
Hackweek
It was hackweek in Novell last week. I decided to make a Taobao extension in OpenOffice.org to facilitate Taobao users manager their transaction data including what they bough and what they sold. So that it could attract more people to use OpenOffice.org for it is reported that Taobao has over 100 million users in China. :-)
Firstly, I need to learn the Taobao Open Platform(TOP) which provides API to manager the business in Taobao. I wrote some example to learn how to use these API to get the transaction data of the user's bough and sold.
Secondly, I also need to spend some time learn how to make an extension in Java. And I found some examples to see how to make a custom menu and dialog in Openoffice.org SDK.
Finally, I got a prototype that could import the transaction data from Taobao into Spreadsheet.
When "Taobao"->"Buy" is click, your bough data is imported in the spreadsheet.
Actully, this is just a demo, not a final version. I will improve this extension and upstream the codes and binary extension into Google project oootaobao.
 Member
Member ppoeml
ppoemlImproved mirror selection for India
Recently, it became evident that users in India don’t get good mirrors. This was solved by configuring a few German and US mirrors to serve users from India.
Courtesy of Adrian Reber from Esslingen University of Applied Sciences, there is an illustrative screenshot that visualizes the efficacy of this. The world map shows accesses to their openSUSE mirror by country (live view). In openSUSE’s MirrorBrain configuration, this mirror is set up to receive German, Danish, Polish, and Indian requests.
The background is that India has bad connectivity to neighbouring countries, but good connection to German and US mirrors. Therefore, now a few German and US mirrors are configured to serve India. The screenshot below demonstrates this for the mirror of the Esslingen University of Applied Sciences:

world map showing client distribution of accesses to an openSUSE mirror in Germany
The world map clearly shows how the mirror gets nearly exclusively German requests, as well as those from India. The same happens for some other German and some US mirrors.
Note that if a mirror in India should become available (would be nice!), it would automatically be preferred, and the other mirrors become fallback mirrors.
While it is not new that we do this, the screenshot of Adrian’s analysis illustrates the issue very nicely. We have similar configuration for a number of countries, where a mirror selection purely based on countries and regions wouldn’t work. For this kind of tuning, we depend on user input.
Hints about how to improve serving our downloads are always appreciated. Please write to admin at opensuse dot org with input in this regard. Thanks!
Hackweek IV: Novell Bugzilla access from command line
During a last Hackweek I decided to work on some tool which will helps users with submitting a new bug. My idea is to create something like reportbug from Debian, but targeted to SUSE. So the first step was find the way how to communicate with a bugzilla (especially to bugzilla.novell.com – bnc). Fortunately I found several libraries, which should be used for it:
- perl-SUSE-BugzillaClient
- pybugz
- python-bugzilla
perl-SUSE-BugzillaClient is written by Thomas Schmidt especially for bnc, so it is able to login using iChain. It also provides few functions for bugzilla communication, but unfortunately only for querying. Pybugz is written by Alastair Tse for Gentoo development in Python. But it is not able to login through iChain and I did not extended it for bnc, because it uses a plain GET/POST communication with parsing of HTML using regexes.
The reason why I have used the python-bugzilla written by Will Woods from RedHat is simple. It uses XMLRPC API, which bugzilla provides. And it’s also written with a flexibility in mind, so writing of another type of Bugzilla was easy. Just some subclassing and reimplementing of few methods and voila, the NovellBugzilla type is here. Because it uses iChain, it was necessary to reimplement login/logout methods – I spend a lot of time to understand how it works. Osc uses a HTTP authentication, which should be supported too, but even if it works with api.opensuse.org, it did not work with bnc. So I used a Firefox and LiveHTTP headers extension to track a communication and implemented the login according it.
The useful advantage of Novell bugzilla is that I extended a method readconfig, which reads a config file. Novell Bugzilla can read the username/password from ~/.oscrc, so you don’t need to have a same password in another config file, if you use osc.
So on the end those few lines of Python code
import bugzilla
bnc = bugzilla.NovellBugzilla(url="https://bugzilla.novell.com", user="mvyskocil", password="XXXXX")
kwargs = {
'product': 'openSUSE 11.2',
'severity': 'Normal',
'cc': [],
'rep_platform': 'x86-64',
'component': 'Java',
'summary': '[Java:packages/ant]: Cannot find a Java virtual machine',
'version': 'unspecified',
'assigned_to': 'mvyskocil@novell.com',
'op_sys': 'Linux',
'description': 'This is a testing bug report\n'
}
bug = bnc.createbug(**kwargs)
print bug.bug_id
Have created this bug#525549. Even if Python is readable for regular programmers, the **kwargs should be expressed. It maps the dictionary to named function arguments (called keyword arguments – kwargs – in a Python world), so both calls in following snippet are equivalent.
d = {'name' : 'value')
call(**d)
call(name='value')
The python-bugzilla comes also with a simple command line tool called bugzilla, so this tool should be used also from shell scripts. It is sometimes little bit raw. For example listing of all products returns an output as a Python dictionary
bugzilla --bztype NovellBugzilla --user mvyskocil --password xxxxxx info -p
...
{'description': 'openSUSE 11.1', 'internals': {'disallownew': 0, 'classification_id': 7340, 'name': 'openSUSE 11.1',
'votestoconfirm': 0, 'milestone_required': 0, 'id': 651, 'votesperuser': 20, 'maxvotesperbug': 5, 'defaultmilestone': '---',
'milestoneurl': '', 'description': 'openSUSE 11.1'}, 'name': 'openSUSE 11.1', 'id': 651}
{'description': 'openSUSE 11.2', 'internals': {'disallownew': 0, 'classification_id': 7340, 'name': 'openSUSE 11.2',
'votestoconfirm': 0, 'milestone_required': 0, 'id': 755, 'votesperuser': 20, 'maxvotesperbug': 5, 'defaultmilestone': '---',
'milestoneurl': '', 'description': 'openSUSE 11.2'}, 'name': 'openSUSE 11.2', 'id': 755}
...
which might be hard to parse in other language. But it provides a lot of functionality, so for other informations about usage, please use man bugzilla.

