
 Member
Member DimStar
DimStaropenSUSE Tumbleweed – Review of the week 2022/48
Dear Tumbleweed users and hackers,
There seems to be no stopping Tumbleweed. It has again been rolling at full speed, with 7 snapshots (1125…1201) released this week. As usual, some smaller, some larger ones.
Let’s dive right in and see what changes have been delivered:
- Icewm 3.2.2
- VLC 3.0.18
- Ruby 3.1.3: There was an issue that ruby extensions are newly looked for in vendor_ruby/3.1.0/x86_64-linux-gnu, where the ‘-gnu’ part is new. All ruby packages in Tumbleweed have been rebuilt to follow this change
- SQLite 3.40.0
- Meson 0.64.1
- Python setuptools 65.6.3
- gawk 5.2.1
- libgcrypt 1.10.1: MD5 is disallowed in FIPS mode now
- Systemd 252.2
- LibreOffice 7.4.3RC2
- Bash 5.2.12
- KDE Plasma 5.26.4
- Cryptsetup 2.6.0
- Linux kernel 6.0.10
- Tcl/Tk 8.6.13
- ffmpeg has been switched to use version 5.x by default; ffmpeg-4 is still available and used by some packages
As that list got so long, it’s no surprise that the staging projects do not carry a lot of changes to be tested at the moment – not a lot, but still some, namely:
- rubygem-rspec 3.12.0: The remaining YaST fixes have been incoming and if nothing new comes up, this should be shipped next week
- Podman 4.3.1: fails the openQA tests
- Python pytest 7.2.0
- Switch to openSSL 3: tracked in Staging:N, main failures are nodejs18, nodejs19, openssh, mariadb
And I’m sure we will see many more changes that developers and packagers are currently preparing, but that has not yet been submitted.
Ubuntu用のバイナリをopenSUSE で動かす
この記事は openSUSE Advent Calendar 2022 の3日目です。
メーカー製のプロダクトの一部には、Windows/Mac だけではなくて Linux 向けの物を用意している場合があります。しかし、たまたま使おうとしたものが、Ubuntu 向けしかありませんでした。
そこで、Ubuntu 向けのバイナリ(dpkg として提供されている物) が openSUSE で動くかどうかを試してみました。
結論から言うと、できます。しかもやり方は難しくありません。
まず、Ubuntu 上で、openSUSE で動かしたいバイナリ(dpkg) をインストールします。この時、どこにインストールされたかを控えておきます。dpkg -deb -c dpkg名 とすれば一覧が表示されます。
次に、インストールされたファイルを全部まとめて openSUSE 側に持って行き、展開します。その後、展開したファイル中にあるターゲットのプログラムを起動すれば動作します。
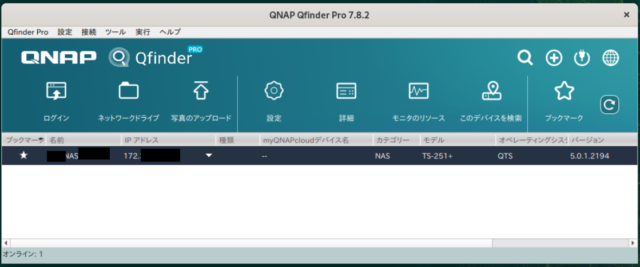
たとえば、QNAP が提供している、QNAP NAS 一覧を表示したり、ログインしたりするためのツール QFinderPro で試してみましょう。Ubuntu 上では、dpkg の内容は
$ dpkg-deb -c QNAPQfinderProUbuntux64-7.8.2.0928.deb drwxrwxr-x qnap/qnap 0 2022-09-28 18:55 ./ drwxrwxr-x qnap/qnap 0 2022-09-28 18:55 ./usr/ drwxrwxr-x qnap/qnap 0 2022-09-28 18:55 ./usr/local/ drwxrwxr-x qnap/qnap 0 2022-09-28 18:55 ./usr/local/bin/ drwxrwxr-x qnap/qnap 0 2022-09-28 18:55 ./usr/local/bin/QNAP/ drwxrwxr-x qnap/qnap 0 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/ drwxrwxr-x qnap/qnap 0 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/ -rw-rw-r-- qnap/qnap 5587 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/cs.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 6546 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/da.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 5731 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/de.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 13337 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/el.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 5497 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/en.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 5847 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/es.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 6431 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/fi.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 5945 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/fr.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 6025 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/hu.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 5752 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/it.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 6276 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/ja.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 38927 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/ko.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 6498 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/nl.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 6454 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/nn.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 5714 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/pl.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 5700 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/pt.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 5716 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/ro.