Member
Member jimmac
jimmacWhat 3 Words?
I dig online maps like everyone else, but it is somewhat clumsy sharing a location. The W3W service addesses the issue by chunking up the whole world into 3x3m squares and assigning each a name (Supposedly around 57 trillion). Sometimes it’s a bit of a tongue twister, but most of the time it’s fun to say to meet at a “massive message chuckle” for some fpv flying. I’m really surprised this didn’t take off.
Cephalocon APAC ... is comming
 Two weeks till Cephalocon APAC 2018 in Beijing (22-23th March), the first Ceph-only conference. Finally! Two full days of talks and speaker from the world wide Ceph Community. The agenda is available since a few days now.
Two weeks till Cephalocon APAC 2018 in Beijing (22-23th March), the first Ceph-only conference. Finally! Two full days of talks and speaker from the world wide Ceph Community. The agenda is available since a few days now.
Helping Cairo
Cairo needs help. It is the main 2D rendering library we use in GNOME, and in particular, it's what librsvg uses to render all SVGs.
My immediate problem with Cairo is that it explodes when called with floating-point coordinates that fall outside the range that its internal fixed-point numbers can represent. There is no validation of incoming data, so the polygon intersector ends up with data that makes no sense, and it crashes.
I've been studying how Cairo converts from floating-point to its
fixed-point representation, and it's a nifty little algorithm. So I
thought, no problem, I'll add validation, see how to represent the
error state internally in Cairo, and see if clients are happy with
getting back a cairo_t in an error state.
Cairo has a very thorough test suite... that doesn't pass. It is documented to be very hard to pass fully for all rendering backends. This is understandable, as there may be bugs in X servers or OpenGL implementations and such. But for the basic, software-only, in-memory image backend, Cairo should 100% pass its test suite all the time. This is not the case right now; in my tree, for all the tests of the image backend I get
497 Passed, 54 Failed [0 crashed, 14 expected], 27 Skipped
I have been looking at test failures to see what needs fixing. Some reference images just need to be regenerated: there have been minor changes in font rendering that broke the reference tests. Some others have small differences in rendering gradients - not noticeable by eye, just by diff tools.
But some tests, I have no idea what changed that made them break.
Cairo's git repository is accessible through [cgit.freedesktop.org]. As far as I know there is no continuous integration infrastructure to ensure that tests keep passing.
Adding minimal continuous testing
I've set up a Cairo repository at gitlab.com. That branch
already has a fix for an uninitialized-memory bug which leads to an
invalid free(), and some regenerated test files.
The repository is configured to run a continuous integration pipeline on every commit. The test artifacts can then be downloaded when the test suite fails. Right now it is only testing the image backend, for in-memory software rendering.
Initial bugs
I've started reporting a few bugs against that repository for tests that fail. These should really be in Cairo's Bugzilla, but for now Gitlab makes it much easier to include test images directly in the bug descriptions, so that they are easier to browse. Read on.
Would you like to help?
A lot of projects use Cairo. We owe it to ourselves to have a library with a test suite that doesn't break. Getting to that point requires several things:
- Fixing current failures in the image backend.
- Setting up the CI infrastructure to be able to test other backends.
- Fixing failures in the other backends.
If you have experience with Cairo, please take a look at the bugs. You can see the CI configuration to see how to run the test suite in the same fashion on your machine.
I think we can make use of modern infrastructure like gitlab and continuous integration to improve Cairo quickly. Currently it suffers from lack of attention and hostile tools. Help us out if you can!
ECMAScript 2018: Asynchronous Iteration

It’s 2018 and it’s time for an update to the JavaScript standard. In January this year the TC39 committee released the latest changes to the ECMAScript standard, appropriately called ECMAScript 2018. One of the changes coming in this update is the introduction of Asynchronous Iteration and the for-await-of loop to iterate over asynchronous functions like generators and promises.
