
 Member
Member Victorhck
VictorhckUnos cuantos trucos para la shell fish que quizás no conocías
Si usas la shell fish en tu distribución GNU/Linux, estos trucos y atajos de teclados te resultarán muy útiles y quizás no los conocías
Desde que hice el cambio de shell de Bash a Fish no he vuelto atrás, salvo para scripts, aunque he de reconocer que el scripting de fish tiene algunas cosas mejores y más intuitivas que bash.
Por el blog he escrito varios artículos sobre Fish, y en este caso quiero compartir unos cuantos trucos propios de fish que te harán el trabajo en la terminal mucho más rápido y llevadero, seguro que alguno lo incorporas a tu día a día.
Ir al directorio anterior y siguiente
Para regresar y volver entre directorios que hemos visitado tenemos estas dos opciones:
-
Alt + ←Para ir al directorio anterior -
Alt + →Para ir al directorio siguiente
Imaginemos que desde nuestro directorio /home vamos a estos directorios:
~/> cd Git/repositorio1
~/Git/repositorio1> cd ../repositorio2
~/Git/repositorio2>
Mediante el uso de los dos atajos de teclados anteriores, podremos desplazarnos entre los directorios visitados, sin necesidad de volver a escribir la ruta, simplemente navegando hacia adelante y atrás de una manera más rápida.
Paginador automático
En ocasiones usamos el comando cat para ver contenido de un archivo, pero nos lo muestra entero, por lo que si es muy largo habrá partes que no podamos ver.
Para eso sirve un paginador, para poder tener el control del archivo que mostramos con cat. Para usarlo escribimos cat archivo y pulsamos el atajo de teclado Alt + p.
¿Qué hace este comando?
Si no sabemos exactamente lo que realiza un comando, y queremos que nos muestre una información muy básica de para qué sirve (muestra la primera línea de la página man del comando) tenemos el atajo de teclado Alt + w
Escribimos el comando y con el cursor todavía al final del comando ejecutamos el atajo de teclado.
Abre tu editor
Si escribes en una terminal echo $EDITOR verás el editor que tienes configurado en tu sistema (en el mío es Vim ¿lo conoces?). Si alguna vez lo queremos abrir rápidamente, bastará con ejecutar Alt + e
Ejecutar el comando anterior como sudo

A veces ejecutamos como un usuario normal un comando que debería tener privilegios de superusuario. Solemos soltar un taco y tal como muestra la imagen podemos ejecutar sudo !!
Con !! ejecutamos el último comando que hayamos ejecutado (valga la redundancia), así que le anteponemos sudo. Peeeeero si usamos fish tenemos el atajo de teclado Alt + s que automáticamente nos antepone sudo al comando anterior en una nueva línea para ejecutarlo. ¡Pruébalo!
¿Usas Fish y conocías estos atajos de teclado? Te aconsejo que los pruebes en tu terminal y te vayas acostumbrando a su uso, verás que alguno te será de gran utilidad en muchas tareas.
Comparte tu experiencia con fish y con estos atajos en los comentarios.

Mide el consumo de tu pantalla con Power Monitor – Plasmoides de KDE (206)
Complementando KDE Eco, el proyecto de la Comunidad que quiere crear software más sostenible, os presento un plamoide que mide el consumo de tu pantalla con Power Monitor, el widget 206 para presentado en el blog y que nos puede ayudar para tener más conocimiento sobre nuestros dispositivos.
Mide el consumo de tu pantalla con Power Monitor – Plasmoides de KDE (206)
Llevo diciéndolo varios artículo, por norma general los plasmoides sirven para decorar, ampliar funcionalidades o proporcionar información que nuestro sistema tiene de su funcionamiento.
Hoy toca hablar del último caso del párrafo anterior ya que Power Monitor, un plasmoide creado por Atul-g, que mide el consumo de energía de tu monitor o pantalla de trabajo, con lo que eres más consciente del gasto energético que realizas.

Y como siempre digo, si os gusta el plasmoide podéis “pagarlo” de muchas formas en la cambiante página de KDE Store, que estoy seguro que el desarrollador lo agradecerá: puntúale positivamente, hazle un comentario en la página o realiza una donación. Ayudar al desarrollo del Software Libre también se hace simplemente dando las gracias, ayuda mucho más de lo que os podéis imaginar, recordad la campaña I love Free Software Day 2017 de la Free Software Foundation donde se nos recordaba esta forma tan sencilla de colaborar con el gran proyecto del Software Libre y que en el blog dedicamos un artículo.
Más información: KDE Store
¿Qué son los plasmoides?
Para los no iniciados en el blog, quizás la palabra plasmoide le suene un poco rara pero no es mas que el nombre que reciben los widgets para el escritorio Plasma de KDE.
En otras palabras, los plasmoides no son más que pequeñas aplicaciones que puestas sobre el escritorio o sobre una de las barras de tareas del mismo aumentan las funcionalidades del mismo o simplemente lo decoran.
La entrada Mide el consumo de tu pantalla con Power Monitor – Plasmoides de KDE (206) se publicó primero en KDE Blog.
Nueva charla y taller «Install Party» en Carcaixent (València) organizada por Asociació Emancipació Comunitaria
Me congratula promocionar una nueva charla y taller «Install Party» en Carcaixent (València) organizada por Asociació Emancipació Comunitaria, con la colaboración de la Asociación GNU/Linux València. Se trata de una nueva edición de la que ya han reallizado algunas ediciones Más información, sigue leyendo.
Nueva charla y taller «Install Party» en Carcaixent (València) organizada por Asociació Emancipació Comunitaria

Todo vuelve a la normalidad en cuanto a actividades presenciales de la comunidad GNU/Linux, eso sí, con todas las medidas de seguridad que sean necesarias y precauciones para no correr más riesgo de lo necesario.
Es por ello que me complace compartir con vosotros un nuevo evento del grupo de personas que en València está impulsado el Software Libre y temas relacionados con el empoderamiento de la sociedad que lleva por nombre Asociació Emanciació Comunitaria, que podéis encontrar en su Grupo y Canal de Telegram.
Es por ello que os invito a la nueva charla y taller «Install Party» en Carcaixent (València) que se va a realizar el próximo sábado 22 de octubre organizado conjuntamente con Mercat 10 (https://t.me/mercat10) y la Asociación GNU/Linux València.

