
 Member
Member dragotin
dragotinownCloud Client 1.8.0 Released
Today, we’re happy to release the best ownCloud Desktop Client ever to our community and users! It is ownCloud Client 1.8.0 and it will push syncing with ownCloud to a new level of performance, stability and convenience.
[caption id=“attachment_586” align=“alignleft” width=“300”] The Share Dialog[/caption]This release brings a new integration into the operating system file manager. With 1.8.0, there is a new context menu that opens a dialog to allow the user to create a public link on a synced file. This link can be forwarded to other users who get access to the file via ownCloud.
The Share Dialog[/caption]This release brings a new integration into the operating system file manager. With 1.8.0, there is a new context menu that opens a dialog to allow the user to create a public link on a synced file. This link can be forwarded to other users who get access to the file via ownCloud.
Also the clients behavior when syncing files that are opened by other applications on Windows has greatly been improved. The problems with file locking some users saw for example with MS office apps were fixed.
Another area of improvements is again performance. With latest ownCloud servers, the client uses even more parallized requests, now for all kind of operations. Depending on the synced data structure, this can make a huge difference.
All the other changes, improvements and bug-fixes are too hard to count. Finally, this release received around 700 git commits compared to the previous release.
All this is only possible with the powerful and awesome community of ownClouders. We received a lot of very good contributions through the GitHub tracker, which helped us to nail down a lot of issues and improved the client tremendously.
But this time we’d like to specifically point out the code contributions of Alfie “Azelphur” Day and Roeland Jago Douma who contributed significant code bits to the sharing dialog on the client and also some server code.
A great thanks goes out to all of you who helped with this release. It was a great experience again and it is big fun working with you!
We hope you enjoy 1.8.0! Get it from https://owncloud.org/install/#desktop

FITRIM/discard with qemu/kvm for thin provisioning
<disk type='block' device='disk'>After:
<driver name='qemu' type='raw'/>
<source dev='/dev/main/factory'/>
<target dev='vda' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0'/
</disk>
<disk type='block' device='disk'>
<driver name='qemu' type='raw'/>
<source dev='/dev/main/factory'/>
<target dev='sda' bus='scsi'/>
<address type='drive' controller='0' bus='0' target='0' unit='0'/>
</disk>
<controller type='scsi' index='0' model='virtio-scsi'/>
<driver name='qemu' type='raw' discard='unmap'/>Restart the VM, and...
factory-vm:~ # fstrim -v /
/: 8,7 GiB (9374568448 bytes) trimmed
factory-vm:~ #
susi:/local/libvirt-images # ls -lh factory.raw
-rw-r----- 1 qemu qemu 20G Mar 15 14:05 factory.raw
susi:/local/libvirt-images # du -sh factory.raw
12G factory.raw
factory-vm:~ # du -sh /home/seife/linux-2.6/
3.9G /home/seife/linux-2.6/
factory-vm:~ # rm -rf /home/seife/linux-2.6/
factory-vm:~ # fstrim -v /
/: 12.7 GiB (13579157504 bytes) trimmed
susi:/local/libvirt-images # ls -lh factory.raw
-rw-r----- 1 qemu qemu 20G Mar 15 14:08 factory.raw
susi:/local/libvirt-images # du -sh factory.raw
6.4G factory.raw
CLT2015 – Chemnitzer Linux-Tage – Veranstaltung zu Linux und Open-Source-Software
Am 21./22. März 2015 findet in Chemnitz (ehemals Karl-Marx-Stadt) die Veranstaltung Chemnitzer Linux-Tage (CLT2015) statt. In diesem Jahr ist sie die größte Veranstaltung zu Open-Source-Software und Linux-Distribution.
