
 Member
Member cgoncalves
cgoncalvesopenSUSE KDE Bug Squashing Days (20-21 September)
 The openSUSE KDE team wants to dedicate some time on KDE bugs before openSUSE 11.1 gets released, focusing on reported KDE bugs on bugzilla.novell.com inviting the community to take part of it.
The openSUSE KDE team wants to dedicate some time on KDE bugs before openSUSE 11.1 gets released, focusing on reported KDE bugs on bugzilla.novell.com inviting the community to take part of it.Let's stamp out bugs in KDE for openSUSE 11.1! The openSUSE KDE team is holding a Bug Squashing event to work the KDE bugs reported in bugzilla.novell.com. You can be a part of a bug-free KDE!
The openSUSE KDE Bug Squashing event is scheduled September 20 through September 21 (right after openSUSE 11.1 Beta1 release), and the main goal is to have zero bugs!
In order of priority, we have the following list:
- Find duplicated bugs, and obviously close then as DUPLICATE;
- Non openSUSE KDE bugs (KDE upstream bugs) should be:
- Reported on bugs.kde.org (if not yet);
- Added the upstream bug URL to the URL field on bugzilla.novell.com;
- Closed as UPSTREAM (resolution field).
- Filter KDE 4.0 bug reports and try to reproduce them on KDE 4.1:
- If you can't reproduce close them as WORKSFORME and leave a comment as it was most probably fixed on KDE 4.1;
- If you still can reproduce them, try to investigate why/how that happens (eg: step-by-step on how to reproduce) and state it's still reproducible;
- Same as above but for KDE 4.1 - taking in consideration the quicklydevelopment of KDE4 it's really easy that those bugs reported have beenfixed meanwhile.
- Help providing info for bugs marked as NEEDINFO
- Set priority for bugs with Priority = P5(None).
- Explore KDE3 and KDE 4.1 looking for bugs. See if KDE3 ones are fixed for KDE4. Bug report them.
Note: Bug squashers should start from higher severity/priority bug reports to lower ones.
To successfully achieve all these tasks, the openSUSE KDE team needs as many people as possible. All you need to help is one (or more) of the following to help us with debugging:
- An updated openSUSE 11.0 or openSUSE 11.1 system
- KDE 3.5.10 installed from KDE:KDE3 OBS repository
- KDE 4.1 installed from KDE:KDE4:Factory:Desktop OBS repository
During the event the community will be in the #opensuse-kde channel on irc.freenode.org to help you out in whatever you might need. The openSUSE KDE mailing list is also a great way to communicate with the KDE community.
See the openSUSE KDE Bug Squashing Days page for more and updated information at http://en.opensuse.org/KDE/Bug_Slashing/20080920
Have a lot of... openSUSE KDE Bug Squashing Days! ;-)

YDialogSpy: An Interactive YaST Dialog Debugger
Programming a GUI version of “Hello, World” is easy in the YaST programming environment, no matter if it’s YCP (the YaST-specific scripting language), plain C++, Perl, Python, or Ruby.
But if dialogs become more complex, it can get demanding to make them look good and – equally important – to behave well as the user resizes dialogs:
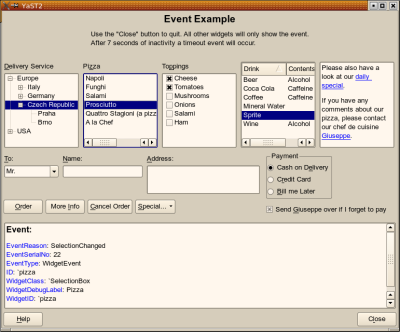
The YaST UI (user interface) engine now features a new debugging tool to make life easier for developers: YDialogSpy. In the Qt version, hit the magic key combination
Ctrl-Shift-Alt-Y
and you will get a YDialogSpy window like this:
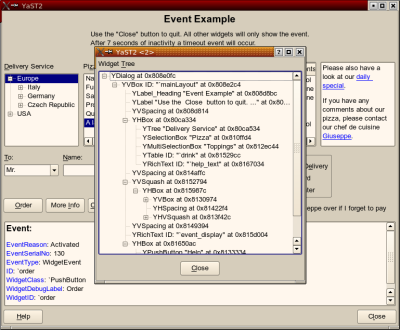
This shows the widget hierarchy of the original dialog as a tree. Clicking around in that tree, you can highlight the corresponding widget (and its child widgets) in the original dialog (move the YDialogSpy window to the side first):
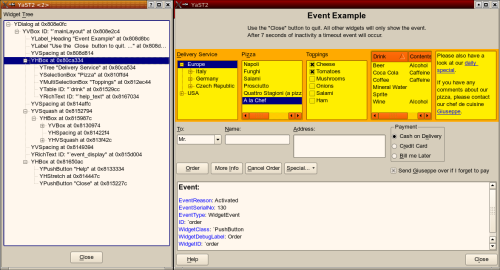
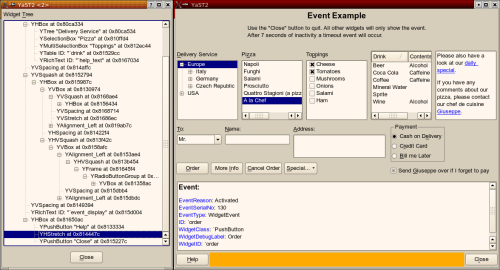
This can also make widgets visible you normally can’t see such as H/VSpacing, H/VStretch etc., and it shows the extent of alignment widgets (left, right, top, bottom) as well as layout boxes (H/VBox):
Availability
yast2-libyui-2.17-9 or later
yast2-qt-2.17.8 or later
The Future
This is just a first version, of course. Future versions will get a “Properties” table that can show certain values of the current widget. Maybe there will also be some (very limited) editing capabilities.