De esta forma se han organizado varias actividades:
- 10:00 h: Charla sobre el Software Libre, donde se explicará la importancia del software libre en una comunidad con democracia real
- 17:00 h: Taller Install Party, al que podréis LLEVAR VUESTRO EQUIPO y os ayudaremos a instalar un Sistema Operativo COMPLETAMENTE LIBRE!!. Además de otras herramientas. que nos permiten independencia de aquellas controladas por instituciones, empresas y estados.
Resumiendo, la información básica es:
- Fecha: sábado, 22 de octubre de 2022
- Horario: A partir de las 10:00
- Lugar: Mercat 10 Carcaixent
- ¿Registro necesario? Si, plazas limitadas. Reserva en los siguientes teléfono 601219700 (Pasqual)
Si podéis asistir no os lo perdáis, seguro que no quedáis decepcionados.
Mas información: GNU/Linux València
La entrada Nueva charla y taller «Install Party» en Carcaixent (València) organizada por Asociació Emancipació Comunitaria se publicó primero en KDE Blog.

Run a Booth, Increase Awareness of openSUSE
The openSUSE community is filled with tons of volunteers, professionals and hobbyists who contribute to the project and want to see it thrive.
One of the ways of doing this is to organize an openSUSE booth for an event.
Recently, security engineer Paolo Perego did this at an event in Rome called RomHack Camp. Perego learned quite a lot at the event that took place Sept 23 - 25 and shared his experience about the hacker camp on the openSUSE Project mailing list.
Perego wrote that people at the conference were surprised to see an operating system vendor having a booth and was able to let them know that openSUSE is also a project full of tools for open-source development.
“The people who previously heard about us thought that we produce a ‘derived’ distribution,” Perego wrote in a report to the community. “I explained that we use rpm, that we started back then like Slackware fork in the very early stages..
“Now (we) have our own identity, brand and added value services.”
In addition to Perego encouraging community members to reach out to contact newspaper, tech journalists and youtubers to promote openSUSE, he encouraged community members to take action.
“Most of the people who came to our booth were not aware of the existence of… openSUSE,” he wrote. “Perhaps if we participate in more events like this (it) can be the first step in changing that.”
Members can learn more about organizing an openSUSE booth on the project’s wiki page.
Along with its many distributions, openSUSE has several open-source tools like YaST, Open Build Service, openQA and several more for open-source developers and hobbyists.

Emoji Selector App on KDE Plasma
Upgrading openSUSE Leap with zypper-upgradedistro
7 hábitos para una edición de texto más eficiente con el editor Vim
Aquí tienes unos consejos recopilados en 7 hábitos para editar texto de una manera más eficiente usando el editor de texto Vim según su creador Bram Moolenaar

Comparto por el blog la traducción que he realizado del artículo «Vim: Seven habits of effective text editing» escrito por Bram Moolenaar, el creador y desarrollador principal del editor Vim, en noviembre de 2000.
En el texto, Bram comparte algunos consejos para utilizar el editor de texto (enfocado a Vim) de una manera más eficiente con tres sencillos pasos y siete hábitos de edición. También tu puedes ahorrarte trabajo con el editor Vim.
Este artículo es una nueva entrega del curso “improVIMsado” que desde hace meses vengo publicando en mi blog sobre el editor Vim y que puedes seguir en estos enlaces:
- https://victorhckinthefreeworld.com/tag/vim/
- https://victorhck.gitlab.io/comandos_vim/articulos.html
Y para aprender Vim (de la manera más inteligente) aquí tienes esta útil guía:

