
 cabelo
cabeloZupt: Backup open source com criptografia pós-quântica híbrida.

O Zupt é uma ferramenta open source de backup que combina compressao de dados com criptografia autenticada e, no modo --pq, proteção pós-quântica baseada em ML-KEM-768 + X25519. No repositório oficial, o projeto é descrito como uma solução em C11 puro, sem dependências externas, voltada para criar arquivos de backup comprimidos e, quando necessário, protegidos com criptografia clássica por senha ou com encapsulamento híbrido resistente ao cenário de computação quântica.
O projeto teve início com a implementação em C desenvolvida por Cristian Cezar Moises.
Como Membro e Embaixador openSUSE e Chapter Lider OWASP SP, entrei na iniciativa para viabilizar sua compilação em conformidade com os requisitos de compliance das distribuições Linux.
Além de atuar no port para as arquiteturas x86, ppc64le, armv7l, aarch64 e s390x. Esta primeira etapa está sendo realizada no openSUSE, permitindo que o DiraQ (um Linux de bolso para Computação Quântica que desenvolvi com Wilson Fonseca ) já incorpore esse recurso, cuja demonstração acontecerá no UNISO Quantum Day dia 7 de Abril.
A ideia central do Zupt é simples: transformar backup em um único fluxo operacional. Em vez de usar uma ferramenta para compactar, outra para cifrar e outra para validar integridade, o Zupt concentra tudo em um só utilitário. O projeto destaca compressão, autenticação por bloco, execução multithread, ocultação de nomes/estrutura dos arquivos dentro do archive e um modo pós-quântico para arquivos que precisam continuar confidenciais por muitos anos.
OK, mas o que significa “pós-quântico” no Zupt
Para entender o diferencial do Zupt, é importante entender o papel do ML-KEM. O NIST define ML-KEM em seu padrão FIPS 203 como um KEM (Key-Encapsulation Mechanism), isto é, um mecanismo de encapsulamento de chave que permite a duas partes estabelecerem um segredo compartilhado por um canal público, para depois usar esse segredo em algoritmos simétricos de criptografia e autenticação. O padrão prevê três conjuntos de parâmetros: ML-KEM-512, ML-KEM-768 e ML-KEM-1024. (Fonte NIST)
No Zupt, o modo --pq usa especificamente o ML-KEM-768, que o próprio SECURITY.md classifica como um esquema de nível de segurança NIST 3, combinado com X25519 em um desenho híbrido. Em outras palavras, o archive não depende só de um algoritmo “novo” pós-quântico, nem só de um algoritmo clássico consagrado: ele deriva a chave de proteção a partir da combinação dos dois. Isso torna o modelo particularmente interessante para migração gradual, porque ele mantém a robustez clássica e adiciona uma camada pensada para a ameaça quântica.
O repositório resume esse benefício com a expressão “harvest now, decrypt later”. Esse risco descreve o cenário em que um adversário intercepta dados cifrados hoje, armazena tudo e espera o futuro, quando a computação quântica ou novos ataques possam quebrar mecanismos clássicos.
O README do Zupt diz explicitamente que o modo --pq existe para enfrentar esse problema; o SECURITY.md reforça que o modo com senha (-p) não é quântico-seguro e recomenda --pq para proteção de longo prazo.
Quando o projeto afirma que essa ideia segue a mesma linha de produtos como Signal e iMessage, a comparação faz sentido no nível conceitual: o Signal documenta seu protocolo PQXDH como uma combinação de X25519 com Kyber/ML-KEM, e a Apple também descreve sua transição para criptografia híbrida pós-quântica no iMessage/PQ3 como resposta ao risco de ataques futuros contra material coletado hoje. O ponto principal não é que Zupt replique literalmente esses protocolos de mensageria, mas que ele adota a mesma filosofia de hibridização entre o mundo clássico e o pós-quântico. (Fonte Signal)
Como o modo --pq funciona na prática
O fluxo híbrido do Zupt funciona assim: a chave pública do destinatário é usada em uma encapsulação ML-KEM-768; ao mesmo tempo, o programa faz uma troca baseada em X25519; depois, os segredos resultantes são combinados e passam por SHA3-512 para derivar duas chaves: uma de cifragem e outra de autenticação. Essas chaves então alimentam o mecanismo simétrico já usado pelo programa, baseado em AES-256-CTR para confidencialidade e HMAC-SHA256 para integridade.
A consequência prática desse desenho é importante: o projeto afirma que o archive continua protegido se pelo menos um dos dois componentes permanecer seguro. Ou seja, mesmo que no futuro surja uma quebra relevante contra X25519, o componente ML-KEM-768 ainda sustentaria a segurança; e, no cenário inverso, o componente clássico ainda adicionaria proteção enquanto permanecesse confiável. Esse é exatamente o valor de um desenho híbrido em uma fase de transição criptográfica.
O que mais o Zupt oferece além do modo pós-quântico
Embora o modo --pq seja o grande diferencial, o Zupt não é “só” um experimento de criptografia. O README destaca compressão, autenticação por bloco, paralelismo e um codec chamado VaptVupt, descrito como o codec padrão da linha 2.0, combinando LZ77 + tANS com aceleração AVX2 para descompressão (Uau).
O projeto também apresenta comparação funcional com gzip, zstd e 7-Zip, ressaltando que o ganho do Zupt não é apenas taxa de compressão, mas a soma de compressão, integridade, criptografia e independência de bibliotecas externas. Também vale uma observação editorial importante para o seu artigo: no momento da consulta, a página do repositório mostrava v1.5.5 como release mais recente publicada, mas o README do branch master já descrevia a linha 2.0-RC e seus recursos, incluindo o VaptVupt como padrão. Para um texto técnico honesto, vale explicitar que parte da documentação do projeto reflete uma transição de versões.
Instalação do Zupt a partir dos fontes no openSUSE
No fluxo de compilação a partir do GitHub, o README oficial documenta um processo direto: clonar o repositório, entrar no diretório, executar make e depois sudo make install. O Makefile confirma que o compilador padrão é gcc, que o binário gerado chama-se zupt e que a instalação, por padrão, vai para /usr/local/bin. Como o procedimento usa git clone, make e gcc, no openSUSE o caminho mais lógico é preparar o ambiente com esses pacotes antes da compilação.
Os pré-requisitos mínimos no openSUSE podem ser instalados assim:
sudo zypper install git gcc make
Em seguida, faça a compilação:
git clone https://github.com/cristiancmoises/zupt.git
cd zupt
make
sudo make install
Depois da instalação, você pode confirmar que o binário entrou corretamente no sistema com:
which zupt
zupt version
zupt help
Esse fluxo está alinhado ao README e ao Makefile do projeto, que mostram build sem dependências externas além do toolchain C padrão.
Instalação do Zupt via zypper no openSUSE

