
 Member
Member baltolkien
baltolkienTaller de navidad: diseño & impresión 3D en Linux Center
Los eventos parece que empiezan a ser más numerosos a medida que la comunidad linuxera vuelve a la normalidad post-pandémica. Hoy me complace compartir la tercera charl0-tallera tras la reapertura de Linux Center, el punto de encuentro y formación de los usuarios GNU/Linux auspiciada de Slimbook que lleva por título «Taller de navidad: diseño & impresión 3D», que será realizado por Adriana en las Linux Center.
Taller de navidad: diseño & impresión 3D en Linux Center
Hemos hablado mucho este verano de la compañía valenciana de ensamblaje de dispositivos compatibles 100% con el Software Libre conocida como Slimbook, pero hemos hablado de sus ultrabooks y no tanto de sus actividades, y es hora compaginar ambas cosas ya que hace poco han dedicido volver al mundo de los eventos con la reapertura de su Linux Center.

De esta forma, el próximo 3 de diciembre de este 2022 vamos a poder disfrutar la tercera charla formal desde su reapertura oficial.
En palabras de los organizadores:
Adriana Fuentes, profesional de las TIC con más de 15 años de experiencia en el sector de tecnologías web, diseño y multimedia. He trabajado como responsable de marketing y diseño, UX/UI y desarrollo de aplicaciones corporativas.
Algunos de sus trabajos han sido:
* Video-animación 3D reproducido en Noticias cuatro (TV)
* Trabajos audiovisuales para empresas utilizando animación 2D o edición de vídeo
* Diseño/guión/maquetación de libros infantiles
* Ganadora del diseño español del concurso europeo de diseño de tarjetas de World of Warcraft organizado por Blizzard.
Y como índice del curso Taller de navidad: diseño & impresión 3D tenemos:
- Repaso rápido INKSCAPE
1.1. Operaciones booleanas
1.2. trazado avanzado
1.3. Convertir trazado a objeto.
1.4. Trabajando con trayectos
1.5. Simplificar
- Ejercicio de diseño vectorial en INKSCAPE
- Modelar el diseño vectorial en 3D con FREECAD
- IMPRIMIR CON IMPRESORA 3D
NOTAS:
- Se necesitan unos conocimientos mínimos de INKSCAPE.
- Venir al curso con INKSCAPE y FREECAD ya instalados.
La información adicional que necesitas es esta:
Plazas Total: 20 (alerta, ¡son limitadas y quedan pocas!)
¿Curso Gratuito o de Pago?: GRATUÍTO gracias a SLIMBOOK.
¿Podemos retransmitirlo via streaming?: No
Localización: Linux Center (Grupo Odín). Ronda de la Química s/n Edificio ABM L’Andana, 7ª planta Frente a Parque Técnológico 46980 Paterna, Valencia
Más información: Linux Center
La entrada Taller de navidad: diseño & impresión 3D en Linux Center se publicó primero en KDE Blog.
Syslog-ng 101, part 1: Introduction
Welcome to the first part of my syslog-ng tutorial series. In this part, I give you a quick introduction what to expect from this series and try to define what syslog-ng is.
I plan to release parts of my tutorial around every week. Of course, the Christmas holidays and the upcoming conference season may cause some delays. Each part will be released as a blog accompanied by a video. It is up to you, which version you follow. However, even if you go with the video, it is worth visiting the blog: you will be able to copy and paste configuration samples from there.
You can watch the video on YouTube:
Or you can read the rest of my blog at: https://www.syslog-ng.com/community/b/blog/posts/syslog-ng-101-part-1-introduction
syslog-ng logo
Lanzada la cuarta actualización de Plasma 5.26
Tal y como estaba previsto en el calendario de lanzamiento de los desarrolladores, hoy martes 29 de novembre la Comunidad KDE ha comunicado que ha sido lanzada la cuarta actualización de Plasma 5.26. Una noticia que aunque es esperada y previsible es la demostración palpable del alto grado de implicación de la Comunidad en la mejora continua de este gran entorno de escritorio de Software Libre.