openSUSE ist natürlich mit einem eigenen Stand vertreten. Zum ersten Mal werde ich ebenfalls vor Ort bei der CLT dabei sein und bringe mein Notebook mit installiertem openSUSE 13.2, AMD Catalyst und einige Steam-Spiele zur Präsentation mit. Als 6-köpfiges Team werden wir mit an sicherheitsgrenzender Wahrscheinlichkeit eine ganze Menge Fragen beantworten wie auch Feedbacks zu openSUSE erhalten. Am Stand haben wir mehrere Geräte mit openSUSE stehen. Dort kann jeder Besucher in openSUSE reinschnuppern. Ich freue mich, wenn ich den einen oder anderen openSUSE-User persönlich antreffe. ![]()
Es werden interessante Vorträge aus folgenden Kategorien gehalten:
- Business-Forum
- Cluster/Virtualisierung
- Datenbank
- Desktop
- Einsteigerforum
- Gesellschaft
- Identitiy Management
- Kernel
- LaTeX
- Linux
- Monitoring
- Nerd
- Programmieren
- Publishing
- Security
- Storage
- systemd
- Web
- Wirtschaft
Link zum Vortragsprogramm:
https://chemnitzer.linux-tage.de/2015/de/programm/plan
Folgende Projekte sind vertreten:
- CAcert.org – kostenlose Zertifikate für jedermann
- Chaostreff Chemnitz e.V.
- CMS Garden e.V. – Open Source CMS
- Code for Chemnitz
- Das NetBSD-Projekt
- Debian-Projekt
- debianforum.de – eine Debian-Online-Community
- Django – Das einfache und schnelle Python-Web-Framework
- Eagle Mode
- eisfair – The easy Internet server
- FabLab Chemnitz – offenes HighTechlabor
- Fedora Project
- FFmpeg
- fli4l – flexible Internet router for Linux
- Fortis Saxonia – Automobilprojekte der Zukunft
- Free Software Foundation Europe
- Freifunk Chemnitz e.V.
- Geany
- Gemeinsam E-Bücher herstellen
- Gentoo Linux
- Hostsharing eG – community driven web hosting
- illumos
- InnoContEx
- invis Server
- Jugend Hackt/awearness
- KMUX – ein ganzes Unternehmen in einer Box
- Kubuntu
- Leipzig Python User Group
- Linuxdistribution siduction
- m23 software distribution
- Mageia.Org
- MEGWARE GmbH und Rechenkraft.net e.V.: HPC & Citizen Science
- OpenLDAP – Verzeichnisdienste für kritische Infrastrukturen
- OpenRheinRuhr e.V.
- OpenStreetMap – die freie Mitmach-Weltkarte
- openSUSE Community
- ownCloud
- Privacy Corner von Aktion Freiheit statt Angst
- Privatsphäre einfach sicherstellen: Die eigene Cloud
- Professioneller Textsatz mit LaTeX
- Python Software Verband e.V.
- ReactOS Project
- Sicherheit in Kommunalen Netzwerken mit pfSense
- Skolelinux.DE – Debian für die Bildung
- Smart-SARAH
- Storage und Monitoring: openATTIC und openITCOCKPIT
- TU Chemnitz Fakultät für Informatik goes Linux
- Ubuntu Community
- Xfce
- YaCy
Unter anderem sind auch folgende Firmen dabei:
- 1C:Enterprise – Entwicklungsumgebung für Business Software
- Amazon Development Center Germany GmbH
- c.a.p.e. IT GmbH
- Dynamik im Web-Application Management
- FromDual GmbH – MySQL Support und Galera Cluster
- Heinlein Support GmbH
- Hetzner Online AG
- Industrieelektronik auf Open-Source und Linux-Basis
- Linux Professional Institute (LPI)
- moneyplex Homebanking
- Pengutronix – Embedded-Linux-Entwicklung
- privacyIDEA
- Python Academy
- VARIA – Mini Embedded Boards (ARM,APU) und Wireless Lösungen
Eintrittspreise:
| Business-Ticket (inkl. Spende): | 80,- € |
| Business-Ticket Sonntag (inkl. Spende): | 60,- € |
| Normal: | 8,- € |
| Ermäßigt: | 4,- € |
Link zum Übersichtsplan inkl. Anfahrtsplan:
https://chemnitzer.linux-tage.de/2015/media/plaene/plan-clt-chemnitz.pdf
Weitere Informationen zur Veranstaltung:
https://chemnitzer.linux-tage.de/2015/de/
ownCloud ETags and FileIDs
Often questions come up about the meaning of FileIDs and ETags. Both values are metadata that the ownCloud Server stores for each of the files and directories in the server database. These values are fundamentally important for the integrity of data in the overall system. Here are some thoughts about what they are why these are so important.This is mainly from a clients point of view, but there are other use cases as well.