O README também documenta instalação por pacote no ecossistema openSUSE. No trecho consultado, a instrução publicada era adicionar o repositório da iniciativa e instalar o pacote com zypper. Como o texto do repositório explicitava o exemplo para openSUSE 16.0, o mais correto é reproduzir exatamente esse procedimento no artigo, sem extrapolar para versões que não estejam listadas no README consultado.
sudo zypper addrepo https://download.opensuse.org/repositories/home:cabelo:innovators/16.0/home:cabelo:innovators.repo
sudo zypper refresh
sudo zypper install zupt
Após isso, os mesmos comandos de verificação continuam válidos:
zupt version
zupt help
Esse método é o mais prático para quem quer começar rapidamente, enquanto a instalação via fonte é mais interessante para auditoria de código, testes com mudanças locais ou validação de uma branch específica.
Uso básico do Zupt
A interface principal do programa gira em torno de alguns subcomandos: compress, extract, list, test, bench, keygen, version e help. O README mostra o formato geral como zupt compress [OPTIONS] <output.zupt> <files/dirs...> e zupt extract [OPTIONS] <archive.zupt>, além de opções como nível de compressão, número de threads, senha, modo pós-quântico, saída de extração e modos de codec.
1. Criando um backup simples sem criptografia
Para apenas compactar arquivos, o uso básico documentado é:
zupt compress backup.zupt ~/Documents/
Esse comando cria um archive .zupt usando o codec padrão documentado no branch atual do projeto. É o modo indicado para dados não sensíveis ou para testes rápidos de desempenho e formato.
2. Criando um backup com senha
Se a intenção é proteger o conteúdo com senha, o README mostra:
zupt compress -p "changeme" backup.zupt ~/Documents/
Nesse caso, o SECURITY.md diz que a derivação passa por PBKDF2-SHA256 e gera chaves para AES-256-CTR + HMAC-SHA256. É uma proteção útil para uso comum, mas a própria documentação alerta que esse modo não é o indicado para proteção de longo prazo contra ameaça quântica.
3. Extraindo um backup
Para restaurar o conteúdo em um diretório específico, o fluxo documentado é:
zupt extract -o ~/restored/ backup.zupt
Se o archive tiver sido protegido com senha, a senha deve ser informada no comando; se tiver sido criado com --pq, será preciso usar a chave privada correspondente. A opção -o define o diretório de destino da restauração.
4. Criando um backup pós-quântico
O modo pós-quântico documentado no README envolve primeiro gerar um par de chaves, depois exportar a chave pública e usá-la na compressão:
zupt keygen -o mykey.key
zupt keygen --pub -o pub.key -k mykey.key
zupt compress --pq pub.key backup.zupt ~/Documents/
Para extrair depois:
zupt extract --pq mykey.key -o ~/restored/ backup.zupt
A lógica é semelhante a fluxos de criptografia de chave pública: quem cria o backup usa a chave pública para proteger o archive, e só quem possui a chave privada consegue abrir o conteúdo. Para arquivos arquivísticos, backups frios, documentos estratégicos e material com exigência de sigilo prolongado, este é o modo mais interessante do Zupt.
5. Listando, testando e ajustando o comportamento
Além de comprimir e extrair, o README informa que o Zupt também oferece:
zupt list backup.zupt
zupt test backup.zupt
list serve para inspecionar o archive, e test para validar integridade. O projeto também documenta -l <1-9> para nível de compressão, -t <N> para número de threads, -s para armazenar sem compressão, -f para codec rápido legado e --solid para modo sólido. Isso permite adaptar o comportamento entre velocidade, taxa de compressão e custo de CPU.
Cuidados e limitações que merecem atenção
Um artigo técnico sobre o Zupt fica mais forte quando menciona não apenas os recursos, mas também os limites atuais. O COMPAT.md informa, por exemplo, que links simbólicos são ignorados, arquivos especiais também podem ser ignorados, e as permissões dos arquivos ainda não são restauradas na extração; o documento também cita limites para tamanho de bloco, quantidade de arquivos e algumas restrições de modo sólido.
Além disso, o README do branch atual é explícito ao dizer que a linha 2.0-RC já está adequada para uso pessoal e testes, mas ainda não é indicada para ambientes críticos ou grandes volumes de dados. Portanto, um texto responsável deve apresentar o Zupt como uma ferramenta muito promissora, tecnicamente interessante e especialmente relevante por trazer criptografia híbrida pós-quântica ao universo de backup, mas ainda em evolução.
Conclusão
O Zupt se destaca por atacar um problema real com uma abordagem moderna: backup não é só compactar arquivos, é preservar confidencialidade, integridade e recuperabilidade por muitos anos. Ao combinar compressão, autenticação por bloco, execução paralela e um modo híbrido ML-KEM-768 + X25519, a ferramenta entra em um espaço ainda pouco explorado por utilitários de backup open source. O grande valor do projeto está justamente em aproximar a discussão de criptografia pós-quântica da operação cotidiana de backup.

 Member
MemberRecopilación del boletín de noticias de la Free Software Foundation – abril de 2026
Recopilación y traducción del boletín mensual de noticias relacionadas con el software libre publicado por la Free Software Foundation.

La Free Software Foundation (FSF) es una organización creada en Octubre de 1985 por Richard Stallman y otros entusiastas del software libre con el propósito de difundir esta filosofía, frente a las restricciones y abusos a los usuarios por parte del software privativo.
Por cierto este mes se cumplen 40 años de la creación de la FSF.
La Fundación para el software libre (FSF) se dedica a eliminar las restricciones sobre la copia, redistribución, entendimiento, y modificación de programas de computadoras. Con este objeto, promociona el desarrollo y uso del software libre en todas las áreas de la computación, pero muy particularmente, ayudando a desarrollar el sistema operativo GNU.
Mensualmente publican un boletín (supporter) con noticias relacionadas con el software libre, sus campañas, o eventos. Una forma de difundir los proyectos, para que la gente conozca los hechos, se haga su propia opinión, y tomen partido si creen que la reivindicación es justa!!
- En este enlace podéis leer el original en inglés: https://www.fsf.org/free-software-supporter/2026/april
- Y traducido en español (cuando el equipo de traducción lo tengamos disponible) en este enlace: https://www.fsf.org/free-software-supporter/2026/abril

Puedes ver todos los números publicados en este enlace: http://www.fsf.org/free-software-supporter/free-software-supporter
¿Te gustaría aportar tu ayuda en la traducción y colaborar con la FSF? Lee el siguiente enlace:
Por aquí te traigo un extracto de algunas de las noticias que ha destacado la FSF este mes de abril de 2026.
Discord no merece tu confianza incuestionable
Del 11 de marzo
Discord, una plataforma no libre de mensajería instantánea y llamadas de voz y video con más de 150 millones de usuarios activos cada mes, se ha unido a otras para anunciar una política de identificación de edad. Las políticas de verificación de edad se promocionan como necesarias para proteger a niños y adolescentes en línea, pero en realidad estas políticas obligan a los usuarios de todas las edades a interactuar con programas invasivos y no gratuitos.
Si Discord quiere nuestra confianza, necesita ganársela liberando su código y respetando a los usuarios que no quieren someterse a un proceso invasivo de verificación de edad para seguir usando Discord. Si vive en un estado o país que está considerando una ley de verificación de edad, comuníquese con sus representantes e infórmeles lo dañinas son las políticas de verificación de edad.
Google ofrece a los usuarios de Android una forma de instalar aplicaciones no verificadas si demuestran que de verdad, verdad quieren hacerlo.
Del 19 de marzo por Thomas Claburn
La presión pública venció a los esfuerzos de Google para obligar a los usuarios de Android a instalar aplicaciones verificadas por Google a través de Google Play (más o menos). Según una publicación reciente en el blog de Google, los usuarios de Android seguirán pudiendo instalar aplicaciones de desarrolladores no verificados a través de un proceso único después de septiembre, que implica fricciones significativas (habilitar el modo de desarrollador, reiniciar el dispositivo, reautenticarse y luego esperar veinticuatro horas).
Esta «opción» puede permitir a los usuarios de Android descargar una amplia variedad de aplicaciones, pero no les permite tener control total sobre su dispositivo. Si es usuario de Android, consulte las opciones que tiene para usarlo libremente con aplicaciones en F-Droid o considere utilizar Replicant, una distribución de Android totalmente libre.
- https://www.theregister.com/2026/03/19/google_android_unverified_apps/
- https://replicant.us/
- https://f-droid.org/
450 socios de la FSFE afectados: el proveedor de pagos Nexi cancela el contrato con la FSFE
Del 16 de marzo por la FSFE
Nexi, el proveedor de pagos a largo plazo de la FSFE, rescindió su contrato sin previo aviso, deteniendo en consecuencia las donaciones recurrentes con tarjetas de crédito y débitos directos de los partidarios del software libre.
Nexi exigió datos confidenciales y privados de los partidarios de la FSFE para un vago análisis de riesgos. La FSFE se negó a entregar estos datos sin una explicación más satisfactoria de por qué Nexi quería esta información, y Nexi parece haber decidido castigar a la FSFE por esta elección.
La FSFE no hizo nada malo al simplemente solicitar más información a Nexi antes de confiar fielmente al proveedor de pagos los datos de sus donantes altruistas: estaba protegiendo la confianza y la seguridad de los miembros de la comunidad del software libre. Puede leer más sobre la información que la FSFE ya le había proporcionado a Nexi en la publicación del blog a continuación.

