
 Member
Member vinzv
vinzvEasyTAG: Organize your music with openSUSE
Audio files in formats such as MP3, AAC, and Ogg Vorbis have made music ubiquitous and portable. With the explosive growth of storage capacity, you can store huge libraries of music. But how do you keep all that music organized? Just tag your music. Then you can access it easily locally and in the cloud. EasyTAG is a great choice for tagging music and is available in openSUSE.
Many audio file types support tagging, including:
- MP4, MP3, MP3, MP2
- Ogg Speex, Ogg Vorbis, Ogg Opus
- FLAC
- MusePack
- Monkey Audio
Installing EasyTAG
EasyTAG is easy to install from openSUSE repositories:
![]()
Or use Zypper in a terminal as Root:
# zypper install easytag
Then launch the program from the Software tool or the application menu for your desktop. EasyTAG’s straightforward interface works well in most desktop environments.
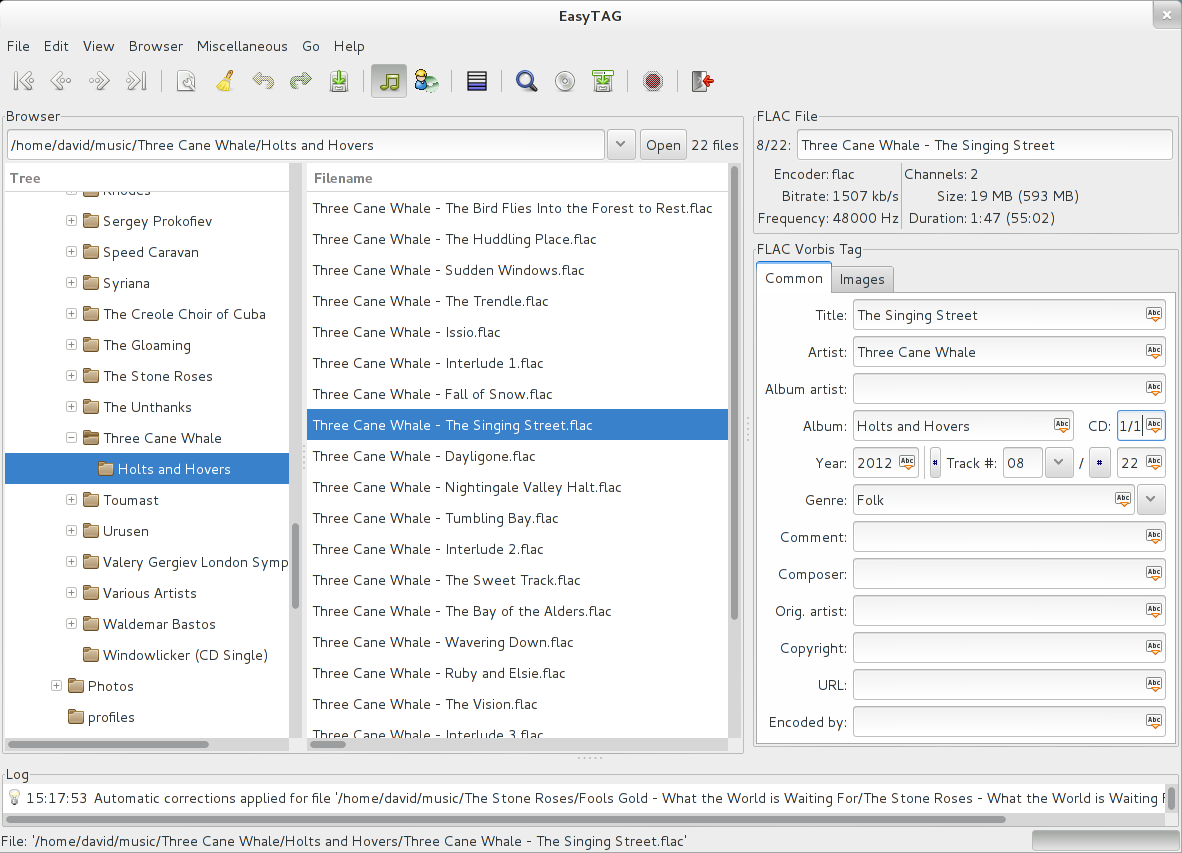
Tagging music
Select a folder where you have music you want to tag. By default, EasyTAG will also load subfolders. You can select each file and add tag information such as the artist, title, year, and so on. You can also add images to a file in JPG or PNG format, which most players understand.