Stay tuned.
Further Reading
http://en.opensuse.org/YaST/Development/Misc/YDialogSpy
(With original-size screen shots)
openSUSE Buildservice: cross-build with OBS Part 3
This is the third part of my article series about the Hackweek Project “cross-build in the OBS” and the current OBS development. The first part can be found here, the second here.
What happened in the meantime?
First of all, the generic code for cross-build went into the subversion repository. The specific patch for cross-build is currently in the flow, because Michael Schröder will incorporate Worker Resource Management into the OBS. This is also important for cross-build, and covers also some areas of the code where also cross-build is implemented. So the cross-build patch is currently kept separate, until Michael is finished. Also, we are working on a more elegant solution to install the qemu packages in the chroot before the worker / local build starts in the emulator. And the KIWI support inside OBS should also work with cross-build repositories.
Second, there are now completely prebuild cross-build OBS packages inside build.o.o. You can use cross-build with “osc build” local build and with OBS workers. Just install the packages from openSUSE:Tools:Devel/obs-all-cross (currently using OBS svn trunc -r 4948). Also, there is an updated qemu inside openSUSE:Tools:Devel/qemu-svn (currently using QEMU svn trunc -r 5181 with lots of patches), that you should install. In case of non cross-build, the codepath should behave exactly as before and exactly as the pure obs snapshot from subversion without the cross-build patches. The solution is good enough to compile complete packages and even projects for Debian:Etch/armv4l, and for Maemo:4.1/armv4l. I measured an average speed mix between IO bound jobs and CPU bound jobs of ca. 1:5-7, which is faster than expected, and also a lot faster than using system emulation. Should you be using native PowerPC workers, you have to deactivate cross-build for PowerPC at the moment inside the code (until Worker Resource Management is implemented).
There are plans to activate cross-build also on build.o.o, for everybodies use. But we are currently fighting with the qemu user mode issues, especially on non Arm architectures. QEMU on PowerPC specifically in user emulation is not generally usable for cross-build at the moment.
Dirk has in the meantime also provided a collection of the Maemo 4.1 packages, so at a later stage these can be used on Arm. This is currently work in progress, so don’t expect it to work yet. The project Name in build.o.o is Maemo:4.1. It provides an arm development enviroment for the Nokia N810 Linux Mobile Phone as well as exactly the same packages for i586, to develop and run the software also on a PC, and is based on Debian.
Next Steps?
Integration of the remaining cross-build code into the mainline OBS code when Michael has done some grounding work.
Installation of the emulators with the OBS preinstall facility. This will also allow to replace very slowly emulated packages by some cross-build packages instead. It allows a mixture of cross-build Type 3 and Type 4.
Integration of Marcus Hüwes work on remote repositories, allowing to get packages and projects from normal ftp/http installation/update trees.
Kiwi support for cross-built repositories.
Activation of cross-build on build.o.o.
If I forgot a cool feature to mention, I would be happy to get feedback on what you would like us to do.
Keep happy hacking with the cross-build OBS packages provided.