Estas son solo algunas de las noticias recogidas este mes, ¡¡pero hay muchas más muy interesantes!! si quieres leerlas todas (cuando estén traducidas) visita este enlace:
Y todos los números del «supporter» o boletín de noticias de 2026 en español, francés, portugués e inglés aquí:


Tumbleweed Monthly Update - March 2026
There were several software package updates for openSUSE Tumbleweed during March.
Tumbleweed saw three Plasma 6.6 updates bringing progressive bugfixes to KWin, the system tray, Spectacle, and the Kicker launcher. KDE Frameworks advanced to 6.24.0 with nanosecond-precision timestamps in KIO and a new Kirigami StyleHints API. The Linux kernel moved from 6.19.5 to 6.19.9 with broad fixes across audio, display, and filesystem drivers. Both the Linux Kernel and FreeRDP fixed several Common Vulnerabilities and Exposures, and Mesa 26.0.2 resolved visual corruption on RDNA 4 hardware and a Counter-Strike 2 regression on Intel Arc.
As always, be sure to roll back using snapper if any issues arise.
For more details on the change logs for the month, visit the openSUSE Factory mailing list.
New Features and Enhancements
Plasma 6.6.1, 6.6.2 & Plasma 6.6.3: Version 6.6.3 finished the month with the third update. Application launcher Kicker receives several fixes for the sidebar, icon display, and expanded root list width calculations. The Task Manager now keeps thumbnails properly aligned in horizontal group tooltips. Spectacle resolves a crash on quick region selection and fixes a pixel-off error in the magnifier tool. The system tray sees improved popup placement on Wayland. PowerDevil restores the battery badge for 100 percent charge and syncs the manual inhibition switch with external changes. Plasma 6.6.2 has KWin resolve crashes in DRM output handling, improves mouse tracking with caret-based zoom, and fixes input region gaps in window decorations. The Kicker applet sees refinements in visual search, scrollbar behavior, and hover logic. Spectacle fixes a crash when exporting via KDE Connect, and System Settings now correctly navigates to subcategories from search results. In version 6.6.1, KWin sees the most changes with fixes for corner rounding applying to both decorations and window surfaces, zoom now works correctly on rotated outputs, and software brightness dimming on external screens on screens were enhanced. The tile editor no longer triggers on key repeat, and interactive move-resize no longer unconditionally raises windows. Clipboard and drag-and-drop teardown under XWayland is improved, and*Wine/Proton color management gains better compatibility. The Kicker application launcher for the Plasma Desktop receives multiple fixes for the icon display, layout margins, and search field behavior. The Task Manager corrects tooltip sizing. The digital clock now properly localizes digits, and the media controller fixes premature label truncation. Plasma Network Manager improves icon accuracy for Wi-Fi disabled states and now responds to external configuration changes. Discover improves Flatpak app resolution and exposes proper star count ratings. Powerdevil adds a power level check before executing critical actions that prevent premature shutdowns.
GNOME Control Center 49.5: The Display and Power panels now handle a missing UPower service instead of failing. An infinite loop when switching battery charge modes on systems with multiple batteries was fixed. Sound and Bluetooth device switching regressions are resolved through an updated libgnome-volume-control.
libxml2 2.15.2: A significant version jump that removes the built-in HTTP client and LZMA compression support, and the parser option XML_PARSE_UNZIP is now required to read compressed data. HTML serialization and character encoding handling are brought more in line with the HTML5 specification, and additional accessors for xmlParserCtxt were added for developers. Several previously patched CVEs are now resolved upstream, including fixes for attribute normalization and standalone checks. Python bindings are no longer built as they are scheduled for removal in 2.16, and Schematron support has similarly been dropped.
Xfce 4.20.2: This update covers the screensaver, session manager, and display settings. xfce4-screensaver fixes a wrong conditional in the lock plug, improves theme preview rendering, and switches from pidof to pgrep for more reliable process detection. The overlay window handling is reworked to use a single permanent window, improving device reliability. xfce4-session fixes an idle function and prevents multiple logout dialogs from being created. It also adds gnome-keyring as a Secret portal provider and improves keyboard layout detection on Wayland. xfce4-settings improves display management by checking EDID to detect output list changes, adds a missing condition for new Wayland outputs, and falls back to output name when EDID data is duplicated.
KDE Frameworks 6.24.0: This updates see KIO gain nanosecond-precision timestamps across file operations, improved paste dialogs with proper titles, and refined trash handling. KCodecs overhauls encoding with safer memory management (using unique_ptr) and Kirigami introduces a new StyleHints API to unify theme behavior. Baloo fixes database access mode issues and KTextEditor adds search history clearing and safer clipboard handling.
7-Zip 26.00: The file manager now uses the file name as a secondary sorting key for more intuitive file list ordering, and the benchmark tool supports systems with more than 64 CPU threads. A bug preventing correct extraction of TAR archives containing sparse files is fixed.
KDE Gear 25.12.3: Kdenlive addresses numerous stability and usability issues, including crashes in the curve editor, audio scrubbing with “Pause on Seek” disabled, and provides better handling of multi-stream clips and improved effect management. Itinerary and Kitinerary expand travel support with new extractors for ferry tickets. NeoChat refines room list navigation, fixes emoticon editor layout issues, prevents timeline scrolling during reactions, and resolves a crash. KMail restores proper rendering of plain-text emails and Tokodon fixes alt-text editing and account switching after login failures.
ImageMagick 7.1.2.16 - 7.1.2.18: The image editor update for version 7.1.2.18 improves the reliability of animated image handling by fixing frame delay parsing and resolves a visual artifact where the -dissolve composite operation introduced random noise. Version 7.1.2.17 focused on addressing multiple vulnerabilities and security advisories are resolved along with out-of-band data handling improvements. Version 7.1.2.16 hardens security and adds overflow checks to several image write paths including JXL, PS3, sixel, SGI, and BMP/DIB. It fixes a heap over-read in BilateralBlurImage with even-dimension kernels, a NULL pointer dereference in HEIC NCLX color profile allocation, and a double-free in SVG gradientTransform parsing.
Ruby 4.0.2: This update fixes a YJIT bug. A segfault with argument forwarding combined with splat and positional arguments is resolved, along with a GC crash in String#% and a crash on signal raise. A 20 percent performance regression in Rails related to global allocatable slots and empty pages is addressed. Several Prism parser issues were corrected including misparsing of standalone in pattern matching and the and? predicate being confused with the and keyword.
FreeRDP 3.24.1: This update sees the API comprehensively marked with [[nodiscard]] to surface unchecked function return values. Smartcard support is improved including ECC key handling in PKCS#11 enumeration, proxy support is extended to RFX and NSC graphics modes, and SDL3 multi-monitor scaling is introduced. Numerous memory leaks across connection setup, settings copying, and smartcard paths were resolved.
libavif 1.4.0: This update adds support for Sample Transform schemes from the AVIF 1.2 specification, which enables 16-bit AVIF file handling and grid-based derived image items. Data behind a document for the software handles picture files was made with avifenc, which can now read PNG or JPEG files through stdin via --stdin-format and supports converting JPEG files with Apple-style gain maps. PNG decoding now respects cICP chunks for color information as per the PNG Third Edition specification. Encoding defaults have been refined; AOM_TUNE_IQ is now used for still color samples with libaom v3.13.0+, while AOM_TUNE_PSNR is used for alpha to avoid ringing artifacts from SSIM tuning. Support for libaom versions 2.0.0 and earlier is removed.
Key Package Updates
Linux kernel 6.19.5 - 6.19.9:: The 6.19.9 update improved audio with a speaker pop fix for Star Labs StarFighter hardware and the Btrfs filesystem resolves a space info lock issue during periodic reclaim. NFS3 now correctly returns EISDIR when a create operation encounters a directory alias. The 6.19.8 kernel was dominated by a major batch of AppArmor fixes and multiple CVE-tracked fixes that were backported. The 6.19.7 release receives multiple corrections for CFS/EEVDF scheduler including fixes for zero_vruntime tracking, lag clamping, and slice protection timing. The AMD XDNA accelerator driver resolves several issues including a crash when destroying suspended hardware contexts. The 6.19.6 kernel had fixes led by extensive perf tooling corrections including reference count leaks, srcline printing with inlines, and Zen 5 vendor event definitions for AMD. Btrfs replaces a BUG() call with proper error handling for unexpected delayed ref types, adds fallback to buffered IO for data profiles with duplication, and improves user interrupt handling in btrfs_trim_fs(). The 6.19.5 releases sees Btrfs correct a block_group_tree dirty list corruption and a chunk allocation abort caused by non-consecutive gaps. GFS2 resolves quota handling and an inline data write path. The SMB client fixes a potential use-after-free and double free in smb2_open_file(). A netfilter nf_tables fix adds an abort skip removal flag for set types to address tracked security-relevant issues.
GStreamer 1.28.1: This update includes a new whisper-based speech-to-text transcription element and the speechmatics element now supports detecting audio events like applause, laughter, and music. Reverse playback and gap handling are improved across multiple components. The V4L2 subsystem gains support for AV1 stateful decoding, and CUDA/GL interop copy paths in cudaupload and cudadownload are fixed. WebRTC components gain the ability to specify custom headers for signalling servers and negotiate H.264 profile and level for encoded input. Various memory leaks, build issues, and race conditions were resolved.
curl 8.19.0: This release addresses four security vulnerabilities and provides new features like initial support for MQTTS and fractional values for --limit-rate and --max-filesize. Support for OpenSSL-QUIC was dropped. A potential NULL dereference in Curl_h1_req_parse_read() was fixed along with a potential out-of-bounds read in OpenSSL debug logging. The build now enables NTLM authentication for compatibility with certain Exchange Server endpoints.
systemd 259.3 & 259.5: The 259.5 update had a notable fix and corrected systemd-update-helper from incorrectly skipping systemctl disable during package removal. A new clean-state command is introduced and triggered automatically at the end of any transaction installing unit files. The systemd-container subpackage now requires libarchive instead of tar for archive handling. Additional systemd-update-helper fixes address do_install_units() incorrectly returning an error when no units need preset, and the clean-state command itself is corrected to remove the full state directory rather than just a subdirectory. The 259.3 was a major version upgrade. The libcap dependency was removed entirely, with its system call wrappers reimplemented directly in systemd.
GnuPG 2.5.18: This update adds support for deleting composite secret keys in gpg-agent and fixes armor parsing when no CRC is found. A recent regression in pkdecrypt with TPM RSA keys is resolved, and scdaemon adds support for D-Trust Card 6.1/6.4. The dirmngr key server search now prints all UID records for a key, which fixes a regression dating back to 2015.
Mesa 26.0.2: The release fixes visual corruption on RDNA 4 in DX11/DXVK titles like Mafia III, a GPU hang with PS epilogs and secondary command buffers, and missing L2 cache invalidation with streamout on GFX12. A Counter-Strike 2 visual glitch regression on Intel A770 is resolved. The Panfrost Bifrost compiler fixes a failure from incorrect vectorization and spill placement issues. An OpenGL VRAM memory leak when setting uniform variables is corrected. X11 shared memory attachment checks are added across drisw, EGL, GLX, and Vulkan WSI paths to prevent allocation failures.
GTK3 3.24.52: This update fixes a Firefox crash at gdk_wayland_drag_context_manage_dnd() when a toplevel Wayland surface is missing, and resolves wild strobing in multi-window mode. A refresh rate calculation overflow on 32-bit targets is corrected, and recolored icon images are no longer constantly reloaded. Accessibility events for unfocused GtkTreeView widgets are fixed, and XKB initialization failures on Wayland are now handled more gracefully.
libtpms 0.10.2: This update fixes a memory leak by freeing the KDF context and resolves incorrect IV retrieval when using OpenSSL 3.0 or later. A build fix for compatibility with newer glibc is also included. For Tumbleweed users running TPM-based virtualization with QEMU or swtpm, this is a security-relevant update.
xfsprogs 6.18.0: This update spans three releases. The mkfs.xfs tool gains several improvements including the ability to configure desired maximum atomic write sizes, AG size alignment based on atomic write capabilities, autodetection of log stripe unit for external log devices, and new default features enabled out of the box with a 2025 LTS config file. Zoned filesystem support is refined with fixes for zone capacity checks on sequential zones and improved default maximum open zones. The proto subsystem adds the ability to populate a filesystem directly from a directory. xfs_scrub removes its EXPERIMENTAL warnings and fixes a null pointer crash in scrub_render_ino_descr. Cross-architecture log CRC mismatches between i386 and other architectures are corrected, and libxfs gains support for reproducible filesystems using deterministic time and seed values. Deprecated sysctl knobs and mount options are removed. The Python dependency is also dropped from the main package since the xfs_protofile script is not essential.
Security Updates
Python 3.11.15:
-
CVE-2025-11468: Fixes a header injection flaw in email header folding where long comments with unfoldable characters could allow injecting headers into email messages.
-
CVE-2025-12084: Addresses quadratic complexity that could lead to denial of service when processing deeply nested documents.
-
CVE-2025-6075: Resolves a performance degradation in
os.path.expandvars()when user-controlled values are passed for environment variable expansion. -
CVE-2026-2297: Fixes an issue where CPython’s import hook for legacy .pyc files did not trigger sys.audit handlers and could potentially allow a security monitoring bypass.