Si pasas mucho tiempo escribiendo texto sin formato, escribiendo programas o código HTML, puedes ahorrar mucho de ese tiempo utilizando un buen editor y usándolo de manera efectiva. Este artículo te mostrará pautas y trucos para hacer tu trabajo de una manera más rápida y con menos errores.
El editor de texto de código abierto Vim (Vi IMproved) será el utilizado aquí para presentar las ideas de una edición más efectiva, pero también se aplican a otros editores. Escoger el editor adecuado es, en realidad, el primer paso hacia una edición de texto más efectiva.
Parte 1: Editar un archivo
1. Muévete con rapidez
La mayor parte del tiempo se emplea en leer, comprobar errores y buscar el lugar adecuado en el que trabajar, en vez de insertar nuevo texto o en cambiarlo. Navegar por el texto, es una tarea que se realiza a menudo, por tanto deberías aprender cómo hacerlo de manera rápida.
Es muy frecuente que quieras buscar algún texto que sabes que está por ahí. O buscar todas las líneas de texto donde aparece cierta palabra o frase. Simplemente puedes utilizar el comando /patrón para encontrar el texto deseado, pero hay maneras más interesantes:
- Si ves una palabra en especial y quieres buscar dónde otras sitios donde se utilice la misma palabra, utiliza el comando
*. Tomará la palabra que se encuentre debajo del cursor y buscará la siguiente. - Si activas la opción
incsearch, Vim mostrará la primera coincidencia del patrón buscado, mientras la estés escribiendo. Esto ayuda a mostrar rápidamente si se produce algún error en el patrón. - Si activas la opción
hlsearch, Vim resaltará todas las coincidencias del patrón marcándolas con un fondo amarillo. Esto da un rápido vistazo de dónde te llevará el comando de búsqueda. En un texto de un código, sirve para mostrar dónde es utilizada una variable. No es necesario mover el cursor para ver todas las coincidencias.
En texto estructurado hay incluso más posibilidades de moverse de una manera rápida por el texto. Vim tiene comandos específicos para programas en C (y lenguajes similares como C++ y Java):
- Utiliza
%para saltar de un la apertura de un paréntesis a su pareja de cierre. O de un «#if» a su pareja «#endif». De hecho,%puede saltar a diferentes parejas de elementos. Es muy útil comprobar si las construcciones () y {} están equilibradas correctamente. - * Utiliza
[{para volver al «{» del comienzo del bloque de código actual. - * Utiliza
gdpara saltar del uso de una variable a su declaración local en el archivo.
Por supuesto existen muchos más. La cuestión es que necesitas aprender estos comandos.
Podrías objetar que no es posible que aprendas todos estos comandos, (hay cientos de comandos de movimientos diferentes, algunos simples, otros más inteligentes) y que te llevaría semanas de entrenamiento aprenderlos todos.
Bueno, no necesitas hacerlo, en vez de eso, identifica cual es tu forma específica de editar y aprender solo esos comandos que hacen que tu edición de texto sea más efectiva.
Hay tres pasos básicos:
- 1. Mientras estás editando, permanece atento en las acciones que repites y/o en las que pasas mucho tiempo.
- 2. Busca si existe un comando en el editor que haga esa acción de una manera más rápida. Lee la documentación, pregunta a un amigo o busca cómo otras personas hacen eso.
- 3. Entrena utilizando el comando. Hazlo hasta que tus dedos escriban el comando sin necesidad de pensarlo.
Vamos a utilizar un ejemplo para mostrar cómo funciona:
1. Te encuentras que cuando estás editando archivos de programas en lenguaje C, a menudo dedicas mucho tiempo a buscar dónde está definida una función. Actualmente utilizas el comando * para buscar otros lugares en los que aparece el nombre de la función, pero acabas pasando por un montón de coincidencias en donde la función es utilizada en vez de dónde está definida. Llegas a la conclusión de que debe haber una manera más rápida de hacer esto.
2. Echando un vistazo a la guía rápida, encuentras un comentario sobre saltar a etiquetas. La documentación muestra cómo puede utilizarse esto para saltar a la definición de una función, ¡justo lo que estabas buscando!
3. Experimentas un poco con la generación de un archivo de etiquetas, utilizando el programa ctags que viene incluido en Vim. Aprendes a utilizar el comando CTRL-] y te das cuenta que al usarlo te ahorra mucho tiempo. Para hacerlo más sencillo, añades unas cuantas líneas a tu archivo Makefile para generar de manera automática el archivo de etiquetas.
Un par de cosas a considerar cuando sigas estos tres pasos:
- «Quiero hacer el trabajo, no tengo tiempo para ir mirando la documentación para encontrar algún comando nuevo». Si piensas así, te quedarás estancado en la edad de piedra de la computación. Algunas personas utilizan Notepad para todo, y después se preguntan por qué otras personas hacen su trabajo en la mitad de tiempo…
- No te excedas. Si siempre tratas de encontrar el comando perfecto para cada pequeña cosa que haces, tu mente no tendrá tiempo para pensar en el trabajo que estabas haciendo. Simplemente escoge aquellas acciones que te llevan más tiempo del necesario y entrena los comandos hasta que no necesites pensar en ello cuando los uses. Así puedes concentrarte en el texto.
En las siguientes secciones encontrarás sugerencias de acciones con las que la mayoría de la gente tiene que lidiar. Puedes usarlas como inspiración para usar los tres pasos básicos para tu propio trabajo.
2. No lo escribas dos veces
Hay un número limitado de palabras que escribimos. E incluso un número limitado de párrafos o frases. Especialmente en los programas de ordenador. Obviamente, no querrás escribir lo mismo dos veces.
A menudo querrás cambiar simplemente una palabra por otra. Si esto hay que hacerlo en todo el archivo, puedes utilizar el comando :s (sustituir). Si únicamente es necesario cambiarlo en algunos casos, un método más rápido es utilizar el comando * para encontrar la siguiente coincidencia de la palabra y utilizar cw para cambiar la palabra. Después escribir n para encontrar la siguiente palabra y . (punto) para que repita el comando anterior cw.
El comando . repite el último cambio. Un cambio, en este contexto, se refiere a insertar, borrar o reemplazar un texto. Poder repetir esta acción es una utilidad muy potente. Si organizas tu edición de texto en torno a ello, muchos cambios se convertirán simplemente en pulsar únicamente la tecla . para realizar los cambios. Ten cuidado si haces otros cambios entre medias, porque el comando reemplazará el cambio que estabas repitiendo. En su lugar, quizás te podría interesar marcar la ubicación usando el comando m, continuar con tu cambio repetido y regresar más tarde a esa ubicación para cambiar lo que fuera necesario.
Algunos nombres de funciones o de variables pueden ser muy complicadas de escribir. ¿Puedes escribir rápidamente «XpmCreatePixmapFromData» sin ningún error y sin volver a revisar cómo se escribe? Vim tiene una utilidad de completado automático que hace que eso sea sencillo.
Busca palabras en el archivo que estás editando, y también en los archivos #include. Puedes escribir «XpmCr» y después pulsar CTRL-N y Vim la completará a «XpmCreatePixmapFromData» para ti. No solo hacer esto te ahorra mucho tiempo de escritura, también evita que cometas errores y tener que solucionarlos más tarde cuando el compilador te muestre un mensaje de error.
Cuando estás escribiendo una frase o una oración muchas veces, hay incluso una manera más rápida de hacerlo. Vim tiene una utilidad con la que grabar una macro. Escribe qa para empezar a grabar la macro en el registro ‘a’.
Después escribes tus comandos de manera normal y para finalizar pulsas q de nuevo para detener la grabación de la macro. Cuando quieras repetir la macro grabada, simplemente escribe @a. Hay 26 registros disponibles para esto.
En la grabación de la macro puedes repetir muchas acciones diferentes, no solo insertar texto. Ten esto en cuenta cuando sepas que vas a repetir algo.
Una cosa a tener en cuenta cuando grabes una macro, es que los comandos serán repetidos exactamente como los escribiste. Cuando te muevas por el texto, debes tener en cuenta que el texto por el que te muevas podría ser diferente cuando el comando sea repetido al reproducir la macro.
Moverse cuatro caracteres a la izquierda podría funcionar en el texto donde estás grabando la macro, pero podrían ser cinco caracteres cuando se repitan los comandos. A menudo es necesario utilizar comandos para moverse por los diferentes textos (palabras, frases) o moverse a un caracter específico.
Cuando los comandos que necesitas repetir se van haciendo más complejos, escribirlos bien a la primera se vuelve más difícil. En vez de grabarlos, deberías escribir un script o una macro. Esto es muy útil para crear plantillas para partes de tu código, por ejemplo, la cabecera de una función. Puedes hacer esto, tan inteligente como quieras.
3. Arréglalo cuando esté mal
Es normal cometer errores al escribir. Nadie puede evitarlo. El truco consiste en detectarlos y corregirlos rápidamente. El editor debería poder ayudarte con esto. Pero necesitas decirle lo que está mal y lo que está bien.
A menudo cometerás los mismos errores una y otra vez. Tus dedos simplemente no hacen lo que quieres. Esto puede corregirse con las abreviaturas. Veamos algunos ejemplos:
:abbr Lunix Linux:abbr accross across:abbr hte the
Las palabras se corregirán de manera automática después de que las hayas escrito.
El mismo método puede ser utilizado para escribir una palabra larga, escribiendo únicamente unos pocos caracteres. Es especialmente útil para palabras que te resultan difíciles de escribir y así evitar escribirlas mal. Algunos ejemplos:
:abbr pn pingüino:abbr MS Mandrake Software
Sin embargo, este método tiende a expandir la palabra completa cuando quizás no lo necesitas, lo que hace difícil saber cuándo realmente quieres únicamente escribir «MS» en tu texto. Es mejor utilizar palabras cortas que por sí mismas no tengan significado propio.
Para encontrar errores en tu texto, Vim tiene un método inteligente de resaltado. En realidad, esto estaba destinado a ser utilizado para resaltar la sintaxis de los programas, pero también puede detectar y resaltar errores.
El resaltado de sintaxis muestra los comentarios en color. Esto no parece una funcionalidad muy importante, pero una vez que comienzas a utilizarlo, verás que se convierte en una gran ayuda. Rápidamente puedes localizar texto que debería ser un comentario, pero no está resaltado como debería (quizás olvidaste añadir el marcador que indica que es un comentario).
O viste una línea de código resaltada como un comentario (olvidaste insertar un «*/*»). Estos son los errores que son difíciles de localizar en un texto simplemente en blanco y negro y que pueden hacer que pierdas mucho tiempo tratando de depurar el código.
El resaltado de sintaxis, también puede encontrar paréntesis a los que le falta una pareja. Un paréntesis «)» sin pareja de apertura, es resaltado con un fondo rojo. Puedes utilizar el comando % para ver cómo coinciden e insertar un «(» o «)» en la posición correcta.
