
 dannyK
dannyKDeutsche OpenStack Tage 2016

A few words about the future of the Limba project
 I wanted to write this blogpost since April, and even announced it in two previous posts, but never got to actually write it until now. And with the recent events in Snappy and Flatpak land, I can not defer this post any longer (unless I want to answer the same questions over and over on IRC ^^).
I wanted to write this blogpost since April, and even announced it in two previous posts, but never got to actually write it until now. And with the recent events in Snappy and Flatpak land, I can not defer this post any longer (unless I want to answer the same questions over and over on IRC ^^).
As you know, I develop the Limba 3rd-party software installer since 2014 (see this LWN article explaining the project better then I could do  ) which is a spiritual successor to the Listaller project which was in development since roughly 2008. Limba got some competition by Flatpak and Snappy, so it’s natural to ask what the projects next steps will be.
) which is a spiritual successor to the Listaller project which was in development since roughly 2008. Limba got some competition by Flatpak and Snappy, so it’s natural to ask what the projects next steps will be.
Meeting with the competition
At last FOSDEM and at the GNOME Software sprint this year in April, I met with Alexander Larsson and we discussed the rather unfortunate situation we got into, with Flatpak and Limba being in competition.
Both Alex and I have been experimenting with 3rd-party app distribution for quite some time, with me working on Listaller and him working on Glick and Glick2. All these projects never went anywhere. Around the time when I started Limba, fixing design mistakes done with Listaller, Alex started a new attempt at software distribution, this time with sandboxing added to the mix and a new OSTree-based design of the software-distribution mechanism. It wasn’t at all clear that XdgApp, later to be renamed to Flatpak, would get huge backing by GNOME and later Red Hat, becoming a very promising candidate for a truly cross-distro software distribution system.
The main difference between Limba and Flatpak is that Limba allows modular runtimes, with things like the toolkit, helper libraries and programs being separate modules, which can be updated independently. Flatpak on the other hand, allows just one static runtime and enforces everything that is not in the runtime already to be bundled with the actual application. So, while a Limba bundle might depend on multiple individual other bundles, Flatpak bundles only have one fixed dependency on a runtime. Getting a compromise between those two concepts is not possible, and since the modular vs. static approach in Limba and Flatpak where fundamental, conscious design decisions, merging the projects was also not possible.
Alex and I had very productive discussions, and except for the modularity issue, we were pretty much on the same page in every other aspect regarding the sandboxing and app-distribution matters.
Sometimes stepping out of the way is the best way to achieve progress
So, what to do now? Obviously, I can continue to push Limba forward, but given all the other projects I maintain, this seems to be a waste of resources (Limba eats a lot of my spare time). Now with Flatpak and Snappy being available, I am basically competing with Canonical and Red Hat, who can make much more progress faster then I can do as a single developer. Also, Flatpaks bigger base of contributors compared to Limba is a clear sign which project the community favors more.
Furthermore, I started the Listaller and Limba projects to scratch an itch. When being new to Linux, it was very annoying to me to see some applications only being made available in compiled form for one distribution, and sometimes one that I didn’t use. Getting software was incredibly hard for me as a newbie, and using the package-manager was also unusual back then (no software center apps existed, only package lists). If you wanted to update one app, you usually needed to update your whole distribution, sometimes even to a development version or rolling-release channel, sacrificing stability.
So, if now this issue gets solved by someone else in a good way, there is no point in pushing my solution hard. I developed a tool to solve a problem, and it looks like another tool will fix that issue now before mine does, which is fine, because this longstanding problem will finally be solved. And that’s the thing I actually care most about.
I still think Limba is the superior solution for app distribution, but it is also the one that is most complex and requires additional work by upstream projects to use it properly. Which is something most projects don’t want, and that’s completely fine.
And that being said: I think Flatpak is a great project. Alex has much experience in this matter, and the design of Flatpak is sound. It solves many issues 3rd-party app development faces in a pretty elegant way, and I like it very much for that. Also the focus on sandboxing is great, although that part will need more time to become really useful. (Aside from that, working with Alexander is a pleasure, and he really cares about making Flatpak a truly cross-distributional, vendor independent project.)