More on Smolt
-
Bug 525324- [home:cgoncalves:playground] the Privacy Policy window has not scrollbar
-
Bug 525322- [home:cgoncalves:playground] smolt does not display special chars
Q: So, what's really new?!
A:
- Smolt KDE4 popup made by Thomas Goettlicher:
-
Qt.ToolButtonTextBesideIcon (the text appears beside the icon) is now default per Nuno Pinheiro's suggestion:

- Window size auto-adjusting:

As you can also see BNC#525322is indeed fixed.

The notification will be shown automatically upon KDE startup (X-KDE-autostart-phase=2)


I'm preparing a Smolt RPM update to submit to openSUSE Factory to get included in time for openSUSE 11.2, though you can try it already by using my home:cgoncalves:playground repository:
openSUSE 11.1:
# zypper ar http://download.opensuse.org/repositories/home:/cgoncalves:/playground/openSUSE_11.1/ home:cgoncalves:playgroundopenSUSE Factory:
# zypper ar http://download.opensuse.org/repositories/home:/cgoncalves:/playground/openSUSE_Factory/ home:cgoncalves:playground# zypper ref home:cgoncalves:playground
# zypper in smolt-snapshot smolt-popup
As always, please give us feedback!
Fresh & Fruity
Available today as part of the SUSE Appliance Program is SUSE Studio 1.0 based on the image creator technology called kiwi. When creating an appliance with SUSE Studio you also have the possibility to export the appliance description to your local computer and use the kiwi backend directly to understand more about image creation and deployment
A professional linux distribution should be able to work as an appliance which is an ll-in-one solution including the application and the operating system. A basic appliance to start with is the JeOS – Just Enough Operating System. kiwi provides these as examples in the kiwi-templates package. To create your first SUSE 11.1 appliance just type:
kiwi --build suse-11.1-JeOS -d /destination/path
The primary image type of a JeOS template is a virtual disk which you can run in a virtual machine like QEmu, KVM, Vmware, VirtualBox, etc… To do this with qemu just call:
qemu /destination/path/LimeJeOS-openSUSE-11.1.i686-1.11.1.vmdk
and here you go with your first appliance. You want to know more about kiwi, just take a look at the wiki here:
or read the full system documentation as PDF here:
Remember to have fun 