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 7367 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/ru.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 6516 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/sv.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 8952 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/th.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 5696 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/tr.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 5093 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/zhcn.UEPConsentForm.htm -rw-rw-r-- qnap/qnap 6582 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/Docs/zhtw.UEPConsentForm.htm drwxrwxr-x qnap/qnap 0 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/License/ -rw-rw-r-- qnap/qnap 94964 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/License/QfinderThirdPartySoftwareNotices.htm -rwxrwxr-x qnap/qnap 20314824 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/QfinderPro -rwxrwxr-x qnap/qnap 274 2022-09-28 18:55 ./usr/local/bin/QNAP/QfinderPro/QfinderPro.sh (以下略)
となっています。ですので、/usr/local/bin/QNAP 配下やその他を何らかの手段で openSUSE 側に持って行き、展開します。あとは、 /usr/local/bin/QNAP/QfinderPro/QfinderPro.sh を実行すれば、Ubuntu 向けとして提供されているプログラムが openSUSE でも動きます。
Campaña de recaudación de fondos para KDE 2022
Hace una semana, la Comunidad KDE hizo mofa del Black Friday y lo convirtió en el Blue Friday, iniciando de forma diferente la campaña de recaudación de fondos para KDE 2022 en la que se intenta asegurar el desarrollo de un proyecto que crece y crece ofreciendo a todo el mundo de forma totalmente gratuita a todos los niveles (monetario, datos, libertad, etc) Software de calidad.
Campaña de recaudación de fondos para KDE 2022
Donar a proyectos abiertos es una de las formas de colaborar más sencillas en el desarrollo de estas iniciativas. Y es que debemos tener claro que gran parte del Software Libre es gratuito pero implica unos gastos básicos, por ejemplo, en cuanto a servidores. Además, si queremos calidad y que se tenga garantías de desarrollo los usuarios, o gran parte de estos, deben colaborar de alguna forma en su desarrollo. Creo que es un buen momento para invitaros a leer este artículo ya algo viejo que publiqué en su día en este humilde blog.
De esta forma, y una vez iniciada la campaña del Blue Friday ésta continúa en forma de la campaña de recaudación de fondos para KDE para que la Comunidad KDE siga creciendo y ofreciendo más y más software de calidad de forma gratuita, tanto de forma monetaria como en forma de datos personales.

En palabras de los desarrolladores:
Tu donación permite a KDE seguir desarrollando el espectacular escritorio Plasma y todas las aplicaciones que necesitas para la educación, la productividad y el trabajo creativo.
Tu donación también ayuda a pagar los servidores que alojan el código de KDE, los sitios web y los canales de chat y videoconferencia que los colaboradores de KDE utilizan para comunicarse entre sí. Además, ayuda a pagar los sprints de desarrollo y la conferencia anual Akademy.
KDE quiere ser capaz de ofrecer a los usuarios y a los miembros de la comunidad mejores servicios y apoyo. Tu donación también ayuda a KDE a proporcionar empleo a las personas que pueden ayudar a que esto suceda.
Tu donación también beneficia al resto de la humanidad. Con ella, KDE tiene los recursos para promover un espectacular catálogo de Software Libre a profesionales, artistas, desarrolladores de software, niños, instituciones públicas, organizaciones sin ánimo de lucro y empresas de todo el mundo.

Tu donación también apoya al propio movimiento del Software Libre. KDE puede adoptar y alimentar nuevos proyectos, ayudándolos a alcanzar la madurez, y ayudando a los nuevos contribuyentes a formar parte de la comunidad del Software Libre con una carrera en la tecnología ética.
Y si eres un desarrollador, puedes beneficiarte de las herramientas y marcos de trabajo de KDE. Las bibliotecas de KDE hacen que sea rápido y fácil construir aplicaciones sofisticadas para todas las plataformas.
El objetivo es llegar a 20.000 €, una cantidad creo que ridícula para todo el gran Software de Calidad que la Comunidad KDE ofrece. En el momento de escribir este artículo se lleva un 25% del mismo… espero que pronto se llegue al 100%.
Yo ya he donado, como suelo donar a otros proyectos como Wikipedia, OpenClipart, Gimp o Inkscape… y creo que esto debería hacerse público para ir mentalizando al resto de usuarios que una cosa es que sea gratis y otra es que no colabores en nada en su desarrollo.