Otros errores comunes también se detectan rápidamente, por ejemplo, usar «#included <stdio.h>» en lugar de «#include <stdio.h>». Es fácil pasar por alto el error en blanco y negro, pero rápidamente se da cuenta de que «include» está resaltado mientras que «included» no lo está.
Un ejemplo más complejo: para el texto en inglés hay una larga lista de todas las palabras que se usan. Cualquier palabra que no esté en esta lista podría ser un error. Con un archivo de sintaxis se pueden resaltar todas las palabras que no están en la lista. Con algunas macros adicionales, se pueden agregar palabras a la lista de palabras, para que ya no se marquen como un error. Esto funciona tal como cabría esperar en un procesador de textos.
En Vim, se implementa con scripts y se pueden ajustar aún más para tu propio uso: por ejemplo, para verificar solo los comentarios en un programa en busca de errores ortográficos.
Parte 2: Editar más archivos
4. Un archivo rara vez viene solo
La gente no trabaja en un solo archivo. En su mayoría, hay muchos archivos relacionados y se editan varios uno tras otro, o incluso varios al mismo tiempo. Deberías poder aprovechar tu editor para hacer que trabajar con varios archivos sea más eficiente.
El método de las etiquetas mencionado anteriormente, también funciona para saltar entre archivos. La uso más normal, es generar un archivo de etiquetas para el proyecto completo en el que estés trabajando. Puedes saltar rápidamente entre todos los archivos del proyecto para encontrar las definiciones de funciones, estructuras, tipos de definiciones, etc.
El tiempo ahorrado frente a la búsqueda manual es inmenso, crear un archivo de etiquetas es la primera cosa que hago cuando estoy navegando por unprograma.
Otro método muy potente, es encontrar todas las ocurrencias de un nombre en un grupo de archivos, utilizando el comando :grep. Vim realiza una lista de todas las coincidencias, y salta a la primera. Con el comando :cn te llevará a cada una de las siguientes coincidencias. Esto es muy útil cuando necesitas cambiar ek número de argumentos en la llamada de una función.
Los archivos Include contienen información útil. Pero encontrar el que contiene la declaración que necesitas ver, puede llevar mucho tiempo. Vim conoce los archivos include y puede buscar en ellos la palabra que buscas. La acción más común es buscar el prototipo de una función.
Coloca el cursor sobre el nombre de la función en su archivo y escribe [I: Vim mostrará una lista de todas las coincidencias para el nombre de la función en los archivos incluidos. Si necesita ver más contexto, puede saltar directamente a la declaración. Se puede usar un comando similar para verificar si incluyó los archivos de encabezado correctos.
En Vim puedes dividir el área en el que se muestra el texto en pantalla en varias partes para editar archivos diferentes. Así puedes comparar el contexto de dos o más archivos y copiar/pegar texto entre ellos. Hay muchos comandos para abrir y cerrar ventanas, saltar entre ellas, ocultar de manera temporal archivo, etc.
De nuevo deberás utilizar los tres pasos básicos que se mencionan al comienzo para seleccionar el grupo de comandos que quieres aprender a utilizar.
Hay más usos de ventanas múltiples. El método de previsualización de etiquetas es un muy buen ejemplo. Esto abre una ventana de visualización especial, mientras el cursor se mantiene en el archivo en el que estás trabajando. El texto en la ventana de previsualización muestra, por ejemplo, la declaración de la función para el nombre dela función que está bajo el cursor. Si mueves el cursor a otro nombre y lo mantienen durante un segundo, la ventana de previsualización ahora mostrará la definición de ese nombre. Podría ser también el nombre de una estructura o una función que está declarada en un archivo incluido en tu proyecto.
5. Trabajemos juntos
Un editor es para editar texto. Un programa de correo electrónico es para enviar y recibir correos electrónicos. Un sistema operativo es para ejecutar programas. Cada programa tiene su propia tarea y debería ser bueno haciéndola. La potencia llega cuando tenemos diferentes programas que pueden trabajar juntos.
Un ejemplo simple: Necesitas escribir un informe de no más de 500 palabras. Seleccionas el párrafo actual mediante la selección visual y lo escribes en el programa «wc»: vip:w !wc -w. El comando externo «wc -w» es utilizado para contar las palabra. ¿Fácil, no?
Siempre habrá alguna funcionalidad que necesites que no esté en el editor. Hacer posible filtrar texto con otro programa significa que puedes añadir esa funcionalidad de manera externa. Siempre ha sido el espíritu de Unix tener programas separados que hagan bien su trabajo y trabajen juntos para realizar una tarea más grande. Desafortunadamente, la mayoría de los editores no funcionan muy bien junto con otros programas.
Por ejemplo, no puedes reemplazar el editor de correo electrónico en Netscape por otro. Terminas usando un editor con pocas funcionalidades. Otra tendencia es incluir todo tipo de funcionalidades dentro del editor. Emacs es un buen ejemplo de dónde puede terminar eso. (Algunas personas lo llaman un sistema operativo que también se puede usar para editar texto).
Vim intenta integrarse con otros programas, pero esto sigue siendo una lucha. Actualmente es posible utilizar Vim como el editor en MS-Developer Studio y Sniff. Algunos programas de correo electrónico que admiten el uso de un editor externo, como Mutt, pueden utilizar Vim. La integración con Sun Workshop está en progreso. Generalmente esto es un área que tiene que ser mejorada en el futuro más cercano. Solo así conseguiremos un sistema que sea mejor que la suma de sus partes.
6. El texto es estructurado
A menudo trabajarás con texto que tienen algún tipo de estructura, pero diferente de lo que admiten los comandos disponibles. Así que, tendrás que recurrir a los «bloques de compilación» del editor y crear tus propias macros y complementos para trabajar con ese texto. Aquí ya estamos llegando a las cosas más complicadas.
Una de las cosas más simples es acelerar el ciclo de edición-compilación-solución. Vim tiene el comando :make, que inicia la compilación, comprueba los errores que produce y te permite saltar a la ubicación de esos errores para solucionar los problemas. Si utilizas un compilador diferente, los mensajes de error no se reconocerán.
En vez de regresar a antiguo sistema de «anotarlos a mano», deberías ajustar la opción ‘errorformat’. Esto le dice a Vim cuales son tus errores y cómo obtener el nombre del archivo y el número de línea de estos. Funciona para mensajes de error complicados de gcc, así que seguramente serías capaz de hacerlo funcionar en casi cualquier compilador.
A veces adaptarse a un tipo de archivos es únicamente una cuestión de ajustar algunas opciones o escribir algunas macros. Por ejemplo, para saltar a las páginas de manual, puedes escribir una macro que guarde la palabra bajo el cursor, limpie el buffer y después lea la página del manual para esa palabra en el buffer. Esa es una manera simple y eficiente de buscar referencias cruzadas.
Utilizando los tres pasos básicos, puedes trabajar de una manera más efectiva con cualquier tipo de archivo estructurado. Simplemente piensa en las acciones que quieres realizar con el archivo, encuentra los comandos del editor que lo hacen y comienza a utilizarlos. Es realmente tan simple como parece. Simplemente tienes que hacerlo.
Parte 3: Afilar la sierra
7. Conviértelo en un hábito
Aprender a conducir un coche conlleva esfuerzo. ¿Es esa una razón para seguir usando tu bicicleta? No, te das cuenta que necesitas invertir tiempo para aprender una nue
va habilidad. La edición de texto no es algo diferente. Necesitas aprender nuevos comandos y convertirlos en un hábito.
Por otra parte, no deberías tratar de aprender cada comando que ofrece un editor. Eso sería una completa pérdida de tiempo. La mayoría de personas sólo necesitan aprender un 10 o 20% de los comandos para sus trabajos. Pero es un conjunto de comandos diferentes para cada persona.
Es necesario que aprendas de vez en cuando y te preguntes si hay alguna tarea repetitiva que pudiera ser automatizada. Si realizas una tarea solo una vez y no crees que tengas que volver a realizarla de nuevo, no intentes optimizarla. Pero probablemente te des cuenta que estás repitiendo algo muchas veces a la hora. Entonces busca la documentación para encontrar el comando que haga eso deuna manera más rápida. O escribe una macro que la realice.
Cuando es una tarea más extensa, como alinear una clase especial de texto específico, podrías buscar en foros o por Internet para ver si alguien más ya lo solucionó antes que tu.
Los pasos básicos esenciales es la última parte. Puedes pensar en una tarea repetitiva, encontrar una solución idónea para ella y después del fin de semana olvidar cómo lo hiciste. Eso no funciona.
Tendrás que repetir la solución hasta que tus dedos lo hagan de forma automática. Solo entonces conseguirás el nivel de eficiencia que necesitas. No intentes aprender muchas cosas a la vez. Pero el realizar unas pocas cosas al mismo tiempo sí funcionará. Para conseguir que tus dedos se adapten con trucos que no utilizas a menudo, quizás deberías escribirlos para poder echarles un vistazo más tarde cuando los necesites.
De todas formas, si mantienes tu meta siempre a la vista, encontrarás maneras de hacer tu edición de texto más y más efectiva.
Un último consejo, para recordarte qué ocurre cuando las personas ignoran todo lo anterior. Todavía veo a gente que pasa la mitas de su día detrás de una pantalla, mirando a la pantalla y después a dos de sus dedos, de nuevo a la pantalla, etc. Y después se preguntan por qué se cansan tanto…
¡Escribe con diez dedos! No solo es más rápido, también es mucho menos cansado. Utilizando una programa para tu ordenador únicamente una hora al día, solo te llevará un par de semanas aprender a mecanografiar.
Epílogo
La idea para el título del artículo, proviene del exitoso libro «Los 7 hábitos de las personas altamente efectivas» de Stephen R. Covey. Lo recomiendo a quien quiera solucionar sus problemas personales y profesionales (¿y quién no quiere?).
Aunque algunas personas dirán que proviene del libro de Dilbert «Siete años de gente altamente defectuosa» del dibujante Scott Adams (¡también recomendado!). Más libros y CD recomendados en https://iccf-holland.org/click1.html.
Acerca del autor
Bram Moolenaar es el autor principal del editor Vim. Escribe las funcionalidades principales de Vim y selecciona qué código por otras personas es incluido. Se graduó en la Universidad Técnica de Delf como técnico de computadoras.
Ahora trabaja principalmente en software, pero todavía sabe cómo manejar un soldador. Es el fundador y tesorero de ICCF Holland, que ayuda a huérfanos en Uganda.
Hace trabajos freelance como arquitectura de sistemas, pero pasa la mayoría de su tiempo trabajando en Vim. Su dirección de correo electrónico es Bram arroba Moolenaar.net.