Moving forward
So, what I will do now is not to stop Limba development completely, but keep it going as a research project. Maybe one can use Limba bundles to create Flatpak packages more easily. We also discussed having Flatpak launch applications installed by Limba, which would allow both systems to coexist and benefit from each other. Since Limba (unlike Listaller) was also explicitly designed for web-applications, and therefore has a slightly wider scope than Flatpak, this could make sense.
In any case though, I will invest much less time in the Limba project. This is good news for all the people out there using the Tanglu Linux distribution, AppStream-metadata-consuming services, PackageKit on Debian, etc. – those will receive more attention
An integral part of Limba is a web service called “LimbaHub” to accept new bundles, do QA on them and publish them in a public repository. I will likely rewrite it to be a service using Flatpak bundles, maybe even supporting Flatpak bundles and Limba bundles side-by-side (and if useful, maybe also support AppImageKit and Snappy). But this project is still on the drawing board.
Let’s see 
P.S: If you come to Debconf in Cape Town, make sure to not miss my talks about AppStream and bundling

 Member
MemberMigrating to Nextcloud 9

Edit: Nextcloud 10 is out with loads of unique features. We now also have a client! You can find out about client account migration here.
Why migrate
Let's start with the why. First, you don't have to migrate yet. This release as well as at least the upcoming releases of own- and Nextcloud will be compatible so you'll be able to migrate between them in the future. We don't want to break compatibility if we can avoid it!Of course, right now Nextcloud 9 has some extra features and fixes and future releases will introduce other capabilities. With regards to security, we have Lukas Reschke working for us. However, we promise that for the foreseeable future we will continue to report all security issues we find to upstream in advance of any release we do. That means well ahead of our usual public disclosure policy, so security doesn't have to be a reason for people to move.
Edit: Nextcloud 10 comes with far more features on top of this. For Nextcloud 11 we have a ambitious road map already but we'll still enable migration from ownCloud 9.1 to Nextcloud 11 so you can migrate at your leisure!
Migration overview
If you've decided to migrate there are a number of steps to go through:- Make sure you have everything set up properly and do a backup
- Move the old ownCloud install, preserving data and config
- Extract Nextcloud, correct permissions and put back data and config
- Switch data and config
- Trigger the update via command line or the web UI
There are other great resources besides this blog, especially this awesome post on our forums which gives a great and even more detailed overview of a migration with an Ubuntu/NGINX/PHP7/MariaDB setup.
Edit: With regard to packages, there are now packages for CentOS and Fedora and other distributions will likely follow soon. See our packages repository if you want to help!
Preparation
First, let's check if you're set up properly. Make sure:- You are on ownCloud 8.2.3 or later
- Make sure you have all dependencies
- Your favorite apps are compatible (with ownCloud 9), you can check this by visiting the app store at apps.owncloud.com
- You made a backup
Removing old files
In this step, we'll move the existing installation preserving the data and configuration.- Put your server in maintenance mode. Go to the folder ownCloud is installed in and execute
sudo -u www-data php occ maintenance:mode --on(www-data has to be your HTTP user). You can also edit yourconfig.phpfile and changing'maintenance' => false, to'maintenance' => true,. - Now move the data and config folder out of the way. Best to go to your webserver folder (something like
/var/www/htdocs/and do amv owncloud owncloud-backup
Deploying Nextcloud
Now, we will put Nextcloud in place.- Grab Nextcloud from our download page or use wget:
wget https://download.nextcloud.com/server/releases/nextcloud-9.0.50.zip - Optional: you can verify if the download went correct using our MD5 code, see this page. Run
md5sum nextcloud-9.0.50.zip. The output has to match this value:5ae47c800d1f9889bd5f0075b6dbb3ba - Now extract Nextcloud:
unzip nextcloud-9.0.50.ziportar -xvf nextcloud-9.0.50.tar.bz2 - Put the config.php file in the right spot:
cp owncloud-backup/config/config.php nextcloud/config/config.php - Now change the ownership of the files to that of your webserver, for example
chown wwwrun:www * -Rorchown www-data * - If you keep your data/ directory in your
owncloud/directory, copy it to your newnextcloud/[*]. If you keep it outside of owncloud/ then you don't need to do anything as its location is in config.php.