Lanzada la cuarta actualización de Plasma 5.26
No existe Software creado por la humanidad que no contenga errores. Es un hecho incontestable y cuya única solución son las actualizaciones. Es por ello que en el ciclo de desarrollo del software creado por la Comunidad KDE se incluye siempre las fechas de las actualizaciones.
De esta forma, el martes 29 de noviembre ha sido lanzada la cuarta actualización de Plasma 5.26, la cual solo trae (que no es poco) soluciones a los bugs encontrados en esta semana de vida del escritorio y mejoras en las traducciones. Es por tanto, una actualización 100% recomendable.
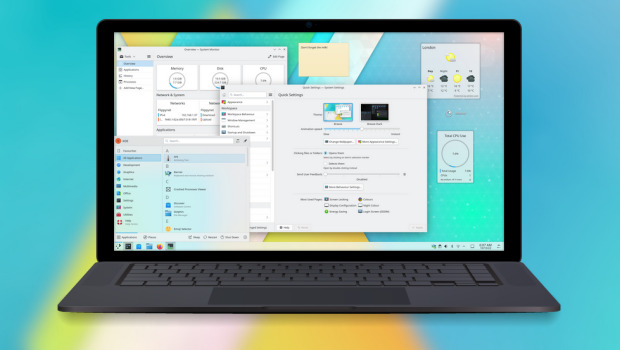
Las novedades de Plasma 5.26
La Comunidad KDE publicó el 11 de octubre Plasma 5.26, una versión que nos ofrecen un gran conjunto de novedades y propuestas que nos acercan a lo que vendrá cuando se realice la transición a Plasma 6 y que se ha centrado en los plasmoides y ha supuesto un gran paso en el desarrollo de Plasma Bigscreen.
Ya ha pasado el día de descarga y actualizaciones, y ya los estoy disfrutando en mi KDE Neon, así que os comento algunas de sus novedades:
- Posibilidad de redimensionar los plasmoides emergentes incrustados en una barra de tareas.
- Timer: nuevo plasmoide que nos sirve para tener un simple temporizador para las tareas que lo requieran o, inlcuso, asignarle acciones como ejecutar un comando.
- Añadido el navegador Aura especialmente diseñado para la pantalla grande del modo Plasma Bigscreen que destaca por tener mosaicos grandes y claramente etiquetados te permiten navegar por la red mundial con tu mando a distancia desde el sofá.
- También se une a Bigscreen Plank Player, un reproductor multimedia sencillo y fácil de usar que te permitirá reproducir vídeos desde un dispositivo de almacenamiento que conectes a tu televisor.
- Mejoras en el entorno Plasma que utiliza el servidor gráfico Wayland, el cual sigue mejroando y hace que las aplicaciones XWayland escaladas ahora se ven más hermosas, nítidas y claras.
Más información: KDE
La entrada Lanzada la cuarta actualización de Plasma 5.26 se publicó primero en KDE Blog.
Lanzada la cuarta actualización de Plasma 5.25
Tal y como estaba previsto en el calendario de lanzamiento de los desarrolladores, hoy martes 29 de novembre la Comunidad KDE ha comunicado que ha sido lanzada la cuarta actualización de Plasma 5.26. Una noticia que aunque es esperada y previsible es la demostración palpable del alto grado de implicación de la Comunidad en la mejora continua de este gran entorno de escritorio de Software Libre.
Lanzada la cuarta actualización de Plasma 5.26
No existe Software creado por la humanidad que no contenga errores. Es un hecho incontestable y cuya única solución son las actualizaciones. Es por ello que en el ciclo de desarrollo del software creado por la Comunidad KDE se incluye siempre las fechas de las actualizaciones.
