
 Trebol-a
Trebol-aIntegrar PushBullet en KDE4
Hace un tiempo en mis listado de aplicaciones fundamentales para Android os comentaba el servicio PushBullet. Para quien todavía no lo conozca es un servicio online que permite la compartición de archivos, fotos, enlaces y texto entre un servidor y varios clientes. Este servicio se instala como plugins (Firefox/Chrome), programa de escritorio (Windows) ó App (Android) en todos aquellos dispositivos que queramos que formen parte de una “red privada” y desde ese momento es absurdamente fácil enviar un PDF desde nuestro PC a nuestro teléfono, un ZIP al teléfono de un amigo, o un POWERPOINT lleno de malware al escritorio de nuestro jefe. Y viceversa.
Faltaba una aplicación de escritorio para GNU/Linux, pero puesto que los desarrolladores de PushBullet han tenido a bien habilitar el acceso al servicio con una sencilla API de acceso veréis como integrar PushBullet en el menú de contexto del ratón en KDE4 (y por extensión en cualquier otro escritorio Linux) es coser y cantar.

La idea es activar una acción en el menú de contexto del ratón en KDE4 que permita mediante un simple click enviar un archivo de cualquier tipo a nuestro móvil.
1. Regístrarse e instalar app
Obviamente lo primero es estar registrado en el servicio. Gratuito.
Después de registrarte instala la applicación oficial para Android. Asegúrate de que todo funciona correctamente y puedes enviar/recibir archivos desde tu escritorio al móvil usando la página https://www.pushbullet.com y viceversa.
Una vez tienes todo instalado y funcionando correctamente necesitas obtener dos datos: tu token de Acceso y el Identificador de dispositivo en Pushbullet del móvil al que quieres enviar los archivos desde el escritorio. El token de acceso lo tienes aquí (guárdalo para usarlo más adelante).
El Identificador de dispositivo de tu móvil en Pushbullet lo obtienes en la página principal de Pushbullet.
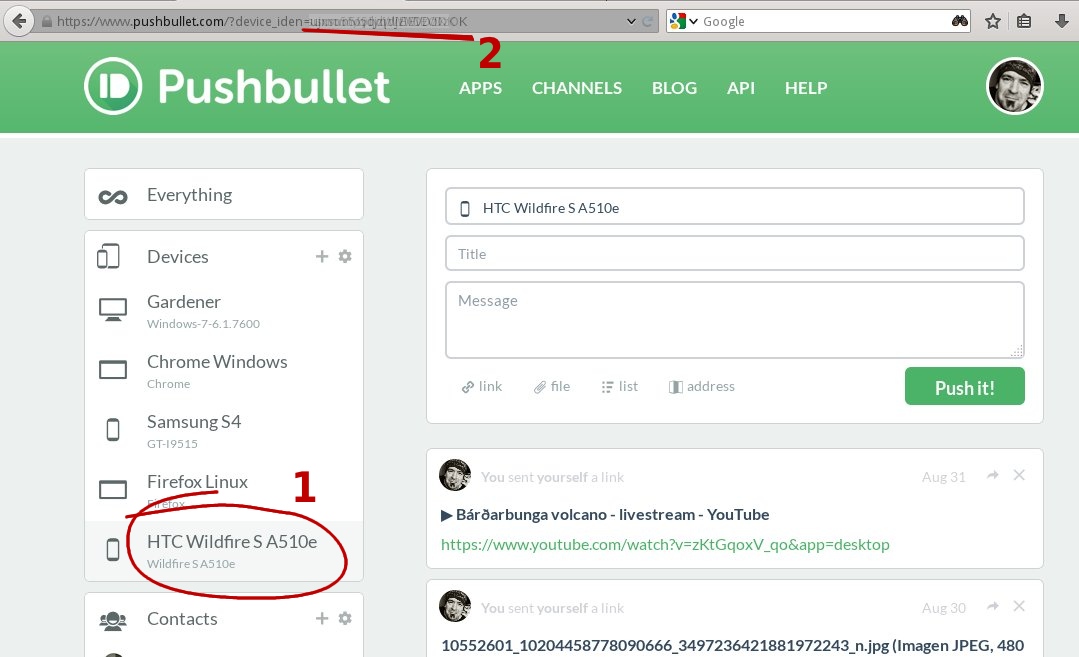 A la izquierda verás la lista de dispositivos que tienes conectados (uno ó varios), cliquea sobre uno de ellos y verás que la url del navegador cambia a algo como
A la izquierda verás la lista de dispositivos que tienes conectados (uno ó varios), cliquea sobre uno de ellos y verás que la url del navegador cambia a algo como
https://www.pushbullet.com/?device_iden=asdf1234asdf1234
lo que va después del signo igual (en negrita) es el ID de tu dispositivo. Apuntalo para usarlo más adelante.