bind 9.20.21:
-
CVE-2026-1519: Fixes a flaw that could potentially lead to denial of service.
-
CVE-2026-3104: Addresses a memory leak that could cause unbounded memory growth and an out-of-memory condition.
-
CVE-2026-3119: Resolves an issue where an authenticated query could cause a termination unexpectedly.
-
CVE-2026-3591: Fixes a use-after-return flaw that could allow an attacker to bypass ACL restrictions via crafted DNS requests.
Linux kernel 6.19.8::
-
CVE-2026-23230: Fixes a vulnerability in the ksmbd kernel SMB server.
-
CVE-2026-23220: Addresses an infinite loop caused by next_smb2_rc in ksmbd.
-
CVE-2026-23226: Resolves a missing lock to protect ksmbd channel list.
-
CVE-2026-23228: Fixes a leak of active_num_conn in the ksmbd SMB server.
-
CVE-2025-71231: Addresses an out-of-bounds index in the crypto IAA driver.
-
CVE-2026-23222: Fixes a memory allocation issue in the crypto OMAP driver.
-
CVE-2026-23229: Resolves a missing spinlock protection in the crypto virtio driver.
-
CVE-2025-71237: Fixes a potential block overflow in nilfs2 that could cause corruption.
-
CVE-2025-71230: Addresses an issue where HFS superblock info was not always cleaned up properly.
-
CVE-2025-71229: Resolves an alignment fault in the rtw88 WiFi driver.
-
CVE-2025-71236: Fixes missing validation before freeing resources in the qla2xxx SCSI driver.
-
CVE-2025-71235: Addresses a module unload race condition in the qla2xxx SCSI driver.
-
CVE-2025-71232: Resolves a memory leak in an error path in the qla2xxx SCSI driver.
-
CVE-2026-23225: Fixes an incorrect CID ownership assumption in the scheduler mmcid subsystem.
-
CVE-2026-23221: Addresses a use-after-free in the fsl-mc bus driver override handling.
-
CVE-2026-23224: Resolves a use-after-free in erofs for file-backed mounts.
-
CVE-2026-23223: Fixes a use-after-free in XFS btree block owner checking.
-
CVE-2026-23227: Addresses a missing lock protection in the Exynos VIDI DRM driver.
-
CVE-2025-71233: Resolves an issue with asynchronous sub-group creation in PCI endpoint.
-
CVE-2025-71234: Fixes a slab out-of-bounds access in the rtl8xxxu WiFi driver.
-
CVE-2025-71238: Addresses a double-free in the qla2xxx SCSI driver’s bsg_done handler.
-
CVE-2026-23236: Fixes improper ioctl memory copy in the smscufx framebuffer driver.
-
CVE-2026-23235: Resolves an out-of-bounds access in f2fs sysfs attribute handling.
-
CVE-2026-23234: Addresses a use-after-free in f2fs write end I/O handling.
libtpms 0.10.2:
- CVE-2026-21444: Fixes a flaw in libtpms that weakened encryption and decryption.
LibVNCServer:
-
CVE-2026-32853: Fixes a vulnerability where a crafted message could lead to information disclosure or denial of service.
-
CVE-2026-32854: Addresses an issue where crafted requests could cause a denial of service.
freeipmi 1.6.17:
- CVE-2026-33554: Resolves improper memory handling and data validation that could lead to stack buffer overflows and acceptance of malformed payloads.
nghttp2 1.68.1:
- CVE-2026-27135: Addresses a vulnerability that fixes an assertion failure from missing state validation.
inkscape 7.1.2.15:
-
CVE-2026-24481: Fixes a heap information disclosure when processing malformed PSD files.
-
CVE-2026-25794: Addresses a heap buffer overflow via integer overflow when writing images with large dimensions.
-
CVE-2026-25796: Resolves a memory leak that could be exploited for denial of service.
-
CVE-2026-25637: Fixes a memory leak in the ASHLAR image writer that could lead to denial of service.
-
CVE-2026-25576: Addresses a heap buffer over-read in multiple raw image format handlers potentially disclosing sensitive information.
-
CVE-2026-26983: Fixes a NULL pointer dereference in the MSL interpreter that could cause a crash.
-
CVE-2026-26284: Resolves a use-after-free that could lead to denial of service or code execution.
-
CVE-2026-26283: Addresses an infinite loop in the JPEG encoder that could cause denial of service.
-
CVE-2026-25965: Fixes a path traversal that could allow reading arbitrary files on the system.
-
CVE-2026-25967: Addresses improper encoding or escaping of output that could allow arbitrary command execution.
-
CVE-2026-25989: Fixes an integer overflow in the internal SVG decoder that could cause denial of service.
-
CVE-2026-25968: Resolves a memory leak in coders that write raw pixel data potentially leading to denial of service.
-
CVE-2026-24485: Addresses an out-of-bounds read that could cause a crash.
-
CVE-2026-25985: Fixes unbounded resource allocation in the SVG decoder that could lead to denial of service.
-
CVE-2026-25987: Resolves an integer overflow in the SVG decoder potentially causing denial of service.
-
CVE-2026-25966: Addresses a security policy bypass via fd: pseudo-filenames allowing stdin/stdout access.
-
CVE-2026-25799: Fixes an out-of-bounds read that could disclose memory contents.
-
CVE-2026-25798: Resolves an out-of-bounds read potentially leading to information disclosure or a crash.
-
CVE-2026-25795: Fixes a NULL pointer dereference that could cause a denial of service.
-
CVE-2026-26066: Addresses resource exhaustion when writing IPTCTEXT that could lead to denial of service.
-
CVE-2026-25638: Resolves a memory leak that could be exploited for denial of service.
-
CVE-2026-25797: Fixes a code injection issue that could allow arbitrary code execution.
-
CVE-2026-25897: Addresses a heap buffer overflow in the sun decoder potentially causing a crash.
-
CVE-2026-25970: Resolves a memory leak that could lead to denial of service via image processing.
-
CVE-2026-25982: Fixes a use-after-free that could lead to denial of service or code execution.
-
CVE-2026-25983: Addresses an out-of-bounds read in the PCD coder that could disclose memory contents.
-
CVE-2026-25898: Resolves an out-of-bounds read that could cause a crash or information disclosure.
-
CVE-2026-25971: Fixes a memory leak in the text coder that could lead to denial of service.
-
CVE-2026-25988: Addresses a use-after-free in the meta coder potentially allowing code execution.
-
CVE-2026-25969: Resolves a memory leak that could lead to denial of service via image processing.
-
CVE-2026-25986: Fixes a vulnerability that could lead to denial of service when processing crafted images.
expat 2.7.5:
-
CVE-2026-32776: Fixes a NULL pointer when handling empty external parameter entity content.
-
CVE-2026-32777: Addresses an infinite loop that could lead to denial of service.
-
CVE-2026-32778: Resolves a NULL pointer after an earlier out-of-memory condition.
TigerVNC:
- CVE-2026-34352: Fixes incorrect permissions that could allow other users to observe or manipulate screen contents, or cause a crash.
clamav 1.5.2:
- CVE-2026-20031: Fixes an error handling bug that could crash the program and cause a denial of service.
FreeRDP 3.24.1:
-
CVE-2026-29774: Fixes a client-side heap buffer overflow.
-
CVE-2026-29775: Addresses an off-by-one boundary check in the bitmap cache subsystem that could cause out-of-bounds read/write.
-
CVE-2026-29776: Resolves an integer underflow that could lead to a crash.
-
CVE-2026-31806: Fixes a heap buffer overflow caused by unchecked bitmap dimensions from a malicious server.
-
CVE-2026-31883: Addresses a size_t underflow leading to a heap buffer overflow via the RDPSND channel.
-
CVE-2026-31884: Resolves a division-by-zero in the ADPCM decoders when nBlockAlign is 0, causing a crash.
-
CVE-2026-31885: Fixes an out-of-bounds read in the ADPCM decoders due to missing predictor and step_index bounds checks.
giflib:
- CVE-2026-23868: Fixes a double-free vulnerability from a shallow copy that could lead to memory corruption.
curl 8.19.0:
-
CVE-2026-1965: Fixes bad reuse of HTTP Negotiate connections that could lead to authentication bypass with wrong credentials.
-
CVE-2026-3783: Addresses a token leak when following redirects with netrc credentials.
-
CVE-2026-3784: Resolves wrong proxy connection reuse with different credentials, potentially exposing authenticated sessions.
-
CVE-2026-3805: Fixes a use-after-free in SMB connection reuse that could lead to a crash or potential code execution.
QEMU 10.2.2:
-
CVE-2026-2243: Fixes an out-of-bounds read in QEMU’s VMDK image handling that could lead to information disclosure or denial of service.
-
CVE-2026-3196: Addresses an integer overflow that could allow a malicious guest to cause unbounded memory allocation and denial of service on the host.
udisks2:
-
CVE-2026-26104: Fixes a missing authorization check that allowed unprivileged users to back up LUKS encryption headers and potentially expose sensitive cryptographic metadata.
-
CVE-2026-26103: Addresses a missing authorization check that allowed unprivileged users to restore LUKS encryption headers, which could potentially render encrypted volumes inaccessible.
GVFS 1.58.2:
- CVE-2026-28296: Fixes a CRLF injection flaw in the FTP backend that could allow a remote attacker to inject arbitrary FTP commands via crafted file paths.
python-tornado6
- CVE-2026-31958: Fixes a denial-of-service vulnerability where requests with thousands of parts could cause excessive CPU consumption.
libjxl 0.11.2:
- CVE-2026-1837: Fixes a memory corruption issue when processing crafted grayscale images with LCMS2 that could potentially lead to code execution or information disclosure.
util-linux:
- CVE-2026-3184: Addresses improper hostname canonicalization that could allow bypass of host-based PAM access control rules.
sdbootutil:
- CVE-2026-25701: Fixes an insecure temporary file vulnerability that could allow local users to access private information or manipulate boot configuration data.
ImageMagick 7.1.2.17:
- CVE-2026-32259: Fixes a stack-based buffer overflow when a memory allocation fails that could potentially allow writes past the end of a buffer.
GraphicsMagick:
-
CVE-2026-25799: Provides a fix that could lead to a crash and denial of service.
-
CVE-2026-28690: Fixes a stack buffer overflow vulnerability that could lead to a crash or potential code execution.
-
CVE-2026-30883: Addresses a heap overflow when encoding a PNG image with an extremely large image profile.
libsoup2:
-
CVE-2026-1760: Fixes improper handling of HTTP requests combining certain headers that could lead to HTTP request smuggling and potential denial of service.
-
CVE-2026-1467: Addresses a lack of input sanitization that could lead to unintended or unauthorized HTTP requests.
-
CVE-2026-1539: Resolves proxy authentication credentials being leaked via the Proxy-Authorization header when handling HTTP redirects.
-
CVE-2026-0716: Fixes a flaw in WebSocket frame processing that could cause out-of-bounds memory reads, potentially leading to memory exposure or a crash.
freetype2 2.14.2:
- CVE-2026-23865: Fixes an integer overflow in the FreeType library that could allow an out-of-bounds read when parsing OpenType variable fonts.
exiv2 0.28.8:
-
CVE-2026-25884: Fixes an out-of-bounds read in the CRW image parser when processing crafted image files.
-
CVE-2026-27631: Addresses an integer overflow causing an uncaught exception that could lead to a crash and denial of service.
-
CVE-2026-27596: Resolves an out-of-bounds read in preview handling that could cause a crash when processing crafted image files.
-
CVE-2025-54080: Fixes an out-of-bounds read triggered when writing metadata into a crafted image file, potentially causing a crash.
-
CVE-2025-55304: Addresses quadratic performance in ICC profile parsing that could lead to denial of service.
-
CVE-2025-26623: Resolves a heap buffer overflow when writing metadata into a crafted image file, potentially allowing code execution.
Salt:
- CVE-2026-31958: Fixes a denial-of-service vulnerability where requests could cause excessive CPU consumption.
openexr 3.4.6:
- CVE-2026-27622: Fixes an out-of-bounds write that could potentially lead to code execution when processing crafted EXR files.
Users are advised to update to the latest versions to mitigate these vulnerabilities.
Conclusion
March 2026 was a month defined by refinement and security hardening across the openSUSE Tumbleweed stack. The three Plasma 6.6 point releases demonstrated KDE’s steady cadence of desktop polish, while the kernel’s progression from 6.19.5 to 6.19.9 kept hardware support and filesystem reliability moving forward. Security was a clear theme throughout the month, with FreeRDP, curl, libsoup2, and the kernel itself all receiving significant CVE attention alongside a broad sweep of image processing fixes across GraphicsMagick, ImageMagick, and exiv2. Under the hood, the jump to libxml2 2.15.2 marked a meaningful step forward in web standards alignment, and GStreamer 1.28.1 pushed multimedia capabilities forward with speech-to-text transcription and AV1 decoding support.
Slowroll Arrivals
Please note that these updates also apply to Slowroll and arrive between an average of 5 to 10 days after being released in Tumbleweed snapshot. This monthly approach has been consistent for many months, ensuring stability and timely enhancements for users. Updated packages for Slowroll are regularly published in emails on openSUSE Factory mailing list.
Contributing to openSUSE Tumbleweed
Stay updated with the latest snapshots by subscribing to the openSUSE Factory mailing list. For those Tumbleweed users who want to contribute or want to engage with detailed technological discussions, subscribe to the openSUSE Factory mailing list . The openSUSE team encourages users to continue participating through bug reports, feature suggestions and discussions.
Your contributions and feedback make openSUSE Tumbleweed better with every update. Whether reporting bugs, suggesting features, or participating in community discussions, your involvement is highly valued.
Visor meteorológico Aero Weather – Plasmoides para Plasma 6 (26)
Tras un parón debido al salto de Qt5/KF5 a Qt6/KF6 que realizó la Comunidad KDE hace ya más de año y medio. Es por ello que decidí retomar esta sección aunque renombrándola ya que en ella solo hablaría de Plasmoides para Plasma 6. Así que hoy os presento el visor meteorológico Aero Weather con el que llegamos al número 26 de la serie.
Visor meteorológico Aero Weather – Plasmoides para Plasma 6 (26)
Como he comentado en otras ocasiones, de plasmoides tenemos de todo tipo funcionales, de configuración, de comportamiento, de decoración o, como no podía ser de otra forma, de información sobre nuestro sistema como puede ser el uso de disco duro, o de memoria RAM, la temperatura o la carga de uso de nuestras CPUs.
Así que espero que le deis la bienvenida a Aero Weathe, un visor meteorológico para KDE Plasma, creado por XcurcX que viene a complementar el abanico de estos widgets para nuestro entorno de trabajo favorito que nos ofrece estas características:
- Tarjeta de clima directa en el escritorio
- Widget de panel compacto
- Condiciones actuales y pronóstico multi-día
- Estados de carga, sin conexión y error con mensajes de reintento
- Opción de color de fuente personalizada
- Ubicación automática por IP o coordenadas manuales
- Soporte para Celsius y Fahrenheit
Este plasmoide es una modificación de Chaac Minimal Weather de zayronxio (creador muy conocido del blog), distribuido bajo GPL-3.0+ con atribución.