ETags
ETags are strings that describe exactly one specific version of a file (example: 71a89a94b0846d53c17905a940b1581e).
 Whenever the file changes, the ownCloud server will make sure that the ETag of the specific file changes as well. It is not important in which way the ETag changes, it also does not have to be strictly unique, it’s just important that it changes reliably if the file changes for whatever reason. However, ETags should not change if the file was not changed, otherwise the client will download that file again.
Whenever the file changes, the ownCloud server will make sure that the ETag of the specific file changes as well. It is not important in which way the ETag changes, it also does not have to be strictly unique, it’s just important that it changes reliably if the file changes for whatever reason. However, ETags should not change if the file was not changed, otherwise the client will download that file again.
In addition to that, The ETags of the parent directories of the file have to change as well, up to the root directory. That way client systems can detect changes that happen somewhere in the file tree. This is in contrast to normal computer file systems where only the modification time of the direct parent of a file is changing.
File IDs
FileIDs are also strings that are created once at the creation time of the file (example: 00003867ocobzus5kn6s).
 But contrary to the ETags, the file IDs should never ever change over the files lifetime. Not on an edit of the file, and also not if the file is renamed or moved. One of the important usages of the FileID is to detect renames and moves of a file on the server.
But contrary to the ETags, the file IDs should never ever change over the files lifetime. Not on an edit of the file, and also not if the file is renamed or moved. One of the important usages of the FileID is to detect renames and moves of a file on the server.
The FileID is used as an unique key to identify a file. FileIDs need to be unique within one ownCloud, and in inter-owncloud connections, they must be compared together with the ownCloud server instance id.
Also, the FileIDs must never be recycled or reused.
Checksums?
Often ETags and FileIDs are confused with checksums such as MD5 or SHA1 sums over the file content.
Neither ETags nor FileIDs are, even if there are similarities: Especially the ETag can be seen as a checksum over the file content. However, file checksums are way more costly to compute than just a value that only needs to change somehow.
What happens if…?
Let’s make a thought experiment and consider what it would mean especially for sync clients if either fileID or ETag gets lost from the servers database.
If ETags are lost, clients loose the ability to decide if files have changed since the last time that was checked by the clients. So what happens is that the client will download the files again, byte-wise compare them to the local file and use the server file if the files differ. A conflict file will be created. Because the ETag was lost, the server will create new ETags on download. This could be improved by the server creating more predictable ETags based on the storage backends capabilities.
If the ETags are changed without reason, for example because a backup was played back on the server, the clients will consider the ones with changed ETags as changed and redownload them. Conflict handling will happen as described if there was a local change as well.
For the user, this means a lot of unnecessary downloads as well as potential conflicts. However, there will not be data loss.
If FileIDs got lost or changed, the problem is that renames or moves on server side can no longer be detected. That would result in a new download of files in the good case. If a fileID however changes to something that was used before, that can result in a rename that overwrites an unrelated file. That is because clients might still have the FileID associated with another file.
Hopefully this little post explains the importance of the additional metadata that we maintain in ownCloud.