* Note that if you have been upgrading your server from before ownCloud 6.0 there is a risk that moving the data directory causes issues. It is best to keep the folder with Nextcloud named 'owncloud'. This also avoids having to change all kinds of settings on the server, so it might be a wise choice in any case: rename the nextcloud folder to owncloud.
Now upgrade!
Next up is restarting the webserver and upgrading.- Restart your webserver. How depends on your distribution. For example,
rcapache2 restarton openSUSE,service restart apache2on Ubuntu. - You can now trigger the update either via OCC or via web. Command line is the most reliable solution. Run it as
sudo -u apache php occ upgradefrom the nextcloud folder. This has to run as the user of your webserver and thus can also bewww-dataorwwwfor example. - Then, finally, turn of maintenance mode:
sudo -u www-data php occ maintenance:mode --off
That's it!
At this point, you'll see the fresh blue of a Nextcloud server! If you encounter any issues with upgrading, discuss them on our forums.
On Open Source, forking and collaboration: Nextcloud 9 is here!

Ecosystems and confidence
A major point which makes open source so beneficial for businesses is that it puts pressure on suppliers to offer great service and support. If they don't, another can enter the market and out-service them. Tight control over the community tough things like CLA and trademark makes it hard to grow such an ecosystem and negates some of the benefits of open source for customers.Luckily, in the end, the AGPL license protects the future of a project, even if its steward clings to power. From conversations with Niels early on, it was clear to me that he has a very different and very confident view on his ability to run a real open source company. His history at Red Hat results in frequent comparisons. And indeed, Red Hat runs things the right way, even supporting a project like CentOS which many other companies would consider an existential threat to their business model. Just as their investment in opensource.com shows: they aim to grow the pie, not grab a bigger slice.
 |
| former 'enterprise feature' done right (and open) |
I'm super proud and happy that we could announce today, with our first release, that Nextcloud will not be doing proprietary code. No closed apps means no inherent conflict between sales and community management/developers within the company, but a full alignment in one simple direction: servicing the customer.
And if you wonder about the collaboration with Collabora/LibreOffice Online and with Western Digital: yes, of course, we'll go full steam ahead and will facilitate where we can! No, we're not afraid that either would 'compete' with us: both will complement and strengthen the ecosystem. So we will work together.
Why? Because the core contributors and founder shared an ambitious goal for Nextcloud: be THE solution for privacy and security.
BBQ and forking
It was great to have conversations with the contributors who visited us as well as some downtime with the team. It's been a busy time since we announced our new endeavor. And it continues to be awesome to get so many supportive comments and feedback on what we're up to! People are excited about our open strategy and appreciate the fact that there is a solid company behind it. The flood of incoming requests for information and support from customers presents a good problem. So let me point out, again, that we're hiring!






Managing configuration drift with Salt and Snapper
Introduction
Many configuration management tools originate in the DevOps space and become immensely popular and while they do manage configuration, they are tailored towards deployment of new servers using this configuration and not towards auditing of existing servers.
For example, lets imagine a server with the following state:
/etc/motd:
file.managed:
- source: salt://common/motd
If we apply this state (in test mode) on a non-compliant server:
$ salt minion1 state.apply test=True
minion1:
----------
ID: /etc/motd
Function: file.managed
Result: None
Comment: The file /etc/motd is set to be changed
Started: 10:06:05.021643
Duration: 30.339 ms
Changes:
----------
diff:
---
+++
@@ -1 +1 @@
-Have a lot of fun...