De esta forma, el martes 29 de noviembre ha sido lanzada la cuarta actualización de Plasma 5.26, la cual solo trae (que no es poco) soluciones a los bugs encontrados en esta semana de vida del escritorio y mejoras en las traducciones. Es por tanto, una actualización 100% recomendable.
Las novedades de Plasma 5.26
La Comunidad KDE publicó el 11 de octubre Plasma 5.26, una versión que nos ofrecen un gran conjunto de novedades y propuestas que nos acercan a lo que vendrá cuando se realice la transición a Plasma 6 y que se ha centrado en los plasmoides y ha supuesto un gran paso en el desarrollo de Plasma Bigscreen.
Ya ha pasado el día de descarga y actualizaciones, y ya los estoy disfrutando en mi KDE Neon, así que os comento algunas de sus novedades:
- Posibilidad de redimensionar los plasmoides emergentes incrustados en una barra de tareas.
- Timer: nuevo plasmoide que nos sirve para tener un simple temporizador para las tareas que lo requieran o, inlcuso, asignarle acciones como ejecutar un comando.
- Añadido el navegador Aura especialmente diseñado para la pantalla grande del modo Plasma Bigscreen que destaca por tener mosaicos grandes y claramente etiquetados te permiten navegar por la red mundial con tu mando a distancia desde el sofá.
- También se une a Bigscreen Plank Player, un reproductor multimedia sencillo y fácil de usar que te permitirá reproducir vídeos desde un dispositivo de almacenamiento que conectes a tu televisor.
- Mejoras en el entorno Plasma que utiliza el servidor gráfico Wayland, el cual sigue mejroando y hace que las aplicaciones XWayland escaladas ahora se ven más hermosas, nítidas y claras.
Más información: KDE
La entrada Lanzada la cuarta actualización de Plasma 5.25 se publicó primero en KDE Blog.
Perjuangan Mencapai Cita-Cita
Kemarin sore saya buru-buru pulang setelah menjemput Vivian dari sekolah. Cuaca mendung gelap dan kelihatannya akan hujan lebat. Daripada terjebak kemacetan, lebih baik sampai di rumah lebih awal dan bisa mempersiapkan diri untuk kuliah Business Intelligence.
Sambil ngabuburit dan mempersiapkan diri untuk kuliah, saya mengecek email dan group chat kuliah. Banyak yang terjebak kemacetan karena hujan dan banjir. Salah satu teman kuliah yang bekerja di salah satu lembaga pemerintah malah info, motornya mogok karena mencoba menerobos banjir setinggi dengkul.
“Menyesal malah pulang, tau gitu kuliah di kantor tadi🥲”, gitu katanya. Saya bilang bahwa ya kita nggak pernah tahu keputusan mana yang paling baik. Sewaktu memutuskan pulang menerobos hujan, itu kan sebenarnya diniatkan untuk hal yang baik, agar bisa kuliah online dari rumah dengan suasana nyaman dan tenteram. Kalau kuliah online di kantor, selesai jam 9 malam dan harus pulang ke rumah. Besok pagi sudah kembali lagi ke kantor. Rasa lelahnya belum hilang.
Karena motornya mogok, akhirnya teman-teman satu group kuliah menyarankan ia bersantai dulu. Minum teh panas dulu karena kebetulan ia berhenti dan menunggu di warung makan. Daripada menyesali keputusan dan sewot karena ada hal-hal yang tidak berjalan sesuai keinginan.
Akhirnya ada ibu-ibu baik hati yang membantunya menyalakan motor dan ia bisa sampai ke rumah tepat sebelum kuliah Business Intelligence dimulai.
Kadang kita kerap menyesali keputusan yang kita ambil karena kita terbebani dengan keputusan tersebut. Misalnya keputusan untuk mengambil kuliah, otomatis ada beban tugas kuliah, beban presentasi, beban mengatur waktu antara pekerjaan, keluarga dan kuliah.

Ada juga yang kuliah sambil kerja. Di pekerjaan kadang mendapatkan situasi yang tidak enak, ditambah dengan beban kuliah pula. Belum lagi yang kuliah sambil kerja dan sudah berkeluarga. Jadi tambah tanggung jawab dan kegiatannya.
