
 Member
Member Futureboy
FutureboyMy Platform for the 2020 openSUSE Board Election

openSUSE Leap offers Predictability
Users of the community enterprise distributions can be confident in the direction of openSUSE Leap for those who might be hunting for a stable Linux distribution that offers predictability and longevity.
Minor releases like openSUSE Leap 15.2 sometimes get compared to a major release. The minor releases are essentially updates that people can choose rather than have forced updates.
Major versions of Leap receive long periods of maintenance and security updates; the release cycle has additional overlap that is greater than that of alternatives. Major releases are coming roughly every three to four years and minor releases come usually once a year, which leads to a life cycle of about 18 months of maintenance and security updates per minor release. Many of the package’s versions are the same as in previous minor releases.
Leap aligns with SUSE Linux Enterprise and its Service Packs (SP), which keeps the system updated, stable and patched. openSUSE and SUSE have been collaborating to bring openSUSE Leap 15.3 and SUSE Linux Enterprise 15 SP3 even closer together to make them fully compatible.
Users who are willing to switch to Leap are likely to find great benefits in choosing an openSUSE distributions and support ecosystem the project provides.
openSUSE Leap not only offers the sources, but Leap 15.3 will also offer the binaries and tools like the Open Build Service to rebuild the distribution. However, no rebuilding efforts are needed to benefit from the enterprise-grade code base. OBS also offers other capabilities like easy to add container builds and openSUSE’s Devel Project allows for the latest software on a stable platform that is much more refined without impacting the underlying enterprise code base. Testing of migrations are also made with the project’s openQA test suite automatically for older releases.
openSUSE Leap has continually moved closer together with SUSE Linux Enterprise, but the openSUSE Project is independently driven by its community and the path for Leap is foreseeable. openSUSE has a thriving global community with multiple distributions, so users pondering a switch from another distribution can consider openSUSE Leap and it’s community a safe haven for their future.
Board Elections - Meet the Candidates
As the openSUSE Board election is drawing closer, with the ballots opening on December 15 already, we want to invite the openSUSE community to a “meet-and-greet” and QA live session with the candidates.
In the past weeks there have been passionate discussions on the election and candidates, and we felt we had to answer the community’s interest with a proper setting.
In this video call the candidates will introduces themselves, present their openSUSE board election platforms and answer questions. While this might sound a bit formal we really want to keep it very informal and relaxed for everyone. The goal is to give the community a better picture of the candidates so they can decide whom to vote for.
Time and date
Saturday, 2020-12-19 at 13:00 UTC
We tried to accommodate as many time zones as possible. We chose Saturday to give people a chance to take part who are working during the weekdays. Please find your local time accordingly here
Location
We will gather at this Jitsi room: https://meet.opensuse.org/meet-the-candidates-2020
The session will be recorded for anyone not being able to take part. Furthermore we’re trying to make a live stream on Youtube possible as well to cover regions not that well connected to meet-o-o. Please keep that in mind so if you don’t want to be recorded it’s better to leave your webcam turned off.
Moderation
Adrien Glauser and Vinzenz Vietzke will be moderating the whole event together to make sure no questions get lost unanswered.
Collecting Questions
As mentioned there will be lots of time for questions and discussions. We will try to monitor the chat for questions as they pop up. But if you already have questions to one or more candidates in mind please email them in advance: vinzv@opensuse.org That makes planning much easier for us.
If there a general questions on the event feel free to get in touch. We’re looking forward to a productive and healthy session!

openSUSE Tumbleweed – Review of the week 2020/50
Dear Tumbleweed users and hackers,
The weekly review for 2020/50 is a bit late, but technically, it is still week 50, so ‘just in time’. Since my last review, Tumbleweed has managed to publish 5 snapshots (1203, 1205, 1207, 1209 and 1211). The fact that they are 2-day intervals is pure co-incidence and by no means planned. 1204 simply never was published, as 1205 reached QA before all reviews could be completed and the snapshot was discarded. 1206 was not produced, as I skipped the check-ins last Sunday. 1208 was again a ‘too fast build compared to test time; and 1210 was discarded due to packaging / build issues around the kubernetes 1.20 updates.