+This is my managed motd
Summary for minion1
------------
Succeeded: 1 (unchanged=1, changed=1)
Failed: 0
------------
Total states run: 1
Salt is able to tell us that there is a file that deviates from the configuration. And we can easily fix it by just removing test=True.
Now, lets say an intruder adds a malicious entry to /etc/hosts:
192.168.1.34 www.google.com
If we re run our state in test mode:
$ salt minion1 state.apply test=True
minion1:
----------
ID: /etc/motd
Function: file.managed
Result: None
Comment: The file /etc/motd is set to be changed
Started: 10:12:11.518105
Duration: 29.479 ms
Changes:
----------
diff:
---
+++
@@ -1 +1 @@
-Have a lot of fun...
+This is my managed motd
Summary for minion1
------------
Succeeded: 1 (unchanged=1, changed=1)
Failed: 0
------------
Total states run: 1
As expected, it did not find anything, because this rule is not in the configuration.
Creating new systems vs auditing existing systems
This model works fine in the DevOps world where the culture is to take a random Linux image from the internet and use it as a base to deploy systems from scratch. As long as all tests pass, replacing the underlying image is not a problem. Only what is explicitly defined is evaluated against the configuration and defined as a drift.
When meeting enterprise customers who are starting to use configuration management to improve the control on their infrastructure, it turns out their expectations where different. “If I use Salt, will it tell me when somebody makes a change to the system?”. “Ugh.. no… well depends…”.
Baselines
That was the point that I started to think about - how could we use the state system to do more generic auditing and how do you do it without ruining the experience of working with states? Then it all clicked – implicit state can be done explicitly by using another state. When the customer said “any change”, they were in reality saying “any change against my defined configuration” plus “any change since my last working configuration”.
So, we needed a way to manage “last working configuration” and turns out SUSE is where Snapper originated and Snapper is nowadays available with most Linux distributions.
Snapper is a set of tools over snapshots (mostly btrfs, but also works on others like ext4 if you have the required kernel/tool patches). Think of it of what docker did to containers, snapper does to snapshots. It adds the required workflows, terminology and tools to make them usable.
It also turns out that my system already has some snapshots, because just like I can manually take one, tools like YaST and zypper take snapshots before and after doing operations. You can even select previous snapshots from the bootloader and boot into the previous working system.
What if I could describe a state in Salt that said: “Nothing deviates from this snapshots, except….”.
Let’s do it
So during this year Department workshop I paired with Pablo and our project had the following steps:
- Complete the Salt execution module to expose the basic snapper operations you can do from the command line. Example:
salt minion1 snapper.create_snapshot
- Create a generic way for sysadmins to do Salt operations which can be reverted. We implemented this as a meta-call (a call taking another call as a parameter)
snapper.run. So you can do something like:
$ salt minion2 snapper.run function=file.append args='["/etc/motd", "some text"]'
minion2:
Wrote 1 lines to "/etc/motd"
This will generate a snapshot before running the command, run the command and then take a snapshot afterwards, also adding metadata about the Salt job that did the change:
... pre | 21 | | Thu Jun 9 10:34:36 2016 | root | number | salt job 20160609103437556668 | salt_jid=20160609103437556668 post | 22 | 21 | Thu Jun 9 10:34:37 2016 | root | number | salt job 20160609103437556668 | salt_jid=20160609103437556668
Because in Salt, state is implemented as a method state.apply or state.highstate, calling snapper.run function=state.apply means you can rollback a failed state.apply.
And of course we not only exposed snapper.diff which takes the snapshot number but also a snapper.diff_jid which tells you what a Salt job changed:
$ salt minion2 snapper.diff_jid 20160609103437556668
minion2:
----------
/etc/motd:
--- /.snapshots/21/snapshot/etc/motd
+++ /.snapshots/22/snapshot/etc/motd
@@ -1 +1,2 @@
Have a lot of fun...
+some text
Additionally, you get snapper.undo_jid which you can guess what it does: it undoes the changes done by a specific salt job (which of course could be a state.apply run).