Tapi justru disitu perbedaannya. Disitu letak perjuangannya. Apakah kita bisa melakukan manajemen pribadi agar bisa mengatasi masalah tersebut. Apakah kita mau belajar untuk membagi waktu agar ada keseimbangan diantara kegiatan yang kita lakukan.
Kalau kita sudah memutuskan untuk kuliah, dicamkan didalam hati agar kuliahnya bisa diselesaikan. Mungkin kita jadi kurang tidur, karena harus mengerjakan tugas malam-malam. Mungkin kita jadi tidak bisa liburan, karena waktunya sempit dan banyak kegiatan yang harus dilakukan. Mungkin kita tidak punya waktu untuk melakukan hal-hal yang kita senangi.
Itu hal wajar. Mau tidak mau kita memang harus berkorban. Bisa berkorban waktu, tenaga maupun biaya. Justru karena berkorban itu, makanya jangan sampai gagal.
Di Excellent dan Aktiva, saya meminta staff untuk membuat laporan harian secara rutin. Setiap sore. Mungkin ini jadi tambahan pekerjaan meski harusnya tidak sulit-sulit amat. Laporan harian itu semacam resume apa saja yang dilakukan sehari itu.
Sebagai staff, saya bisa saja punya banyak alasan untuk tidak melakukan tugas tersebut. Namun saya juga tidak bisa berargumentasi jika dari sekian banyak staff, hanya saya yang tidak bisa mengirimkan laporan secara periodik sesuai yang diminta.
Analoginya sama seperti tugas kuliah. Mata kuliah Business Intelligence meminta semua mahasiswa untuk menyiapkan final assignment berupa analisa data, implementasi (application) dan improvementnya. Silakan buat sebaik mungkin, minggu depan harus siap dipresentasikan.
Kalau ada tugas seperti itu, apa saya harus berdebat dengan dosen bahwa saya tidak punya basic pengetahuan untuk materinya? Apa saya harus berdebat dengan dosen bahwa saya belum siap? Bahwa saya banyak tugas lain dari mata kuliah Ubiquitous Computing, Research Methodology dan IT Forensics? Kan nggak.
Dosen sudah memberikan tugas, ya tugas saya untuk menyelesaikannya. Kalau untuk menyelesaikan tugas itu saya harus membagi waktu dengan cermat antara pekerjaan di kantor, urusan keluarga dan urusan bisnis, ya saya harus bisa membaginya. Kalau untuk menyelesaikannya saya harus mengerjakan malam-malam sehingga waktu tidur berkurang ya saya harus melakukannya. Jika karena tugas saya terpaksa tidak liburan, tidak ke rumah kabin, tidak ke kebun Zeze Zahra, tidak bisa nonton Netflix, tidak bisa melihat Curiosity Stream, ya itu harga yang harus dibayar. Itu pengorbanan bentuk kecil yang harus saya lakukan.
Banyak para dosen dan mahasiswa yang kuliah terpisah jauh dari tempat tinggal. Banyak dari mereka yang menempuh pendidikan di luar negeri, jauh dari keluarga dan sanak saudara. Dengan budget terbatas, mungkin adakalanya timbul perasaan lonely dan nelangsa, apalagi jika lingkungan juga bukan seperti lingkungan di Indonesia yang sudah familiar. Justru hal-hal seperti itu yang bisa mendewasakan kita dan membuat kita belajar menghargai apa-apa yang selama ini kita anggap sepele. Saya selalu kagum pada para mahasiswa yang harus berjuang seperti itu untuk bisa mencapai yang dicita-citakan. Hal-hal yang tidak enak cukup ditelan, untuk nantinya diceritakan pada anak bahwa kita pernah harus berjuang sedemikian rupa agar bisa sampai di tujuan yang diharapkan.