Anyway, the five snapshots that were published accumulated these changes:
- KDE Plasma 5.20.4
- gdb 10.1: now with debuginfod support
- Pulseaudio 14.0
- Mozilla Thunderbird 78.5.1
- Linux kernel 5.9.12
- SQLite 3.34.0
- Mesa 20.2.4
- NetworkManager 1.28.0
- QEmu 5.2.0
- Wine 6.0 rc1
- Kubernetes 1.20
The staging projects are currently filled with these updates/changes:
- KDE Applications 20.12 (currently RC being tested)
- icu 68.1: breaks a couple of builds (Staging:I)
- brp-check-suse: a bug fix in how it detected dangling symlinks (it detected them, but did not fail as it was supposed to)
- permissions package: prepares for easier listing, while supporting a full /usr merge
- RPM 4.16: still a few packages build failures (Mozilla *, openblas)
- Ruby 3.0: mainly YaST not ready for that switch. We are likely to stay on 2.7 as ‘default ruby’ version, but add rubygem packages for Ruby 3.0 by end of the year
- First experiments with rpmlint 2.0 started in Staging:M
- openssl 3.0: currently alpha 9 in Staging:O

Kubic with Kubernetes 1.20.0 released
Announcement
The Kubic Project is proud to announce that Snapshot 20201211 has been released containing Kubernetes 1.20.0.
Release Notes are avaialble HERE.
Upgrade Steps
All newly deployed Kubic clusters will automatically be Kubernetes 1.20.0 from this point.
For existing clusters, please follow our new documentation our wiki HERE
Thanks and have a lot of fun!
The Kubic Team
Tumbleweed Gets PulseAudio 14, Updates for Plasma, Firewalld
Four openSUSE Tumbleweed snapshots updated hundreds of packages in the rolling release this week.
There were two major versions to arrive this week and one of them, pulseaudio, has an important message for GNOME who plan on using the new major version.
An update of Mesa 20.2.4 and firewalld 0.9.1 arrived in the latest snapshot - 20201209. While no new features were added in Mesa 20.2.4, there was a rendering bugfix for Blender viewport with AMD NAVI 5700 XT GPUs. Firewalld 0.9.1 removed a patch and added a workaround for the Docker bridge. ModemManager 1.14.8 made minor improvements and fixed a daemon crash when a device is being removed during the initialization sequence. NetworkManager 1.28.0 unified some behavior affecting IPv4 and IPv6 connections with the boot configuration generator. A couple new features were added for the DNS server package bind 9.16.8 and a feature change affecting the EDNS buffer size has been changed from 4096 to 1232 bytes; the change log states that measurements were done by multiple parties and that the change should not cause any operational problems as most of the Internet “core” is able to cope with IP message sizes between 1400-1500 bytes. More color printer support was added in the hplip 3.20.9 update. Other packages to update in the snapshot were vim 8.2.2105, mutt 2.0.3, poppler and sudo 1.9.4, which allows the parser to detect when an upper-case reserved word is used when declaring an alias.
The 20201207 snapshot updated three packages. GNU Compiler Collection 10 received a minor update to enable fortran for offload compilers. The 6.2.1 version of gmp fixed a longtime AArch64 bug and gstreamer-devtools 1.18.1 fixed a memory leak and made various stability and reliability improvements.
Text editor nano updated to version 5.4 in Tumbleweed’s 20201205 snapshot. The changes made in nano varied from the cursor skipping over “combined zero-width characters” to “backspacing” to delete just one zero-width character at a time. KDE Plasma 5.20.4 fixed the dragging panel to resize for the top and right panels in the plasma-desktop package and the breeze package made a color scheme change notification. The plasma-workspace package had some fixes including a build fix with the newer Qt. ImageMagick 7.0.10.45 corrected the rotation parameter for an SVG transformation. Mozilla Thunderbird 78.5.1 took care of a stack overflow Common Vulnerabilities and Exposures that was caused by incorrect parsing of the SMTP server response codes. Apparmor 3.0.1 provided its first minor update, which added support for capability checkpoint_restore for the 5.9 and later Linux Kernels. The caching DNS resolver unbound 1.13.0 made a fixed that added unencrypted DNS over HTTPS support. There were incremental improvements in the update of libvirt 6.10.0 and some new Application Programming Interface implementations were added. Version 5.9.12 of the Linux Kernel had some s390 fixes and added bindings for Raspberry Pi firmware based PWM bus. Other packages to update in the snapshot were fwupd 1.5.2, yast2-storage-ng 4.3.27 and sqlite3 3.34.0, which enhanced the recursive common table expressions to support two or more recursive terms as is done by an SQL Server.