Files you have altered appear in bold in the file listing. To save each, press Ctrl+S. You can also select the entire list and use Ctrl+Shift+S to save all the files at once.
One of the most powerful features of EasyTAG is the file scanner. The scanner recognizes patterns based on a template you provide. Once you provide the right template and scan files, EasyTAG automatically tags all of them for you. Then you can save them in bulk. This saves a lot of time and frustration when dealing with large libraries.
When you upload your tagged files to a cloud service, your tags allow you to quickly find and play the music you want anytime.
This article is an adaption of EasyTAG: Organize your music on Fedora under Creative Commons License.


Leap 15.1, the release that nobody talks about
openSUSE Leap 15.1 is almost ready for release! (1) This is always a high point of the year for me. I started researching what was new in this release. However, there is not much buzz around this release. I found only a few articles on Softpedia (2), Phoronix (3) and the announcement by Ludwig Nussel (4).
When I tried to establish what was new (5) in Leap 15.1, I started to understand why. Leap 15.1 mostly features minor updates. Still there are updates that are noteworthy. In the table below I highlighted in green the updated packages that are really new. In blue, I highlighted new packages that are also present in updated Leap 15 installations.
| Package name | Leap 15 | Leap 15 | Leap 15.1 | Tumbleweed |
| with updates | ||||
| Amarok | 2.9.0 | 2.9.0 | 2.9.0 | 2.9.0 |
| Audacity | 2.2.2 | 2.2.2 | 2.2.2 | 2.3.1 |
| Calibre | 3.23.0 | 3.27.1 | 3.40.1 | 3.40.1 |
| Calligra suite | 3.1.0 | 3.1.0 | 3.1.0 | 3.1.0 |
| Chromium browser | 66 | 73 | 73 | 73 |
| Darktable | 2.4.3 | 2.4.3 | 2.6.2 | 2.6.2 |
| Digikam | 5.9.0 | 5.9.0 | 6.0.0 | 6.1.0 |
| Flatpack | 0.10.4 | 0.10.4 | 1.2.3 | 1.2.4 |
| GIMP | 2.8.22 | 2.8.22 | 2.8.22 | 2.6.12 |
| Gnome Applications | 3.26 | 3.26 | 3.26 | 3.30 |
| GNU Cash | 3.0 | 3.0 | 3.0 | 3.4 |
| Hugin | 2018.0.0 | 2018.0.0 | 2018.0.0 | 2018.0.0 |
| Inkscape | 0.92.2 | 0.92.2 | 0.92.2 | 0.92.4 |
| KDE Applications | 17.12 | 17.12.3 | 18.12.3 | 19.04.0 |
| KDE Plasma 5 desktop | 5.12.5 | 5.12.8 | 5.12.8 | 5.15.4 |
| Krita | 4.0.3 | 4.0.3 | 4.1.8 | 4.1.8 |
| LibreOffice | 6.0.4 | 6.1.3 | 6.1.3 | 6.2.3 |
| Linux kernel | 4.12.14 | 4.12.14 | 4.12.14* | 5.0.9 |
| Mozilla Firefox | 60.0 | 60.6.1 | 60.6.1 | 66.0.3 |
| Mozilla Thunderbird | 52.7 | 60.6.1 | 60.6.1 | 60.6.1 |
| Pidgin | 2.13 | 2.13 | 2.13 | 2.13 |
| Rapid Photo Downloader | 0.9.9 | 0.9.9 | 0.9.14 | 0.9.14 |
| Scribus | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 |
| Shotwell | 0.28.3 | 0.28.3 | 0.28.3 | 0.30.2 |
| VLC | 3.0.2 | 3.0.2 | 3.0.6 | 3.0.6 |
| YaST | 4.0.74 | 4.0.87 | 4.1.68 | 4.2.0 |
Software package updates
Calibre is updated to 3.40 and includes some improvements to Kobo drivers, support for the Kindle Whitepaper 2018, a bunch of improvement for the Edit book functionality, the Content station has a new “Copy to library” function and some usability improvements of the Tag browser.
Darktable is updated to 2.6, including a new retouch module, a new filmic module, a new module to handle duplicates in the darkroom, you can now change the cropped area in the perspective correction module, the mask blur feature has been extended with a guided-filter to fine tune it and the color balance module has two new modes based on ProPhotoRGB and HSL.