Y como siempre digo, si os gusta el plasmoide podéis «pagarlo» de muchas formas en la página de KDE Store, que estoy seguro que el desarrollador lo agradecerá: puntúale positivamente, hazle un comentario en la página o realiza una donación. Ayudar al desarrollo del Software Libre también se hace simplemente dando las gracias, ayuda mucho más de lo que os podéis imaginar, recordad la campaña I love Free Software Day de la Free Software Foundation donde se nos recordaba esta forma tan sencilla de colaborar con el gran proyecto del Software Libre y que en el blog dedicamos un artículo.
Más información: KDE Store
¿Qué son los plasmoides?
Para los no iniciados en el blog, quizás la palabra plasmoide le suene un poco rara pero no es mas que el nombre que reciben los widgets para el escritorio Plasma de KDE.
En otras palabras, los plasmoides no son más que pequeñas aplicaciones que puestas sobre el escritorio o sobre una de las barras de tareas del mismo aumentan las funcionalidades del mismo o simplemente lo decoran.
Aquí bajo os muestro los últimos publicados en el blog:
-
Visor meteorológico Aero Weather – Plasmoides para Plasma 6 (26)
 Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2)
Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2) -
Lanzador estilo MacOS para KDE Plasma: Tahoe Launcher – Plasmoides para Plasma 6 (25)
 Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2)
Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2) -
Mejoras en el nuevo Bouncy Ball de Plasma 6
 Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2)
Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2) -
El rebote infinito de Bouncy Ball aterriza en Plasma 6 – Plasmoides para Plasma 6 (24)
 Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2)
Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2) -
Ejecuta una orden desde tu escritorio, Run Command – Plasmoides de KDE (248)
 Sigo con estas pequeñas aplicaciones que se conocen como applets,… Lee más: Ejecuta una orden desde tu escritorio, Run Command – Plasmoides de KDE (248)
Sigo con estas pequeñas aplicaciones que se conocen como applets,… Lee más: Ejecuta una orden desde tu escritorio, Run Command – Plasmoides de KDE (248) -
Visor meteorológico para tu escritorio Nori- Plasmoides para Plasma 6 (23)
 Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2)
Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2)