The 20201203 snapshot began the week and started to update the Plasma 5.20.4 packages, which were completed in the follow on 20201205 snapshot; the discover package in this snapshot fixed the sidebar size and height as well as fixed the incorrect usage of units on ApplicationDelegate. GNOME Web package epiphany 3.38.2 fixed a crash when a safe browsing database is corrupted. The browser also reduced the size of the storage access API permission request. A new major version of the GNU Project debugger, gdb 10.1, arrived in this snapshot; the package was filled with patches and added new commands like set exec-file-mismatch and tui new-layout. Another major version to arrive in this snapshot was pulseaudio 14. One highlight pointed out in the new major version is the build with --enable-stream-restore-clear-old-devices, which is considered a bit of a destructive option; it will clear the old PA routing once when upgraded prior to 14.0, but it’s required for GNOME; this should be a one-off action that won’t bother too much, but users are encouraged to read the release notes.

Building a openSUSE MicroOS RPi Network Monitor
openSUSE MicroOS is one of openSUSE’s most exciting projects, and for me has replaced openSUSE Leap as my go-to server operating system of choice. I currently have 3 MicroOS installations, all running as podman with openSUSE containers. The machines are as follows:
- A nice fanless Zotac x86-64 NUC running at home as my Nextcloud and ssh-based backup server/NAS
- A VM on Hetzner Cloud running this blog, my saltstack master and a few other public facing services. (Kudos to Hetzner for adding the openSUSE MicroOS ISO to the list of Cloud ISOs so I could do a custom installation)
- A VM on Linode for running a US-based proxy for some of my friends who otherwise might have too-high latency accessing services on the Hetzner host. (Kudos to Linode for consistantly supporting openSUSE Leap releases on the day of release and providing ways of doing custom installs of any OS)
