
 Member
Member _Marcus_
_Marcus_Linux Bierwanderung 2009
There is no entrance fee, you just have to pay your own hotel+food+travel ;)
It is not too late to join, in fact you can even just drop by, say hi and join in.
I will probably go, even though I have not booked yet. ;)
Porting Valgrind to Windows
At first I had to resolve lots of SVN merge conflicts after doing an SVN update for the first time in months. The code for Darwin had been merged into Valgrind's trunk and this of course had touched lots of the same places that also my changes touch. After getting it to build again I was relieved to find that it still worked more or less like last time I had hacked on it, and I could continue with real coding.
Despite warnings from upstream developers that a Windows port of Valgrind would basically mean a total rewrite, it hasn't turned out to be that bad. In most of the source files with conditional compilation for the different platforms, the Windows code is basically just one more elif branch. Many parts of Valgrind, like the VEX virtual CPU or the Stabs and Dwarf debug information handling, practically work as such also on Windows.
So, does Valgrind work on Windows? Yes but actually no;)
For trivial console programs, sure, it kinda works, Memcheck detects the kinds of errors it is supposed to detect. (Memcheck is the only Valgrind tool that builds so far.)
But for "real" programs with a GUI it basically doesn't work. A lot of work remains to be done, and some mysteries remain to be solved. A healthy dose of pessimism is useful: I am not that sure it will ever work well enough to be useful.
What kinds of applications could Valgrind eventually be useful for on Windows? Personally, I would look forward to the possibility to use it on Open Source applications based on Open Source libraries like the GTK+ and (partial) GNOME stacks. GIMP or Evolution come to mind. Why not Qt-based applications, too. Perhaps even OpenOffice.org. I am not personally interested in making Valgrind work for applications based on weird proprietary technologies like COM.
I have been hacking it on 32-bit XP. Some minor additions are needed to handle also WOW64, i.e. 32-bit code on 64-bit Windows, and more major additions for 64-bit Windows.
So, what can you do to help? If you are an application developer with no in-depth Windows knowledge, don't bother. If you are an experienced Windows hacker with knowledge of kernel and Win32 subsystem system calls (or are prepared to learn about such things, like I was), you can help.
For anybody interested in helping, prerequisites would be as follows:
- A basic understanding of how Valgrind works on Linux
- A MinGW and MSYS installation, and some experience of gcc in general and MinGW in particular
- An SVN client, to keep up with upstream development
- Autotools, to be able to run the autogen.sh. If requested, I might be convinced to run a make dist now and then to create a tarball that includes my diffs and a pre-generated configure script.
- Debugging tools for Windows, to get the latest windbg.dll, and to get WinDbg which is essential for finding out how undocumented things work. (Of course, if you have more advanced tools like SoftICE available, the better.)
- Literature (or a good knowledge of these things by heart...). I recommend the following books:
-
Windows NT/2000 Native API Reference by GaryNebbett. Documents the kernel "native" API. Needed for writing wrappers for kernel system calls. Might be hard to find. Much of the same information is also available on the web.
- Windows Internals, Fifth Edition by Mark E. Russinovich, David A. Solomon and Alex Ionescu. A classic, the fifth edition of which has just been published.
- Advanced Windows Debugging by Mario Hewardt and Daniel Pravat.
-
Windows Graphics Programming: Win32 GDI and DirectDraw by Feng Yuan might also be useful.
- Wine and ReactOS sources can be useful at times
- Decide whether all this makes any sense at all, whether it's best just to declare it a failure before wasting any more time.
- Write wrappers for more kernel system calls.
- Write wrappers for such Win32 (GDI, USER) system calls that modify data (to tell the tool what memory has been written to, to avoid invalid warnings about use of uninitialized data). Mostly undocumented territory here.
- Fix the mysterious issues in handling callbacks from system calls (this happens a lot in GUI programs; in fact most user code in such executes in callbacks). Callbacks are a bit like signal handlers in POSIX, except that they aren't, as callbacks and system calls can be stacked arbitrarily high.
- Fix issues related to communication with csrss.exe. Again, this is mostly undocumented foo...