La entrada Visor meteorológico Aero Weather – Plasmoides para Plasma 6 (26) se publicó primero en KDE Blog.
Lanzador estilo MacOS para KDE Plasma: Tahoe Launcher – Plasmoides para Plasma 6 (25)
Tras un parón debido al salto de Qt5/KF5 a Qt6/KF6 que realizó la Comunidad KDE hace ya más de año y medio. Es por ello que decidí retomar esta sección aunque renombrándola ya que en ella solo hablaría de Plasmoides para Plasma 6. Así que hoy os presento Tahoe Launcher, un lanzador estilo MacOS para KDE Plasma, con el que llegamos al número 25 de la serie.
Lanzador estilo MacOS para KDE Plasma: Tahoe Launcher – Plasmoides para Plasma 6 (25)
Como he comentado en otras ocasiones, de plasmoides tenemos de todo tipo funcionales, de configuración, de comportamiento, de decoración o, como no podía ser de otra forma, de información sobre nuestro sistema como puede ser el uso de disco duro, o de memoria RAM, la temperatura o la carga de uso de nuestras CPUs.
Así que espero que le deis la bienvenida a Tahoe Launcher, un lanzador estilo MacOS para KDE Plasma, porque si una cosa caracteriza al entorno de trabajo de la Comunidad KDE es su posibilidad de personlización, y si alguien quiere un lanzador similar al escritorio de la manzana, ¿por qué no tenerlo?

Tahoe Launcher nos presenta una interfaz minimalista basada en una cuadrícula de iconos con efectos de transparencia y desenfoque (blur). Destaca por su alta capacidad de personalización, permitiendo ajustar la rejilla de aplicaciones (filas y columnas), el tamaño de los iconos y el diseño del buscador integrado, todo ello bajo un consumo mínimo de recursos gracias a su desarrollo nativo en QML.