¡El primer prototipo de Adaptable Linux Platform (ALP) ya está disponible!
Ya puedes probar el primer prototipo de la nueva era de openSUSE ALP (Adaptable Linux Platform), la próxima generación de Linux

La introducción del nuevo proyecto ALP (Adaptable Linux Platform) a las comunidades de SUSE y openSUSE ha iniciado un esfuerzo para construir y diseñar una nueva plataforma centrada en aplicaciones, segura y flexible.
¿Qué es ALP?
Bueno, aunque no me ha quedado muy claro qué es el concepto detrás de ALP, ya que hay conceptos técnicos que se me escapan, quiero compartir la definición y noticias que ofrecen desde SUSE.
Adaptable Linux Platform (ALP) está cambiando de la estructura influenciada y centrada en el estilo UNIX de los sistemas operativos anteriores a un diseño más centrado en la aplicación y la carga de trabajo.
Está evolucionando una plataforma flexible y segura con conceptos avanzados, como se ve en proyectos como MicroOS y SLE Micro, junto con la incorporación de otros componentes. Esta plataforma está diseñada para crear, implementar y administrar fácilmente aplicaciones, independientemente del hardware o el entorno.
La separación de la habilitación de hardware en un sistema operativo host y una capa de aplicación (en contenedores) proporciona una plataforma inmutable para cargas de trabajo y entornos de tiempo de ejecución de cargas de trabajo.
Si bien la prueba de concepto de la plataforma Adaptable Linux no se proporciona con el escritorio, la adición del escritorio a ALP se realizará en las siguientes versiones.
Por tanto, la idea detrás de ALP es permitir que los usuarios se concentren en sus cargas de trabajo mientras se abstraen del hardware y la capa de aplicación. Con el uso de máquinas virtuales y tecnologías de contenedores, Adaptable Linux Platform permite que las cargas de trabajo sean independientes del flujo de código.
Les droites
«Les droites» es el primer prototipo de ALP. Las siglas de ALP, nombran a los Alpes, y de ahí escoger nombres de montañas de ese conjunto montañoso.
El primer prototipo viene con las siguientes características:
- Software: Salt preinstalado y Ansible disponible en repositorios, lo que permite a los usuarios configurar y/o administrar los sistemas ALP de manera flexible y ágil.
- Soporte de hardware: la línea de base de la arquitectura para ALP se establece en x86_64-v2. La consideración anterior de x86_64-v3 se rechazó después de la ronda de comentarios inicial. Estamos considerando el soporte de x86_64-v3 y posiblemente v4 a través de la funcionalidad hwcaps.
- Cifrado de disco completo
Les Droites viene en este primer prototipo con FDE (Full Disk Encryption). Aunque puede que no sea la solución definitiva, es un primer acercamiento y dependerá de las pruebas y la respuesta de la comunidad a esta elección.
FDE cifra el hardware en el disco duro, que cifra y descifra a medida que se accede a ellos; encontrar e implementar la mejor solución para una arquitectura para ALP es fundamental para el proyecto.
Aunque algunas cargas de trabajo todavía están en la fase de trabajo en progreso y siguen los principios de diseño de ALP, algunos componentes ya vienen en contenedores, como GDM o Yast2, y otros seguirán, como Cockpit.
En ALP, estos nuevos servicios en contenedores se conocen como WORKLOADS (CARGAS DE TRABAJO).
ALP pretende necesitar la menor cantidad de intervención posible. Esto utiliza algunas capacidades de autogestión, lo que le permite reconocer instantáneas estables y revertirlas si se encuentra algún comportamiento inesperado después de un parche. Esto asegura que mantiene el cumplimiento mediante la aplicación de parches de acuerdo con las cargas de trabajo y el uso del propio sistema.
Este prototipo viene con un primer acercamiento de las funciones de Autogestión y Zero Touch, se implementará completamente en los próximos lanzamientos.
Estas funcionalidades de autogestión serán configurables:
- Seguridad y actualizaciones periódicas
- Actualizaciones de seguridad
- Actualizaciones críticas de seguridad
- Solo descarga e instalación manual
- Sin actualizaciones automáticas
Estas políticas se pueden configurar para que se instalen según se requiera para adaptarse mejor a los usuarios y los componentes que utilizan ALP.
Probar ALP «Les Droites»
Tienes disponible ALP para descargar en este enlace:
Enlaces de interés
- https://www.suse.com/c/the-first-prototype-of-adaptable-linux-platform-is-live/
- https://www.suse.com/c/alp-prototype-is-evolving-proof-of-concept-expected-in-fall/
- https://documentation.suse.com/alp/all/html/alp/index.html
- https://news.opensuse.org/tag/adaptable-linux-platform