Kalau kita yang kuliah bisa ulang-alik setiap hari, kuliah bisa online sambil ngemil dan bersantai, kuliah dengan budget yang lebih dari cukup dan kemudian mengeluhkan pengorbanan yang harus dilakukan, gimana kalau kita sampai ditest pada situasi yang lebih berat seperti mereka? Apa kita harus jejeritan di tengah malam karena stress pada beban yang kita anggap sangat berat?
Hal-hal seperti itu yang membuat saya bersemangat untuk bisa belajar mengatur waktu dan menyelesaikan tugas sebagaimana mestinya. Karena itu tugas dan saya harus menyelesaikannya sebaik mungkin.
Pada akhirnya, hidup kita milik kita, susah maupun senang, kita juga yang menjalaninya.
Lanzada la cuarta actualización de Plasma 5.26
Tal y como estaba previsto en el calendario de lanzamiento de los desarrolladores, hoy martes 29 de novembre la Comunidad KDE ha comunicado que ha sido lanzada la cuarta actualización de Plasma 5.26. Una noticia que aunque es esperada y previsible es la demostración palpable del alto grado de implicación de la Comunidad en la mejora continua de este gran entorno de escritorio de Software Libre.
Lanzada la cuarta actualización de Plasma 5.26
No existe Software creado por la humanidad que no contenga errores. Es un hecho incontestable y cuya única solución son las actualizaciones. Es por ello que en el ciclo de desarrollo del software creado por la Comunidad KDE se incluye siempre las fechas de las actualizaciones.
De esta forma, el martes 29 de noviembre ha sido lanzada la cuarta actualización de Plasma 5.26, la cual solo trae (que no es poco) soluciones a los bugs encontrados en esta semana de vida del escritorio y mejoras en las traducciones. Es por tanto, una actualización 100% recomendable.
Las novedades de Plasma 5.26
La Comunidad KDE publicó el 11 de octubre Plasma 5.26, una versión que nos ofrecen un gran conjunto de novedades y propuestas que nos acercan a lo que vendrá cuando se realice la transición a Plasma 6 y que se ha centrado en los plasmoides y ha supuesto un gran paso en el desarrollo de Plasma Bigscreen.
Ya ha pasado el día de descarga y actualizaciones, y ya los estoy disfrutando en mi KDE Neon, así que os comento algunas de sus novedades:
- Posibilidad de redimensionar los plasmoides emergentes incrustados en una barra de tareas.
- Timer: nuevo plasmoide que nos sirve para tener un simple temporizador para las tareas que lo requieran o, inlcuso, asignarle acciones como ejecutar un comando.
- Añadido el navegador Aura especialmente diseñado para la pantalla grande del modo Plasma Bigscreen que destaca por tener mosaicos grandes y claramente etiquetados te permiten navegar por la red mundial con tu mando a distancia desde el sofá.
- También se une a Bigscreen Plank Player, un reproductor multimedia sencillo y fácil de usar que te permitirá reproducir vídeos desde un dispositivo de almacenamiento que conectes a tu televisor.
- Mejoras en el entorno Plasma que utiliza el servidor gráfico Wayland, el cual sigue mejroando y hace que las aplicaciones XWayland escaladas ahora se ven más hermosas, nítidas y claras.
Más información: KDE
La entrada Lanzada la cuarta actualización de Plasma 5.26 se publicó primero en KDE Blog.
Pemanis Buatan, Kadar Garam dan Pengajian
Di lingkungan rumah tinggal orang tua saya di Tambun maupun di lingkungan sekitar rumah kabin Zeze Zahra di Batujaya Karawang, saya menemukaan kenyataan hidup yang hampir mirip. Banyak warga yang mengalami sakit diabetes, darah tinggi dan stroke.
Kehidupan yang tidak mudah membuat hal tersebut lebih menyesakkan. Uang pendapatan sehari-hari yang seharusnya bisa digunakan untuk keperluan kebutuhan pokok dan pendidikan jadi tersedot untuk biaya pengobatan.
