
 Member
Member tserong
tserongSalt and Pepper Squid with Fresh Greens
A few days ago I told Andrew Wafaa I’d write up some notes for him and publish them here. I became hungry contemplating this work, so decided cooking was the first order of business:

It turned out reasonably well for a first attempt. Could’ve been crispier, and it was quite salty, but the pepper and chilli definitely worked (I’m pretty sure the chilli was dried bhut jolokia I harvested last summer). But this isn’t a post about food, it’s about some software I’ve packaged for managing Ceph clusters on openSUSE and SUSE Linux Enterprise Server.
Specifically, this post is about Calamari, which was originally delivered as a proprietary dashboard as part of Inktank Ceph Enterprise, but has since been open sourced. It’s a Django app, split into a backend REST API and a frontend GUI implemented in terms of that backend. The upstream build process uses Vagrant, and is fine for development environments, but (TL;DR) doesn’t work for building more generic distro packages inside OBS. So I’ve got a separate branch that unpicks the build a little bit, makes sure Calamari is installed to FHS paths instead of /opt/calamari, and relies on regular packages for all its dependencies rather than packing everything into a Python virtualenv. I posted some more details about this to the Calamari mailing list.
Getting Calamari running on openSUSE is pretty straightforward, assuming you’ve already got a Ceph cluster configured. In addition to your Ceph nodes you will need one more host (which can be a VM, if you like), on which Calamari will be installed. Let’s call that the admin node.
First, on every node (i.e. all Ceph nodes and your admin node), add the systemsmanagement:calamari repo (replace openSUSE_13.2 to match your actual distro):
# zypper ar -f http://download.opensuse.org/repositories/systemsmanagement:/calamari/openSUSE_13.2/systemsmanagement:calamari.repo
Next, on your admin node, install and initialize Calamari. The calamari-ctl command will prompt you to create an administrative user, which you will use later to log in to Calamari.
# zypper in calamari-clients # calamari-ctl initialize
Third, on each of your Ceph nodes, install, configure and start salt-minion (replace CALAMARI-SERVER with the hostname/FQDN of your admin node):
# zypper in salt-minion # echo "master: CALAMARI-SERVER" > /etc/salt/minion.d/calamari.conf # systemctl enable salt-minion # systemctl start salt-minion
Now log in to Calamari in your web browser (go to http://CALAMARI-SERVER/). Calamari will tell you your Ceph hosts are requesting they be managed by Calamari. Click the “Add” button to allow this.


Once that’s complete, click the “Dashboard” link at the top to view the cluster status. You should see something like this:
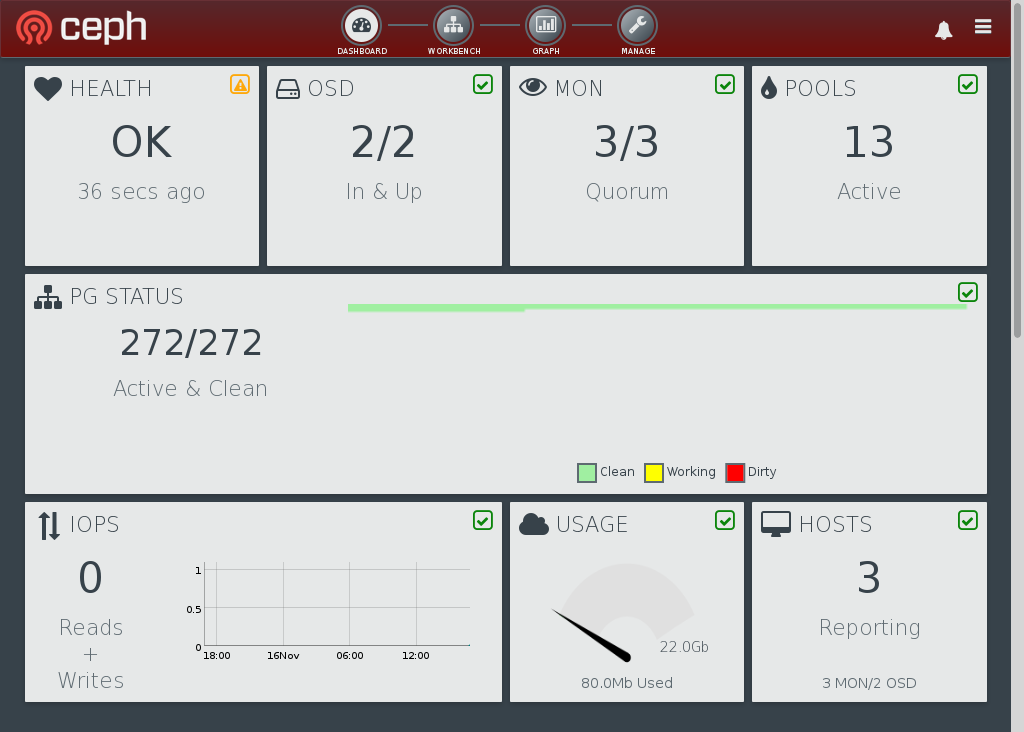
And you’re done. Go explore. You might like to put some load on your cluster and see what the performance graphs do.