Digikam is updated to 6.0. This means that you can now manage video files in the same way as you would manage photos. In the album management, you can now use virtual folders (RAW/JPG/PNG) to sort items in a list. Digikam 6.0 uses libraw 0.19, which enables support for over 200 new RAW files. This includes support for iPhone 8, 8+ and X and support for Samsung S7, S7 Edge and S8. There are also many improvements for connecting with external web services. Finally, Digikam now uses a separate database for fussy and duplicate search, improving performance and reliability.
Flatpack is updated to 1.2.3, which includes many security improvements.
KDE applications got a big update to 18.12. Dolphin (file manager) received many improvements, including the ability to hide the Places panel and dock the Terminal panel. The folder view and settings dialog have been updated. Ocular (PDF and document viewer) has a new typewriter annotation feature that enables you to type everywhere on a page. Konsole (terminal application) now has full support for emoji. The Gwenview (image viewer) has seen many improvements, including the crop tool, the reduce red eye tool, improved zooming and better drag and drop functionality. Spectacle (screenshot tool) gained the ability to sequentially number screenshot files and now remembers the lastest save settings. With the rectangular region selection mode, you can select a part of the screen . Ark (unzip tool) now supports the tar.zst archive file standard.
Krita is updated to 4.1.8 and introduces the new reference images tool that lets you place and edit a reference image to help you with drawing. Another help with drawing is provided by the improved vanishing point assistant. Krita 4.1 features many animation improvements and a better color picker tool.
LibreOffice 6.1 offers 2 new icon themes ‘Colibre’ and ‘Karasa Jaga’, it loads documents with many images faster, the gradient tool has been improved and new fill gradients are available, you can now add page numbers and page counts in the header and footer sections of Writer, you can insert a Signature line in Writer, you can now sort images anchored to cells in Calc, the merge cells dialog box has become much clearer in Calc, you can now use CSVs as data sources in Calc and a new page menu has been added in Impress.
Linux kernel has received some back-ports of Graphics hardware from the Linux kernel 4.19, including better support for AMD Vega cards.
Rapid Photo Downloader (from the Graphics repository) is updated to 0.9.14. Canon’s latest RAW file format CR3 is supported on systems that have ExifTool 10.87 or newer.
YaST has received several improvements and is updated to 4.1.68. YaST has improved the default partitioning proposal for systems with less than 12 GB, YaST received some UI improvements including better support for 4K monitors, the YaST Firewall module has been adapted to work with Firewalld, the Partitioner can now directly format full disks and create MD RAIDs on top of disks without partitions.
Installation options
Besides the standard installation options (full ISO, KDE live ISO, Gnome live ISO, network installer) there is now full support for Raspberry Pi installations. The server installation now features an option for a transactionally updated system. Furthermore there are the more traditional server installations for X86_64 and JeOS (the minimal server installation for the Cloud). You can find the Beta versions of Leap 15.1 here.
Published on: 4 May 2019
In Defense of Tumblweed: Why @BryanLunduke is wrong
What is OpenSUSE Tumbleweed?
OpenSUSE Tumbleweed is a cutting-edge Linux distribution from the OpenSUSE team. It uses the latest versions of software applications and the Linux kernel for those who want to see what will be coming up in other Linux distributions in 6-months to a year or more from the time that they appear in Tumbleweed. This means that there are bugs; lots of them. Things break, This is the price that you pay for having the very cutting edge or software technology.
What did Bryan Lunduke actually say?
Let’s break down his complaints. There are only two.
- SUSE Studio
- YaST (ugly, cumbersome, hard to use, stupid, bloated)
The first complaint is an application stack that doesn’t actually have anything directly to do with Tumbleweed. I never used it. It was going by the wayside when I started using OpenSUSE as my daily OS of choice. The source code is still out there and maybe it should be forked and brought back to life. I don’t know. I can’t argue with this point because it is a red herring and has nothing to do the OpenSUSE Tumbleweed distribution.
The second list of complaints is pretty vague, but his complaint is basically that YaST has issues that are causing it to bring does the entire distribution as a whole.

What is YaST?
YaST (Yet Another Setup Tool) is a set of system management tools that are grouped together in a single management application called YaST though they can be installed and run separately as needed.