Ninguno de estos dos datos deberías compartirlos públicamente.
2. Script bash de subida
El script es muy sencillo. Con las credenciales obtenidas anteriormente sube cualquier archivo al servidor PushBullet en Amazon. Después de subirlo obtiene la url del archivo y la envía al móvil. Al teléfono entonces nos llega un aviso con un enlace a dicho archivo, ó la imagen (caso de tratarse de un GIF, PNG, JPG) ó archivo de audio, etc, etc…
Descarga el script bash desde aquí, guárdalo y edita.
Donde pone:tokenA="1234asdf1234asdf1234"
Reemplaza y pon tu token de Acceso que obtuviste anteriormente
Donde pone passwordPushBullet="12345678"
Pon tu contraseña de acceso a Pushbullet
Donde pone dispositivo="12345678qwerty"
Reemplaza y pon tu Identificador de dispositivo obtenido anteriormente.
Guárdalo en (p.ejem) /home/tu-usuario/bin/pushbullet.sh y hazlo ejecutable (chmod +x /home/tu-usuario/bin/pushbullet.sh).
Listo, ahora puedes abrir un terminal y escribir pushbullet.sh /home/tu-user/Desktop/imagen.jpg
Si el primer argumento es un archivo el script lo sube al servidor de PushBullet e inmediatamente te lo envía al teléfono. Si no es un archivo porque por ejemplo has escrito pushbullet.sh "Hola amigos, esto es una prueba" el script lo envía al teléfono directamente como si fuese una anotación. Esto es especialmente útil para enviar largos párrafos de texto al móvil.
3. Personalizar menú de contexto KDE4
Para insertar Pushbullet en el menú de contexto del ratón de KDE4 y que aparezca sobre cualquier archivo.
Abre un editor de texto y pega el siguiente contenido:[Desktop Entry]
X-SuSE-translate=true
Encoding=UTF-8
Type=Service
ServiceTypes=KonqPopupMenu/Plugin
MimeType=all/all;
Actions=pushbullet
Name=Enviar
Icon=web
[Desktop Action pushbullet]
Name=Móvil via PushBullet
Exec=pushbullet.sh "%f"
Icon=pushbullet
Guardalo en /home/tu-usuario/.kde4/share/kde4/services/pushbullet.desktop. En adelante basta hacer click derecho sobre un icono de archivo y seleccionar Acciones > Móvil via PushBullet para que casi de forma inmediata aparezca en tu teléfono el archivo. (el menú de contexto puede requerir algunos reintentos sobre iconos para que se actualice la caché de KDE4 y aparezca el nuevo menú).
4. Cosas a mejorar
– Barra de progreso: No hice ninguna barra de progreso para la subida porque el envío es tan inmediato y rápido que casi se tarda más en abrir/cerrar el diálogo que en recibir el archivo. Pero quizás si estáis pensando en enviar archivos muy grandes si sería interesante añadir algún diálogo de subida.
– Errores: Idem de lo anterior. Si algo no funciona el script no avisa ni advierte. Tocará examinar en consola donde está el fallo. Normalmente algún token/password mal escrito.
– Subidas múltiples. Actualmente el script solo procesa un archivo en cada ejecución. Si se seleccionan varios se lanzarán varias instancias al mismo tiempo y en este punto ignoro cuales son las limitaciones del servicio de PushBullet. Si no os da por enviar 10 películas de 600Mg al mismo tiempo no debería haber problemas.