Concerning ceph-deploy
The instructions above have you manually installing and configuring salt-minion on each node. This isn’t too much of a pain, but is even easier with ceph-deploy which lets you do the whole lot with one command:
ceph-deploy calamari connect --master <calamari-fqdn> <node1> [<node2> ...]
Unfortunately, at the time of writing, we don’t have a version of ceph-deploy on OBS which supports the calamari connect command on openSUSE or SLES. I do have a SUSE-specific patch for ceph-deploy to fix this (feel free to use this if you like), but rather than tacking that onto our build of ceph-deploy I’d rather push something more sensible upstream, given the patch as written would break support for other distros.
Distros systemsmanagement:calamari Builds Against
The systemsmanagement:calamari project presently builds everything for openSUSE 13.1, 13.2, Tumbleweed and Factory. You should be able to use the packages supplied to run a Calamari server on any of these distros.
Additionally, I’m building salt (which is how the Ceph nodes talk to Calamari) and diamond (the metrics collector) for SLE 11 SP3 and SLE 12. This means you should be able to use these packages to connect Calamari running on openSUSE to a Ceph cluster running on SLES, should you so choose. If you try that and hit any missing Python dependencies, you’ll need to get these from devel:languages:python.
Disconnecting a Ceph Cluster from Calamari
To completely disconnect a Ceph cluster from Calamari, first, on each Ceph node, stop salt and diamond:
# systemctl disable salt-minion # systemctl stop salt-minion # systemctl disable diamond # systemctl stop diamond
Then, make the Calamari server forget the salt keys, ceph nodes and ceph cluster. You need to use the backend REST API for this. Visit each of /api/v2/key, /api/v2/server and /api/v2/cluster in your browser. Look at the list of resources, and for each item to be deleted, construct the URL for that and click “Delete”. John Spray also mentioned this on the mailing list, and helpfully included a couple of screenshots.
Multiple Cluster Kinks
When doing development or testing, you might find yourself destroying and recreating clusters on the same set of Ceph nodes. If you keep your existing Calamari instance running through this, it’ll still remember the old cluster, but will also be aware of the new cluster. You may then see errors about the cluster state being stale. This is because the Calamari backend supports multiple clusters, but the frontend doesn’t (this is planned for version 1.3), and the old cluster obviously isn’t providing updates any more, as it no longer exists. To cope with this, on the Calamari server, run:
# calamari-ctl clear --yes-i-am-sure # calamari-ctl initialize
This will make Calamari forget all the old clusters and hosts it knows about, but will not clear out the salt minion keys from the salt master. This is fine if you’re reusing the same nodes for your new cluster.
Sessions to Attend at SUSECon
SUSECon starts tomorrow (or the day after, depending on what timezone you’re in). It would be the height of negligence for me to not mention the Ceph related sessions several of my esteemed colleagues are running there:
- FUT7537 – SUSE Storage – Software Defined Storage Introduction and Roadmap: Getting your tentacles around data growth
- HO8025 – SUSE Storage / Ceph hands-on session
- TUT8103 – SUSE Storage: Sizing and Performance
- TUT6117 – Quick-and-Easy Deployment of a Ceph Storage Cluster with SLES – With a look at SUSE Studio, Manager and Build Service
- OFOR7540 – Software Defined Storage / Ceph Round Table
- FUT8701 – The Big Picture: How the SUSE Management, Cloud and Storage Products Empower Your Linux Infrastructure
- CAS7994 – Ceph distributed storage for the cloud, an update of enterprise use-cases at BMW
Update: for those who were hoping for an actual food recipe, please see this discussion.