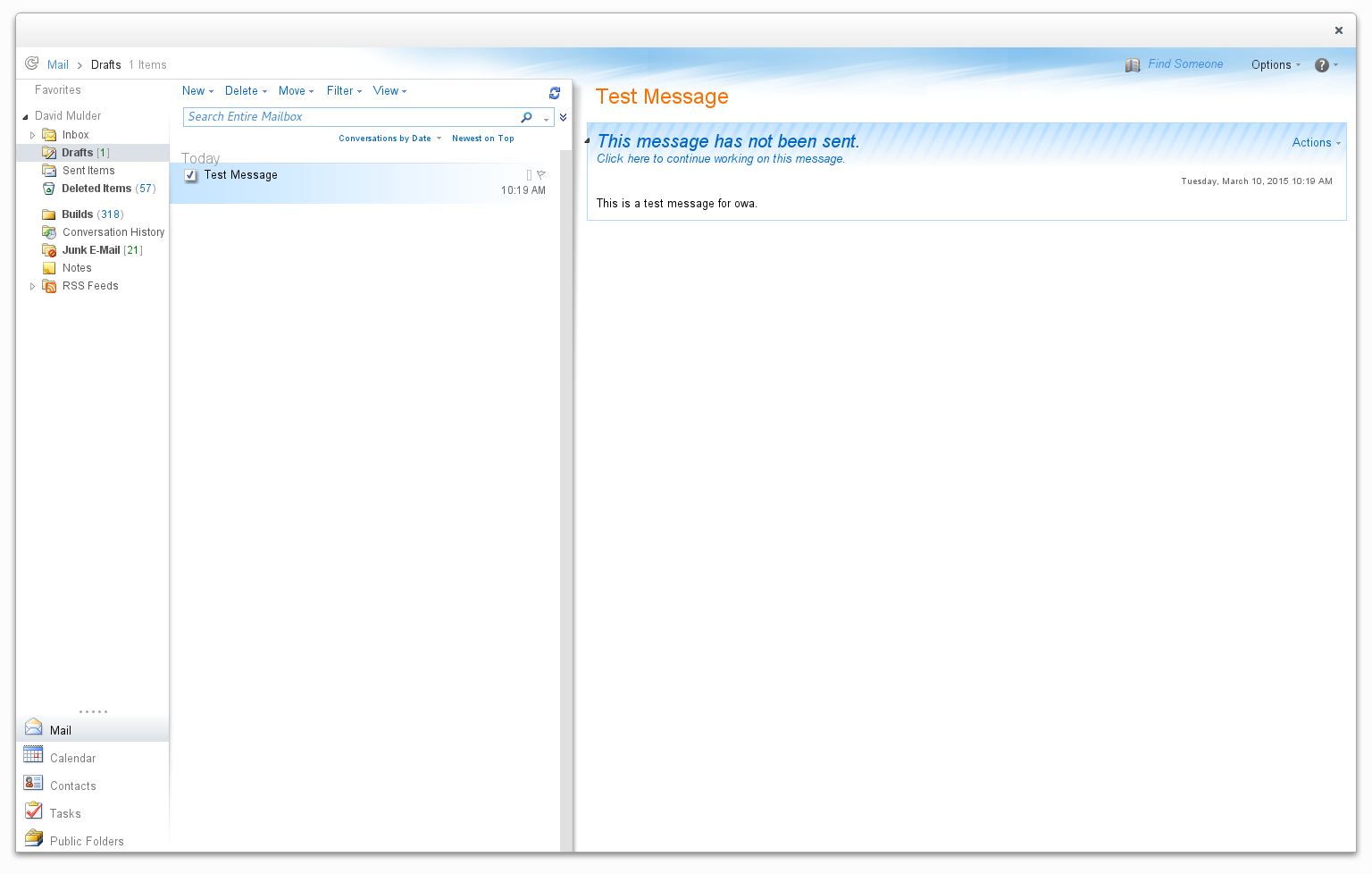
Simple Browser Project
I’ve been looking for a good way to access my corporate email on my linux (opensuse) laptop. Evolution is pretty good, but the evolution-ews plugin is REALLY buggy. The connection was dropping every few minutes for me. The user interface also feels too cluttered for what I’m trying to do. So, I decided to try a different approach.
I wrote a simple python based webkit browser to modify the look and feel of owa to make it more like a desktop app.
You can access the source code here:
http://github.com/DavidMulder/simple_browse
Or you can install the opensuse package here:
http://software.opensuse.org/package/simple_browse?search_term=simple_browse
I also plan to use it to play Netflix on my mythtv box. It seems like I should be able to modify the css styling to make the summaries bigger on the page, etc.
Portable Float Map with 16-bit Half
Recently we saw some lively discussions about support of Half within the Tiff image format on the OpenEXR mailing list. That made me aware of the according oyHALF code paths inside Oyranos. In order to test easily, Oyranos uses the KISS format PPM. That comes with a three ascii lines header and then the uncompressed pixel data. I wanted to create some RGB images containing 16-bit floating point half channels, but that PFM format variant is not yet defined. So here comes a RFC.