kaveau: easy and integrated backups solution for KDE
During the last week I had the possibility to work on anything I wanted, Novell’s hackweek is so cool :)
I decided to dedicate myself to an idea that has been obsessing me since a long time. Last December my brand new hard disk suddenly died, making impossible to recover anything. Fortunately I had just synchronized the most important documents between my workstation and my laptop, so I didn’t lose anything important. This incident make me realize that I should perform backups regularly and I immediately started looking for a good solution.
Personally I think that doing backups is pretty boring so I wanted something damned easy to setup and use. Something that once configured runs in the background and does the dirty job without bothering you. Let’s face the truth: I wanted Apple’s Time Machine for KDE.
After some searches I realized that nothing was fitting my requirements and I decided to create something new: kaveau.
What is kaveau?
Kaveau is a backup program that makes backup easy for the average user.
As you will see while coding/planning kaveau I made some assumptions and so only few things are configurable. I really think that sometimes “less is more”.
What does kaveau?
Current features:
- it performs backups to an external storage device: I don’t think it will ever store backup data on a remote host. If you want to do that just use some good project like Backup pc.
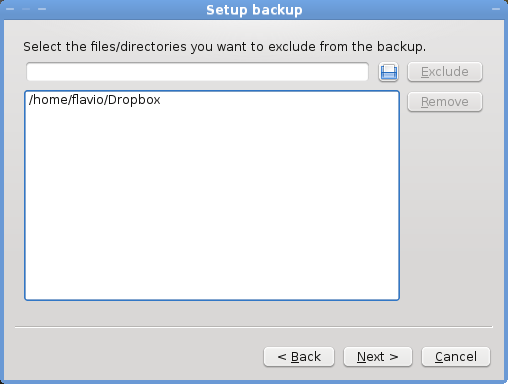
- it backs up the complete home directory of the user: storage is cheap and average users (like me) keep everything inside their home directory ( but it’s possible to exclude some directories from the backup).
- it performs incremental backups.
- the backup data are neither compressed nor stored in fancy formats: in this way you can plug your external disk into another machine and access your data without additional work.
- backups are performed automatically every hour (of course only if your external disk is plugged).
- notification messages are shown if your backup is older that a week. More enhancements are coming…
What technologies does it use?
Backups are performed using rdiff-backup because it’s damned easy to use, well tested (it’s used also in production environments) and packaged by all distributions.
The awesome solid library is used for interacting with the external disks is super easy.
Status of kaveau
I have been working on kaveau just for five days, so there’s still a lot of work to do.
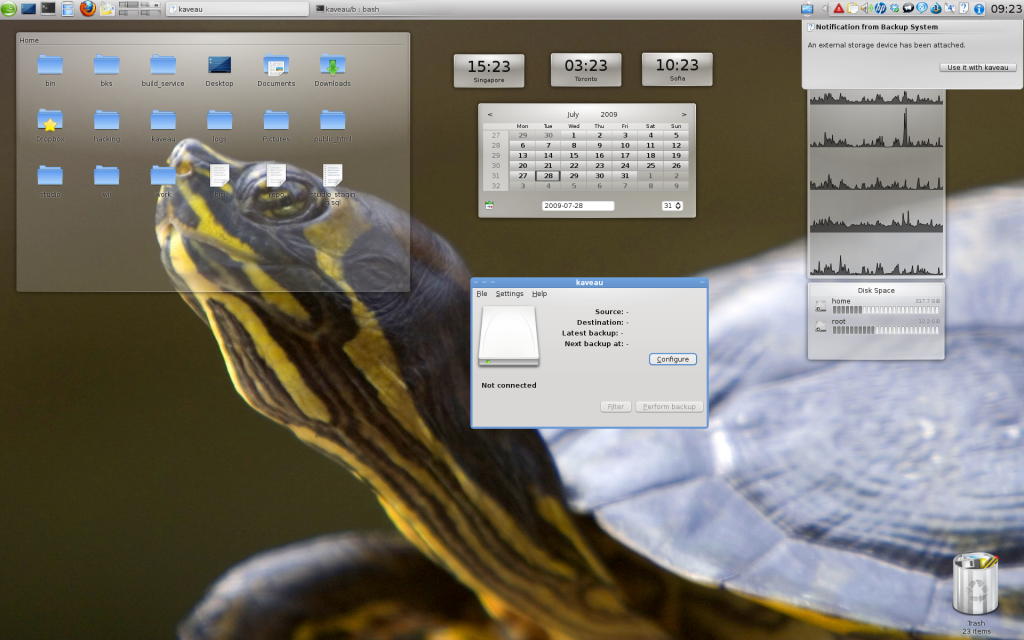
A screenshot tour will give you the right idea of its status.
First run - external storage device attached
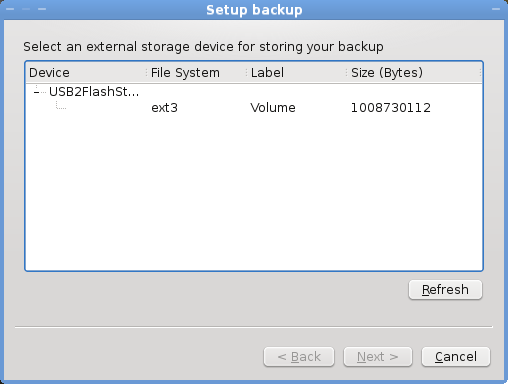
####Backup wizard - page 1
####Backup wizard - page 2
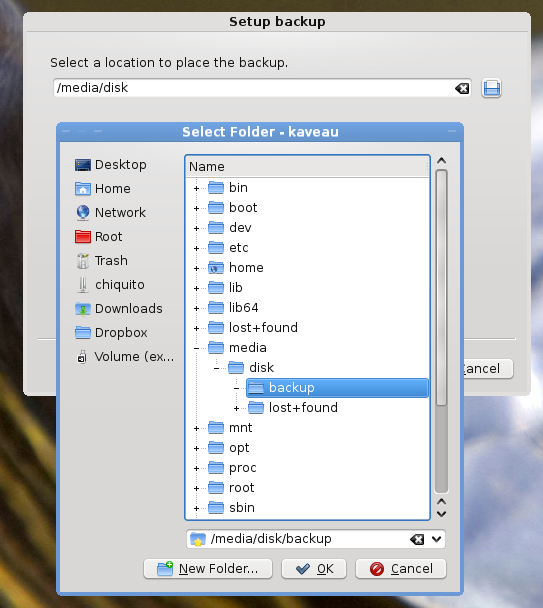
####Backup wizard - final page
####Backup operation in progress
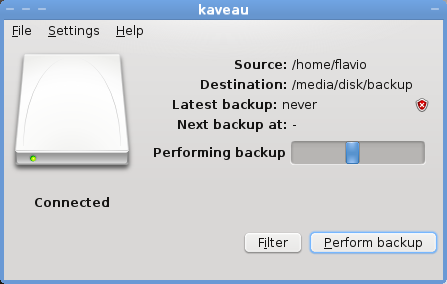
####Backup completed
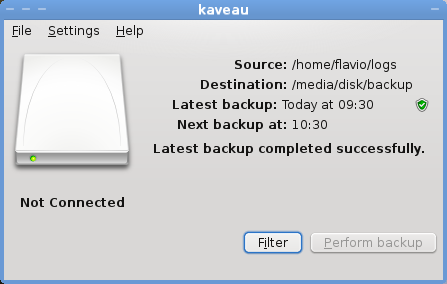
Right now the code is available on this git repository but I don’t recommend you to try it (unless you want to find and fix bugs ;) ).
I would really appreciate:
- feedback about the user interface (right now it looks too much like Time Machine).
- icons: it would be great to have a desktop icon and some system tray icons (contact me for more details).
- new code, bug fixes, code reviews, hints,…
ullae-veliyae: Live graphs for I/O, CPU...
RPM can be found here: http://download.opensuse.org/repositories/home://nikanth/openSUSE_11.1/noarch/
The new shiny Smolt client
Since end of last week I restarted working on my Smolt Qt Client, which was born during first semester exams (nothing to do in that boring and meaningless period, right?). But before I continue, let me quote what the Smolt project is all about:
Smolt is, very simply, a hardware reporting tool for Linux based systems. It was originally written for Fedora and now also supports SuSE, Debian and Ubuntu. It gathers information from users, and stores them in a queryable database with a web frontend that produces statistics.
More information about Smolt here. The original Smolt client was written in GTK but the Smolt maintainer decided to replace it by mine - "With great power comes great responsibility".
The client is quite a straightforward port of the GTK one as you can see:
 Smolt GTK client
Smolt GTK client Smolt Qt client
Smolt Qt clientNoticed the new "Distribution" tab? In a near future it will provides distribution specific information such as installed packages. It has been developed by Sebastian Pipping as a Google Summer of Code 2009 project to support Gentoo, though support for other distributions are currently under development (openSUSE/SUSE Linux, Fedora and Debian):