„Indie Game: The Movie“ auf openSUSE
Startet man unter openSUSE, bzw. mit einem KDE-Desktop, von Steam aus „Indie Game: The Movie“, so kommt zwar ein archaisch wirkendes Xterm hoch, welches behauptet einem Adobe AIR zu installieren, allerdings passiert danach nichts mehr. Hat man Adobe AIR bereits installiert startet „Indie Game: The Movie“ ohne Probleme.
Hier kommen gleich mehrere Probleme zusammen:
- Adobe AIR unterstützt schon seit mehreren Jahren Linux offiziell nicht mehr. Es muss also eine alte Version installiert werden, welche dann natürlich nicht die modernsten Annahmen macht was die Linuxumgebung angeht
- Die Standardinstallation von Adobe AIR benötigt root-Rechte. Steam führt man allerdings normalerweise nicht als root aus, und das Skript welches die Installation durchführt fordert auch offensichtlich keine an.
- Adobe AIR will bei der Installation auf KWallet, oder alternativ den Gnome Keyring zugreifen. Auf openSUSE 13.1 mit KDE findet es aber, obwohl natürlich KWallet installiert ist, keinen von beiden.
Zur manuellen Installation ist zunächst Adobe AIR von der Archivseite http://helpx.adobe.com/air/kb/archived-air-sdk-version.html herunterzuladen. Es empfiehlt sich die letzte Version mit Linuxunterstützung, also die 2.6 Runtime, zun nutzen. Diese muss mit root-Rechten und Zugriff auf X ausgeführt werden. Hierbei ergibt sich dann das Problem, dass KWallet nicht gefunden wird. Adobe AIR ist eine 32-bit Anwendung, auf den inzwischen üblichen 64-bit-Systemen prüft es offensichtlich im falschen Verzeichnis auf die Existenz der Bibliothek. Legt man, an sich redundant, das korrekte Verzeichnis in die Umgebungsvariable LD_LIBRARY_PATH, so läuft der Installer erfolgreich durch. Nach dem Download ist also folgendes in einer Konsole auszuführen.
chmod +x AdobeAIRInstaller.bin
su # sudo gibt per default keinen Zugriff auf den laufenden X-Server
LD_LIBRARY_PATH=/usr/lib64 ./AdobeAIRInstaller.bin
PowerVR SGX code leaked.
I've been fed links from several sides now, and i cannot believe how short-sighted and irresponsible people are, including a few people who should know better.
STOP TELLING PEOPLE TO LOOK AT PROPRIETARY CODE.
Having gotten that out of the way, I am writing this blog to put everyone straight and stop the nonsense, and to calmly explain why this leak is not a good thing.
Before i go any further, IANAL, but i clearly do seem to tread much more carefully on these issues than most. As always, feel free to debunk what i write here in the comments, especially you actual lawyers, especially those lawyers in the .EU.
LIBV and the PVR.
Let me just, once again, state my position towards the PowerVR.I have worked on the Nokia N9, primarily on the SGX kernel side (which is of course GPLed), but i also touched both the microcode and userspace. So I have seen the code, worked with and i am very much burned on it. Unless IMG itself gives me permission to do so, i am not allowed to contribute to any open source driver for the PowerVR. I personally also include the RGX, and not just SGX, in that list, as i believe that some things do remain the same. The same is true for Rob Clark, who worked with PowerVR when at Texas Instruments.
This is, however, not why i try to keep people from REing the PowerVR.
The reason why i tell people to stay away is because of the design of the PowerVR and its driver stack: PVR is heavily microcode driven, and this microcode is loaded through the kernel from userspace. The microcode communicates directly with the kernel through some shared structs, which change depending on build options. There are sometimes extensive changes to both the microcode, kernel and userspace code depending on the revision of the SGX, customer project and build options, and sometimes the whole stack is affected, from microcode to userspace. This makes the powervr a very unstable platform: change one component, and the whole house of cards comes tumbling down. A nightmare for system integrators, but also bad news for people looking to provide a free driver for this platform. As if the murderous release cycle of mobile hardware wasn't bad enough of a moving target already.