A portable float map (PFM) starts with the first line identifier “Pf” or “PF” and contains 32-bit IEEE floating point data. The 16-bit IEEE/Nvidia/OpenEXR floating point data variant starts with a first line “Ph” or “PH” magic similar to PFM. “Ph” stands for grayscale with one sample. The “PH” identifier is used for RGB with three samples.
That’s it. Oyranos supports the format in git and maybe in the next 0.9.6 release.

Online Programming Competitions are Overrated
I believe that the assessment for a senior/architect level programmer, should be done by finding how co-operative [s]he is with others to create interesting products and their history than by assessing how competitive [s]he is in a contest.
Algorithms
On my lone programming competition experience (on hackerrank), the focus of the challenges were on Algorithms (discrete math, combinatorics etc.).Usage of standard, simple algorithms, instead of fancy, non-standard algorithms is a better idea in real life, where the products have to last for a long time, oblivious to changing programmers. Fancy algorithms are usually untested, harder to understand for a maintenance programmer.
Often, it is efficient to use the APIs provided by the standard library or ubiquitously popular libraries (say jquery). Unless you are working on specific areas (say compilers, memory management etc.) an in-depth of knowledge of a wide-range of algorithms may not be very beneficial (imo) in day-to-day work, elaborated in the next section.
Runtime Costs
There are various factors that decide the runtime performance, such as: Disk accesses, Caches, Scalable designs, Pluggable architectures, Points of Failures, etc.Algorithms optimize mostly one aspect, CPU cycles. There are other aspects (say choice of Data structures, databases, frameworks, memory maps, indexes, How much to cache etc.) which have a bigger impact on the overall performance. CPU cycles are comparatively cheap and we can afford to waste them, instead of doing bad I/O or a non-scalable design.
Most of the times, if you choose proper datastructures and get your API design correct, we can plug the most efficient algorithm, without affecting the other parts of the system, iff your algorithm proves to be really a bottleneck. A good example is the Evolution of filesystems, schedulers in the Linux Kernel. Remember that Intelligent Design school of software development is a myth.
In my decade of experience, I have seen more performance problems due to poor choice of datastructures or unnecessary I/O, than due to poor selection of algorithms. Remember, Ken Thompson said: When in doubt, Use Brute Force. It is not important to get the right algorithm on the first try. Getting the skeleton right is more important. The individual algorithms can be changed, after profiling.
At the same time, this should not be misconstrued as an argument to use bubblesort.
The 10,000 hour rule
Hardware
AHA Algorithms
Conclusion:
Having said all these, these online programming contests are a nice way to improve one's skills and to think faster. I will be participating in a few more to make myself fitter. There may be other programming challenges which are better and test all aspects of an engineer. I should write about my view after an year or so.
One more thing: Zenefits & Riptide I/O
Linux audio library smackdown part4: LibAO
Last time I’ve took look at Simple Direct Layer and how to get audio out of it. If SDL still feels little bit too hard to cope with I think I have solutions for you: libAO. Besides being no brainier with API libAO provides huge list of supported operating systems.
There is so much audio systems supported that you won’t be dissapointed but as much as I like everyone use Roaraudio. I don’t see it’s happening really soon (sorry roar you had your time in fame) but supporting Roaraudio doesn’t mean that libAO is obsolete. It’s far from being obsolete. Libao supports OSS, ALSA and Pulseaudio out of the box and only problem is license is GPL 2.0+ so it’s no-go for proprietary development.
History
LibAO is developed under Xiph umbrella. Xiph is the organization who brought you Ogg/Vorbis, FLAC, Theora and currently they are hammering together next generation video codec Daala. Opus-audio codec standard is also Xiph project. LibAO rised from Xiph’s need multi-platform audio output library for Vorbis-audio codec. In this point if you don’t have any glue what I just said in last sentences I think you should take your spoon and start shovelling about Open Source audio codecs.
Becaus of the history libAO only has output mode and doesn’t use any callbacks. It doesn’t have fancy Float32 mode (as much as I understood) but that doesn’t say it’s bad thing. It works as expected you just feed bytes and after while you hear them from your speakers.