La entrada Campaña de recaudación de fondos para KDE 2022 se publicó primero en KDE Blog.
Portal Perumahan
Saat pandemi covid di awal tahun 2020, banyak perumahan dan lingkungan tempat tinggal yang memportal jalan-jalan. Baik jalan gang maupun jalan yang agak besar. Hanya jalan utama yang tidak diportal. Hal ini hampir merata di semua perumahan, bukan hanya perumahan tempat saya tinggal.
Perasaan takut pada penyebaran covid ditambah lagi dengan alasan keamanan membuat pemasangan portal itu dimaklumi. Meski hal itu jadi merepotkan banyak orang. Warga perumahan sendiri kerepotan karena harus memutar jauh, apalagi bagi para ojek online yang kadang tidak tahu jalur mana yang diportal dan jalur mana yang bisa dilewati.
Kini, setelah pandemi mereda dan kehidupan sosial berangsur kembali normal, banyak dari portal-portal itu yang tetap dikunci, tidak dibuka-buka. Alasan bisa banyak dicari, tapi bagi banyak orang, alasan satu-satunya adalah karena sudah merasa nyaman begitu. Jalanan jadi sepi, tidak ada lalu lalang kendaraan dan bisa lebih bebas ngapain saja di jalan yang diportal tersebut.
Masalahnya, itu jadi zalim pada orang lain. Itu kan jalan umum, bukan jalan pribadi. Jalan umum, apalagi jika jalan itu cukup besar dan sering dilalui oleh orang lain seharusnya ya dibuka jika kondisinya sudah memungkinkan. Kalau saya tinggal di lingkungan yang sama, mungkin saya enak-enak saja menikmati kenyamanan berkat jalan yang diportal, tapi kan itu sama saja saya memanfaatkan fasilitas umum untuk kepentingan pribadi.
Mengapa jalan diportal terus-terusan tanpa pernah dibuka, karena jalan yang tertutup katanya lebih aman buat anak-anak yang bermain. Tapi kan jalan itu diciptakan bukan buat anak-anak bermain melainkan untuk lalu lalang. Bisa saja digunakan untuk bermain diwaktu sore, tapi itupun kalau jalannya memang jalan gang yang relatif jarang dilalui kendaraan.
Saya kerap melihat banyak juga yang parkir kendaraan terus menerus setiap hari, sampai memagari mobilnya dengan pot bunga supaya tidak terserempet mobil yang lewat. Dengan memportal jalan dan tidak pernah membukanya, yang bersangkutan bisa bebas parkir mobil didepan rumah seterusnya, setiap hari, setiap waktu.
Tapi kembali lagi ke awal, masalahnya itu jalan umum. Fasilitas umum. Tidak selayaknya digunakan seperti itu properti pribadi. Jika terpaksa digunakan karena situasi tertentu dan itupun terkait kepentingan umum (misalnya untuk TPS pemilihan umum) itu masih bisa dimaklumi, apalagi sifatnya situasional pula.
Saya pribadi sering merasa bersalah jika sementara waktu parkir mobil di depan rumah. Meski sudah mepet sekali ke pinggir, sudah memperhitungkan jalur yang lewat tidak terganggu dan sifatnya hanya sementara waktu (misalnya menunggu Vivian saat hendak diantar ke sekolah atau saat hendak dijemput dari sekolah), saya tetap merasa bersalah dan sedapat mungkin menghindari hal itu.
Saya memang sengaja mengontrak rumah terpisah, khusus untuk parkir mobil Bumblebee sekaligus bisa dimanfaatkan untuk tempat tinggal keponakan. Jadi kami bisa berbagi biaya sewa. Saya bisa bolak-balik ke tempat menaruh mobil dengan sepeda atau motor listrik, jadi bisa sekalian olah raga dan bersantai juga.
Saya berpikir, tidak ada faedahnya juga jika kita menyerobot fasilitas umum untuk kepentingan pribadi kita. Apalagi jika itu merugikan pihak lain. Rasanya juga jadi tidak berkah buat kehidupan kita. Sedapat mungkin kita usahakan untuk menghindari penggunaan fasilitas umum untuk kepentingan pribadi.
Apakah ada yang punya pengalaman mirip?
Disponible Plasma Mobile Gear 22.11
Hoy toca hablar de que está disponible, desde el 30 de noviembre Plasma Mobile Gear 22.11, la colección de aplicaciones especialmente diseñadas para dispositivos móviles. Hagamos una breve reseña del lanzamiento a la espera de entrar en harina.