Synchronous Iteration
The form of iteration JS programmers are used to using is called Synchronous Iteration. It is used to iterate over things like an array or a function that has completes execution and returns a result.
It is possible for you to implement your own custom iterators for objects you create. The link above has an in depth explanation of how these iterators work and the different ways they can be used. I will summarize their usage like so:
- Synchronous iteration requires the target object to be iterable
- An object is iterable if it defines [Symbol.iterator]()
- [Symbol.iterator]() must return an iterator
- An iterator is an object that must at least define a function next()
- The function next() must return an object in the form {value: $value, done: false} when iterating over values
- The iterator is considered finished when the next() function returns {done: true}
Here is an example implementation of a custom iterable:
The problem with these synchronous iterators is that they can not be used to iterate over asynchronous operations, like calling a generator function (since generator functions call yield, they do not “finish” executing). To solve this problem the TC39 committee has added asynchronous iteration to the ECMAScript 2018 release.
Asynchronous Iteration
ES2018: asynchronous iteration
The new form of iteration, to use when iterating over asynchronous iterators is called asynchronous iteration. It is similar to its synchronous counterpart but instead of defining [Symbol.iterator]() the iterable must instead define [Symbol.asyncIterator](). The creation of asynchronous iterators is as follows:
- Asynchronous iteration requires the target object to be iterable
- An object is iterable if it defines [Symbol.asyncIterator]()
- [Symbol.asyncIterator]() must return an AsyncIterator
- An AsyncIterator is an object that must at least define a function next()
- The function next() must return a promise that resolves with an IteratorResult
- The IteratorResult is an object with a form {value: $value, done: false}
- When the iterator is finished it must return {done: true}
However unlike the synchronous iterators, the asynchronous iterators cannot be used in a standard for-of loop. Instead they must use the new for-await-of loop. I have created an implementation of the synchronous iterator example above using asynchronous iterators below. Notice how the next() function in the iterable return a Promise instead of an object like in the first example. Also worth noting is that we have to use an asynchronous function to await for the result of the asynchronous iteration before we can update the page.
While the example is clearly more involved than the first, hopefully you can see that the asynchronous iterators now give developers the power to iterate over Promises and generator functions.
ECMAScript 2018: Asynchronous Iteration was originally published in Information & Technology on Medium, where people are continuing the conversation by highlighting and responding to this story.
Representing the Impractical and Impossible with JDK 10 “var”
Having benefited from “var” for many years when writing c#, I’m delighted that Java is at last getting support for local variable type inference in JDK 10.
From JDK 10 instead of saying
ArrayList<String> foo = new ArrayList<String>();
we can say
var foo = new ArrayList<String>();
and the type of “foo” is inferred as ArrayList<String>
While this is nice in that it removes repetition and reduces boilerplate slightly, the real benefits come from the ability to have variables with types that are impractical or impossible to represent.
Impractical Types
When transforming data it’s easy to be left with intermediary representations of the data that have deeply nested generic types.
Let’s steal an example from a c# linq query, that groups a customer’s orders by year and then by month.
While Java doesn’t have LINQ, we can get fairly close thanks to lambdas.
from(customerList)
.select(c -> tuple(
c.companyName(),
from(c.orders())
.groupBy(o -> o.orderDate().year())
.select(into((year, orders) -> tuple(
year,
from(orders)
.groupBy(o -> o.orderDate().month())
)))
));
While not quite as clean as the c# version, it’s relatively similar. But what happens when we try to assign our customer order groupings to a local variable?
CollectionLinq<Tuple<String, CollectionLinq<Tuple<Integer, Group<Integer, Order>>>>> customerOrderGroups =
from(customerList)
.select(c -> tuple(
c.companyName(),
from(c.orders())
.groupBy(o -> o.orderDate().year())
.select(into((year, orders) -> tuple(
year,
from(orders)
.groupBy(o -> o.orderDate().month())
)))
));
Oh dear, that type description is rather awkward. The Java solutions to this have tended to be one of
- Define custom types for each intermediary stage—perhaps here we’d define a CustomerOrderGroup type.