- And finally, allowing a system administrator to use snapshots as a baseline to apply state. Lets take the original example with the malicious user modifying `/etc/hosts’, we will add a snapper state rule:
my_baseline:
snapper.baseline_snapshot:
- number: 20
- ignore:
- /var/log
- /var/cache
/etc/motd:
file.managed:
- source: salt://common/motd
Now we apply the state in test mode again:
$ salt minion1 state.apply test=True
minion1:
----------
ID: my_baseline
Function: snapper.baseline_snapshot
Result: None
Comment: 1 files changes are set to be undone
Started: 12:20:24.899848
Duration: 1051.996 ms
Changes:
----------
files:
----------
/etc/hosts:
----------
actions:
- modified
comment:
text file
diff:
--- /etc/hosts
+++ /.snapshots/21/snapshot/etc/hosts
@@ -22,5 +22,3 @@
ff02::3 ipv6-allhosts
-192.168.1.34 www.google.com
-
----------
ID: /etc/motd
Function: file.managed
Result: None
Comment: The file /etc/motd is set to be changed
Started: 12:20:25.953348
Duration: 20.425 ms
Changes:
----------
diff:
---
+++
@@ -1 +1 @@
-Have a lot of fun...
+This is my managed motd
Summary for minion1
------------
Succeeded: 2 (unchanged=2, changed=2)
Failed: 0
------------
Total states run: 2
Exactly what we expect!.
Conclusions
So with this you can use your configuration management to manage your state against a defined state and on top of that we give you the tooling to inspect and rollback configuration changes.
We will continue adding the missing pieces to give the administrators full overview and control over their running systems.
You can find our current work in this github repository. We plan of course to send it upstream once the design and implementation settles down.
Switches of libgreattao
Switches are one of idea, which makes libgreattao amazing. It’s allows interface to morph. For example: we have question dialog with one button(abort) and we add to it ok and cancel. Libgreattao can automatically puts ok and cancel into select list and put exit as separate button. Another example is implementing view switching in file manager. File manager will deliver list of file name, properties and icons and libgreattao takes full advantage about select view and view it in iconview control or in properties list control.
Look at video:
Nextcloud hackweek and open BBQ!
If you're in the area, we'd love to see you show up Wednesday at Egilolfstraße 31, Plieningen/Hohenheim close to Stuttgart Airport. Nearest public transport would be either U3 Plieningen or S2/3 Flughafen/Messe. Join us starting 6PM for the good times!
View Larger Map
We'll have some alcoholic and non-alcoholic beverages, meat, fruits, veggie stuff and of course a BBQ. Give us a shout if you're coming on the forums!




Research at Ailao
Readers of this blog should be already a little bit familiar with the Ailao brand, which we use for spinning off and commercialization of our academic research. Originally, Ailao was all about text and question answering, but there was always the theme of dealing with unstructured data in general.
Nowadays, Ailao is not just me (Petr BaudiÅ¡) anymore – but a partnership with Tomáš Gogár and Tomáš Tunys, fellow PhD students! And we are widening our breadth to cover documents in general, developing a machine learning computational platform Ailao Brain (just a codename!) as well as working hard on some exciting end-user products. We are also working on a prettier website (including a new look for this blog) and many other things, but more on that soon.
What I wanted to point out is our talk at Machine Learning Meetups Prague. The talk itself (video) is in Czech, but you can enjoy at least our English slides on our bleeding edge technology research (webpage information extraction and text understanding). Stay tuned for more!
Overcommit? Overcommit!
Git itself provides support for running hook scripts at many events. It would be nice to run some checks automatically, for example when creating a commit.
The problem is not how to run the checks but how to integrate them, make them fast and safe, provide a nice output, etc…
Overcommit
By chance I came across Overcommit, a nice framework for running Git hooks.
It provides a wide variety of predefined checks which are easy to use. I found some of them really useful:
-
Forbid commits to blacklisted branches - e.g. you can forbid direct commits to
masterbecause you want to use Pull Requests. This can also avoid mistakes, e.g. once I did a typo ingit checkout -band overlooked that. The followingcommitandpushwent by mistake directly tomaster… -
Run Rubocop automatically to avoid fix up commits later. I see “make Rubocop happy” commits quite often in YaST.
