast when it comes to indexing and searching log data. To put this scalability in context, the largest SSB appliance stores up to 10 terabytes of uncompressed, raw logs. With SSB’s current indexing performance of 100,000 events per second, that equates to approximately 8.6 billion logs per day or 1.7 terabytes of log data per day (calculating with an average event size of 200 bytes). Using compression, a single, large SSB appliance could store approximately one month of log data for an enterprise generating 1.7 terabytes of event data a day. This compares favorably to other solutions that require several nodes for collecting this amount of messages, and even more additional nodes for storing them. While storing logs to the cloud is getting popular, on-premise log storage is still a lot cheaper for a large amount of logs.
The GUI makes searching logs, configuring and managing the SSB easy. The search interface allows you to use wildcards and Boolean operators to perform complex searches, and drill down on the results. You can gain a quick overview and pinpoint problems fast by generating ad-hoc charts from the distribution of the log messages.
Configuring the SSB is done through the user interface. Most of the flexible filtering, classification and routing features in the syslog-ng Open Source and Premium Editions can be configured with the UI. Access and authentication policies can be set to integrate with Microsoft Active Directory, LDAP and RADIUS servers. The web interface is accessible through a network interface dedicated to the management traffic. This management interface is also used for backups, sending alerts, and other administrative traffic.
SSB is a ready-to-use appliance, which means that no software installation is necessary. It is easily scalable, because SSB is available both as a virtual machine and as a physical appliance, ranging from entry-level servers to multiple-unit behemoths. For mission critical applications, you can use SSB in High Availability mode. Enterprise-level support for SSB and syslog-ng PE is also available.
■ Read more about One Identity’s syslog-ng and SSB products here.
Digest of YaST Development Sprint 113
Time flies and it has been already two weeks since our previous development report. On these special days, we keep being the YaST + Cockpit Team and we have news on both fronts. So let’s do a quick recap.
Cockpit Modules
Our Cockpit module to manage wicked keeps improving.
Apart from several small enhancements, the module has now better error reporting and correctly
manages those asynchronous operations that wicked takes some time to perform. In addition, we have
improved the integration with a default Cockpit installation, ensuring the new module replaces the
default network one (which relies on Network Manager) if both are installed. In the following days
we will release RPM packages and a separate blog post to definitely present Cockpit Wicked to the
world.
On the other hand, we also have news about our Cockpit module to manage transactional updates. We are creating some early functional prototypes of the user interface to be used as a base for future development and discussions. You can check the details and several screenshots at the following pull requests: request#3, request#5.
Btrfs Subvolumes in the Partitioner
Regarding YaST and as already mentioned in our previous blog post, we are working to ensure Btrfs subvolumes get the attention they deserve in the user interface of the YaST Partitioner, becoming first class citizens (like partitions or LVM logical volumes) instead of an obscure feature hidden in the screen for editing a file system.
As part of that effort, we improved the existing mechanism to suggest a given list of subvolumes, based on the selected product and system role. See more details and screenshots at the corresponding pull request.
We also added some support for Btrfs quotas, a mechanism that can be used to improve space
accounting and to ensure a given subvolume (eg. /var or /tmp) does not grow too much and ends
up filling up all the space in the root file system. This pull
request explains the new feature with several
screenshots, including the new quite informative help texts.
All the mentioned changes related to subvolumes management will be submitted to openSUSE Tumbleweed in the following days.
More YaST enhancements
Talking about the YaST Partitioner, you may know that we recently added a menu bar to its interface. During this sprint we improved the YaST UI toolkit to ensure the keyboard shortcuts for such menu bar stay as stable as possible. Check the details at this pull request.
We have also been working in making the installer more flexible by adding support to define, per product and per system role, whether YaST should propose to configure the system for hibernation. In the case of SUSE Linux Enterprise, we have adapted the control file to propose hibernation in the SLED case, but not for other members of the SLE family.
See you soon
Of course, we have done much more during the latest two weeks. But we assume you don’t want to read about small changes and boring bug-fixes… and we are looking forward to jump into the next sprint. So let’s go back to work and see you in two weeks!