- Chaining many operations together—adding more transformations onto the end of this chain
- Lose the type information
Now we don’t have to work around the problem, and can concisely represent our intermediary steps
var customerOrderGroups =
from(customerList)
.select(c -> tuple(
c.companyName(),
from(c.orders())
.groupBy(o -> o.orderDate().year())
.select(into((year, orders) -> tuple(
year,
from(orders)
.groupBy(o -> o.orderDate().month())
)))
));
Impossible Types
The above example was impractical to represent due to being excessively long and obscure. Some types are just not possible to represent without type inference as they are anonymous.
The simplest example is an anonymous inner class
var person = new Object() {
String name = "bob";
int age = 5;
};
System.out.println(person.name + " aged " + person.age);
There’s no type that you could replace “var” with in this example that would enable this code to continue working.
Combining with the previous linq-style query example, this gives us the ability to have named tuple types, with meaningful property names.
var lengthOfNames =
from(customerList)
.select(c -> new Object() {
String companyName = c.companyName();
int length = c.companyName().length();
});
lengthOfNames.forEach(
o -> System.out.println(o.companyName + " length " + o.length)
);
This also means it becomes more practical to create and use intersection types by mixing together interfaces and assigning to local variables
Here’s an example mixing together a Quacks and Waddles interface to create an anonymous Duck type.
public static void main(String... args) {
var duck = (Quacks & Waddles) Mixin::create;
duck.quack();
duck.waddle();
}
interface Quacks extends Mixin {
default void quack() {
System.out.println("Quack");
}
}
interface Waddles extends Mixin {
default void waddle() {
System.out.println("Waddle");
}
}
interface Mixin {
void __noop__();
static void create() {}
}
This has more practical applications, such as adding behaviours onto existing types, ala extension methods
Encouraging Intermediary Variables
It’s now possible to declare variables with types that were erstwhile impractical or impossible to represent.
I hope that this leads to clearer code as it’s practical to add variables that explain the intermediate steps of transformations, as well as enabling previously impractical techniques such as the above.
A Russian translation of this post has been provided at Softdroid
The post Representing the Impractical and Impossible with JDK 10 “var” appeared first on Benji's Blog.

Connecting new screens

The new behavior is to now pop up a selection on-screen display (OSD) on the primary screen or laptop panel allowing the user to pick the new configuration and thereby make it clear what’s happening. When the same display hardware is plugged in again at a later point, this configuration is remembered and applied again (no OSD is shown in that case).
Another change-set which we’re about to merge is to pop up the same selection dialog when the user presses the display button which can be found on many laptops. This has been nagging me for quite a while since the display button switched screen configuration but provided very little in the way of visual feedback to the user what’s happening, so it wasn’t very user-friendly. This new feature will be part of Plasma 5.13 to be released in June 2018.
OSC interactive review
Requests are one of the staples for collaboration in the OBS. You can review via the webui or with OSC.
WebUI
Lets take the request listing for openSUSE:Factory. Your normal workflow will probably end up as
- middle mouse click on the little magnifying glass icon on the right.
- review the request in a new tab
- close the new tab
- go back step 1
My issues with the WebUI
- no advancing to the next request in my current list.
- I have to manually unfold/fold many diff chunks for a proper review.
- In the latest version of the WebUI: “We truncated the diff of some files because they were too big. If you want to see the full diff for every file, click here.” But even then I have to unfold every change myself again.