- Does SEH need any handling?
- Read MSVC debugging information (.pdb files). (Either using Microsoft's APIs, or the existing code in Valgrind.)
- Test on Vista and Windows 7
- Make it cross-compilable from Linux
- Make it buildable with Microsoft's tools. (Either just a makefile for nmake, or a Visual Studio project.)
- Once it works well enough, some kind of integration with Visual Studio
Making Valgrind buildable with Microsoft tools would not be impossible. If I get offers of help from otherwise qualified people who would want to help but can't/won't use MinGW, I might try. A couple of short inline assembly parts would need MSVC syntax versions. A couple of assembler source files would need MASM syntax versions. Does MSVC support vararg macros in its preprocessor?
I have diffs at http://www.iki.fi/tml/valgrind/ . Apply to valgrind trunk from SVN as of the time indicated. Making binaries available is not really useful at this stage (if ever).
Ullae-veliyae (iotop-gui) : Hackweek
The hackweek project I worked on was to implement a live graphing utility for per process I/O data. See https://features.opensuse.org/306941 (Yes, I added the fate request, just now, after doing most of the work.)
Screen-shots, RPM download link, project homepage link,..
The main idea behind choosing to work on this was to do some GUI programming on a modern language. I work on the linux-kernel(so no gui) and most of the time I write ‘C’ programs.(In fact, at times even when bash would be appropriate!)
So I decided to do this and had to choose between moonlight and Java. My experience with C# was nil, and moonlight was an applet/flash equivalent not aimed at desktop apps.(Yes, there are desktop applications in flash. Even mono has mopen) I thought that I would have to access procfs and might also need to do netlink sockets and moonlight could be a problem. And the real benefit of flash is the the IDE/designer for development, which anyway moonlight is yet to get. In the end, I chose Java.(was a tough fight with C# but again gtk# versus winforms…)
And here it is..
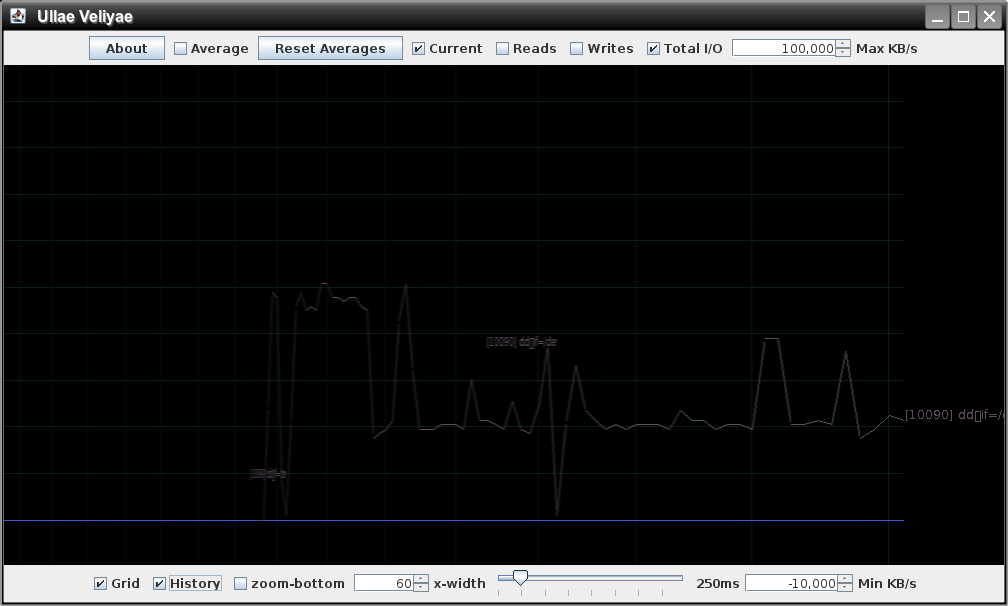
watching dd...