-
Run the tests locally before pushing the changes, that makes sure the tests still pass. Sometimes you forget to run the tests or simply you are too lazy to run them.
-
And last but not least it can check spelling of the commit messages to avoid typos.
For more details see the Overcommit documentation.
Speed?
A very nice Overcommit feature is that it wants to be quick, your usual git workflow should not be slowed down because of the hooks.
For example it tries running all hooks in parallel and the Rubocop hook checks only the changed files, which speeds it up for large repositories a lot. Running Rubocop over all source files in the YaST registration module takes about 7 seconds on my machine, but when a single file is checked it takes just a fraction of a second.
Installation
I have prepared RPM packages with Overcommit, simply add the YaST:Head repository and run
zypper in "rubygem(overcommit)"
Initializing the Hooks
Now go to your Git repository and set up the hooks:
- Use
overcommit --installto install the hooks. - Add the
.overcommit.ymlconfiguration file. - Run
overcommit --signto sign the current configuration. You will need to run it again whenever the config files is changed. See the Security section in the documentation for more details.
You need to install Overcommit in each Git repository separately, but it is possible to automate the setup.
Using the Hooks
Then you use the git commands as usually, you do not need to change anything
to run the hooks. You will just see the results of the Overcommit hooks
in the output.
If a hook fails the whole git command fails. So if for example the Rubocop
hook fails when creating a commit then the commit is not created and you can fix
the problem early.
If for some reason you want to temporarily disable the Overcommit checks run
the git command with OVERCOMMIT_DISABLE=1 environment setting.
Example Configuration
Here is an example .overcommit.yml file proposed for YaST:
PreCommit:
# do not commit directly to these branches, use Pull Requests!
ForbiddenBranches:
enabled: true
branch_patterns:
- master
- openSUSE-*
- SLE-10-*
- Code-11*
- SLE-12-*
RuboCop:
enabled: true
# treat all warnings as failures
on_warn: fail
CommitMsg:
SpellCheck:
enabled: true
# force using the English dictionary
env:
LC_ALL: en_US.UTF-8
PrePush:
RSpec:
enabled: true
command: [ "rake", "test:unit" ]
# do not fail because of translations
env:
LC_ALL: en_US.UTF-8
Example Session
I recorded an example session to show the mentioned Overcommit features in action in the registration repository:
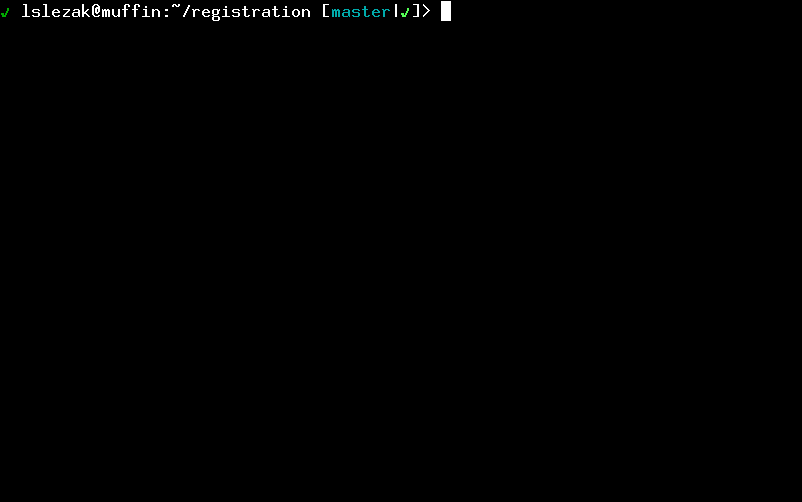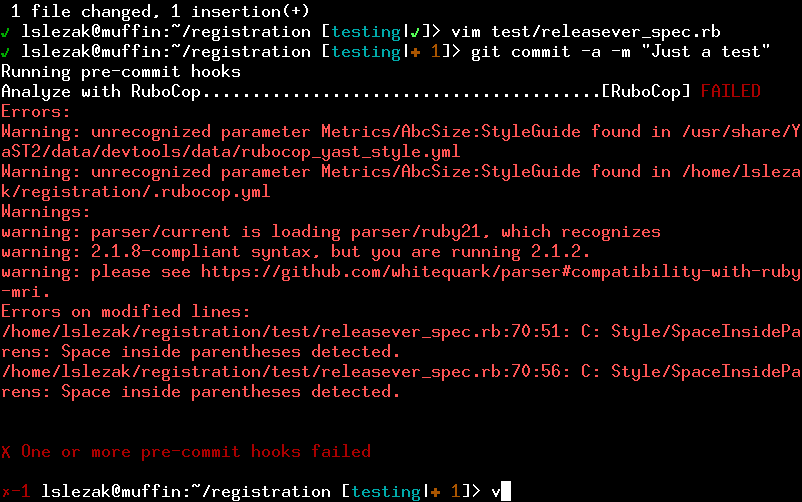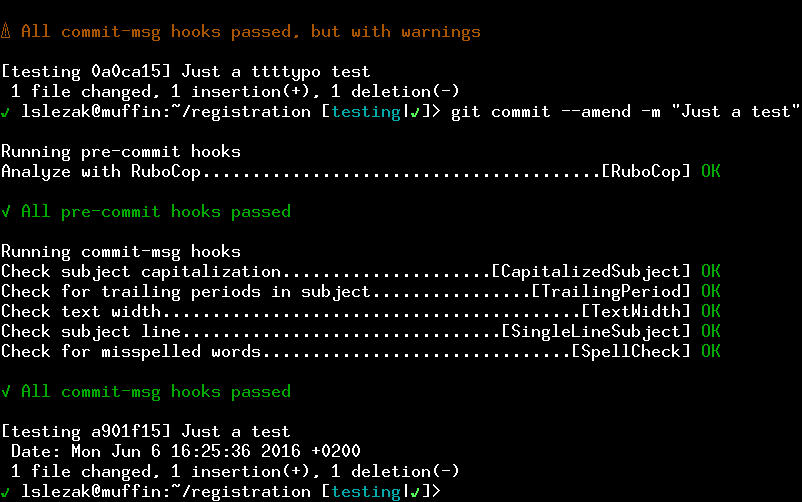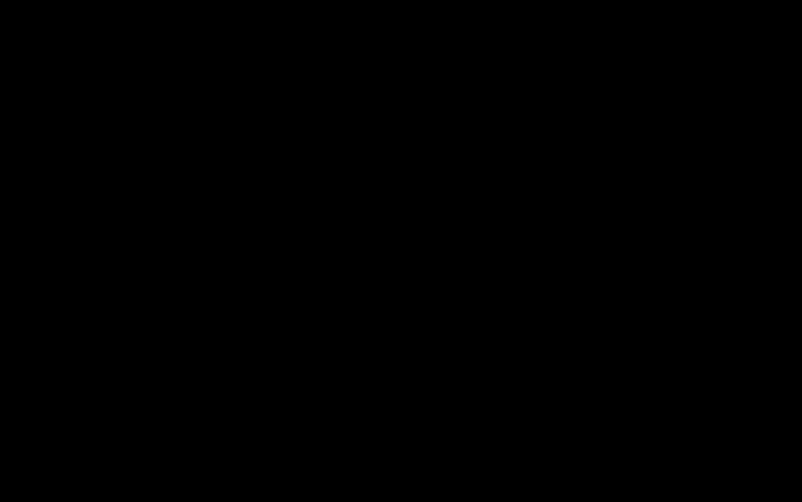
It looks nice, isn’t it? (If you like the git status in the bash prompt check this older post).
Conclusion
It looks very promising and it could catch some obvious mistakes early, I will give it a try. I will try using it for some time and then we will see if it could be used in YaST more widely.