Recopilación del boletín de noticias de la Free Software Foundation – octubre de 2022
Recopilación y traducción del boletín mensual de noticias relacionadas con el software libre publicado por la Free Software Foundation.

La Free Software Foundation (FSF) es una organización creada en Octubre de 1985 por Richard Stallman y otros entusiastas del software libre con el propósito de difundir esta filosofía.
La Fundación para el software libre (FSF) se dedica a eliminar las restricciones sobre la copia, redistribución, entendimiento, y modificación de programas de computadoras. Con este objeto, promociona el desarrollo y uso del software libre en todas las áreas de la computación, pero muy particularmente, ayudando a desarrollar el sistema operativo GNU.
Además de tratar de difundir la filosofía del software libre, y de crear licencias que permitan la difusión de obras y conservando los derechos de autorías, también llevan a cabo diversas campañas de concienciación y para proteger derechos de los usuarios frentes a aquellos que quieren poner restricciones abusivas en cuestiones tecnológicas.
Mensualmente publican un boletín (supporter) con noticias relacionadas con el software libre, sus campañas, o eventos. Una forma de difundir los proyectos, para que la gente conozca los hechos, se haga su propia opinión, y tomen partido si creen que la reivindicación es justa!!
- En este enlace podéis leer el original en inglés: https://www.fsf.org/free-software-supporter/2022/october
- Y traducido en español (cuando el equipo de traducción lo tenga disponible) en este enlace: https://www.fsf.org/free-software-supporter/2022/octubre