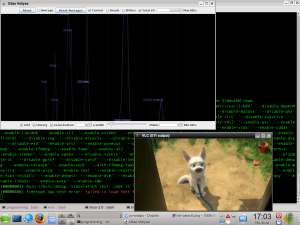
Watching vlc reading from disk as I seek
You can download it from http://download.opensuse.org/repositories/home:/nikanth/ The source is also available at http://gitorious.org/ullae-veliyae/
RPM quick Links:
[Yes, it should be made as no-arch! ;)]
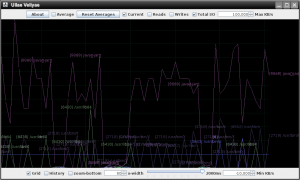
chaos
If you are trying it out, see whether you can find an easter egg?  [Yes, it is kind of lame to have easter-eggs on a open-source project with just hundreds of LOC] The easter egg is an hidden functionality.
[Yes, it is kind of lame to have easter-eggs on a open-source project with just hundreds of LOC] The easter egg is an hidden functionality.
I should thank Vojtech Pavlik, for his very useful ideas of “history”, such that we can squeeze the historical data and keep it for longer duration. And another idea of showing average of the data instead of current data, as it tends to be spiky. I haven’t implemented rolling-window for the average though.
A picture is worth 1000 words, but trying it out yourself is worth much more than that. So play with this once. 

New QJson release
Gran Canaria Desktop Summit has been great and really productive. I had the pleasure to meet people interested in QJson, chat with them but also hack with them.
In fact we hacked a lot, doing lots of changes to QJson:
- the API has been cleaned, now it can be considered stable
- unicode support has been completely rewritten
- it’s now possible to convert QVariant objects into JSON ones
So it’s with a great pleasure that I announce the release of QJson 0.6.0.
Beware, since the API has been changed your application will probably break. I’m really sorry about that, but I guarantee it won’t happen in the future (as I said both API and ABI interfaces can now be considered stable).
QJson web site has been updated, reflecting all the changes made to the library. openSUSE packages has been moved from my home repo to KDE:Qt one.
One last note, if you have problems with QJson please contact me using the qjson-devel mailing list. You can subscribe here.

Voulez-vous chercher les paquets avec moi?
... YaST webpin package search client!
It is already quite some time since I blogged about YaST frontend to webpin package search, which enables user to search packages in online repositories and install them via one-click handler later. I proposed some solutions of integrating it with the rest of YaST, but did not particularly like any of them (that's the perfectionist side of me ...). After being (just a little bit :)) poked by some openSUSE users, I decided to implement two of the less perfect solutions ;-) in the first part of Hackweek IV.
In order to use the client and search packages in online repositories, you will need a new yast2-packager-webpin package (which has been splitted off the "main" yast2-packager). It contains the module, the client and the .desktop file, which effectively adds the icon to YaST control centre. The idea behind creating a new package is rather simple - not to clutter software section of CC with (similar) modules/icons by default for all users, including those who don't want to make use of that functionality. Now I guess I've made this package (originating from Packman) rather obsoleted .. :)
In addition to that, you can launch webpin package search from package manager's menu (Qt and ncurses so far), just as you would do with repository manager or online update configuration.
Call for contribution
These are the things that still need to be done in order to get webpin search integration even better:1. A new icon for webpin client is needed - as you can see, I recycled package manager icon for the time being
2. Gtk package manager (yast2-gtk-pkg) can't call webpin client currently - should be simple and straightforward to add the functionality to it.
If any of those sounds appealing to you, please let me know and I'll give you all the necessary information on how, what, where etc. :)
FAQ's
Q: Why haven't you made webpin search separate filter view of package manager/integrated it into regular search in existing package manager(s) GUI?A: Because neither of package managers (Qt/Gtk/curses) speaks XML and webpin search engine does not speak libzypp. Learning PMs read XML and adjusting their data models to feed it, along with libzypp data, to UI is work for few hackweeks in a row (for me, a person with zero experience with C++ XML libs - yast2-packager-webpin uses Perl XML::Simple). However if anyone's willing to hack on this ...
Q: Why does webpin search not work in Factory?
A: Because Factory is not a rpm-md repo. See bug #431939 for gory details
Introducing Libstorage
Libstorage is a C++ library for managing Linux storage devices. So far it was developed as part of YaST but since a few weeks it is an independent project.