ENOS 2008: a quick review
As announced on openSUSE News, ENOS 2008 took place this Saturday, September 6th at ISEP, Porto, Portugal. The event started at 10:00 am (local time) and during 1h:30m people had the opportunity to meet each other in a non formal environment, and at the same time I gave away openSUSE t-shirts, caps, lots of stickers and PromoDVDs (thanks Novell, specially to Martin Lasarsch!) to them. At 11:30 we started the two scheduled morning presentations:
- "The openSUSE 11.0 News" (Carlos Gonçalves, PDF) - as the name says, I presented the news of openSUSE 11.0, but also took the opportunity to do an overview of the openSUSE project since many of the attendance wasn't openSUSE users, and at the end random slides including information on how to get involved, how to communicate, openSUSE 11.1 roadmap, etc.
- "Migrating from Windows to Linux" (Lívio Cipriano, PDF) - a great talk by Lívio on how to migrate from Windows to Linux with good points of view and tips to easily migrate even in enterprises environments, eg: start using cross-platform software such as OpenOffice.org, Firefox, and Thunderbird and later migrate to Linux - users won't notice much difference indeed.
- "YaST - a programming platform. PackgeKit and PolicyKit" (Ricardo Cruz) - it was mainly a technical talk about YaST. Ricardo showed us how simply is to create a "Hello World!" windows, buttons and some widgets. He also introduced PackageKit and PolicyKit.
-
"Oxygen, a pillar of KDE4" (Nuno Pinheiro, PDF) - Pinheiro's main goal with this presentation was to demonstrate that Oxygen is not a KDE icons theme, but rather much more stuff than that.
-
"Qtractor, an Audio/MIDI multi-track sequencer" (Rui Capela, PDF) - Linux Audio hacker on his spare time Rui spoke about his audio/MIDI multi-track sequencer Qtractor application, gave audio demos using it, and highlighted some Linux Kernel Real Time 2.6.{26,27} issues as for example the time lag problem kernel-rt is facing at the moment.
-
"Mono - introducing Mono and its features" (Andreia Gaita) - what can I say... awesome talk! Andreia presented Mono and MonoLight, what made them, developers, develop such technology, what we can do with it, etc. This talk was indeed one of the reasons to people have attended ENOS 2008.
Gallery








See the rest of the photo gallery
ENOS 2009:
ENOS 2009 already has place, Castelo Branco, and it will be organized by Associação de Informática de Castelo Branco. Anyone interested in helping us is highly welcome. I hope see you next year! ;-)The Community:
- Mailing list: opensuse-pt@opensuse.org (subscribe)
- IRC: #opensuse-pt on irc.freenode.net
- Web: http://opensusept.org/
Big thanks to Porto Linux, ISEP, and Novell for the support!
Thanks to all attendees for participating!
P.S.: there are two presentation PDFs missing. I will add them as soon as possible.
small Qt based mail biff
Some days ago I was asked what this little button bar on my desktop is and I explained that it’s only a small program I wrote to keep track on my mail folders. I know there are many many programs out there which already does the same but for some reason he liked it and encouraged me to blog about it 
qbiff runs as a server client application and is able to manage mails stored in the maildir format. The server should run on the machine which locally stores the data and the client or multiple of them can run on the desktop you have an eye on. The connection(s) between the server and the client(s) are SSL connections, even though there is no mailcontent which is transfered the information how many mails, how many new ones and what mail folders exists might be an information not everybody needs to know about… so I chose a secure connection 
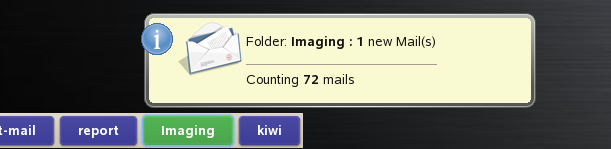
If the file .qbiffrc exists the user can control which mail folders should be checked, if the file doesn’t exist all folders the server finds at start up will be used. Each folder is represented by a button. Whenever a new mail arrives the button changes its color and notifies the user with a tip window about the current mail situation of this folder. A click on the button runs a user defined program whereas the first parameter is the path and name of the folder. In my setup I call mutt respectively to read the mail in the folder
So it looks basically like this…
Packages can be found in my home Project at:
- http://download.opensuse.org/repositories/home:/sax2
- Install the package qbiffd on your server
- Install the package qbiff on your client, server and client could be the same machine
- Edit the file /etc/sysconfig/qbiff on the server and setup at least the QBIFF_USER which should be the same user the mails belong to and the QBIFF_FOLDER which is the base directory of your mails
- Run the server by calling rcqbiffd start
- Run the client by calling qbiff-client. The default password for the SSL certificates is “linux“
- click on a folder button and read the note about how to setup a personal mail reader script
If you want to create your own certificates you need to check out the code at
- svn co https://svn.berlios.de/svnroot/repos/qbiff/qbiff-head .
and run the following commands:
- cd cert-server && make distclean && make
- cd ../cert-client && make distclean && make
- cd ..