What about API
Supported outputs: Alsa, Oss, Jack, Mac OS X, Windows
License: GNU General Public license 2.0+
As said libAO API is difficult to describe since there almost ain’t NAN of it. You initialize, ask output device, put in your mode settings and start feeding data. Pulseaudio simple is almost easy as this but it’s still more difficult if you compare it to libAO. LibAO doesn’t support recording so only output and there must be a way to use another device than default but it’s not very easy to find or I was too lazy to dig it out.
So who wants to use libAO? People in hurry and don’t mind GPL-license, someone with very very tiny need of just getting audio out and people how hate bloat.
Summary: So if you hate bloat and again license doesn’t make you unhappy please use this library. Still libAO has kind of same problem that ALSA has. It’s mature, usable and ready for hardcore torturing but is it sexy? No! Is fresh? No, No! Is something that will change it API every week or hour?
After this I have to choose what to bring next. I have FFmpeg, Gstreamer and VLC in row. If you have opinion about next framework let me know.

Why openSUSE?
As this is hosted on my personal blog, this should probably go without saying, but given the topics covered in this post I wish to state for absolute clarity that the content of this post does not necessarily reflect the official opinion of the openSUSE Project or my employer, SUSE Linux GmbH. This is my personal opinion and should be treated as such
One thing I get asked, time and time again, is "Why openSUSE?". The context isn't always the same "Why should I use it?", "Why should I contribute to openSUSE?", "Why do you use it?", "Why not use [some other distribution]?" but the question always boils down to "What's special about the openSUSE Project?"
It's a good question, and in the past, I think it's one which both the openSUSE Project as a whole and me as an individual contributor have struggled to satisfactorily answer. But I don't believe that difficulty in answering is due to a lack of good reasons, but an abundance of them, mixed in with a general tendency within our community to be very modest.
This post is my effort to address that, and highlight a few reasons why you, the reader, should contribute to the openSUSE Project and use the software we're developing
Reason 1: We're not (just) a Linux Distribution
Normally, the first thing people think of when they hear openSUSE is our 'Regular Release Distribution', such as openSUSE 13.2 which we released last year (Download it HERE)
The openSUSE Project however produces a whole bunch more.
For starters, we have not one, but technically TWO other Linux Distributions which we release and maintain
openSUSE Tumbleweed - our amazing rolling release which manages to give it's users stable, usable, Linux operating system, with constantly updating software.
Perfect not only for Developers, but anyone who wants the latest and greatest software, leading Linux experts like Greg Kroah-Hartman have stated rolling releases like Tumbleweed represent the 'future' of Linux distributions. I agree, and I think openSUSE's is the best (for reasons that will be made clear later in this post).
In my case it's replaced all but one of my Linux installations, which previously included non-openSUSE distributions. The last (my openSUSE 13.1 server) is likely to end up running Tumbleweed as soon as I have a weekend to move it over. I started small with Tumbleweed, having it on just one machine, but after a year, I just don't see the need for the 'old fashioned' releases any more in any of my use cases.
If you want to see it for yourself, Download it HERE
openSUSE Evergreen - this is a great community driven project to extend the lifecycle of select versions of our Regular Release beyond its usual "2 Releases + 2 Months" lifespan.
While technically not a 'true' separate Distribution in the purest sense of the word, it takes a herculean effort from our community to keep on patching the distribution as it gets older and older, but it allows us to offer a 'Long Duration Support' for a significant period after the regular lifespan.
The current openSUSE Evergreen release is openSUSE 13.1, which will be supported until at least November 2016 and can be Downloaded HERE
So, we're not just *a* Linux distribution but several, but wait, there's more!
The openSUSE Project hosts a whole pile of other software Projects, always Open Source, which we both use ourselves and encourage others to use and contribute to. These include:
Open Build Service - our build tool, building all of our packages as well as ones for SUSE Linux Enterprise, Arch, Debian, Fedora, Scientific Linux, RHEL, CentOS, Ubuntu, and more.
openQA - automated testing for *any* operating system, that can read the screen and control the test host the same way a user does.
YaST - The best/only comprehensive Linux system configuration & installation tool.
KIWI - Create Linux images for deployment on real hardware, virtualisation, and now even container systems like Docker. Kiwi is the engine that powers SUSE Studio
Snapper - Create, manage, and revert system snapshots. Roll-back without hassle when your system gets messed up (p.s. It's probably your fault it messed up, so Snapper can show you what changed between snapshots too)
OSEM - Open Source Event Management. Lots of Open Source projects have their own conferences and other events. We have our own tool for managing proposals, organising schedules, taking registrations, etc.