OSC - The normal way
- one terminal:
osc rq list -t submit -s new openSUSE:Factory - 2nd terminal:
osc rq show -d ID- the ID is taken from the first listing. - 2nd or in worst case 3rd terminal:
osc rq youraction ID - go back to step 2
My issues
- all manually copy pasting of IDs
OSC interactive mode
My config:
Quick and dirty checklist to update syn 0.11.x to syn 0.12
Today I ported gnome-class from version 0.11 of the syn crate to
version 0.12. syn is a somewhat esoteric crate that you use to
parse Rust code... from a stream of tokens... from within the
implementation of a procedural macro. Gnome-class implements a
mini-language inside your own Rust code, and so it needs to parse
Rust!
The API of syn has changed a lot, which is kind of a pain in the
ass — but the new API seems on the road to stabilization, and is nicer
indeed.
Here is a quick list of things I had to change in gnome-class to
upgrade its version of syn.
There is no extern crate synom anymore. You can use syn::synom now.
extern crate synom; -> use syn::synom;
SynomBuffer is now TokenBuffer:
synom::SynomBuffer -> syn::buffer:TokenBuffer
PResult, the result of Synom::parse(), now has the tuple's
arguments reversed:
- pub type PResult<'a, O> = Result<(Cursor<'a>, O), ParseError>;
+ pub type PResult<'a, O> = Result<(O, Cursor<'a>), ParseError>;
// therefore:
impl Synom for MyThing { ... }
let x = MyThing::parse(...).unwrap().1; -> let x = MyThing::parse(...).unwrap().0;
The language tokens like synom::tokens::Amp, and keywords like
synom::tokens::Type, are easier to use now. There is a Token!
macro which you can use in type definitions, instead of having to
remember the particular name of each token type:
synom::tokens::Amp -> Token!(&)
synom::tokens::For -> Token!(for)
And for the corresponding values when matching:
syn!(tokens::Colon) -> punct!(:)
syn!(tokens::Type) -> keyword!(type)
And to instantiate them for quoting/spanning:
- tokens::Comma::default().to_tokens(tokens);
+ Token!(,)([Span::def_site()]).to_tokens(tokens);
(OK, that one wasn't nicer after all.)
To the get string for an Ident:
ident.sym.as_str() -> ident.as_ref()
There is no Delimited anymore; instead there is a Punctuated
struct. My diff has this:
- inputs: parens!(call!(Delimited::<MyThing, tokens::Comma>::parse_terminated)) >>
+ inputs: parens!(syn!(Punctuated<MyThing, Token!(,)>)) >>
There is no syn::Mutability anymore; now it's an Option<token>, so
basically
syn::Mutability -> Option<Token![mut]>
which I guess lets you refer to the span of the original mut token
if you need.
Some things changed names:
TypeTup { tys, .. } -> TypeTuple { elems, .. }
PatIdent { -> PatIdent {
mode: BindingMode(Mutability) by_ref: Option<Token!(ref)>,
mutability: Option<Token![mut]>,
ident: Ident, ident: Ident,
subpat: ..., subpat: Option<(Token![@], Box<Pat>)>,
at_token: ..., }
}
TypeParen.ty -> TypeParen.elem (and others like this, too)
(I don't know everything that changed names; gnome-class doesn't use all the syn types yet; these are just the ones I've run into.)
This new syn is much better at acknowledging the fine points of
macro hygiene. The examples directory is particularly instructive;
it shows how to properly span generated code vs. original code, so
compiler error messages are nice. I need to write something about
macro hygiene at some point.
Everything is Better in Slow Motion
Powerslidin’ Sunday from jimmac on Vimeo.
Superb weather over the weekend, despite the thermometer dipping below 10°C.