Puedes ver todos los números publicados en este enlace: http://www.fsf.org/free-software-supporter/free-software-supporter
Después de muchos años colaborando en la traducción al español del boletín, desde inicios del año 2020 he decidido tomarme un descanso en esta tarea.
Pero hay detrás un pequeño grupo de personas que siguen haciendo posible la difusión en español del boletín de noticias de la FSF.
¿Te gustaría aportar tu ayuda en la traducción? Lee el siguiente enlace:
Por aquí te traigo un extracto de algunas de las noticias que ha destacado la FSF este mes de octubre de 2022
Entrevista con Martin Dougiamas de Moodle
Del 22 de septiembre
Después de un poco de pausa, estamos reiniciando la serie de entrevistas que la FSF comenzó hace diez años, en las que destaca el trabajo de los desarrolladores que eligen las licencias GNU.
Estamos felices de que Martin Dougiamas, CEO de Moodle,se una a nosotros para la primera entrevista después de este largo descanso. En esta entrevista, Martin nos cuenta su experiencia con la educación remota al crecer en Australia Occidental y cómo ha ayudado a informar la dirección del Sistema de gestión de aprendizaje de Moodle (LMS).
Moodle LMS, escrito en el lenguaje de programación PHP, es una plataforma de aprendizaje diseñada para proporcionar a los educadores, administradores y estudiantes un único sistema sólido, seguro e integrado para crear entornos de aprendizaje personalizados. También comparte cómo la GPLv3 ha ayudado a Moodle y su comunidad de educadores, desarrolladores y organizaciones en todo el mundo.
La vigilancia impía de las aplicaciones ‘shameware’ anti-pornografía
Del 22 de septiembre por Dhruv Mehrotra
Parece que las empresas de software privativo están continuamente encontrando nuevas formas de explotar a sus usuarios. El llamado «shameware» es un software diseñado para instalarse en el dispositivo de un usuario e informar toda la actividad en línea directamente a otra persona, ya sea el padre, el cónyuge, el maestro o el líder religioso de alguien.
Este software está diseñado para espiar a sus usuarios las 24 horas del día, y lo hace realizando capturas de pantalla, registrando las aplicaciones de software utilizadas para navegar por Internet y registrando las URL de las páginas web visitadas.
El software también es parte de un ecosistema más amplio de avergonzar a las personas por parte de quienes están en posiciones de poder, lo que hace que las personas se sientan mal consigo mismas y que los expertos científicos consideran que carece de cualquier prueba de un «efecto positivo duradero».
El artículo de WIRED ofrece entrevistas con usuarios que instalaron el software bajo la dirección de los líderes de su iglesia, así como varias pruebas que revelaron cosas como la dependencia del software en las API de accesibilidad, diseñadas específicamente para ayudar a los usuarios con discapacidades, y Pixel de Facebook, que envía datos confidenciales directamente. a Facebook, con el fin de capturar datos cada vez más invasivos sobre la persona en cuyo dispositivo está instalado el Shameware no libre.
Ada & Zangemann listos para reservar en inglés
Del 8 de septiembre por Matthias Kirschner
El director ejecutivo de la Free Software Foundation Europe, Matthias Kirschner, publicó recientemente un libro para ayudar a los niños a conocer los conceptos del software libre y lo que la libertad del software puede significar en sus vidas.
A través de una narración encantadora, a la protagonista Ada le encanta jugar y reparar. Y para el deleite de sus amigos y familiares, incluso descubre algunos trucos muy útiles para modificar la tecnología que la rodea para que funcione de formas nuevas, divertidas y útiles.
Mientras tanto, Zangemann, un desarrollador e inventor de software muy rico, intenta controlar todos los dispositivos que usan los ciudadanos de su ciudad. Ahora disponible para descarga gratuita de gestión de restricciones digitales (sin DRM) en inglés, también puede solicitar copias físicas de No Starch Press, que se enviarán desde los EE. UU. a partir de diciembre.
- https://k7r.eu/ada-zangemann-ready-to-pre-order-in-english/
- https://fsfe.org/activities/childrensbook/
- https://nostarch.com/ada-zangemann
Nextcloud trabaja con los gobiernos para crear el reemplazo de MS Office para la UE
En un nuevo desarrollo prometedor, varios gobiernos europeos están trabajando con Nextcloud, que tiene la licencia GNU Affero General Public License versión 3 (AGPLv3), para crear una plataforma que ayude a los gobiernos a recuperar su independencia de una pequeña cantidad de potente software privativo. empresas mediante la creación de un reemplazo gratuito de Microsoft Office 365 destinado a las organizaciones gubernamentales municipales, estatales y federales dentro de la UE.
Además de lograr la soberanía digital general, otros beneficios esperados incluyen tener un paquete de software de oficina que cumpla con los estándares de privacidad, sea fácil de usar y descentralizado.
- https://betanews.com/2022/08/26/nextcloud-works-with-governments-to-create-ms-office-rival-for-the-eu/
- https://nextcloud.com/blog/european-governments-work-with-nextcloud-to-build-digitally-sovereign-office/

Estas son solo algunas de las noticias recogidas este mes, pero hay muchas más muy interesantes!! si quieres leerlas todas (cuando estén traducidas) visita este enlace:
Y todos los números del «supporter» o boletín de noticias de 2022 aquí:

—————————————————————
Novedades de las aplicaciones de Plasma Mobile Gear 22.09
Tras comentar las novedades generales del sistema para dispositivos móviles en las dos últimas entradas (domingo y lunes), finalizo esta serie con las novedades de Plasma Mobile Gear 22.09, el conjunto de mejoras que fueron publicadas el pasado 27 de septiembre. Cerremos este lanzamiento como se merece.
Novedades de las aplicaciones de Plasma Mobile Gear 22.09
Como comenté hace unos días ha sido lanzado Plasma Mobile Gear 22.09, la cual llega con muchas novedades de las cuales se han ido conociendo en medio de la Akademy-es 2022 de Barcelona.
Hoy toca finalizar de hablar de este lanzamiento comentando las novedades de las aplicaciones que complementan el ecosistema móvil, pero adaptable a otros dispositivos, de Plasma Mobile.
-
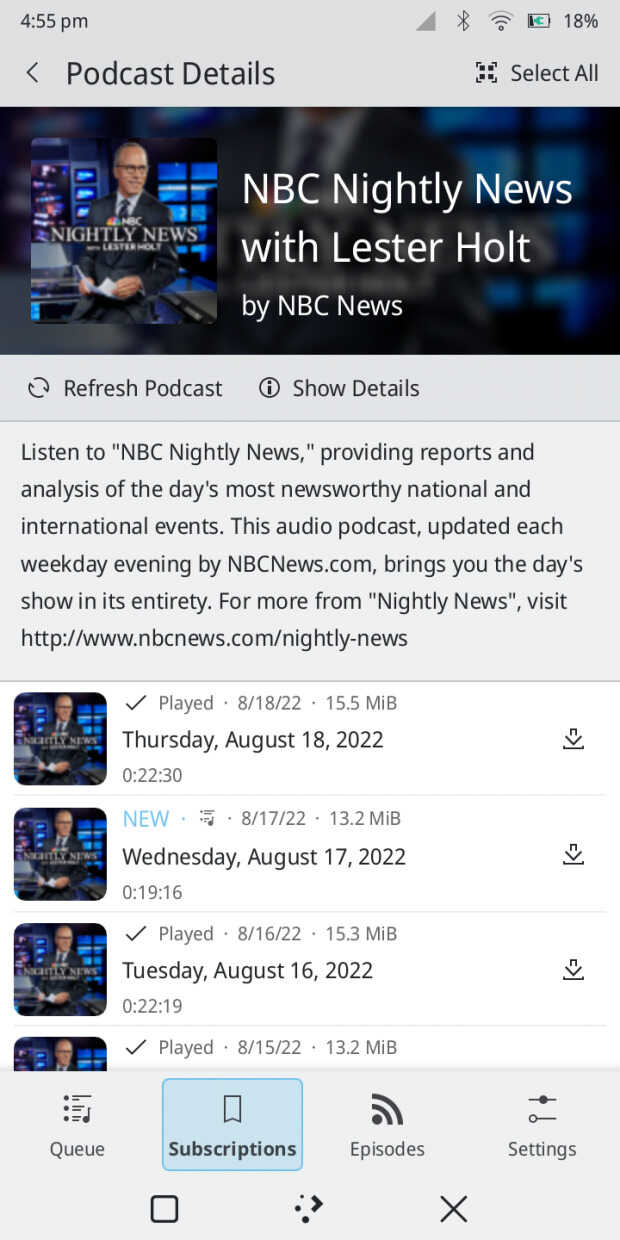
Kasts, el gestor de podcast:
- Se ha simplificado la interfaz combinando la página de podcasts con la de la lista de episodios.
- Se ha trabajado en la mejora de las páginas de información del podcast y de los episodios, añadiendo una barra de botones (desplazando las acciones fuera de la cabecera de la aplicación), y rehaciendo el diseño de la información.
- Añadida la funcionalidad del temporizador de reposo.
- Añadido la posibilidad de enviar todos los estados de los episodios locales al servidor de sincronización (gpodder).
- Nueva opción para marcar una cantidad personalizada de episodios como no reproducidos al añadir un nuevo podcast.
- Añadido el guardado de la posición y el tamaño de la ventana.
-
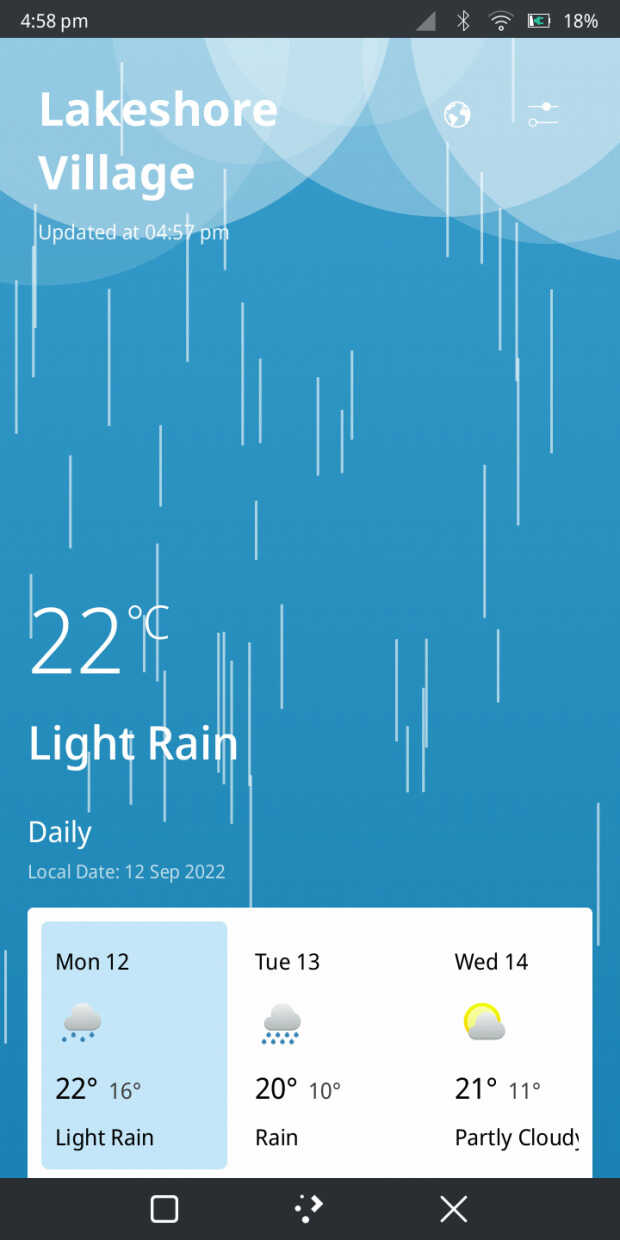
Weather, visualizador del tiempo:
- Adaptados los fondos meteorológicos para que utilicen directamente OpenGL, lo que mejora el rendimiento en los dispositivos de gama baja.
- Mejorado la compatibilidad con las tabletas haciendo que la lista de ubicaciones y los ajustes se muestren como diálogos en pantallas más grandes.
- Solucionados losproblemas con la vista dinámica de la ubicación del tiempo que no cambia si se elimina.
-
Terminal (QMLKonsole):
- Mejorada para el uso de la tableta, añadiendo una barra de pestañas y moviendo los ajustes a un diálogo cuando hay suficiente espacio.
-
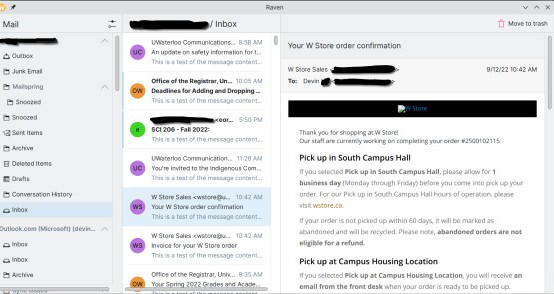
Raven, cliente de correo (nueva aplicación):
- Se ha renovado el cliente de correo nativo para Plasma Mobile, basado en el trabajo de Carl con Pelikan, y ya tenemos un prototipo para un cliente de correo electrónico compatible con Akonadi. Raven es actualmente funcional como un lector de correo electrónico básico, y está previsto que comparta componentes con el próximo soporte de correo de Kalendar.
-
Clock, el reloj del sistema:
- Eliminada la animación del temporizador del segundero ya que distrae
-
Neochat, el cliente de mensajería instantánea:
- Implementado el soporte para configurar las notificaciones por sala.
- Añadido un selector de espacio a la lista de salas, que permite filtrar la lista de salas para las salas incluidas en el espacio seleccionado (proyecto GSoC).
- Modificado el diseño de la línea de tiempo para que se vea mejor cuando la ventana es muy amplia.
- Mejoras en las traducciones, el diseño y la estabilidad de NeoChat.
¿Qué es Plasma Mobile?

Para los que no lo conozcan Plasma Mobile es la alternativa libre a interfaz gráfica para smartphones de la Comunidad KDE, hablé de él hace un tiempo y, poco a poco, se está convirtiendo en un clásico del blog.
Su idea es muy simple, tras conquistar tu escritorio KDE la Comunidad también quiere conquistar tu teléfono móvil… aunque todavía lo tenga complicado por todas las limitaciones de hardware que todavía tiene este campo de la tecnología.
No obstante, confiemos que de igual forma se han ido conquistando los ordenadores de sobremesa, portátiles y servidores, lleguemos un día que podamos tener libertad total en nuestros smartphones.
Y para cuando eso ocurra la Comunidad KDE estará preparada para ello y por eso está confeccionando un catálogo más que decente de aplicaciones con tecnología adaptativa.
La entrada Novedades de las aplicaciones de Plasma Mobile Gear 22.09 se publicó primero en KDE Blog.