The logic behind me attempting to keep people away from REing the PowerVR is, at one end, the attempt to focus the available decent developers on more rewarding GPUs and to keep people from burning out on something as shaky as the PowerVR. On the other hand, by getting everyone working on the other GPUs, we are slowly forcing the whole market open, singling out Imagination Technologies. At one point, IMG will be forced to either do this work itself, and/or to directly support open sourcing themselves, or to remain the black sheep forever.
None of the above means that I am against an open source driver for PVR, quite the opposite, I just find it more productive to work on the other GPUs amd wait this one out.
Given their bad reputation with system integrators, their shaky driver/microcode design, and the fact that they are in a cut throat competition with ARM, Imagination Technologies actually has the most to gain from an open source driver. It would at least take some of the pain out of that shaky microcode/kernel/userspace combination, and make a lot of peoples lives a lot easier.
This is not open source software.
Just because someone leaked this code, it has not magically become free software.It is still just as proprietary as before. You cannot use this code in any open source project, or at all, the license on it applies just as strongly as before. If you download it, or distribute it, or whatever other actions forbidden in the license, you are just as accountable as the other parties in the chain.
So for all you kiddies who now think "Great, finally an open driver for PowerVR, let's go hack our way into celebrity", you couldn't be more wrong. At best, you just tainted yourself.
But the repercussion go further than that. The simple fact that this code has been leaked has cast a very dark shadow on any future open source project that might involve the powervr. So be glad that we have been pretty good at dissuading people from wasting their time on powervr, and that this leak didn't end up spoiling many man-years of work.
Why? Well, let's say that there was an advanced and active PowerVR reverse engineering project. Naturally, the contributors would not be able to look at the leaked code. But it goes further than that. Say that you are the project maintainer of such a reverse engineered driver, how do you deal with patches that come in from now on? Are you sure that they are not taken more or less directly from the leaked driver? How do you prove this?
Your fun project just turned from a relatively straightforward REing project to a project where patches absolutely need to be signed-off, and where you need to establish some severe trust into your contributors. That's going to slow you down massively.
But even if you can manage to keep your code clean, the stigma will remain. Even if lawyers do not get involved, you will spend a lot of time preparing yourself for such an eventuality. Not a fun position to be in.
The manpower issue.
I know that any clued and motivated individual can achieve anything. I also know that really clued people, who are dedicated and can work structuredly are extremely rare and that their time is unbelievably valuable.With the exception of Rob, who is allowed to spend some of his redhat time on the freedreno driver, none of the people working on the open ARM GPU drivers have any support. Working on such a long haul project without support either limits the amount of time available for it, or severely reduces the living standard of the person doing so, or anywhere between those extremes. If you then factor in that there are only a handful of people working on a handful of drivers, you get individuals spending several man-years mostly on their own for themselves.
If you are wondering why ARM GPU drivers are not moving faster, then this is why. There are just a limited few clued individuals who are doing this, and they are on their own, and they have been at it for years by now. Think of that the next time you want to ask "Is it done yet?".
This is why I tried to keep people from REing the powerVR, what little talent and stamina there is can be better put to use on more straightforward GPUs. We have a hard enough time as it is already.
Less work? More work!
If you think that this leaked driver takes away much of the hard work of reverse engineering and makes writing an open source driver easy, you couldn't be more wrong.This leak means that here is no other option left apart from doing a full clean room. And there need to be very visible and fully transparent processes in place in a case like this. Your one man memory dumper/bit-poker/driver writer just became at least two persons. One of them gets to spend his time ogling bad code (which proprietary code usually ends up being), trying to make sense of it, and then trying to write extensive documentation about it (without being able to test his findings much). The other gets to write code from that documentation, but also little more. Both sides are very much forbidden to go back and forth between those two positions.
As if we ARM GPU driver developers didn't have enough frustration to deal with, and the PVR stack isn't bad enough already, the whole situation just got much much worse.
So for all those who think that now the floodgates are open for PowerVR, don't hold your breath. And to those who now suddenly want to create an open source driver for the powervr, i ask: you and what army?