Pola hidup sehat mungkin jarang menjadi pertimbangan. Kita saja yang mungkin bekerja rutin setiap hari kerap mengabaikan pola hidup sehat, apalagi bagi keluarga yang memiliki sedikit pilihan, hanya bisa makan apa yang tersedia.
Itu sebabnya jadi banyak yang mengulang siklus yang sama dari waktu ke waktu. Jadi turun temurun. Sekolah sampai tingkat SLTA saja atau bahkan lebih rendah, kemudian bekerja sebagai buruh atau bekerja serabutan, berkeluarga dan mengulang siklus yang sama. Hanya sedikit yang bisa keluar dari lingkaran tersebut.

Saat menghadiri pemakaman salah satu warga yang berpulang karena sakit, saya bicara ke adik saya Mardalih yang mengurus Yayasan Ultima Insani Madania. Saya sampaikan padanya bahwa ada baiknya yayasan menjalankan program tambahan, misalnya membantu keluarga yang terkena musibah. Memfasilitasi pembelian kain kafan, membantu proses penggalian kubur hingga membantu hal lain terkait pemakaman.
Karena pernah mengalami sendiri kehilangan anggota keluarga, saya merasakan bahwa jika terkena musibah kadang kita sulit berpikir dengan jernih. Bantuan dari orang lain untuk mengurus hal tersebut tentu akan sangat meringankan beban keluarga yang terkena musibah.
Di perkotaan dan di perumahan, biasanya sudah ada lembaga keagamaan atau yayasan yang mengurus hal tersebut, namun di perkampungan seperti di tempat tinggal keluarga di Tambun Bekasi dan di Batujaya Karawang, proses itu masih mengandalkan gotong royong keluarga dan warga sekitar.
Yayasan Ultima Insani Madania merupakan yayasan yang bergerak dibidang pendidikan, kesehatan dan pemberdayaan masyarakat. Dibiayai dari CSR (Corporate Social Responsibility) PT Excellent Infotama Kreasindo dan PT Aktiva Kreasi Investama dan dari donasi individu warga masyarakat.
Sesuai misinya, saya berharap yayasan Ultima bisa menjadi pihak yang memberdayakan masyarakat baik terkait pengurusan bagi yang berduka cita maupun dalam bentuk edukasi.
Setiap malam biasanya ada pengajian anak-anak dan setiap minggu ada pengajian ibu-ibu. Saya mengusulkan pada pengurus agar 1x dalam sebulan, ada sisipan di pengajian ibu-ibu, berupa edukasi dari tenaga kesehatan (dokter atau bidan) mengenai pola hidup sehat. Misalnya mengenai saran menghindari minuman dengan pemanis buatan, mengurangi konsumsi gula maupun garam.
Ada beberapa rekan saya yang berprofesi sebagai tenaga kesehatan dan saya bisa minta bantuannya untuk memberikan edukasi dalam bahasa sederhana dan mudah dimengerti.
Selain edukasi ke ibu-ibu, hal yang mirip nantinya dilakukan juga terhadap anak-anak. Agar ada kesinambungan pemahaman dan ada inisiatif untuk mulai hal yang benar. Meski mungkin hasilnya belum signifikan, saya berharap apa yang dilakukan bisa membekas dan bisa membawa dampak berkelanjutan.
Sama seperti saat membangun Excellent maupun rumah kabin Zeze Zahra, saya tidak tahu apakah inisiatif ini bisa berkembang ke arah yang lebih luas atau tidak, namun bagi saya sepanjang hal itu baik untuk dilakukan, ya dilakukan saja. Nanti sambil belajar dari pihak lain yang sudah berpengalaman dan sekaligus mereview apa yang sudah dilakukan.