¿Qué es Plasma Mobile?

Para los que no lo conozcan Plasma Mobile es la alternativa libre a interfaz gráfica para smartphones de la Comunidad KDE, hablé de él hace un tiempo y, poco a poco, se está convirtiendo en un clásico del blog.
Su idea es muy simple, tras conquistar tu escritorio KDE la Comunidad también quiere conquistar tu teléfono móvil… aunque todavía lo tenga complicado por todas las limitaciones de hardware que todavía tiene este campo de la tecnología.
No obstante, confiemos que de igual forma se han ido conquistando los ordenadores de sobremesa, portátiles y servidores, lleguemos un día que podamos tener libertad total en nuestros smartphones.
Y para cuando eso ocurra la Comunidad KDE estará preparada para ello y por eso está confeccionando un catálogo más que decente de aplicaciones con tecnología adaptativa.
Disponible Plasma Mobile Gear 22.11
Este 30 de noviembre Plasma Mobile Gear ha lanzado su versión 22.11, la cual llega con muchas novedades, aunque la principal viene de un cambio en la forma de realizar sus lanzamientos.
Según los desarrolladores:
Hemos decidido migrar los lanzamientos de las aplicaciones de Plasma Mobile a KDE Gear, empezando por KDE Gear 23.04. Esto significa que Plasma Mobile Gear será descontinuado en el futuro, y las aplicaciones de Plasma Mobile seguirán el calendario de lanzamientos de la mayoría de las otras aplicaciones de KDE, simplificando el empaquetamiento. Para preparar esto, se ha hecho un esfuerzo continuo para asegurar que todas las aplicaciones tengan creadas las categorías de Bugzilla adecuadas.
Así que os invito a leer las futuras entradas dondee comentaremos las novedades de este lanzamiento que da fin a una nomenclatura, a la espera de poder realizar un articulo más completo.
La entrada Disponible Plasma Mobile Gear 22.11 se publicó primero en KDE Blog.

Nano, VirtualBox update in Tumbleweed
A steady pace of openSUSE Tumbleweed snapshots arrived to users this week and there were tons of conversation on the openSUSE Factory mailing list regarding plans to advance the rolling release’s microarchitecture and discussions about the mitigation plan/call for help.
The changes to x86-64-v2 are expected to take place in the first quarter of the 2023 new year and forthcoming changes will be communicated on both the mailing list and blog.
A single package arrived in snapshot 20221128. The Skype plugin for chat client Pidgin, skype4pidgin, updated to version 1.7. The plugin fixed the loss of admin rights when joining a room, problems with file transfers through the client and issues where people were not appearing as being online.
An update of gawk 5.2.1 arrived in snapshot 20221127. The utility fixed issues with the debugger, dropped a few patches and addressed some subtle issues with untyped array elements being passed to functions. The general purpose cryptographic library package libgcrypt, which is based on code from GnuPG, updated to version 1.10.1 and fixed minor memory leaks. The package was updated to improve support for PowerPC architectures and it added the hardware optimizations configuration file hwf.deny to the /etc/gcrypt/ directory. There was also a git+ update of kdump, an update of heaptrack 1.4.0, iputils 20221126 and libeconf 0.4.9, which added new Application Programming Interface calls and fixed some compiling issues.
Snapshot 20221126 updated five packages. A memory leak and buffer overflow were fixed in the libpng16 1.6.39 update. Some code cleanup was made with the libstorage-ng 4.5.53 update and libzypp 17.31.6 avoids calling getsockopt when info is already known and the patch is expected to fix logging on Windows Subsystem for Linux. An upgrade of macros were made for both the coming Leap 15.5 and Fedora 37 in manpages-l10n 4.16.0. An update of python-setuptools 65.6.3 fixed logging errors and improved the reproducibility of clib builds by sorting the sources.
A major version update of text editor nano updated in snapshot 20221125. Nano 7.0 allows for unicode codes to be entered (via M-V) without leading zeroes and by finishing short codes. The new major version now allows string binds containing bindable function names between braces. The braced function names may be mixed with literal text. Nano was not the only text editor to update in the snapshot. An update of vim 9.0.0924 freed memory when executing mapclear, unmenu and delfunc at the more prompt. The package also fixed Amazon Web Services configuration files that were not recognized. An update of video media player VLC 3.0.18 fixed color regression and some rendering and performance issues with older GPUs. Several more packages were update in the snapshot including apparmor 3.1.2, image processing framework gegl 0.4.40, openvpn 2.5.8 and more.