For all those who are rinsing out their shoes ask yourself how many unsupported man-years you will honestly be able to dedicate to this, and whether there will be enough individuals who can honestly claim the same. Then pick your boring task, and then stick to it. Forever. And hope that the others also stick to their side of this bargain.
LOL, http://goo.gl/kbBEPX
What have we come to?The leaked source code of a proprietary graphics driver is not something you should be spreading amongst your friends for "Lolz", especially not amongst your open source graphics driver developing friends.
I personally am not too bothered about the actual content of this one, the link names were clear about what it was, and I had seen it before. I was burned before, so i quickly delved in to verify that this was indeed SGX userspace. In some cases, with the links being posted publicly, i then quickly moved on to dissuade people from looking at it, for what limited success that could have had.
But what would i have done if this were Mali code, and the content was not clear from the link name? I got lucky here.
I am horrified about the lack of responsibility of a lot of people. These are not some cat pictures, or some nude celebrities. This is code that forbids people from writing graphics drivers.
But even if you haven't looked at this code yet, most of the damage has been done. A reverse engineered driver for powervr SGX will now probably never happen. Heck, i just got told that someone even went and posted the links to the powerVR REing mailinglist (which luckily has never seen much traffic). I wonder how that went:
Hi,
Are you the guys doing the open source driver for PowerVR SGX?
I have some proprietary code here that could help you speed things along.
Good luck!
So for the person who put this up on github: thank you so much. I hope that you at least didn't use your real name. I cannot imagine that any employer would want to hire anyone who acts this irresponsibly. Your inability to read licenses means that you cannot be trusted with either proprietary code or open source code, as you seem unable to distinguish between them. Well done.
The real culprit is of course LG, for crazily sticking the GPL on this. But because one party "accidentally" sticks a GPL on that doesn't make it GPL, and that doesn't suddenly give you the right to repeat the mistake.
Last months ISA release.
And now for something slightly different...Just over a month ago, there was the announcement about Imagination Technologies' new SDK. Supposedly, at least according to the phoronix article, Imagination Technologies made the ISA (instruction set architecture) of the RGX available in it.
This was not true.
What was released was the assembly language for the PowerVR shaders, which then needs to be assembled by the IMG RGX assembler to provide the actual shader binaries. This is definitely not the ISA, and I do not know whether it was Alexandru Voica (an Imagination marketing guy who suddenly became active on the phoronix forums, and who i believe to be the originator of this story) or the author of the article on Phoronix who made this error. I do not think that this was bad intent though, just that something got lost in translation.
The release of the assembly language is very nice though. It makes it relatively straightforward to match the assembly to the machine code, and takes away most of the pain of ISA REing.
Despite the botched message, this was a big step forwards for ARM GPU makers; Imagination delivered what its customers need (in this case, the ability to manually tune some shaders), and in the process it also made it easier for potential REers to create an open source driver.
Looking forward.
Between the leak, the assembly release, and the market position Imagination Technologies is in, things are looking up though.Whereas the leak made a credible open source reverse engineering project horribly impractical and very unlikely, it did remove some of the incentive for IMG to not support an open source project themselves. I doubt that IMG will now try to bullshit us with the inane patent excuse. The (not too credible) potential damage has been done here already now.
With the assembly language release, a lot of the inner workings and the optimization of the RGX shaders was also made public. So there too the barrier has disappeared.
Given the structure of the IMG graphics driver stack, system integrators have a limited level of satisfaction with IMG. I really doubt that this has improved too much since my Nokia days. Going open source now, by actively supporting some clued open source developers and by providing extensive NDA-free documentation, should not pose much of a legal or political challenge anymore, and could massively improve the perception of Imagination Technologies, and their hardware.
So go for it, IMG. No-one else is going to do this for you, and you can only gain from it!
 Member
MemberSpeeding up openSUSE 13.2 boot
Investigating, I found out that in 13.2 the displaymanager.service is now a proper systemd service with all the correct dependencies instead of the old 13.1 xdm init script.
At home, I'm running NIS and autofs for a few NFS shares and an NTP server for the correct time.
The new displaymanager.service waits for timesetting, user account service and remote file systems, which takes lots of time.