Trollolo - Command line tool for Trello with a brilliant name ;)
And many more, many of which can be found on our GitHub project page
Reason 2: We build and use the best tools
You might have noticed a common theme among many of the software projects listed above. We're a Project that cares a lot about using the right tool for the job.
In many cases that means using many of the same tools that other projects use, IRC, Git & GitHub, Forums, Mailing Lists, etc. We're not the kind of project that wants to invent new types of wheels just because we didn't invent the first one, but when the tools that are out there don't do the job well enough, we roll up our sleeves and try to produce the *best* tool for that job.
Obviously, we do this motivated by the need to scratch our own itches, but we also work very hard to produce tools which can, and should, be adopted by a much wider audience than just 'users and contributors to the openSUSE Distributions'.
This is probably best highlighted by talking about two of our best tools, the Open Build Service, and openQA.
Open Build Service - As already mentioned, our build tool builds all of the openSUSE Distributions packages, ISOs, Images, etc.
It also generates and hosts repositories for these packages.
It has always been built as a 'cross-distribution' tool, currently able to build packages for SUSE Linux Enterprise, Arch, Debian, Fedora, Scientific Linux, RHEL, CentOS, Ubuntu and more.
With both a web-based UI (you can see and use our installation HERE) and the osc command-line tool (Documentation HERE) the barrier to entry is pretty low. Even someone with no packaging experience can easily see the contents of any package in OBS, understand how it's put together, branch it (aka fork it to use the github equivalent term) into their own Project and get hacking away.
We also allow our openSUSE instance of OBS to be used by *anyone* without charge, so they can build and host their packages on our infrastructure for free (though at the very least, we'd like it very much if they made sure their openSUSE packages work really nice in return ;) )
OBS is already used by other companies and projects like VideoLAN, Dell, HipChat and ownCloud, but if you're in the business of making software for Linux, you really need to ask yourself the question "Why don't I use OBS to build my packages?"
openQA - Another jewel in our crown and somewhere I've been spending a lot of my time lately. openQA is a testing tool that lets you build tests for any operating system or application. Unlike practically every other testing tool I've looked at, openQA actually tests software the same way *users* do. It looks at the screen, and makes sure the user will see what you expect them to see. Then press the same keyboard and mouse buttons that a user would to work through the application. You can see it in action HERE
openSUSE use openQA extensively to build Tumbleweed. Proposed code for Tumbleweed is tested by openQA before it is accepted, and tested again AFTER it's accepted (to make sure it integrates well with everything else that has been recently merged).
This is how we're able to offer Tumbleweed as a 'stable' Rolling Release, because thanks to openQA we *know* the Distribution works *before* we put any updates in the hands of any users. If something does break, openQA stops the release, and users don't notice any problems, besides perhaps a slight delay in receiving new updates. On the (exceptionally rare) chance that something slips by openQA, that becomes a new test case, so we never make the same mistake twice.
openQA is also being used by SUSE for the testing of SUSE Linux Enterprise, and the Fedora Project have recently started using it. We'd love to see more distributions using it, and while playing around we've already managed to get openQA testing different operating systems like Android and even Windows :)
Reason 3: Engineering matters
Why all this focus on tools? Well for our community, engineering matters. Beyond the tools that we use to make this happen, we spend a lot of time, braincells, and discussions, getting under the hood and trying to find the best way to build our software.
This has led to openSUSE leading the way with lots of innovations in areas like package management. zypper and libsolv mean that, unlike other RPM-based Linux distributions 'dependency-hell' is a thing of the past for us, and we manage to stand toe to toe with Debian and Ubuntu, look at their package managers and go 'yeah, we can do that, and more'
We're also not interested in being another Open Source project taking everything from dozens of upstream projects and either stamping our logo on it and calling it our own, or changing a whole bunch of stuff and not giving stuff back.
We work hard with our upstream projects, be that the Kernel, GNOME, KDE, whatever, to give our feedback, get our patches merged, not just for their benefit, but our own - the more they accept, the less work we'll have to do maintain long winded openSUSE specific patch sets in the Future.