I will be fixing last bugs found to then push a new release version out late this week, so before openSUSE 11.2 feature/version freeze. In the meantime if you want to try it and even report bugs, checkout my home:cgoncalves:playground repository for the smolt-snapshot package:
openSUSE 11.1:
# zypper ar http://download.opensuse.org/repositories/home:/cgoncalves:/playground/openSUSE_11.1/ home:cgoncalves:playgroundopenSUSE Factory:
# zypper ar http://download.opensuse.org/repositories/home:/cgoncalves:/playground/openSUSE_Factory/ home:cgoncalves:playground# zypper ref home:cgoncalves:playground
# zypper in smolt-snapshot
Please, give us feedback! We want to know your opinion about Smolt!
Call for openSUSE Core Test Team
In addition to well-developed code, testing is a major part of ensuring a rock-solid openSUSE Linux distro. To make sure testing of openSUSE 11.2 (and beyond) are done in a well-organized way, we’re improving the way the openSUSE Core Test Team works together to ensure top quality for openSUSE.
In the next couple of days Milestone 4 of openSUSE 11.2 will be available. This is a very good moment to have a closer look into the next openSUSE release: some new features are already implemented and there is enough time to fix reported problems.
Thus we are looking for 15 members of the openSUSE Community that are willing to contribute to the openSUSE project by joining the openSUSE Core Test Team and operate in the following areas:
- Check if new features are implemented and working as requested
- Have a deeper look into the install and update system of openSUSE and ensure a broad hardware coverage
- Creating, improving and executing test cases for various areas of the distribution
Repository for test cases and tracking system for all test results will be Testopia, the test case management extension of Novell’s Bugzilla. Members of the Core Test Team will get access to the openSUSE test plans and will so be able to contribute. Beside storing test results they are also able to create or modify test cases.
If you are really interested in joining the openSUSE Core Test Team and willing to spend a reasonable amount of time to move the openSUSE project forward please get in contact with Holger Sickenberg <holgi at suse.de> providing following information:
- Your Linux experience
- Previous testing experience, if any
- Areas you are interested in testing
The number of members is limited to 15 at the moment to ensure we are able to adequate support everyone of them. We will add more once we’ve figured out in the smaller group whether everything works.
Of course everybody is still able to contribute to the openSUSE project by testing parts of the distribution. Enabling the openSUSE Core Test Team will not have any impact on that. Further information on testing is available at www.opensuse.org/Testing.
We are looking forward to your application. Deadline for applications is August, 15th 2009.