The modules allow the user to easily control most administrative functions that might be needed. Not all of the modules are the same though. Some such as the printer and scanner modules suck. Other modules like the Software Management module are great. I consider this to be on par with Debian’s Synaptic package management tool which is freaking amazing. If unevenness in the quality of the modules is the reason why he dislikes it so much, then it’s not a completely wrong reason but it’s not a really good one either.
I say that it’s a given that some of the modules are out of date or need a fresh new rewrite, but that’s not specifically what he is saying. He keeps his complaints vague and oddly personal. I’m not privy to much of the inner-workings of the OpenSUSE distribution but I’ve seen from social media that there is some bad blood there between him and folks in OpenSUSE and I really hope this isn’t just a rant against them instead of really against the distribution.
With that aside, let’s talk about the real issue with YaST and any GUI based configuration tool. It is yet another level of abstraction away from actually working with the operating system. For example, YaST has an module called HTTP Server. If you run it, it will set up Apache and any modules like PHP for you and will give you some basic options for tuning it without actually needing to work with the command line or configuration files directly. If someone told me that they had been a system administrator for 5 years but they had only ever used YaST, I wouldn’t hire them because many times things break and they can’t be fixed with YaST. Tools like YaST should mainly be a time saver not a replacement for good configuration and I think that’s what it is currently.
Even with my own genuine complaints above, they don’t really co-inside with Bryan Lunduke’s complains (it’s ugly, cumbersome, hard to use, stupid, and bloated) because I can’t see all of that. It’s no more ugly than any other tool (besides real nerds care about function over form). Granted, some of the modules are cumbersome and hard to use, but not all of them. It’s “stupid, stupid and it’s stupid” what the heck is that supposed to mean? Use your words Lunduke! Don’t just emote. “It’s bloated.” There are currently 183 total YaST modules. Many will never be used by an end user because they are only used during installation. However if you were to install them all, it would take up 176MiB which would average out to .96MiB per module. There are some required Ruby libraries that I’m not taking into account here, but this really isn’t what I would call bloat. You can even uninstall the modules that you don’t want without causing a huge fuss.
Let’s Wrap Up
Bryan Lunduke is wrong when he says that OpenSUSE Tumbleweed is one of the worst distros out right now. He is wrong when he says that YaST is dragging down the entire distro. YaST has problems, but they aren’t what he says they are.

Noisy Workshop
Usually, in my workshop I am listening to the great radio station Bayern 2 (Yeah for public law media). But sometimes you just need to listen to nice classic english punk music, speed folk or (the one and only) Lemmy and friends.
For that I was looking for a so called boom box to stream to from my mobile, simple, dirty and loud. Good that I was a proud awardee at the HiFiBerry Maker Contest 2017 with my TeakEar build, where I won a nice set of a RaspberryPi Zero with a little HiFiBerry MiniAmp, coming with all what is needed to make that working.  That should be enough to get proper punk sound in the workshop - and escape the boring normal commercial boom boxes all around.
That should be enough to get proper punk sound in the workshop - and escape the boring normal commercial boom boxes all around.
At a flee market I found a great case for that - exactly one of these that were in the classrooms of my school giving the unbanning gong at the end of each lesson. Nicely with the original non-color textile hiding the speaker and nicely done bended and veneered wood for the elegance.

A great fit for my usecase.
Two 3.3 inch Visaton fullrange speaker are mounted in simple closed chassis. The Raspi with the Amp is mounted between them. All is mounted on a back plate that fits the school speaker chassis. Boombox ready.
From a software perspective, it is there is just a Raspbian running that is configured to act as a bluetooth audio device for my mobile.
I think it is a nice addition to my workshop, with a great ease of use since it auto-connects to my mobile. Does it sound great? Oh no, not ..really. Is it loud? Well, yes, loud enough to not get in trouble with the neighbors. Given it’s size, it is actually impresse.
Surely Lemmy would be fine to play Rock’n Roll through it :)
The only downsize of the whole thing is that it disturbs the radio reception quite a bit, so it is really either or. Any hints how to reduce that?

Weblate 3.6.1
Weblate 3.6.1 has been released today. It is a bugfix release fixing several issues reported after the 3.6 release.
Full list of changes:
- Improved handling of monolingual Xliff files.
- Fixed digest notifications in some corner cases.
- Fixed addon script error alert.
- Fixed generating MO file for monolingual PO files.
- Fixed display of uninstalled checks.