Sumber gambar : Tien Vu (Pixabay)
Battery Bar – Plasmoides de KDE (212)
Hoy os presento Battery Bar, el plasmoide de KDE número 212 de la gran serie de los mismos mostrados en el blog y que nos ofrece un widget informativo sobre el estado de la barería de nuestro dispostivo
Battery Bar – Plasmoides de KDE (212)
De plasmoides tenemos de todo tipo funcionales, de configuración, de comportamiento, de decoración o, como no podía ser de otra forma, de información sobre nuestro sistema como puede ser el uso de disco duro, o de memoria RAM, la temperatura o la carga de uso de nuestras CPUs.
A todos ellos se les une otro plasmoide creado por lonelytrainsistor que añade una barra de batería a un panel orientado horizontalmente en KDE Plasma.
En realidad, el applet añade dos barras de batería a un panel:
- barra principal (verde por defecto) – llena la pantalla en función del porcentaje de energía que queda en la batería,
- barra auxiliar (roja por defecto) – su longitud representa el porcentaje de batería que se utilizará durante la próxima hora (por defecto) con el consumo de energía actual.

Además, este plasmoide tiene otras características visuales como:
- cuando la batería se está cargando la barra principal respira lentamente de vez en cuando,
- cuando el cargador está desconectado se mostrarán varias burbujas que escapan de la barra principal hacia la derecha,
- cuando el cargador está conectado, un rápido destello brillante recorrerá la barra principal de izquierda a derecha.
Y como siempre digo, si os gusta el plasmoide podéis “pagarlo” de muchas formas en la nueva página de KDE Store, que estoy seguro que el desarrollador lo agradecerá: puntúale positivamente, hazle un comentario en la página o realiza una donación. Ayudar al desarrollo del Software Libre también se hace simplemente dando las gracias, ayuda mucho más de lo que os podéis imaginar, recordad la campaña I love Free Software Day 2017 de la Free Software Foundation donde se nos recordaba esta forma tan sencilla de colaborar con el gran proyecto del Software Libre y que en el blog dedicamos un artículo.
Más información: KDE Store
¿Qué son los plasmoides?
Para los no iniciados en el blog, quizás la palabra plasmoide le suene un poco rara pero no es mas que el nombre que reciben los widgets para el escritorio Plasma de KDE.
En otras palabras, los plasmoides no son más que pequeñas aplicaciones que puestas sobre el escritorio o sobre una de las barras de tareas del mismo aumentan las funcionalidades del mismo o simplemente lo decoran.
La entrada Battery Bar – Plasmoides de KDE (212) se publicó primero en KDE Blog.
Webminars de la asociación Dédalo sobre la Semana del software libre
La Fundación Dédalo lleva desde el año 2006 dando a conocer el Software Libre y las diferentes alternativas disponibles en el mercado. Este es el objetivo con el que se ha programado la Semana del Software Libre.

La fundación Dédalo desde Navarra en España, pone en marcha unos seminarios a los que se puede asistir previa reserva en su web, donde nos enseñarán el uso de diversas herramientas de software libre.
En concreto serán los días 29 y 30 de noviembre y 1 de diciembre de 2022.
Los objetivos que se pretenden conseguir con esta nueva edición (la que hace ya la número XVII) son:
- Divulgar y dar a conocer los programas de Software Libre de uso más común.
- Fomentar el uso del Software Libre, tanto en el ámbito doméstico como en el profesional, mostrando las ventajas e inconvenientes de este tipo de soluciones.
- Mostrar las similitudes en las formas de trabajar entre diferentes sistemas libres y privativos, demostrando su eficacia como alternativas completas, prácticas y útiles.
- Acercar a las empresas TIC de la Ribera tecnologías libres de desarrollo de primer nivel.
29 de noviembre de 2022
Correo electrónico libre con Thunderbird.
Aprende a manejar tus cuentas de correo electrónico personales y profesionales con Thunderbird, el cliente de correo electrónico libre más usado.
Asistencia gratuita, previa inscripción en nuestro teléfono 948 088 044, desde su web haciendo clic aquí.