Is anyone still using PPP at all?
So there are two possible reasons:
- nobody is testing -rc kernels
- nobody is using PPP anymore
Switching from syslog-ng to rsyslog - it's easier than you might think
Many people actually will not care who is taking care of their syslog messages, but since I had done a few customizations to my syslog-ng configuration, I needed to adapt those to rsyslog.
Now with Bug 899653 - "syslog-ng does not get all messages from journald, journal and syslog-ng not playing together nicely" which made it into openSUSE 13.2, I had to reconsider my choice of syslog daemon.
Basically, my customizations to syslog-ng config are pretty small:
- log everything from VDR in a separate file "/var/log/vdr"
- log everything from dnsmasq-dhcp in a separate file "/var/log/dnsmasq-dhcp"
- log stuff from machines on my network (actually usually only a VOIP telephone, but sometimes some embedded boxes will send messages via syslog to my server) in "/var/log/netlog"
2014-11-10T13:30:15.425354+01:00 susi rsyslogd: ...
$template myFormat,"%timegenerated:1:4:date-rfc3339%%timegenerated:6:7:date-rfc3339%%timegenerated:9:10:date-rfc3339%-%timegenerated:12:21:date-rfc3339% %syslogtag%%msg%\n"
$ActionFileDefaultTemplate myFormat
20141110-13:54:23.0 rsyslogd: ...
if $programname == 'dnsmasq-dhcp' then {
-/var/log/dnsmasq-dhcp
stop
}
if $programname == 'vdr' then {
-/var/log/vdr
stop
}
$ModLoad imudp.so # provides UDP syslog reception
$UDPServerRun 514 # start syslog server, port 514
if $fromhost-ip startswith '192.168.' then {
-/var/log/netlog
stop
}
Service Design Patterns in Rails: Request and Response Management
- Service Controller
- Data Transfer Object
- Request Mapper
- Response Mapper
@product = Product.find(params[:id])
end
end
end
end
openSUSE 13.2 – AMD Catalyst refurbished
Die offizielle AMD Catalyst Version 14.9 ist trotz diverser Tests nach wie vor auf openSUSE 13.2 nicht lauffähig. Diesbezüglich habe ich von der openSUSE Community jede Menge Anfragen erhalten, wann mit einer lauffähigen Version des proprietären Treibers zu rechnen ist. Zur Zeit hat AMD offiziell noch keine neue Version auf ihrer Webseite veröffentlicht, die mit dem neuen X-Server 1.16 auf openSUSE 13.2 laufen würde.
Durch einen Tipp eines User, wurde ich auf ein inoffizielles AMD Catalyst-Paket im Ubuntu-Repository aufmerksam gemacht, dass mit dem neuen X-Server laufen sollte. Diese Version basiert noch auf einem Entwicklungszweig von AMD Catalyst 14.6. Mit großer Hoffnung ging ich an die Sache heran, um den Treiber für openSUSE 13.2 fit zu machen. Hierzu muss ich bereits das neue Packaging Skript zum Bau der RPMs einsetzen, weil das alte Packaging Skript mit der neueren openSUSE-Version auf Grund der neuen Gegebenheiten bzgl. der Struktur des X-Servers (Stichwort: update-alternatives) nicht mehr kompatibel ist.
Nach Fertigstellung des neuen makerpm-amd-Skript und diversen Tests kann ich mit Freude bestätigen, dass die refurbished-Variante von AMD Catalyst auch auf openSUSE 13.2 läuft. Ein Patch für neuere Kernel-Versionen bis einschließlich 3.18 habe ich ebenfalls eingepflegt. Zudem habe ich bewusst AMD Catalyst 14.9 als Basis genommen und die Dateien vom AMD Catalyst-Paket aus dem Ubuntu-Repository ersetzt. Die Paketversion bzw. Treiberversion bleibt weiterhin 14.301.1001, jedoch wird sie intern als 14.201.1006.1002 genannt. Lediglich die Revisionsnummer vom Paket habe ich auf 99 erhöht, um ein problemloses „Updaten“ auf die refurbished-Version bei einem Distributionsupgrade zu ermöglichen.