- ./.certinstall on the server and the client

Hackweeks
I was not so lucky as most of my teammates, who spent the week on the wonderful offices (as they say) of Novell Utah. Maybe if I was in the states already... but well, I had recently an interview in the US Embassy which was the last step of my visa process, so I hope that at least I can make it for the Gnome Boston Summit!
So, firstly I thought of dedicating my week to this task that I submitted to the ideas website, but in the end realized it would be a ton of work to complete without help, and nobody joined me so I decided to learn to use OpenSuseBuildService in order to package Bugzilla, a pretty complex server side software.
Fortunately, I've learnt a lot this week, especially thanks to all the people in irc://irc.freenode.net/#openSUSE-buildservice (above all, darix) and some people from my team (Ray Wang and Stephen Shaw). I could also contact the author of the RPM file for Fedora (who was formerly working for Red Hat), and he's willing to help on joining efforts, as OBS is cross-distribution.
Unfortunately, packaging is a complex task and I didn't finish the package. The documentation is a bit incomplete and having past experience in packaging is a plus that I didn't have. It's awesome that inside our UIA Team we have exclusive resources dedicate to this, because it would be impossible to do from just the developer side.
One of the difficulties I found is finding packages I needed. I could find some of them (BTW, using Webpin is cool for searching on SUSE software repositories, including Packman; except for the fact that doesn't enhance one-click-install) but not all so then I'll have to help on providing packages for some CPAN Perl modules, contributing to the devel:languages:perl official repo.
On the way of learning OBS, I also filed bugs and feature requests (not only to OBS, but also to Banshee! as I have been using it a lot lately at the same time I hack and I even cooked some small patches):
OBS:
Usability issues in project creation page
Link to "My projects" fails if no home:login project has been created yet
New option for uploading the tarball
ChangeLogs parsing is too strict: lines beginning with tab are not recognized, only one date format is accepted
OBS should not allow to create a package named "packageand"
The spec parser should detect the use of a miscplaced packageand(_:_) keyword
Banshee:
No such file or directory errors while importing
Cannot empty some ID3 tag fields
Importing songs without album metadata breaks artist navigation on the iPod
Banshee inserts deduced fictional text on metadata
Should try to locate correct album (and download its cover) in case no album is supplied on metadata
The patches are quite simple so I hope they get committed soon! Clearly Banshee devs and contributors are doing an amazing work, I'm specially amazed by the Moonlight effects, the Muinshee front-end and the effort that it seems is being dedicated to bring Library Sync & Refresh for 1.4. I wish them all the best success.
So let's get back to packaging. Firstly I thought I had found some limitations in OBS or rpm systems because the lack of proper "dual dependency" support. In the past when I installed Bugzilla manually (and updated it to newer versions) I found it a bit hard to do it, specially to deal with DB creation and upgrade. I wanted to make this process easier for the potential rpm user, but without limiting the choice of the DB engine used (as now Bugzilla supports MySQL, PostgreSQL, and Oracle, although the latter was not on my scope). It turns out that it's really hard to apply virtual-provides rules for these cases, as we should stablish more sub-dependencies depending on the db engine you choose, such as perl-DBD-mysql or perl-DBD-Pg, and because it would cause inconsistent situations in case someone in the future replaces his DB-engine with the alternative one (as in theory it should work at the dependencies-level without warning). For references, you may be interested in reading the whole thread about it in the BuildService mailing-list, whose last message includes a possible hack to workaround these problems using patterns (although I don't like to use patterns for solving something like this).
Even discarding the dream about solving this at a package level, it's difficult to solve it at an app level that wouldn't involve reading manuals. My idea was to modify Bugzilla upstream in order to avoid running manually a local script for its initialization, and replace it with a nice web front-end (even if it's only allowed to be run locally). That would cause problems because normally the webserver user doesn't have enough permissions to create files and the database tables and initial data (I'm sure there's always a solution that also doesn't expose security problems, but it's hard to find it as it's noticed in this thread in bugzilla devel newsgroup; so, help is truly welcome).