Here is a code example creating a 1GB partition on /dev/sdb.
Environment env(false); StorageInterface* s = createStorageInterface(env); string name; // Create 1GB partition on /dev/sdb and format it with Ext4. s->createPartitionAny("/dev/sdb", 1048576, name); s->changeFormatVolume(name, true, EXT4); // Set mount-point to "/home" and fstab option to "relatime". s->changeMountPoint(name, "/home"); s->changeFstabOptions(name, "relatime"); // Set filesystem label to "HOME" and mount filesystem by label. s->changeLabelVolume(name, "HOME"); s->changeMountBy(name, MOUNTBY_LABEL); // Commit the change to the system. This will create the partition, // format and mount it and update /etc/fstab. s->commit(); destroyStorageInterface(s);
Besides of hard-disks libstorage handles RAID, LVM, NFS, various filesystems and encryption. Swig generated Python bindings are also provided. Libstorage has no dependencies on YaST, neither for building nor runtime. We hope libstorage will also be useful for other projects.
More information is available in the openSUSE Wiki, including a list of useful features people would love to see implemented in the near future.
Comments are as always welcome.
Firewall Zone Switcher
So you got that shiny new Netbook, installed Linux on it and carry
it along everywhere you go. The default enabled Firewall blocks
incoming traffic so you feel safe when connecting to that anonymous
WiFi network at your favorite fastfood restaurant. Unfortunately the
very same Firewall becomes quite annoying at home where it prevents
your system from discovering printers or blocks ssh.
You have the choice of either opening the ports permanently,
exposing your system in hostile networks, or having to use sudo to
enable or disable the Firewall. Well, not anymore with Firewall Zone
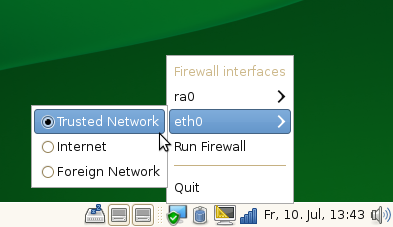
Switcher! With that little applet you can now switch the zone of
your network interface to ‘internal’ with only two mouse clicks when
you are at home. In an untrusted Network you just set the zone to
‘external’. And if you need some custom configuration you could set
the zone ‘dmz’ to have some open some ports or create a custom zone.
Firewall Zone Switcher is *not* meant to be some kind of ‘Personal
Firewall’ that confuses the user with all kinds of low level stuff.
It’s neither a Firewall configuration tool. That job is still left
to Admin tools like YaST. Firewall Zone Switcher settings are
temporary and are reset to the system defaults on reboot.
Firewall Zone Switcher consist of a DBus service and a system
tray applet. Both are written in python currently to have proof of
concept program quickly. Packages are available from the openSUSE
build service. You also need to update SuSEfirewall2 from that
repo. Source code repo is available at gitorious.
Keep in mind that the app as well as the patch to SuSEfirewall2 are just proof
of concept ie experimental so there will be bugs. Feedback welcome nevertheless
OpenSUSE 11.1 and Plesk 9.2.1 update
After more than three years of using Suse 9.3 with Plesk 8.1 on one of my VPS, I decided that it is time to update to OpenSUSE 11.1 with Plesk 9.2.1 control panel. The update process went very well, here are the steps involved:
1. create a full backup of your vps (databases, websites, accounts,
emails, ...). I have used "tar" command for that.
2. in plesk 8.1 control panel, do a complete backup (you need plesk
backup module to be installed), or if you prefer the command line you
can use the following command:
# /usr/local/psa/bin/pleskbackup all
Since version 9.x, the structure of Parallels Plesk Panel backup has been changed. Plesk backup created with Plesk Backup Manager is not just one file but a number of files and directories under backups directory /var/lib/psa/dumps. So, you will need to convert your backup file created in plesk 8.1 to be compatible with plesk 9.x. It's a very simple process, see step 3.