Wichtiger Hinweis: AMD Catalyst wird in 5 RPM-Paketen (fgrlx-core, fglrx-graphics, fglrx-amdcccle, fglrx-opencl, fglrx-xpic) aufgeteilt und installiert. In Zukunft wird es möglich sein, nur bestimmte fglrx-Pakete zu installieren. Momentan werden über das makerpm-amd-Skript alle Pakete gebaut und auf Wunsch direkt installiert. Fairerweise muss ich darauf hinweisen, dass die Deinstallationsroutine im makerpm-amd-Skript wegen Inkompatibilität zur Zeit deaktiviert ist und noch überarbeitet werden muss. Der Treiber kann trotzdem über zypper oder YaST entfernt werden, falls es notwendig sein sollte.
[UPDATE 10.11.2014]
Das makerpm-amd-Skript wurde aktualisiert und läuft jetzt auch auf openSUSE Tumbleweed.
[/UPDATE 10.11.2014]
Downloads:
Die Installationsanleitung für das o.g. Skript ist nach wie vor gültig:
http://de.opensuse.org/SDB:AMD/ATI-Grafiktreiber#Installation_via_makerpm-amd-Skript
Installation guide for the above-mentioned script is still valid:
http://en.opensuse.org/SDB:AMD_fglrx#Building_the_rpm_yourself
Home server updated to 13.2
- dnsmasq does not log to syslog anymore -- this is bug 904537 now
- wwoffle did not want to start because the service file is broken, this can be fixed by adding "-d" to ExecStart and correcting the path of ExecReload to /usr/bin instead of /usr/sbin (no bugreport for that, the ExecStart is already fixed in the devel project and I submitrequested the ExecReload fix. Obviously nobody besides me is running wwwoffle, so I did not bother to bugreport)
- The apache config needed a change from "Order allow,deny", "Allow from all" to "Require all granted", which I could find looking for changes in the default config files. Without that, I got lots of 403 "Permission denied" which are now fixed.
- mysql (actually mariadb) needed a "touch /var/lib/mysql/.force_upgrade" before it wanted to start, but that's probably no news for people actually knowing anything about mysql (I don't, as you might have guessed already)
- My old friend bug 899653 made it into 13.2 which means that logging from journal to syslog-ng is broken ("systemd-journal[23526]: Forwarding to syslog missed 2 messages."). Maybe it is finally time to start looking into rsyslog or plain old syslogd...
- owncloud
- gallery2
- vdr
- NFS server
- openvpn

ownCloud Client 1.7.0 Released
Yesterday we released ownCloud Client 1.7.0. It is available via ownCloud’s website. This client release marks the next big step in open source file synchronization technology and I am very happy that it is out now.
The new release brings two lighthouse features which I’ll briefly describe here.
Overlay icons
For the first time, this release has a feature that lives kind of outside the ownCloud desktop client program. That nicely shows that syncing is not only a functionality living in one single app, but a deeply integrated system add-on that affects various levels of desktop computing.
 Here we’re talking about overlay icons which are displayed in the popular file managers on the supported desktop platforms. The overlay icons are little additional icons that stick on top of the normal file icons in the file manager, like the little green circles with the checkmark on the screenshot.
Here we’re talking about overlay icons which are displayed in the popular file managers on the supported desktop platforms. The overlay icons are little additional icons that stick on top of the normal file icons in the file manager, like the little green circles with the checkmark on the screenshot.
The overlays visualize the sync state of each file or directory: The most usual case that a file is in sync between server and client is shown as a green checkmark, all good, that is what you expect. Files in the process of syncing are marked with a blue spinning icon. Files which are excluded from syncing show a yellow exclamation mark icon. And errors are marked by a red sign.
What comes along simple and informative for the user requires quite some magic behind the curtain. I promise to write more about that in another blog post soon.
Selective Sync
Another new thing in 1.7.0 is the selective sync.