The email announcement for snapshot 20221124 was not sent due to an error with the preparation of the changelog, but the snapshot did go out.
The 7.0.4 version update of virtualbox arrived in snapshot 20221123. The new major version had multiple Graphical User Interface changes to include fixing a regression in the new virtual machine wizard. Oracles’ VM package also added support for the Secure Boot feature. An update of sudo 1.9.12p1 fixed a Common Vulnerability and Exposure that had the potential out-of-bounds write for passwords smaller than eight characters when the password authentication is enabled. CVE-2022-43995 does not affect configurations that use other authentication methods like PAM, AIX authentication or BSD authentication. An update of mariadb 10.10.2 had InnoDB storage crash recovery fixes and improved optimization of joins with many tables, including eq_ref tables.
/usr/bin/*ctl なプログラムが何をするのかを試してみました(1)
この記事は openSUSE Advent Calendar 2022 の1日目です。
systemd が使われるようになると、daemon の制御とかのやり方は大きく変わりました。/etc/init.d にあるスクリプトから、systemd パッケージに含まれるコマンドを使うようになってきました。それらのコマンドは、xxxxxctl という、末尾に ctl が含まれるものが多いように感じました。そこで、/usr/bin/ の中にある、末尾が ctl なプログラムがどんなものかを簡単に調べて見ることにしました。
今回は、bluetoothctl を紹介します。
コマンド名: bluetoothctl
パッケージ: bluez-5.55-150300.3.11.1.x86_64
動作: ○
詳細:
bluetooth の制御をするためのコマンドです。初っ端からですが、systemd とは無関係です。動作には、bluethoothd が必要です。
手持ちの、openSUSE が動く物理マシンでは、bluetooth 機能が標準で入っていなかったので、USB 接続の、バッファローの USB アダプタを使って検証してみました。
まずは、systemd で bluetoothd を起動しておきます。
続いて、USB アダプタを差し込み、bluetoothctl を起動します。
起動すると、プロンプトが表示されるので、デバイスのスキャンをするため、スキャンコマンドを入力すると、エラーになってしまいます。
# bluetoothctl Agent registered [CHG] Controller 00:1B:DC:F3:8B:51 Pairable: yes [bluetooth]# scan on Failed to start discovery: org.bluez.Error.NotReady [bluetooth]#
これは、USB Bluetooth アダプタを差し込んだだけでは、まだ機能が動いていないためです。まずは、Bluetooth アダプタの機能を有効にするため、power on と入力します。すると、今度は見えるようになりました。
# power on [CHG] Controller 00:1B:DC:F3:8B:51 Class: 0x00000104 Changing power on succeeded [CHG] Controller 00:1B:DC:F3:8B:51 Powered: yes [bluetooth]# scan on Discovery started [CHG] Controller 00:1B:DC:F3:8B:51 Discovering: yes [NEW] Device 77:6C:E6:94:2A:38 77-6C-E6-94-2A-38 [NEW] Device 7E:4D:FE:CB:CC:D9 7E-4D-FE-CB-CC-D9 [CHG] Device 77:6C:E6:94:2A:38 RSSI: -73 [NEW] Device 4C:FD:32:93:41:95 4C-FD-32-93-41-95 [CHG] Device 77:6C:E6:94:2A:38 RSSI: -65 [NEW] Device 46:D9:DC:39:CC:E8 46-D9-DC-39-CC-E8 [NEW] Device 8C:DE:52:B8:AB:EA SRS-X33 [CHG] Device 77:6C:E6:94:2A:38 RSSI: -73 [CHG] Device 77:6C:E6:94:2A:38 RSSI: -65 [bluetooth]#
ここで、pair コマンドを入力すると
# pair 8C:DE:52:B8:AB:EA Attempting to pair with 8C:DE:52:B8:AB:EA [CHG] Device 8C:DE:52:B8:AB:EA Connected: yes [CHG] Device 8C:DE:52:B8:AB:EA Modalias: bluetooth:v0039p1582d2110 [CHG] Device 8C:DE:52:B8:AB:EA UUIDs: 00001108-0000-1000-8000-00805f9b34fb [CHG] Device 8C:DE:52:B8:AB:EA UUIDs: 0000110b-0000-1000-8000-00805f9b34fb [CHG] Device 8C:DE:52:B8:AB:EA UUIDs: 0000110c-0000-1000-8000-00805f9b34fb [CHG] Device 8C:DE:52:B8:AB:EA UUIDs: 0000110e-0000-1000-8000-00805f9b34fb [CHG] Device 8C:DE:52:B8:AB:EA UUIDs: 0000111e-0000-1000-8000-00805f9b34fb [CHG] Device 8C:DE:52:B8:AB:EA UUIDs: 00001200-0000-1000-8000-00805f9b34fb [CHG] Device 8C:DE:52:B8:AB:EA ServicesResolved: yes [CHG] Device 8C:DE:52:B8:AB:EA Paired: yes Pairing successful [bluetooth]#
となり、ペアリングが出来るようになりました。
この先は試してみていませんが、デバイスの削除とか情報の取得とか色々できるようです。
GUI な環境が無い状況での bluetooth 利用には使えると思います。

Post-mortem: Downtime on November 30, 2022
Iseng-Iseng Berhadiah : Menanam Pepaya untuk Masa Depan
Saya pernah menanam pepaya California dan Mexican Sweet di pekarangan rumah kabin Zeze Zahra. Niat awal sekedar iseng menanam, ternyata hasil buahnya banyak sekali.