Announcing Tumbleweed snapshot review site
Adapted from announcement to opensuse-factory mailing list:
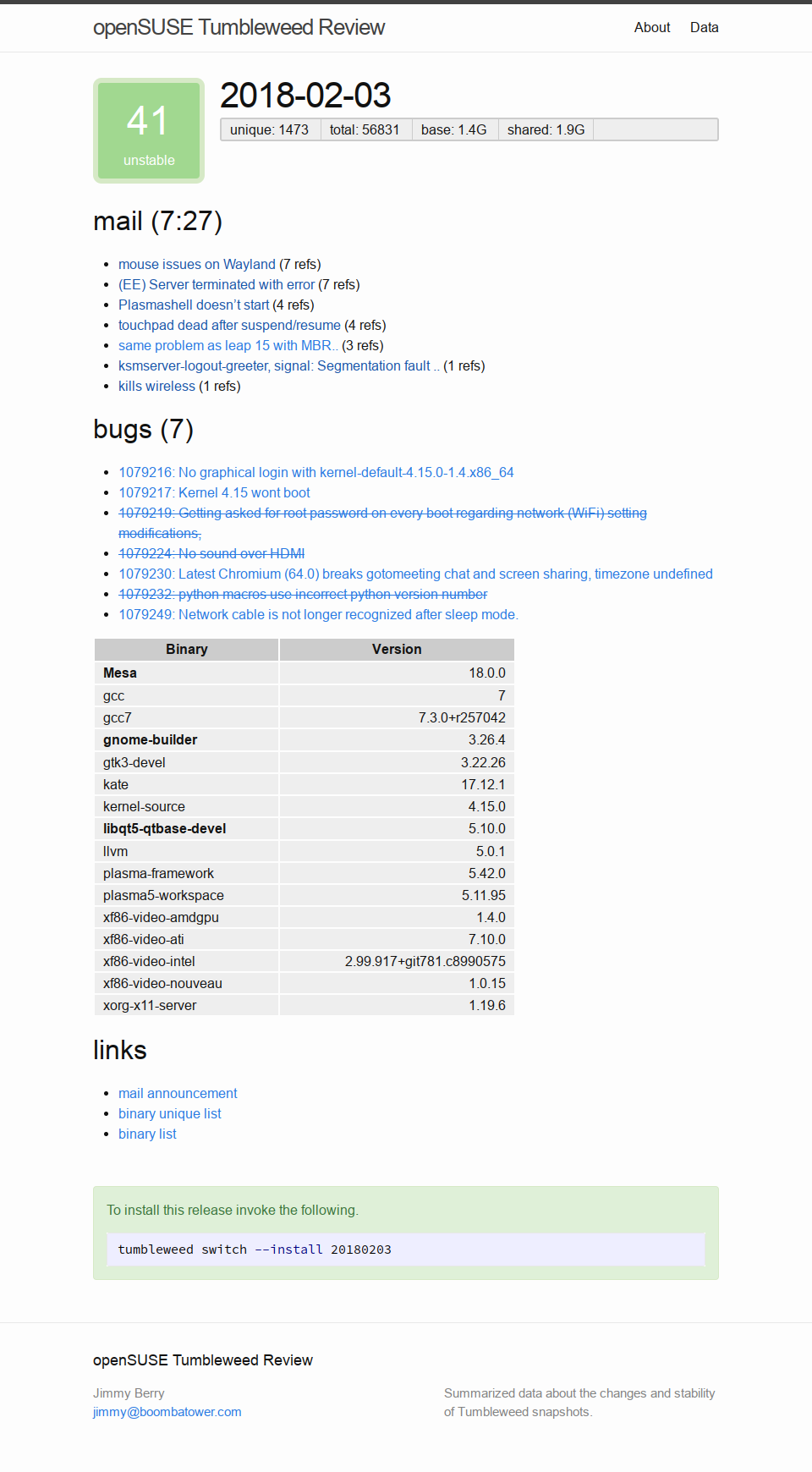
Following up on my prior announcement of Tumbleweed Snapshots, introducing a snapshot review site. By utilizing a variety of sources of feedback pertaining to snapshots a stability score is estimated. The goal is to err on the side of caution and to allow users to avoid troublesome releases. Obviously, there are many enthusiasts who enjoy encountering issues and working to resolve them, but others are looking for a relatively stable experience.