In ownCloud client it was always possible to have more than one sync connection. Using that, users do not have to sync their entire server data to one local directory as with many other sync solutions. A more fine granular approach is possible here with ownCloud.
 For example, mp3’s from the Music dir on the ownCloud go to the media directory locally. Digital images which are downloaded from the camera to the “photos” dir on the laptop are synced through a second sync connection to the server photo directory. All the other stuff that appears to be on the server is not automatically synced to the laptop which keeps it organized and the laptop harddisk relaxed.
For example, mp3’s from the Music dir on the ownCloud go to the media directory locally. Digital images which are downloaded from the camera to the “photos” dir on the laptop are synced through a second sync connection to the server photo directory. All the other stuff that appears to be on the server is not automatically synced to the laptop which keeps it organized and the laptop harddisk relaxed.
While this is of course still possible we added another level of organization to the syncing. Within existing sync connections now certain directories can be excluded and their data is not synced to the client device. This way big amounts of data can be easier organized depending on the demands of the target device.
To set this up, check out for the button Choose what to Sync on the Account page. It opens the little dialog to deselect directories from the server tree. Note that if you deselect a directory, it is removed locally, but not on the server.
What else?
There is way more we put into this release: A huge amount of bug fixes and detail improvements went in. Fixes for all parts of the application: Performance (such as database access improvements), GUI (such as detail improvements for the progress display), around the overall processing (like how network timeouts are handled) and the distribution of the applications (MacOSX installer and icons), just to name a few examples. Also a lot of effort went into the sync core where many nifty edge cases were analyzed and better handled.
Between version 1.6.2 and the 1.7.0 release more than 850 commits from 15 different authors were pushed into the git repository (1.6.3 and 1.6.4 were continued in the 1.6 branch which commits are also in the 1.7 branch). A big part of these are bug fixes.
Who is it?
Who does all this? Well, there are a couple of brave coders funded by the ownCloud company working on the client. And we do our share, but not everything. Also coding is only one thing. If you for example take some time and read around in the client github repo it becomes clear that there are so many people around who contribute: Reporting bugs, testing again and again, answering silly looking questions, proposing and discussing improvements and all that (yes, and finally coding too). That is really a huge block, honestly.
Even if it sometimes becomes a bit heated, because we can not do everything fast enough, that still is motivating. Because what does that mean? People care! For the idea, for the project, for the stuff we do. How cool is that? Thank you!
Have fun with 1.7.0!
Ruby packaging next
Taking ruby packaging to the next level
Table of Content
- TL;DR
- Where we started
- The basics
- One step at a time
- Rocks on the road
- “Job done right?” “Well almost.”
- Whats left?
TL;DR
- we are going back to versioned ruby packages with a new naming scheme.
- one spec file to rule them all. (one spec file to build a rubygem for all interpreters)
- macro based buildrequires. %{rubygem rails:4.1 >= 4.1.4}
- gem2rpm.yml as configuration file for gem2rpm. no more manual editing of spec files.
- with the config spec files can always be regenerated without losing things.
Where we started
A long time ago we started with the support for building for multiple ruby versions, actually MRI versions, at the same time. The ruby base package was in good shape in that regard. But we had one open issue - building rubygems for multiple ruby versions. This issue was hanging for awhile so we went and reverted to a single ruby version packaged for openSUSE again.
Service Design Patterns in Rails: Client-Service Interaction styles
Anyway, I started reading it some days ago and while reading it, I've been trying to match the patterns described in it with what I know from having worked on Rails for the last few years. The examples in the book are Java and C#. It was a nice surprise to see that a typical Rails application already implements most of them, thus if you use Rails, you are already using them, the same way you use the MVC pattern.
Thus, today I'll write a post on how Rails implements the Client-Service Interaction Styles patterns described in this book. Hopefully, I won't put the book back to the shelf for more dust and this post will be followed by other posts on the other patterns.
Client-Service Interaction Styles patterns are:
- Request/Response
- Request/Acknowledge
- Media Type Negotiation
- Linked Service
Request/Response
This is the simplest pattern and the default one. The Request/Response is nothing more than sending a Response to a Request. For example, if we take the typical Rails example application for maintaining a Product, the product controller would contain:
class ProductsController < ApplicationController
def index
@products = Product.all
end

Decade of Experience and some [un]wise words
Here are some things that I have learned in the last 10 years. Some of them may apply to you. Some of them may not. Choose at your own will. If you are interested in becoming a [product|project] manager, the following may not be helpful, but if you intend to stay a developer, it may be useful.