Karena hal tersebut, saya menambah jumlah bibit yang ditanam dengan jarak tanaman yang lebih rapat. Harapannya, tanaman tersebut bisa menghasilkan buah yang lebat dalam beberapa bulan kedepan.
Trabaja en KDE
La comunidad de KDE a través de la organización KDE e.v. que representa a KDE en cuestiones legales y financieras, ofrece unas plazas de empleo para trabajar en la comunidad

KDE es una gran comunidad global que crea software libre para ser utilizado por cualquier persona en sistemas GNU/Linux e incluso por otros sistemas privativos.
La comunidad de KDE está formada por diferentes personas que desarrollan software, corrigen errores, escriben, traducen de manera altruista, compartiendo sus conocimientos, tiempo y esfuerzo en este gran proyecto de software libre.
Pero además de ese trabajo voluntario, hay también una serie de personas que trabajan contratados por KDE, mediante KDE e.v. para realizar diferentes tareas dentro de la comunidad, en las que se requiere un toque más profesional.
Esas personas contratadas por KDE trabajan y coordinan sus esfuerzos y trabajos para hacerlo junto a la gran comunidad de KDE.
Si quieres encontrar un trabajo relacionado con el software libre, en un gran proyecto como es KDE, echa un vistazo a estas ofertas de empleo que ofrece KDE.
Documentación
KDE e.V. está buscando una persona con experiencia en redacción técnica para actualizar la documentación de KDE en sus diversos proyectos. La documentación del software y comunidad está en constante evolución y requiere una cuidadosa planificación y mantenimiento, así como una comunicación regular y una estrecha colaboración con nuestros equipos de colaboradores.
Se basará en el resultado del trabajo de documentación anterior. Consulta la convocatoria de la propuesta para obtener más detalles sobre esta oportunidad de contratación.
Hardware
Tu tarea abarcará desde discutir con los fabricantes y evaluar el tipo de hardware que planean enviar, hasta asegurarte de que sea viable que KDE lo admita, ya sea implementando las características o coordinando con los diferentes equipos para asegurarse de que esto pueda suceder en de manera oportuna.
Eventualmente, esto requerirá la colaboración con las comunidades de integración de sistemas para garantizar que nuestros usuarios obtengan una experiencia óptima. Consulta la convocatoria de la propuesta para obtener más detalles sobre esta oportunidad de contratación.
Software
KDE e.V. está buscando un ingeniero de software para desarrollar la plataforma de software de KDE. Trabajará en KDE Frameworks, Plasma, Qt y otras bibliotecas de middleware para impulsar el estado del arte en la tecnología de KDE.
Las responsabilidades incluyen el desarrollo de nuevas funciones, la corrección de errores, la realización del trabajo de portabilidad necesario, la mejora de la cobertura y la confiabilidad de las pruebas y el mantenimiento del código existente. Consulta la convocatoria de la propuesta para obtener más detalles sobre esta oportunidad de contratación.
En los diversos enlaces se especifican los conocimientos necesarios que se requieren y también las condiciones del trabajo. Todos ellos para realizar en remoto. Y un correo de contacto al que enviar tu propuesta o pedir más información al respecto.
Quizás alguna de esta se adapta a tu perfil técnico y consigas el puesto y sea una puerta que se abra a trabajar en el gran proyecto que es KDE dentro de la comunidad de software libre. ¡Anímate!