So I did:
systemctl disable ypbind.service autofs.service ntpd.serviceIn order to use them anyway, I created a short NetworkManager dispatcher script which starts / stops the services "manually" if an interface goes up or down.
This brings the startup time (until the lightdm login screen appears) down to less than 11 seconds.
The next thing I found was that the machine would not shut down if an NFS mount was active. This was due to the fact that the interfaces were already shut down before the autofs service was stopped or (later) the NFS mounts were unmounted.
It is totally possible that this is caused by the violation in proper ordering I introduced by the above mentioned hack, but I did not want to go back to slow booting. So I added another hack:
- create a small script /etc/init.d/before-halt.local which just does umount -a -t nfs -l (a lazy unmount)
- create a systemd service file /etc/systemd/system/before-halt-local.service which is basically copied from the halt-local.service, then edited to have Before=shutdown.target instead of After=shutdown.target and to refer to the newly created before-halt.local script. Of course I could have skipped the script, but I might later need to add other stuff, so this is more convenient.
- create the directory /etc/systemd/system/shutdown.target.wants and symlink ../before-halt-local.service into it.
Hibernate Filesystem Corruption in openSUSE 13.2
UPDATE: This bug is fixed with the dracut update to version dracut-037-17.9.1
I was never very fond of dracut, but I did not think it would be so totally untested: openSUSE Bug #906592. Executive summary: hibernate will most likely silently corrupt (at least) your root filesystem during resume from disk.
If you are lucky, a later writeback from buffers / cache will "fix" it, but the way dracut resumes the system is definitely broken and I already had the filesystem corrupted on my test VM, while investigating the issue, so it is not only a theoretical problem.
Until this bug is fixed: Do not hibernate on openSUSE 13.2.
Good luck!
Service Design Patterns in Rails: Web Service Evolution
The previous posts were:
- Tolerant Reader
- Consumer driven contract
- Versioning
Unbound RGB with littleCMS slow
The last days I played with lcms‘ unbound mode. In unbound mode the CMM can convert colours with negative numbers. That allows to use for instance the LMS colour space, a very basic colour space to the human visual system. As well unbound RGB, linear gamma with sRGB primaries, circulated long time as the new one covers all colour space, a kind of replacement of ICC or WCS style colour management. There are some reservations about that statement, as linear RGB is most often understood as “no additional info needed”, which is not easy to build a flexible CMS upon. During the last days I hacked lcms to write the mpet tag in its device link profiles in order to work inside the Oyranos CMS. The multi processing elements tag type (mpet) contains the internal state of lcms’ transform as a rendering pipeline. This pipeline is able to do unbound colour transforms, if no table based elements are included. The tested device link contained single gamma values and matrixes in its D2B0 mpet tag. The Oyranos image-display application renderd my LMS test pictures correctly, in opposite to the 16-bit integer version. However the speed was decreased by a factor of ~3 with lcms compared to the usual integer math transforms. The most time consuming part might be the pow() call in the equation. It is possible that GPU conversions are much faster, only I am not aware of a implementation of mpet transforms on the GPU.
pam_systemd on a server? WTF?
20141120-05:15:01.9 systemd[1]: Starting user-30.slice.
20141120-05:15:01.9 systemd[1]: Created slice user-30.slice.
20141120-05:15:01.9 systemd[1]: Starting User Manager for UID 30...
20141120-05:15:01.9 systemd[1]: Starting Session 1817 of user root.
20141120-05:15:01.9 systemd[1]: Started Session 1817 of user root.
20141120-05:15:01.9 systemd[1]: Starting Session 1816 of user wwwrun.
20141120-05:15:01.9 systemd[1]: Started Session 1816 of user wwwrun.
20141120-05:15:01.9 systemd[22292]: Starting Paths.
20141120-05:15:02.2 systemd[22292]: Reached target Paths.
20141120-05:15:02.2 systemd[22292]: Starting Timers.
20141120-05:15:02.2 systemd[22292]: Reached target Timers.
20141120-05:15:02.2 systemd[22292]: Starting Sockets.
20141120-05:15:02.2 systemd[22292]: Reached target Sockets.