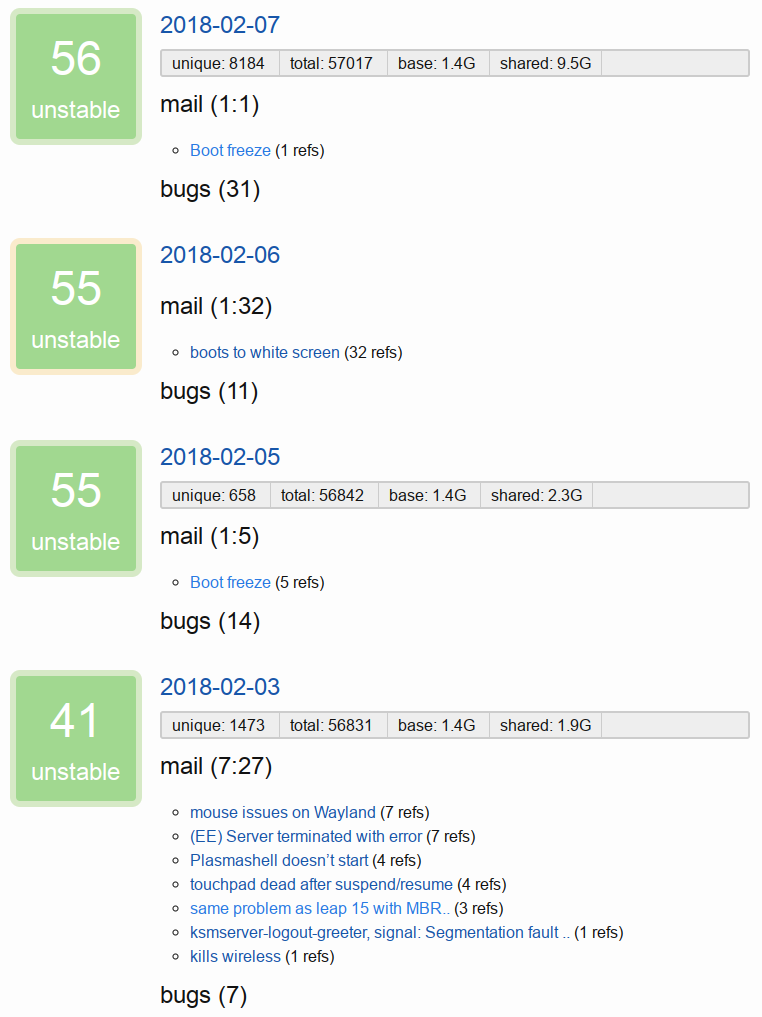
Releases with a low score will continue to impact future release scores with a gradual trail-off. Given that issues generally are not fixed immediately in the next release this assumes the next few releases may still be affected. If the issue persists and is severe it will likely be mentioned again in the mailing list and the score again reduced.
Major system components that are either release candidates or low minor releases are also considered to be risky. For example, recent Mesa release candidates caused white/black screens for many users which is not-trivial to recover from for less-technical users. Such issues come around from time to time since openQA will not catch everything.
Release stability is considered to be pending for the first week after release to allow time for reports to surface. This of course depends on enthusiasts who update often, encounter, and report problems.
The scoring is likely to be tweaked over time to reflect observations. It may also make sense to add a manual override feature to aid scoring when something critical is encountered.
Integrating the scoring data into the tumbleweed-cli would allow users to pick a minimum stability level or score and only update to those releases. Such a mechanism can be vital for systems run by family members, servers, or the wave of gamers looking for the latest OSS graphics stack.
For more details see the code behind the site. Currently, you can see the very low scores for the releases laden with shader cache issues and those therafter. This is the first iteration of the site so nothing too fancy and the score is fairly basic.
The site also provides a machine readable (YAML) version of the data.
As a side-node, Tumbleweed Snapshots are limited to 50 snapshots due to a hosting restriction, but that should generally be over two months worth.
Hopefully others find this useful, enjoy!