And so, with all these MicroOS boxes in my life, as reliable as they may be, I wanted to have a simple way of keeping an eye on whether or not the machines are up or not, possibly evolving to more interesting checks in the future. I wanted this to be able to monitor my machines even when my main laptop at home is off, and I wanted to not have to worry about updating the monitoring system at all. So an idea formed, why not use MicroOS to monitor MicroOS?
Hardware Used
I cobbled this little project together out of random bits of hardware I had lying around, namely:
- Raspberry Pi 3B+ with the official RPi case
- Joy IT 3.2” TFT display with 3 GPIO buttons
- 32GB micro SDCard
- 8GB random old USB stick
Software Used
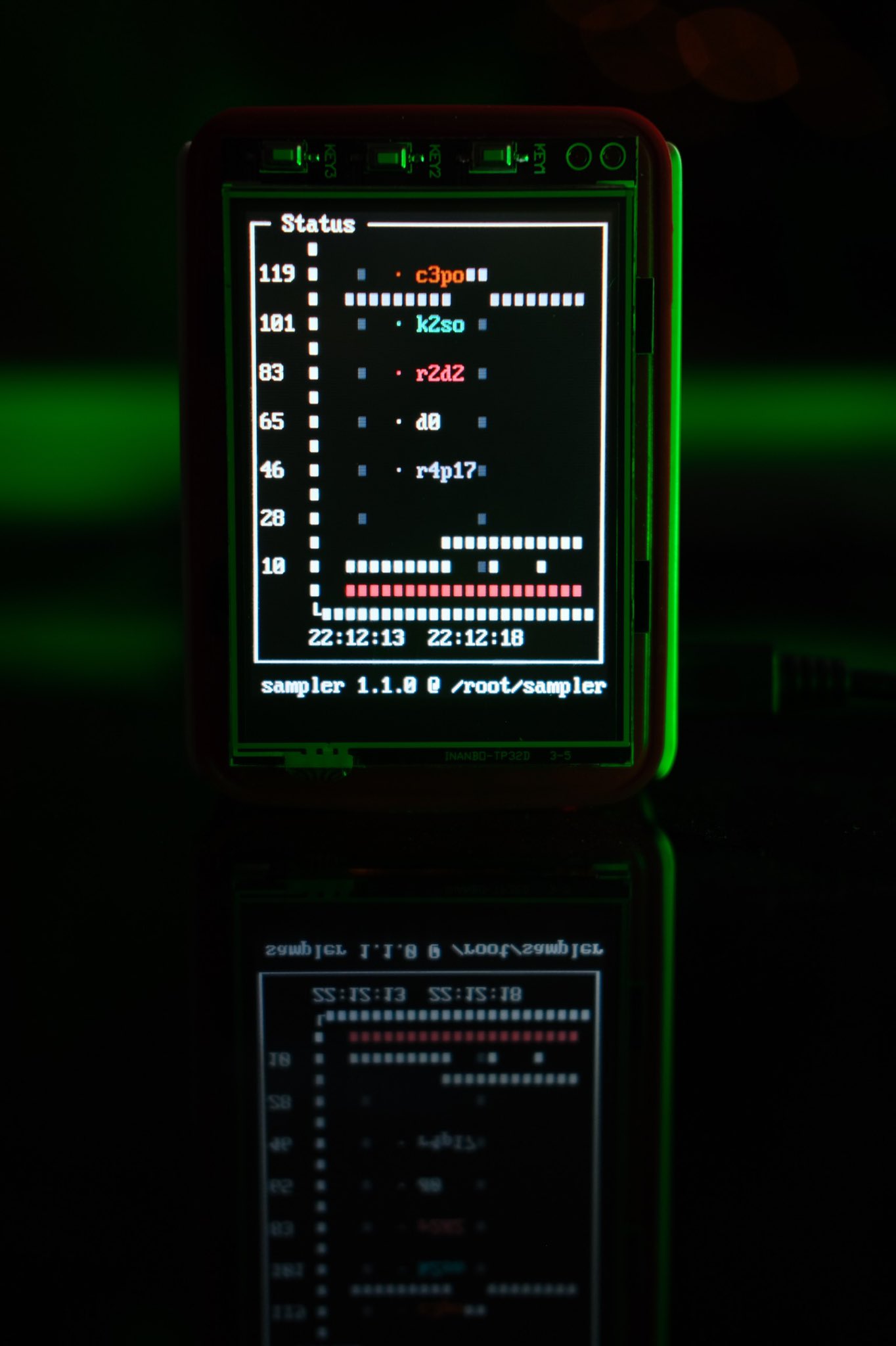
I found a very nice command-line visualisation tool called sampler that perfectly fit my needs for this project. It’s nice and small, lets you draw graphs based on numbers it gets from whatever shell commands you run at whatever frequency you tell it to poll. It can also produce alerts if the results do not match expected values. So given the basic monitoring I want is basically just a ping and be alerted if they stopped responding, sampler is absolutely perfect. I packaged it for openSUSE as part of this project so it’s now available for regular Tumbleweed as well as MicroOS.
Installing MicroOS on the SDCard
First I needed to download the latest official openSUSE MicroOS aarch64 image for Rasbperry Pi from the official download page. For this project we’re using a plain old MicroOS image without any pre-installed services, not the Container Host images which come with podman.
wget https://download.opensuse.org/ports/aarch64/tumbleweed/appliances/openSUSE-MicroOS.aarch64-RaspberryPi.raw.xz
Putting in the SDCard into the reader, I simultaniously extracted the image and wrote it direct to the image with the following command. (Substitue sdX with the correct name for your SDCard device)
xzcat openSUSE-MicroOS.aarch64-RaspberryPi.raw.xz | dd bs=4M of=/dev/sdX iflag=fullblock oflag=direct status=progress; sync
And that’s it, the SDCard is ready to go…or is it?
But Wait!