Y como siempre digo, si os gusta el plasmoide podéis «pagarlo» de muchas formas en la página de KDE Store, que estoy seguro que el desarrollador lo agradecerá: puntúale positivamente, hazle un comentario en la página o realiza una donación. Ayudar al desarrollo del Software Libre también se hace simplemente dando las gracias, ayuda mucho más de lo que os podéis imaginar, recordad la campaña I love Free Software Day de la Free Software Foundation donde se nos recordaba esta forma tan sencilla de colaborar con el gran proyecto del Software Libre y que en el blog dedicamos un artículo.
Más información: KDE Store
¿Qué son los plasmoides?
Para los no iniciados en el blog, quizás la palabra plasmoide le suene un poco rara pero no es mas que el nombre que reciben los widgets para el escritorio Plasma de KDE.
En otras palabras, los plasmoides no son más que pequeñas aplicaciones que puestas sobre el escritorio o sobre una de las barras de tareas del mismo aumentan las funcionalidades del mismo o simplemente lo decoran.
Aqueí bajo os muestro los últimos publicados en el blog.

Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2)

Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2)

Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2)

Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2)

Sigo con estas pequeñas aplicaciones que se conocen como applets, widgets o plasmoides… para Plasma 5 (que a partir de ahora lo tengo que especificar),…

Calendario original para tu escritorio, Almanac Asimetric – Plasmoides para Plasma 6 (2)
La entrada Lanzador estilo MacOS para KDE Plasma: Tahoe Launcher – Plasmoides para Plasma 6 (25) se publicó primero en KDE Blog.

Quick Update on the Package Version Tracking Feature in OBS
Closing Out a Roughly 8-Year Era
The series for openSUSE Leap 15 is coming to an end after nearly eight years of providing a consistent community distribution that’s upgradable to SUSE’s enterprise product. Leap 15.6 will reach End of Life (EOL) at the close of this month closing out an end of an era as it will no longer receive maintenance or security updates going forward.
The Leap 15 journey began it journey on May 25, 2018, when 15.0 was released as a fresh community build on top of SUSE Linux Enterprise 15. It brought a huge variety of new software along with a easy migration to SLE, transactional updates, server roles, scalable cloud images, and more.
What followed was an impressively long run of incremental releases from Leap 15.1 to 15.6 as each stable release aligned with its twin, which is source and binary compatible, and delivered maintenance and security updates to users over several years.
The series far exceeded promises and ultimately spanned nearly eight years of active support. With Leap 15.6 going EOL, users who wish to continue receiving maintenance and security updates should upgrade to Leap 16. Leap 16 is expected to go to 16.6 in Fall 2031 and will have 24 months of support for a point release.
Running an unsupported release means your system will no longer receive patches for vulnerabilities, which poses a real security risk over time. The upgrade path to Leap 16 is the recommended way to stay protected and supported.
You can download openSUSE Leap 16 and use the migration tool to upgrade.
Leap 15.6 itself received nearly 24 months of support, which extended the traditional support period of 18 months by about six months. With Leap 16, users can expect a full 24 months of community support per point release, which is a commitment that reflects the significant effort from maintainers to keep users protected.
Thank you to all the contributors, packagers, and users who made the Leap 15 series such a long-lasting and reliable platform. Here’s to the next chapter with Leap 16!
My new toy: April 1 syslog-ng performance tests
Almost 15 years ago, Balabit had a campaign, stating that syslog-ng could process 650k messages a second. Now I am happy to present 7 million EPS (events per second). Timing the announcement to April 1 is not a coincidence :-)
While the 650k EPS measurement was true, it was misleading. This value was measured right after syslog-ng 3.2 introduced multi-threading, in lab environment, under optimal circumstances, using synthetic log messages. However, there was no fine print explaining this, just the statement that syslog-ng could process 650k EPS. It was fixed after a while, but it took years to recover from the effects of this marketing campaign, and engineers ten years later still had a nervous breakdown when someone mentioned “650k”. Why? Because from that moment, everyone expected syslog-ng to collect logs at that message rate in a production environment with complex configurations. Which was of course not the case.
Fast-forward to today, I’m happy to share that:
syslog-ng can collect logs at 7 million EPS
-
Is this measurement value valid? Yes.
-
Does it apply to real world? No.
-
Does it sound good? Definitely :-)
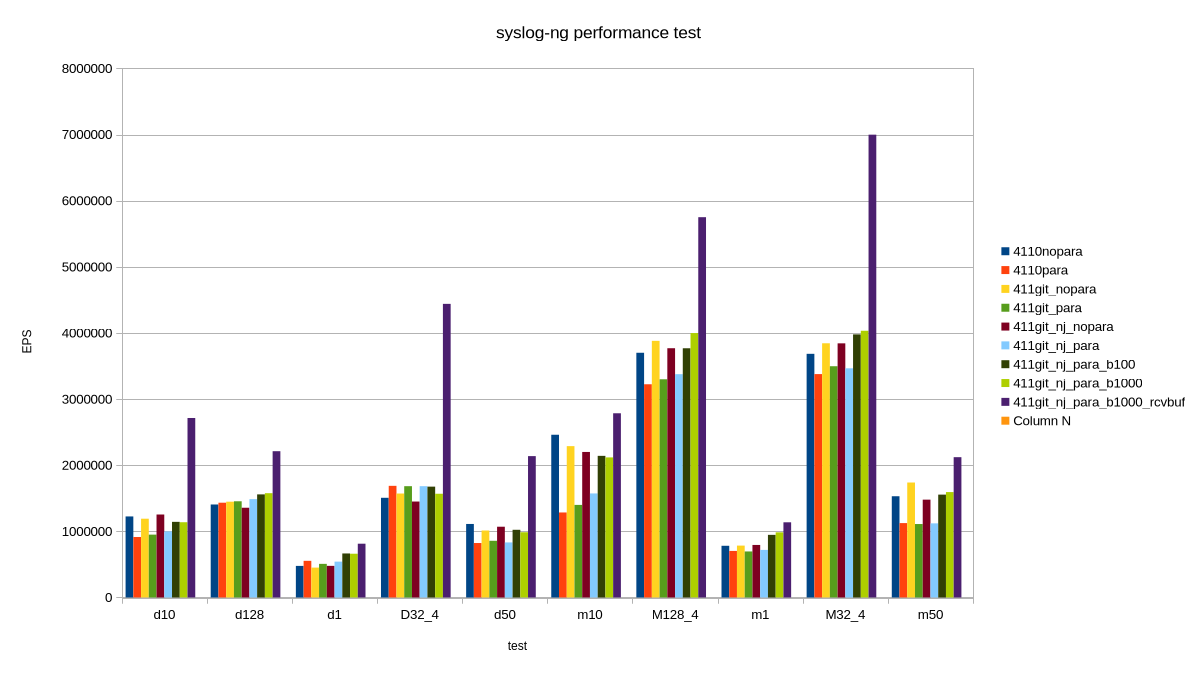
My latest syslog-ng benchmark results
The tool: sngbench
I love playing with various non-x86 systems. I have various ARM, POWER, MIPS systems at home, and sometimes I access other architectures, like RISC-V remotely. And, of course, not just different architectures, but different operating systems: various Linux distributions, MacOS, FreeBSD, sometimes also other BSD variants. I’m a server guy, and for the past 15+ years: a syslog-ng guy. Sometimes I had access to an exotic system on the other side of the world only for less than an hour, but I almost always tested syslog-ng.
For many years I had a bunch of shell scripts and configs to benchmark syslog-ng performance. Not for real world production loads, but rather for comparing architectures and operating systems. I needed a script which could do measurements with minimal dependencies and do it quickly, in one go. This is how sngbench was born, based on my previous ugly scripts. It has quite a few advantages and shortcomings:
-
Minimal dependencies: bash and syslog-ng
-
No complex setup: everything runs on the same host
-
network bandwidth is not a limiting factor
-
loggenandsyslog-ngprocesses are competing for resources -
Two bundled configurations: a performance tuned and the default syslog-ng.conf from openSUSE with minimal modifications to add a TCP source
-
By default, very short (20 seconds) measurements, so disk I/O is not a limiting factor
-
Many different test scenarios: from a single TCP connection to 4 * 128
Of course this describes just the “factory defaults”. You can easily change the test scenarios and configurations too.
How I reached 7 million EPS, and why it is not relevant
I was testing syslog-ng code which was not yet even merged to the development branch. First, I tested these patches with various settings. Along the way I remembered that Splunk guidelines mention so-rcvbuf tuning also for TCP connections. Previously I only used that for optimizing UDP performance. Now I have done it for TCP. Wonders happened :-)
But, of course, the main question is: can you achieve this performance in production? TL;DR: No.
My tests are run from localhost. Network bandwidth is not an issue. Tests are run in short bursts. This is peak performance; when it comes to writing logs to files or forwarding to a cluster of Splunk or Elasticsearch endpoints around the clock, that would be slower. Also, in my fastest test case, logs came from four different loggen instances, over 32 TCP connections each, at a constant rate. In the real world, logs come in bursts and connections are opened and closed regularly.
Test environment and tests
I used my AI mini workstation with Fedora Linux 44 Beta. First, I took a base line with stock syslog-ng 4.11.0 included in the distribution. Then I used my syslog-ng git snapshot packages for Fedora from https://copr.fedorainfracloud.org/coprs/czanik/syslog-ng-githead/. Initially it also had jemalloc support compiled in. Later I disabled it and purely focused on the yet to be merged parallelize() optimizations from GitHub. I experimented with enabling and disabling parallelize(), adding various batch_size() values, and finally also so-recbuf().