Inscripción online: pincha aquí
30 de noviembre de 2022
Reutiliza tu viejo PC con GNU/Linux
Aprende a instalar un sistema operativo Linux en tu PC y vuelve a darle utilidad como cuando lo compraste. Conoce los mejores sistemas operativos para equipos antiguos.
Asistencia gratuita, previa inscripción en nuestro teléfono 948 088 044, desde su web haciendo clic aquí
Inscripción online: pincha aquí
1 de diciembre de 2022
OBS: Streaming con software libre
En este Webinar veremos y conoceremos una de las herramientas Software Libre más utilizadas para realización de streamings y grabación de vídeos, OBS Studio. Un software que está siendo más usado cada día (incluso por profesionales del sector audiovisual) y tiene multitud de funcionalidades como: streaming (en multitud de plataformas), grabación, escenas, múltiples fuentes de audio y vídeo, mejora de sonido, plugins… etc. Resuelve tus dudas.
Asistencia gratuita, previa inscripción en nuestro teléfono 948 088 044 o desde su web haciendo clic aquí
Inscripción online: pincha aquí

Si te interesan los temas y tienes disponibilidad, no dudes en inscribirte y asistir.

Tumbleweed to Roll Out Mitigation Plan, Advance Microarchitecture
A mitigation plan for a microarchitecture level change and information about advancing openSUSE’s rolling release Tumbleweed to an x86-64-v2 microarchitecture kicked off a significant move forward for the project this week.
Tumbleweed and openSUSE other distributions are built for old x86-64-v1 hardware and transitioning to x86-64-v2 will require community efforts to support users with hardware that can’t make the transition to the microarchitecture.
The “openSUSE Factory repository is repurposed to move forward with x86-64-v2,” wrote Tumbleweed release manager Dominique Leuenberger in an email to the openSUSE Factory mailing list. A new repository “will be set up as openSUSE Factory currently exists today. This change is necessary to align with the SUSE factory first policy to keep aligned with the project’s sponsor’s development efforts.
That new repository looks like it will be named openSUSE:Factory:LegacyX86 and volunteers would be needed to maintain aspects of the repository designed for x86-64-v1 users.
“I’ll help with the initial setup (incl openQA) but, once running, expect not to touch this anymore (unless the people opting to take care ask for specific help),” Leuenberger wrote in a reply. “I expect installer ISO files, but I’d not expect live” images.
People attending openSUSE’s open release engineering meeting discussed the topic and came up with an action plan.
The discussed and agreed upon solution forward is repurposing Tumbleweed’s main repository to x86-64-v2 like ALP will be upon its release. The i586 support will be dropped from the repository and only -32bit parts that are necessary for specific packages will exist, but no complete repository will exist for -32bit. Users will not need to do anything other than to zypper dup when the repository transitions to x86-64-v2, but a notification for this change is expected to be sent to users.
As for the users of the legacy systems who remain on x86-64-v1, action will be necessary. The repository list will need to be updated from download.opensuse.org/tumbleweed/repo/oss to something like download.opensuse.org/ports/legacyx86/tumblewed/repo/oss.
“With this solution, we provide benefits to users of more recent machines than that of V1 by using the newer CPU instructions,” he wrote. “Yet this provides a path for users to still run Tumbleweed on machines that might not have the needed hardware.”
To check the hardware for those running Tumbleweed, users can use the following command in a terminal.
/lib64/ld-linux-x86-64.so.2 --help
Results should likely result in the following:
x86-64-v4
x86-64-v3 (supported, searched)
x86-64-v2 (supported, searched)
“Once the new intel port repository is ready, I’ll let you know the exact location of it,” Leuenberger emphasized in the email “We can expect for these changes to take place in the first quarter of the new year of 2023.”
A recent poll on openSUSE’s Twitter found that 51 percent of poll respondents had an understanding of microarchitecture levels and the benefits it brings to developers and infrastructure optimization.
For more information, follow the discussion on the openSUSE Factory mailing list.