20141120-05:15:02.2 systemd[22292]: Starting Basic System.
20141120-05:15:02.2 systemd[22292]: Reached target Basic System.
20141120-05:15:02.2 systemd[22292]: Starting Default.
20141120-05:15:02.2 systemd[22292]: Reached target Default.
20141120-05:15:02.2 systemd[22292]: Startup finished in 21ms.
20141120-05:15:02.2 systemd[1]: Started User Manager for UID 30.
20141120-05:15:02.2 CRON[22305]: (wwwrun) CMD (/usr/bin/php -f /srv/www/htdocs/owncloud/cron.php)
20141120-05:15:02.4 systemd[1]: Stopping User Manager for UID 30...
20141120-05:15:02.4 systemd[22292]: Stopping Default.
20141120-05:15:02.4 systemd[22292]: Stopped target Default.
20141120-05:15:02.4 systemd[22292]: Stopping Basic System.
20141120-05:15:02.4 systemd[22292]: Stopped target Basic System.
20141120-05:15:02.4 systemd[22292]: Stopping Paths.
20141120-05:15:02.4 systemd[22292]: Stopped target Paths.
20141120-05:15:02.4 systemd[22292]: Stopping Timers.
20141120-05:15:02.4 systemd[22292]: Stopped target Timers.
20141120-05:15:02.4 systemd[22292]: Stopping Sockets.
20141120-05:15:02.4 systemd[22292]: Stopped target Sockets.
20141120-05:15:02.4 systemd[22292]: Starting Shutdown.
20141120-05:15:02.4 systemd[22292]: Reached target Shutdown.
20141120-05:15:02.4 systemd[22292]: Starting Exit the Session...
20141120-05:15:02.4 systemd[22292]: Received SIGRTMIN+24 from PID 22347 (kill).
20141120-05:15:02.4 systemd[1]: Stopped User Manager for UID 30.
20141120-05:15:02.4 systemd[1]: Stopping user-30.slice.
20141120-05:15:02.4 systemd[1]: Removed slice user-30.slice.
After some searching, I found that pam_systemd is to blame: it seems to be enabled by default. Looking into the man page of pam_systemd, I could not find anything in it that would be useful on a server system so I disabled it, and pam_gnome_keyring also while I was at it:
pam-config --delete --gnome_keyring --systemd...and silence returned to my logfiles again.
Aurora goes Firefox Developer Edition
Mozilla announced a few days ago a new flavour of the Firefox browser called Firefox Developer Edition. This new Firefox edition is in fact replacing the previous Aurora version. Just to add some background how it was structured until a few days ago:
- Nightly – nightly builds of mozilla-central which is basically Mozilla’s HEAD
- Aurora – regular builds published for openSUSE under mozilla:alpha
- Beta – weekly builds for openSUSE under mozilla:beta
- Release – full stable public releases as shipped as end user product for openSUSE under mozilla and in Factory/Tumbleweed
There is a 6 weeks cycle where the codebase goes from Nightly to Aurora to Beta to Release while it stabilizes.
Now as Aurora is replaced to be Firefox Developer Edition I am also changing the way how to deliver those to openSUSE users:
- Nightly – there are no RPMs provided. People who want to run it can/should grab an upstream tarball
- Firefox Developer Edition – now available as package firefox-dev-edition from the mozilla repository
- Beta – no changes, available (as long time permits) from mozilla:beta
- Release – no changes, available in mozilla and submitted to openSUSE Factory / Tumbleweed
A few more notes on the Firefox Developer Edition RPMs for openSUSE:
- it’s brand new so please send me feedback about packaging issues
- it can be installed in parallel to Release or Beta and is started as firefox-dev and is using a different profile unless you change that default; therefore it can even run in parallel with regular Firefox
- it carries most of the openSUSE specific patches (including KDE integration)
- it currently has NO branding packages and therefore does not use exactly the same preferences as the openSUSE provided Firefox so it behaves like Firefox when installed with MozillaFirefox-branding-upstream
Service Design Patterns in Rails: Web Service Implementation Styles
- Transaction script
- Datasource adapter
- Operation script
- Command invoker
- Workflow connector