3. convert the created backup file to be compatible with plesk 9.x
# /usr/local/psa/bin/pre9-backup-convert -v convert -d /var/lib/psa/dumps/
where /var/lib/psa/dumps/ is backups directory on the server with Parallels Plesk Panel 9
4. restore the backup files to use them with plesk 9.x. It can be done using the web interface, Home -> Backup Manager -> Server Repository, click the backup name to enter the backup details page and select the required restoration options and click Restore to start the restoration process.
If you would like to use command line to restore your domains, clients, server configuration, ... then you can use the following command:
# /usr/local/psa/bin/pleskrestore --restore /var/lib/psa/dumps/ -level server -verbose -debug
You can restore only clients or domains, for more options see:
# /usr/local/psa/bin/pleskrestore --help
Note: I had a small problem and I found that it is not possible to have a client with the same name as your name in Plesk Admin Profile. Maybe it is stupid, but I had some errors and only after I changed the name in Admin Profile (in Plesk control panel) to be different, I could restore without any problem everything.
I think that's all what I did, from what I remember. If something is missing I am sure you can find a lot of useful stuff using our friend google.
Other useful stuff:
1. Plesk 9.x support as well postfix, so if you want to change from qmail to postfix, try that:
# /usr/local/psa/bin/autoinstaller --select-release-current --install-component postfix
if you are not happy, you can switch back to qmail:
# /usr/local/psa/bin/autoinstaller --select-release-current --install-component qmail.
If you are not sure if you are using qmail or postfix there are many ways to find that, one is to look in Plesk Control Panel on the Services management page {Home -> Services Management} if you have SMTP Server (Postfix) or SMTP Server (QMail)
If you decide you want to switch back, simply, do it, the emails are not lost, don't worry.
2. Replace Horde webmail with AtMail
One of the many new features of Plesk 9, is the option to choose a different webmail client. The default webmail client Horde can be replaced if you are looking for something a bit lighter, AtMail. You need to install from Plesk Control Panel, both webmail clients, and to switch between them:
- Log into Plesk.
- Chose the domain which you want to use another webmail, enter on “Mail Accounts” page
- Click the “Mail Settings” icon
- Switch the “WebMail” to “AtMail (default is Horde)
- Click “OK”
If you decide you want to switch back, simply reverse the procedure, the emails are not lost, don't worry.
That's all.
References:
http://kb.parallels.com/en/5819
http://kb.parallels.com/en/5801
http://kb.parallels.com/en/952
http://kb.parallels.com/en/5969
http://kb.parallels.com/en/5864
Atomic git
A solution could be to have the git repository inside another git repository. For example, have the linux-2.6.git repo inside another git repo, say git-o-git. When you do a pull in linux-2.6.git, and if it succeeds do a `git commit -a` in the outer git-o-git. If it fails for some reason, one can go back to previous version of linux-2.6.git repo by doing a `git clean -d -f` and `git checkout -f` in the outer git-o-git.
It should be possible to add wrapper scripts to `git` and do this auto magically. May be it could be called as git WC, as it is built on top of git porcelain, which is built on top of git plumbing commands. ;-)
Has anyone tried this already?
GIT pull mishap and git clean
Updating ce8a742..faf80d6
error: git checkout-index: unable to write file drivers/usb/gadget/s3c-hsotg.c
error: git checkout-index: unable to write file drivers/usb/gadget/u_audio.c
error: git checkout-index: unable to write file drivers/usb/gadget/u_audio.h
Freed some disk space and re-ran the `git-pull`. But it failed saying
$ git pull
Updating ce8a742..faf80d6
error: Untracked working tree file 'Documentation/ABI/testing/sysfs-bus-pci-devices-cciss' would be overwritten by merge.
Some of the files were created by the previous pull, but they are considered untracked files as the previous pull failed. `git pull -f` didnt help as git was reluctant to delete my untracked files.
Deleting huge list of files one by one was a pain. I was thinking of doing a git status to get the list of untracked files and deleting them. But Jony rescued me by telling me about `git clean` which can delete all the untracked files!
But I would really like to see a way to pull/checkout and over-write the untracked files, so that other untracked files, which will not be over-written, need not be deleted. Is there a way to do it?