Gnome Asia summit 2020
 24-26 November 2020 @ https://events.gnome.org/event/24
24-26 November 2020 @ https://events.gnome.org/event/24
I think it maybe too late to help out telling anyone about this event since registeration already closed but look like the registeration still open. Anyway, let see the schedule:
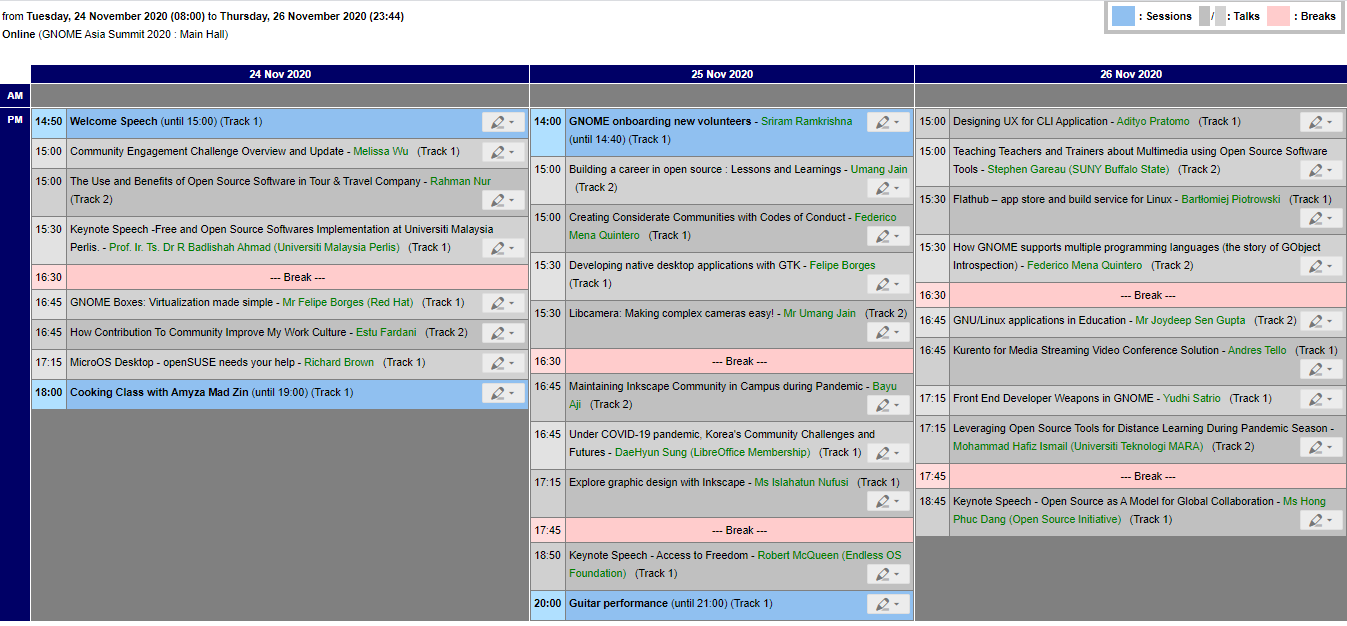{kind=link}

Some of the segment that offer good topic and caught my eyes :
- The Use and Benefits of Open Source Software in Tour & Travel Company - Rahman Nur
- Building a career in open source : Lessons and Learnings - Umang Jain
- Under COVID-19 pandemic, Korea’s Community Challenges and Futures - DaeHyun Sung
- Leveraging Open Source Tools for Distance Learning During Pandemic Season - Mohammad Hafiz Ismail
Gnome Asia summit 2020 will start by tomorrow today and conference will be online. This event was sponsor by Gitlab and openSUSE.

MicroOS & Kubic: New Lighter Minimum Hardware Requirements
You Spoke, We Heard
openSUSE MicroOS has been getting a significant amount of great attention lately.
We’d like to thank everyone who has reviewed and commented on what we are doing lately. One bit of clear feedback we received loud and clear was that the Minimum Hardware requirement of 20 GB disk space was surprisingly large for an Operating System calling itself MicroOS. We agree! And so we’ve reviewed and retuned that requirement.
New Minimum Storage Requirements
The New Minimum Supported Storage Requirements for MicroOS are
-
5 GBfor the read-only/ (root)partition, with 20GB as the recommended maximum size. -
5 GBfor the read-write/varpartition, with 40GB as the recommended size, or however large you require for your workloads.
Please Note, a standard installation of the minimal MicroOS system role currently uses no more than
-
450 MBwith bare metal hardware support. -
285 MBwithout bare metal hardware support.
Therefore these new lighter requirements still ensure that your MicroOS installations have plenty of room for many automated snapshots from transactional-updates. These changes will not compromise the promise that MicroOS can be updated and rolled back atomically without worry.
MicroOS Desktop Differences
The MicroOS Desktop, which is currently in Alpha and being actively developed, has a subtly different minimum requirement, as a result of its different use case.
-
5 GBfor the read-only/ (root)partition, with at least 40GB recommended, or however large you require for your desktop. -
/varand/homeare provided as read-writenoCoWsub-volumes as part of the/ (root)partition for the storage of containers, flatpaks and user-data.
Available Now
These changes have all been submitted to openSUSE:Factory, tested in openQA, and will soon be released as part of Snapshot version 20201121. They will soon be available for both MicroOS and Kubic across all ISO, Cloud, and VM Images.
Thanks and have a lot of fun!
The MicroOS & Kubic Team