By default, MicroOS images have no root password, no user accounts, and no services installed. I needed to have some way to setup the Pi when it first boots from the SDCard. MicroOS has two tools available for such first boot configuration:
- Ignition, originally from CoreOS which has a lovely structured JSON config but a limited scope of what it can setup.
- Combustion, written specifically for MicroOS and capable of doing anything you can write in a shell script.
As I already had a feeling I’d need to do some quirky things, especially to get the TFT display running, I opted to use combustion. I could have used ignition for the easy stuff and left combustion in combination for the trickier parts but it seemed silly to me to have to learn how to write a new JSON config file when I could just as easily write everything in a shell script.
Preparing a combustion USB stick
On first boot combustion looks for a device with a volume named combustion containing a directory called combustion and a script called script so that’s precisely what I did to my USB stick
mkfs.ext4 /dev/sdY
e2label /dev/sdY combustion
mount /dev/sdY /mnt
mkdir -p /mnt/combustion/
touch /mnt/combustion/script
After a few trial runs and a bit of hacking around the final script now looks like this:
#!/bin/bash
# combustion: network
## Copy config and device tree overlays for Pi TFT & GPIO buttons to /boot/efi
cp extraconfig.txt /boot/efi/
cp joy-IT-Display-Driver-32b-overlay.dtbo /boot/efi/overlays/
cp tft_keys.dtbo /boot/efi/overlays/
## Change boot params so framebuffer console goes to TFT display
sed -i "/^GRUB_CMDLINE_LINUX_DEFAULT=/ s/\"$/ fbcon=map:10\"/" /etc/default/grub
grub2-mkconfig -o /boot/grub2/grub.cfg
## Mount /var and /home so user can be created smoothly
mount /var
mount /home
## Make user
useradd -m ilmehtar
## Add user to sudoers
echo "ilmehtar ALL=(ALL) NOPASSWD: ALL" > /etc/sudoers.d/ilmehtar
## Create ssh folder and populate authorized_keys for remote sshd
mkdir -pm700 /home/ilmehtar/.ssh
chown ilmehtar:users -R /home/ilmehtar/.ssh
cat authorized_keys > /home/ilmehtar/.ssh/authorized_keys
## Setup vconsole so framebuffer console has right font/keyboard layout (Optional)
cp vconsole.conf /etc/vconsole.conf
## Setup Wifi
cp wpa_supplicant.conf /etc/wpa_supplicant/wpa_supplicant.conf
systemctl enable wpa_supplicant@wlan0.service
cp /etc/sysconfig/network/ifcfg-eth0 /etc/sysconfig/network/ifcfg-wlan0
## Disable IPv6 (Optional)
cp 90-disableipv6.conf /etc/sysctl.d/
## Install sampler
zypper --non-interactive install sampler
cp sampler.yaml /home/ilmehtar/sampler.yaml
## Make user login by default
mkdir -p /etc/systemd/system/getty@tty1.service.d
cp autologin.conf /etc/systemd/system/getty@tty1.service.d
## Make sampler run by default
echo "[ \$TERM = 'linux' ] && sleep 30 && sampler -c ~/sampler.yaml" >> /home/ilmehtar/.bashrc
## Reboot after setup
cp firstbootreboot.service /etc/systemd/system/
systemctl enable firstbootreboot.service
## Clear up mounts
umount /var
umount /home
The script references a number of additional files, all of which are placed alongside script in the combustion directory on the USB stick:
File Listing of the combustion directory
90-disableipv6.conf
authorized_keys
autologin.conf
extraconfig.txt
firstbootreboot.service
joy-IT-Display-Driver-32b-overlay.dtbo
sampler.yaml
script
tft_keys.dtbo
tft_keys.dts
vconsole.conf
wpa_supplicant.conf
Joy-IT-Display-Driver-32b-overlay.dtbo is a Device Tree overlay provided by the manufactorer of the TFT hat. tft_keys.dtbo is my own Device Tree overlay compiled from tft_keys.dts. All the other files are text files used to configure various aspects of the system to my liking and are documented at the bottom of this post for anyone wanting to use this idea as a basis for their own projects.