Maybe the easier and fastest solution is a mixture of both worlds, that is, having a web front-end that asks you the initial configuration, and the form submission process just writes it in a local XML and tells the admin to open a console and run a script as root to finish the process. But even with this solution I guess we should need something to detect at runtime (which should be cross distribution) if some package is installed (which also checks the version). I guess there's already some of that capabilities used in the bugzilla's script checksetup.pl, so I would reuse them. However, in case it finds a problem, there's no way for the application to request installation of a package directly to your OS (but I've attended to a PackageKit conference in last Guadec in which I heard something about this possibility in the future!).
opensuse-tutorials is up online
There are fedora-tutorials, ubuntu-futorials website on the web, for anyone who envies, of course, we have opensuse-tutorials either.
This link is for those who doesn’t don’t know it yet.
feel free to register and contribute to it.
Planning a short stay in Boston
This is going to be an interesting end of year.
BTW, I'm currently looking for a small apartment (or big room) to rent, ideally around Cambridge. Unfortunately I'm not having much success, since apartments I found are either too expensive, or not available for those two months. So if you know about some good place, information will he highly appreciated! (mail lluis at novell dot com).
Google Chrome on openSUSE
As I guess everyone notice, Google has released their own Browser called Chrome. Based on Webkit (based on KHTML of KDE fame) it is a small, fast and foremost secure webbrowser. And if you are reading this, you likely know that it does not work on Linux, but only on Windows.
But wait … we have the Windows Emulator Wine and I am one of its developers…
This also explains the first comment from a colleague on Wednesday morning was: “Why don’t you have fixed Wine to run it yet?!?” We tried together to get the online installer to run, but not successful.
Over night however some other folks found out how to do it by using the offline installer.
So how to install Chrome:
1. Get the Wine 1.1.3 from the openSUSE buildservice Emulators:Wine repository.
Its available via the Community Repositories Module in YAST2 on openSUSE 10.3 and 11.0,
after adding this repository upgrade the wine package.
This piece of code run as root will do it on openSUSE 11.0:
zypper sa http://download.opensuse.org/repositories/Emulators:/Wine/openSUSE_11.0/ Wine
zypper in wine
All other steps are done as desktop user from a regular shell.
2. Download the Chrome Offline Installer
wget http://gpdl.google.com/chrome/install/149.27/chrome_installer.exe
3. Install richedit native libraries.
While Wine contains richedit libraries they are not yet up to the task to help Chrome yet.
(This is likely to be fixed soon.)
To install them run:
winetricks riched20 riched30
3. Run Chrome Installer
wine chrome_installer.exe
This will popup a dialog where you can press return until Chrome itself starts.
Since we need to supply Chrome with some Options to make it work with current Wine, you need
to close it again. Click anyway any crash messageboxes.
4. Run Chrome itself
We need to supply Chrome with some additional commandline options to make it run with Wine,
so we need to do start it by hand (instead of clicking on the convenient Desktop Icon already there).
cd ~/.wine/drive_c/windows/profiles/*/*/*/Google/Chrome/Application
wine chrome.exe --new-http --in-process-plugins
5. Surf!
And of course the obligatory screenshot:
Most of the funny workarounds above will actually vanish in the next Wine releases, now that the Wine developers can actively debug it.
The WineHQ Application database entry has the ongoing discussion of getting it to work and links to the Wine bugzilla entries.
Convenient setters in C++?
RepoInfo & reference to the modified object. This pattern is common in higher OO languages like Java and is convenient as it saves typing when setting serveral properties at once (i'm not sure how it is performance-wise).
RepoInfo repo;
// you write
repo
.setAlias("foo")
.setName("Foo Project Repository")
.setEnabled(true).setAutorefresh(false);
// instead of
repo.setAlias("foo");
repo.setName("Foo Project Repository");
repo.setEnabled(true);
repo.setAutorefresh(false);
Unless the class is part of a class hierarchy, everything's OK. But after splitting RepoInfo to RepoInfoBase and a derived RepoInfo the dark side of C++ has shown up.
RepoInfo repo;
repo
.setAlias("foo") // RepoInfoBase setter
.setEnabled(true) // RepoInfoBase setter
.setPriority(50); // RepoInfo setter - this won't compile becase setEnabled() returned
// a RepoInfoBase &, and C++ does not bother with figuring out that the
// object is also a RepoInfo.
In order to make this work in this setup, you have to redefine each setter from the base class in the derived class and make it return the reference to the derived class:
class RepoInfoBase
{
RepoInfoBase & setAlias( ... ) { _pimpl->alias = ...; return *this; }
}
class RepoInfo : public RepoInfoBase
{
RepoInfo & setAlias( ... )
{ RepoInfoBase::setAlias(...); return *this; }
}
but by doing this the RepoInfo class looses some of the advantages of being derived from RepoInfoBase.
So, is it best to stick with setters returning void, or is there a better way to do this?