- In big companies, It is easier to do things and ask for excuse than to wait for permission, for trying radical changes or new things. There will always be people in the hierarchy to stop you from trying anything drastic, due to risk avoidance. Think how much performance benefits read-ahead gives; professional life is not much different. Do things without bothering about if your work will be released/approved.
- Prototype a lot. What you cannot play around with in production/selling codebases, you can, in your own prototypes. Only when you play around enough, you will understand the nuances of the design.
- Modern technologies get obsolete faster. People who knew just C program can still survive. But people who knew Angular 1.0 may not survive even Angular 2.0 Keep updating yourself if you want to be in the technology line for long
- Do not become a blind fan of any technology / programming language / framework. There is no Panacea in software.
- When one of my colleagues once asked a senior person for an advice, he suggested: "God gave you two ears and one mouth, use them proportionately". I second it, with an addendum, "Use your two eyes to read" also.
- Grow the ability to zoom in and out to high/low levels as the situation demands. For example, you should know to choose between columnar or row based storage AND know about CPU branch prediction AND have the ability to switch to both of these depths at will, as the situation demands. Having a non-theoretical, working knowledge of all layers will make you a better programmer. There is even a fancy title for this quality, full-stack programmer.
- Best way to know if you have learnt something well, is to teach it. Work with a *small* group of people with whom you can give techtalks and discuss your research interests. Remember the african proverb, If you want to go fast, go alone. If you want to go far, go together. Having a study groups helps a lot. But remember, talk is cheap and don't get sucked into becoming a theoretician. If you are interested in becoming one, get a job as a lecturer and work on hard problems. Look to Andy Tanenbaum or Eric Brewer for inspiration.
- Keep a diary or blog of what you have learned. You can assess yourself on an yearly basis and improve yourself. Create and use your github account heavily.
- Try different things and fail often. Failure is better than not-trying and being idle. When Rob Pike says, "I am not used to success", he is not merely being humble. It takes years of dedication, work, luck and a lot of failures to become successful and have a large / industry level impact.
- Do not be driven too much by money or promotion or job titles. The world does not remember Alan Turing or Edsger Dijkstra or Dennis Ritchie by their bank balance or positions. There are probably a thousand software architects in your locality if you dig linkedin. Try to do good work. Also learn to think like an author.
- Good work invariably will get appreciated, even if the appreciation may be delayed in many cases. Sloppy work will be noticed in the long term, even if it is missed in short term. The higher you grow, sloppy work may get more visibility.
- There will be people smarter and more talented than you, always. Try to learn from them. Sometimes they may be younger than you. Don't let age stop you.
- Work in an open source project with a very active community. Communication skills are very important even for an engineer. The best way to improve it for an engineer is to work on an open source project. Ideally, see through the full release of a linux distro. It will take you through all activities like packaging, programming, release management, marketing etc. the tasks which you may not be able to participate in your day job. I recommend openSUSE if you are looking for a suggestion ;)
- Except for Mathematics and Music, there is no other field with prodigies. Understand the myth of genius programmer.
- There are a lot of bad managers (at least in India). Most of these managers are bad at management, because they were lousy engineers in the first place and so decided to do an MBA and become a people manager, after which they don't have to code (at least in India). If you get one of them, do not try to fight them. Work with them on a monthly basis with a record of objectives and progresses. The sooner you get a bad manager, the better and faster you will appreciate good managers.
- Last but not least, identify a very large, audacious problem and throw yourself at it fully. All the knowledge that you have accumulated over the years with constant prototyping and reading will come in handy while solving it. In addition, you will learn a thousand other things, which you could not have learned by lazily building knowledge by reading alone. But the goal that you need to work on has to be audacious (like the goals that gave us Google filesystem or AWS etc.) and solve a very big problem. However, you should start this only after a few years of building a lot of small things and have a full quiver. To become a good system-side programmer, you should have been a good userspace programmer. To become a good distributed systems developer, you should have used a distributed system, etc.