Reason 4: Community, Community, Community
The openSUSE Community is great, so great they deserve a blog post of this length on their own. But for the purposes of this post I want to summarise a few things.
First, a little bit about SUSE. We're sponsored by SUSE, and they make up an important part of the community, employing a good number of openSUSE contributors, and regularly contributing to the openSUSE Project in terms of code, staff, money.
In many respects their the 'Patron' of the openSUSE Project, having our back when we need it, but not overarching overlords controlling the project. The openSUSE Project is independent, free to set it's own direction.
SUSE sees themselves as peers in the community, taking part in the same way as everyone else, encouraging its engineers to be involved in discussions, and help set the direction of the openSUSE Project via code submissions, just like everyone else.
Open Source works best when there is freedom to innovate, that's the business openSUSE is in, and SUSE is a company that understands at it's Core - as their current recruitment campaign says "Open Source is in their Genes" (P.S. They're Hiring)
So if SUSE aren't 'in charge', who is? Well, the community is. Those who do, decide, and we want more people to help join us doing stuff! We're the kind of project that is very open to new contributors, and we try hard to maintain a very low barrier to entry.
We're not the sort of project with lots of hoops you need to jump through before you're allowed to do anything.
If you see something that needs fixing, talk to the people also working on it, fix it for/with them, and submit your contributions. This is true for code, the website, wiki, marketing stuff, anything, anywhere. We're not a project where you need permission before you can get involved.
We try and keep our processes lean but the ones we do have are on our Wiki, and in terms of getting together with existing contributors, they can most easily be found in our IRC Channels and on our Mailing Lists
If you're a user and need help actually using openSUSE but aren't ready to get involved with contributing to the project yet, then we have a great community of contributors helping support people via IRC and our Forums
But doesn't everyone doing everything everywhere lead to chaos? No, not really. The Open Source model works, with the few processes we have in place providing enough structure and safety that problems get caught and dealt with as part of a natural flow and learning process.
But, it's not utopia, from time to time of course stuff pops up, and that's why the openSUSE project has the Board.
Our job is to help keep this Project on the right track, keep people talking to each other, resolving conflicts, keeping everyone on the same page, and being the 'decision makers of last resort' if there is no one else able/suitable to make a decision that affects the Project.
This basically boils down to being the 'Universal Escalation Point' - If you have a problem, if no one else can help, and if you can find them (and that should be easy), maybe you should contact board@opensuse.org (LINK - ahh, nostalgia)
The structure of the Board is also a nice reflection of how the rest of our community is structured - of the 5 elected Board seats, no more than 2 can be occupied by people employed/controlled by the same organisation. This means no company (not even SUSE) can have a majority of the seats on the Board, ensuring it's healthy and balanced just like the rest of our community.
And finally, the openSUSE community is just a great bunch of people. I've been contributing to this project since it started, and it's dragged me in and is as much fun as ever. We have great, smart, funny, dedicated people, and it's a pleasure working with them both as part of my day job and hobby.
A big part of that is our regular openSUSE Conferences. 2011 was my first, and the wonderful combination of meeting people, great talks, and (lots of) openSUSE Beer, enabled me to jump from being a 'casual contributor' on the fringes to someone who really felt part of this great community.
We have another openSUSE Conference coming up in May, in Den Haag/Netherlands. There's still time to Submit talks (we'd love to see more from other Projects) or Register. If this post has got you interested in openSUSE, come along, it's a great opportunity to meet us :)
And remember our motto and default /etc/motd.. Have a Lot of Fun!
Qactus is out in the wild
Qactus, a Qt-based OBS notifier, is out in the wild. Version 0.4.0 is the first release.
I started it a long time ago together with Sivan Greenberg as a personal project for learning Qt. And now it’s back into life 
It features
– Build status viewer
– Row editor with autocompleter for project, package, repository and arch
– Submit requests viewer
– Bugs
This application is possible thanks to Marcus ‘darix’ Rueckert. He has helped me getting further knowledge of the OBS API.
I think this version is usable. So, why don’t you give it a try?
The source code is hosted on GitHub.