More Powermanagement for radeonhd
 .
.Determination of some of the values is still scary, and I don't know yet whether we will stumble over them - especially the minimum frequencies are sort-of guessed from the (known) minimum PLL output frequencies. But we need them, because some cards (e.g. one RV770 I have here) only have one known good memory clock configuration, while it can save tons of power if it is lowered (tested + measured, GDDR5 memory really uses a lot of power). Therefor, the values are checked for reasonable bounds, and rejected if they exceed. So if a future chip needs less than 500mV for operation, we will have to update these tests...
The current code has all these bits in place, but doesn't configure anything different than previous versions. First, a set of reasonable settings has to be determined, which will need additional heuristics (this is done in rhdPmSelectSettings(), which needs some love still). This selection also depends on how difficult it will be to change the engine and memory clock, and the VDDC voltage. So far we only set the engine clock, but code is already in place for the other two.
Before setting a clock, it must be made sure that the engines using this clock are idle - that's why we (ahem!) only set the engine clock once at the beginning so far:
- For setting the engine clock, the engine must be idle (surprise).
- For setting the memory clock, memory accesses must be prohibited. Which means that the screen will be blank during this phase. It remains to be seen whether the vertical blank is long enough to do this on the fly. Otherwise this means that we typically shouldn't change the memory clock during runtime. Things get messy when multiple screens are attached...
- For setting the VDDC voltage, all engines must be idle. Also, certain combinations of engine and memory clock require certain VDDC voltages.
 . Remains to be seen whether we can sort-of interpolate between good settings, because typically there are more voltage values available than used...
. Remains to be seen whether we can sort-of interpolate between good settings, because typically there are more voltage values available than used...Later we will need an oracle for selecting the right power state according to the current usage pattern. It might be easier to do that in kernel space, but this remains to be seen.
That's it for today, I actually hoped to get more accomplished during our HackWeek. But reading out dynamic AtomBIOS tables can be... intriguingly complex.