First Boot
And with all that prep work done, the first boot is now surprisingly easy. I inserted the SDCard, added the USB stick and connected the Pi to ethernet (The wifi won’t work until it’s configured by combustion). Powering on the Pi the whole device can be left alone for a few minutes. It boots itself, does all of the configuration, and the end result is a nice working desktop network monitor:

The GPIO switches on the top even work as the P and ESC keys for sampler, allowing me to pause the polling or dismiss any alerts. A little bit of hardware hacking (read: hot glue and acryrlic) finished of the project with a little stand so the whole thing sits on my desk at an angle easy for me to read.
The system doesn’t have any passwords, so can’t be logged in remotely with the exception of ssh using the non-root user using my existing public key. Simple and secure enough.
All this might seem like a little overkill, I realise it probably is, but one great benefit of having everything in this one combustion script is now I know I can wipe that SDCard or use a new Pi and get it back up and running to exactly how I like it directly from the first boot, without any manual intervention at all. Which I guess means I could reuse this Pi for other projects..anyone got any ideas?
Thanks and Have a Lot of Fun
Additional Config Files Used (For Reference)
90-disableipv6.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
autologin.conf
[Service]
ExecStart=
ExecStart=-/sbin/agetty -a ilmehtar %I $TERM
extraconfig.txt
dtoverlay=joy-IT-Display-Driver-32b-overlay:rotate=0,swapxy=1
dtoverlay=tft_keys
gpio=18,23,24=pu
dtparam=audio=on
max_usb_current=1
hdmi_force_hotplug=1
config_hdmi_boost=7
hdmi_drive=1
hdmi_ignore_edid=0xa5000080
firstbootreboot.service
[Unit]
Description=First Boot Reboot
[Service]
Type=oneshot
ExecStart=rm /etc/systemd/system/firstbootreboot.service
ExecStart=rm /etc/systemd/system/default.target.wants/firstbootreboot.service
ExecStart=systemctl reboot
[Install]
WantedBy=default.target
sampler.yaml
runcharts:
- title: Status
position: [[0, 2], [80, 40]]
rate-ms: 1000
triggers:
- title: Node Down
condition: '[ $cur = "DOWN" ] && echo 1 || echo 0'
actions:
visual: true
legend:
enabled: true
details: false
scale: 0
items:
- label: node1
sample: ping -qc5 192.168.1.1 2>&1 | awk -F'/' 'END{ print (/^rtt/? $5:"DOWN")
}'
- label: node2
sample: ping -qc5 192.168.1.2 2>&1 | awk -F'/' 'END{ print (/^rtt/? $5:"DOWN")
}'
- label: node3
sample: ping -qc5 192.168.1.3 2>&1 | awk -F'/' 'END{ print (/^rtt/? $5:"DOWN")
}'
- label: node4
sample: ping -qc5 192.168.1.4 2>&1 | awk -F'/' 'END{ print (/^rtt/? $5:"DOWN")
}'
- label: node5
sample: ping -qc5 192.168.1.5 2>&1 | awk -F'/' 'END{ print (/^rtt/? $5:"DOWN")
}'
tft_keys.dts
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835";
fragment@0 {
target-path = "/soc";
__overlay__ {
tft_keys{
compatible = "gpio-keys";
autorepeat;
key1 {
label = "Key 1";
linux,code = <1>;
gpios = <&gpio 18 1>;
};
key2 {
label = "Key 2";
linux,code = <25>;
gpios = <&gpio 23 1>;
};
key3 {
label = "Key 3";
linux,code = <1>;
gpios = <&gpio 24 1>;
};
};
};
};
};
vconsole.conf (Because uk layout is best keyboard layout)
KEYMAP=uk
FONT=eurlatgr.psfu
FONT_MAP=
FONT_UNIMAP=
wpa_supplicant.conf
network={
ssid="My-SSID"
psk="MyPassword"
}


How to disable ICMP ping replies (linux)
Few weeks ago during server setup phase for one of my project, I notice there is no ICMP or ping replies from server and some port are not able to access.
I told the network engineer to check and seem they blocking the ports and disabling ICMP replies from their firewall configuration.
From that accident I do some google-fu if I can do same thing for personal computer / server. We can setting the kernel variable or use iptable to disable ICMP / ping replies if requested.