AI in a miniature box :-)
This blog is part of a longer series about my adventures with my new machine and AI. You can reach me to discuss this blog on one of the contacts listed in the upper right corner. You can read the rest of the blogs under the toy tag.
Este mes de marzo en KDE Linux
Hoy os traigo el otro resumen del progreso en KDE Linux, un informe detallado de la última entrada de Nate Graham en su blog «Adventures in Linux and KDE», donde nos pone al día sobre los avances de KDE Linux, el sistema operativo «del futuro» de la comunidad KDE. Es decir, que bienvenidos a el progreso de este mes de marzo en KDE Linux, otro gigantesco paso que nos acerca a un sueño para los simpatizantes de este entorno de trabajo.
Este mes de marzo en KDE Linux
El bueno de Nate no solo se encarga de informarnos del progreso de Plasma en sus artículos de «This week in Plasma, sino que en ocasiones nos obsequia con una mirada a otros proyectos de la Comunidad.
Si hace un par de meses se publicó el artículo «Busy months in KDE Linux» y hace un mes otro llamado «This month in KDE Linux» en los que Nate nos muestra que el proyecto está vivo y que si no pasa nada en unos meses tendremos entre nosortros la primera versión estable de esta distribución.
Evidentemente os animo a leer el artículo completo que ha titulado «This month in KDE Linux: March 2026» pero aquí os ofrezco un resumen del mismo para los que no tenemos un dominio exhaustivo del inglés.
- Ahora es más difícil que el ordenador deje de funcionar tras una actualización, ya que se han mejorado los mecanismos para «volver atrás» automáticamente si algo falla. Este punto creo que es el básico para esta distribución.
- Se ha optimizado la gestión de memoria para evitar que el equipo se congele por completo cuando tienes demasiadas aplicaciones abiertas; en su lugar, el sistema simplemente cerrará la que más consuma.
- Para el día a día, conectar un iPhone o iPad ahora es más sencillo, permitiendo pasar fotos directamente desde el gestor de archivos.
- El sistema es más «parlanchín» y claro: si intentas abrir un programa que no es compatible, te explicará por qué en lugar de dar un error genérico.

- Al escribir contraseñas ahora verás asteriscos para confirmar que estás tecleando.
- Se ha incluido un corrector ortográfico listo para usar.n
- Ahora el sistema operativo permite «abrir» archivos que son copias exactas de un CD o DVD (como los archivos .iso) sin necesidad de grabarlos en un disco físico.
- Mejorado el soporte para archivos antiguos de Word
- Mayor compatibilidad con diferentes formatos de música y archivos comprimidos.
Para finalizar, os dejo las palabras de Nate:
¿Te parece emocionante este proyecto? ¡Espero que sí! Estamos construyendo un sistema operativo de propósito general para gente normal, con el objetivo de integrar todos los componentes de serie de una forma que rivalice con Windows y MacOS. Si quieres echar una mano con el proyecto, hay varias formas de hacerlo.
Si eres una persona técnica y aventurera, instala KDE Linux e informa de los fallos que encuentres.
Si se te da bien escribir, la documentación siempre se puede mejorar. Envía tus propuestas de cambios (merge requests) aquí.
KDE Linux se apoya mucho en Flatpak, por lo que solucionar problemas de empaquetado o de código en aplicaciones de este tipo es de gran ayuda.
¡Incluso puedes ayudarnos a construir el propio sistema operativo! El objetivo de la versión Beta está completado al 71% y queda mucho por hacer:
Y si ya estás usando KDE Linux, ¡cuéntanos qué tal ha sido tu experiencia! ¿Es buena? ¿Qué podemos mejorar?
Como vemos, KDE Linux no es solo una «distro» más; es el campo de pruebas y la vitrina oficial de lo que KDE puede ofrecer cuando controla todo el ecosistema, un sueño que no viene de ahora (ya escuché esto en la Akademy de A Coruña de 2015 y cuyo primer se dio con KDE Neon).
Vemos que el desarrollo de esta Comunidad cuyos objetivos están claros se construye dando pasos pequeños pero seguros.
La entrada Este mes de marzo en KDE Linux se publicó primero en KDE Blog.
Thunderbird y la bandeja de sistema en Linux
El cliente de correo Thunderbird y la gestión para que se visualice en la bandeja de sistema de sistemas GNU/Linux es un problema que quizás pronto tenga solución
Desde hace tiempo utilizo el cliente de correo Thunderbird para la gestión de mis correos electrónicos, por hacer la tarea de manera eficiente y ser software libre y para asegurarme que siga siendo así he donado varias veces al proyecto.
Algo que todavía queda pendiente en sistemas GNU/Linux y que de manera recurrente se ha pedido, es la posibilidad de minimizar la aplicación en la bandeja del sistema y que además muestre el número de correos sin leer, o si hay alguno nuevo.
Es un problema más complejo de lo que pueda parecer, pero que quizás poco a poco se vaya solventando hasta dar con la solución.
De manera periódica, cada mes en Thunderbird publican una revisión del desarrollo que están llevando a cabo en el software. De las novedades en las que trabajan, de los problemas solucionados y tareas en las que sigue involucrado el equipo de desarrollo.
En la revisión de marzo de 2026 un apartado me llamó la atención, el referente al trabajo desarrollado para la bandeja de sistema en sistemas GNU/Linux.
Como he comentado, algo recurrente en las peticiones a Thunderbird era la posibilidad de que Thunderbird se minimizara en la bandeja de sistema y que además mostrara número de correos sin leer o alertas de correos nuevos. Desconozco si en sistemas privativos como el de Microsoft o Apple sí hace eso.
En este caso el equipo de desarrollo comparte la siguiente nota:
Bandeja del Sistema Linux
Este mes queremos dar un reconocimiento especial a Christophe Henry, que ha ido más allá con una ambiciosa contribución para mejorar la integración de la bandeja de sistemas de Thunderbird en Linux.
Este trabajo no es un parche pequeño y abarca varias partes de la base de código, incluyendo JavaScript, C++ y Rust, e incluso conecta con interfaces de XPCOM. El objetivo es unificar cómo se comportan los indicadores de correo no leído y los iconos de bandeja entre plataformas, lo cual es un problema sorprendentemente complejo si se tienen en cuenta las diferencias entre entornos Linux, Windows y macOS.
Lo que realmente destacó fue el nivel de persistencia detrás de esta contribución. A lo largo de varias iteraciones, Christophe resolvió fallos de compilación, peculiaridades de la plataforma y comentarios detallados de revisiones, todo ello mientras abordaba problemas complicados como la codificación de imágenes, las APIs de bandeja del sistema y la integración entre idiomas.
Este tipo de trabajo rara vez es sencillo y a menudo requiere profundizar en partes desconocidas de la pila. Ver que se impulse con este nivel de cuidado y determinación es precisamente lo que hace que la colaboración de código abierto sea tan poderosa.
¡Gracias por la dedicación y el esfuerzo! Realmente marca la diferencia.
Espero que ese esfuerzo, poco a poco vaya dando los resultados esperados y el cliente de correo Thunderbird llegue a ese grado de integración con sistemas GNU/Linux, en el que la diversidad es la norma y que supongo complica la tarea.