- Indicate administered projects on project listing.
- Allow update to recover from missing VCS repository.
If you are upgrading from older version, please follow our upgrading instructions.
You can find more information about Weblate on https://weblate.org, the code is hosted on Github. If you are curious how it looks, you can try it out on demo server. Weblate is also being used on https://hosted.weblate.org/ as official translating service for phpMyAdmin, OsmAnd, Turris, FreedomBox, Weblate itself and many other projects.
Should you be looking for hosting of translations for your project, I'm happy to host them for you or help with setting it up on your infrastructure.
Further development of Weblate would not be possible without people providing donations, thanks to everybody who have helped so far! The roadmap for next release is just being prepared, you can influence this by expressing support for individual issues either by comments or by providing bounty for them.

Distracted by LeoCAD Once Again on openSUSE Linux
LattePanda Gigglescore
A Gigglescore is a ratio score of price to performance for single-board-computers like the LattePanda or Raspberry Pi. A lower Gigglescore means a better value for the money. A higher one is worse. You can see more here: https://gigglescore.com/
My LattePanda:
sudo ./benchmark.sh 149
Repository 'openSUSE-Leap-15.0-Non-Oss' is up to date.
Repository 'openSUSE-Leap-15.0-Oss' is up to date.
Repository 'openSUSE-Leap-15.0-Update' is up to date.
Repository 'openSUSE-Leap-15.0-Update-Non-Oss' is up to date.
All repositories have been refreshed.
Category5.TV SBC Benchmark v1.1
Powered by sysbench 1.0.11
Number of threads for this SBC: 4
Performing CPU Benchmark… WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
576.760 events per second. Price: Ģ930.02 per unit.
Performing RAM Benchmark… WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
3,625,781.466 events per second. Price: Ģ0.15 per unit.
Performing Mutex Benchmark… WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
6.873 events per second. Price: Ģ7.80 per unit.
Total Giggle cost of this board: Ģ1,397.58
Giggles (Ģ) are a cost comparison that takes cost and performance into account. While the figure itself is not a direct translation of a dollar value, it works the same way: A board with a lower Giggle value costs less for the performance.
If a board has a high Giggle value, it means for its performance, it is expensive. Giggles help you determine if a board is better bang-for-the-buck, even if it has a different real-world dollar value. Total Giggle cost does not include I/O since that can be impacted by which SD card you choose. Lower Ģ is better.
Being that the suggested retail price is currently $149, we get a Gigglescore of 1,397.58. This is right between the Raspberry Pi 3 B+ and the ODROID XU4 in terms of value for the dollar.
Sabayon Linux | Review from an openSUSE User
Weblate 3.6
Weblate 3.6 has been released today. It brings rewritten notifications, user data download and several other improvements. It also sets depreciation timeline for Python 2 installations - after April 2020 Weblate will only support Python 3.
Full list of changes:
- Add support for downloading user data.
- Addons are now automatically triggered upon installation.
- Improved instructions for resolving merge conflicts.
- Cleanup addon is now compatible with app store metadata translations.
- Configurable language code syntax when adding new translations.
- Warn about using Python 2 with planned termination of support in April 2020.
- Extract special chars from the source string for visual keyboard.
- Extended contributor stats to reflect both source and target counts.
- Admins and consistency addons can now add translations even if disabled for users.
- Fixed description of toggle disabling
Language-Teamheader manipulation. - Notify users mentioned in comments.
- Removed file format autodetection from component setup.
- Fixed generating MO file for monolingual PO files.
- Added digest notifications.
- Added support for muting component notifications.
- Added notifications for new alerts, whiteboard messages or components.
- Notifications for administered projects can now be configured.
- Improved handling of three letter language codes.
If you are upgrading from older version, please follow our upgrading instructions.
You can find more information about Weblate on https://weblate.org, the code is hosted on Github. If you are curious how it looks, you can try it out on demo server. Weblate is also being used on https://hosted.weblate.org/ as official translating service for phpMyAdmin, OsmAnd, Turris, FreedomBox, Weblate itself and many other projects.
Should you be looking for hosting of translations for your project, I'm happy to host them for you or help with setting it up on your infrastructure.
Further development of Weblate would not be possible without people providing donations, thanks to everybody who have helped so far! The roadmap for next release is just being prepared, you can influence this by expressing support for individual issues either by comments or by providing bounty for them.