Temporarily disable ICMP / ping replies
$ su -
echo "1" > /proc/sys/net/ipv4/icmp_echo_ignore_all
# This instructs the kernel to simply ignore all ping requests
# 1 = ignore ping requests and 0 = allow ping request
or
$ iptables -A INPUT -p icmp -j DROP
Permanently disable ICMP / ping replies
To disable ping requests permanently, add this line into your /etc/sysctl.conf file:
net.ipv4.icmp_echo_ignore_all = 1
And reload sysctl’s policy by # sysctl -p.
Or save iptables rule by
# for distros with systemd
/usr/libexec/iptables.init save
# for all other distros
service iptables save
# univeral way: edit main config by yourself
vim /etc/sysconfig/iptables
Advancing openSUSE Images for The PinePhone
Awareness grew after a post in an online forum appeared in June about openSUSE images for the PinePhone, which is a smartphone developed by Pine64 that allows user to have full control over their device and run mainline Linux.
“I am working on porting openSUSE for PinePhone,” the post began. “I am working on some improvements porting all packages to openSUSE. I am working with Open Build Service, so soon we will have news about it.”
Replies to the post began to fill the page and word spread. At the moment the animation of the logo became visible on the PinePhone screen, pictures were taken, posted to social media and comments began to spread on Twitter.
“The most interesting thing about my work with the PinePhone was creating the Geeko logo boot animation,” said Adrian Campos Garrido, who took the hobby project to an official capacity.
Garrido, who is a Platform Architect, did this by bringing his passion and work to the devel project, submitted the packages he was using for the project to openSUSE Factory and began building the official images in OBS.
“I am very happy with all the migration to OBS since it allows me to do the work I did before but everything is much more efficient and more comfortable,” he said. “My interest in the PinePhone came from the first moment because it was a device with great possibilities of becoming the first device at a reasonable price that works practically the same as a computer; since it was presented as integrated into the mainline kernel of GNU/Linux.”
The first steps focused on how to create an operating system image, Garrido said, who is interested in everything related to technology and open source.
“For this I used a series of scripts and a Jenkins slave on my servers to create an image,” he said. “Then, I started to port all the packages to openSUSE; starting by learning how the Spec Files worked for building RPM packages.”
His journey of building the openSUSE images for the PinePhone wasn’t easy.
“The most difficult thing was to adapt the kernel with the package to make the calls and the audio work.”
There are still some known issues that need fixing like the Bluetooth, accelerometer and GPS. Garrido has been focused on keeping the releases as stable as possible and plans on progressing with a roadmap to allow him to have a clearer objective of where to continue.
“Any help is welcome from helping with the maintenance of the package to reporting bugs,” he said. “Reporting is very interesting and allows me to prioritize some tasks over others.”
People can contact Garrido on GitHub and find out how to help on the openSUSE images wiki page.
openSUSE Tumbleweed – Review of the week 2020/49
Dear Tumbleweed users and hackers,
Week 49 felt like a normal week, with no disasters happening, steady rolling distribution, openQA being on our side, blocking one snapshot that could have caused quite some pain to you, the users. So all in all, exactly what we want from a stable, rolling distribution. And this still resulted in 5 snapshots released during this week (1127, 1129, 1130, 1201, 1202).
The main changes in those five snapshots included:
- Mozilla Firefox 83.0
- Grep 3.6: the GREP_OPTIONS environment variable no longer affects grep’s behavior
- GNOME 3.38.2
- Linux kernel 5.9.11
In the staging projects, these changes are being tested and worked on:
- KDE Plasma 5.20.4
- KDE Applications 20.12 (currently RC being tested)
- icu 68.1: breaks a couple of builds (Staging:I)
- brp-check-suse: a bug fix in how it detected dangling symlinks (it detected them, but did not fail as it was supposed to)
- permissions package: prepares for easier listing, while supporting a full /usr merge
- RPM 4.16: still a few packages build failures (postgresql, Mozilla *, openblas)
- Ruby 3.0: mainly YaST not ready for that switch
- First experiments with rpmlint 2.0 started in Staging:M
- openssl 3.0: currently alpha 9 in Staging:O